まえがき
DeNAでAIプロダクト開発をしている @birdwatcher です。
今回は、個人的に趣味で作ったプロダクトの紹介です。
業務・趣味に限らず、AIプロダクト開発における工夫や学びを添えて紹介します。
最近はLLM単体の能力が向上し、できることが増えていますが、組み合わせることで面白いプロダクトを作れると思っています。
無料で学ぶ!生成AIとバズった技術まとめで紹介した技術を寄せ集めてプログラムしたお話です。(今回の開発も無料枠で行っています)
$\tiny{\text{音声合成:AivisSpeech れな,もえ(現実20代女子AIボイチェン@リアボVC公式モデル)}}$
$\tiny{\text{画像生成:Gemini 2.0 Flash Image Generation}}$
対象読者
- 生成AIを活用したプロダクト開発に興味がある方
- 細かい技術的な工夫に興味がある方
概要
複数のAIと対話できるプロダクトです。
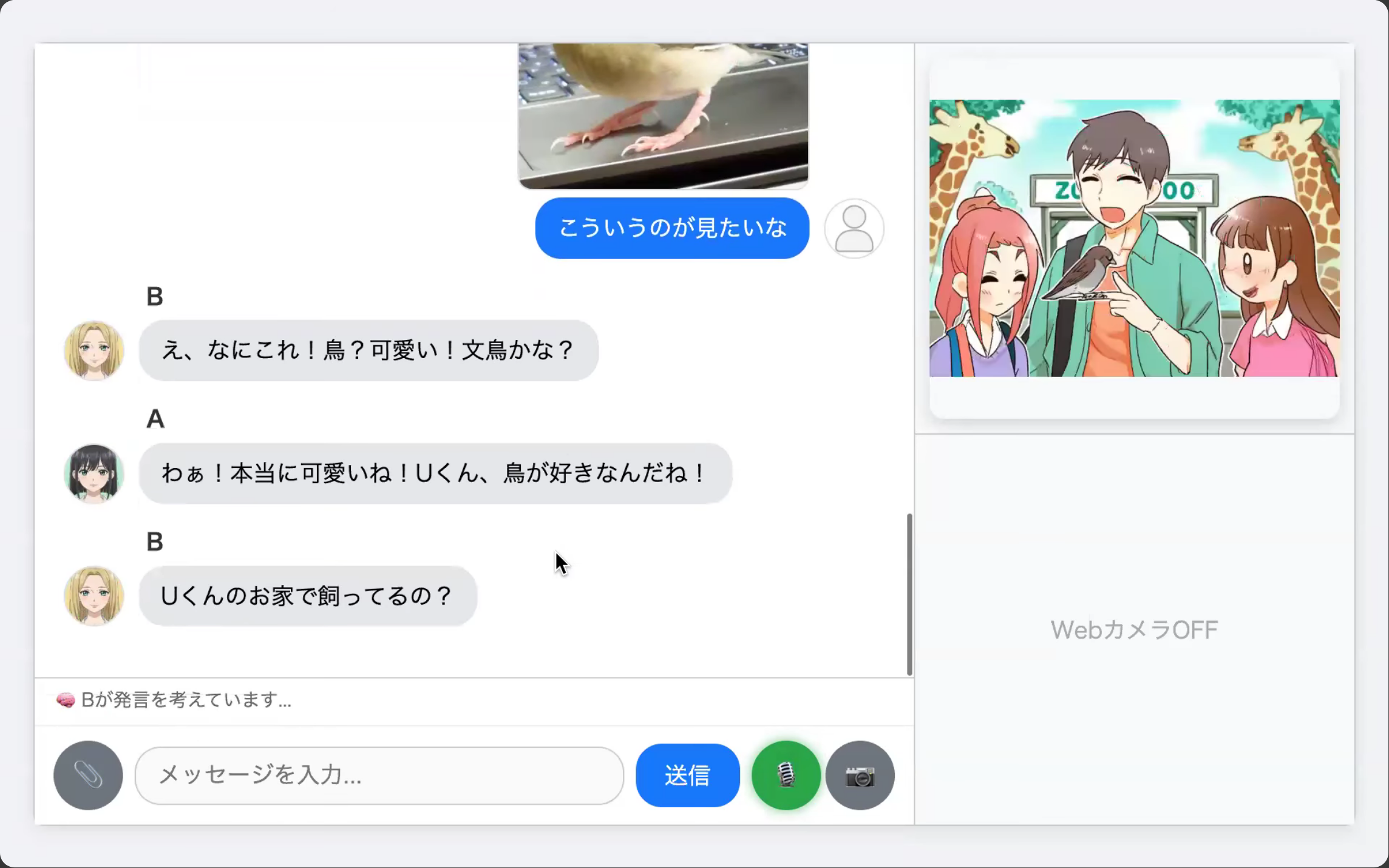
(右上の画像は、Gemini 2.0 Flash image Generationのもの)
- テキスト生成(LLM/VLM):Ollama, Gemini, Openrouter
- 画像生成:Gemini 2.0 Flash image generation (preview), FastSD CPU
- 音声合成(TTS):VoiceVox, Coeiroink, AivisSpeech
- 音声認識(ASR):WebKit, Whisper, Vosk, Gemini
- 画像入力:画像添付, Webカメラ
全部ローカルか無料枠の範囲でやっています。
技術
LLMについて
LangChainを使って開発をしています。
LangChainの基礎についてはこちらにまとめています。
今回のプログラムは、複数のLLMによって構成されます。
- 話者決定LLM
- 発話内容生成LLM
- 状況説明LLM
話者決定LLM
対話履歴から次に話すべき話者を判定させます。
確実に次の話者を失敗なく生成させるために構造化出力を使います。
from pydantic import BaseModel
from typing import Literal
class SpeakerSchema(BaseModel):
speaker: Literal["User", "Alice", "Bob"]
prompt = PromptTemplate.from_template("...省略...")
llm = ChatGoogleGenerativeAI(model="gemini-2.0-flash")
chain = prompt | llm.with_structured_output(SpeakerSchema)
このように構造化出力を使用することで、「です」や「ます」など無駄な出力をさせることなく、候補の中から確実に選ぶ事ができます。
今回の話者決定タスクでは、同じユーザーが連続して発言しないようにスキーマを動的に構築する工夫を入れています。
SpeakerSchema = type(
"SpeakerSchema", (BaseModel,), {
"__annotations__": {"speaker": Literal[tuple(candidates)]},
"speaker": ...,
}
)
LangChainの構造化出力について
LangChainの構造化出力の方法はいくつかあります。
- StructuredOutputParser
- PydanticOutputParser
- with_structured_output
公式ドキュメントではwith_structured_outputを推奨しています。
with_structured_outputを使うと、モデルが構造化出力に対応していればモデルのツールを使い、サポートしていないときは代わりのものを使うようです。
実際にトレースツールLangSmithで確認してみましょう。
-
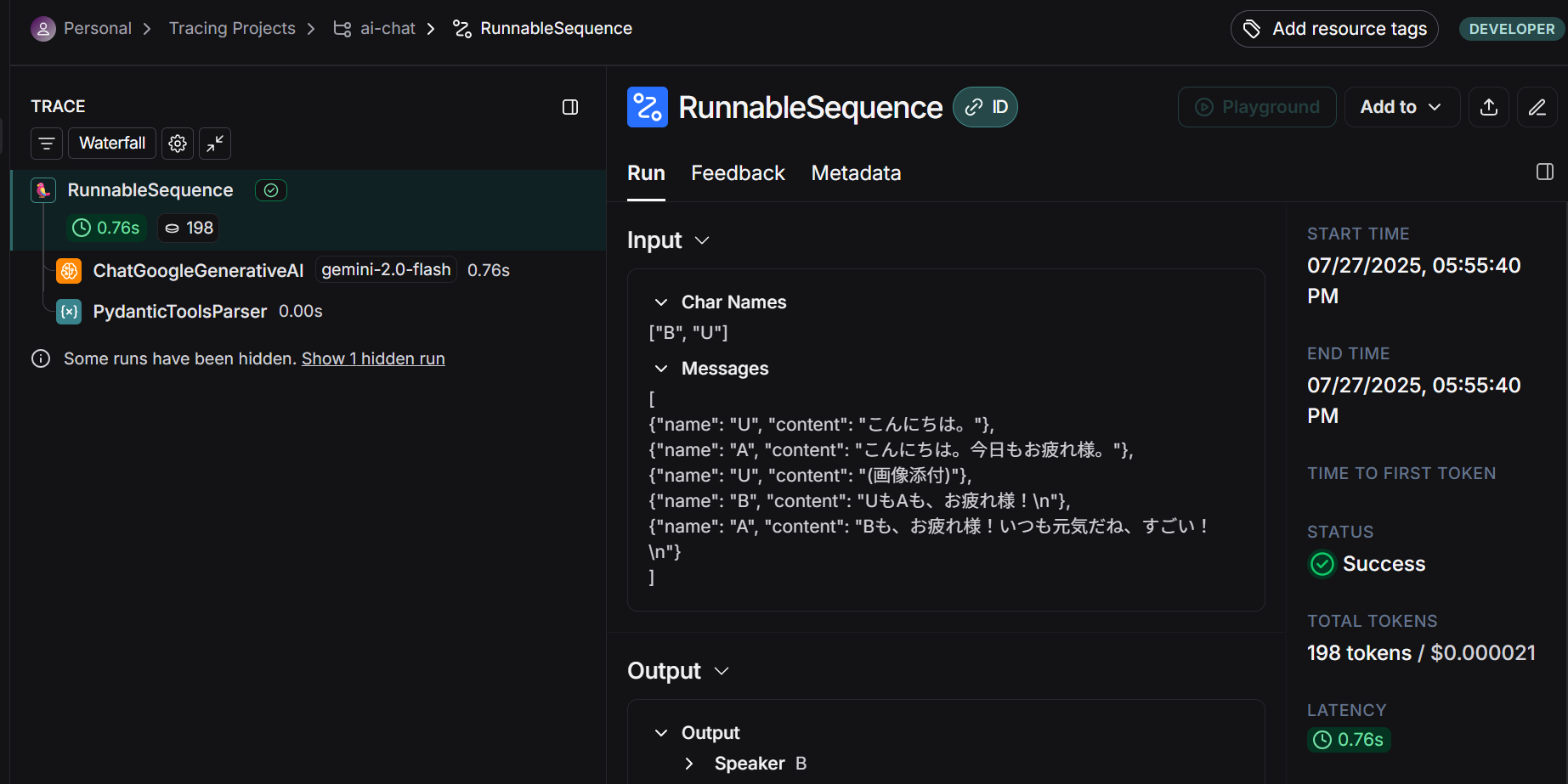
ChatGoogleGenerativeAI(gemini-2.0-flash)を使った場合:
-
ChatOllama(gemma3)を使った場合:
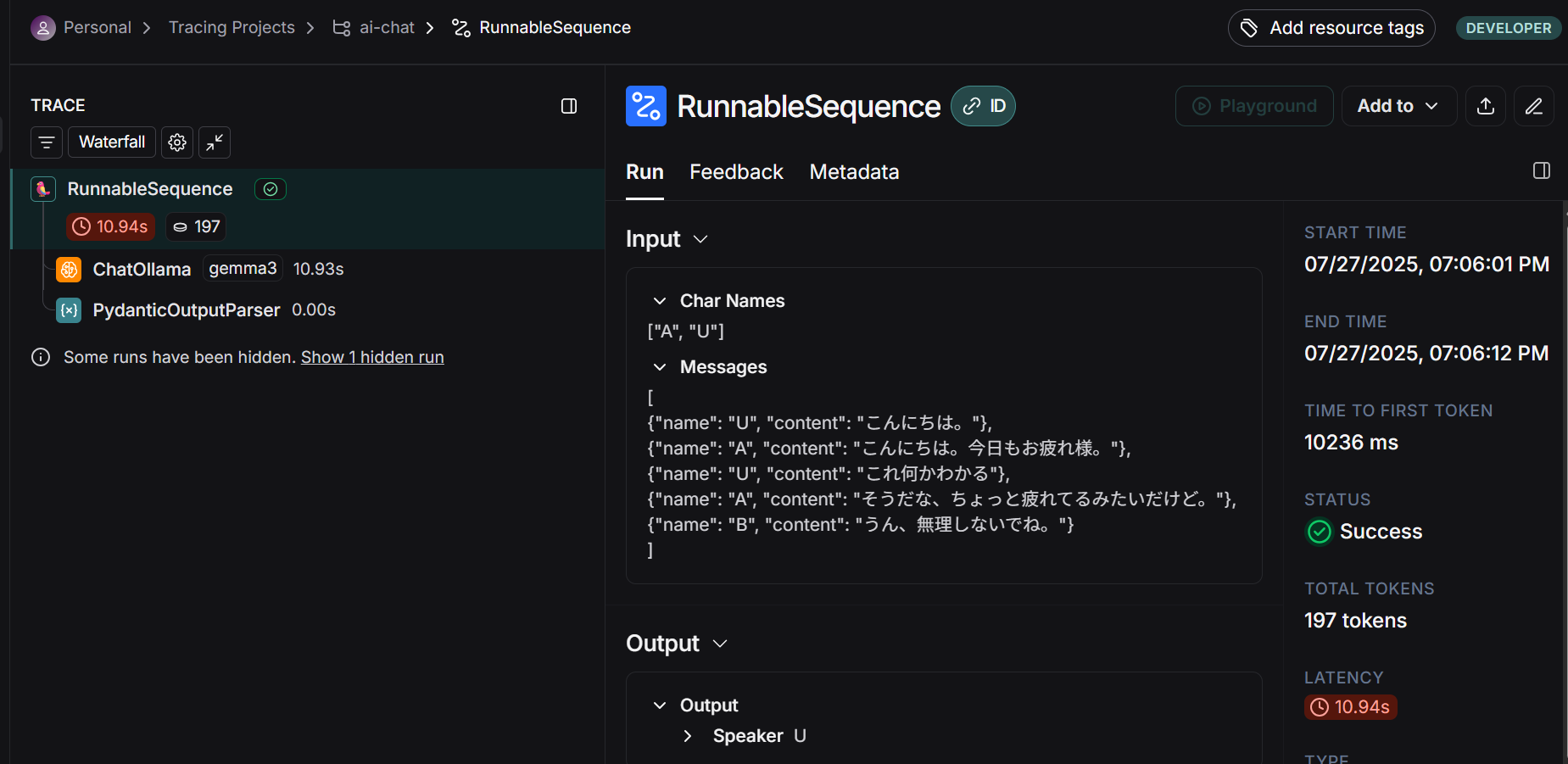
前者はPydanticToolParserであるのに対し、後者はPydanticOutputParserになっています。geminiはモデル自体が構造化出力をサポートしているのでToolが使われたが、GemmaはサポートしていないからOutputParserが使われたという挙動のようです。
では次はPydanticOutputParserで何が指示されるか構造化指示をする内部プロンプトを見てみましょう。
from pydantic import BaseModel, Field
from langchain.output_parsers import PydanticOutputParser
class Bird(BaseModel):
name: str = Field(description="名前")
length: int = Field(description="体長(cm)")
output_parser = PydanticOutputParser(pydantic_object=Bird)
print(output_parser.get_format_instructions())
# 【出力結果】
# The output should be formatted as a JSON instance that conforms to the JSON schema below.
#
# As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}
# the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
#
# Here is the output schema:
# ```
# {"properties": {"name": {"description": "名前", "title": "Name", "type": "string"}, "length": {"description": "体長(cm)", "title": "Length", "type": "integer"}}, "required": ["name", "length"]}
# ```
単純な2つの属性を持つ構造化出力を指示するのに多くの複雑そうな指示文が確認できました。
一方、StructuredOutputParserでは、
from langchain.output_parsers import ResponseSchema, StructuredOutputParser
response_schemas = [
ResponseSchema(name="name", description="名前", type="string"),
ResponseSchema(name="length", description="体長(cm)", type="int"),
]
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
print(output_parser.get_format_instructions())
# 【出力結果】
# The output should be a markdown code snippet formatted in the following schema, including the leading and trailing "```json" and "```":
#
# ```json
# {
# "name": string // 名前
# "length": int // 体長(cm)
# }
# ```
非常にシンプルで直感的な指示が生成文を確認できました。
これらの指示文をプロンプトに埋め込んで使うことを思うと、シンプルな(LiteralやList、階層構造がない)場合はStructuredOutputParserを使いたいなという気持ちになりました。(どちらが良いかは定かではないです。)
構造化出力は失敗することがあります。複雑な構造化出力であるほど失敗可能性が高まります。
失敗したときの対策として次の工夫ができます。
from langchain_core.exceptions import OutputParserException
chain.with_retry(
retry_if_exception_type=(OutputParserException,), # 構造化出力失敗した場合
stop_after_attempt=3, # リトライ回数
wait_exponential_jitter=False, # 指数バックオフをOFFに
)
これは単純にリトライをするということですが、別のLLMに出力の修正を依頼することができます。
from langchain.output_parsers import OutputFixingParser, PydanticOutputParser
base_parser = PydanticOutputParser(pydantic_object=Bird)
parser = OutputFixingParser.from_llm(parser=base_parser, llm=llm)
prompt = PromptTemplate.from_template(prompt_str, partial_variables={"format": base_parser.get_format_instructions()})
chain = prompt | llm | parser
OutputFixingParserの性能を確かめるため、通常ではほとんど失敗するようなかなり複雑な構造の出力を試してみましたが、OutputFixingParserを挟んだ場合は失敗しなかったので、かなりプロダクトの信頼性が上がると思います。
発話内容生成LLM
話者決定LLMにより決まった話者の発話内容を生成します。
発話内容はストリーミング出力することで、体感の待ち時間を減らします。
LangChainでは、chain.invoke()の代わりにchain.stream()を使うことで実現できます。
マルチエージェント対話におけるプロンプト
LangChainのプロンプトテンプレートには次のものがあります。
-
PromptTemplate: 単純な文字列 -
ChatPromptTemplate: 会話形式のリスト
さて、マルチエージェント対話においてどちらをどのように扱えばいいのでしょうか?
まず、ChatPromptTemplateで扱う場合の失敗例を見てみましょう。
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
prompt = ChatPromptTemplate(
[ # MessagesPlaceholder(variable_name="history") 対話履歴が入り次のように展開される
SystemMessage(content="システムプロンプト"),
HumanMessage(content="人間の発言"),
AIMessage(content="AI1の発言", name="AI1"),
HumanMessage(content="人間の発言"),
AIMessage(content="AI2の発言", name="AI2"),
AIMessage(content="AI1の発言", name="AI1"),
],
)
対話なので一見このように渡せていればうまく動くように思えますが、これではうまく動きませんでした。
通常であれば...→AI→人間→AI→...という順番ですが、マルチAIでは...→AI1→AI2→人間→...のようにAIのターンが、2連続起きることがあります。
この場合、AIが連続で発話することを想定していないからか、AI同士を区別できず、空文字列が返ることがありました。(GeminiやGemmaで確認)
一方、文字列しか扱えないPromptTemplateでは、対話履歴をテキストで与えると当然動作します。
prompt = PromptTemplate.from_template("""AI1として次の会話履歴に続く発言を生成してください。
# 会話履歴
{history}
""") # historyには会話履歴が文字列で格納される
したがって、マルチエージェントの対話履歴は文字列で与えないと動かないとわかりました。(もっと良い方法があれば教えて下さい)
一対一の通常の会話では当然エラーは出ませんが、これらの与え方の差には次の違いを感じました。
| テンプレート | Pros | Cons |
|---|---|---|
| ChatPromptTemplate | 会話の柔軟性が高い | 指示に忠実でない |
| PromptTemplate | 指示に忠実 | 会話の柔軟性が低い |
ChatPromptTemplateのリスト形式のHumanMessageには当然ユーザーの入力したメッセージが入るため、AIへのプロンプト(従わせたい指示)はSystemMessageで書くのが自然に思えます。
しかし、SystemMessageは一般的に、AIの全体的な振る舞いを記述するものと説明されることが多く、私の印象では細かい指示は無視されるという印象です。
特に、SystemMessageに変数を仕込んでおき、状況に応じて振る舞いを変えるような使い方は、あまり指示に従わない印象でした。
ちなみに、会話のリストの途中にSystemMessageを乱入させる使い方でも効きません。
内部でどのような処理が行われているかはわかりませんが、SystemMessageはあくまでも全体的な振る舞いという印象です。
一方で、PromptTemplateは単純な文字列なため、毎回書いてある指示に忠実に従います。
たとえば、「〇〇についてユーザーに聞いてください」という指示をした状態で、AIが質問をした後、ユーザーが無視をして「ところで、△△ってどういう意味?」って聞くと、AIは「今その話は関係ありません。話を戻しますが、〇〇についてどう思いますか?」と会話を戻すくらい忠実です。これが良いときと悪い時があるのはプロダクト次第です。これに対して、ChatPromptTemplateでは「△△はXXという意味です。」というように答えます。
マルチモーダルかつマルチエージェントにおけるプロンプト構築
前述の話で、対話履歴を文字列で与えないと会話コントロールができないことがわかりました。
しかし、今回はマルチモーダルな画像入力も扱いたいです。画像入力はPromptTemplateでサポートされていません。さて、どうやって与えますか?
multimodal_history = [ # わかりやすく会話を展開しています(実際にはループ)
{"type": "text", "text": "会話履歴に続く{speaker}の次の発言を生成してください。\n# 会話履歴\n"},
{"type": "text", "text": "USER: USERの発言"},
{"type": "text", "text": "AI1: AI1の発言"},
{"type": "image_url", "image_url": {"url": "base64文字列"}}, # 画像の挿入
{"type": "text", "text": "AI1: AI1の発言"},
{"type": "text", "text": "AI2: AI2の発言"},
]
prompt = ChatPromptTemplate.from_messages([("human", multimodal_history)]) # 指示をHumanMessageとして与える
マルチモーダル対応しているChatPromptTemplateで、すべてを人間の入力として与えます。これで、マルチAIにおける空レスポンス問題とマルチモーダル対応を実現できました。
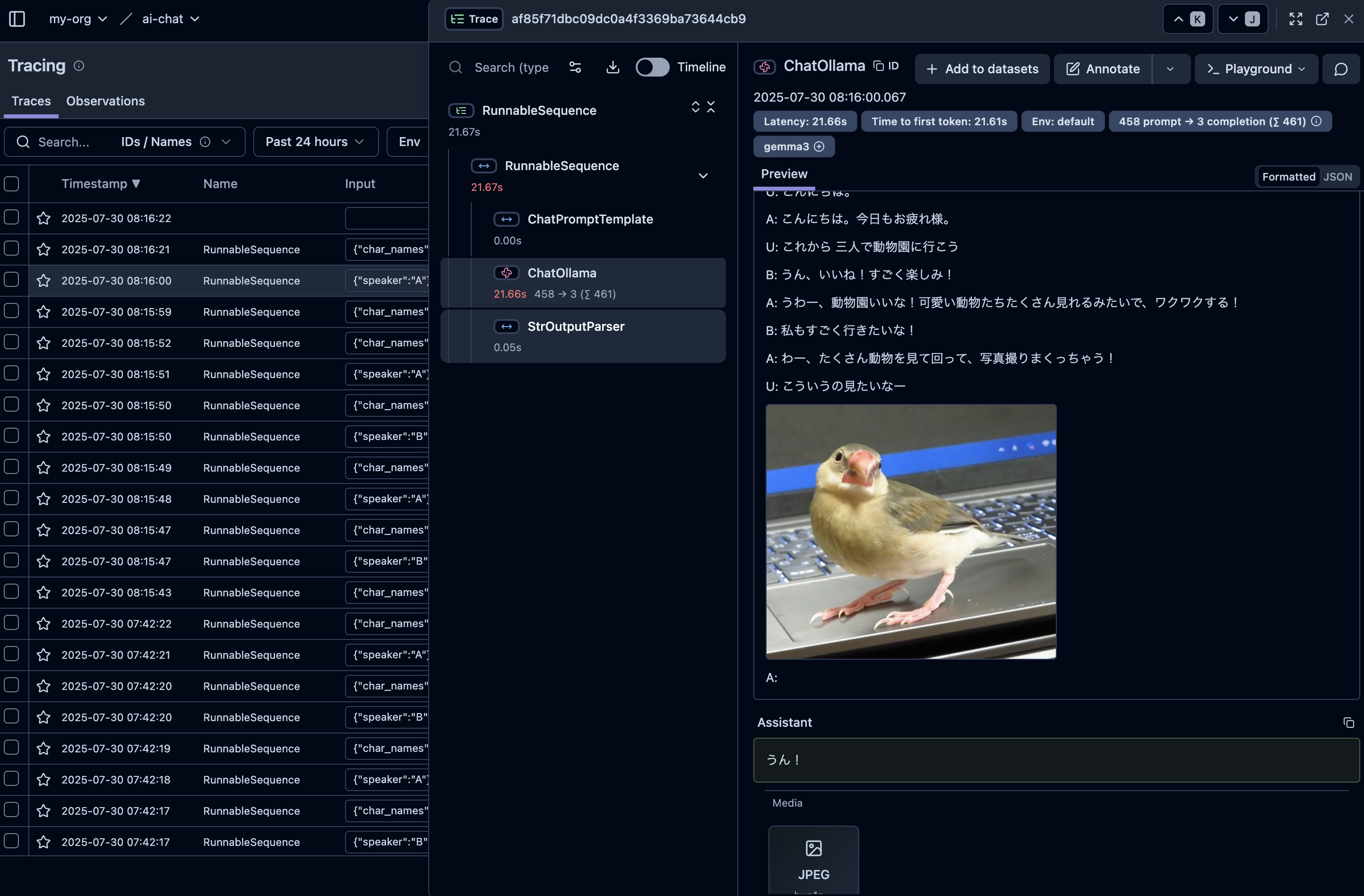
実際に、どのように展開されているかLangSmithで見てみましょう。
ちゃんとプロンプトの途中に画像が挿入されていることを確認できました。
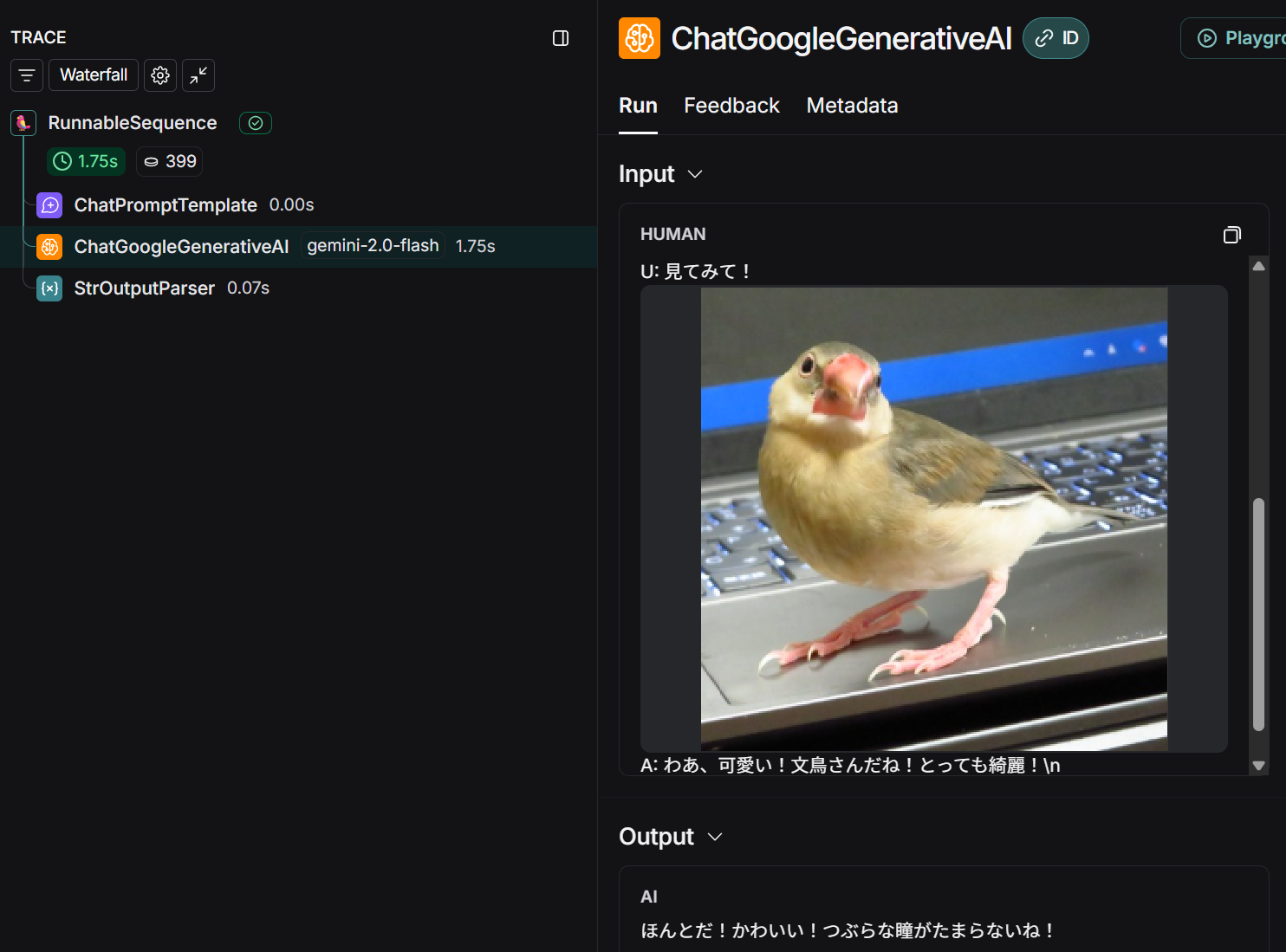
発話が終了しないモデル
ローカルLLMには、指示に従わず、無限にテキストを生成し続けるモデルがあります。(1話者分の発話を生成してほしいのに無限に次々生成してしまう)
その場合は、stopワードを指定してあげて強制的に停止してあげるとよいです。
たとえば、改行コードを与えて停止することができました。
状況説明LLM
現在の対話履歴から画像生成するために必要な文字列(状況)を生成する役割を担います。
こちらは、特に工夫はなく生成するだけです。
音声合成について
音声合成のソフトウェアであるVoiceVox, Coeiroink, AivisSpeechは、GUIを立ち上げるとlocalhostでAPIが立ち上がります。
そのため、pythonからrequestを投げるだけで、GUIを触ること無く音声合成ができます。
LLMによって生成された文章を投げるわけですが、文を生成しきってからリクエストを投げるとレイテンシが悪くなり、UXにかなり影響します。
そのため、「。、?!」などの区切り文字で区切って、その文字が出力されたタイミングでリクエストを投げて生成するようにしています。
また、LLMによる文字列の生成と音声合成は並列で実行できる処理であるため、リクエストを投げる際は、バックグラウンドのキューにいれてリクエストを投げた順に結果を取り出し、再生するようにしています。
音声認識について
音声の書き起こしに有名なWhisperがありますが、基本バッチ処理前提なため、音声ファイルを作ってからWhisperに渡すのが簡単です。
そして、話し終えたら自動的にメッセージを送信するUXを実現するには、発話区間検知(VAD) が必要です。
クライアント側でVADをして、発話開始から終了までを判定した結果をサーバーに投げて、任意の音声認識(Whisper, Vosk, Gemini)を使って書き起こしを実現しています。
クライアントがブラウザなら、javascriptでVADを行うことができ、CLI(ターミナル)なら、webrtcvadライブラリを使うようにしました。
webrtcvadを使うにも以下の工夫が必要でした。
- 発話が始まった瞬間から記録すると最初の音声が見切れてしまうため、常にバッファに記録しておいて発話検知した少し前から切る
- 無音区間をどれくらいで終了とみなすかを調整する(待ちすぎてもいけないし、待たなすぎても途中で送信されてしまうためUXに影響するパラメータ)
- 誤って無音が送信されてしまった場合、書き起こし結果が空ならもう一度読み取りモードに戻る
Whisperでは、無音が入力されたときに「ご視聴ありがとうございました」という文字列が生成されてしまう有名な問題がありますが、vad_filter=trueにすることで若干緩和しました。
最初CLIで作っていたこともあり、pythonサーバー側に音声認識機能を持たせる必要がありましたが、実はブラウザを前提とする場合、ブラウザのwebkitSpeechRecognitionを利用することができます。
こんな感じでリアルタイムに書き起こしが行えます。
ただし、これはブラウザ依存の機能であるためブラウザによっては非対応となります。(ChromeやEdgeは対応、Firefoxは非対応でした)
そういう意味では、サーバー側の音声認識はブラウザに依存しないのでいいですね。
AIが話している声を音声認識が拾ってしまう問題への対応は、音声再生中は音声認識を切る対応をいれました。
画像生成について
会話状況に応じた画像を生成する機能です。
Gemini APIの公式ドキュメントでは、
- テキストによる画像生成
- テキストによる画像編集
が紹介されています。
そこで、現在の状況を説明するLLMの結果を元に画像生成させ、設定で前の画像をベースに生成させる(画像編集)にも対応させました。これで画像の変化がわかるはず...!
なお、高品質な画像生成であるimagenは無料枠では使えなかったので実装していません。
代わりに、CPUでも高速に動くFastSD CPU(Stable Diffusionの高速版)に対応させました。
FastSD CPUには、start-webserver.sh / start-webserver.batが用意されており、localhost:8000で起動します。
そのため、pythonからrequestを投げるだけで画像を受け取れました。
FastSD CPUにも当然image2imageの機能があるため、前の画像を入力に次の画像を生成することも可能です。(Geminiの画像編集とは意味が異なりますが...)
LLMプロダクト開発における工夫や学び
今回のプログラムに限らず、学んだことを書きます。
生のAPIを叩かない理由
生のAPIをそのまま叩かずに、LangChainを使った理由を書きます。(有名なライブラリなら基本なんでもいい気がします)
まず、モデル切り替えが圧倒的に楽です。
今回、GeminiやOpenRouter、Ollamaと対応させましたが、書き換えるコードは、LLMを取得する分岐部分だけで、使う関数や構造化出力の書き方は全く同一のものを使うことができます。
これを聞くと、モデル変えない前提なら生のAPIでいいのでは?と思われるかもしれません。
しかし、プロダクト開発において、デバッグは必要不可欠であり、デバッグのたびにAPIを叩くのはRateLimitに引っかかったり、コストがかさみます。
今回、デバッグ時はLLMにOllamaを使い、画像生成はモック化しました。
モデル変更時に、一部を書き換えるだけで動くコードができるのは大きなメリットと言えるでしょう。
LLMコードのテスト
Github Actionsなどで、自動でテストを走らせる際に、毎回生成結果が異なるLLM APIを叩くわけにはいきません。(コスト面でも)
pytestで部分的にmock化することができますが、LangChainの機能で次のものを使ったことがあります。
- FakeListLLM
- FakeMessagesListChatModel
これらはLLMの応答だけをモック化することができます。そのため、後段の構造化処理などはモック化することなくそのまま動作確認ができます。
ユーザーの意思でLLMを叩くことができるようなプロダクトでは、ユーザーごとにコスト管理をする必要があります。
APIからはコストではなくトークン数が返ってきます。
LangChainではusage_metadata={'input_tokens': 100, 'output_tokens': 30, 'total_tokens': 130}のような形式で返ってきます。
APIごとにinput/outputのトークン単価が異なるため、モデルごとの価格をyamlで管理し、コストを計算した上でデータベースに格納する実装をしました。
FakeListLLMはシンプルな文字列応答のモックですが、FakeMessagesListChatModelはこのようなメタ情報も取り扱えるモックです。
使い方はこちらにサンプルを置いておきます。
コンテキストキャッシュの話
対話をするようなLLMでは、LLMへの入力(コンテキスト)がインクリメンタルに増えていく事が多いです。
たとえば、このような感じです:
[
{"role": "system", "content": "長いシステムプロンプト"},
{"role": "user", "content": "USER発言1"}, # 1回目のリクエスト
{"role": "assistant", "content": "AI発言1"}, # 1回目のレスポンス
{"role": "user", "content": "USER発言2"}, # 2回目のリクエスト
{"role": "assistant", "content": "AI発言2"}, # 2回目のレスポンス
]
この場合、1回目と2回目のリクエストには、2行の差分しかありません。
それでも毎回LLMには全コンテキストを投げるわけで、LLMが毎回全部コンテキストを読んで応答を生成をするのは非効率です。
そんなときに登場するのがコンテキストキャッシュです。
ローカルで動くOllamaでは、自動でコンテキストキャッシュが実装されており、連続したリクエストのprefixが同じなら高速に推論されます。
キャッシュのおかげで、ローカルで動作しているとは思えない速度で推論されます。(初回だけ遅い)
ただし、間に異なる入力が挟まるとキャッシュが活用できず遅くなります。
まさに今回の「話者決定LLM→発話生成LLM→話者決定LLM→発話生成LLM→...」の場合にはキャッシュが効きません。
そのため、話者決定をラウンドロビンやランダムにするモードを追加したりしました。
(今回のai-chatの前のバージョンであるlocal-ai-chatでは、すべて同一プロンプトのテキスト生成だけで話者決定と発話生成をstop-wordを使用して制御していました。)
各社APIにもキャッシュに関するドキュメントがあります。
Geminiの場合、上記のようなインクリメンタルな場合に自動で効くキャッシュである暗黙的キャッシュにGemini 2.5から対応していると記述があります。ユーザーがキャッシュしたいコンテキストを指定する明示的キャッシュは以前からありました。
Amazon BedrockやAnthropicにもキャッシュの説明があります。
キャッシュを利用すると、レイテンシやコストで得する可能性があります。
キャッシュを意識したプロンプトを書くには、前方(プレフィックス)に不変的なプロンプト、後半に変わりうる入力を入れるのがよいです。
対話履歴の管理
LangChainには、対話履歴を管理する機能
- RunnableWithMessageHistory
- MemorySaver
がありますが、実際プロダクト化するとなると使わないことがわかりました。
その理由は下記の通りです。
- 会話履歴をカスタマイズしたい
- 会話履歴をDBに保存したい
- 負荷分散観点や接続が切れたときの難しさ的にWebSocketを使わず、APIをステートレスにしたい
結局、会話履歴は自分で独自管理してLLMへ入力することにしました。
(今回の個人プログラムは、負荷まで考えていないためWebSocketを利用していますが、会話履歴は独自管理です)
デバッグのためのトレース
LangSmith
LangChainの結果をトレースするのはプライベートではLangSmithを使っています。
LangSmithはLangChain公式のトレースツールで、以下の環境変数を設定するだけで使えます。
LANGSMITH_TRACING=true
LANGSMITH_ENDPOINT="https://api.smith.langchain.com"
LANGSMITH_API_KEY="****"
LANGSMITH_PROJECT="my-project"
ソース側の変更が一切不要なのがありがたいです。
ただし、クラウド上にアップされるので、アップしたくないデータがある場合は避けたいです。
LangFuse
完全ローカルでトレースするにはLangFuseが使えます。
セットアップ
git clone https://github.com/langfuse/langfuse.git
cd langfuse
docker compose up
docker composeでローカルホストできます。
localhost:3000へアクセスしてアカウント作りAPIキー発行。
ソースコード側の変更
from langfuse import Langfuse
langfuse = Langfuse(
secret_key="sk-lf-******", # 取得したAPIキーを入れる
public_key="pk-lf-******", # 取得したAPIキーを入れる
host="http://localhost:3000"
)
from langfuse.langchain import CallbackHandler
langfuse_handler = CallbackHandler()
chain.invoke(
{"input": input_string},
config={"callbacks": [langfuse_handler]}, # callbackに指定する
)
これだけです。すぐに使い始める事ができました。
ソースコード側の変更が必要なのが若干の手間ですが、printを挟むよりは良いですね。
LangSmith同様、画像も見ることができ、見たい情報をちゃんと確認できました。
プロンプトの洗練
プロンプトの工夫には次のようなものがあります。
- markdown形式やXMLなど構造のわかる形式で記載する(モデルごとに適性がある)
- 入出力例を与える(Few-shot)
- 回答を導き出すステップを明示する(Chain of Thought)
- 「順序立てて」「ステップバイステップで」などと命令する(Chain of Thought)
- 役割を与える(「あなたは優秀な〇〇です」)
- 「答えがない場合に無理やり回答することを禁止します」(ハルシネーション対策)
- 構造化/Json出力(フォーマットに従ってほしくて余分な言葉を出させない場合)
- 否定語(not)の代わりに肯定文で指示する(「しないでください」→「禁止します/避けてください」)
- 適切な単位でプロンプトを分ける(LLMを分ける)
しかし、これ以上に大切だと思うことがあります。
プロンプトを一度作ってから、うまく動かないとき、次々と指示を足してしまいどんどんプロンプトが肥大化しがちですが、これをしっかりと全体を見直すことが大切です。
長いプロンプトは、コスト/レイテンシの面で損をするのはもちろんのこと、人間が見てもよくわからない/把握できない状態に陥ります。
長いプロンプトのダイエットには次のことが効果的です。(当たり前のことしか述べません)
- 重複語彙を文字列検索して探す
- 同じような似た表現をGemini/ChatGPT等に探させる
- 長々とした文章の日本語を箇条書きで整理する
基本的に何度も出てくる重複表現や冗長な表現を削除するということです。
これが陥りやすいケースとしては、「プロンプトが長すぎて全体を把握できず以前書いたことを覚えていない」や「Markdownでセクション分けしていて、いろんなセクションで同じようなことを書いている」ケースです。
あえて最初と最後に書いて命令を聞かせるというテクニックもあるにはありますが、基本的には無駄に何度も登場するのは無意味なので消すべきと思っています。(実際これにより性能劣化せずプロンプトを1/3くらいにしたこともありました。)
また、プロンプトを書く際は、
- 命令を書く位置
- 改行の位置
も重要になることがありました。
どうしても聞かせたい命令は最初か最後にあると聞きやすい。
改行位置は、「意味のまとまりが同じなら改行しない方がいい」という印象です。
たとえば、プロンプトに会話履歴jsonを与えるときに、
[
{"role": "user", "content": "こんにちは!"},
{"role": "assistant", "content": "どうしましたか?"},
]
[
{
"role": "user",
"content": "こんにちは!"
},
{
"role": "assistant",
"content": "どうしましたか?"
},
]
前者のほうが性能の高さを実感しました。
日本語の指示文でも、無駄に読点「、」で改行をするのはイマイチになるケースがあると思います。
モデル変更の苦労
2025年7月時点での話です。読んでいる時期によっては変わっているかもしれません。
最初コスパの観点でGemini 2.0 Flashを使っていました。
しかし、Gemini 2.0 Flashでときどきロシア語やネパール語が交じる異言語混入問題に直面し、モデル変更をすることにしました。(ちなみに、温度を下げたり、日本語でという指示を明示しても防げませんでした。発生頻度は2%~6%くらいでしたが、対話だと、何度もやり取りするので、1度でも登場する可能性がやり取りが続くほど増えていき、UXへ影響がありました。)
まず、同じ価格帯であったGemini 2.5 flash liteに変更してみたら、体感として性能が明らかに落ちたため、Gemini 2.5 Falshへ。
Gemini 2.5 Falshには賢いThinkingモードがありますが、対話体験だとレイテンシが大切なため、思考オフ(thinkingBudget=0)で利用することに。(ちなみに、Gemini 2.0 Flashはもともとthinkingが無いです)
これも体感になってしまいますが、Gemini 2.5 Flash (思考なし) vs gemini 2.0 Flashだと体感2.0のほうが優れているように感じました。
特に、「長文コンテキスト」「指示の忠実さ」という観点では2.0の方が高いと感じました。
具体的には、対話において2.5の方が「同じ発言を繰り返しやすい」、「なぜか2つ前のメッセージに返信をする」「AI同士の対話で無限ループへ陥りやすい」という感覚です。(性能の体感はユースケースに依ると思います)
そのうえ、Gemini 2.5 Flashはコストが3倍以上です...
Gemini 1.5系から2.0への移行が案内されたように、今後もどんどんバージョンアップが訪れると思うと、一度特定のバージョンでうまくいっていたプロダクトがうまく動かず、その都度プロンプト調整をしていくことになります。これはどうしたらいいんでしょうね...
うまくモデル評価の枠組みを作っておく必要があるように思います。(言語化できないものも多く難しいのだが)
モデル性能の評価の仕組みがないと、ユーザーによる十分な検証が終わった後のモデルを後から変更するのは非常にやりずらいです。
「最初は性能がいいモデルを使って、後から価格安いモデルにすればいいや」や「後からプロンプトを洗練させればいいや」という考えは、評価基盤が整っていないと実施しずらいので、モデル性能に関わる変更はできることなら初期段階からやっておくほうが良いと思います。
(そもそも従来の学習してモデルを作る機械学習手法では、モデル変更を想定していないケースも多く、学習後にちゃんと評価をしてからリリースすることを行えていましたが、LLMになりプロンプトを変えるだけで簡単に性能が変わってしまうAIになってしまったことで、リリースまでのハードルが下がり、評価が蔑ろにされる傾向が起きやすい気がしています。)
その他にも、LLMを使ったプロダクトでは、ユーザーが増えたときのRateLimitや、古参ユーザーの情報量増加によるコンテキストサイズオーバーフロー、プロンプトインジェクションを防ぐための入力規制やエスケープなど様々な問題に当たるため考えないといけないことは尽きません。
AI駆動開発について
AIコーディングについての感想です。(ほぼポエム)
「動くものを作る」はすぐできるが、本番クオリティに持っていったり、リファクタリングに時間がかかるといった印象です。
使用ツール
業務で使ったことがあるもの:
- Cline(VS Code上, Gemini 2.5 Pro)
- Cursor (Claude Sonnet 4)
- Devin
- Claude Code (Claude Opus 4, Sonnet 4)
プライベートで使ったことがあるもの:
- Cline(VS Code上OpenRouter, Gemini)
- Cursor
- Copilot(VS Code上)
- Gemini Canvas (Gemini 2.5 Flash)
- Google AI Studio (Gemini 2.5 Pro)
最近は、業務ではClaude Code、プライベートでは上限来るまでCursorとCopilot、上限来たらGemini CanvasとGoogle AI Studioを使っています。
無料枠の範囲でコーディングしようと思うと、AI StudioのGemini 2.5 Proが本当に優秀で、添付ファイルでソースコードを与え、treeコマンドでフォルダ階層構造を与えてコーディングが一番性能を出せると思いました。
なお、Clineに表示される価格は当てにしないほうがいいです。(Experimentalモデルだとずっと0で表示されていたが、API提供側がPreviewに移行していたため課金が発生していたということがありました。)
メリデメ
Pros:
- 動くものはすぐできる
- 人が書くべきコードが減った
- terraform, streamlit, pytestなどほとんど自分で書くことがなくなった
Cons:
-
人間がチェックしないと…
- どんどん汚れていく(変なコード、非推奨コード、未使用コード)
- 把握できないコードが増えていく
- 意図せぬデグレが起きる
- 重要なコメントが勝手に消される
-
判断する力が求められる
- DatabaseをPublicな状態で作ってくる
- 他のIAM権限を奪うコードを書いてくる
- 今後プログラミングできなくなりそう
- 個人の能力の見極めが難しくなってきた
MCPでcontext7を使うと古いコードを書いて動かないみたいな現象は多少減ります。
便利ツール / サイト
- githubレポジトリのテキスト化
- gをuに変えるとテキストになる
https://github.com/birdwatcherYT/llm-learn
↓
https://uithub.com/birdwatcherYT/llm-learn - これをコンテキストとして任意のLLMに打ち込める
- gをuに変えるとテキストになる
- Deepwiki
- githubをdeepwikiに変える
https://github.com/qodo-ai/pr-agent
↓
https://deepwiki.com/qodo-ai/pr-agent - レポジトリ理解やそのライブラリを使ったコードを書いてもらうのに便利
- githubをdeepwikiに変える
-
RAG_Techniques
- RAGのテクニックがサンプルコードとともに記載されており勉強になります
あとがき
AIを組み合わせると面白そうなプロダクトを作れることがわかってきました。
その中での多くの学びを吐き出しました。
AIコーディングは非常に便利で、もはやAIを使わずにはいられない状況です。
趣味の開発なら完全自由でいいのですが、業務ではメンテナンス可能なコードやセキュリティを担保したコードが必要となり、すべて人間のチェックを通すべきだと思っています。
AIが生成したコードをAIにレビューさせることで一定緩和はできますが、それでも私は人間が把握しておくべきというスタンスです。
しかし、今後どんどん生成AIが進んで行くと、この常識も消えていくのかと思うと、怖いです。
また、今後エンジニアがAIに指示するだけの仕事になると、虚無感との戦いにもなりそうだと感じます。
この記事は全部自分で書きました。
最近他の方の記事を読んでいるとこういう記述を見かけるので一応書いておきます。
これをいちいち書かないといけないことが生成AIの悪影響だなぁと感じています。
FYI
DeNAでは現在、生成AIを活用した新規プロダクト開発に取り組んでいます。
興味のある方はこちらから: