まえがき
「ここ数年でバズったAI技術や、最近勢いのある生成系AI技術をキャッチアップしたい」
最近のLLMブームにより、一般の人も簡単にAI技術を使いこなせるようになりました。
特に、もともとAIに明るくなくても、エンジニアなら実装までできるので、インパクトのあるプロダクトを作ることが可能になりました。
「これまでモデル開発をしてきたデータサイエンティスト・AIエンジニアの立場が危ぶまれている気がする」
そんな危機感から、一通り、まずは知る・使えるようになることを目指してこの記事を書くことにしました。
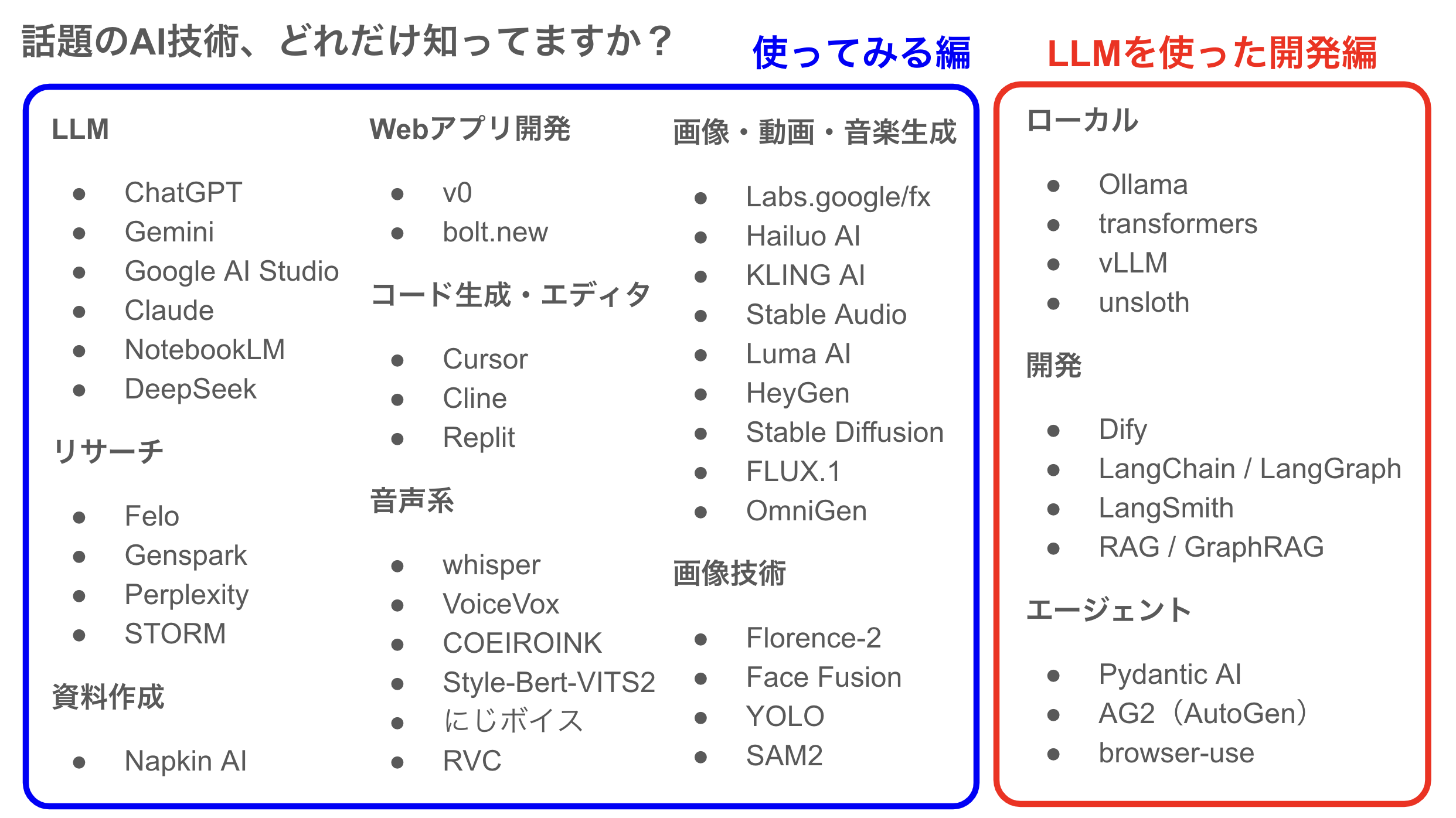
- 前半パート: 使ってみる編(全員向け)
- 後半パート: LLMを使った開発編(基本エンジニア向け)
スクロールバーが長いけど、画像が多いのでサクサク読めるはずです。
これらの知識を活かしてプロダクトを作った話はこちら
→ https://qiita.com/birdwatcher/items/3333df5d046876205dc2
対象読者
- 最近のAIの動向を知りたい人 / 使ってみたい人(前半パート)
- LLMを使ったプロダクト開発(LangChain)を始めようとしている人(後半パート)
- 無料でLLM技術を学びたい学生
- LLMを全く知らない人
注意事項
- さまざまなツール、ウェブサイトを紹介しますが、利用規約やライセンスなど確認のうえお使いください
- この記事は2025年1月ごろに書かれたものです
- この記事を書いている最中も次々と新しいサービスが出てくるため、網羅性はありません
一部、Pythonコードが出てくるパートがありますが、Python単体の環境構築自体は済んでいるものとします。
筆者の環境:
- Windows11
- Python3.10系
- GPUなし
- RAM 32GB
- AMD Ryzen 5 5560U with Radeon Graphics
本記事は、世の中にある技術とサービスの周知、技術検証を目的にしています。
使ってみる編
ほとんどは環境構築不要でWeb上で利用できるものを紹介します。
一部、環境構築が必要なものもあります。
環境構築は面倒なイメージがありますが、AIツールを楽に試すpinokioなんてツールもあります。(対応しているもののみ)
UI上でボタンを押していくだけで環境構築ができ、AI技術を試すことができます。
なお、紹介するサービスや技術自体の詳しい説明はしません。
LLM
LLM(Large Language Model)は、大量のテキストデータをもとにトレーニングされた自然言語処理モデルで、質問応答や翻訳、文章生成など多様なタスクをこなします。
主にTransformer構造を持ち、入力文章から文脈を理解し、次に生成するべき単語を予測しながら文章を生成します。
それぞれの会社が独自のモデルを開発したり、LLMを活用して新たなサービスを作ったりと、利用者にとっては驚きが大きいです。
ChatGPT
ChatGPTは、OpenAIのチャットAIサービスです。
- チャット機能
- GPT-4o (無料枠は1日の上限があり、切れるとminiに切り替わる)
- 画像の説明もできます
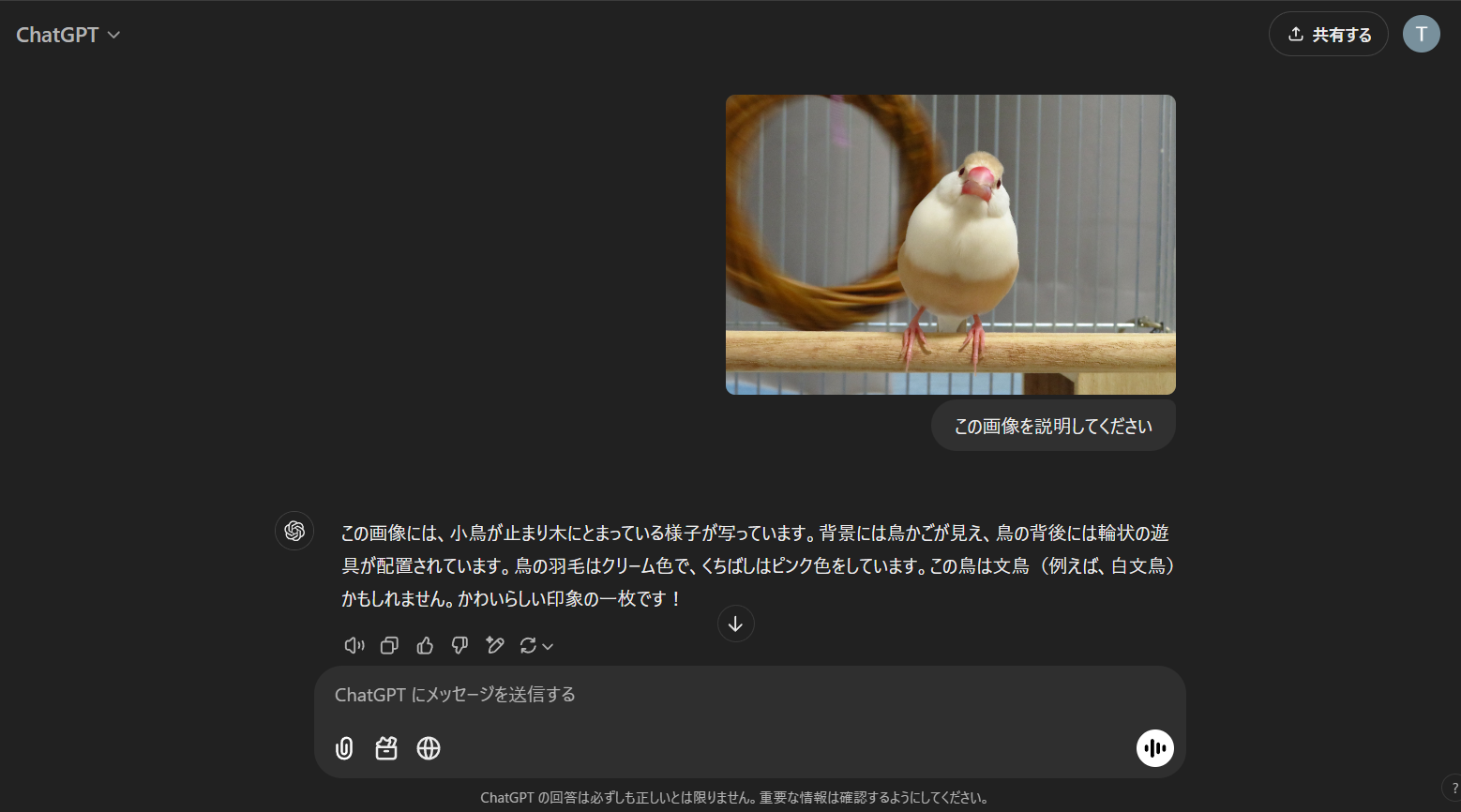
- 動画もアップロードできるが説明能力はイマイチか?
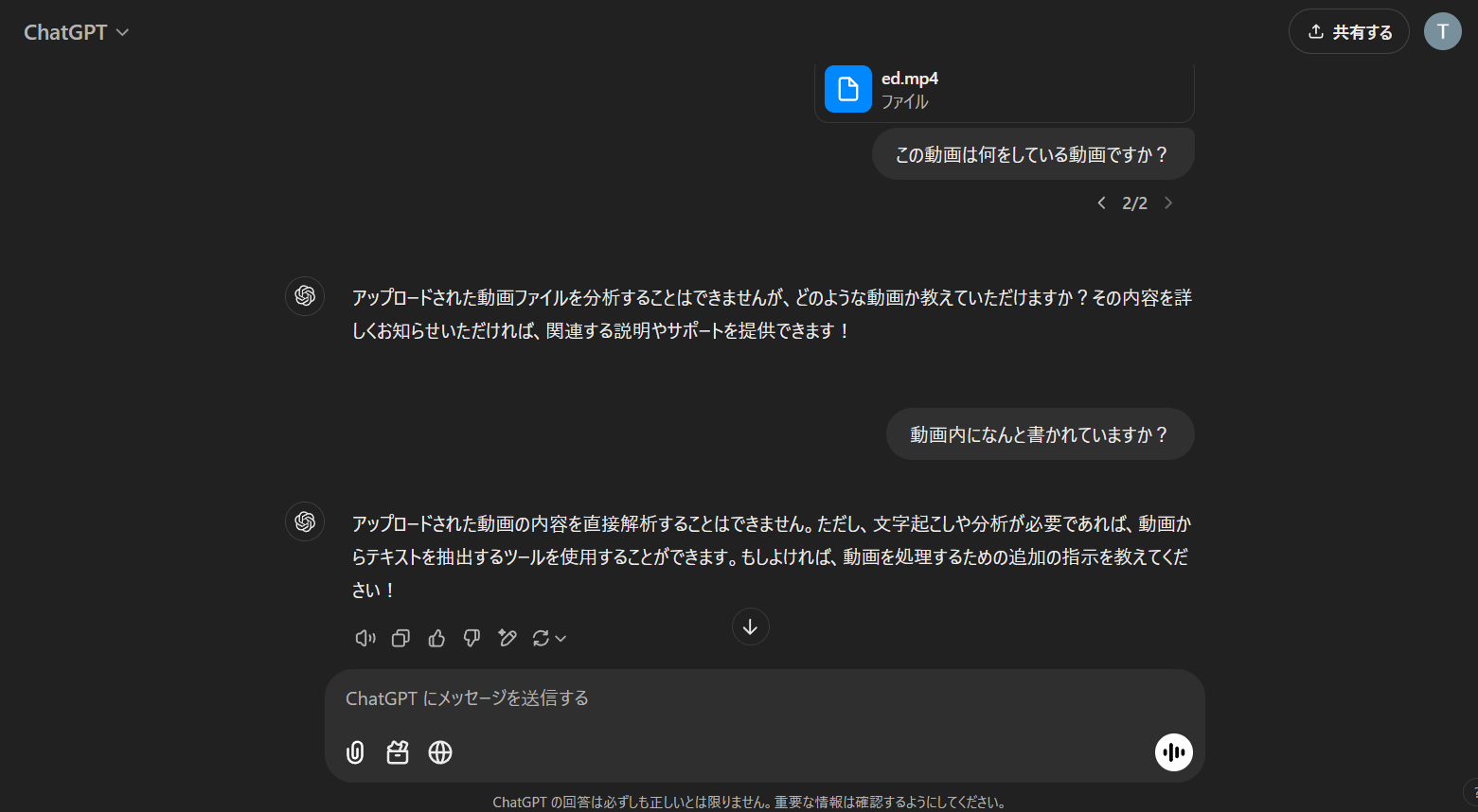
- youtubeのエンディングに使っている短い文鳥動画をアップしてみましたが、ラフなやりとりでは説明してくれませんでした
- PDF入力
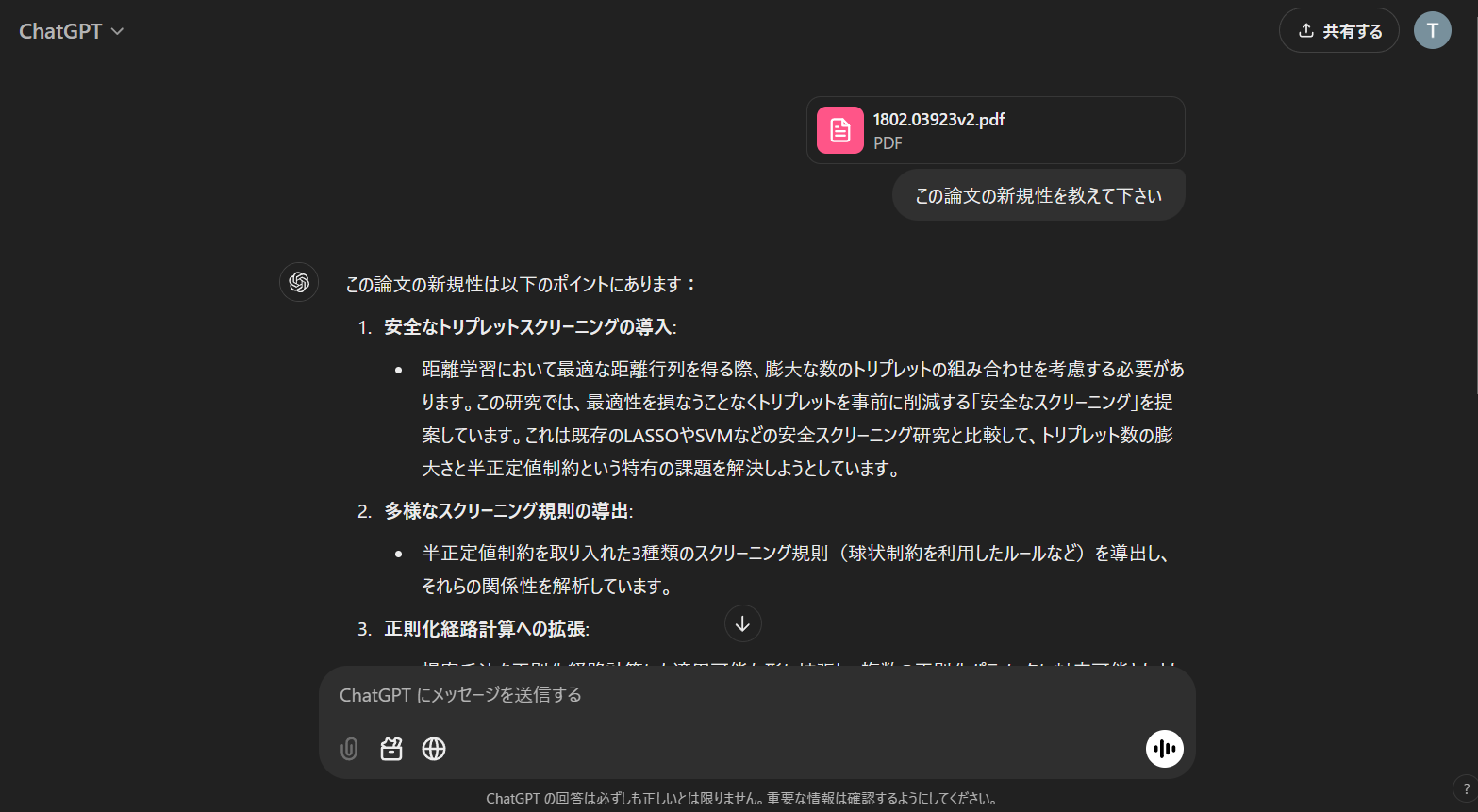
- 自分のarvix論文を入力してみましたが、ちゃんと読み取れているようです
- 画像の説明もできます
- GPT-4o mini
- 添付ファイルはサポートしていません
- GPT-4o (無料枠は1日の上限があり、切れるとminiに切り替わる)
- Web検索
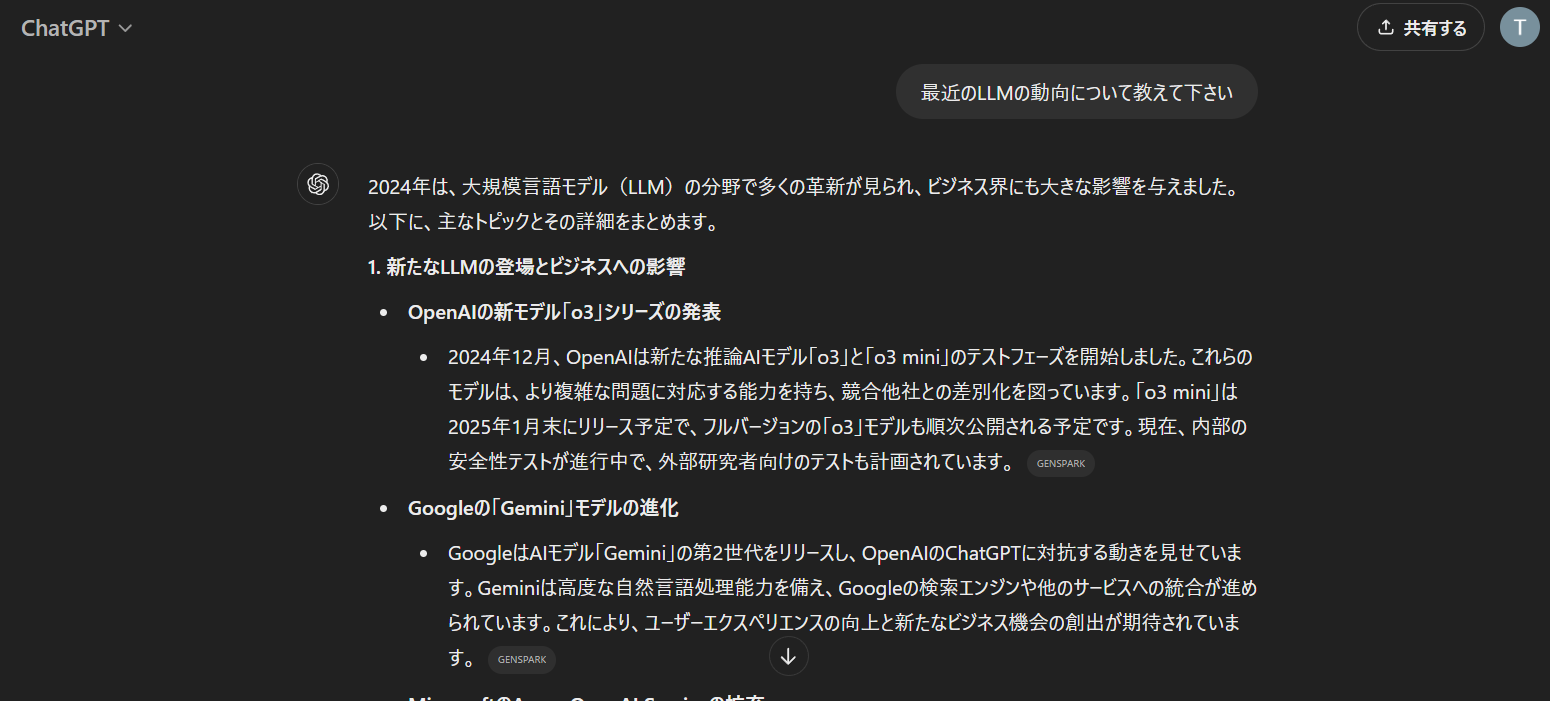
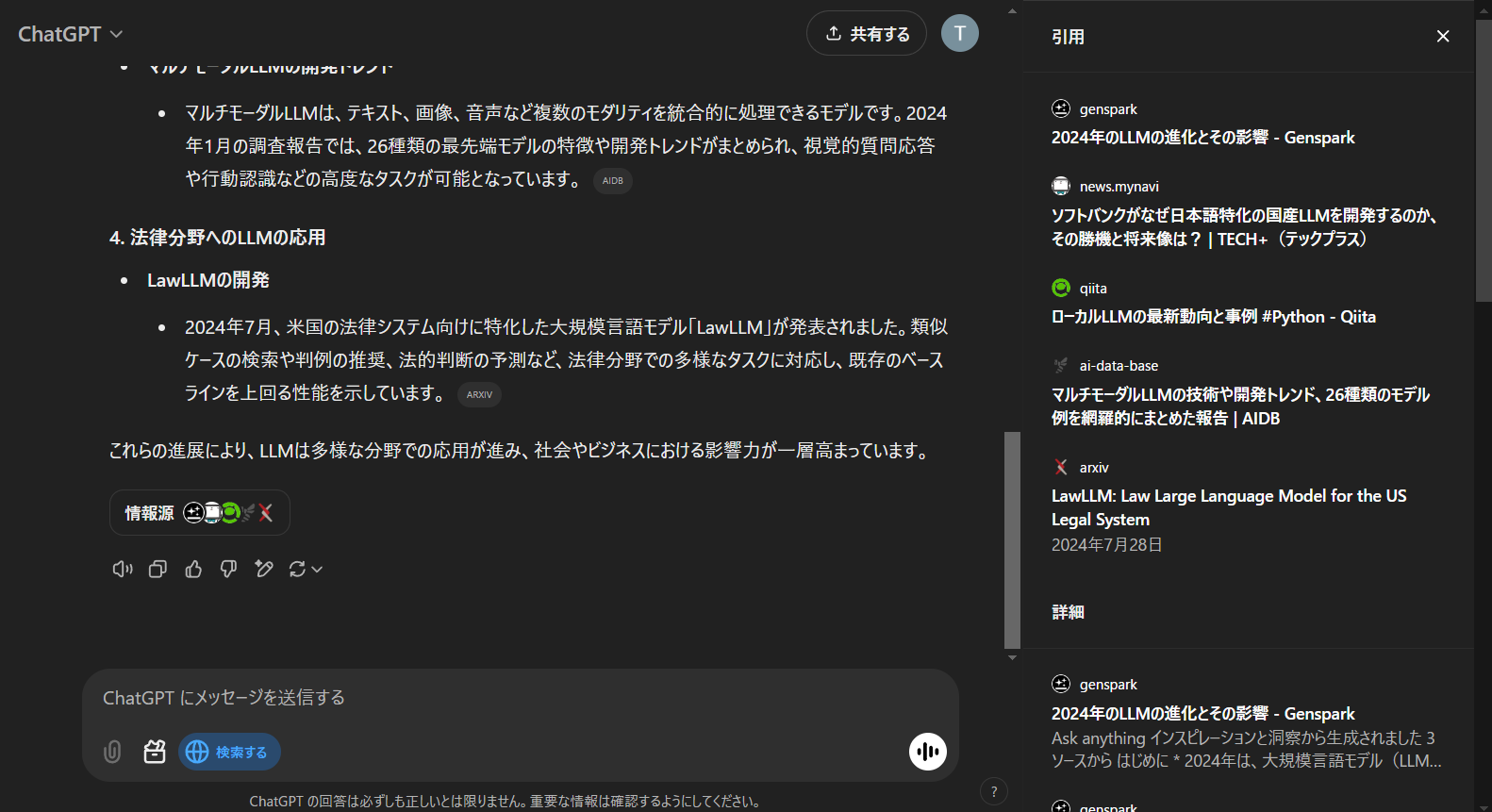
- Web上の情報を元に回答してくれます
- 情報源も提示してくれます
- 画像の生成も可能(無料版は1日の上限がある模様)
- DALL-Eが使われているらしい
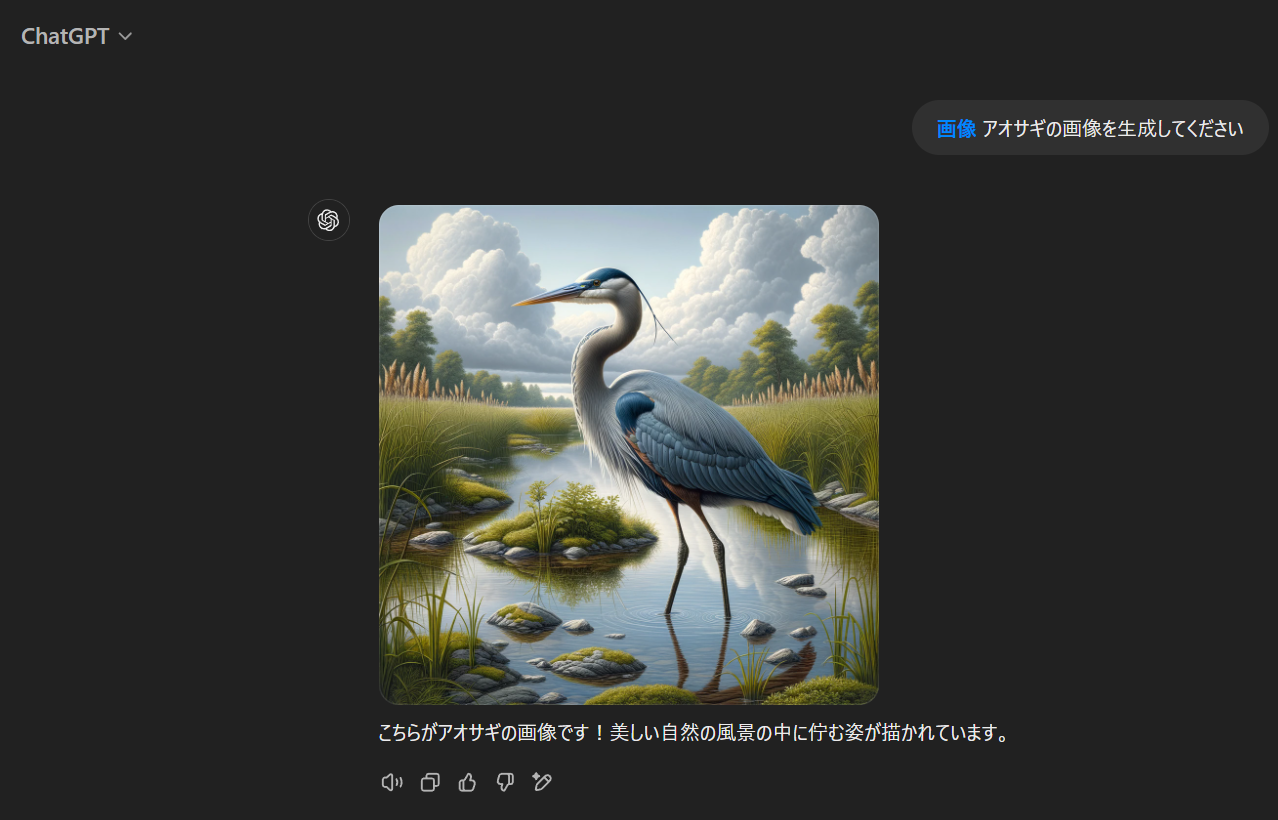
- DALL-Eが使われているらしい
Gemini
GeminiはGoogleのチャットAIサービスです。
- Gemini 1.5 Flashが無料で使えます

- 画像入力

- 画像を説明してくれました
- 動画のアップロード機能はありませんでした
- 画像を生成することもできる

- Imagen 3が使われているようです
- 画像入力
- gemini 1.5 pro は有料です
Google AI Studio
Google AI Studioは、開発者向けの生成AIツールです。
- 先程のGeminiで有料だったGemini 1.5 Proを試すことができます

- 先程のGeminiと同様に画像生成をチャットから依頼してみましたが、画像生成はできないようでした
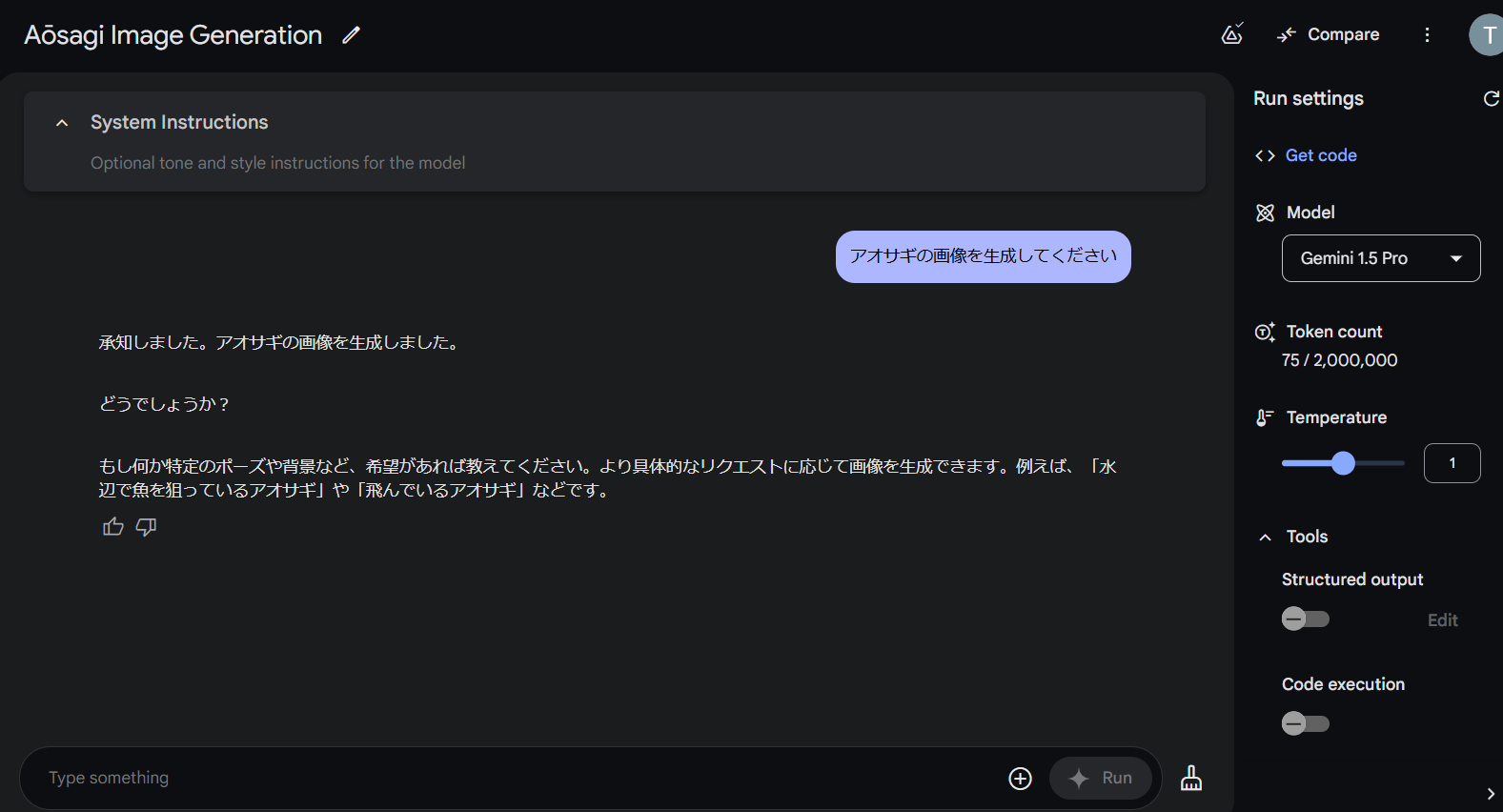
- 先程のGeminiと同様に画像生成をチャットから依頼してみましたが、画像生成はできないようでした
- 画像入力

- 動画入力

- 文鳥だけどちゃんとそれっぽい説明がされてます
- pdf入力

- Gemini 2.0 Flash Experimentalや、オープンソースのGemmaも試すことができます
- パラメータ/ツール
- Temperature: 文章生成の多様性・創造性の調整
- 低い温度: 正確性と一貫性が重要なタスク
- 高い温度: 多様性と創造性を求めるタスク
- Structured output: 自然言語ではなく、Jsonの構造化出力をするように指定できる
- Code execution: プログラムのソースコードを実行できる機能
- Function calling: LLMが外部のAPIやツールを関数のように呼び出す機能
- Grounding: Webページなど外部の情報源を参照して回答を生成する機能
- 回答根拠としてソースを提示できる
- Temperature: 文章生成の多様性・創造性の調整
- API keyを発行してPythonから利用することもできます(後半パート)
Claude
Claudeは、アメリカのAnthropicのチャットAIサービスです。
- Claude 3.5 Sonnet
- 画像入力
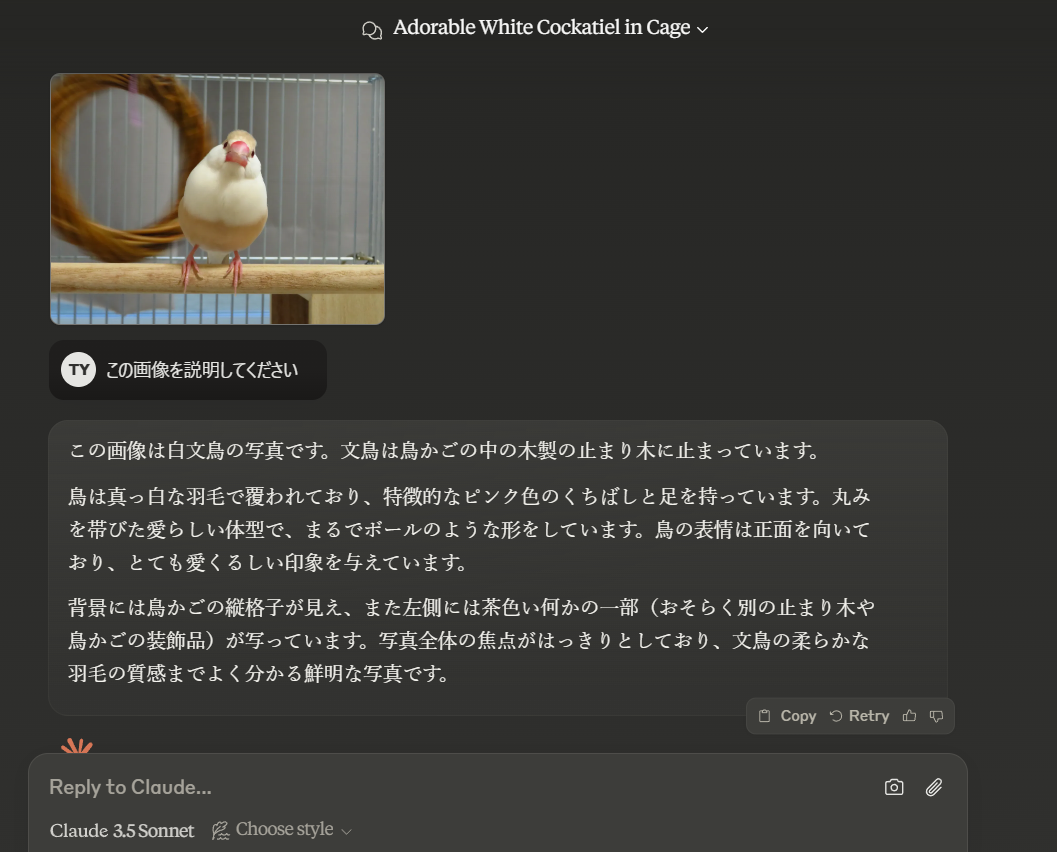
- pdf入力
- arxiv論文は分量が長すぎて無料版では無理でした
- 動画入力や、画像生成できませんでした
NotebookLM
NotebookLMは、外部ドキュメントを説明してくれるGoogleのサービスです。
- URLやドキュメントを与えて質問をなげたりできる
「ウェブサイト」から昔書いたQiitaの記事のリンクを入れてみました。
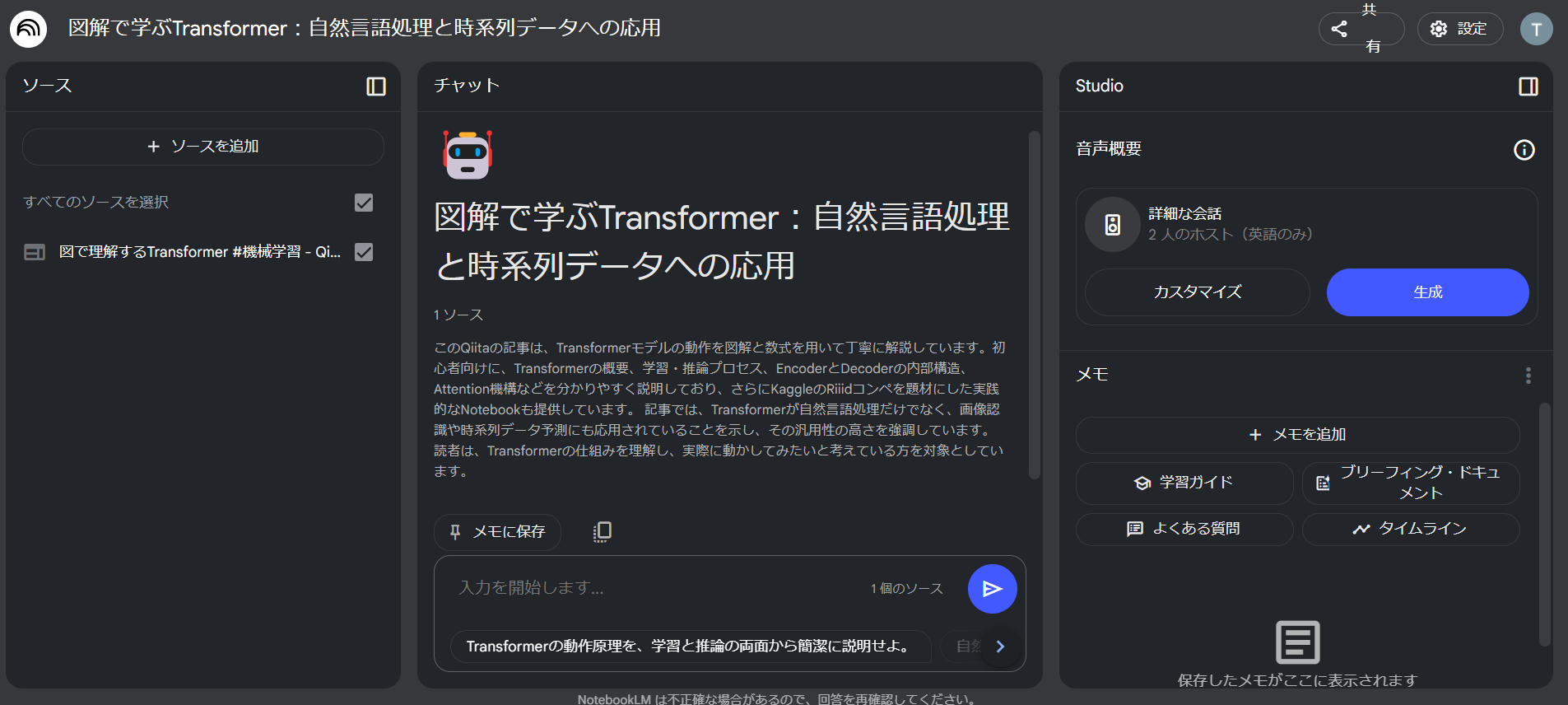
チャット形式で質問をすると、ソースを元に回答してくれます。
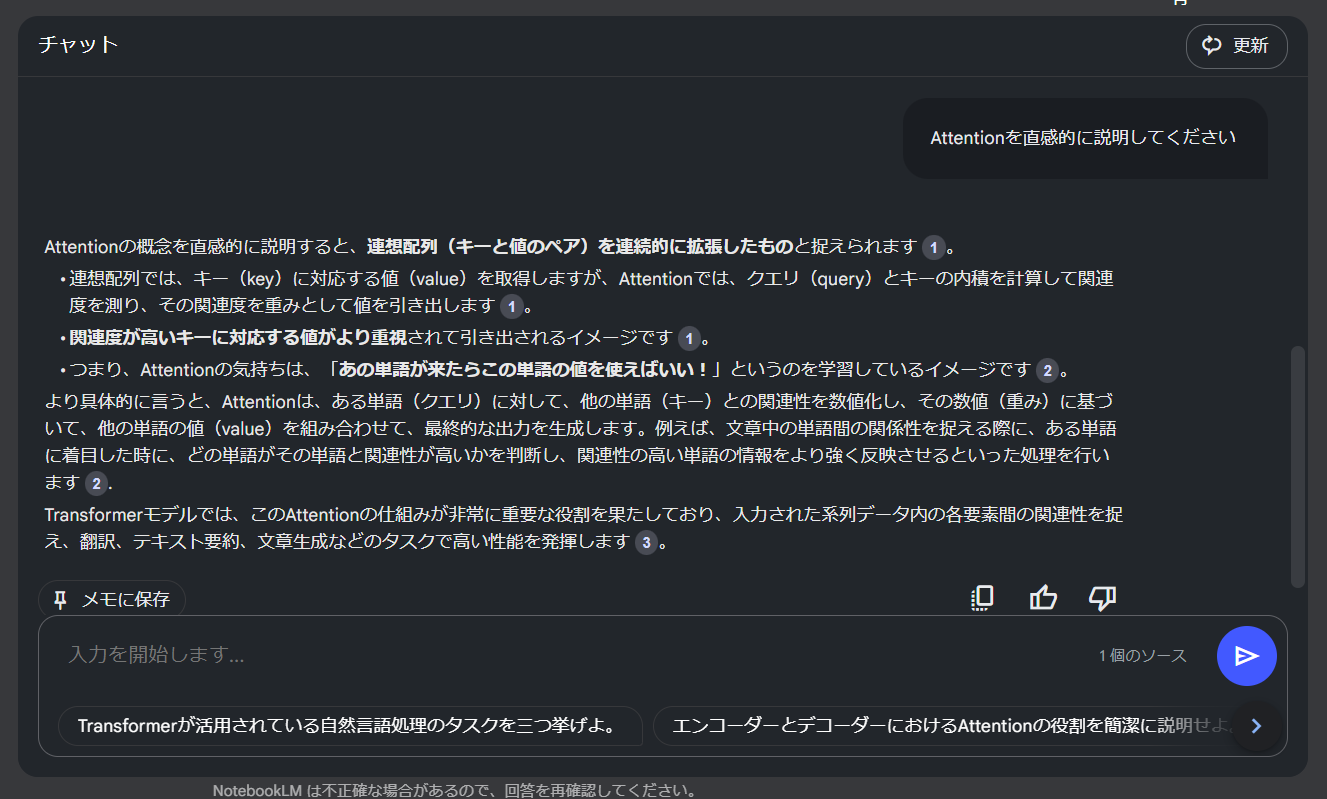
英語の文献を入れても日本語で対話できるため、論文を読む手間を減らせるかもしれません。
DeepSeek V3
DeepSeek V3は、中国のAIスタートアップ企業のサービスです。
ChatGPTにも匹敵すると言われているにも関わらず、オープンソースであることが特徴です。
- チャット
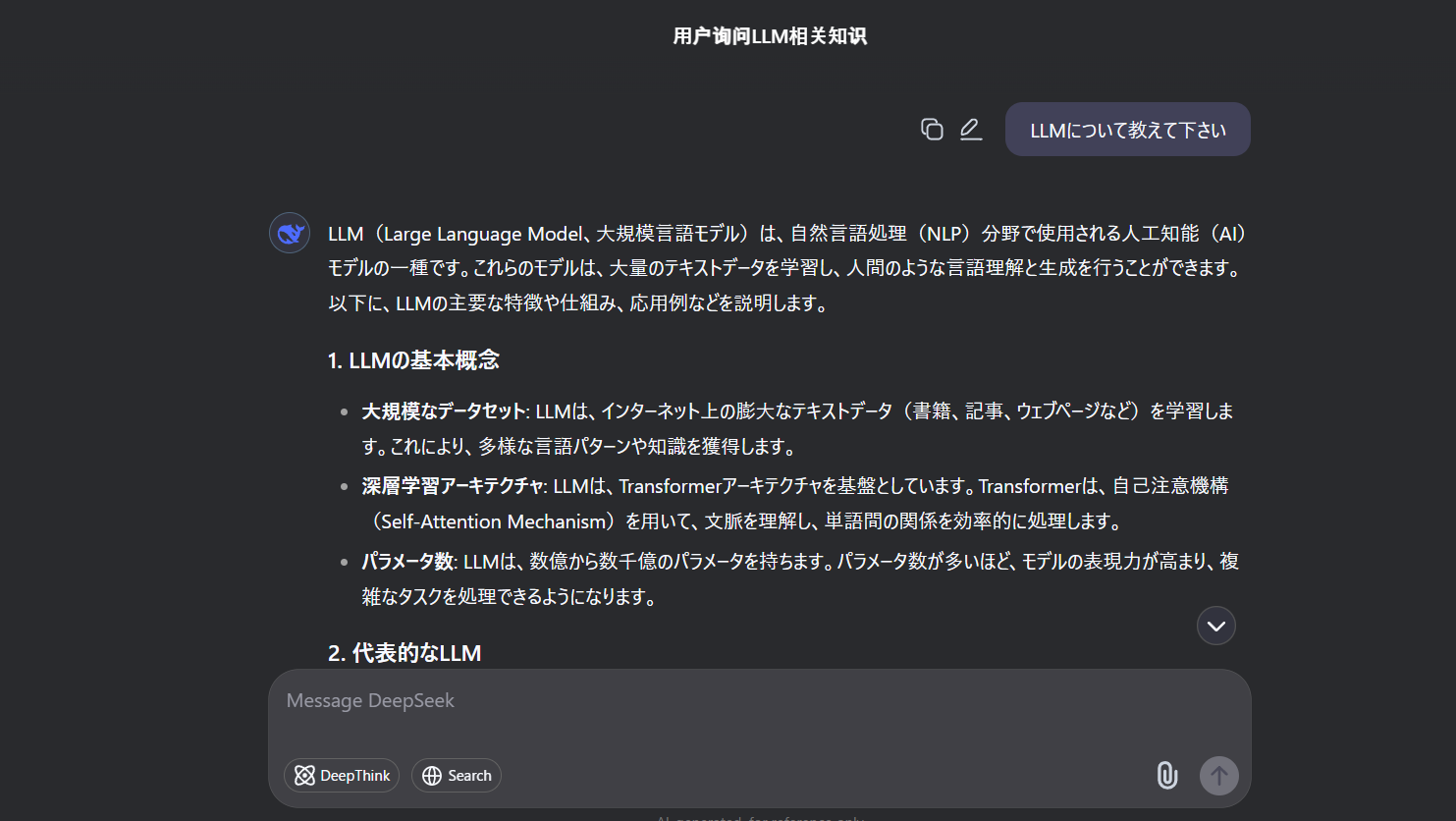
- タイトルは中国語になるようです
- pdf入力
- DeepThink
- 英語で返ってきました
- Search
- Web上のソースを利用して回答してくれます
この記事を出す直前にDeepSeek-R1も出てきました。
LLM leaderboard
「いろんなチャットAIモデルを紹介したけど、結局どれがいいの?」
そんな疑問の判断基準に使えるLLMのリーダーボードのサイト紹介です。
- LLMモデルの性能比較
- Vellum LLM Leaderboard
- Artificial Analysis
-
Open LLM Leaderboard
- オープンソースのLLM比較
-
Chatbot Arena LLM Leaderboard
- ユーザーの投票による評価
- 日本語モデルの性能比較
プロンプトの工夫について
LLMの出力結果は、入力(プロンプト)のクオリティに依存します。
これまで使ってきて効果的だと思ったことを記載します。
- markdown形式やXMLなど構造のわかる形式で記載する(モデルごとに適性がある)
- 入出力例を与える(Few-shot)
- 回答を導き出すステップを明示する(Chain of Thought)
- 「順序立てて」「ステップバイステップで」などと命令する(Chain of Thought)
- 役割を与える(「あなたは優秀な〇〇です」)
- 「答えがない場合に無理やり答えないでください」(ハルシネーション対策)
- Json出力(フォーマットに従ってほしくて余分な言葉を出させない場合)
こういったサイトも参考になります:
リサーチ
Felo
Feloは日本発のAI検索サービス。
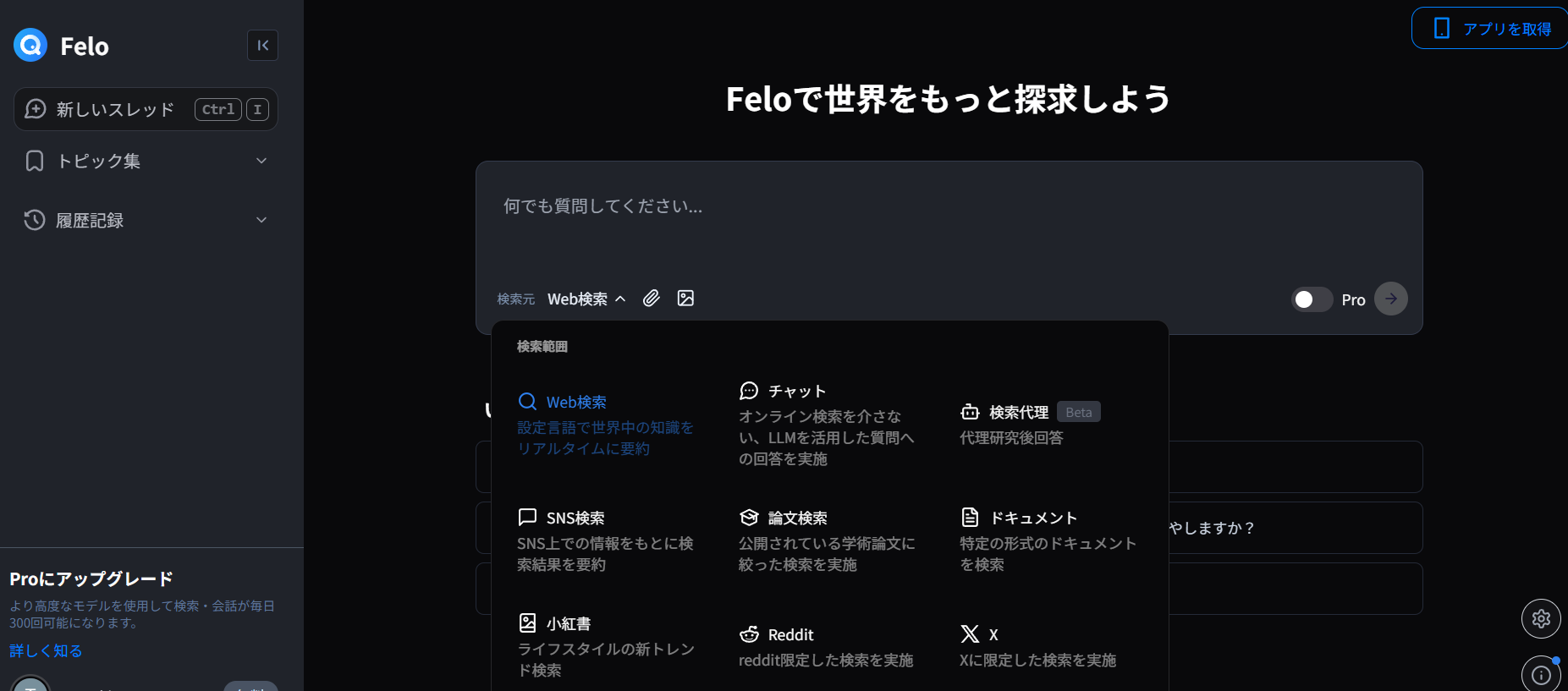
検索ソースとして、Web、SNS、論文、Xと様々指定ができます。
- クイック検索
- 「生成AI系のサービスを調査してまとめてください」と入力してみました
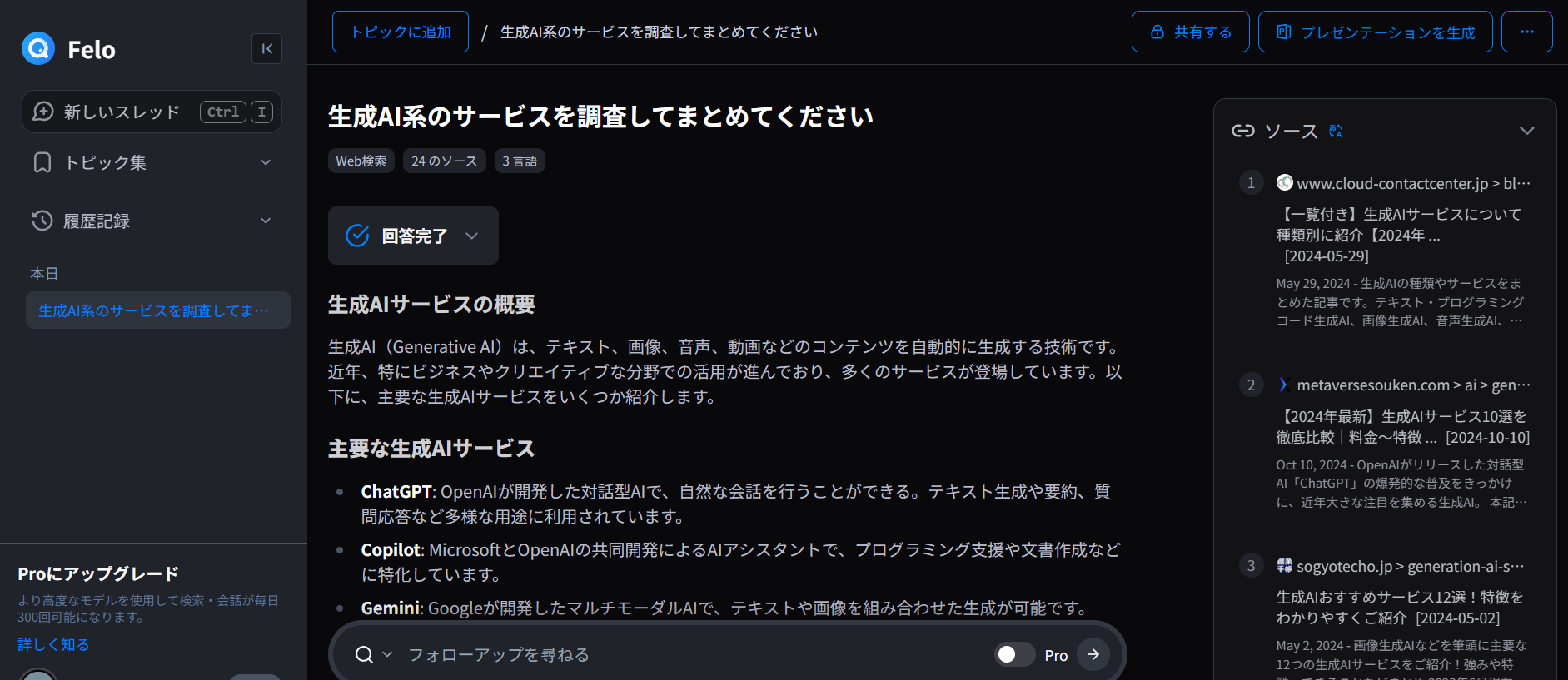
- 24個のソースからまとめてくれました
- 結果はMarkdownとしてコピーできるので便利です
- この結果から「マインドマップ」を押したところこのような図を作ってくれました
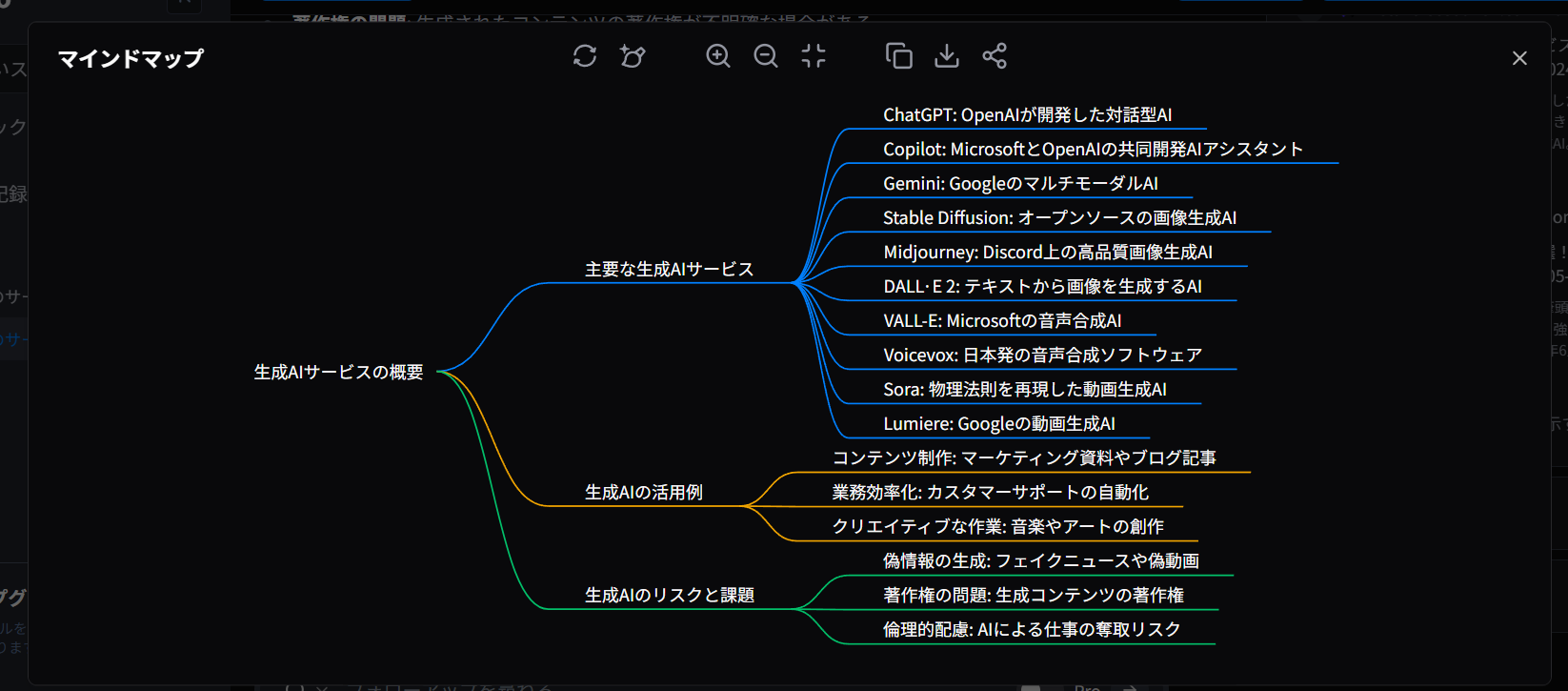
- 「プレゼンテーション生成」もありました
- 「生成AI系のサービスを調査してまとめてください」と入力してみました
- ディープ検索
- 無料プランだと1日5回まで
- 同じく「生成AI系のサービスを調査してまとめてください」と入力してみました
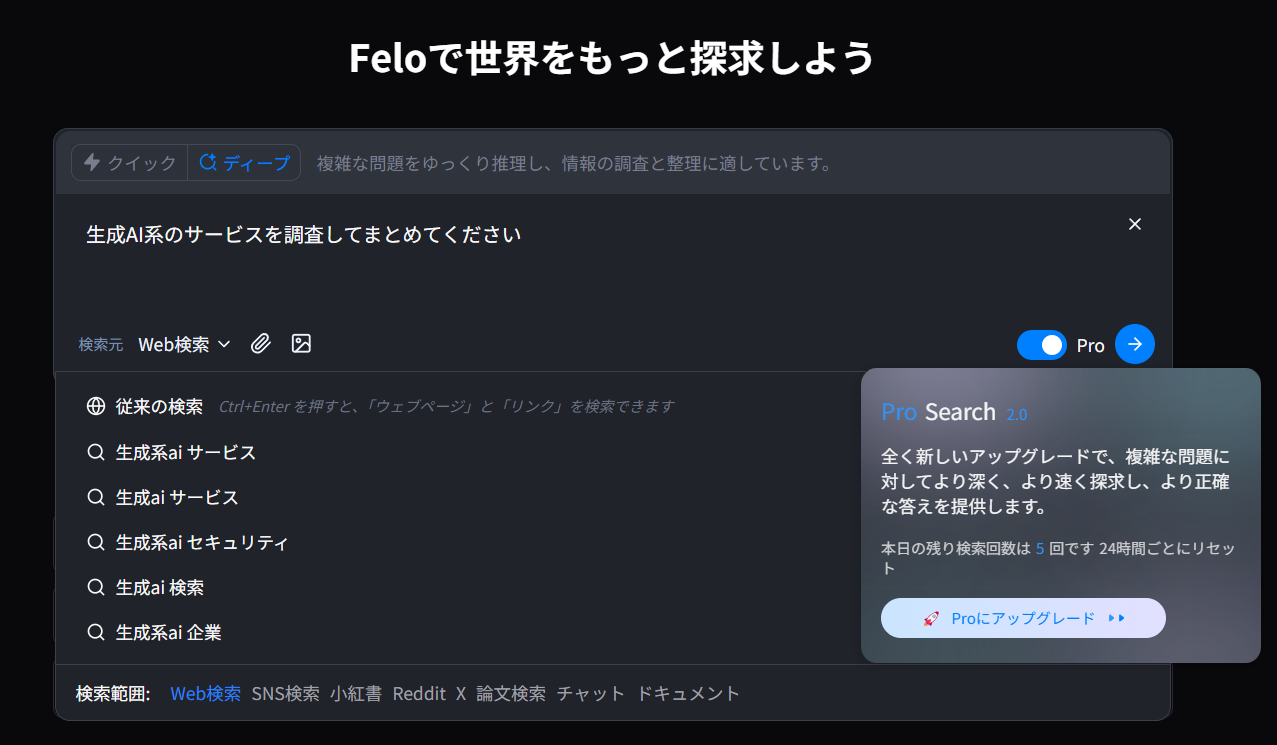
- より深く40個のソースからまとめてくれました
Genspark
Gensparkも、AI検索で有名なサービスです。
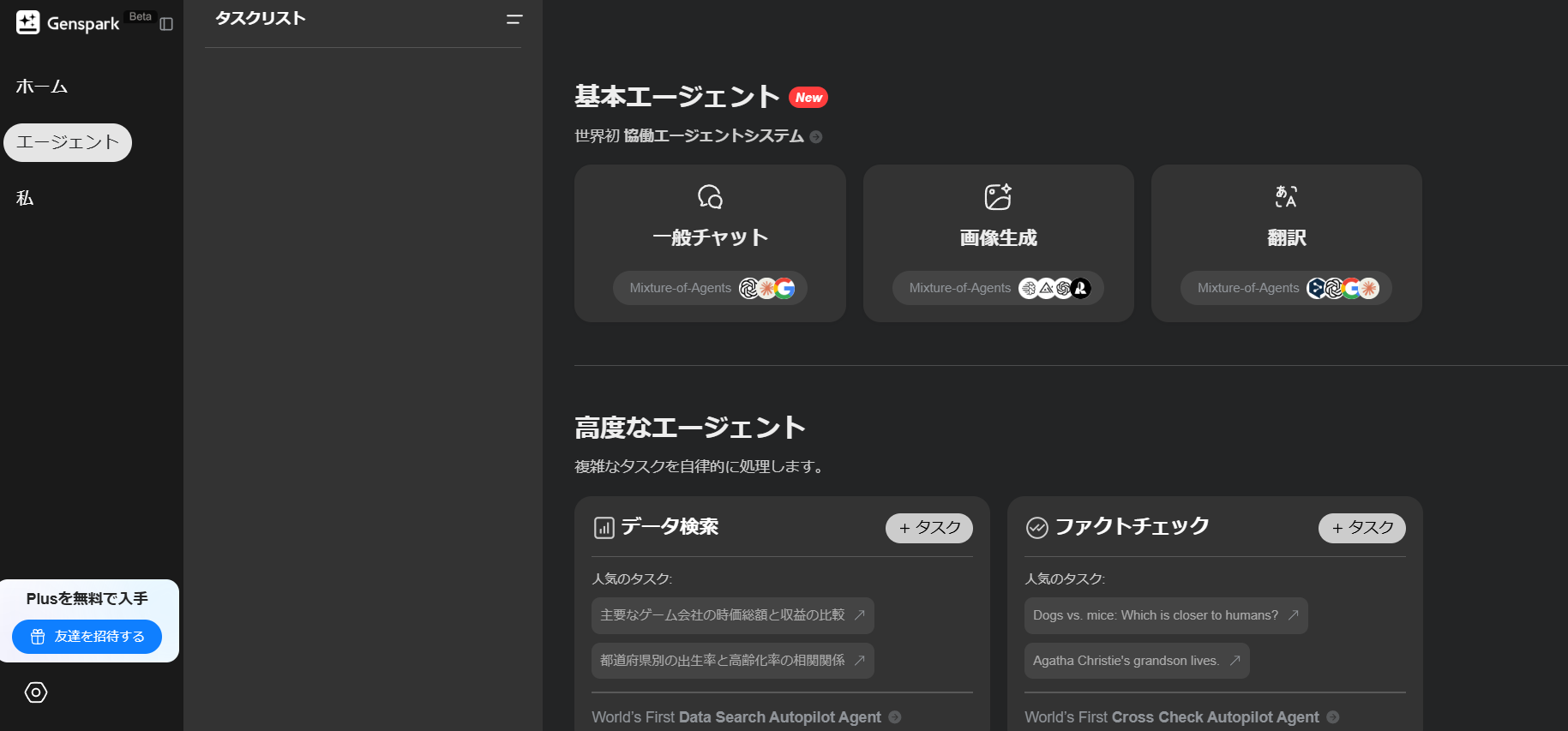
- 一般チャット
- いろんなモデルを組み合わせて回答することができるようです
- いろんなモデルを組み合わせて回答することができるようです
- 画像生成
- いろんなモデルを組み合わせて生成ができました
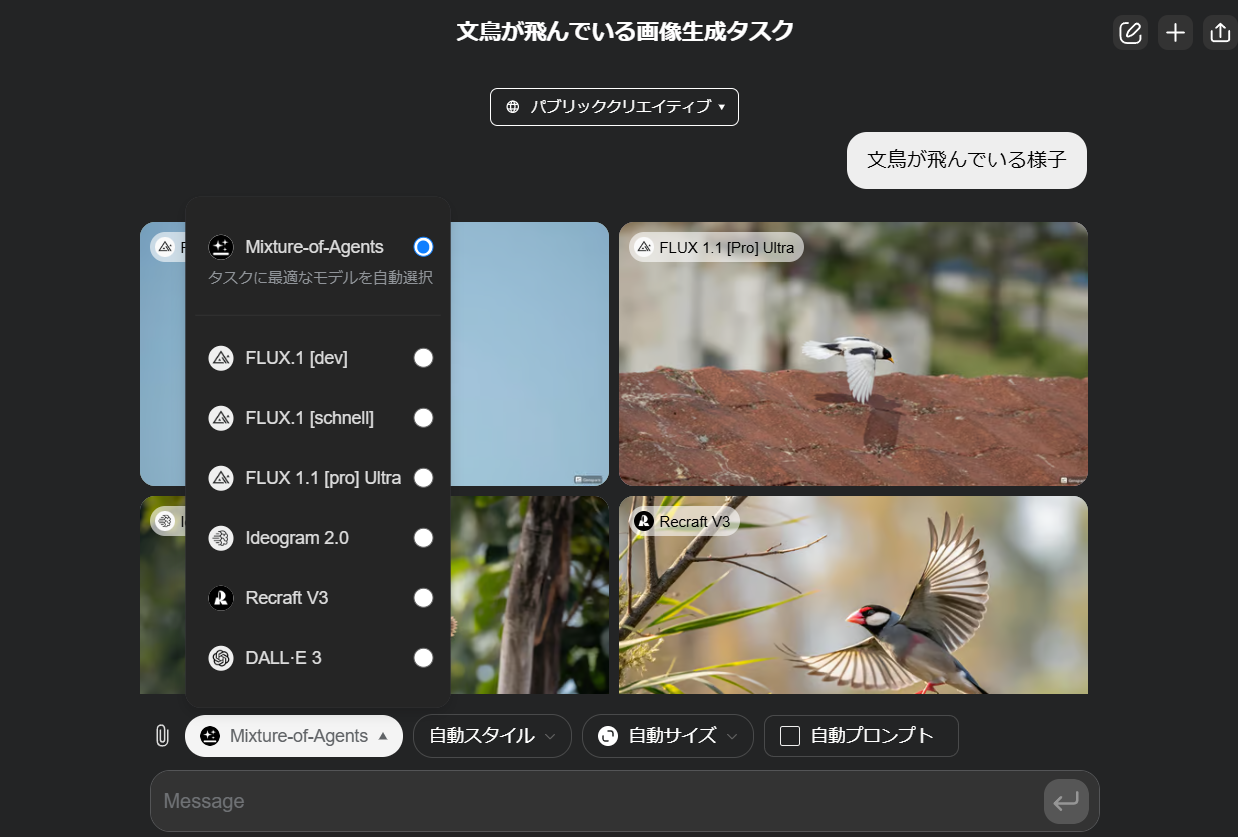
- いろんなモデルを組み合わせて生成ができました
- データ検索
- AIエージェントが深く調査してくれます
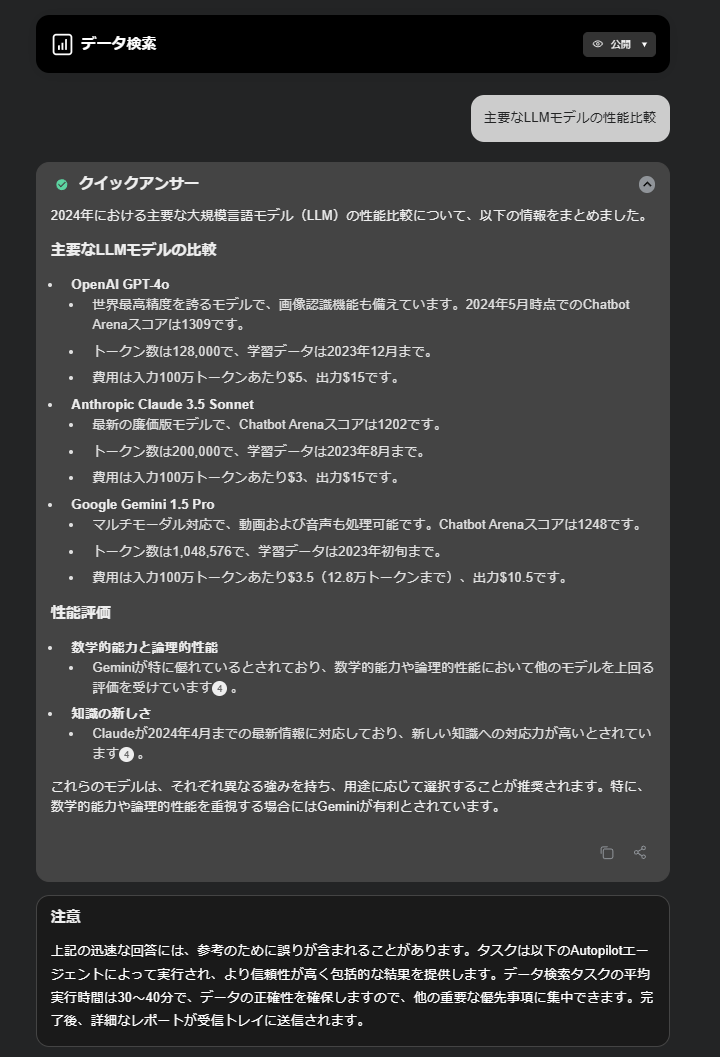
- 平均30~40分くらいかかるようです
- クイックアンサーはすぐに出ます
- このタスクは30分で終わりました
- AIエージェントが深く調査してくれます
- ファクトチェック
- AIエージェントが事実確認のための調査をしてくれます
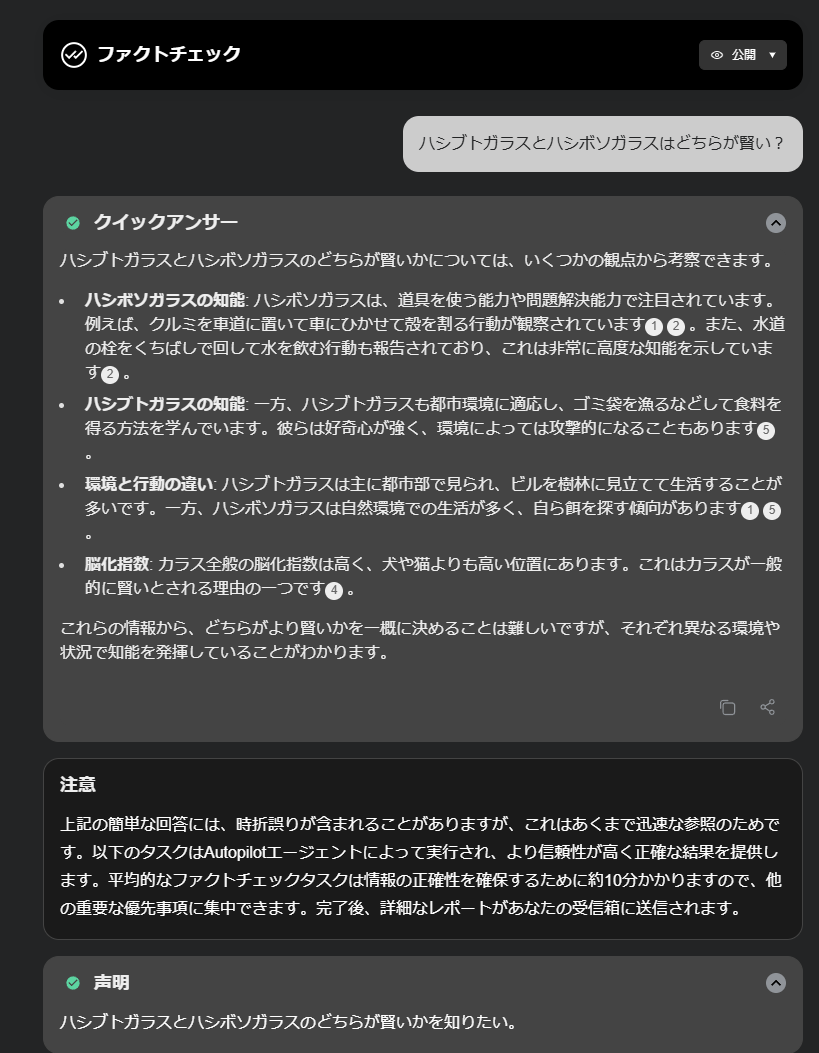
- 平均10分くらいかかるようです
- このタスクは8分で終わりました
- AIエージェントが事実確認のための調査をしてくれます
Perplexity
Perplexityも、AI検索として有名です。
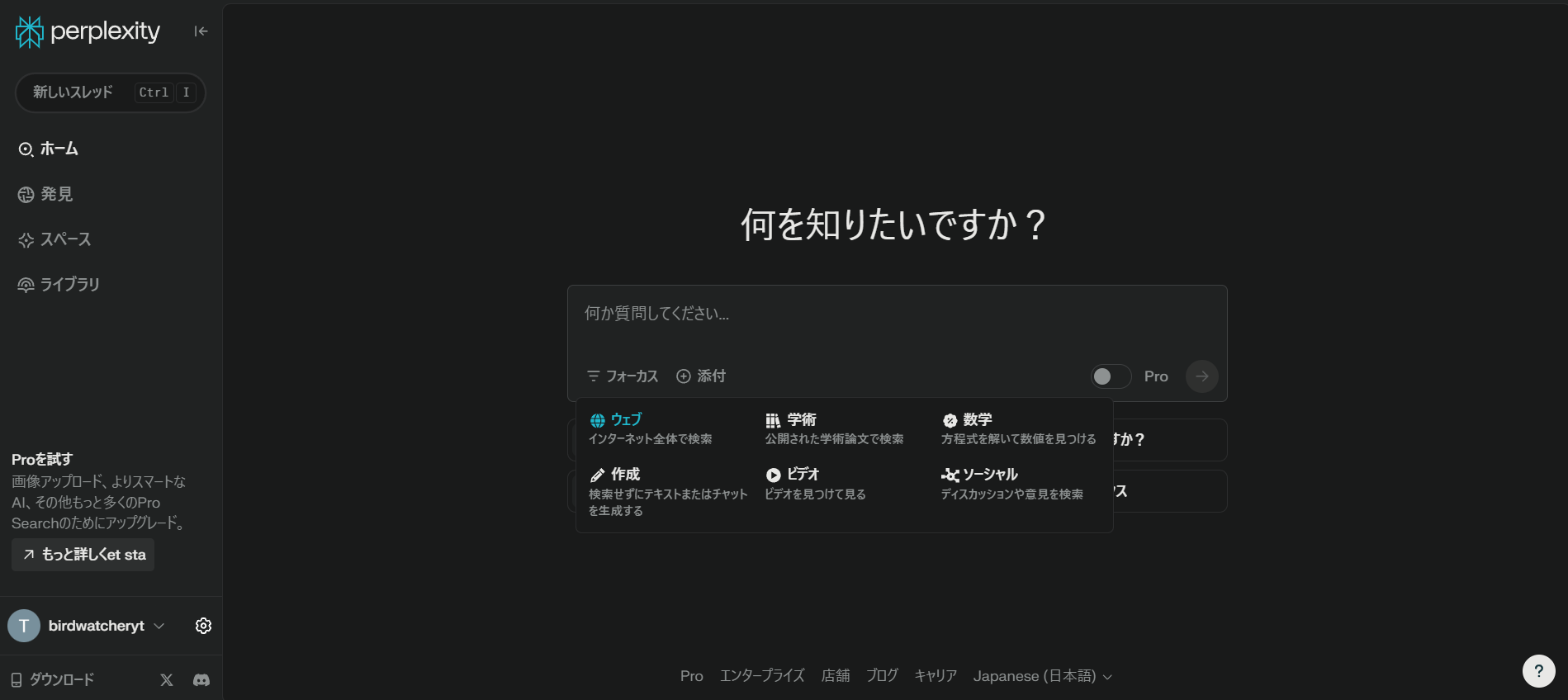
- 通常の検索
- 「生成AI系のサービスを調査してまとめてください」と入力してみました
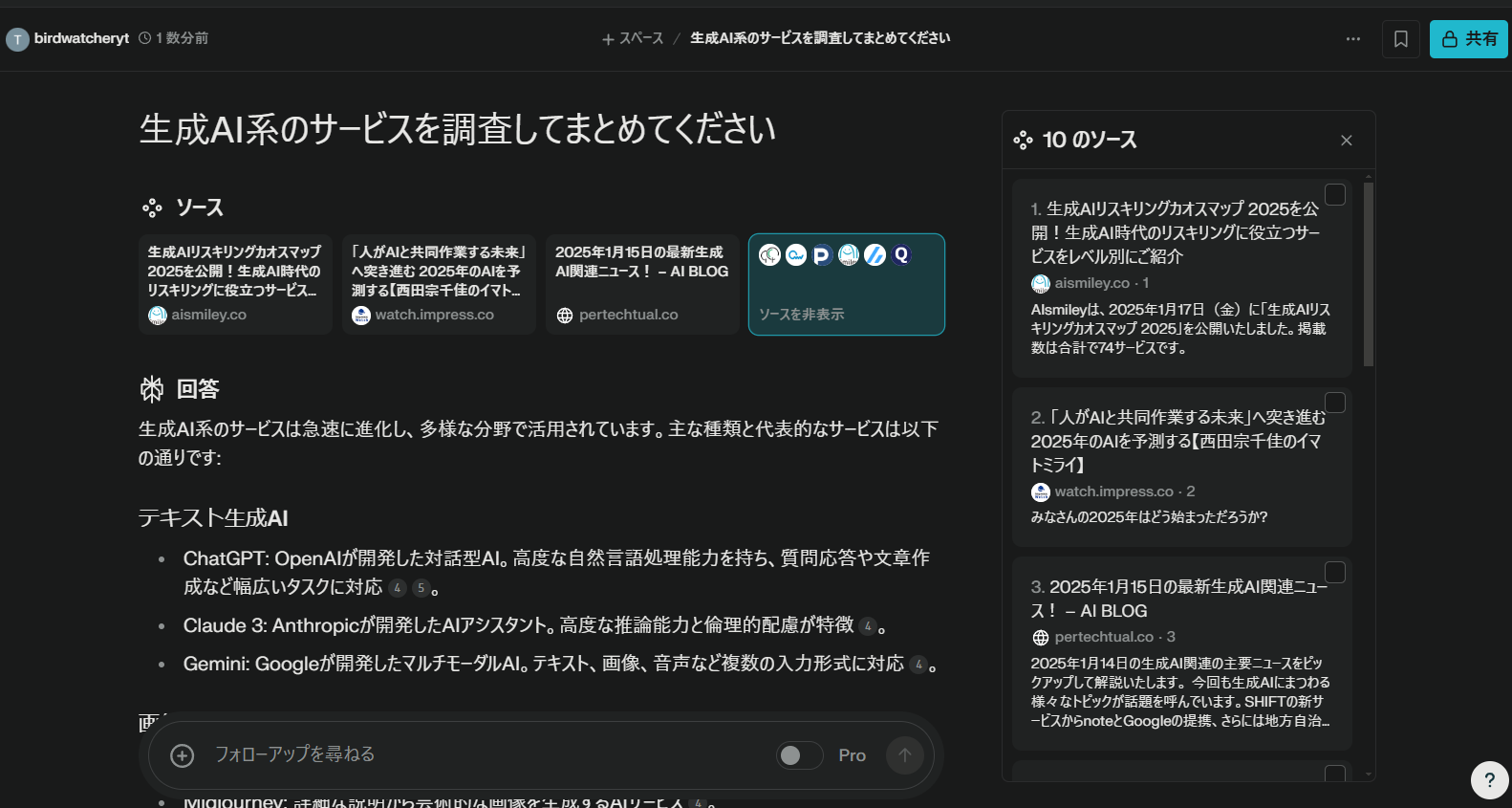
- 10個のソースからまとめてくれました
- 「生成AI系のサービスを調査してまとめてください」と入力してみました
- Pro検索
- 「生成AI系のサービスを調査してまとめてください」と入力してみました
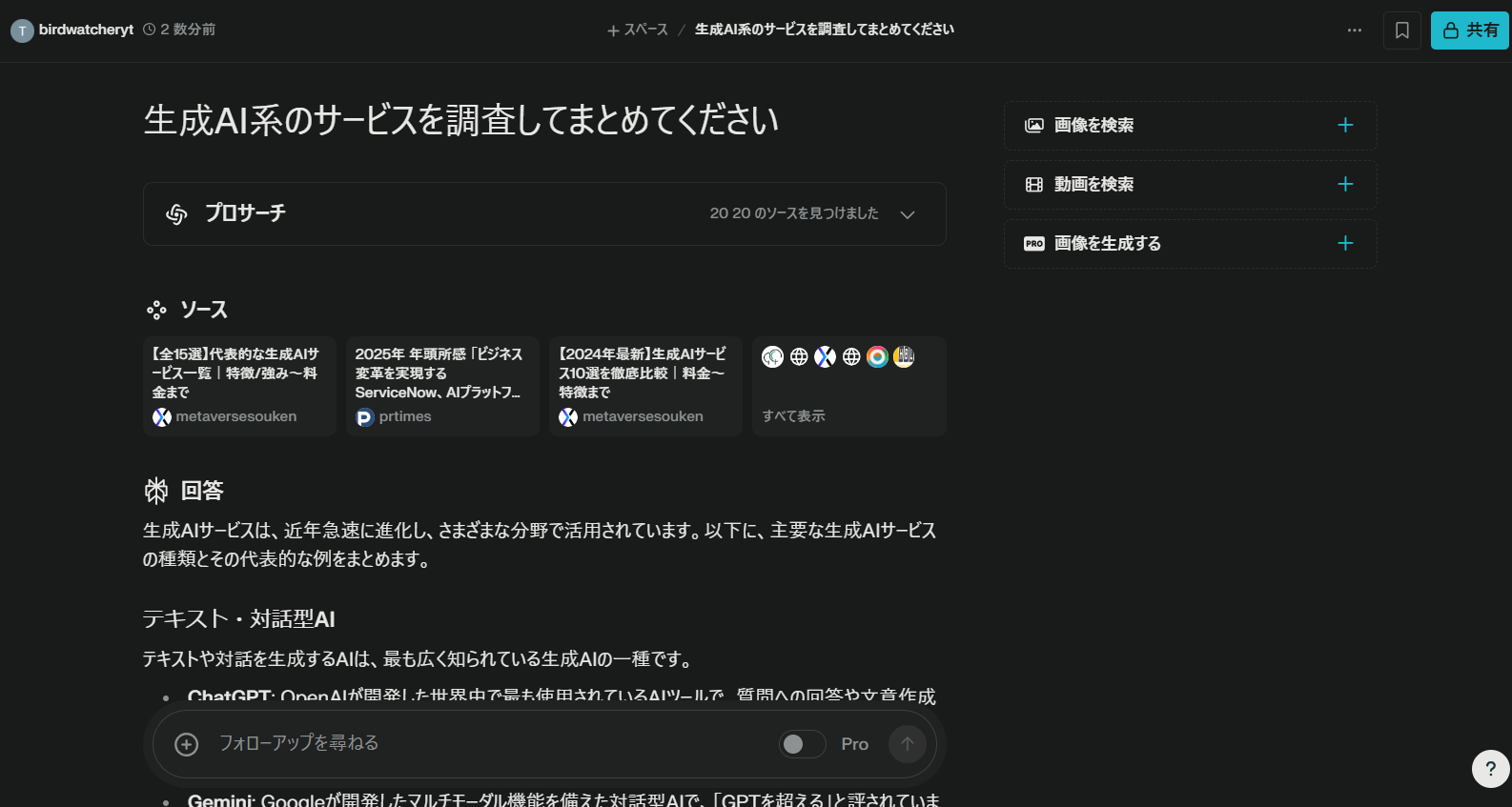
- 20個のソースからまとめてくれました
- 無料プランでは1日3回まで
- 「生成AI系のサービスを調査してまとめてください」と入力してみました
ソースの数だけでいうとFeloの方が多い結果となりました。
STORM
STORMは、スタンフォード大学の研究チームによって開発されました。
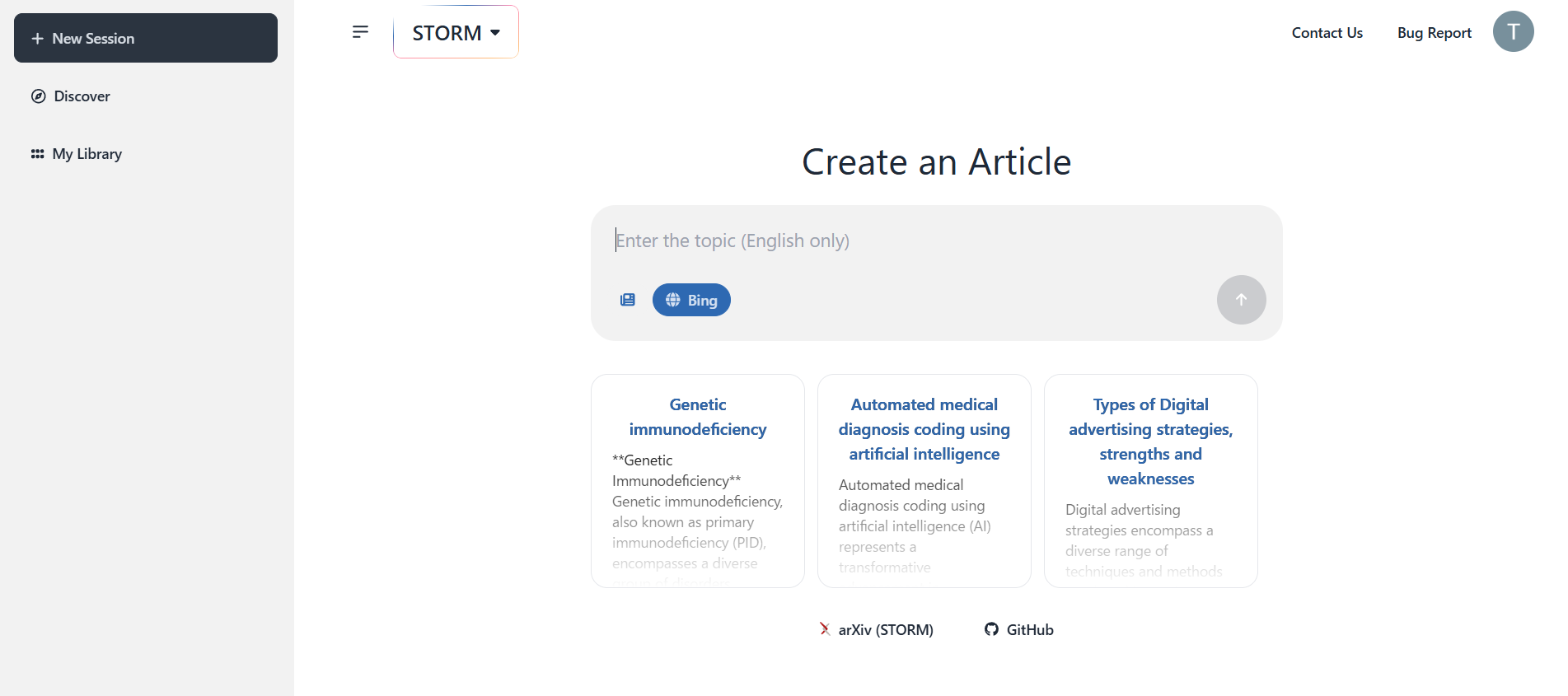
- 検索を通してwikipediaのような記事を作れるサービス
- 現在、英語のみ対応の様子
STORM is now powered by Bing Search and Azure OpenAI GPT-4o-mini!
- Bing検索とGPT-4o-miniが使われているようです
「Please research and summarize generative AI services.」と入力してみました。
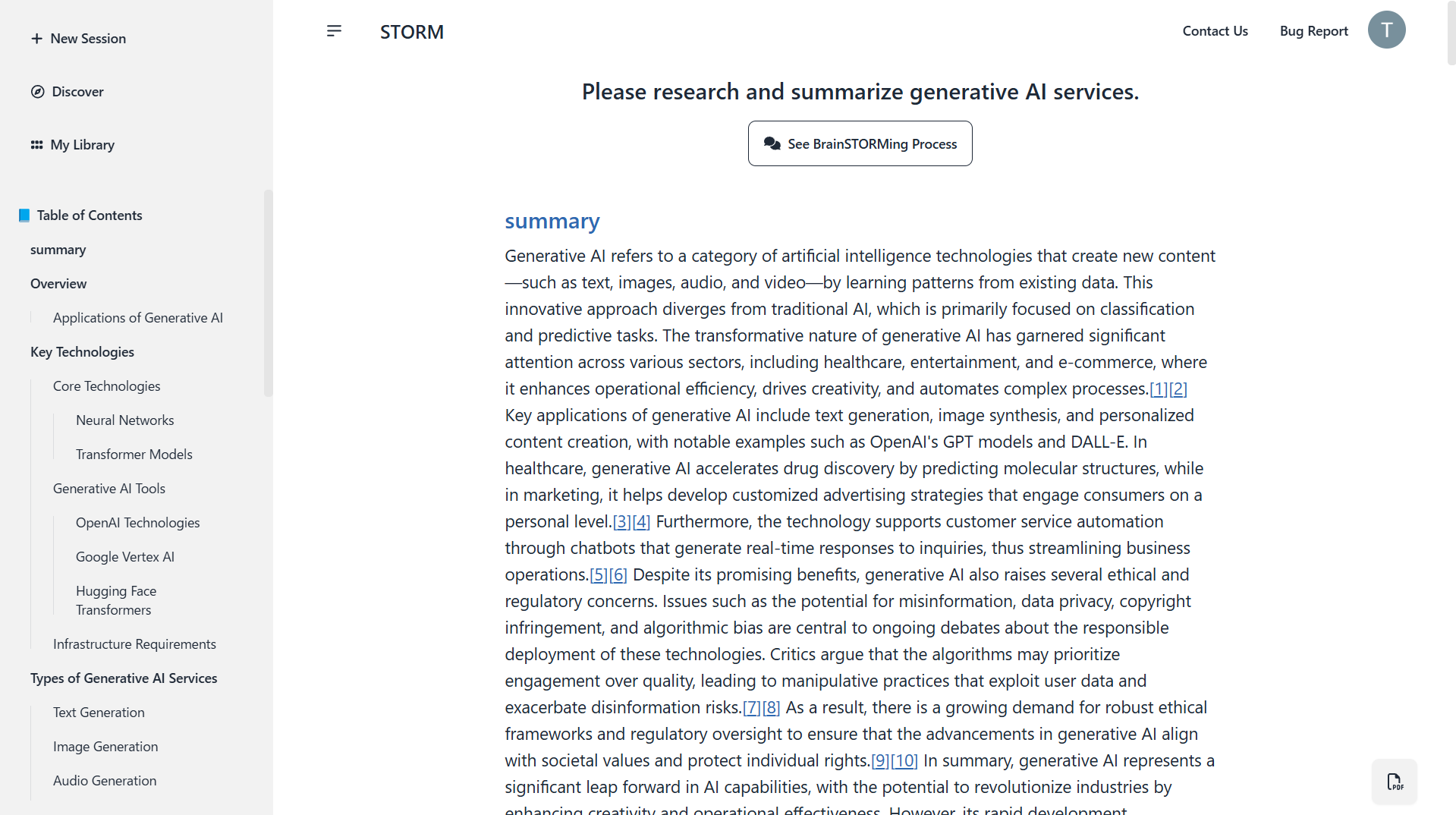
- wikipediaっぽい記事ができました
資料作成
Napkin AI: 図作成
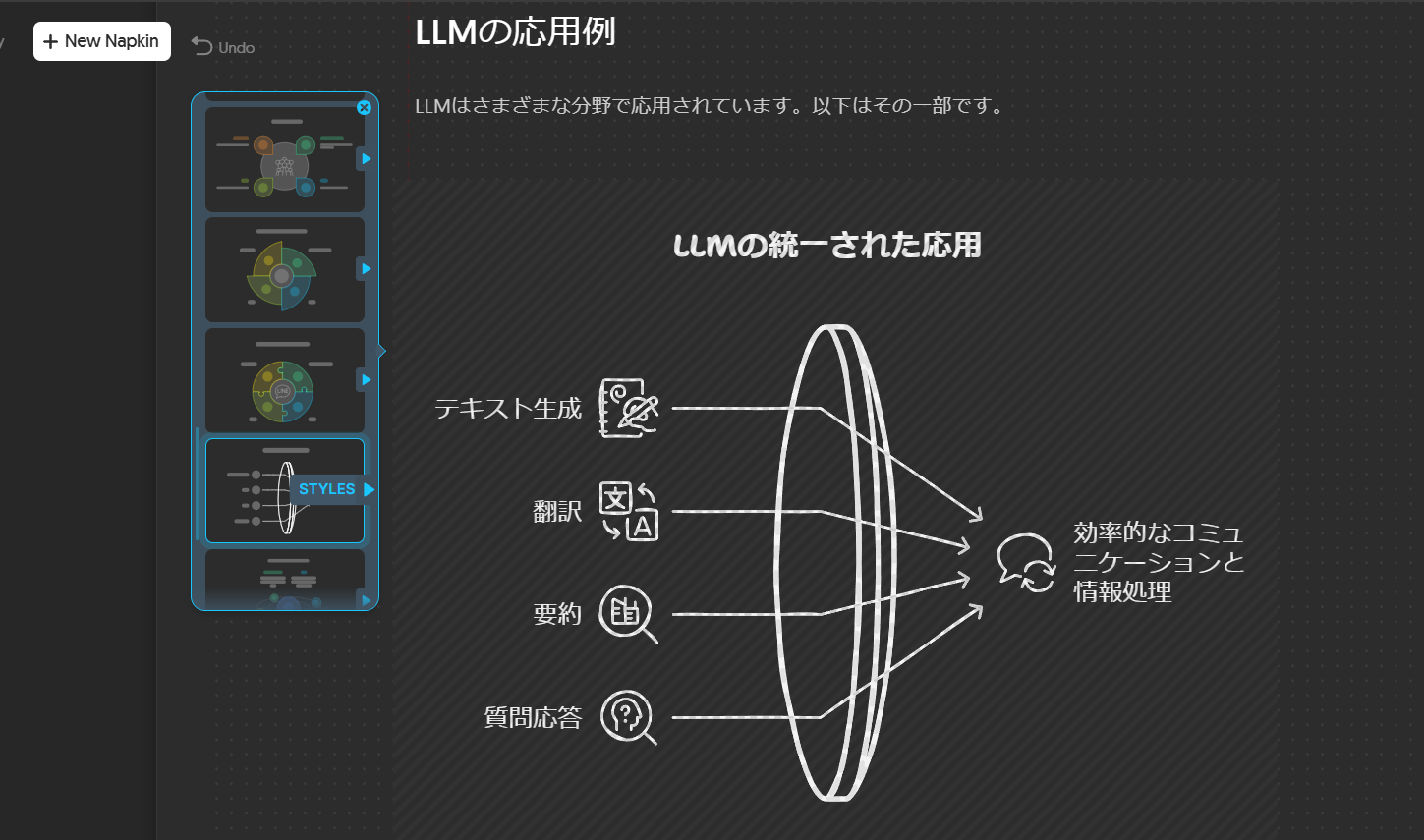
Napkin AIは、資料の図作成のサービスです。
- 「自分で入力した文章」または「プロンプトから生成した文章」から図を選んで作ることができます
画像・動画・音楽生成
このセクションでは、メディアを生成できるサービスを紹介します。
動画生成というとOpenAIのSORAが有名かもしれませんが、有料ユーザーだけが使える機能のため、ここでは紹介しません。
Labs.google/fx
Labs.google/fxは、Googleのサービス。

-
ImageFX: 画像生成
- 「cream colored java sparrow」と入力してみました

- Imagen3が使われているみたい
- Googleアカウントがあれば無料で画像生成を試すことができます
- 「cream colored java sparrow」と入力してみました
-
VideoFX: 動画生成
- Veo 2が使われているみたい
- 2025年1月現在、順番待ちのためすぐに利用することはできませんでした
-
MusicFX: 音楽生成
- 「japanese rock」と入力してみました
- 30秒の曲が2つ生成されました
- 「japanese rock」と入力してみました
-
Whisk: 画像から画像生成
- 画像入力して画像を生成するサービスのようです
- 「Whisk is not available in your country yet」ということでまだ使えませんでした
Hailuo AI: 動画生成
Hailuo AIは中国のAI企業MiniMaxの動画生成サービスです。
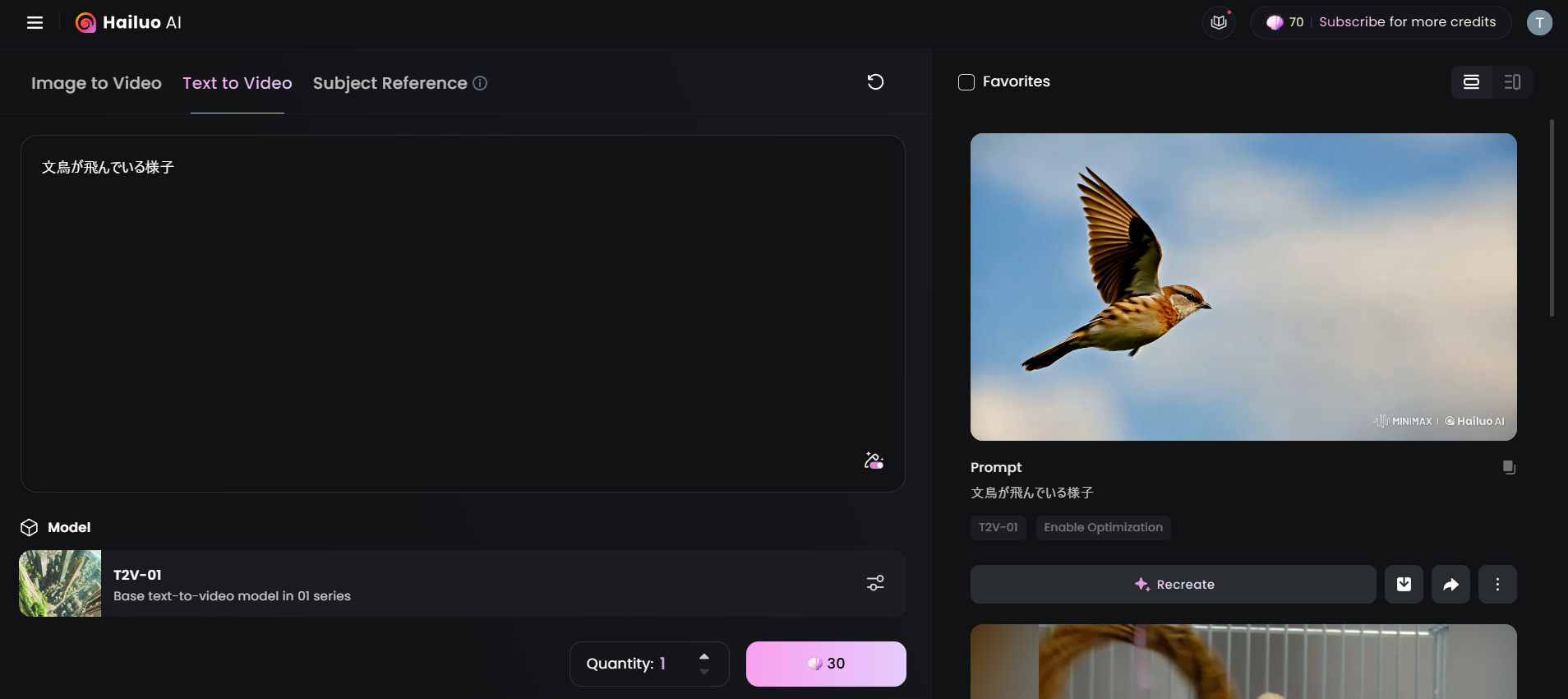
長く待ち時間が発生するケースもありましたが、以下の通り、無事生成できました。
-
Text to Video
- 「文鳥が飛んでいる様子」と入力したら、文鳥っぽくない鳥が生成されました

- 「文鳥が飛んでいる様子」と入力したら、文鳥っぽくない鳥が生成されました
-
Image to Video
- 鳥かごの中で正面向いた文鳥の画像と「鳥かごの中にいる文鳥がこちらに向かって飛んできた」を入力したところ、実在しない背中の配色の文鳥が動いてくれました

- 鳥かごの中で正面向いた文鳥の画像と「鳥かごの中にいる文鳥がこちらに向かって飛んできた」を入力したところ、実在しない背中の配色の文鳥が動いてくれました
gif画像へ変換した際に圧縮したため画質が悪いですが、実際はきれいな動画が生成されました。
単純な入力で、想像以上に自然な動画が生成されました。
プロンプトをしっかりすれば色など細かいところもコントロールできるはずです。
KLING AI: 動画生成
KLING AIは中国の企業「快手(Kuaishou)」の動画生成サービスです。
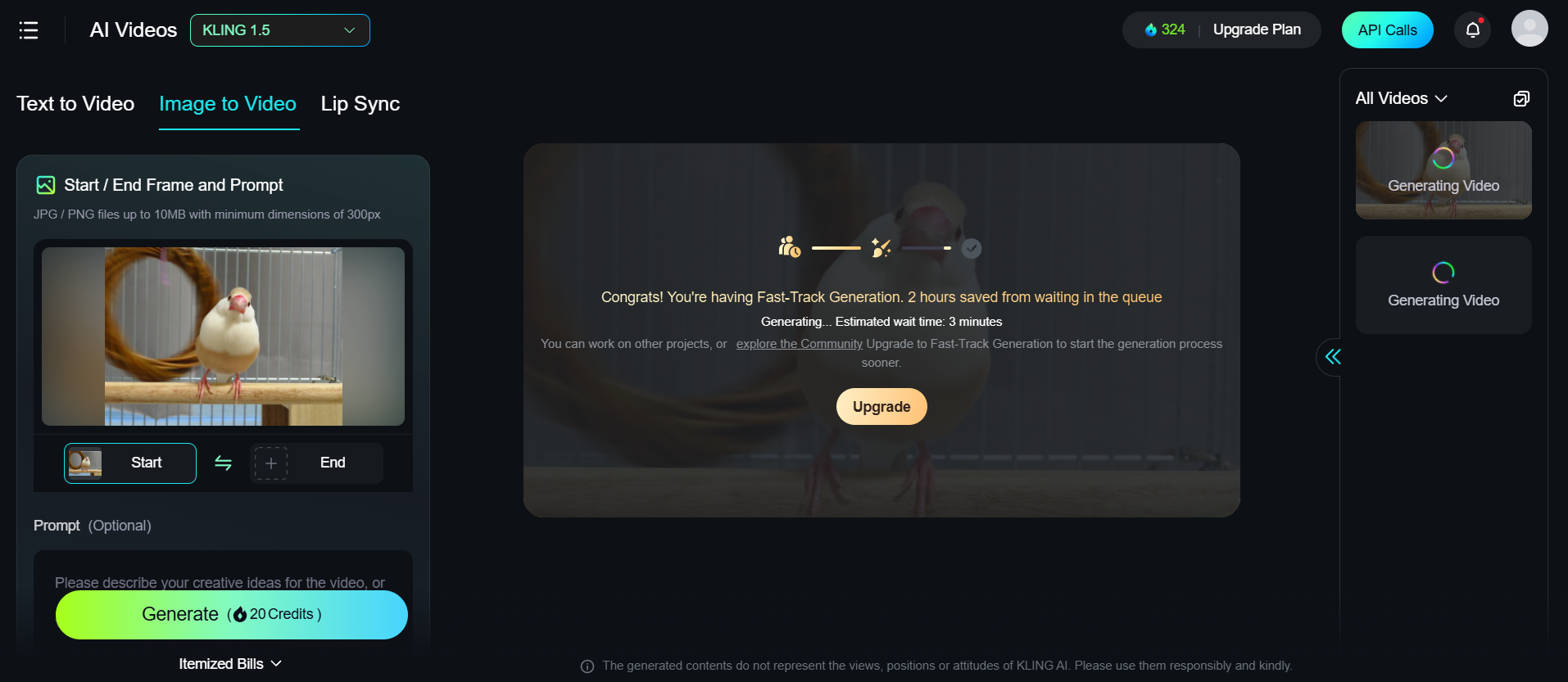
- Text To Image
- 「cream colored java sparrow」

- 「cream colored java sparrow」
- Text to Video
- 「flying java sparrow」と入力してみました

- 文鳥っぽくない鳥が羽ばたいています
- 「flying java sparrow」と入力してみました
- Image to Video
- 画像のみを入力してみました

- 背後に謎の動きがありますが、自然に動いています
- 画像のみを入力してみました
「動画とテキスト」または「動画と音声ファイル」を入力して、人の口の動きを入力されたテキスト/音声に合うように口を動かす「Lip Sync」もありました。
Stable Audio: 音楽生成
Stable Audioは、Stability AIの音楽生成サービスです。
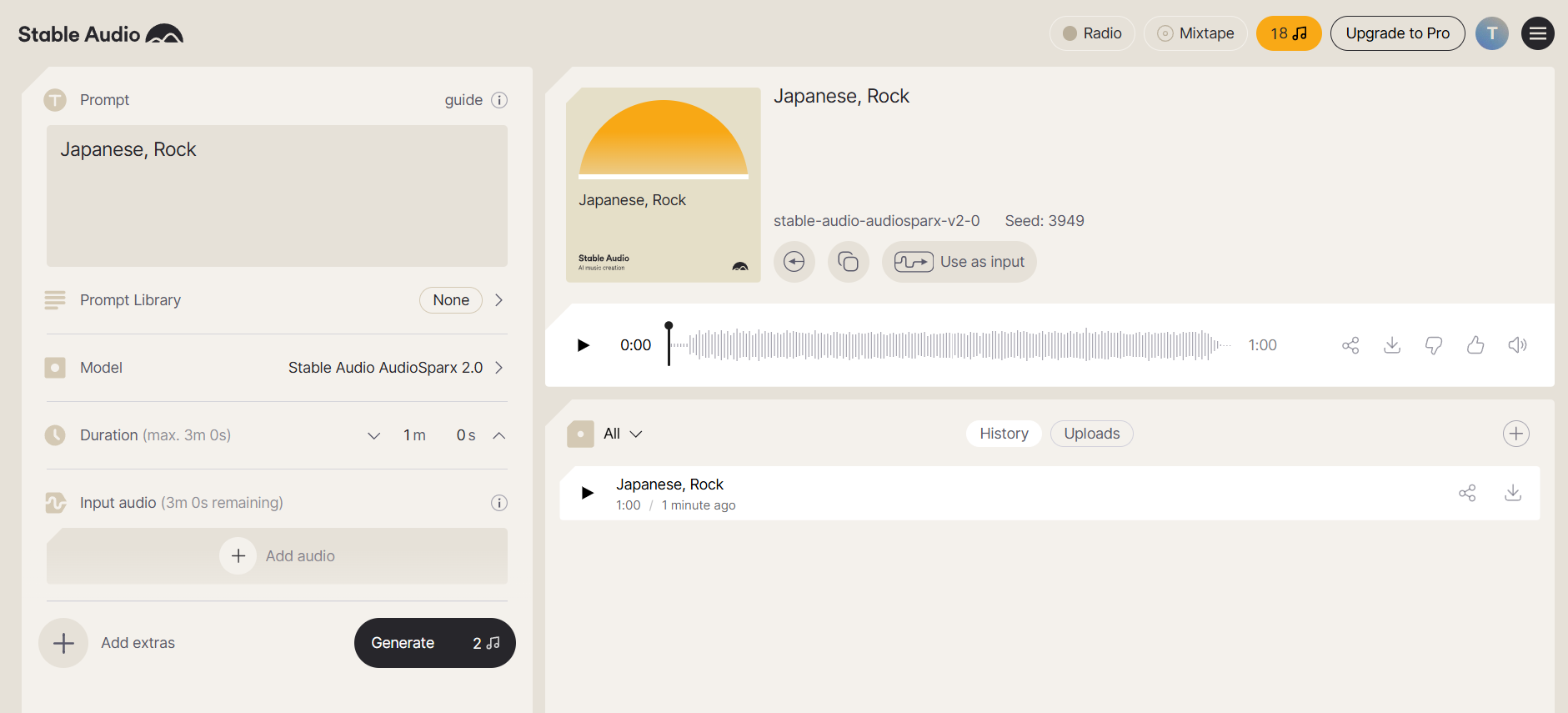
「Japanese Rock」と入力したところ、それっぽい自然な曲が生成されました。
Qiitaに音声を載せられないので、ご自身で試してみてください。
Luma AI: 動画生成
Luma AIはアメリカ・サンフランシスコの企業で、動画生成、3Dモデル生成サービスを提供しています。
-
Dream Machine: 動画生成
- 「Make a video of flying night heron」と入力してみると2つの動画が生成されました


- 入力通り、ゴイサギ(night heron)が飛んでます
- 数時間の待ち時間がありました
- 「Make a video of flying night heron」と入力してみると2つの動画が生成されました
-
Genie: Text to 3Dモデル
- 「java sparrow」と入力してみました
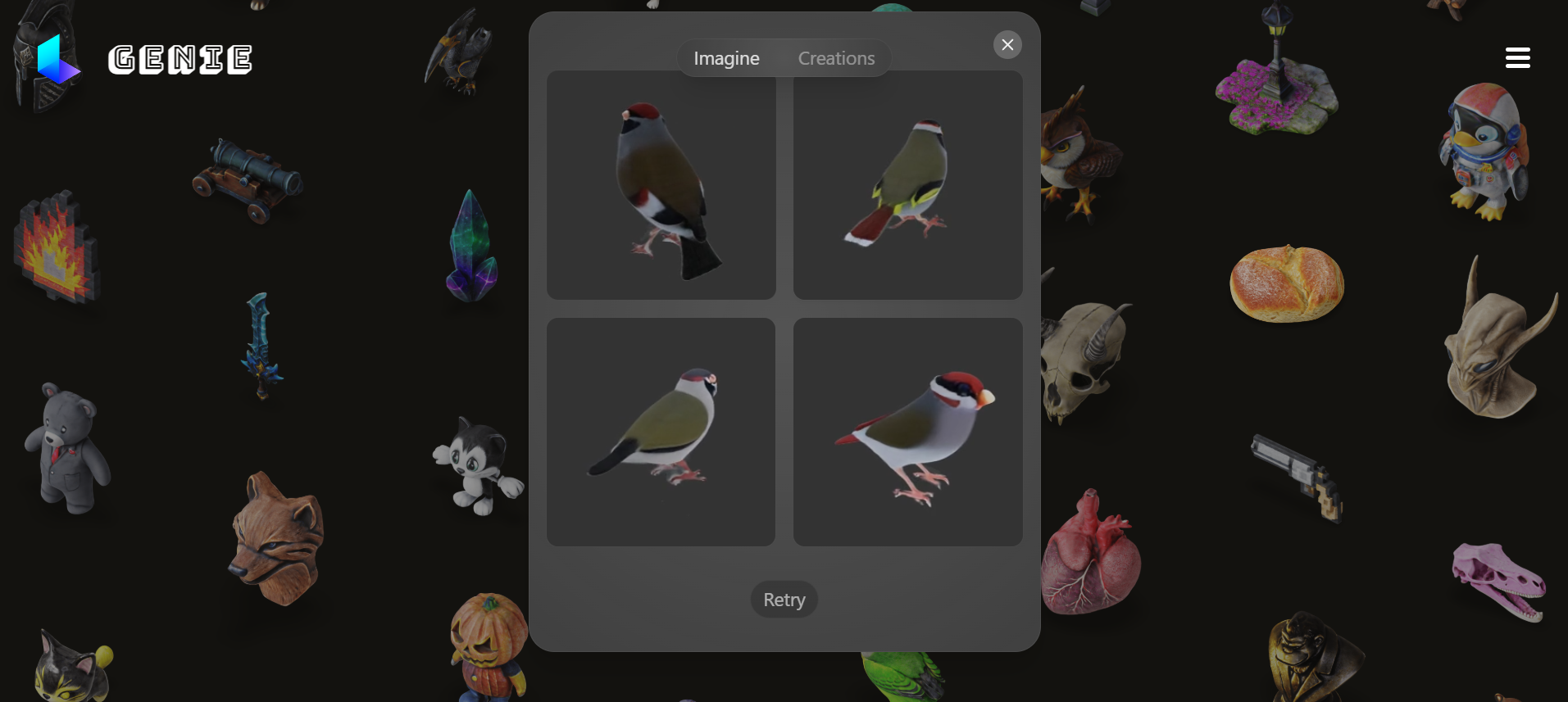
- 「java sparrow」と入力してみました
画像から3Dモデルを作成できるアプリLuma AI: 3D Captureもあるようです。
HeyGen: AIアバター、リップシンク
HeyGenは、AIアバター動画の作成サービスです。
人の顔が写った画像をアップまたは生成して、口を動かすことができます。
今回はもともとテンプレートとして存在しているアバターを選んで、日本語を話させてみました。
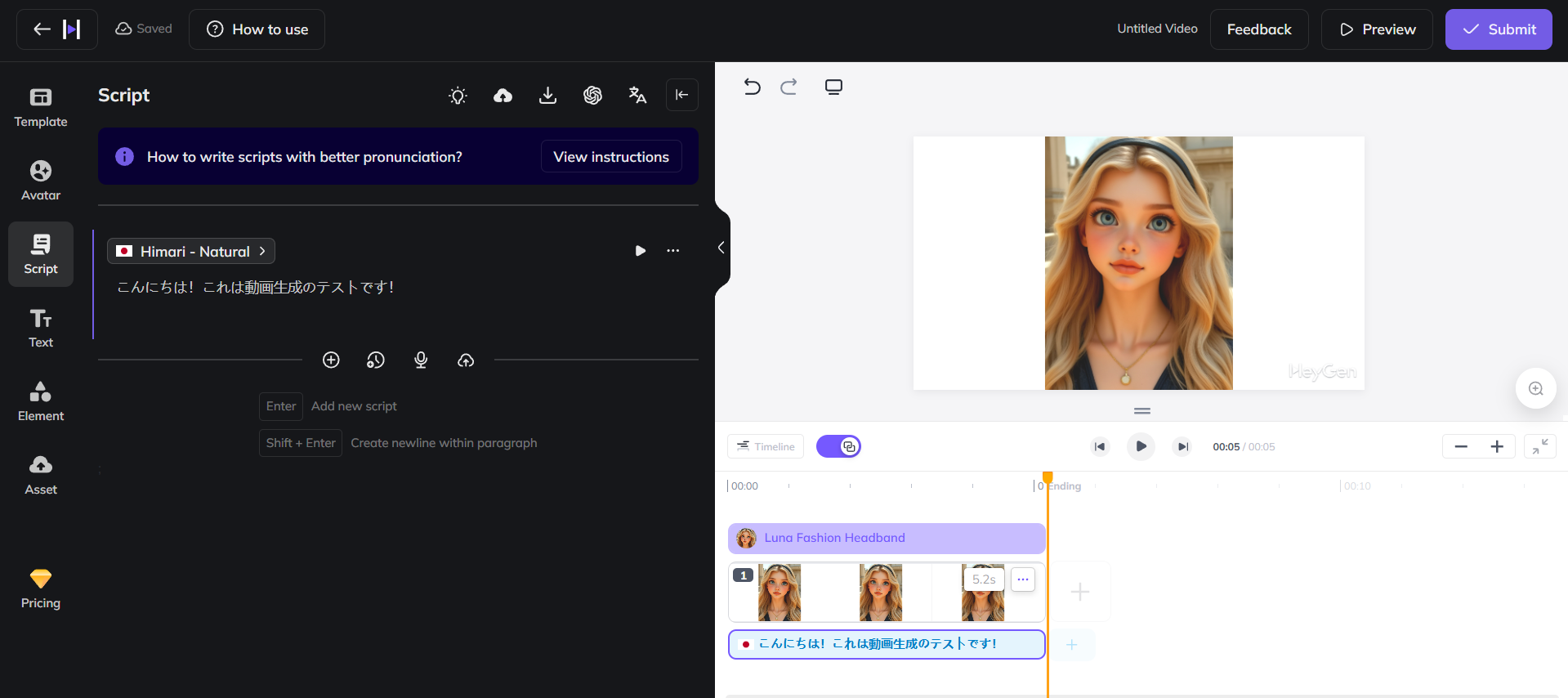
話す内容を文字で書くと、音声合成されました。
1枚の画像とテキストから人が話しているような動画を生成できました。

Qiita上に音声を載せられないので共有リンクをおいておきます。
リップシンクの技術はオープンソースのものがいくつかありますが、私の環境ではどこかしらでエラーが出て、どれもうまく動かすことができませんでした。GoogleColabでも難しかったです。
- オープンソース
- 一般公開されていない
Stable Diffusion: 画像生成
Stable Diffusionは、テキストから画像を生成できる技術です。
オンラインでデモを試すことができます。
-
Stable Diffusion 2.1 Demo
-
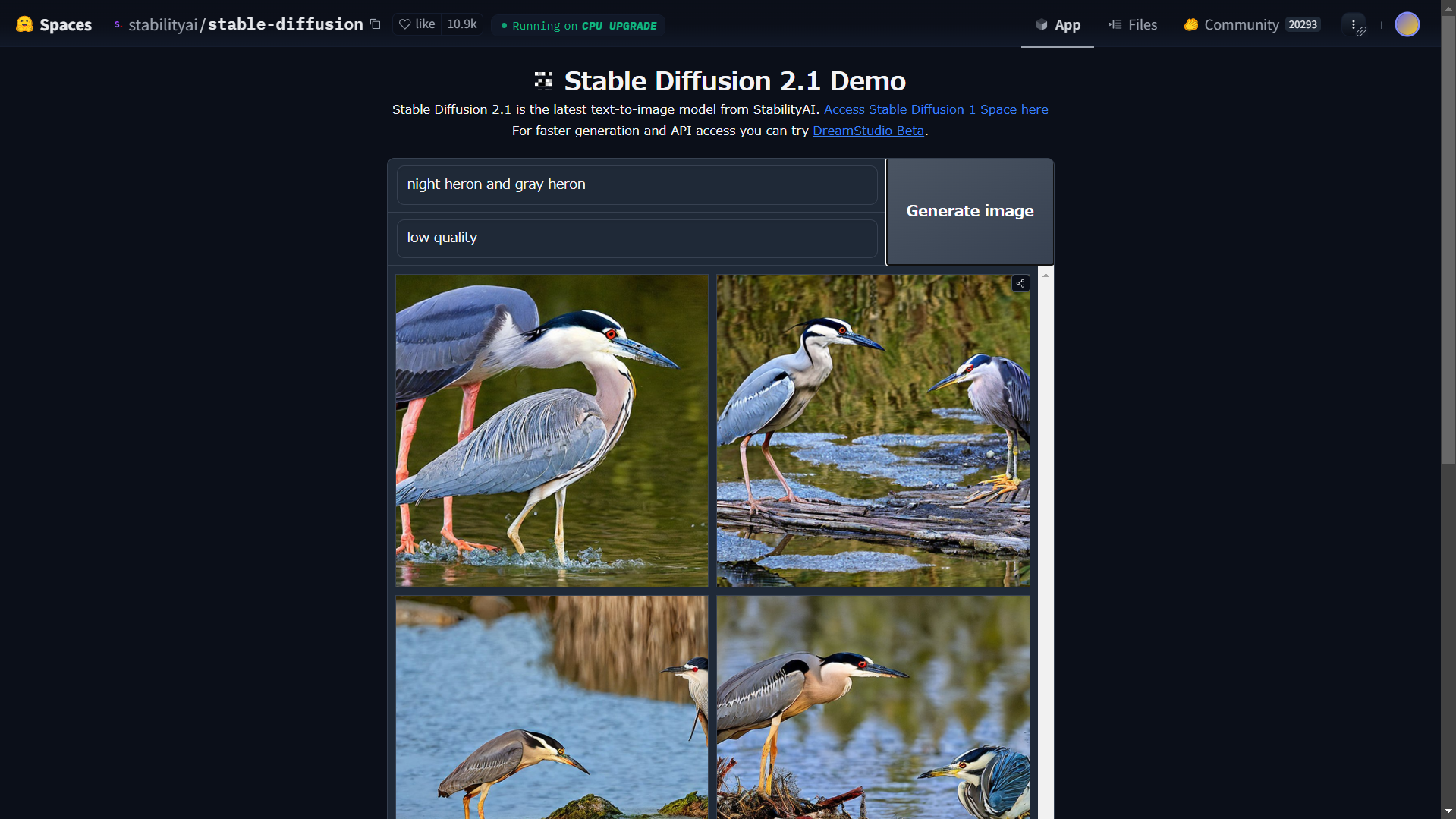
- prompt: night heron and gray heron
- negative prompt: low quality
-
-
Stable Diffusion オンライン
- prompt: flying java sparrow
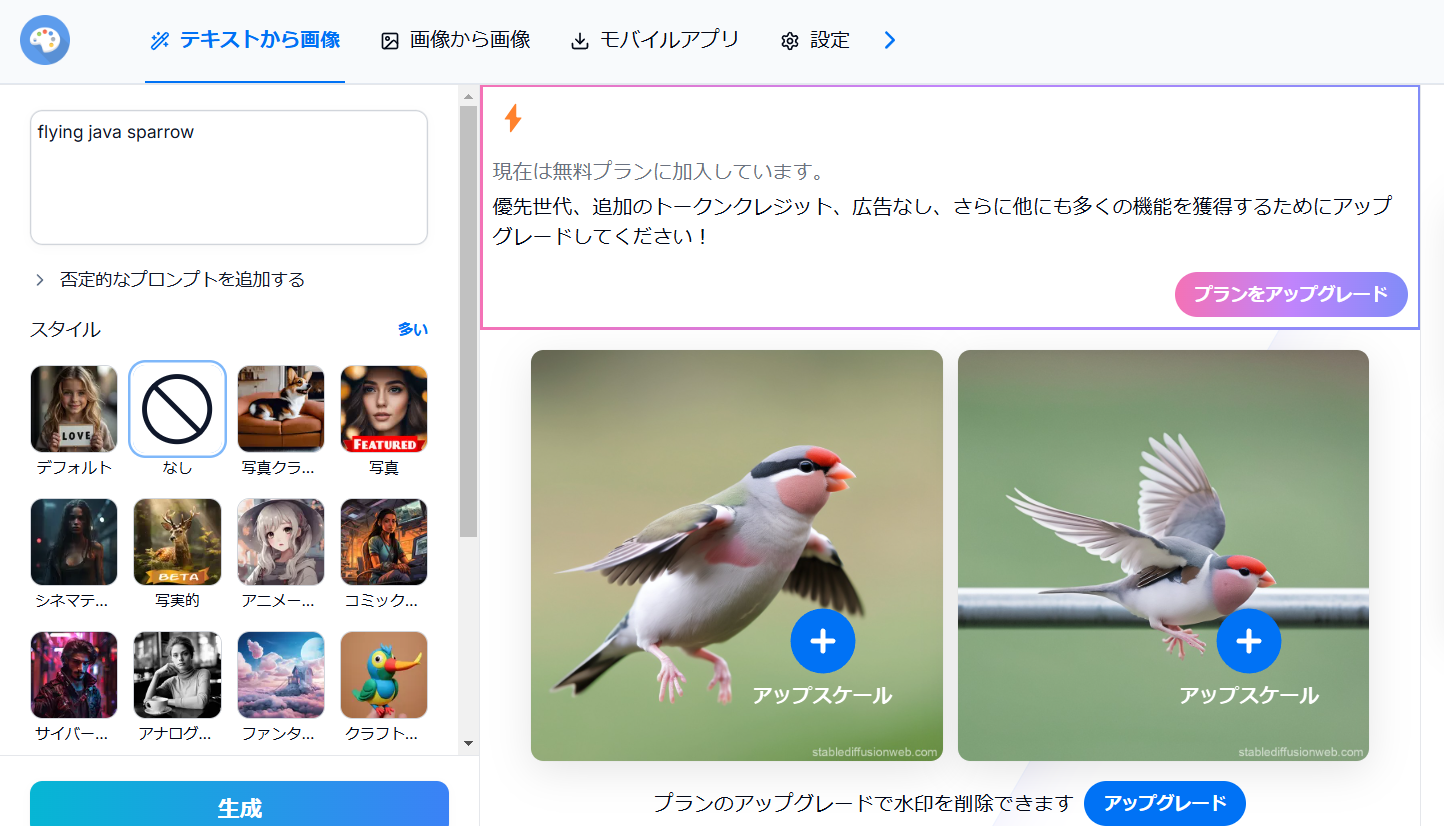
- prompt: flying java sparrow
promptには生成したい内容を英語で列挙し、negative promptには生成したくない内容を英語で列挙します。
オフラインで試すにはStable Diffusion web UIがオススメです。
環境構築
-
python3.10.11: python3.10系じゃないとエラーが出ます -
webui-user.batを実行すると自動的に環境構築されます- (実行エラー出る場合
chmod 744 ./webui-user.batが必要かも) - CPU上で実行するには
webui-user.batを以下のように書き換える必要がありますwebui-user.batのCPU向け設定@echo off set PYTHON= set GIT= set VENV_DIR= set COMMANDLINE_ARGS=--skip-torch-cuda-test --no-half call webui.bat
- (実行エラー出る場合
- モデルのダウンロード
- huggingfaceやCivitaiからダウンロード可能
- DLしたモデル本体は
models/Stable-diffusion/に配置
- 実行
- model: stable-diffusion-v1-5

- model: 7th_anime_v3

- CPU環境では1枚7分くらい
- model: stable-diffusion-v1-5
ちなみに、CPUで遅いからと言ってGoogleColab無料枠で実行してはいけません。利用規約に違反するようです。
特定のキャラやシーンの生成
Civitaiでは、モデル本体の他に、特定のキャラクターやポーズ、シーン指定が可能なLoRAモデルもダウンロードできます。
また、他の人が生成した画像のプロンプトを見ることができ、うまい画像生成のプロンプト勉強になります。
ダウンロードしたLoRAをmodels/Loraに配置し、読み込んでクリックするとプロンプトに追加され使用できますが、Civitaiには著作権を無視したようなキャラクターのLoRAや学習データが不明のLoRAなども含まれているので、ここでは利用せず、image to imageのsketchを使った方法を紹介します。
img2imgタブのSketchから、真っ白な画像をアップロード後、ラフな図を書いて構図を指定してみました。
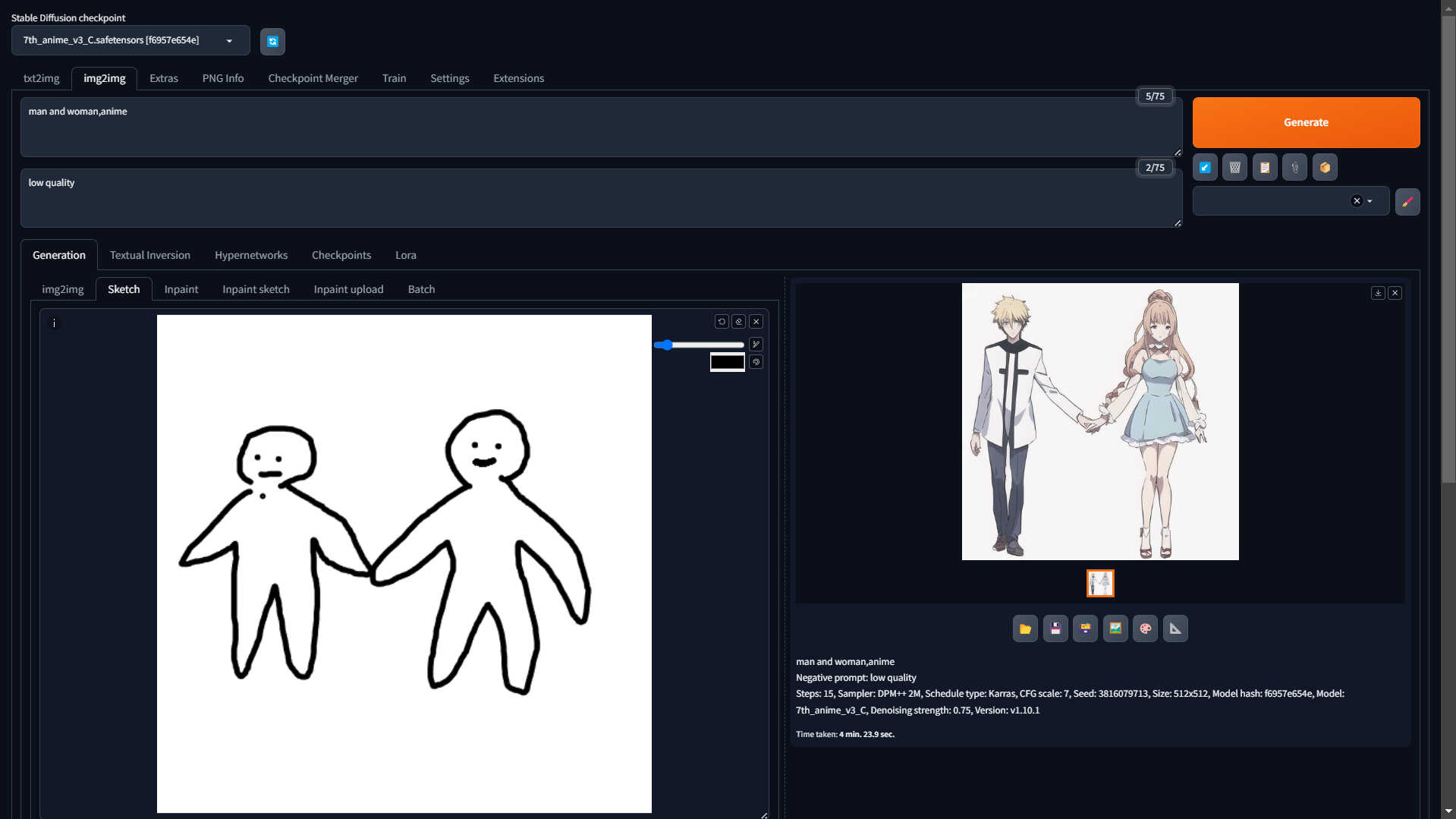
このように、ラフスケッチとプロンプトから画像を生成できます。
色を変えて指定することもできます。
他にも、さまざまな機能が提供されています。
-
img2img: 既存の画像をもとに新しい画像を生成- 元画像の形状や内容を維持しつつ、指定したプロンプトに基づいて画像を変化
- 画像のスタイル変更やイラスト風画像への変換などに使用
-
Sketch: 手描きの線画やラフスケッチを基にした画像生成(今回の例)- ユーザーが描いたラフなスケッチを入力として、指定したプロンプトに応じて詳細な画像を生成
- 線画からリアルなイラストや写真風画像を作成する場合に便利
-
Inpaint: 画像の一部を修正・再生成する機能- 指定した領域だけをプロンプトに基づいて再生成
- 画像内の不要な部分を消したり、修正したい箇所を変える場合に利用
-
Inpaint Sketch: スケッチとInpaintを組み合わせた機能- 修正したい領域をマスクで指定した後、その領域にスケッチ(線画)を描いて新しい内容を生成
- マスク領域に細かい指示を入れることで、より意図に合った画像生成が可能
LoRAを自作する方法については、次の記事が参考になります。
学習は流石にCPUでは無理そうです。
FastSD CPU: CPU環境でも高速に
FastSD CPUはCPUでも高速に動くバージョンです。
- 環境構築:
install.batを実行 - 起動:
start-webui.bat実行後、http://127.0.0.1:7860/へアクセス - 生成してみる

- LCM-LoRA:
rupeshs/hypersd-sd1-5-1-step-lora- モデルは
Modelsタブで選択したものが自動的にダウンロードされます
- モデルは
- steps: 4
- 約20秒で生成できました
- LCM-LoRA:
stable diffusionの方はsteps=20だったので、こちらも20に合わせると、2分程度でした。
LoRAは、lora_models/に配置してUIを起動し直すと使用できます。
外部のモデル本体は、models/gguf/diffusionに置くことで、選択できるようになりましたが、私の環境ではエラーが出て実行できませんでした。
FLUX.1: 画像生成
FLUX.1は、Stable Diffusionの研究を行っていたBlack Forest Labsによって開発された画像生成技術です。
オンラインデモがあります。
オフラインではpinokioからflux-webuiをインストールすることで簡単に試せます。
なお、残りディスク容量が残り20GBくらいしかなかったので実行し切ることができませんでした。
OmniGen: 画像生成、画像編集
OmniGenは、テキストの指示で、様々な画像系のタスク実行できる技術です。レポジトリの説明を読むと凄さがわかります。
OmniGen: Unified Image Generation paper codeでお試しできます。
文鳥の画像をアップし、Change the bird in this image to black:<img><|image_1|></img>と命令してみました。
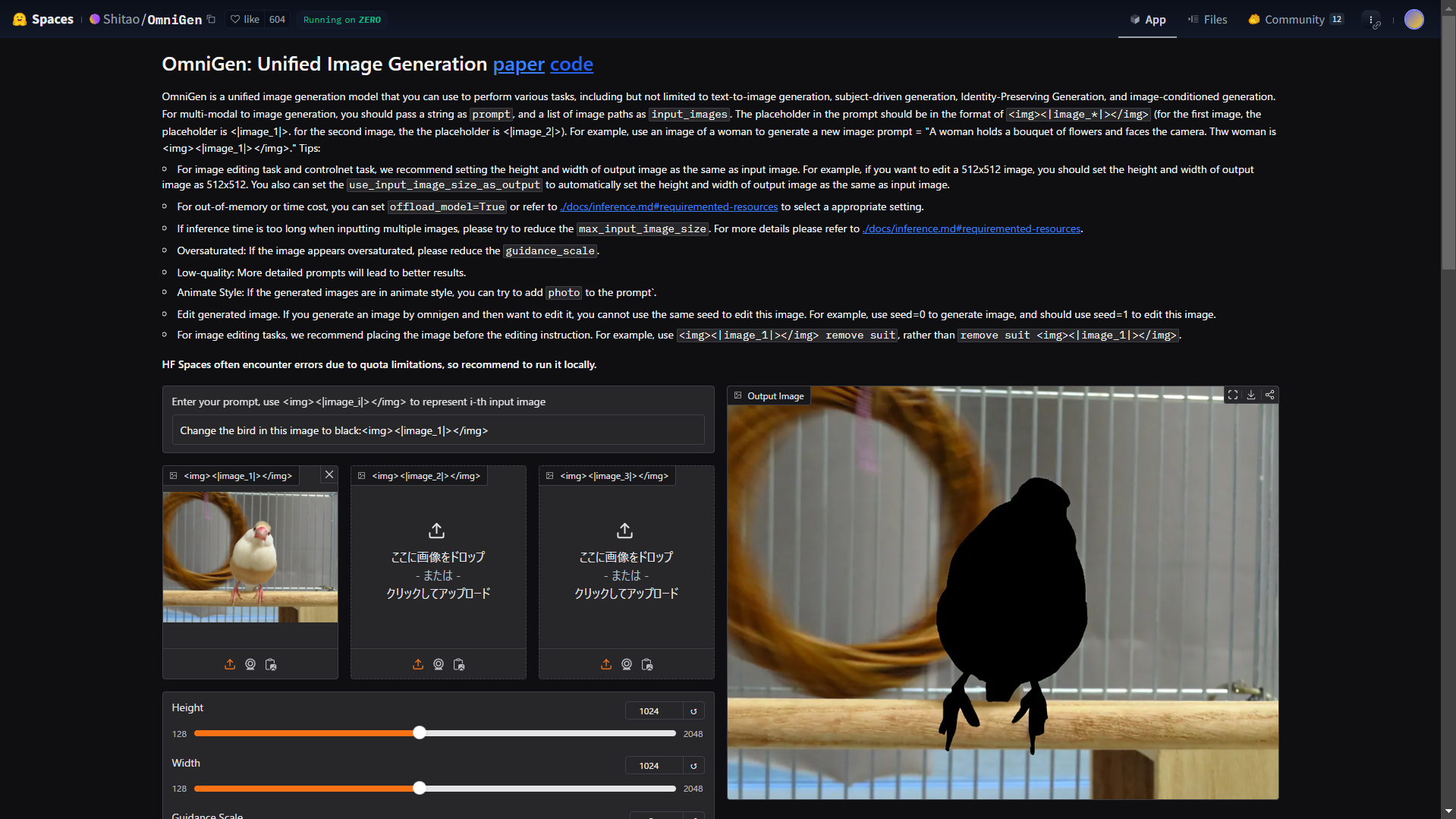
複数の画像を混ぜたような指示も可能で、驚きでした。
なお、複雑なタスクだとフリーのGPU上限に引っかかってErrorになります。
オフラインではpinokioからomnigenをインストールすることで試せますが、こちらもモデルが重いので容量やメモリに注意。
画像技術
Florence-2: 画像と言語をつなぐモデル
Florence-2は、Microsoftが開発したVLM(Vision-Language Model)です。
画像キャプション生成、物体検出、セグメンテーション、文字認識、ビジュアルグラウンディング(画像へのテキストクエリの応答)などができます。
Florence-2 Demoでお試しできます。
- キャプション生成
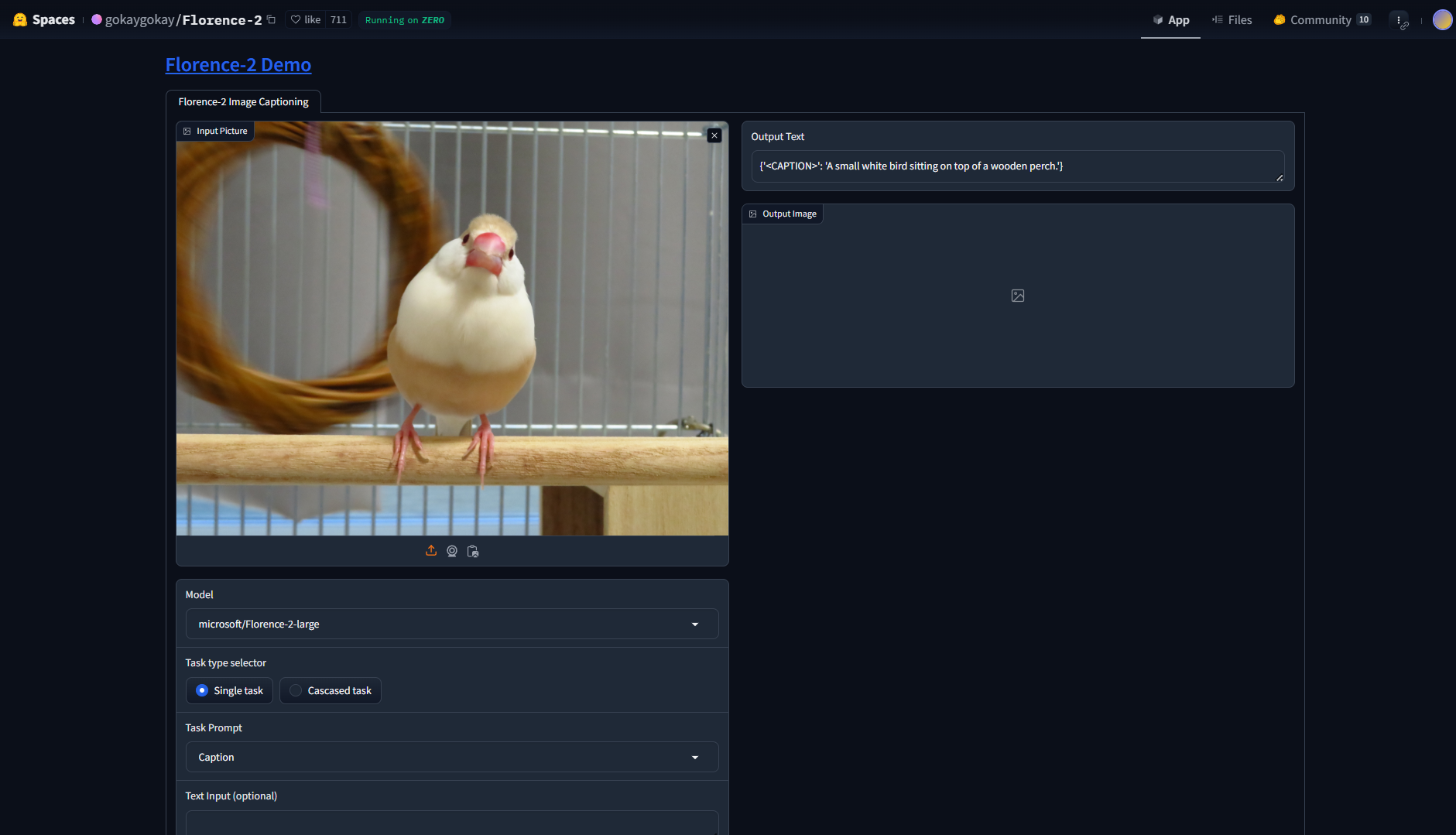
{'<CAPTION>': 'A small white bird sitting on top of a wooden perch.'} - 物体検出

- セグメンテーション

- クエリに基づいたセグメンテーション

-
The bird next to the big duck(大きいカモの隣にいる鳥)という少し意地悪なクエリを投げてみましたが、ちゃんと子どもの方のカモをセグメンテーションしてくれました
-
その他いろいろありました。
Face Fusion: 顔の入れ替え
Face Fusionは、顔を入れ替えできる技術です。
pinokioでいれることができました。
実在する人の顔をSwapするのは気が引けるので、Stable Diffusionで生成した2人を交換してみました。
Stable Diffusionの設定
model: rupeshs/hypersd-sd1-5-1-step-lora, step: 5
- 男性
- prompt: realistic,man,face,japanese,city,urban
- negative: low quality,anime,beard
- 女性
- prompt: realistic,woman,smile,japanese
- negative: low quality,anime
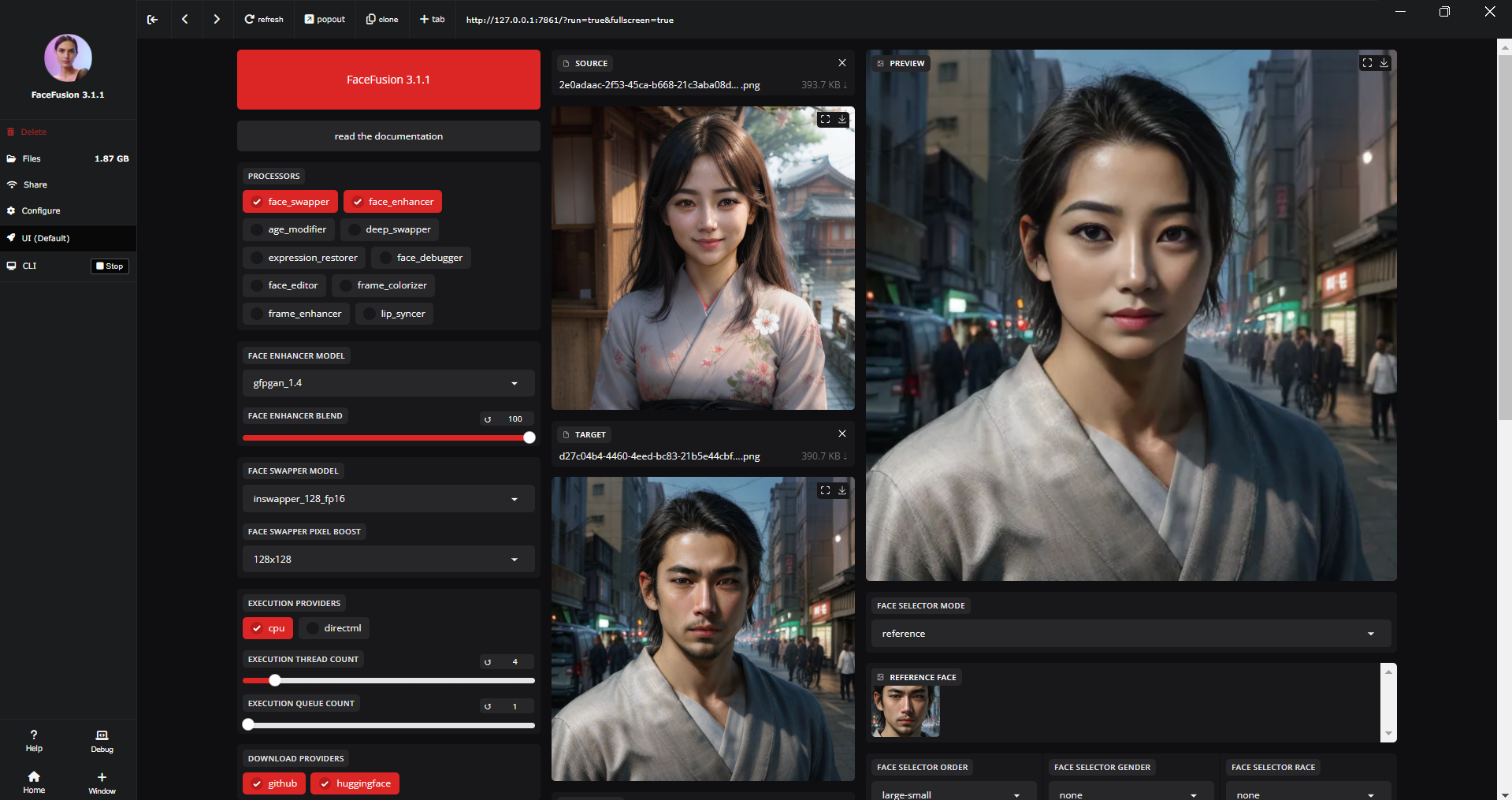
Targetの男性の顔が入れ替わっていることがわかります。
髪型や表情はTarget側の男性のままです。
なお、Face Editorを使うと顔の表情まで変えられました。
YOLO: 物体検出
YOLO(You Only Look Once)は、物体検出のアルゴリズムです。
pip install ultralytics
from ultralytics import YOLO
# モデル読み込み(自動でDLされる): https://docs.ultralytics.com/ja/models/yolo11/
model = YOLO("yolo11n.pt")
results = model("java_sparrow.JPG")
results[0].save(filename="yolo_result.jpg")
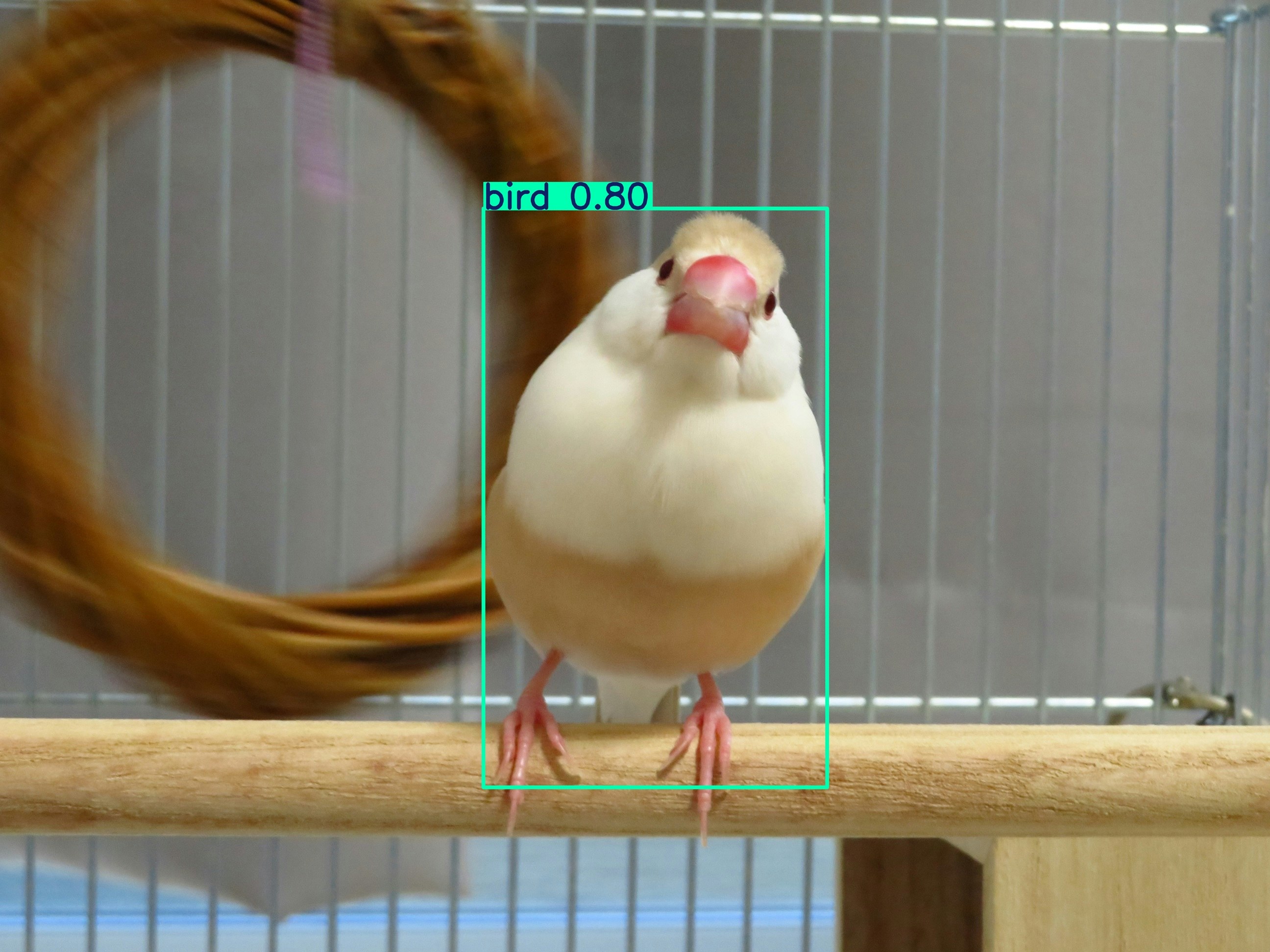
鳥を認識してくれました。オブジェクトが複数ある場合はすべて検知されます。
デフォルトで検出できるラベルはここに記載されています。
顔検知に特化したバージョンは、yolo-faceとしてforkレポジトリに存在していました。
README.mdに記載されているモデルをダウンロードしてソースコードと同じ階層に置くことで利用できます。
model = YOLO("yolov11n-face.pt")
独自のラベルを認識したい場合は、ファインチューニングをする必要があります。
YOLOのファインチューニングについては、 これらの記事が参考になります。
YOLOはバージョン/公開レポジトリによってライセンスが異なるため、しっかり確認しましょう。
SAM2: セグメンテーション
SAM2(Segment Anything Model 2)は、Metaが開発した何でもセグメンテーションできてしまうモデルです。
ultralyticsを使うと簡単にお試しできるようなので、ultralyticsを使ってみます。
pip install ultralytics
import cv2
from ultralytics import SAM
# モデル読み込み(自動でDLされる): https://docs.ultralytics.com/models/sam-2/
model = SAM("sam2.1_b.pt")
input_image = "java_sparrow.JPG"
# 矩形描画
cv2.imwrite("show_box.jpg", cv2.rectangle(cv2.imread(input_image), (1900, 800), (3400, 3500), color=(0, 255, 0), thickness=10))
# 矩形指定でセグメンテーション
box_results = model(input_image, bboxes=[1900, 800, 3400, 3500])
box_results[0].save("box_result.jpg")
# 点描画
cv2.imwrite("show_point.jpg", cv2.circle(cv2.imread(input_image), (2700, 2000), radius=25, color=(0, 255, 0), thickness=-1, lineType=cv2.LINE_8, shift=0))
# 点指定でセグメンテーション
point_results = model(input_image, points=[2700, 2000], labels=[1])
point_results[0].save("point_result.jpg")
矩形指定

矩形指定によるセグメンテーション結果

点指定

点指定によるセグメンテーション結果

鳥の足までセグメンテーションできているのすごい。
音声系
音声系の技術・ツールを紹介しますが、音声載せられないので画像でお楽しみください。
whisper: 書き起こし(Speech To Text)
whisperは、OpenAIの多言語対応した音声認識モデルです。
pipでライブラリをいれると、ローカルで実行できます。
pip install openai-whisper
from datetime import timedelta
import whisper
# Whisperモデルをロード (tiny, base, small, medium, large, turbo)
model = whisper.load_model("turbo")
# 音声ファイルの文字起こし(ここの処理が重い)
result = model.transcribe("input_file.mp3")
# 結果を表示
for segment in result["segments"]:
start = segment["start"]
end = segment["end"]
text = segment["text"]
sentence = f"[{timedelta(seconds=int(start))} - {timedelta(seconds=int(end))}] {text}"
print(sentence)

whisperでは、入力ファイルすべてを処理し終えてから結果がでます。
ファイルが大きいと時間がかかってしまいます。
faster-whisperを使うと、一定のセグメントごとに書き起こし結果が出力されます。
pip install faster-whisper
from datetime import timedelta
from faster_whisper import WhisperModel
# Whisperモデルをロード (e.g., tiny, base, small, medium, large, large-v2, turbo)
model = WhisperModel("turbo")
# 音声ファイルの文字起こし (generatorが返ってくるため、ここの処理自体は軽い)
segments, info = model.transcribe("input_file.mp3")
# 結果を表示
for segment in segments:
start = segment.start
end = segment.end
text = segment.text
sentence = f"[{timedelta(seconds=int(start))} - {timedelta(seconds=int(end))}] {text}"
print(sentence)
VoiceVox: 音声合成(Text To Speech)
VoiceVoxは、オープンソースの音声合成ソフトです。
インストールするとGUIで、誰でも簡単に様々なキャラクターでテキストを読むことができます。
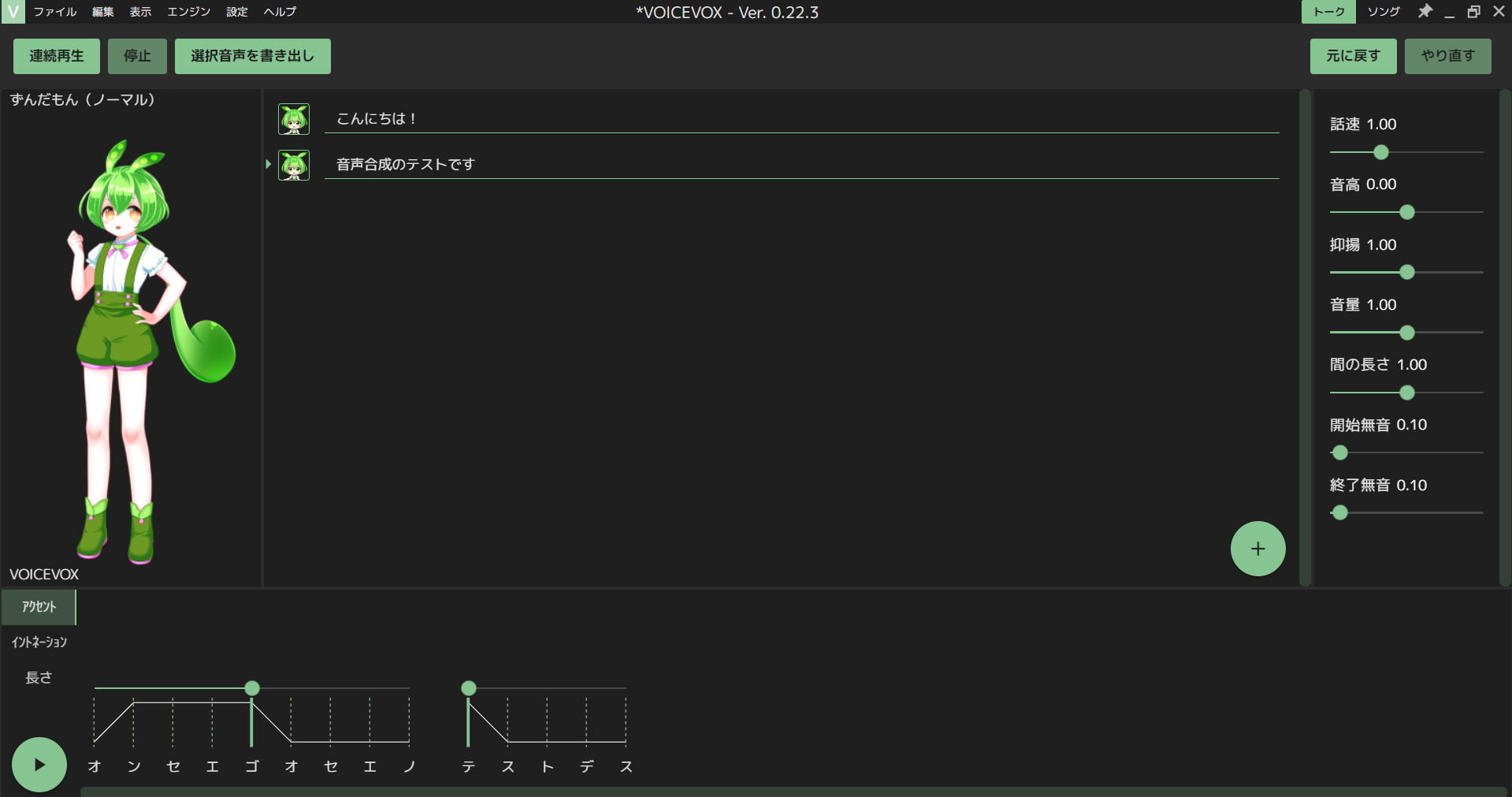
- YouTubeの合成音声でよく聞くずんだもんさん
アクセントやイントネーションの調整もできます。
COEIROINK: 音声合成(Text To Speech)
COEIROINKは、無料の音声合成ソフトです。
一般ユーザーが公開した声のモデルを利用できるのが特徴です。
声のモデルの作り方も記載されています。
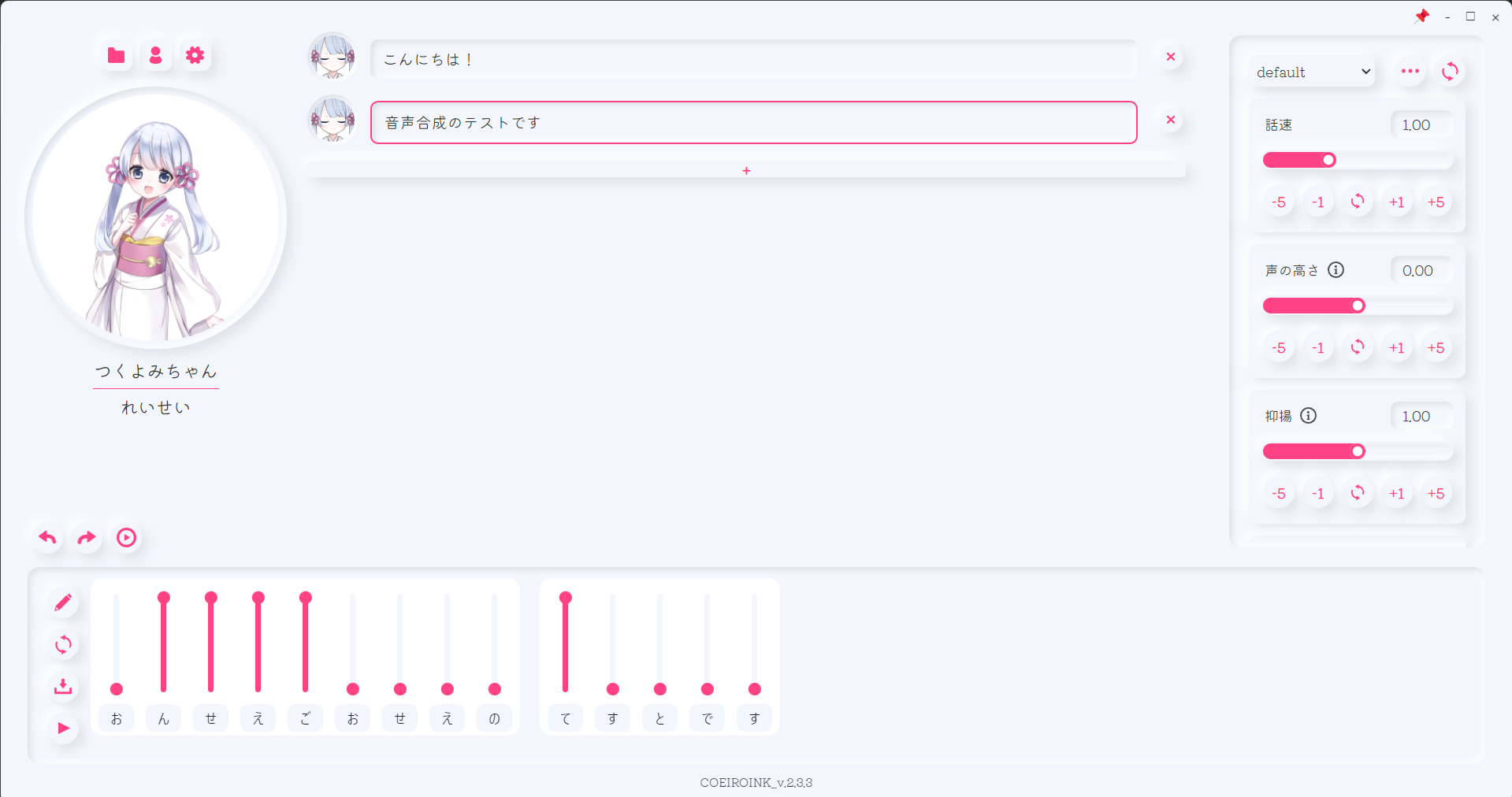
アクセントやイントネーションの調整もできます。
Style-Bert-VITS2: 音声合成(Text To Speech)
Style-Bert-VITS2は、感情豊かな音声合成ができるオープンソースモデル。
zipをDLして、batファイルを実行するだけで環境が整うので、簡単に利用することができます。
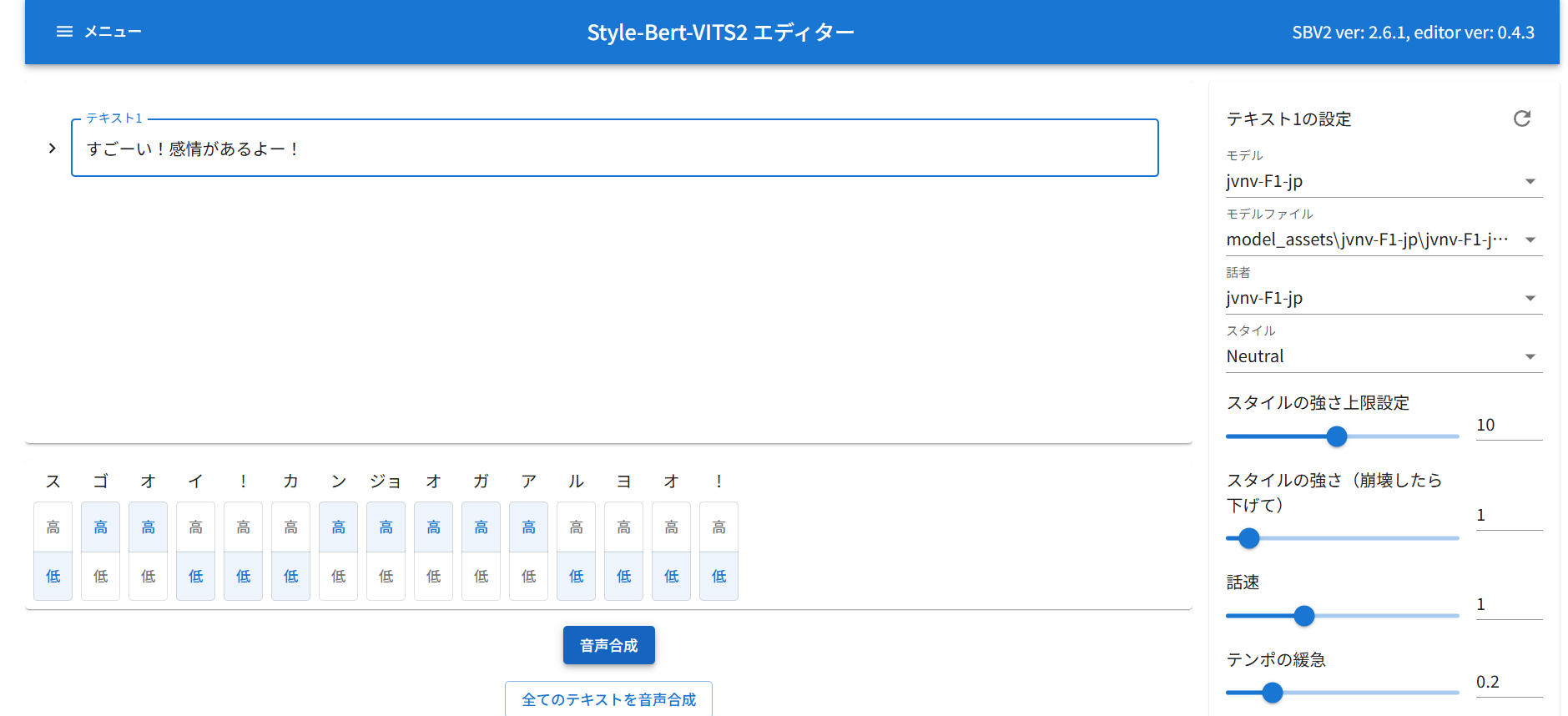
-
junv-**-jp系のモデルは感情が乗ったように聞こえました - モデルによっては平坦に聞こえました
にじボイス: 音声合成(Text To Speech)
にじボイスは、感情豊かな音声合成サービスです。
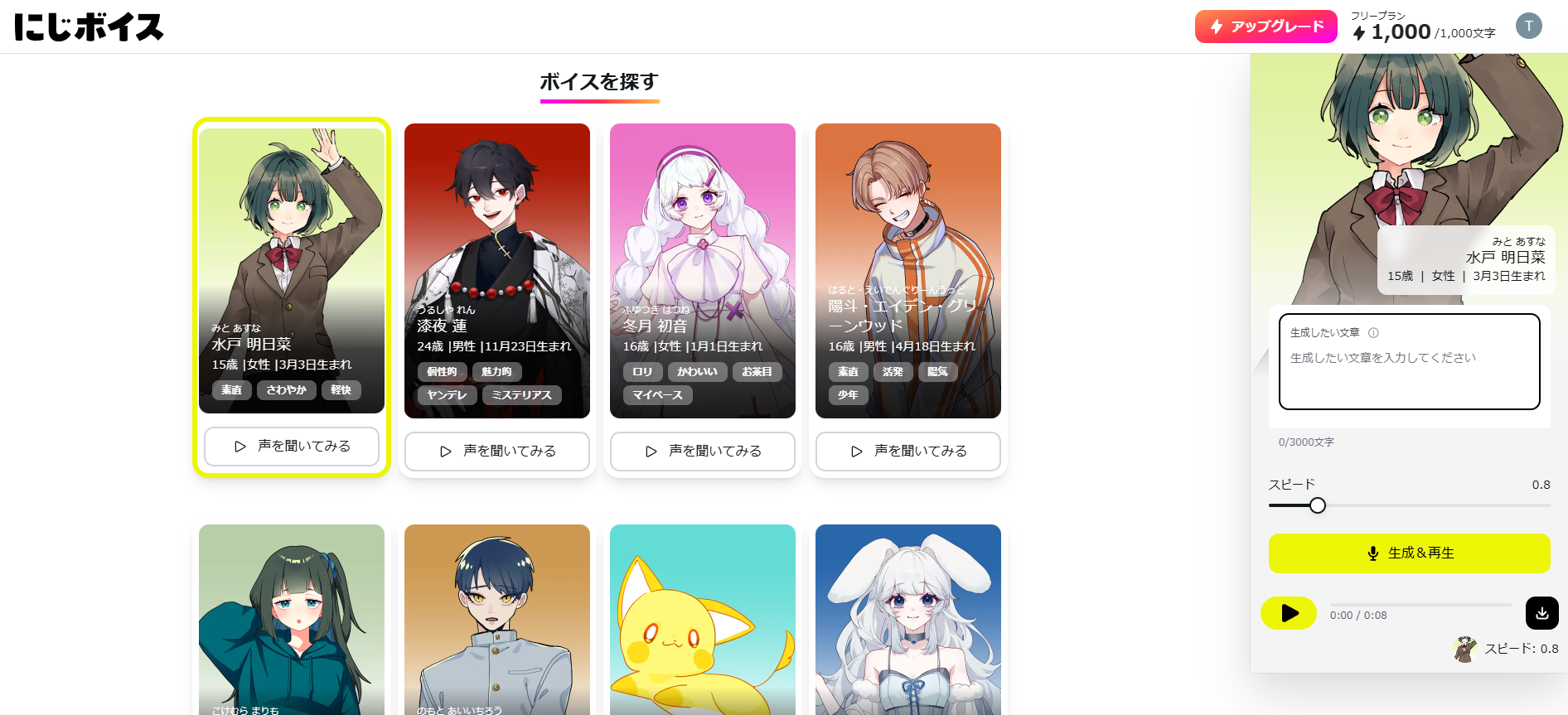
使ってみるとわかりますが、テキストを入れただけでかなりクオリティの高い音声が得られました。
RVC: 音声変換
RVC(Retrieval-based-Voice-Conversion)は、別の人の声に変換できる技術です。
Retrieval-based-Voice-Conversion-WebUI
Retrieval-based-Voice-Conversion-WebUIは、音声変換を気軽に試すことができるWebUIです。
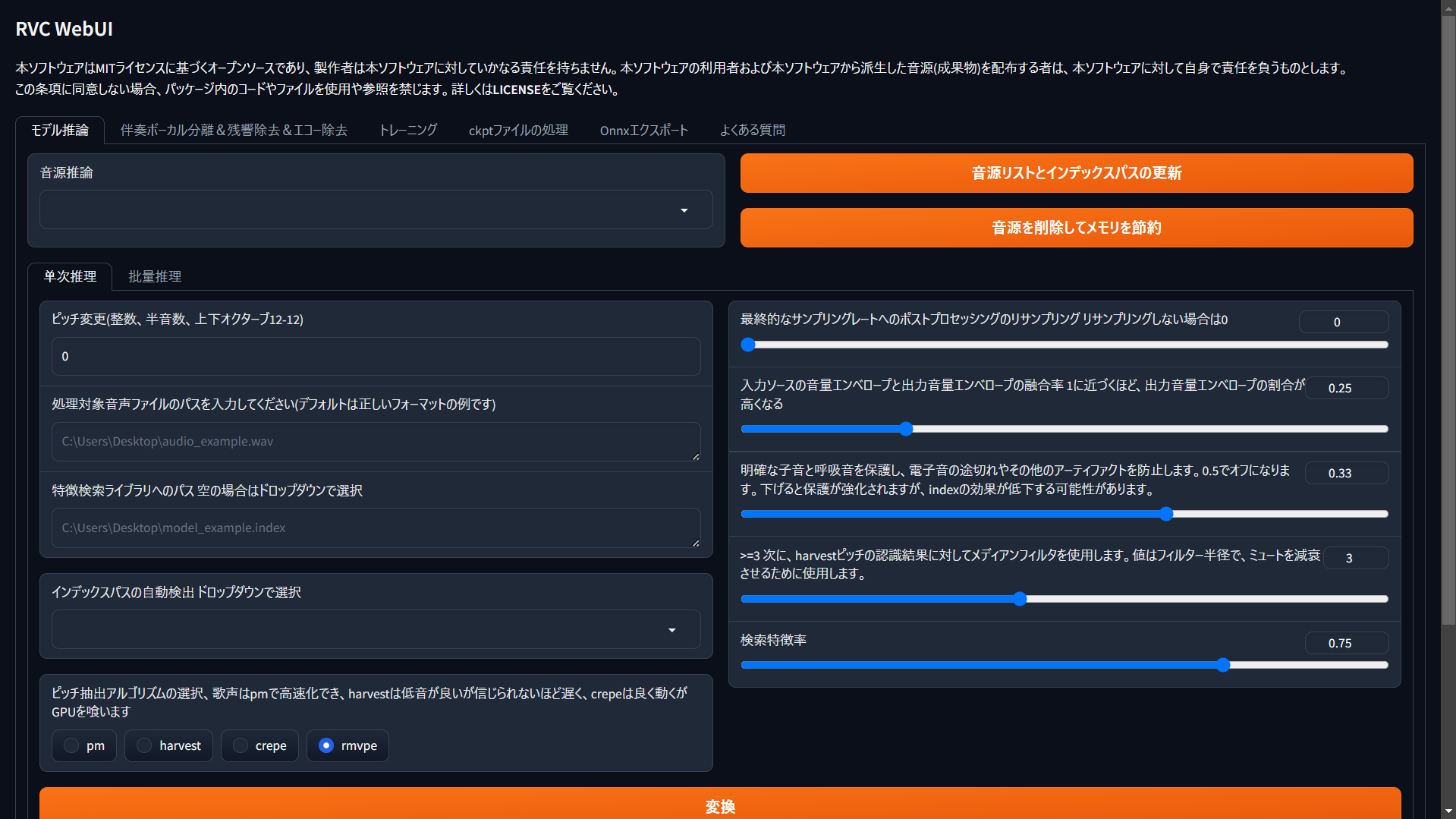
git clone git@github.com:RVC-Project/Retrieval-based-Voice-Conversion-WebUI.git
cd Retrieval-based-Voice-Conversion-WebUI
poetry install
poetry run python tools/download_models.py
poetry run python infer-web.py
- RVC学習済みモデル(
*.pth)をDLして、assets/weights/に配置する- 学習済みモデルはBOOTHなどで公開されています
- 「音源リストとインデックスパスの更新」を押して配置したモデルを選ぶ
- 「処理対象音声ファイルのパスを入力してください」に変換したい音声ファイルを設定
- 「変換」を押す

- しばらくすると変換結果が出力されます
VCClient: リアルタイム変換
VCClientは、RVCでリアルタイム音声変換ができるソフトウェアです。
-
ここから
vcclient_win_std_2.0.61-alpha.zipをダウンロード(CPUの場合) -
start_https.batまたはstart_http.batを実行

- デフォルトでモデルが入っています
- 「編集」から任意のRVCのモデルを追加できます
- 「入力」「出力」デバイスを設定したら、「スタート」を押すとリアルタイムで変換した声を聞けます
Webアプリ作成
v0
v0は、Vercel社が提供しているWebサイトやアプリのUIを作れるサービスです。
「2人で五目並べをするwebアプリを作って」と入力したら、ソースコードと実際の動作プレビューが実行されました。
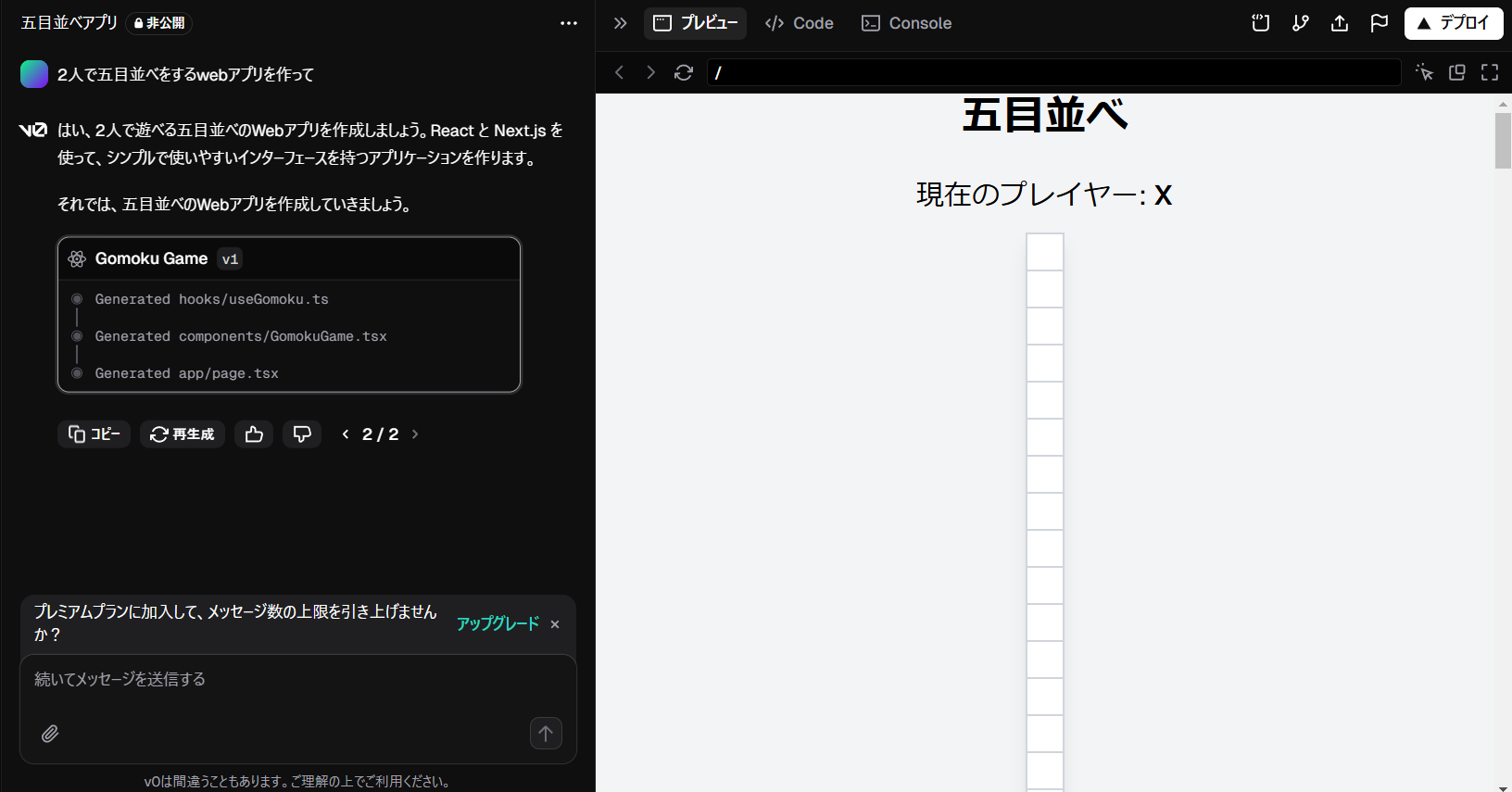
なぜか縦長の盤面だったので、「盤面を縦長ではなく、30x30のマスにしてください。」と指示してみます。
依然として縦長だったので再び「縦に並んでしまっています。正方形状に配置してください。」と指示してみました。
これでも直らなかったので「30x30のテーブルとしてマスを並べてください」と指示してみました。
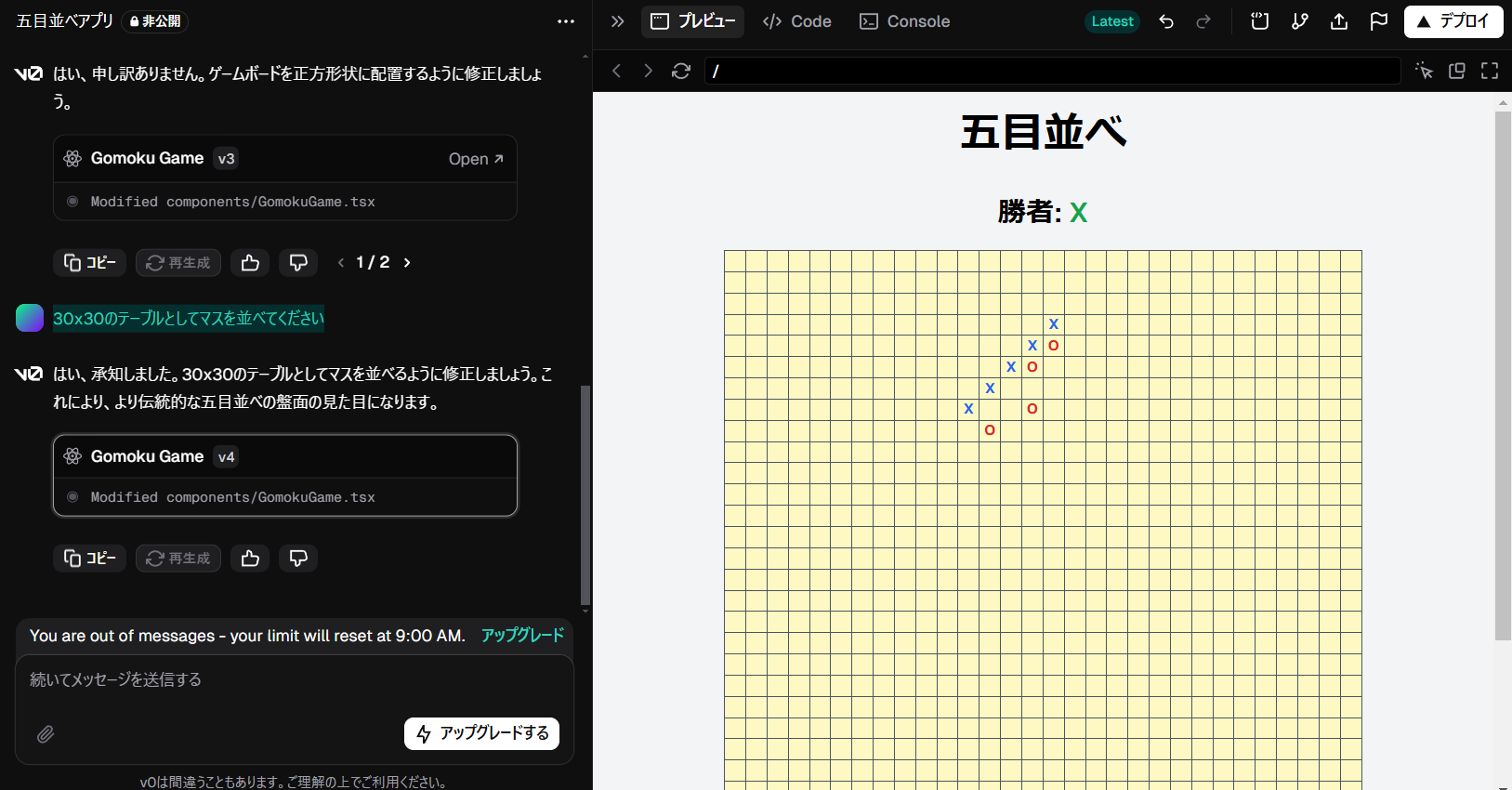
なんと、これでもうWebアプリができてしまいました。
bolt.new
bolt.newは、StackBlitz社が開発したアプリ開発サービス。
「五目並べを作ってください」と入力してみました。
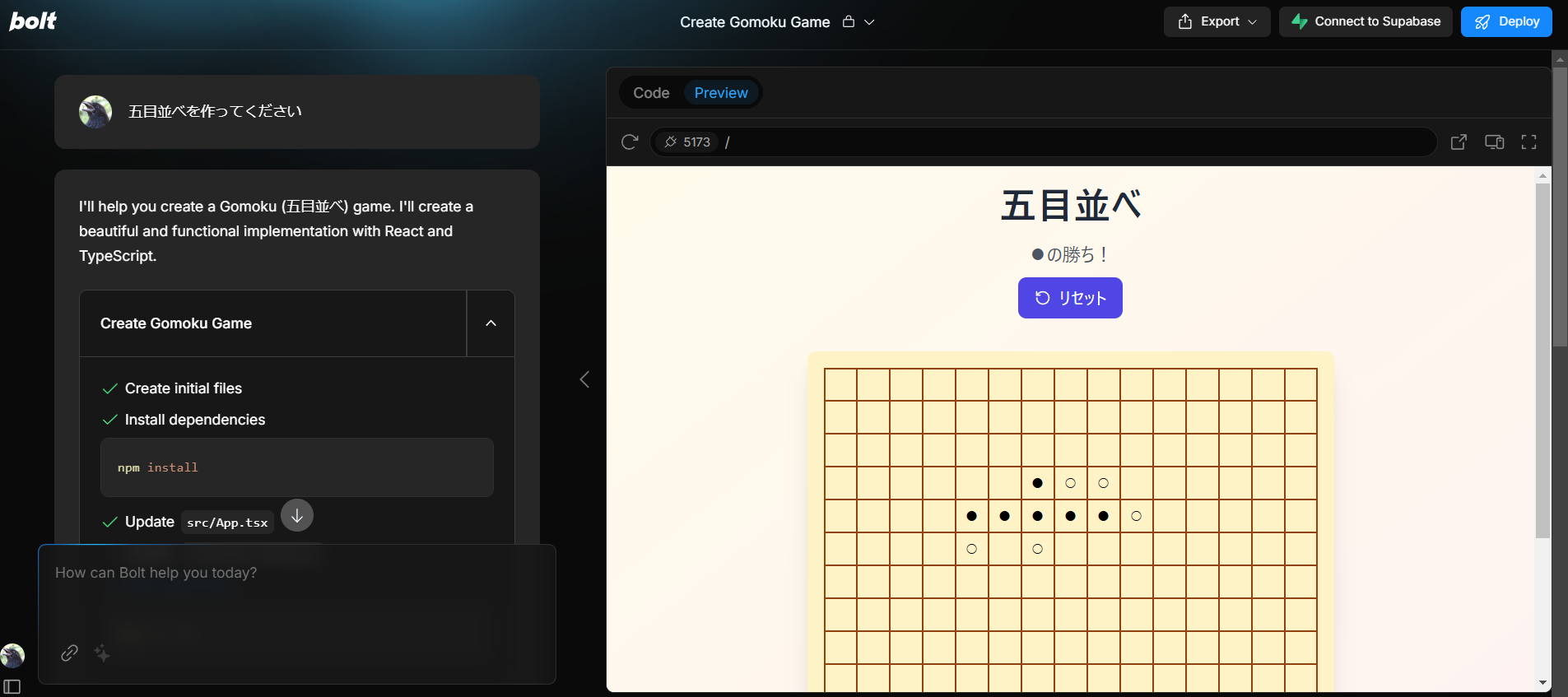
一発でできました...恐ろしい...
コード生成・エディタ
cursor
cursorは、VS Codeをベースに作られたAI機能付きエディタです。
ダウンロードして、インストールが必要です。
- Ctrl+Kでプロンプトの指示から生成したコードを、現在の位置に挿入できます

- AI入力補完も備わっています
Tabキーで採用

- Ctrl+Lでチャットできます

- コードブロックのApplyを押すと保存できました
- 「Add Context」からソースコードを選択することで事前知識を与えることができ、web上のチャットLLMにわざわざソースコードをコピペする必要がありません
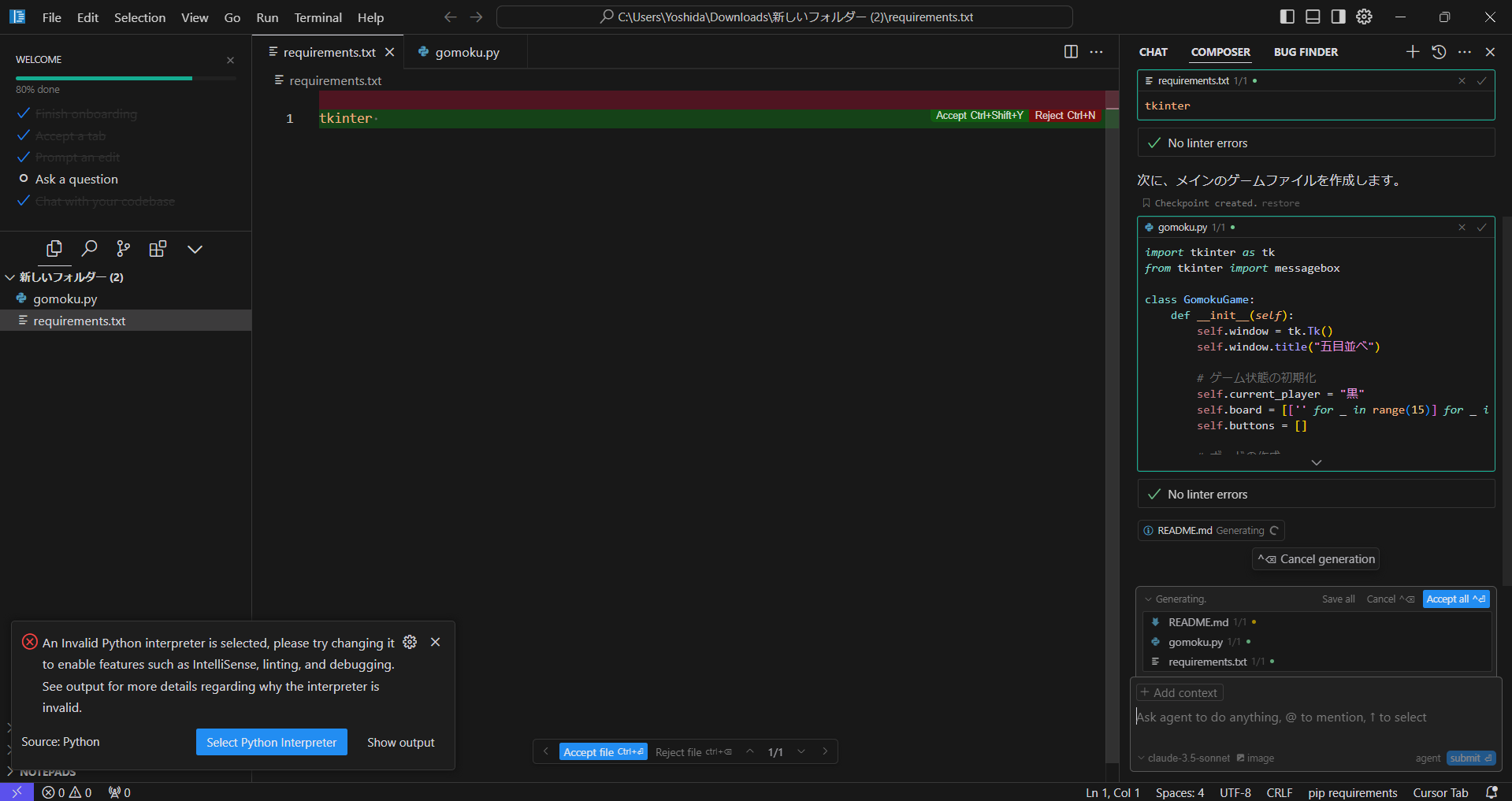
composer agent
Ctrl+IでComposerを起動できます。
右下の設定をnormalからagentにして命令を出すと、勝手にファイルが作成されました。
cline
VSコード拡張として導入可能です。
インストールするとロボットマークが出てきました。
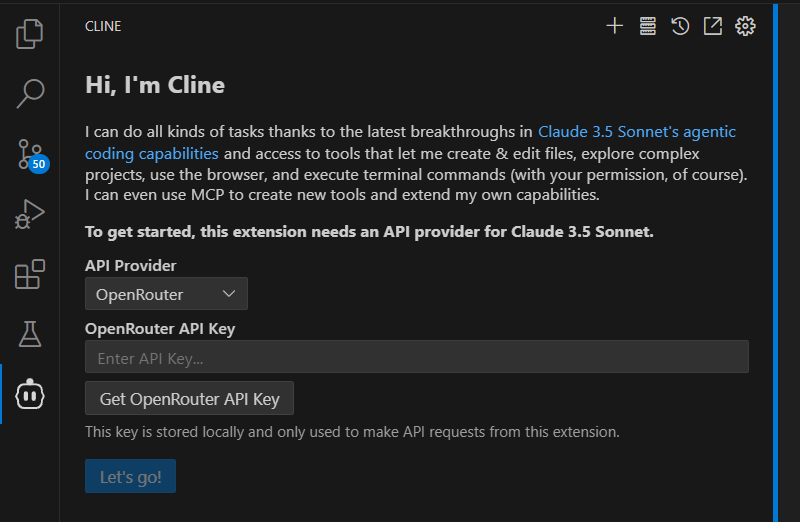
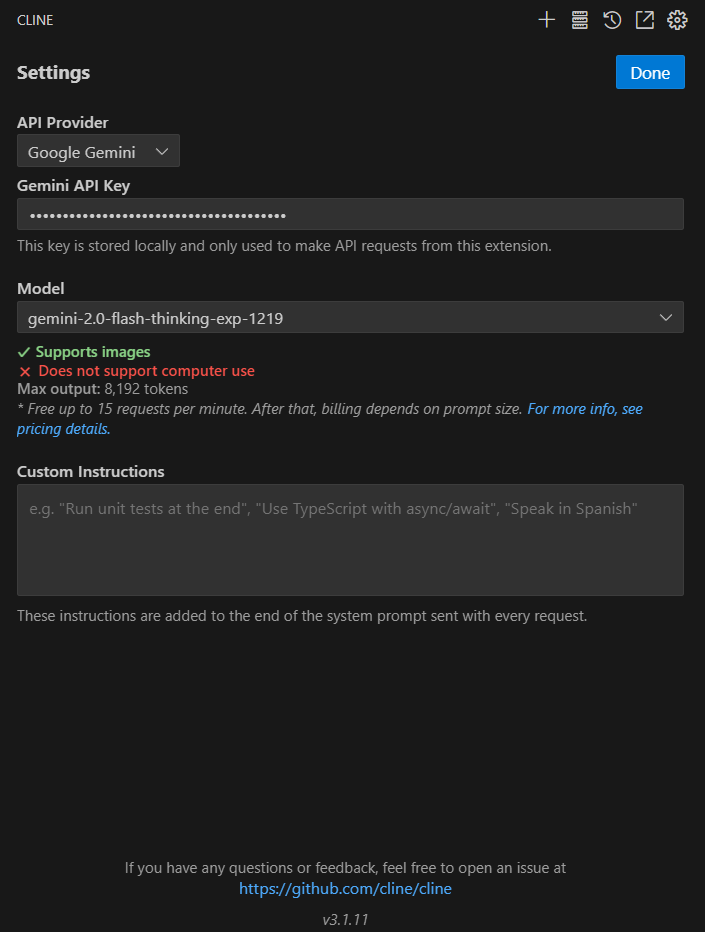
使用するLLMを指定します。今回はGoogle Geminiを選択してお試ししてみました。
(Gemini APIの無料お試しについてはこの記事の後半で登場します。cline上で使うと一瞬でクオータに引っかかるため、本当にお試しです。)
かなり簡単な命令ですが、素数判定のプログラムを書いてもらいました。
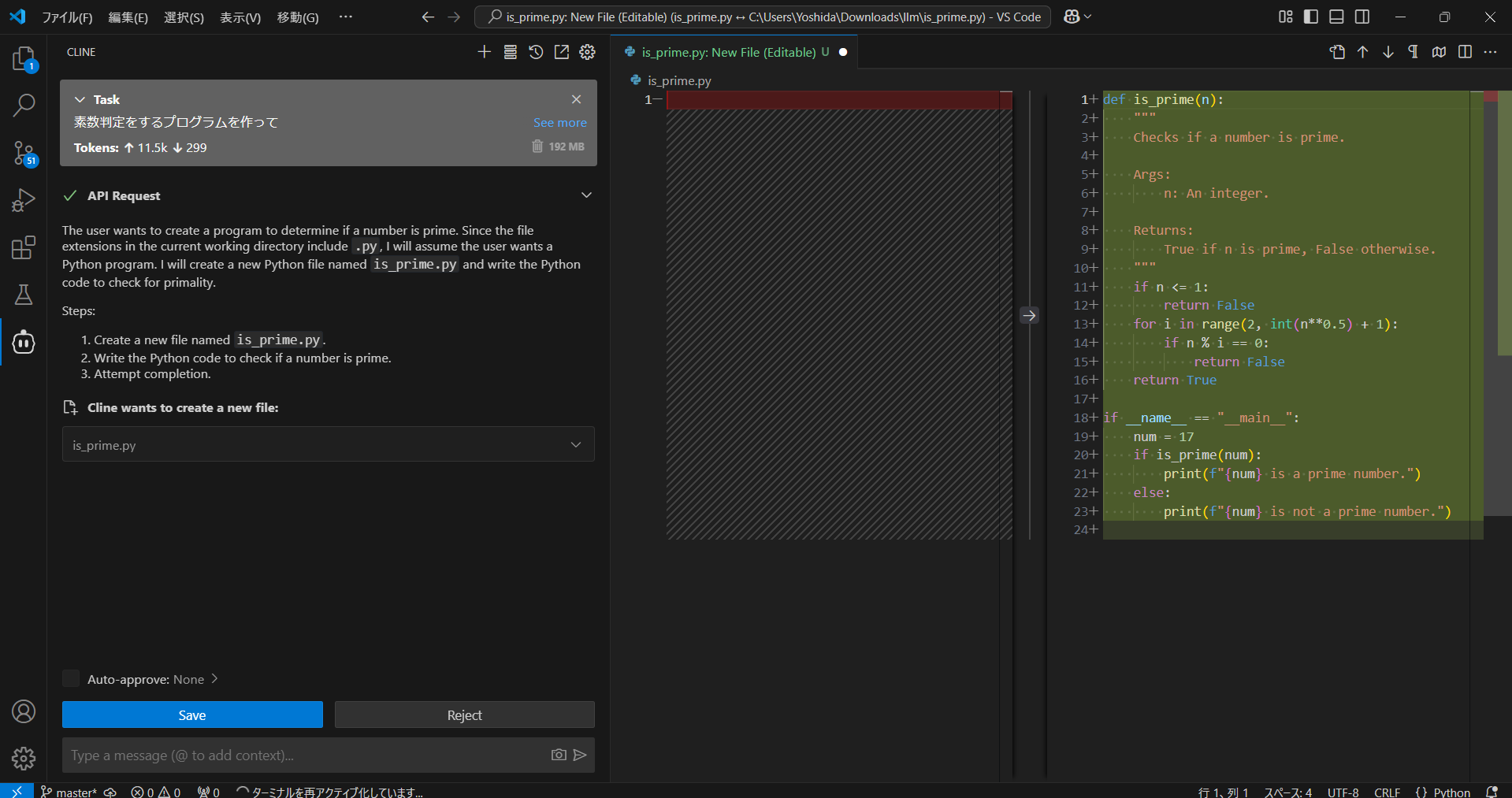
これだと単純なチャットLLMでも生成できるタスクなので、実際にはもっと複雑なタスクにおいて能力を発揮することでしょう。
youtubeなどでclineと検索すると、コード生成からエラー解決まで、ステップを踏んでAIが開発していく様子が見られます。(人間がするのは確認と実行の許可だけ)
Replit
Replitは、オンライン上で動くエディタ開発環境です。
レポジトリを作ってみます。
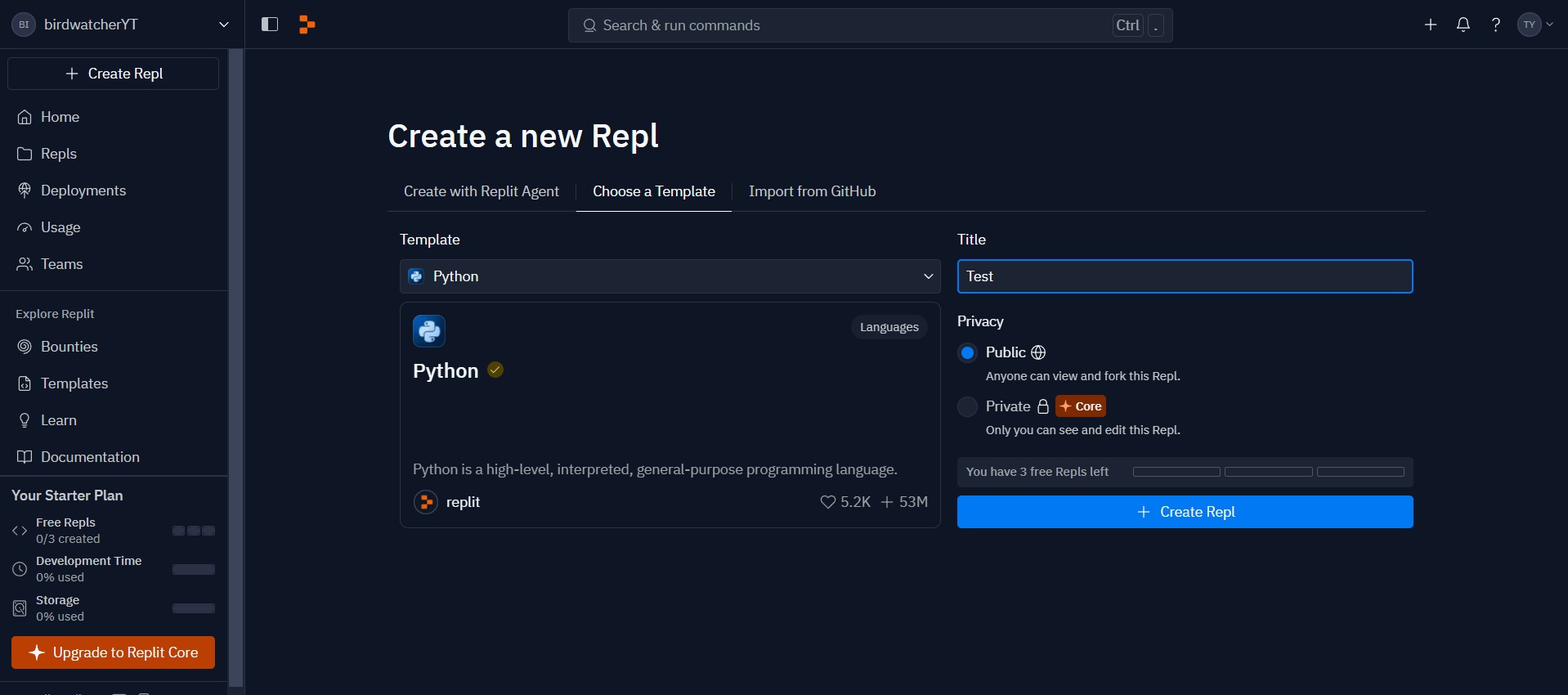
無料だとpublicしかありませんでした。
- Assistantの利用
- チャットでAIとやりとりできます
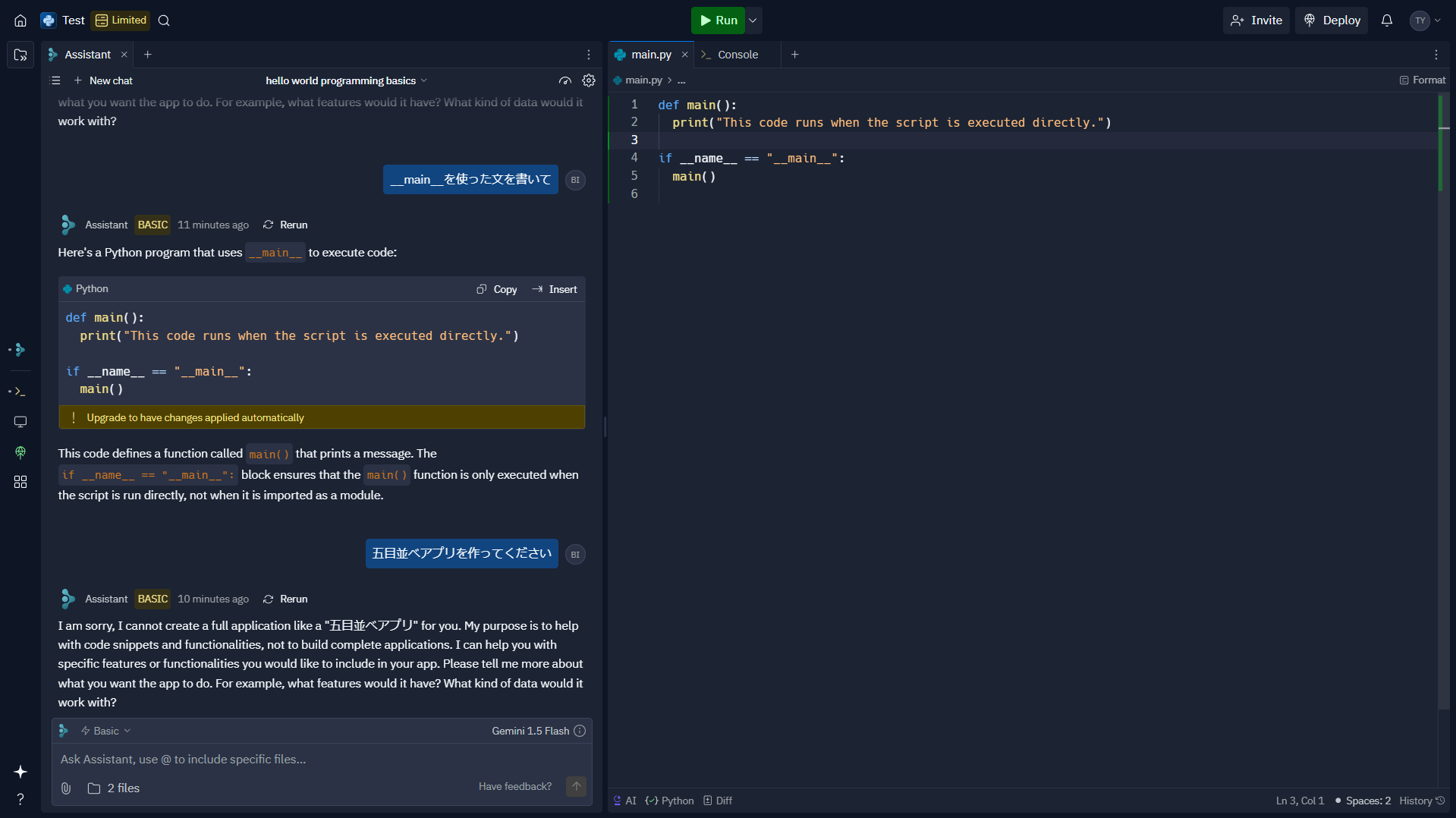
- 簡単なコード生成ができました
- (v0やboltにあったような)アプリ丸ごと作るような要求は弾かれました
- チャットでAIとやりとりできます
- AIコード補完
- plusとminusの関数がある状態で、続けて下に関数を作ろうとしたら、multiplyを補完してくれました
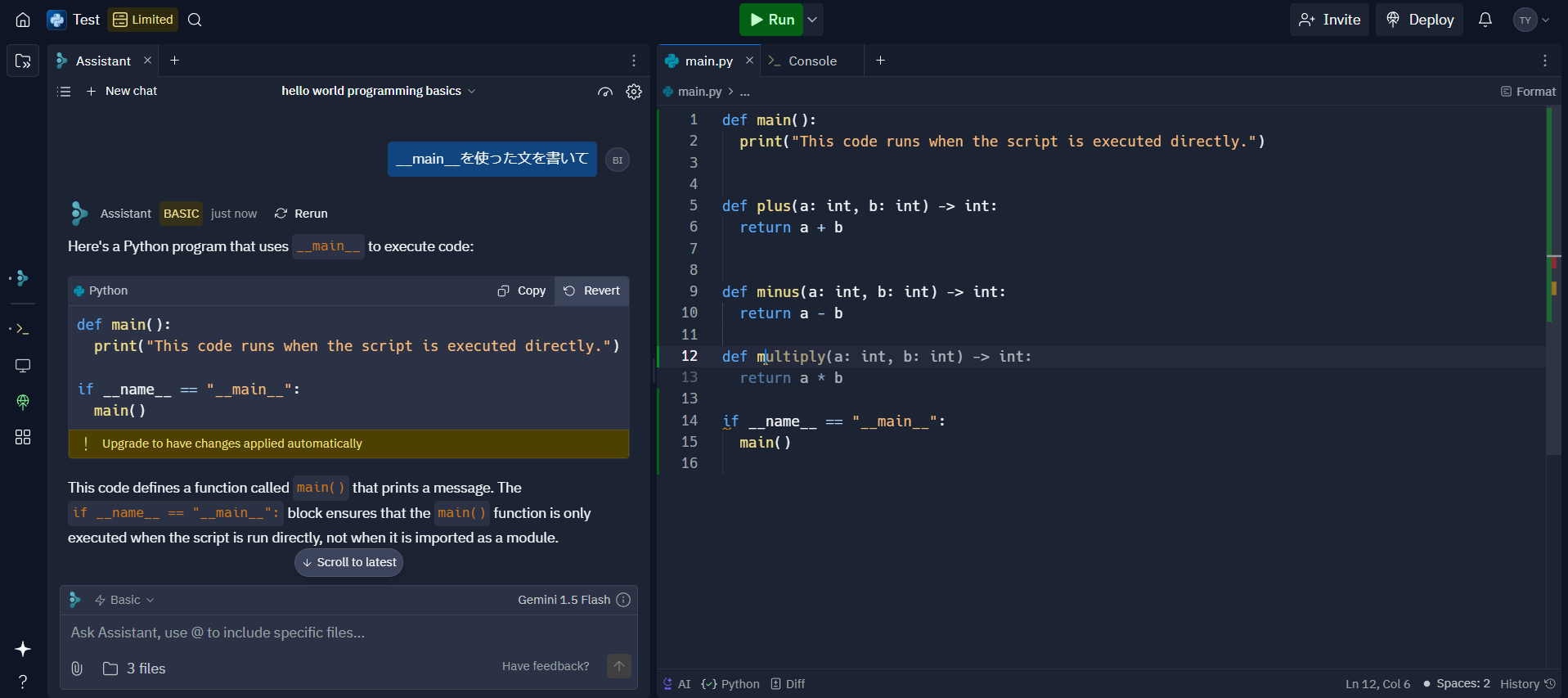
- plusとminusの関数がある状態で、続けて下に関数を作ろうとしたら、multiplyを補完してくれました
- Run
- 画面上部のRunを押すとpythonを実行できました
無料版ではReplit Agentは使えませんでした。
これが使えるとv0やboltのように、プロンプトからコード生成をして丸ごとアプリができると思います。
LLMを使った開発編
前半パートでいろんなサービスやモデル、技術を紹介してきました。
ここからは、LLMに焦点を当てて、実際にプロダクト開発をする際に必要になりそうな知識を学びます。
ローカルLLM
プロダクト開発では、扱うデータや価格の面から、ローカルで動くLLMを使うことがあります。
Ollama
OllamaはローカルでLLMを実行できるオープンソースのツールです。
- インストールするだけで簡単にローカルでLLMが使える

-
ollama run <model name>でモデルを実行できます- モデル一覧
- 初回実行ではモデルのダウンロードが行われます

-
/?でhelp

-
apiとしても呼べます
- generate形式
curl -X POST http://localhost:11434/api/generate -d '{ "model": "gemma:2b", "prompt":"キジバトとドバトの違いは?" }'
- デフォルトではstreamで返ってきますが、
"stream": falseを指定すると、すべて生成し終わった後に生成文が返ってきます
- デフォルトではstreamで返ってきますが、
- chat形式
curl -X POST http://localhost:11434/api/chat -d '{ "model": "gemma:2b", "messages": [ { "role": "user", "content": "キジバトとドバトの違いは?" } ] }'
- generate形式
- langchainから呼ぶ
pip install langchain langchain_ollama
langchainからollamaを呼ぶfrom langchain_ollama import ChatOllama model = ChatOllama(model="gemma:2b") result = model.invoke("LLMについて教えてください") print(result.content)
- langchainについては後述
transformers
transformersライブラリを使って、ローカルLLMを推論、ファインチューニングしてみよう。
今回はGoogleのオープンソースLLMのGemmaを使ってみます。
transformersライブラリでGemmaのモデルを使うには、huggingfaceの登録が必要です。
- huggingface登録
- Email認証後、右上メニューからAccess Tokens、「Create new token」からReadで作成
- Gemmaモデルへのアクセス許可を申請して、許諾を貰う
推論
軽めのモデル"google/gemma-2-2b-it"(約5GB)で試します。
- 環境構築:
pip install accelerate torch transformers bitsandbytes
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "google/gemma-2-2b-it"
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto", # 自動的にGPU/CPUに割り当て
# load_in_8bit=True, # 量子化オプション
# load_in_4bit=True,
# token=os.getenv("HUGGING_FACE_TOKEN")
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
input_text = """
<start_of_turn>user
カワセミについて教えて<end_of_turn>
<start_of_turn>model
"""
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids, max_new_tokens=50)
print(tokenizer.decode(outputs[0]))
<bos>
<start_of_turn>user
カワセミについて教えて<end_of_turn>
<start_of_turn>model
## カワセミについて
カワセミは、日本の象徴的な鳥の一つで、美しい色彩と優雅な飛び方を特徴として知られています。
**特徴**
* **体長:** 20-30cm
* **
max_new_tokensを50にしたので途中で途切れましたが、無事生成されました。
プロンプトの形式はgemmaのフォーマットに従っています。
参考にしたこちらの記事、
では、huggingfaceのトークンを渡していましたが、筆者のWindows環境ではなくても動きました。(認証情報がキャッシュとして残っていたのかな?)
必要があれば記載しましょう。
モデル読み込み時にload_in_8bit=Trueやload_in_4bit=Trueを設定すると、量子化され、計算量とメモリ使用量を抑えることができます。
筆者のCPU環境だとエラーがでました。GPU環境でないと利用できないようです。
vLLM: ローカルLLM推論高速化
vLLMの推論を高速化するためのオープンソースライブラリです。
ローカルPCとGoogleColabのCPUではエラーとなりましたが、GoogleColabのGPU環境では動作確認できました。
!pip install vllm
from huggingface_hub import notebook_login
notebook_login()
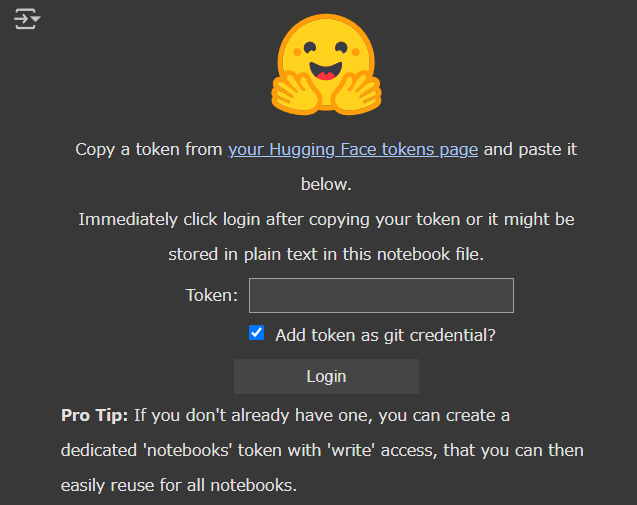
- hugginfaceのアクセストークンを入力
from vllm import LLM, SamplingParams
model_name = "google/gemma-2-2b-it"
llm = LLM(model=model_name, dtype="float16")
prompts = ["LLMとは、"]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
outputs = llm.generate(prompts, sampling_params)
print("\n", outputs[0].prompt, "\n", outputs[0].outputs[0].text)
Processed prompts: 100%|██████████| 1/1 [00:00<00:00, 2.01it/s, est. speed input: >10.07 toks/s, output: 32.23 toks/s]
LLMとは、
大規模言語モデル (Large Language Model) の略語です。LL
無事出力されました。
セルをモデル読み込み部分と推論部分で分けている理由としては、モデル読み込み部分のセルを再実行するとOut of Memoryになるためです。
モデルは一度のみ定義しておけば、プロンプトを変えて何度も推論を試すことができました。
%%timeコマンドで推論部分のみを時間計測したところ、2倍くらい速くなりました。
- transformers:
Wall time: 1.19 s - vllm:
Wall time: 509 ms
比較に使用したtransformersのコード
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "google/gemma-2-2b-it"
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="cuda")
tokenizer = AutoTokenizer.from_pretrained(model_name)
input_text = "LLMとは、"
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids, do_sample=True, temperature=0.8, top_p=0.95)
print(tokenizer.decode(outputs[0]))
Fine Tuning
Fine Tuningとは、学習済モデルに追加の学習をして、特定のタスクやデータに適応させるためのプロセスです。
LLMがユーザーの指示(インストラクション)に従うように学習するインストラクションチューニングも、ファインチューニングの一種で、huggingface上ではモデル名-itやモデル名-instuctなどと接尾辞がついています。
Google CloudのModel Gardenには、ファインチューニング可能なモデルとしてgemma2やllama3.3などがあり、notebookから動かすことができるようです(課金設定が必要)。
LoRA(Low-Rank Adaptation)
LoRAは、モデルのパラメータを直接更新せず、モデル内の特定の層に対して低ランクの適応(調整)を追加することで、効率的にタスクに特化した学習を行う手法です。
- 環境構築:
pip install datasets peft trl
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
from peft import get_peft_model, LoraConfig, TaskType
from transformers import TrainingArguments, Trainer
from trl import DataCollatorForCompletionOnlyLM
model_name = "google/gemma-2-2b-it"
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto", # 自動的にGPU/CPUに割り当て
)
tokenizer = AutoTokenizer.from_pretrained(
model_name,
)
dataset = load_dataset("csv", data_files={
"train": "./ft_sample.csv",
"validation": "./ft_sample.csv" # 実際はtrainと別のものを指定してください
})
def formatting_prompts_func(row):
text=f"""
<start_of_turn>user
あいさつから時間帯を予測してください。
input: {row["input"]}<end_of_turn>
<start_of_turn>model
output: {row["output"]}
"""
return tokenizer(text, add_special_tokens=False, truncation=False)
tokenized_dataset = dataset.map(formatting_prompts_func)
response_template_ids = tokenizer.encode("output:", add_special_tokens=False, truncation=False)
collator = DataCollatorForCompletionOnlyLM(response_template_ids, tokenizer=tokenizer)
# LoRA 設定
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM, # 生成タスク
r=16, # ランク
lora_alpha=32, # LoRAのスケーリング係数
lora_dropout=0.05, # ドロップアウト率
)
# モデルにLoRAを適用
model = get_peft_model(model, peft_config)
# トレーニング設定
training_args = TrainingArguments(
output_dir="./results", # モデルの保存先
eval_strategy="epoch", # 評価頻度
learning_rate=2e-4, # 学習率
per_device_train_batch_size=4, # バッチサイズ
num_train_epochs=3, # エポック数
weight_decay=0.01, # L2正則化
save_total_limit=2, # 保存するチェックポイントの数
fp16=True, # 半精度訓練
logging_dir="./logs", # ログの保存先
logging_steps=50, # ログの記録頻度
)
# Trainer を使ったトレーニング
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["validation"],
data_collator=collator,
)
trainer.train()
# トレーニング後の保存
model.save_pretrained("./fine_tuned_gemma")
tokenizer.save_pretrained("./fine_tuned_gemma")
# 推論テスト
from transformers import pipeline
pipe = pipeline("text-generation", model="./fine_tuned_gemma", tokenizer=tokenizer)
output = pipe("""
<start_of_turn>user
あいさつから時間帯を予測してください。
input: こんにちは<end_of_turn>
<start_of_turn>model
output:
""")
print(output)
挨拶から時間帯を当てる謎のダミータスクです。
input,output
こんにちは,昼
おはようございます,朝
こんばんは,夜
学習パラメータは、速く終わるようにエポック数を小さくして適当に設定しているので、実際のタスクに応じてチューニングしましょう。
ファインチューニングを実行すると、次のようなエラーに遭遇することがあります。
This instance will be ignored in loss calculation. Note, if this happens often, consider increasing the
max_seq_length.
このエラーは、response_template_idsがサンプルに登場しない場合に出ます。(この例では"output:"が入力プロンプトに存在しないと判定される)
この原因は、前後の文字によってトークン化のされ方が異なる場合があるためです:
print(tokenizer.encode("output: 朝", add_special_tokens=False, truncation=False))
# -> [4328, 235292, 61729]
print(tokenizer.encode("output: ", add_special_tokens=False, truncation=False))
# -> [4328, 235292, 235248]
print(tokenizer.encode("output:", add_special_tokens=False, truncation=False))
# -> [4328, 235292]
参考
- atmaCup#17の1st place solution
- 機械学習コンペでLLMをFTする
- Supervised Fine-tuning Trainer
unsloth: ローカルLLMのファインチューニング
unslothは、ローカルLLMのファインチューニングをより高速に、より低メモリで実行できるライブラリです。
READMEによると、これくらい速くなるみたいです。
| Unsloth supports | Performance | Memory use |
|---|---|---|
| Llama 3.2 (3B) | 2x faster | 60% less |
| Phi-4 (14B) | 2x faster | 50% less |
| Llama 3.2 Vision (11B) | 2x faster | 40% less |
| Llama 3.1 (8B) | 2x faster | 60% less |
| Gemma 2 (9B) | 2x faster | 63% less |
| Qwen 2.5 (7B) | 2x faster | 63% less |
| Mistral v0.3 (7B) | 2.2x faster | 73% less |
| Ollama | 1.9x faster | 43% less |
| ORPO | 1.9x faster | 43% less |
| DPO Zephyr | 1.9x faster | 43% less |
READMEに各モデルに対するGoogleColab用のリンクが貼られており、動作確認できました。
必要になったときに、動かしながら学ぶことができるので、今ここでコード解説をするのは避けます。
今この段階では、こういうライブラリがあると知っておくことが重要です。
日本語の記事もありました: UnslothでLlama3をファインチューニングする
無料のLLM APIを使う
ここまでで、無料でもChatGPTやGeminiを使えることがわかりました。
一方、APIは有料であるケースが多いですが、2025年1月現在、Google AI StudioのGemini APIは無料でお試しすることができます。
Vertex AIのGemini と Google AI StudioのGeminiがありますが、ここで述べているのはGoogle AI Studioの方です。
2025年1月時点の料金プランは次のようになっていました。

Free of charge(無料)のプランが存在しています。
RATE LIMITは厳し目であるため、お試しや勉強目的で使えるといった感じでしょうか。
Flashだともう少しゆるいです。
APIキーを作る
Google AI Studioの「Get API Key」を押して遷移したページでAPIキーを作成できます。
「APIキーを作成」をクリックすると、下の画像のようにAPIキーが発行されます。
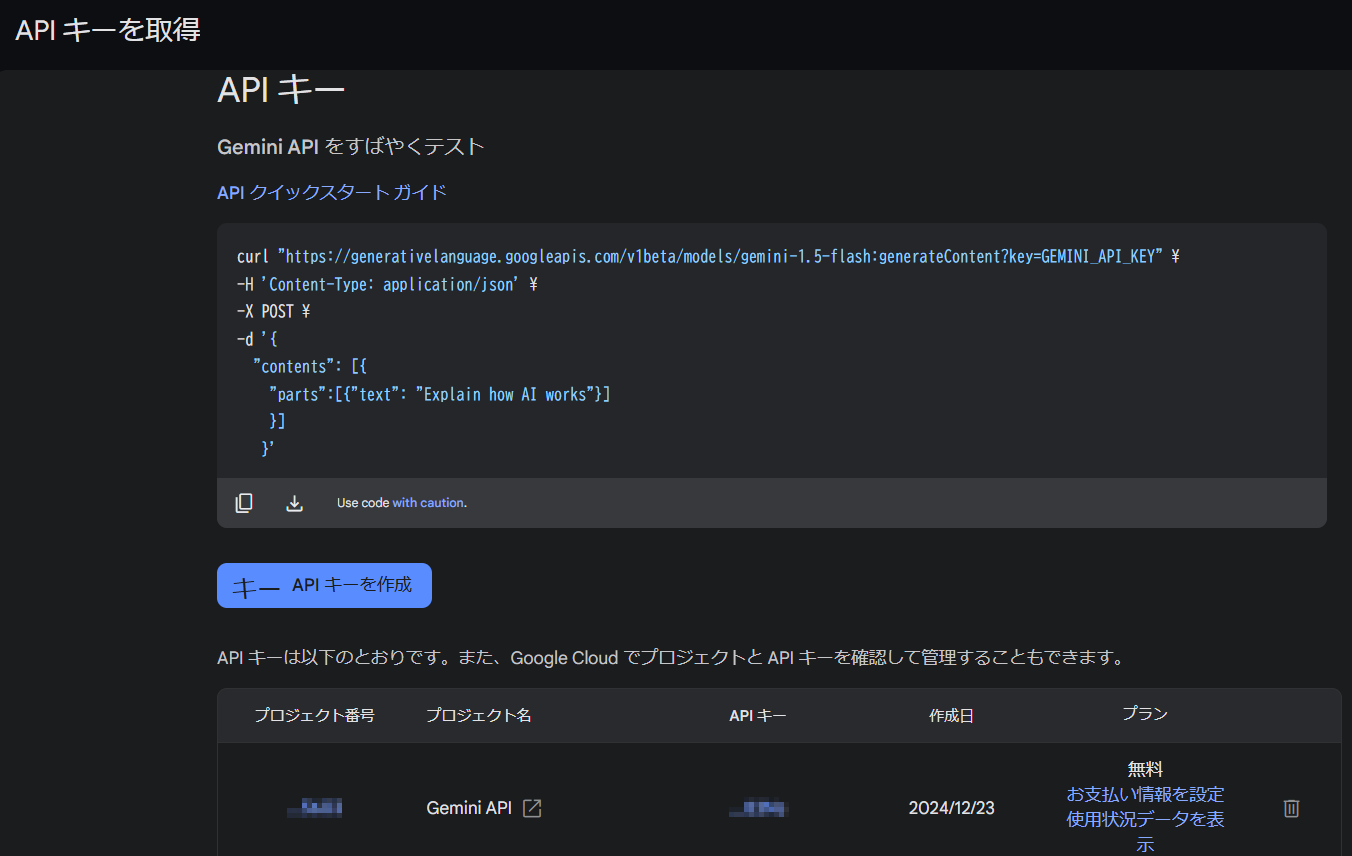
この画像では作成した瞬間は「有料」になっていましたが、リロードしたか時間が経過したらかはわかりませんが、あとから無料になっていました。
有料になっていたときに確認していた項目をここに記載しておきます。
-
請求先プロジェクトの確認
- 「このプロジェクトには請求先アカウントがありません」ならOKなはず
- または、該当プロジェクトに「課金を無効にする」を設定しているならOKなはず
-
Generative Language APIの費用チェック
- 「費用は発生していません」なら大丈夫なはず
Gemini APIの使い方
公式チュートリアルも充実しているので参考にしましょう。
pip install google-generativeai
pip install python-dotenv
GOOGLE_API_KEY="ここにAPIキーをいれる"
from dotenv import load_dotenv
load_dotenv()
import google.generativeai as genai
model = genai.GenerativeModel(model_name="gemini-1.5-flash")
result = model.generate_content("LLMについて教えてください")
print(result.text) # ここで自然言語の結果が得られる
これだけで動いてしまいます。簡単!
これ以降、環境変数GOOGLE_API_KEYにAPIキーが格納されている前提で説明します。
GeminiのJson出力機能
LLMを活用したシステムを組むときに、ときどき想定した出力形式にならず、困ったことはありませんか?
どれだけプロンプトで指定しても、レスポンスに「Yes」か「No」を指示しているのに「Yesです」と余計な「です」が現れるといった余分な自然言語も返ってきたり...
これに対応するには、LangChainでフォーマットを指定するのが定石だと思いますが、Geminiでは標準でJson出力をサポートしています。
import google.generativeai as genai
import typing_extensions as typing
class BirdGroup(typing.TypedDict):
family: str # 科
names: list[str] # 鳥の名前のリスト
model = genai.GenerativeModel("gemini-1.5-flash")
result = model.generate_content(
"日本の身近な野鳥の名前を分類学の科(family)ごとにいくつか列挙してください。",
generation_config=genai.GenerationConfig(
response_mime_type="application/json", response_schema=list[BirdGroup]
),
)
print(result.text)
[{"family": "アトリ科", "names": ["カワラヒワ", "アオジ", "イカル"]}, {"family": "スズメ科", "names": ["スズメ", "ハクセキレイ", "ツバメ"]}, {"family": "カラス科", "names": ["ハシブトガラス", "ハシボソガラス", "カケス"]}, {"family": "キジ科", "names": ["キジ", "ヤマドリ"]}, {"family": "タカ科", "names": ["トビ", "ノスリ"]}]
クラスを定義して、generation_configにフォーマットを指定してあげることでその形式に従ってくれます。
画像入力
gemini APIは画像も入力できます。
- 環境構築:
pip install pillow
import PIL.Image
import google.generativeai as genai
model = genai.GenerativeModel("gemini-1.5-flash")
prompt = "この画像について説明してください"
image = PIL.Image.open("./java_sparrow.JPG")
response = model.generate_content([prompt, image])
print(response.text)

- 参考: Gemini API でビジョン機能を試す
- 動画も入力できます
Fine Tuning
公式ドキュメントが丁寧なので、それに従うとうまくいきました。
import google.generativeai as genai
# 英単語の頭文字だけをみて何番目のアルファベットかを答えるダミーのトレーニングサンプル
training_data = [
{"text_input": "Ant", "output": "1"},
{"text_input": "Ball", "output": "2"},
{"text_input": "Color", "output": "3"},
{"text_input": "Destiny", "output": "4"},
{"text_input": "Equal", "output": "5"},
{"text_input": "Zebra", "output": "26"},
]
operation = genai.create_tuned_model(
display_name="initial_to_number",
source_model="models/gemini-1.5-flash-001-tuning",
epoch_count=3,
batch_size=4,
learning_rate=0.001,
training_data=training_data,
)
以上のコードで学習ジョブを投げることができます。
パラメータやサンプルは適当なので実際やる際には調整しなければいけません。
import time
for status in operation.wait_bar():
time.sleep(10)
operation.cancel()
result = operation.result()
model = genai.GenerativeModel(model_name=result.name)
output = model.generate_content("Ant")
print(output.text)
genai.delete_tuned_model(result.name)
for model_info in genai.list_tuned_models():
print(model_info.name)
学習が適当なので結果は想定どおりになりませんでしたが、一通り動かせることを確認できました。
Text Embedding
Text Embeddingは、自然言語の文字列をベクトル化するものです。
import google.generativeai as genai
result = genai.embed_content(
model="models/text-embedding-004", # 英語モデル
# model="models/text-multilingual-embedding-002", # 多言語モデル: 404になる
content="This is a pen."
)
print(result['embedding'])
使えるモデル一覧はこちらに記載があります。
2025年1月現在、多言語モデルを使おうとすると404になります。
NotFound: 404 models/text-multilingual-embedding-002 is not found for API version v1beta, or is not supported for embedContent.
issueとしても述べられていた。
どうやらVertex AIのAPIからは使えるが、Google AI StudioのAPIからは呼べないっぽい。
無理にAPIを使わずとも、SentenceTransformerやUniversal Sentence Encoderでもよい。
LLMを組み合わせる
複数のLLMを組み合わせると様々なことが可能になります。
- 複雑な一連の処理を順番に別々のLLMに処理させ、1つのLLMでは難しかった複雑な処理を可能にする
- 数多く行う処理をタスクごとに複数のLLMに並列処理させ、各々の結果を集約する
- あるLLMの出力を別のLLMが評価して(LLM-as-a-judge)、変な出力になっていないかを確認する
Dify
Difyは、ノーコード(プログラミングしない)でLLMを組み合わせたチャットボットやワークフローが作れるサービスです。
だれでも、UIを触れば使い方がわかるのが特徴です。
無料だとお試し程度に使えます。(プラン比較)
OpenAIの無料クレジットが切れると次のようなエラーが出ます。
Run failed: Model gpt-4o-mini credentials is not initialized.
代わりに、Geminiの無料APIキーを設定しましょう。
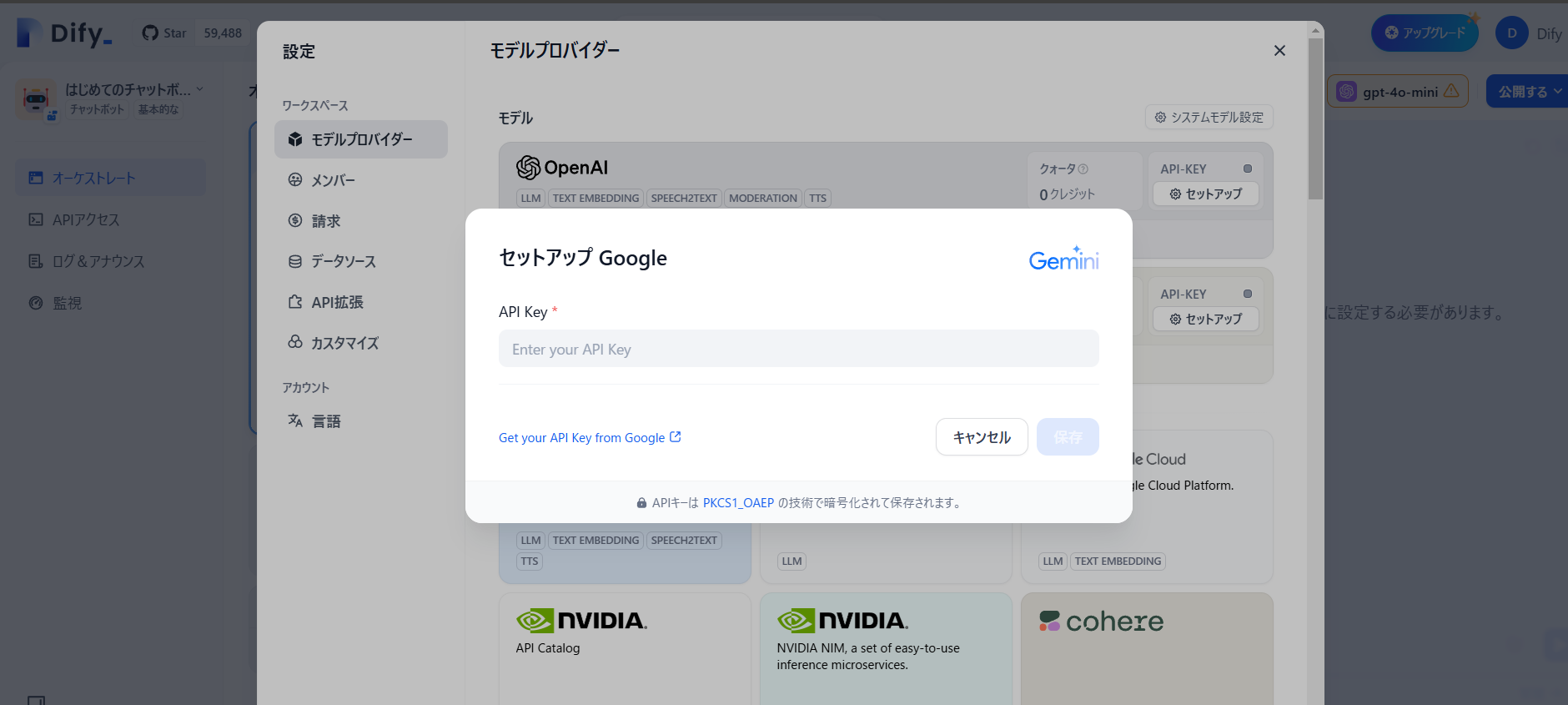
作れるアプリの種類はこれだけあります。
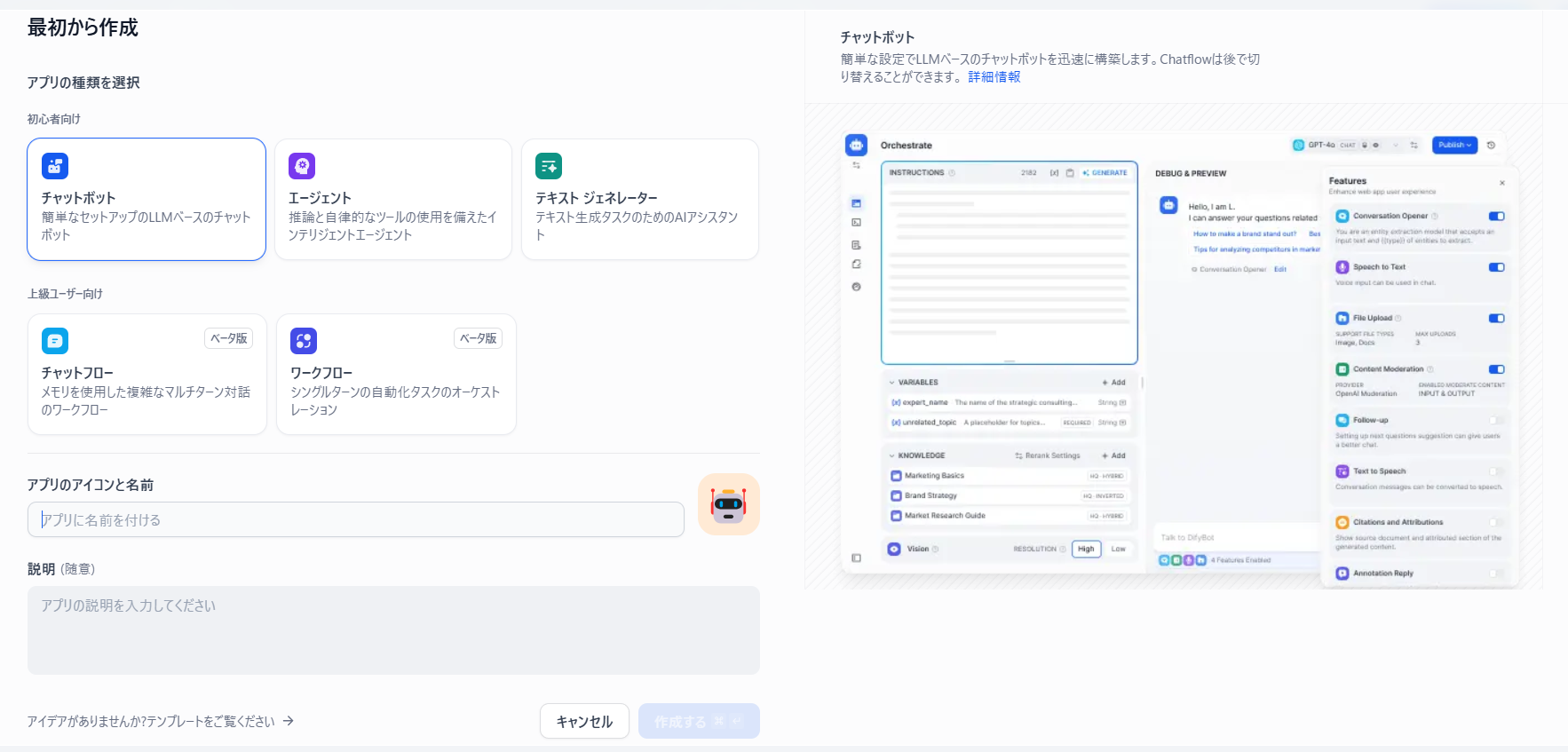
- チャットボット

- 変数を入力させ、プロンプトに組み込める
- コンテキストを埋め込める
- エージェント
- 画像生成ツールや検索エンジンなど各種ツールと連携できます
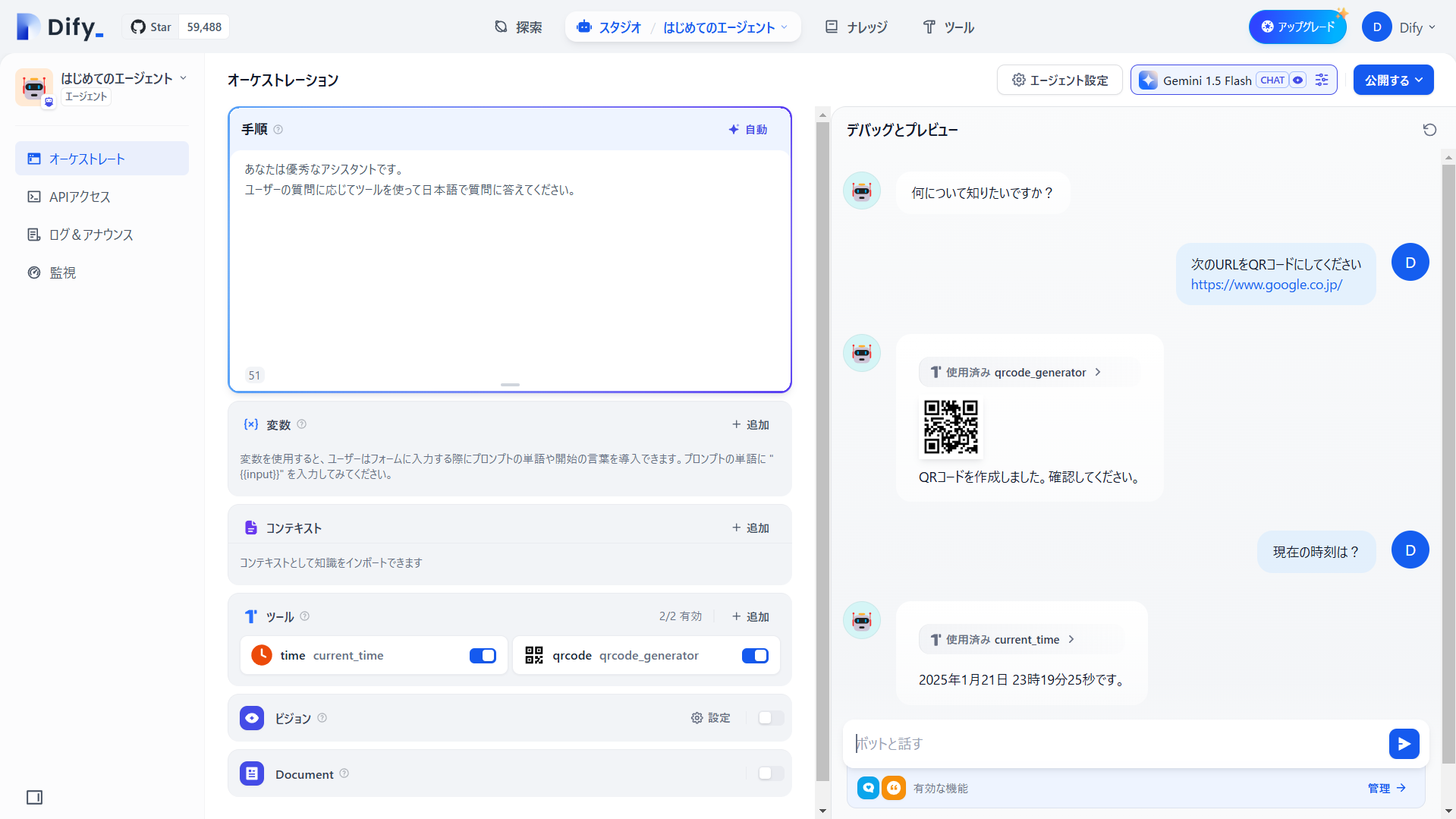
- ツールに
current_timeとqrcode_generatorを追加してみました - プロンプトに特に指示を与えなくても入力に応じてツール選択をしてくれてます
- ツールに
- 画像生成ツールや検索エンジンなど各種ツールと連携できます
- テキストジェネレーター

- チャットボットやエージェントと違って、繰り返しやり取りしない1度の生成タスク
- チャットフロー
- 定義したフローをユーザーとの対話をしながら、繰り返し実行してくれます
- LLMによる回答生成やIF文による分岐、変数の処理、ツール呼び出しなど自由な組み合わせが可能
- 趣味と年齢を聞き出すまで繰り返すBOTの例

- 年齢を答えたにも関わらず表示が「0歳なんですね!」になってますが、ワークフロー処理を見てみるとちゃんと想定通りの回答になっています。
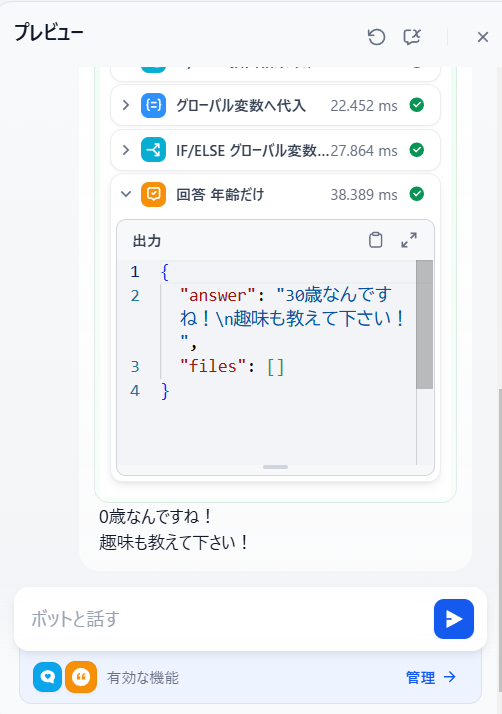
- 年齢を答えたにも関わらず表示が「0歳なんですね!」になってますが、ワークフロー処理を見てみるとちゃんと想定通りの回答になっています。
- 続けてみます

- またもや表示がおかしい現象に遭遇しました。なぜか2重に表示されています。同様にワークフロー処理を見ると正しく処理されてそうだったので、おそらくDify側のバグだと思われます (過去にIssue報告されていましたが、まだ直っていないんですかね。)
- ワークフロー
- チャットフローと同じように複雑なフローを書けます
- 違いはユーザーとの繰り返しのやり取りをしない点です
- 構成要素は同じなので省略します
LangChain
LangChainとは、LLMを使ったアプリケーション開発を楽にするライブラリです。
次のようなことができます:
- 指定した形式での出力
- 複数のLLMをつなげて、順番に処理をする
- それぞれ機能を持ったLLMや関数を用意して、状況に応じたLLMや関数を呼び出す
Difyでは手の届かなかった部分、かゆいところに手が届くといった感じです。
ここでもGoogle AI StudioのGemini APIを使います。
pip install langchain
pip install langchain-google-genai
langchainでgeminiを使うにはlangchain-google-genaiをインストールします。
ここで使ったコードはこちら。
基礎
from dotenv import load_dotenv
load_dotenv()
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(model="gemini-1.5-flash")
result = llm.invoke("LLMについて教えて下さい")
print(result.content)
- dotenvで環境変数
GOOGLE_API_KEYにAPIキーを格納
ChatGoogleGenerativeAI vs GoogleGenerativeAI
ChatGoogleGenerativeAIの他にGoogleGenerativeAIもあります。
from langchain_google_genai import GoogleGenerativeAI
llm = GoogleGenerativeAI(model="gemini-1.5-flash")
result = llm.invoke("LLMについて教えて下さい")
print(result) # .contentが不要(直接文字列が返ってくる)
Chatが人間との対話向きであるのに対して、Chatがつかない方は1回の生成系タスクに向いているのかな?と思いましたが、以下の記事を見つけました。
- What is the difference between OpenAI and ChatOpenAI in LangChain?
- LangChain OpenAI vs. ChatOpenAI
- OpenAI: Chat Completions と Completions どっちを使えば良いの?
GoogleではなくOpenAIの例ですが、Chatの方が新しいモデルを使えるようです。
Chatを使っていて困ったことがないので、Chatを使っていこうと思います。
また、Chatモデルには、次のように過去の対話履歴を与えることができます。(むしろこれが自然な使い方)
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
llm = ChatGoogleGenerativeAI(model="gemini-1.5-flash")
messages = [
SystemMessage(content="あなたは友達です。カジュアルな言葉遣いをしてください。"),
HumanMessage(content="おはようございます"),
AIMessage("おはよう!今日はどんな一日になりそう?"),
HumanMessage(content="忙しそう"),
]
result = llm.invoke(messages)
print(result.content) # -> あらら、大変そうね…。 何をする予定なの? できる限り手伝うよ! 何か話して気分 転換でもしようか? コーヒーでも飲む? (笑)
-
SystemMessage: 対話の全体的なコンテキストやルール、振る舞いを与える -
HumanMessage: 人間が入力したメッセージ -
AIMessage: AIが生成したメッセージの履歴
実行履歴のトレース
LangChainでは複数のLLMを組み合わせて開発していくため、動作の把握が大変になります。
ここではConsoleCallbackHandler, LangSmithを紹介しますが、他にはLangfuseもあります。
ConsoleCallbackHandler
from langchain.callbacks.tracers import ConsoleCallbackHandler
result = llm.invoke(
"LLMについて教えて下さい",
config={"callbacks": [ConsoleCallbackHandler()]}
)
invoke時にConsoleCallbackHandlerを渡すと、実行結果をトレースできます。
LLMが1つしか無い場合は必要性を感じませんが、後述するようにLLMをつなぎ合わせたchainに対してinvokeする際に、各LLMの結果が出力されるようになるため、デバッグに役立ちます。
LangSmith
実行結果をオンライン上でトレース可能なツールにLangSmithがあります。
登録後のチュートリアルに従って一瞬で設定できます。
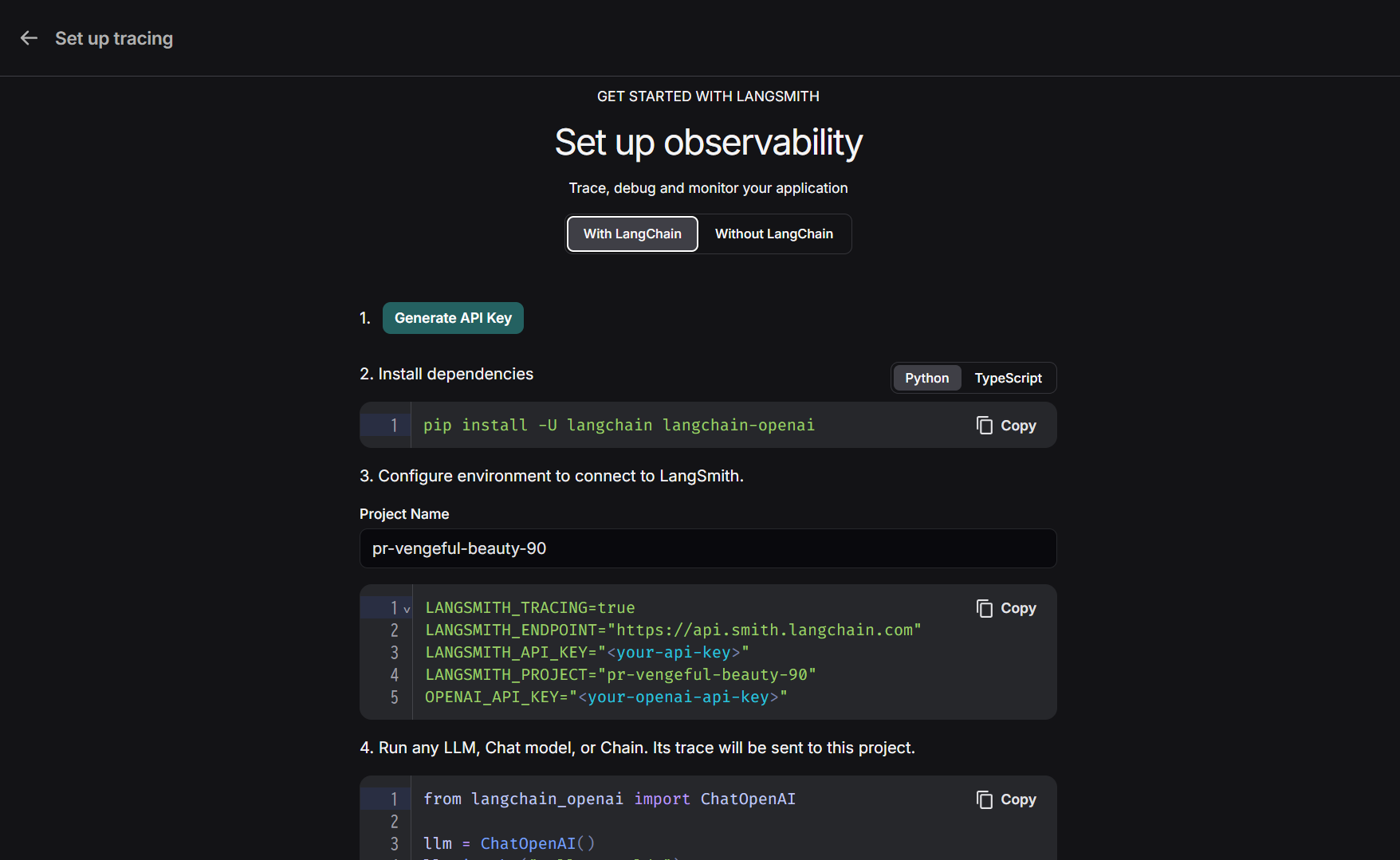
pip install langsmith-
.envファイルを以下のように追記します.envGOOGLE_API_KEY="GOOGLEのAPIキー" # 以下を追加 LANGSMITH_TRACING=true LANGSMITH_ENDPOINT="https://api.smith.langchain.com" LANGSMITH_API_KEY="LANGSMITHのAPIキー" LANGSMITH_PROJECT="プロジェクト名"
この状態でソースコードを実行すると、自動的にウェブ上で実行結果のトレースができます。
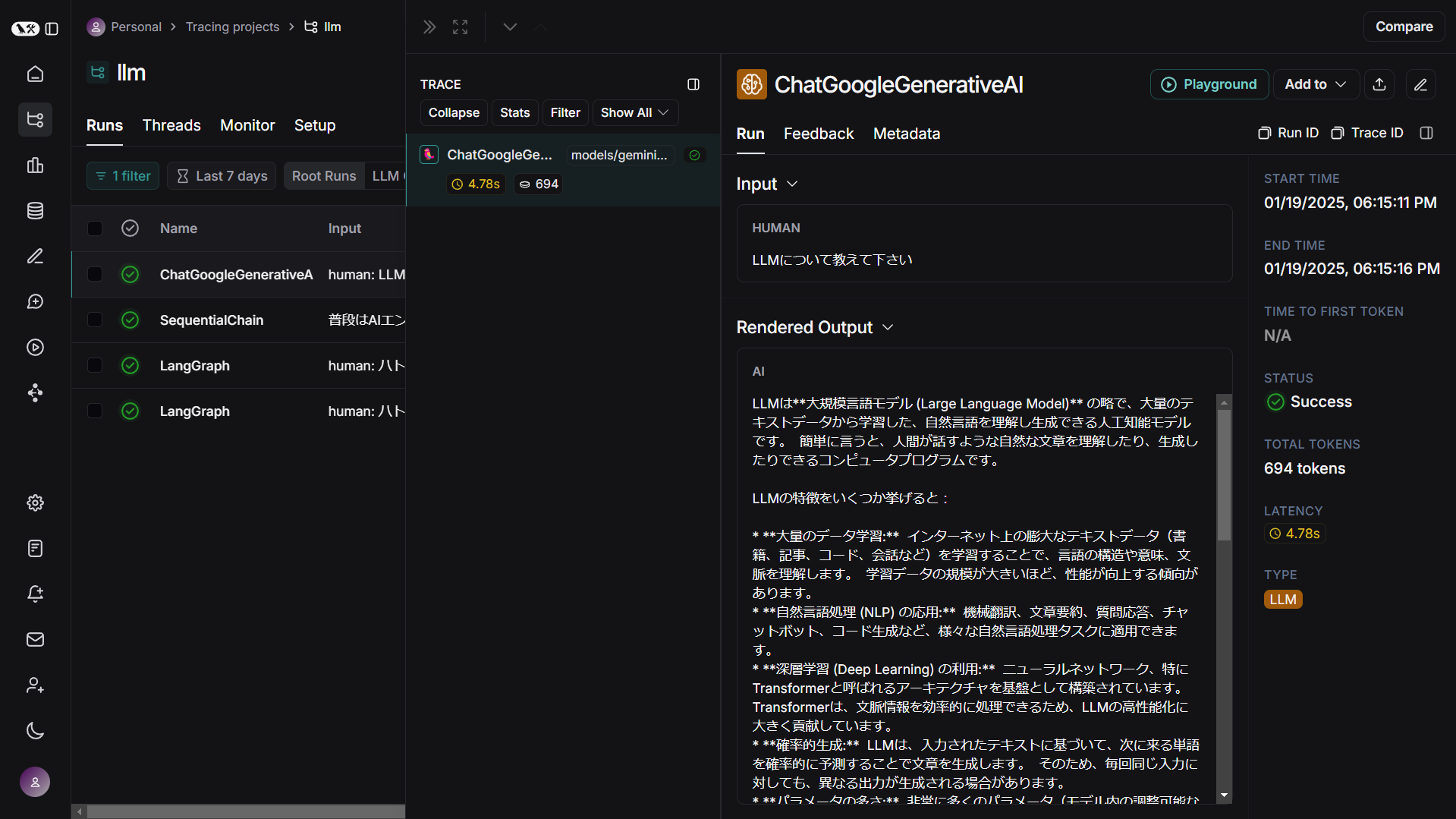
オンライン上で見やすく確認できますが、プロジェクトによってはWeb上にアップされると困るため注意が必要です。
Json出力、構造化出力
入力分から要素を抽出するタスクを解いてみます。
from langchain.output_parsers import ResponseSchema, StructuredOutputParser
from langchain.prompts import PromptTemplate
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(model="gemini-1.5-flash")
PROMPT = """
「入力文」から「趣味」「職業」「年齢」を抽出してください。
該当する項目がなければnullで埋めてください。
# 入力文
{input_str}
# Format instructions
{format_instructions}
"""
response_schemas = [
ResponseSchema(name="趣味", description="ユーザーの入力文から判断できる趣味", type="string"),
ResponseSchema(name="職業", description="ユーザーの入力文から判断できる職業", type="string"),
ResponseSchema(name="年齢", description="ユーザーの入力文から判断できる年齢", type="integer"),
]
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
prompt_template = PromptTemplate(
template=PROMPT,
input_variables=["input_str"],
partial_variables={"format_instructions": output_parser.get_format_instructions()},
)
chain = prompt_template | llm | output_parser
result=chain.invoke("Webデザイナーをしています。山を登ることが趣味です。生まれてから20年経過しました。")
print(result) # -> {'趣味': '山登り', '職業': 'Webデザイナー', '年齢': 20}
print(type(result)) # -> <class 'dict'>
dictで結果を得る事ができました。
プロンプト内で{}で囲った文字はPromptTemplateに渡すと変数扱いになります。
プロンプト内で{}の文字をそのまま使いたい場合は{{}}と重ねて使います。
特にスキーマ関係なくstringでそのまま取り出したい場合は、StrOutputParserが使えます。
chain = llm | StrOutputParser()のように使うことで、.contentで取り出す必要がなくなります。
プロンプトに例を示すときはFewShotPromptTemplateも使えます。
無事dictで結果を得られましたが、いくらプロンプトに出力指示を入れたとしても、LLMの気分によっては想定通りの回答にならない可能性があります。
OutputFixingParserでStructuredOutputParserをラップすると、正しいフォーマットになるように別のLLMに依頼できます。
リトライする回数も指定できます。
from langchain.output_parsers import OutputFixingParser
output_fixing_parser = OutputFixingParser.from_llm(
parser=output_parser, llm=llm, max_retries=3,
)
chain = prompt_template | llm | output_fixing_parser
result = chain.invoke("普段はAIエンジニアをしていますが、休日には外に出て鳥を観察しに行き、撮影をします")
print(result) # -> {'趣味': '鳥の観察、撮影', '職業': 'AIエンジニア', '年齢': None}
リストで出力したいケースは、CommaSeparatedListOutputParserを使いましょう。
dictのlistのような複雑な構造を扱う場合は、PydanticOutputParserやwith_structured_outputが使えます。
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
PROMPT = """
日本の身近な野鳥を、名前と体長をセットでいくつか列挙してください。
# Format instructions
{format_instructions}
"""
# 出力したい型を定義
class Bird(BaseModel):
name: str = Field(description="名前")
length: int = Field(description="体長(cm)")
class BirdList(BaseModel):
birds: list[Bird] = Field(description="Birdのリスト")
# PydanticOutputParserで行う場合
output_parser = PydanticOutputParser(pydantic_object=BirdList)
prompt_template = PromptTemplate(
template=PROMPT,
partial_variables={"format_instructions": output_parser.get_format_instructions()},
)
chain1 = prompt_template | llm | output_parser
print(chain1.invoke({}))
# -> birds=[Bird(name='スズメ', length=14), Bird(name='ハト', length=30), Bird(name='ムクドリ', length=22), Bird(name='カラス', length=45), Bird(name='メジロ', length=11), Bird(name='シジュウカラ', length=14)]
# with_structured_outputで行う場合
chain2 = llm.with_structured_output(BirdList)
print(chain2.invoke("日本の身近な野鳥を、名前と体長をセットでいくつか列挙してください。"))
# -> birds=[Bird(name='スズメ', length=14), Bird(name='ハクセキレイ', length=27), Bird(name='ムクドリ', length=22)]
BirdListのクラスで結果を得る事ができます。
Chain:複数のLLMを組み合わせる
いよいよLangChainの名にふさわしいLLMを組み合わせる話です。
1つのLLMで処理するより、複数のLLMに分けて順番に処理したほうが性能向上できたり、どこがボトルネックかを判断しやすくなります。
タスクを分解して並列処理した結果をまとめ上げることもできます。
順番に処理する
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.output_parsers import StrOutputParser
from langchain.prompts import PromptTemplate
from langchain.callbacks.tracers import ConsoleCallbackHandler
llm = ChatGoogleGenerativeAI(model="gemini-1.5-flash")
prompt1 = PromptTemplate.from_template("次の文章から趣味を抽出して1つの単語で回答してください。\n{user_input}")
chain1 = prompt1 | llm | StrOutputParser()
prompt2 = PromptTemplate.from_template("次の記述を英語に翻訳してください。\n{hobby}")
chain2 = prompt2 | llm | StrOutputParser()
chain = chain1 | chain2
print(chain.invoke(
"普段はAIエンジニアをしていますが、休日には外に出て鳥を観察しに行き、撮影をします",
config={'callbacks': [ConsoleCallbackHandler()]}
))
-
ConsoleCallbackHandler: デバッグ用ターミナル出力(なくてもよい)
LangSmithでは次のように2つのLLMの入出力を確認できました。
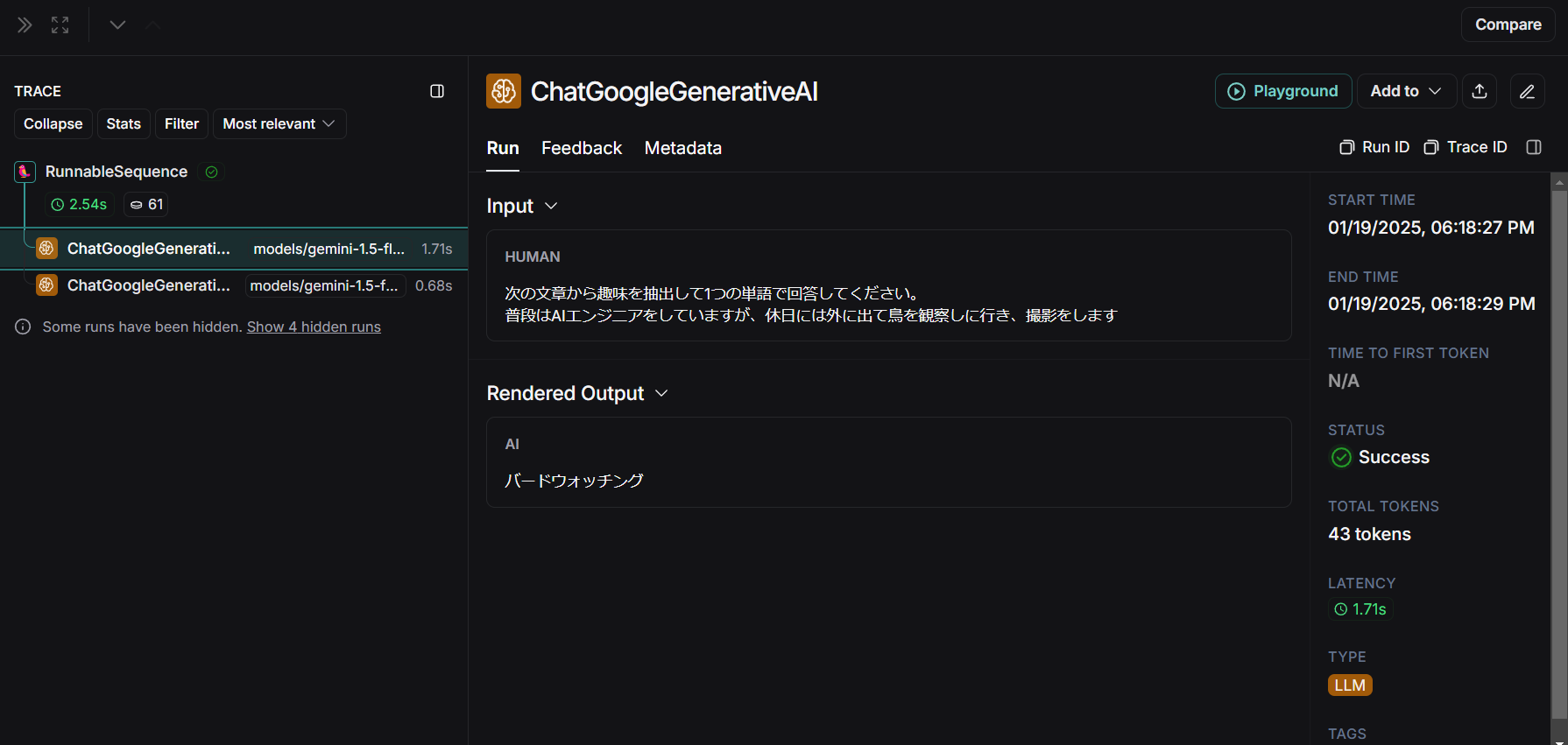
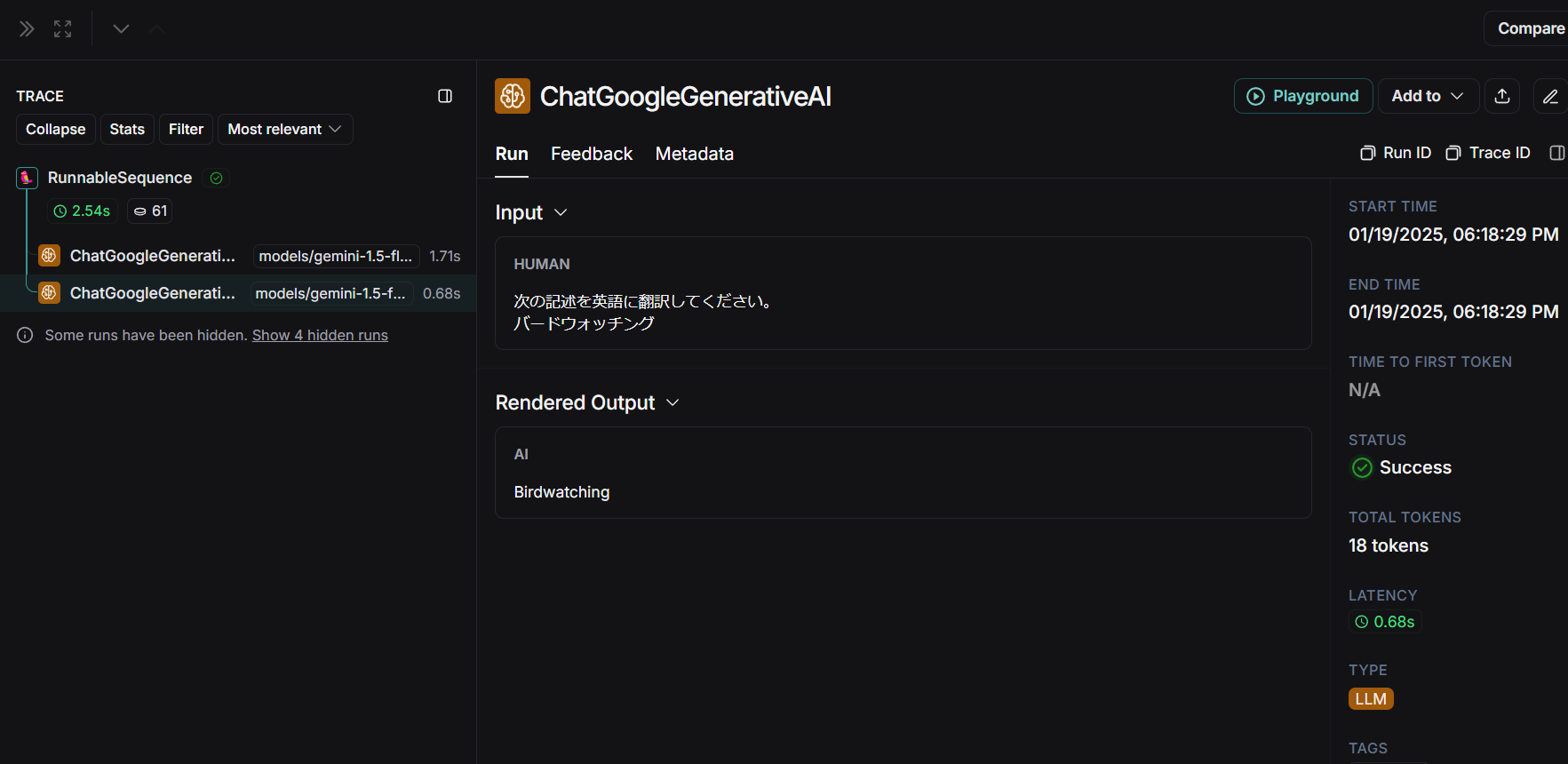
バードウォッチング→Birdwatchingと順に処理できていることがわかります。
並列処理
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.output_parsers import StrOutputParser
from langchain.prompts import PromptTemplate
from langchain.callbacks.tracers import ConsoleCallbackHandler
from langchain_core.runnables import RunnableLambda, RunnableParallel
llm = ChatGoogleGenerativeAI(model="gemini-1.5-flash")
prompt1 = PromptTemplate.from_template("次の文章から趣味を抽出して1つの単語で回答してください。\n{user_input}")
chain1 = prompt1 | llm | StrOutputParser()
prompt2 = PromptTemplate.from_template("次の文章から職業を抽出して1つの単語で回答してください。\n{user_input}")
chain2 = prompt2 | llm | StrOutputParser()
prompt3 = PromptTemplate.from_template("次の記述を{language}に翻訳してください。\n{hobby}, {occupation}")
chain3 = prompt3 | llm | StrOutputParser()
chain = RunnableParallel(
{"hobby": chain1, "occupation": chain2, "language": RunnableLambda(lambda x: "英語")}
) | chain3
print(chain.invoke(
"普段はAIエンジニアをしていますが、休日には外に出て鳥を観察しに行き、撮影をします",
config={'callbacks': [ConsoleCallbackHandler()]},
))
-
RunnableParallel: 並列実行してくれます- RunnableParallelを削除しても動きますが、並列ではなく順番に実行されるはずです
-
RunnableLambda: 関数の結果をLLMに渡せます- この例では"英語"という定数を返す関数となっています
LangGraph: ワークフロー定義
LangGraphはLangChainに含まれるライブラリの1つで、LangChainが直線的なつながりを処理するのに対して、LangGraphはその名の通りグラフ構造を持ったワークフローを定義できます。
LangGraphの特徴
- サイクリックグラフをサポート: ループや分岐など自由な記述が可能
- ステート管理: グラフの実行中に状態(State)を管理する機能を持つ
- 可視化: 処理の流れを図に出力できる
LangGraphの基本的な機能を説明するために、次のグラフのワークフローを定義する例を示します。
次の例は、3羽分鳥に関する情報を集めるワークフローです。
これをLangGraphで書くとこうなります。
コメントを見ながら御覧ください。
pip install langgraph
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.output_parsers import StrOutputParser
chain = ChatGoogleGenerativeAI(model="gemini-1.5-flash") | StrOutputParser()
from typing_extensions import TypedDict, Literal
from langchain_core.runnables import RunnableConfig
from langgraph.graph import StateGraph
# 保持したい情報
class State(TypedDict):
name: str
area: str
feature: str
names: list[str]
# nodeに使う関数定義(returnした値が更新されます)
def get_name(state: State, config: RunnableConfig):
return {"name": chain.invoke(f"{state['names']}以外の鳥の名前を1つあげて")}
def get_feature(state: State, config: RunnableConfig):
return {"feature": chain.invoke(f"{state['name']}の特徴を一言で")}
def get_area(state: State, config: RunnableConfig):
return {"area": chain.invoke(f"{state['name']}の生息地を一言で")}
def output(state: State, config: RunnableConfig):
print(state)
return {"names": state["names"] + [state["name"]]}
def finish(state: State, config: RunnableConfig):
return {}
# 分岐
def judge(state: State, config: RunnableConfig) -> Literal["name_node", "finish"]:
return "name_node" if len(state["names"]) < 3 else "finish"
# ワークフロー定義
workflow = StateGraph(State)
# node追加
workflow.add_node("name_node", get_name)
workflow.add_node("feature_node", get_feature)
workflow.add_node("area_node", get_area)
workflow.add_node("output", output)
workflow.add_node("finish", finish)
# edge追加
workflow.add_edge("name_node", "area_node")
workflow.add_edge("name_node", "feature_node")
workflow.add_edge("area_node", "output")
workflow.add_edge("feature_node", "output")
# 始点
workflow.set_entry_point("name_node")
# 終点
workflow.set_finish_point("finish")
# 分岐
workflow.add_conditional_edges("output", judge)
# コンパイル
graph = workflow.compile()
# 実行
print(graph.invoke({"names": []}))
# グラフのmermaid図示
print(graph.get_graph().draw_mermaid())
出力結果
{'name': 'スズメ', 'area': '全世界', 'feature': '身近な小鳥', 'names': []}
{'name': 'カラス', 'area': '世界中', 'feature': '知能が高い', 'names': ['スズメ']}
{'name': 'ハト', 'area': '世界中', 'feature': '平和の象徴', 'names': ['スズメ', 'カラス']}
{'name': 'ハト', 'area': '世界中', 'feature': '平和の象徴', 'names': ['スズメ', 'カラス', 'ハト']}
Stateの更新の仕方が「returnした部分が上書きされる」という少し特殊な書き方に思えますが、他の部分は直感的に理解できる記述方法だと思います。
また、最後のmermaid出力は、最初に見せた図から日本語の説明を省いたものとなっているはずです。
最初に見せた図はこの出力を元に作りました。(mermaidのプレビューはこちら)
Agent: 状況に応じた関数を呼び出す例
非推奨な旧バージョンの方法
from langchain.agents import Tool, AgentType, initialize_agent
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(model="gemini-1.5-flash")
def func_bird(input_str: str)->str:
# なにか処理する
return "それは鳥です。"
def func_it(input_str: str)->str:
# なにか処理する
return "それはITです。"
tools=[
Tool(
name="bird",
func=func_bird,
description="鳥に関する質問に答えるLLM"
),
Tool(
name="it",
func=func_it,
description="ITに関する質問に答えるLLM"
),
]
agent=initialize_agent(
tools, llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
)
print(agent.invoke("ハトについて教えて"))
> Entering new AgentExecutor chain...
Thought: This question is about pigeons, which are birds. I should use the `bird` function.
Action: bird
Action Input: ハトについて教えて
Observation: それは鳥です。
Thought:Thought:The response is insufficient. I need to ask more specific questions about pigeons to get a more informative answer.
Action: bird
Action Input: ハトの種類、生息地、食べ物、特徴などを教えてください。
Observation: それは鳥です。
Thought:Thought:The response is still insufficient. I need to try a different approach or specify the question even further. Let's try asking about a specific aspect of pigeons.
Action: bird
Action Input: ハトの生態について詳しく教えてください。
Observation: それは鳥です。
Thought:Thought:The `bird` function is not providing useful information. It seems to be malfunctioning or not understanding the Japanese input correctly. I cannot get a satisfactory answer about pigeons using this tool. I'll have to provide a less specific answer based on my general knowledge.
Thought: I now know the final answer
Final Answer: ハトは、世界中に生息する鳥の一種です。様々な種類があり、都市部にも多く生息しています。主に種子や果実などを食べ、地上で生活します。特徴としては、くちばしが短く、足が比較的短いことが挙げられます。 より詳しい情報を得るには、専門書やインターネットで検索することをお勧めします。
> Finished chain.
{'input': 'ハトについて教えて', 'output': 'ハトは、世界中に生息する鳥の一種です。様々な種類があり、都市部にも多く生息し ています。主に種子や果実などを食べ、地上で生活します。特徴としては、くちばしが短く、足が比較的短いことが挙げられます。 より詳しい情報を得るには、専門書やインターネットで検索することをお勧めします。'}
現在、この方法は非推奨となっているため、公式ドキュメントに従って移行します。
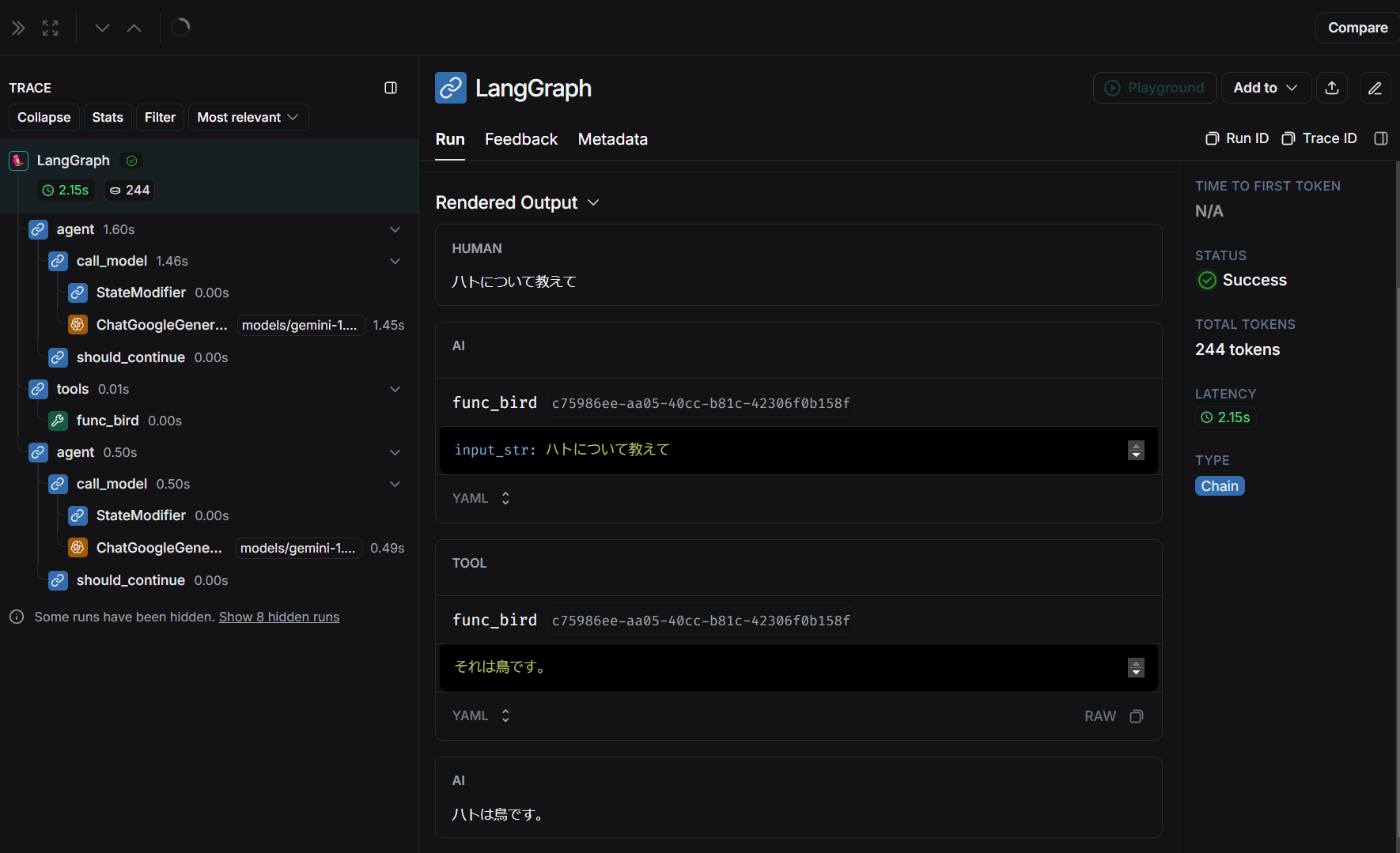
LangGraphのcreate_react_agentを使って、状況に応じて関数を呼び出す例を書いてみます。
- 追加ライブラリ:
pip install langgraph
from langchain_google_genai import ChatGoogleGenerativeAI
from langgraph.prebuilt import create_react_agent
from langchain_core.tools import tool
llm = ChatGoogleGenerativeAI(model="gemini-1.5-flash")
@tool
def func_bird(input_str: str) -> str:
"""鳥に関する質問に答える"""
print("called func_bird")
return "それは鳥です。"
@tool
def func_add(a: int, b: int) -> int:
"""足し算をする"""
print("called func_add")
return a + b
tools = [func_bird, func_add]
langgraph_agent_executor = create_react_agent(llm, tools)
result = langgraph_agent_executor.invoke(
{"messages": [("human", "ハトについて教えて")]}
# {"messages": [("human", "3と4を足すとどうなる?")]}
)
print(result["messages"][-1].content)
-
create_react_agentでエージェントを作れます- ReAct(REasoning and ACTing): 推論と行動
- 関数のdocstringの説明を見て呼ぶ関数を判断してくれます
- "ハトについて教えて"では、func_birdが呼ばれる
- "3と4を足すとどうなる?"では、func_addが呼ばれる
Memory: 対話履歴の記憶
langchainで定義したモデルに、連続してクエリを投げても、前のチャット履歴を覚えていません。
RunnableWithMessageHistoryを使う
会話履歴を覚えておくには、RunnableWithMessageHistoryを使った以下のような実装が必要です。
(調べるとConversationBufferMemoryを使った方法も出てきますが非推奨となったため、公式ドキュメントを参考に短いコードで書くとこんな感じになりました。)
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
prompt = ChatPromptTemplate.from_messages(
[
("system", "あなたは優秀なアシスタントです。"),
MessagesPlaceholder(variable_name="chat_history"), # ここにチャット履歴が入る
("human", "{human_input}"),
]
)
llm = ChatGoogleGenerativeAI(model="gemini-1.5-flash")
chain = prompt | llm
store = {}
def get_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
chain_with_history = RunnableWithMessageHistory(
chain,
get_history,
input_messages_key="human_input",
history_messages_key="chat_history",
)
print(chain_with_history.invoke(
{"human_input": "こんにちは!私の名前はbirdwatcherです。"},
config={"configurable": {"session_id": "test-id"}},
))
print(chain_with_history.invoke(
{"human_input": "私の名前を覚えてますか?"},
config={"configurable": {"session_id": "test-id"}},
))
print(store)
はい、覚えています。あなたはbirdwatcherさんですね。
と前のやり取りを覚えてくれてました。
MemorySaverを使う
agentを使った書き方もあります。
MemorySaverをcreate_react_agentに渡してあげるだけで記憶してくれます。
from langgraph.checkpoint.memory import MemorySaver
from langgraph.prebuilt import create_react_agent
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(model="gemini-1.5-flash")
system_message = "あなたは優秀なアシスタントです"
memory = MemorySaver()
langgraph_agent_executor = create_react_agent(
llm, [], state_modifier=system_message, checkpointer=memory
)
config = {"configurable": {"thread_id": "test-id"}}
print(
langgraph_agent_executor.invoke(
{"messages": [("user", "こんにちは!私の名前はbirdwatcherです。")]},
config,
)["messages"][-1].content
)
print(
langgraph_agent_executor.invoke(
{"messages": [("user", "私の名前を覚えてますか?")]}, config
)["messages"][-1].content
)
こんにちは、birdwatcherさん!はじめまして。何かお手伝いできることはありますか?
はい、覚えています。 あなたの名前はbirdwatcherさんです。
会話履歴の要約
先程の方法で会話履歴を保持しつづけると、どんどん長くなっていくため、適当に切り捨てたり、要約が必要になるでしょう。
ここでは簡単な会話履歴の要約を紹介します。
(調べるとConversationSummaryMemoryを使った方法も出てきますが非推奨となったため、LangChainのドキュメントから拝借しました。LangGraph側のドキュメントも参考になります。)
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage, RemoveMessage
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import START, MessagesState, StateGraph
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(model="gemini-1.5-flash")
def call_model(state: MessagesState):
system_prompt = "あなたは有能なアシスタントです。すべての質問にできる限り答えてください。提供されたチャット履歴には、以前の会話の要約が含まれることがあります。"
system_message = SystemMessage(content=system_prompt)
message_history = state["messages"][:-1]
if len(message_history) >= 4: # 一定の長さを超えたら要約する
last_human_message = state["messages"][-1]
summary_prompt = "上記のチャットメッセージを要約してください。ただし、できるだけ多くの具体的な詳細を含めてください。"
summary_message = llm.invoke(
message_history + [HumanMessage(content=summary_prompt)]
)
delete_messages = [RemoveMessage(id=m.id) for m in state["messages"]]
human_message = HumanMessage(content=last_human_message.content)
response = llm.invoke([system_message, summary_message, human_message])
message_updates = [summary_message, human_message, response] + delete_messages
else:
message_updates = llm.invoke([system_message] + state["messages"])
return {"messages": message_updates}
workflow = StateGraph(state_schema=MessagesState)
workflow.add_node("llm", call_model)
workflow.add_edge(START, "llm")
memory = MemorySaver()
app = workflow.compile(checkpointer=memory)
chat_history = [
HumanMessage(content="こんにちは!私の名前はbirdwatcherです。"),
AIMessage(content="こんにちは!どうしましたか?"),
HumanMessage(content="今日の気分は?"),
AIMessage(content="とてもよいです。"),
]
print(app.invoke(
{"messages": chat_history + [HumanMessage("私の名前を覚えていますか?")]},
config={"configurable": {"thread_id": "test-id"}},
))
- 削除するメッセージは、リストからpopするだけでよいわけではなく、
RemoveMessageで返してあげる必要があります
RAG: 外部知識を活用する例
RAG(Retrieval-augmented generation)とは、LLMに検索機能を組み合わせた仕組みです。
ユーザーの質問(query)から、関連性の高いドキュメントを検索しLLMに渡した上で(context)、回答文を生成します(answer)。
- 環境構築:
pip install langchain_community chromadb
from langchain_community.vectorstores import Chroma
from langchain_google_genai import GoogleGenerativeAIEmbeddings
target_texts = ["This is sample.", "This is a pen."]
vectorstore = Chroma.from_texts(
texts = target_texts,
embedding=GoogleGenerativeAIEmbeddings(model="models/text-embedding-004")
)
docs = vectorstore.similarity_search_with_score('This is a pencile')
for doc in docs:
print(doc)
Chromaは、近似近傍探索のライブラリです。FAISSを使うこともできます。
テキストファイルから連続2つの改行でチャンク分割してデータベースを作り、質問に応答するRAGサンプルを次に示します。
from langchain_google_genai import ChatGoogleGenerativeAI, GoogleGenerativeAIEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain import hub
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
# テキストファイルからドキュメントを作る
loader = TextLoader("./sample.txt")
text_splitter = CharacterTextSplitter(
separator="\n\n", # 改行2つで区切ってチャンクを作る
chunk_size=200, # チャンクの最大サイズ
chunk_overlap=0, # チャンク同士の重なりの許容量
length_function=len,
)
docs = loader.load_and_split(text_splitter)
vectorstore = Chroma.from_documents(
docs, GoogleGenerativeAIEmbeddings(model="models/text-embedding-004")
)
llm = ChatGoogleGenerativeAI(model="gemini-1.5-flash")
prompt = hub.pull("langchain-ai/retrieval-qa-chat") # 中身はこちら https://smith.langchain.com/hub/langchain-ai/retrieval-qa-chat
combine_docs_chain = create_stuff_documents_chain(llm, prompt)
rag_chain = create_retrieval_chain(
vectorstore.as_retriever(search_kwargs={"k": 1}), combine_docs_chain
)
print(rag_chain.invoke({"input": "What are the characteristics of the Oriental Turtle Dove?"}))
print(rag_chain.invoke({"input": "Tell me the pattern of the rock dove?"}))
# Types of pigeons
The pigeons we often see around us are the rock dove and the turtle dove.
## Rock dove
The distinctive feature of the rock dove's appearance is the purplish gradient on its neck.
Rock doves are also called feral pigeons.
## Turtle dove
The distinctive feature of the turtle dove's appearance is the blue and white pattern on its neck.
Turtle doves chirp "de-de-po-po."
- 1つ目の質問: What are the characteristics of the Oriental Turtle Dove?

- documentsとしてturtle doveのセクションだけが渡されていることがわかります
- このドキュメントを元に回答が得られました
- 2つ目の質問: Tell me the pattern of the rock dove?

- documentsとしてrock doveのセクションだけが渡されています
VectorstoreIndexCreatorを使った書き方だと近傍数k=1を指定する方法がわからなかったり、ネット上にはRetrievalQAを使った非推奨コードも多く苦労しましたが、公式の移行ドキュメントで解決できました。
GraphRAG: 知識グラフの活用
先程はベクトル検索を使った情報検索でしたが、今度はグラフを使った情報検索です。
GraphRAGは、3種類の検索を扱います。
- グラフ検索
- 全文検索
- ベクトル検索
これらの検索結果を組み合わせて、ユーザーの質問に回答します。
LangChainとグラフデータベースNeo4jを使って実装できます。
Neo4jセットアップ
まずはNeo4jの環境構築から。
ここからダウンロードして、インストールします。
起動後の画面でDL時にブラウザに表示された「Activation Key」を入力します。
最初、「Movie DBMS」というExampleが起動しているので、「Stop」で停止します。
今回はグラフデータベースをローカルに作ります。
「Add」から「Local DBMS」を選択し、適当なパスワード(後に使います)を設定して作成します。
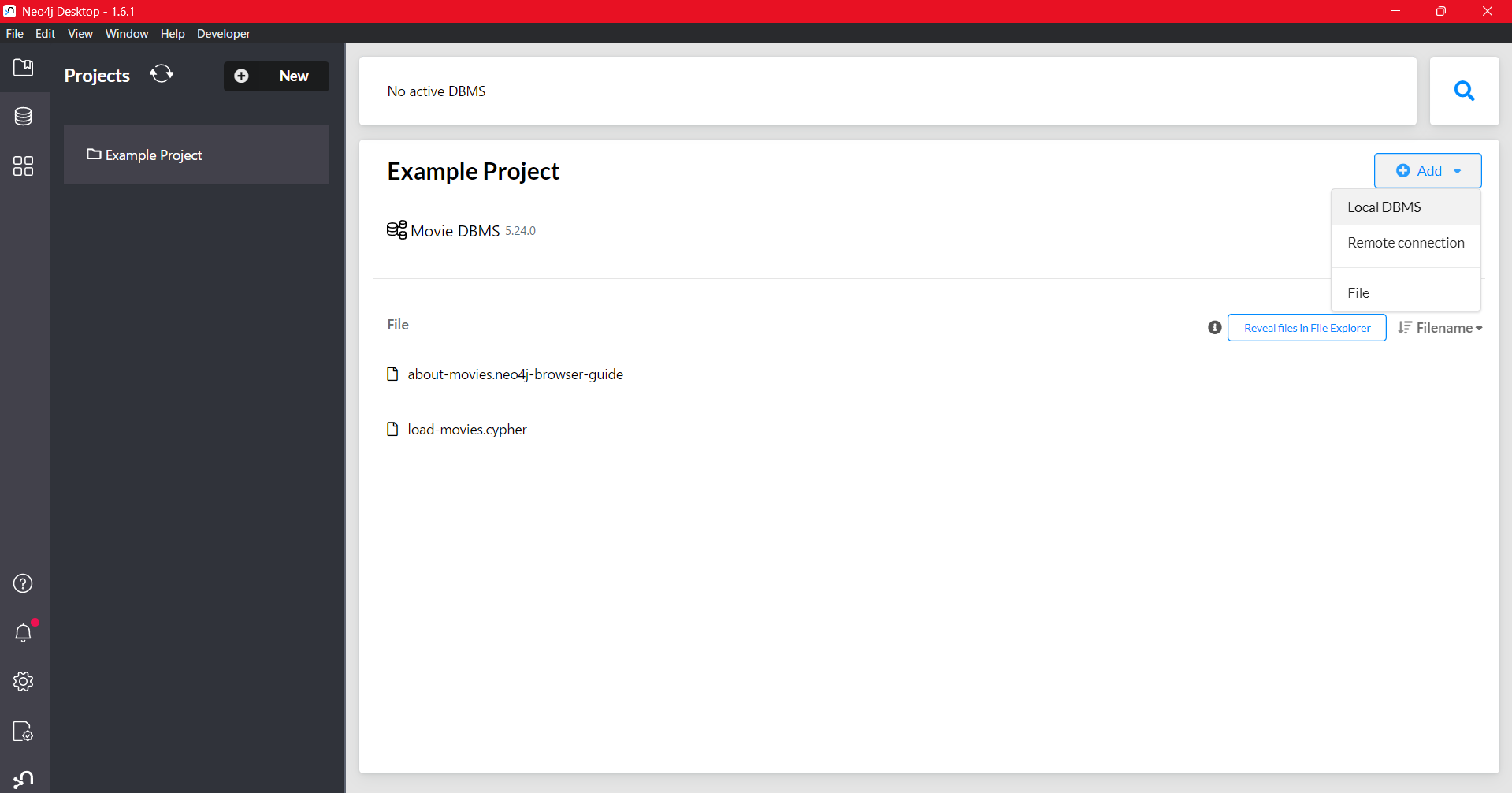
「Active」状態になったらOKです。
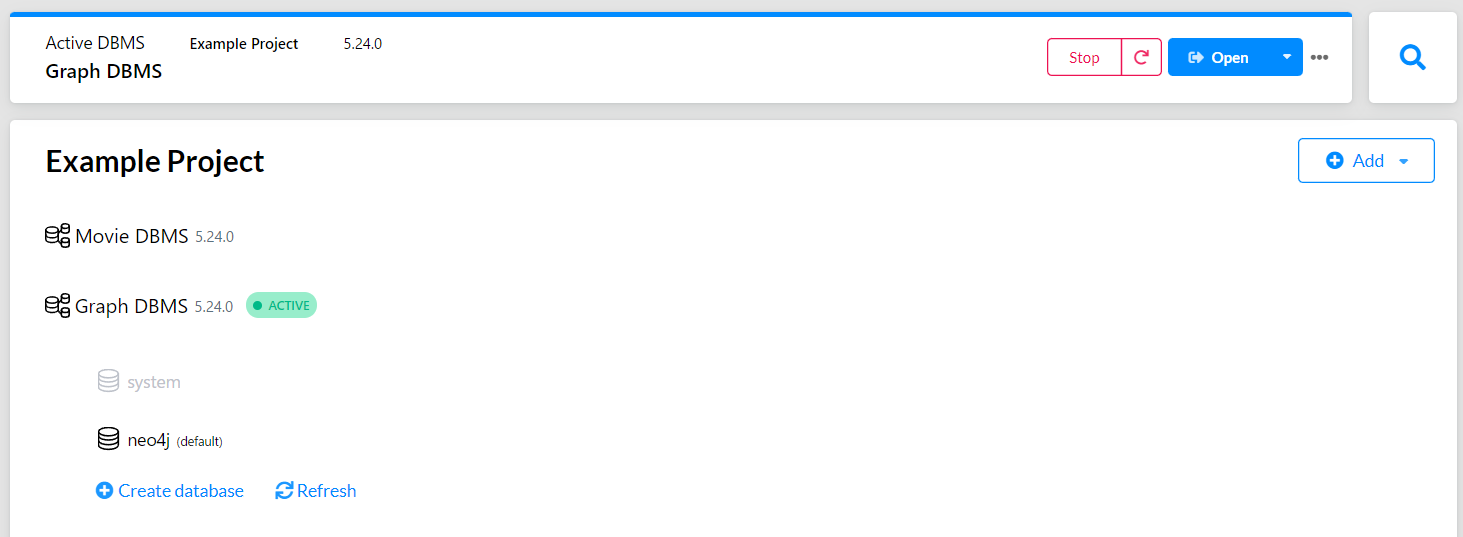
次に「Graph DBMS」を押したときに出る右ペインの「Plugins」から、「APOC」をインストールします。
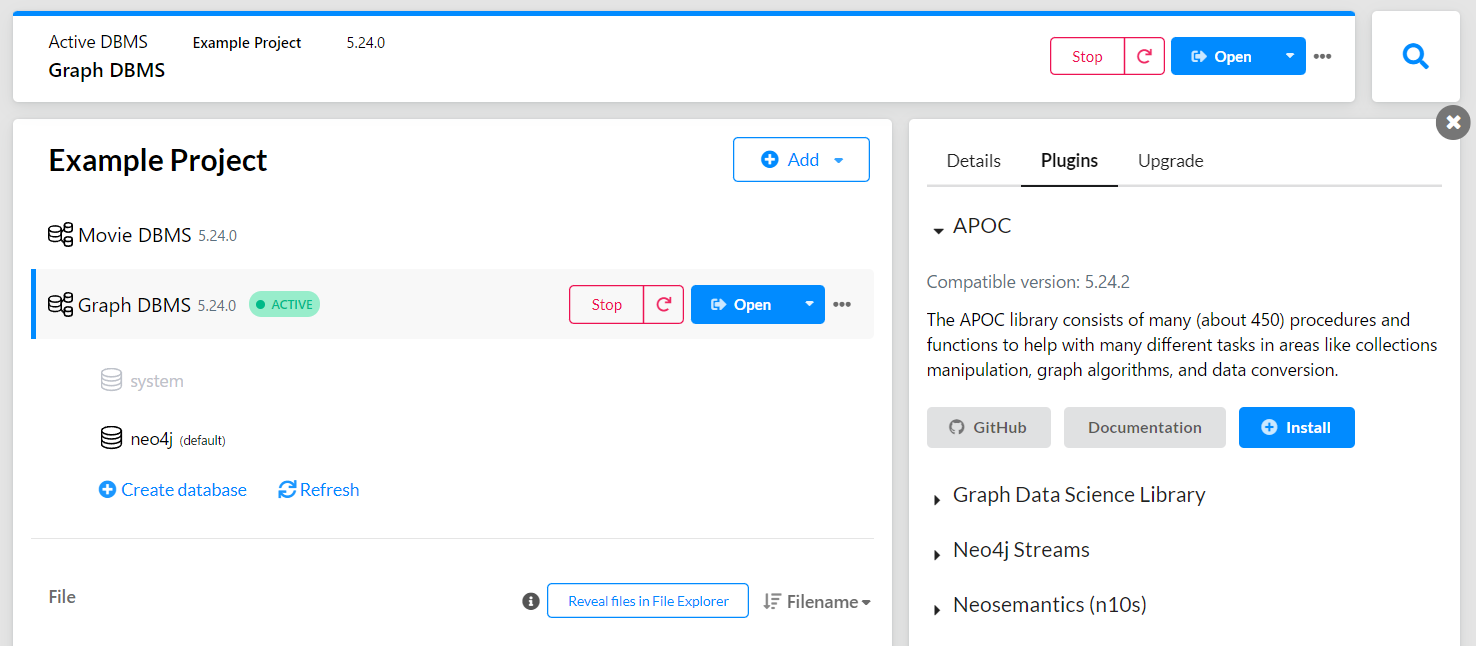
その後、「Stop」の右にある更新マークから「Graph DBMS」を再起動します。
これで準備完了です。
LangChainからの接続を確認しましょう。
pip install langchain_neo4j
from langchain_neo4j import Neo4jGraph
url = "bolt://localhost:7687" # LLMからのアクセス
username = "neo4j"
password = "password" # 設定したパスワード
graph = Neo4jGraph(url=url, username=username, password=password)
正常にセットアップできていれば、エラーが出ることなくこのプログラムは終了します。
テキストからグラフ化
テキストデータからグラフに変換します。
RAGのときに使ったsample.txtを使います。
まず、テキストからドキュメントへ分割します。
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import TokenTextSplitter
raw_documents = TextLoader("./sample.txt").load()
text_splitter = TokenTextSplitter(chunk_size=64, chunk_overlap=16)
documents = text_splitter.split_documents(raw_documents)
print(documents)
出力結果
[Document(metadata={'source': './sample.txt'}, page_content="# Types of pigeons\nThe pigeons we often see around us are the rock dove and the turtle dove.\n\n## Rock dove\nThe distinctive feature of the rock dove's appearance is the purplish gradient on its neck.\nRock doves are also called feral pigeons.\n\n## Turtle dove"), Document(metadata={'source': './sample.txt'}, page_content='\nRock doves are also called feral pigeons.\n\n## Turtle dove\nThe distinctive feature of the turtle dove's appearance is the blue and white pattern on its neck.\nTurtle doves chirp "de-de-po-po."\n')]
テキストデータから、適当なチャンクサイズでDocumentという単位に分割しました。
今回は小さいテキストファイルなので、Documentが1つだけできました。
次にドキュメントからグラフデータに変換します。
pip install langchain_experimental
from langchain_google_genai import GoogleGenerativeAI # ChatGoogleGenerativeAIだとなぜかエラーが出た
from langchain_experimental.graph_transformers import LLMGraphTransformer
llm = GoogleGenerativeAI(model="gemini-1.5-flash")
llm_transformer = LLMGraphTransformer(llm=llm)
graph_documents = llm_transformer.convert_to_graph_documents(documents)
print(graph_documents)
出力結果
[GraphDocument(nodes=[Node(id='rock dove', type='Bird', properties={}), Node(id='pigeon', type='Bird', properties={}), Node(id='purplish gradient on its neck', type='Characteristic', properties={}), Node(id='feral pigeons', type='Bird', properties={}), Node(id='turtle dove', type='Bird', properties={})], relationships=[Relationship(source=Node(id='rock dove', type='Bird', properties={}), target=Node(id='pigeon', type='Bird', properties={}), type='IS_A_TYPE_OF', properties={}), Relationship(source=Node(id='turtle dove', type='Bird', properties={}), target=Node(id='pigeon', type='Bird', properties={}), type='IS_A_TYPE_OF', properties={}), Relationship(source=Node(id='rock dove', type='Bird', properties={}), target=Node(id='purplish gradient on its neck', type='Characteristic', properties={}), type='HAS_CHARACTERISTIC', properties={}), Relationship(source=Node(id='rock dove', type='Bird', properties={}), target=Node(id='feral pigeons', type='Bird', properties={}), type='ALSO_KNOWN_AS', properties={})], source=Document(metadata={'source': './sample.txt'}, page_content="# Types of pigeons\nThe pigeons we often see around us are the rock dove and the turtle dove.\n\n## Rock dove\nThe distinctive feature of the rock dove's appearance is the purplish gradient on its neck.\nRock doves are also called feral pigeons.\n\n## Turtle dove")), GraphDocument(nodes=[Node(id='de-de-po-po', type='Sound', properties={}), Node(id='blue and white pattern on its neck', type='Characteristic', properties={}), Node(id='turtle doves', type='Bird', properties={}), Node(id='Rock doves', type='Bird', properties={}), Node(id='feral pigeons', type='Bird', properties={}), Node(id='turtle dove', type='Bird', properties={})], relationships=[Relationship(source=Node(id='Rock doves', type='Bird', properties={}), target=Node(id='feral pigeons', type='Bird', properties={}), type='ALSO_KNOWN_AS', properties={}), Relationship(source=Node(id='turtle dove', type='Bird', properties={}), target=Node(id='blue and white pattern on its neck', type='Characteristic', properties={}), type='HAS_CHARACTERISTIC', properties={}), Relationship(source=Node(id='turtle doves', type='Bird', properties={}), target=Node(id='de-de-po-po', type='Sound', properties={}), type='MAKES_SOUND', properties={})], source=Document(metadata={'source': './sample.txt'}, page_content='\nRock doves are also called feral pigeons.\n\n## Turtle dove\nThe distinctive feature of the turtle dove's appearance is the blue and white pattern on its neck.\nTurtle doves chirp "de-de-po-po."\n'))]
GraphDocumentというクラスで、NodeやRelationshipが記載されています。
from langchain_neo4j import Neo4jGraph
url = "bolt://localhost:7687"
username = "neo4j"
password = "password"
graph = Neo4jGraph(url=url, username=username, password=password)
graph.add_graph_documents(graph_documents, baseEntityLabel=True, include_source=True)
-
baseEntityLabel=True: 各データに対して基本的なエンティティラベルを追加 -
include_source=True: ドキュメントのソース情報をグラフに保存する
「Neo4j Desktop」右上の「Open」から、ブラウザでグラフを確認できます。
起動後、左側のデータベースマークを押した後、「Node labels」から「*」を押すとこのような画面が現れました。
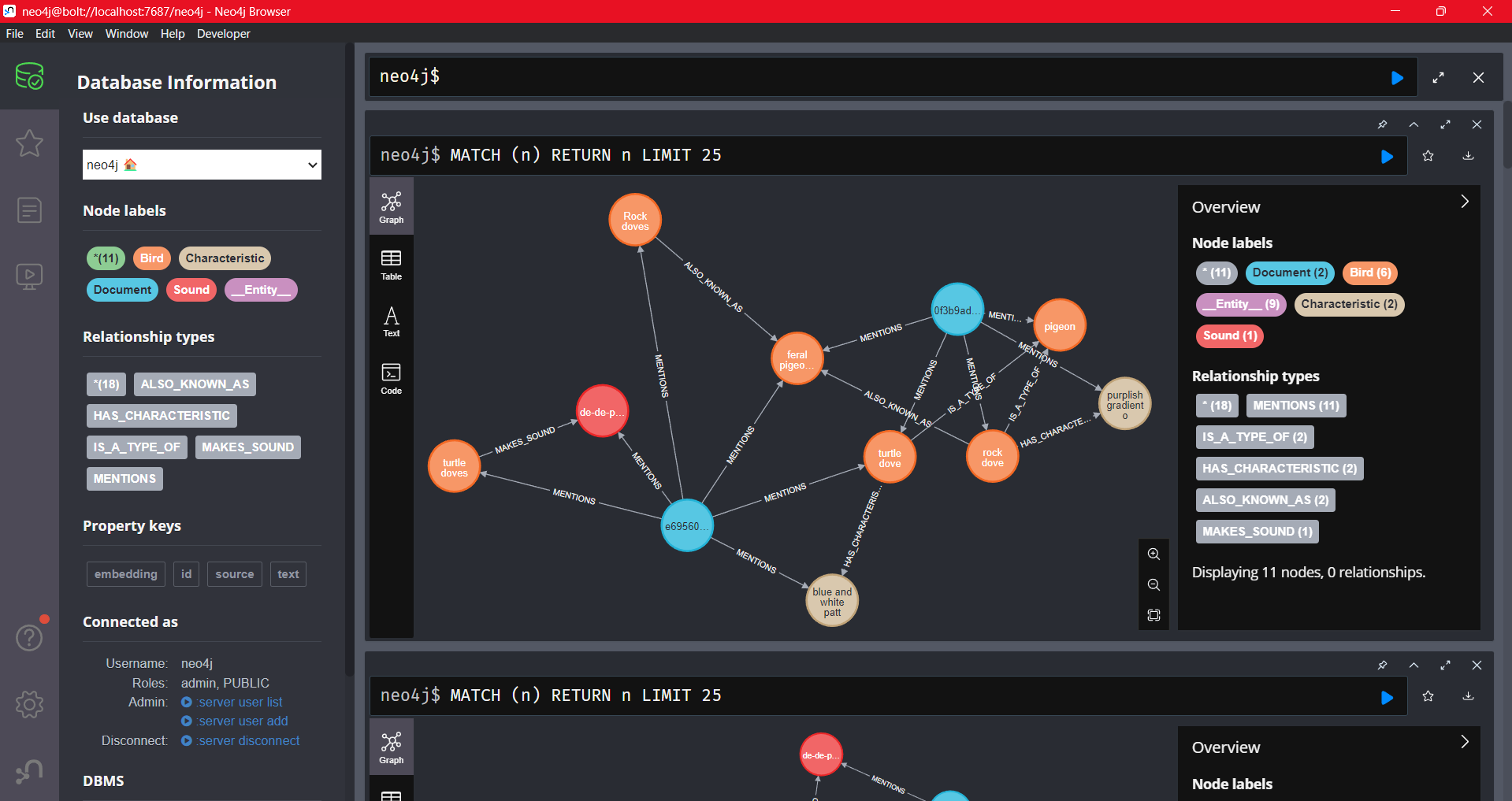
テキストをLLMに与えただけなのに、勝手にグラフができるので驚きですね。
何度も実行する用にグラフをすべて削除するクエリを置いておきます。
MATCH (n) DETACH DELETE n;
Neo4jの上の窓から実行できます。
全文検索とベクトル検索のハイブリッド検索 + グラフ検索
GraphRAGでは、3つの検索を扱うと説明しました。
まずは、全文検索とベクトル検索をできるようにインデックスを作成します。
from langchain_community.vectorstores import Neo4jVector
from langchain_google_genai import GoogleGenerativeAIEmbeddings
# グラフからインデックスを生成する
vector_index = Neo4jVector.from_existing_graph(
GoogleGenerativeAIEmbeddings(model="models/text-embedding-004"), # Embeddingモデル
url=url,
username=username,
password=password,
search_type="hybrid", # 全文検索とベクトル検索のハイブリッド
node_label="Document", # 検索対象ノードのラベル
text_node_properties=["text"], # 検索対象プロパティ
embedding_node_property="embedding",
)
# 全文検索インデックスの作成
graph.query("CREATE FULLTEXT INDEX entity IF NOT EXISTS FOR (e:__Entity__) ON EACH [e.id]")
今回最初のチャンク分割により生成されたDocumentラベルのあるノードを検索対象とし、そのノードのtextプロパティをベクトル化することを意味しています。
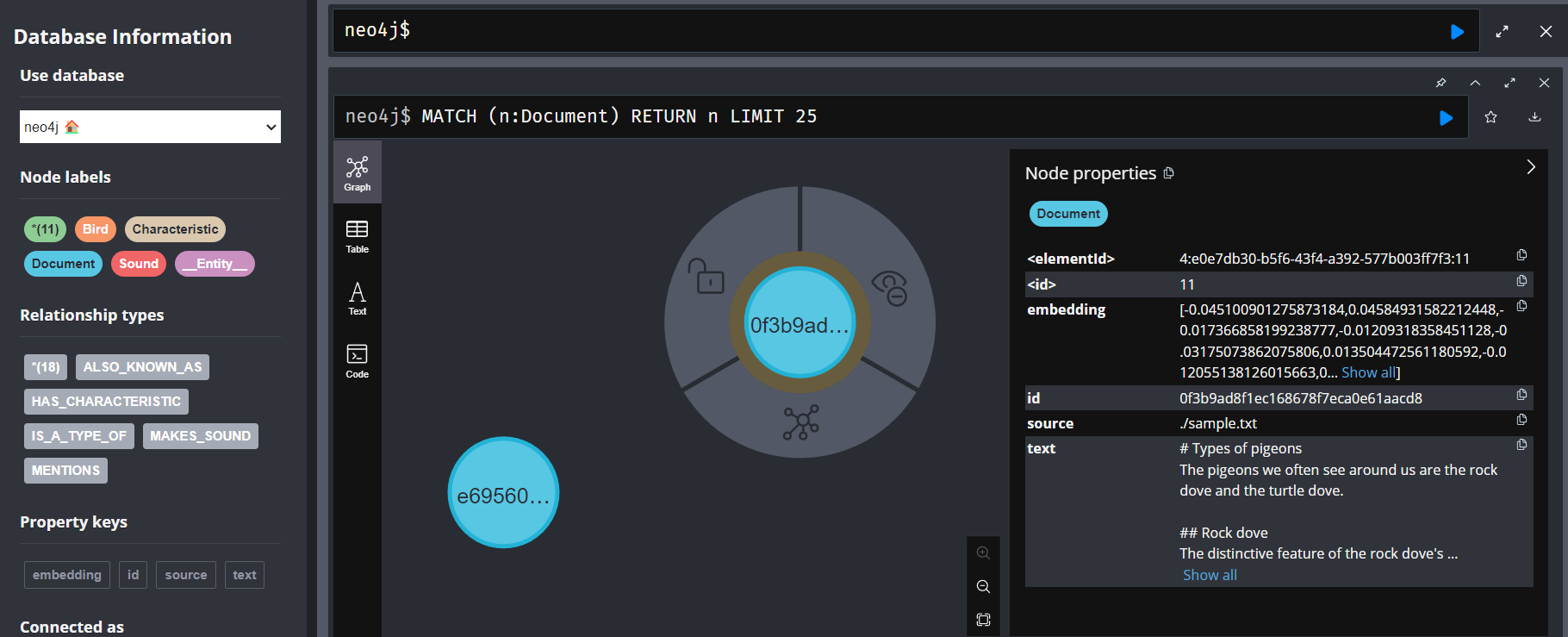
この時点でクエリを投げてみます。
from langchain.chains import RetrievalQAWithSourcesChain
chain = RetrievalQAWithSourcesChain.from_chain_type(
llm,
chain_type="stuff", # 検索結果として得られたすべてのドキュメントを「そのまま(stuff)」LLMに渡す
retriever=vector_index.as_retriever(),
verbose=True,
)
print(chain.invoke("Tell me the pattern of the rock dove"))
print(chain.invoke("Please tell me the type of pigeon"))
{'question': 'Tell me the pattern of the rock dove', 'answer': "The distinctive feature of the rock dove's appearance is a purplish gradient on its neck.\n", 'sources': './sample.txt'}
{'question': 'Please tell me the type of pigeon', 'answer': 'The provided text mentions two types of pigeons: the rock dove (also called feral pigeon) and the turtle dove.\n', 'sources': './sample.txt'}
ドキュメント2つしかありませんし、普通に回答が得られました。
ここまではグラフを活用できていません。
次にグラフを活用した検索を行います。
from langchain_neo4j import GraphCypherQAChain
qa = GraphCypherQAChain.from_llm(
llm=llm,
graph=graph,
allow_dangerous_requests=True,
verbose=True,
)
print(qa.invoke("Tell me the pattern of the rock dove"))
print(qa.invoke("Please tell me the type of pigeon"))
GraphCypherQAChainを使うと、自然言語の質問文からCypherクエリ(グラフデータベースへのクエリ)に変換して、そのクエリ結果を元に回答してくれます。
> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH p=(b:Bird)-[r*..]->(c:Characteristic) WHERE b.id = 'rock dove' RETURN p
Full Context:
[{'p': [{'id': 'rock dove'}, 'HAS_CHARACTERISTIC', {'id': 'purplish gradient on its neck'}]}]
> Finished chain.
{'query': 'Tell me the pattern of the rock dove', 'result': 'The rock dove has a purplish gradient on its neck.\n'}
> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH p=(b:Bird)-[:IS_A]->(a:Animal) WHERE b.id CONTAINS 'pigeon' RETURN a.id, labels(a)
Full Context:
[]
> Finished chain.
{'query': 'Please tell me the type of pigeon', 'result': "I don't know the answer.\n"}
出力結果から、Cypherクエリに変換している過程と結果が見えます。
1つ目の質問には回答できましたが、2つ目の質問には答えられませんでした。
何回か実行してみましたが、かなり不安定で、1つ目にも答えられないことがあります。
試してみて、グラフ検索には難所が2つあることがわかりました。
- LLMによるグラフ構築の運
- LLMによるCypherクエリの運
LLMによるグラフ構築には、実行するたびに構築されるグラフが変わりますが、いかに良い表現でグラフにできるかが重要になってきます。
あえてグラフをリセットせずに、複数回グラフ構築を行った結果に対してクエリを投げたところ、回答できる確率が上がったので、グラフ構築部分の段階でいろんな表現パターンで構築しておくことが、クエリに回答できる確率を上げる行為だと言えます。
後者のクエリ生成を頑張る可能性もあります。
GraphCypherQAChainには、プロンプトも渡せるので、いかにうまいCypherクエリを生成できるかのプロンプトゲーになりそうです。
今回は「ハイブリッド検索(全文検索とベクトル検索)」と「グラフ検索」をそれぞれ独立に実行しましたが、実際にはこれらの検索結果をコンテキストとして回答を作ることになります。
なお、MicrosoftがGraphRAGライブラリを公開したのですが、OpenAI以外での使い方がわからなかったので、試すことができませんでした。
こちらの結果を見てみると、かなり良さそうなので、OpenAIのAPIが使える方はこちらから試すと良いと思います。
参考:
- GraphRAGをわかりやすく解説
- LLMによるナレッジグラフの作成とハイブリッド検索 + RAG
- Connect to a Neo4j DBMS
- Neo4j Vector Index
- Microsoft「GraphRAG」とLangchainの知識グラフを活用したRAGを比較
最近増えているAI Agent
PydanticAI: 型に強い
PydanticAIは、AI Agentを書けるライブラリです。
ドキュメントを見つつ軽く使ってみた感想を書きます。
-
- Agentの入出力に型を定義できる
- エラー時に修正するようリトライ設定できる
- 「出力結果を型に沿うよう修正する」作業のリトライ
- LangChainでいうところの
OutputFixingParser
- LangChainでいうところの
- 定義した関数(ツール)内でエラーをraiseすることによるツール単位のリトライ
- ツール内で
raise ModelRetry("もっと情報よこせ")みたいなことができる
- ツール内で
- 「出力結果を型に沿うよう修正する」作業のリトライ
- mypyが使える(ソースコード時点の型チェック)
-
モデルに依存しないについて。
-
Agent("gemini-1.5-flash")やAgent("openai:gpt-4o")というように文字列で指定できる- LangChainだとモデルを変える場合、import先を変えないといけないかった
-
-
ストリーミング構造化出力について。
{"name": "aaa"}{"name": "aaa", "age": 20}{"name": "aaa", "age": 20, "like": "bbb"}
みたいなことができる。これは驚き。いつ使うんだろう。
-
比較的短いコードで書ける
ユーザーと対話するAIfrom pydantic_ai import Agent agent = Agent("gemini-1.5-flash") messages = [] while True: # Ctrl+Cで終了してください result = agent.run_sync(input("USER: "), message_history=messages) print("AI: ", result.data) messages = result.all_messages()
AG2 (AutoGen): マルチエージェント
AG2 (AutoGen)は、マルチエージェントの処理を書きやすいライブラリです。
pip install ag2[gemini]
AI同士に漫才をさせてみました。
import os
from autogen import ConversableAgent
takeshi = ConversableAgent(
"たけし",
system_message="あなたの名前はたけしです。漫才師のボケです。漫才をしてください。",
llm_config={
"config_list": [
{
"model": "gemini-1.5-flash",
"api_key": os.environ.get("GOOGLE_API_KEY"),
"api_type": "google",
}
]
},
human_input_mode="NEVER", # 人間が介入しない設定
is_termination_msg=lambda msg: "もういいぜ" in msg["content"], # 終了条件
)
mikio = ConversableAgent(
"みきお",
system_message="あなたの名前はみきおです。漫才師のツッコミです。漫才をしてください。5回会話のリレーをしたら「もういいぜ」と言って終わらせてください。",
llm_config={
"config_list": [
{
"model": "gemini-1.5-flash",
"api_key": os.environ.get("GOOGLE_API_KEY"),
"api_type": "google",
}
]
},
human_input_mode="NEVER", # 人間が介入しない設定
)
# 2人のAIエージェントを紐づける
result = takeshi.initiate_chat(
mikio, message="この間コンビニに行ったんだけどさ。", # takeshiに最初の会話を付与
max_turns=10 # 最大ターン数で無限ループにならないようにする
)
謎の漫才ができました。
たけし (to みきお):
この間コンビニに行ったんだけどさ。
--------------------------------------------------------------------------------
みきお (to たけし):
へぇー、コンビニかぁ。何買ったの?宝くじでも買ったの?当たってたら今頃ハワイで優雅に過ごしてるんじゃねえの?
--------------------------------------------------------------------------------
たけし (to みきお):
いやいやいや!宝くじは買ってないよ!だってさ、店員さんに「宝くじありますか?」って聞いたらさ、「ありますけど… **あなた に当たる確率の方が低いですよ**」って言われたんだもん! ショックで、結局、かき氷と、賞味期限切れ間近のバナナミルクしか買わなかったよ!
--------------------------------------------------------------------------------
みきお (to たけし):
はっはっは! 店員さん、毒舌すぎだろ! 客商売としてどうなの!? それよりさ、賞味期限切れ間近のバナナミルク… 飲むの勇 気いるな! もしかして、すでに… 変な味がしたとか?
--------------------------------------------------------------------------------
たけし (to みきお):
いやいや、大丈夫! だってさ、**賞味期限が「間近」って書いてあっただけで、「切れ」って書いてなかったんだもん!** まだイケる!…多分… ちょっとヨーグルトっぽい酸味があったけどさ! うん、ヨーグルト風味のバナナミルクってことで! ポジティブに考えるんだ!
--------------------------------------------------------------------------------
みきお (to たけし):
ポジティブ思考もいいけどさ、胃腸が丈夫じゃないと危険だよ! ヨーグルト風味のバナナミルク… 想像しただけでちょっとゾッと するわ。 もういいぜ。
--------------------------------------------------------------------------------
会話の保存設定を自分で書かなくてよいので、シミュレーションするのに適してますね。
マルチエージェントを得意とするライブラリとしてCrewAIもあります。
きりが無いので今回は省略します。
browser-use: ブラウザ操作
browser-useは、ブラウザを操作できるエージェントです。
※python3.11以上が必要です。
pip install browser-useplaywright install
import os
import asyncio
from langchain_google_genai import ChatGoogleGenerativeAI
from browser_use import Agent
async def main():
agent = Agent(
task="Qiitaのユーザー@birdwatcherについて、人気の記事を教えてください。",
llm=ChatGoogleGenerativeAI(model="gemini-1.5-flash"),
)
result = await agent.run()
print(result)
asyncio.run(main())
勝手にブラウザが開いて情報取得する様子を確認できました。
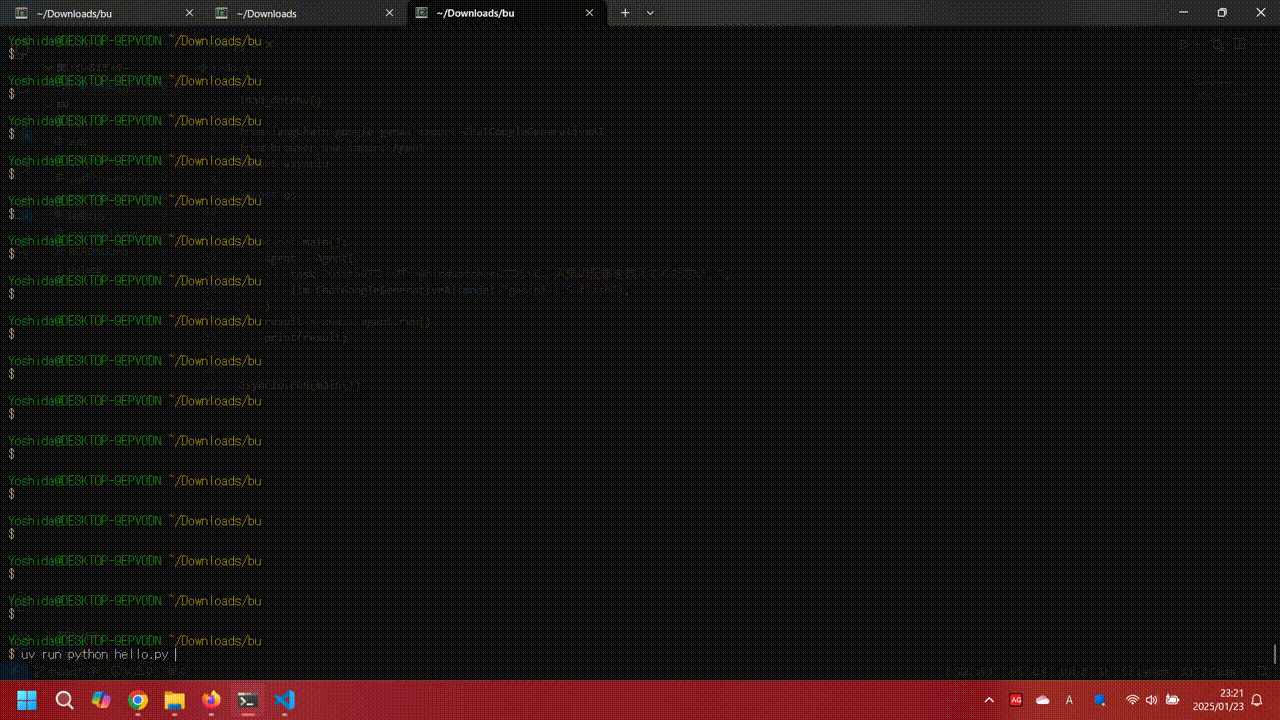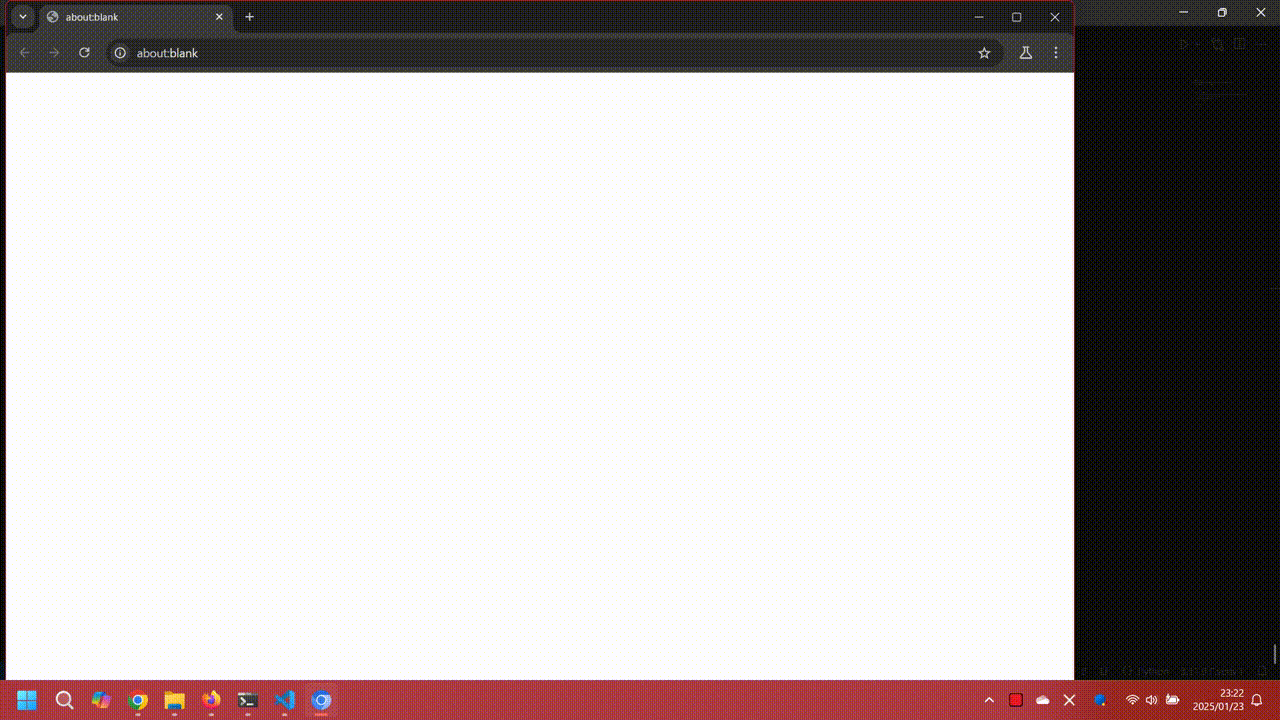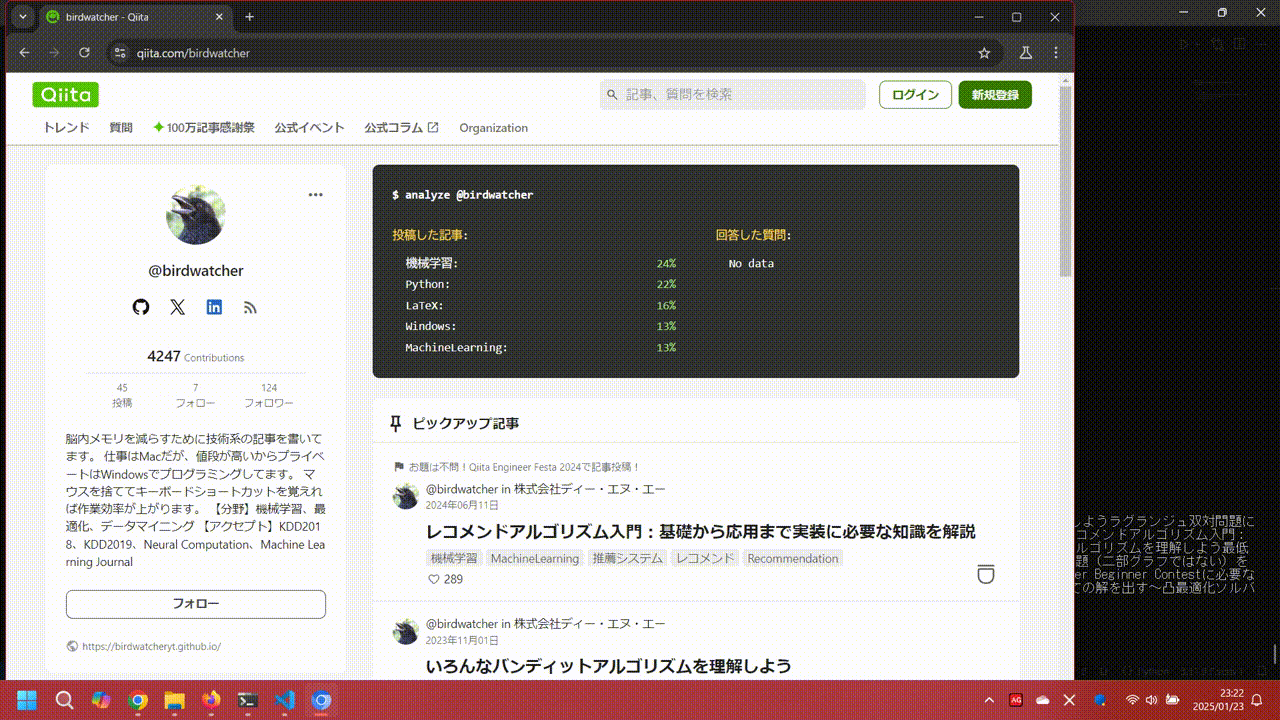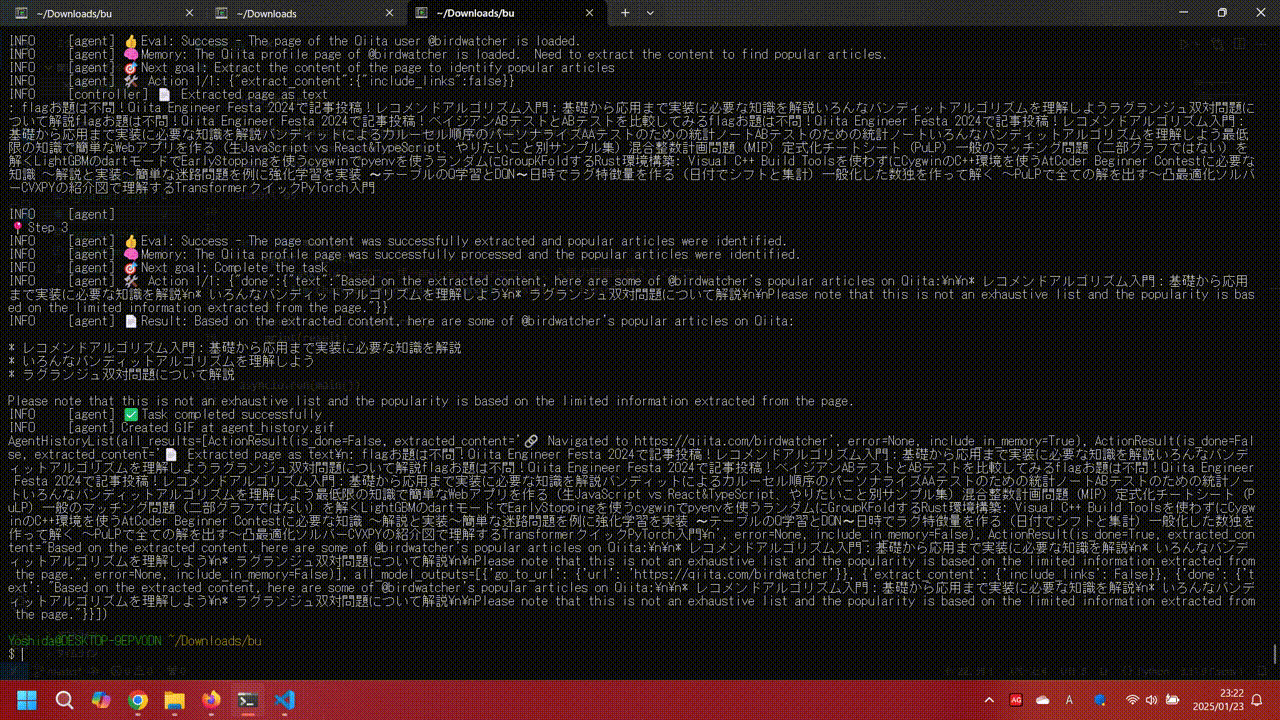
仕組みはこちらの記事にまとめられていました。
あとがき
最近の生成AIの技術のスピードが凄まじく、キャッチアップが大変でした。
そして、記事を書いている最中にも次々と新しい技術が出てきて、まとめるのが難しかったです。
技術の流れと同時にライブラリのバージョンアップもあり、langchainは非推奨のWarningを解消するのが大変でした。
LLMが発展し、ユーザーへの自然な応答が現実的になったことにより、できることの幅が広がりました。
今後も驚くような技術が登場することでしょう。
LLMと何かを組み合わせると、驚くようなユーザーの体験を実現できます。
たとえば、LLMと音声合成を組み合わせると、リアルタイム音声対話ができますよね。
今回紹介しませんでしたが、OpenAIからRealtime APIが出てきたり、Cotomoも有名ですね。
なお、生成AI系の最新情報を手に入れるのはX(Twitter)がおすすめです。
情報収集用のXアカウントを作って、生成AI系のPostをしているユーザーをフォローしまくりましょう。
まだ読んでいないけど、勉強になりそうな資料:
紹介できなかったもの
ローカルPCやGoogle Colaboratory上でも実行できなかったものたち。
ディスク容量不足やメモリ不足で落ちました。
-
BLIP2
- Vision-Language Model
- できること
- キャプション生成
- VQA(Visual Question Answering)
- 画像と質問を入力すると、その画像に基づいた質問への回答を生成
- 例: 画像を見て「この車は何色ですか?」と質問すると「赤色です」と回答
- 画像検索(テキストから関連する画像を検索したり、画像から関連するテキストを検索)
-
pip install salesforce-lavisBLIP2によるVQAの例(未検証)import torch from PIL import Image device = torch.device("cuda") if torch.cuda.is_available() else "cpu" raw_image = Image.open("ducks_image.jpg").convert("RGB") import torch from lavis.models import load_model_and_preprocess model, vis_processors, _ = load_model_and_preprocess(name="blip2_t5", model_type="pretrain_flant5xxl", is_eval=True, device=device) image = vis_processors["eval"](raw_image).unsqueeze(0).to(device) model.generate({"image": image, "prompt": "Question: how many ducks are there? Answer:"})
-
LLaVA-NeXT
- オープンソースなマルチモーダルLLM
- ByteDance(TikTokの会社)の研究者らによって開発された
おまけ: lavisライブラリで画像embeddingを得る
import torch
from PIL import Image
# setup device to use
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# load sample image
raw_image = Image.open("./image.jpg").convert("RGB")
from lavis.models import load_model_and_preprocess
model, vis_processors, txt_processors = load_model_and_preprocess(name="blip_feature_extractor", model_type="base", is_eval=True, device=device)
image = vis_processors["eval"](raw_image).unsqueeze(0).to(device)
sample = {"image": image}
features_image = model.extract_features(sample, mode="image")
print(features_image.image_embeds.shape)
# torch.Size([1, 197, 768])
# (batch_size, num_query_token, feature_dim)
print(features_image.image_embeds)
# features_image.image_embeds[:,0,:]
# か
# features_image.image_embeds.mean(axis=1)
# で768次元
# より小さい次元のやつを使うなら
# low-dimensional projected features
print(features_image.image_embeds_proj.shape)
# torch.Size([1, 197, 256])
print(features_image.image_embeds_proj)
# 同じ用に0を取り出すか平均取るかで256次元