はじめに
有名な物体検出・認識アルゴリズムにYOLOというものがあります。YOLOを使えば手軽に機械学習による物体検出・認識を試すことができますが,最初から用意されている事前学習済みモデルでは認識できる物体の種類に限りがあります。そのため事前学習済みモデルでは認識できない物体を認識したい場合は,モデルのファインチューニングが必要になります。
今回はUltralyticsが公開しているYOLOv8のファインチューニングを行ってみました。あくまでも備忘録的なものではありますが,この記事ではデータセットの作成からトレーニング結果の確認までを説明します。
実行環境は以下の通りです。
| OS | Windows11 |
|---|---|
| GPU | RTX3090 |
| Python | 3.10.13 |
| Pytorch(cuda) | 2.2.0 |
| ultralytics | 8.1.9 |
Label Studioを使ったデータセットの作成
画像データの作成
ファインチューニングを行うにはデータセットを作成しなければならないわけですが,そのためにはまず画像を用意しなけばなりません。普通に写真を撮っても良いのですが,面倒なので今回は学習対象が映った動画を撮影し,そこから適当な間隔で画像を切り出しました。
基本的に画像は多ければ多いほど物体認識の性能は高くなると考えられますが,アノテーションに掛ける労力も考えると,ある程度の枚数に抑えた方が良いでしょう。目的のタスクの難易度にもよりますが,数十から百数十枚程度で十分な性能となるような印象です。
After Effectsを利用できる場合は,コンポジション設定から解像度を720p,フレームレートを1fps,デュレーションを50程度とし,対象の物体が映っていない部分を削除したうえで連番出力すると,勝手に50枚程度の画像を出力してくれるので便利です(他の動画編集ソフトでも連番出力くらいは対応しているはず)。
Label Studioの使い方
ある程度の画像データが用意出来たら,次にその画像のアノテーションを行います。画像のアノテーションにはLabel Studioという便利なオープンソースソフトウェアを利用します。
Label Studioは以下のコマンドでインストールできますが,同時に他のライブラリも色々インストールされるので,環境を汚染されたくない人はanaconda等を利用して別の環境を作成すると良いかもしれません。
pip install label-studio
起動するにはターミナルに以下のコマンドを入力します。
label-studio
自動的にwebサイトが開くのでSIGN UPタブからアカウントを作成してログインします。
ログイン出来たらCreate Projectから新しくプロジェクトを作成します。
下のような画面が表示されるのでProject Nameを適当に入力します。
Data Importタブを開いて,先ほど作成した学習対象の物体を撮影した画像をドラッグアンドドロップします。
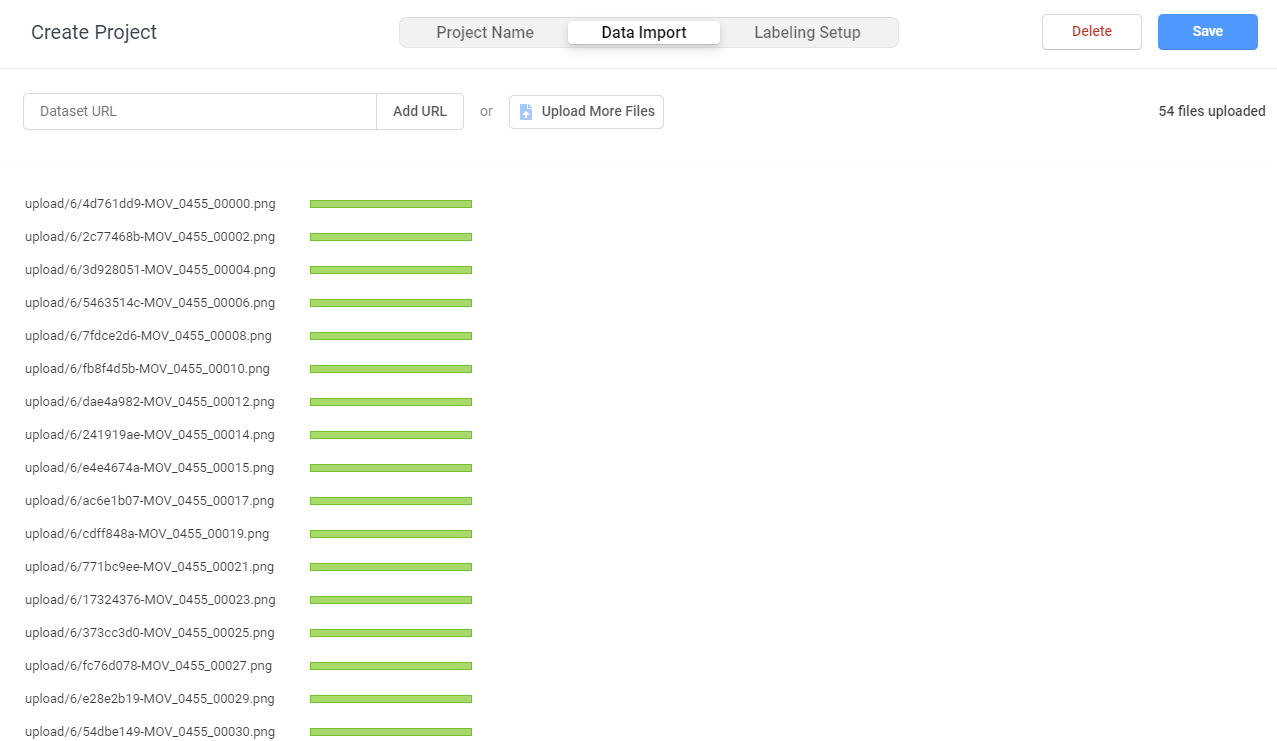
Labeling Setupタブを開いてComputer Vision>Object Detection with Bounding Boxesを選びます。
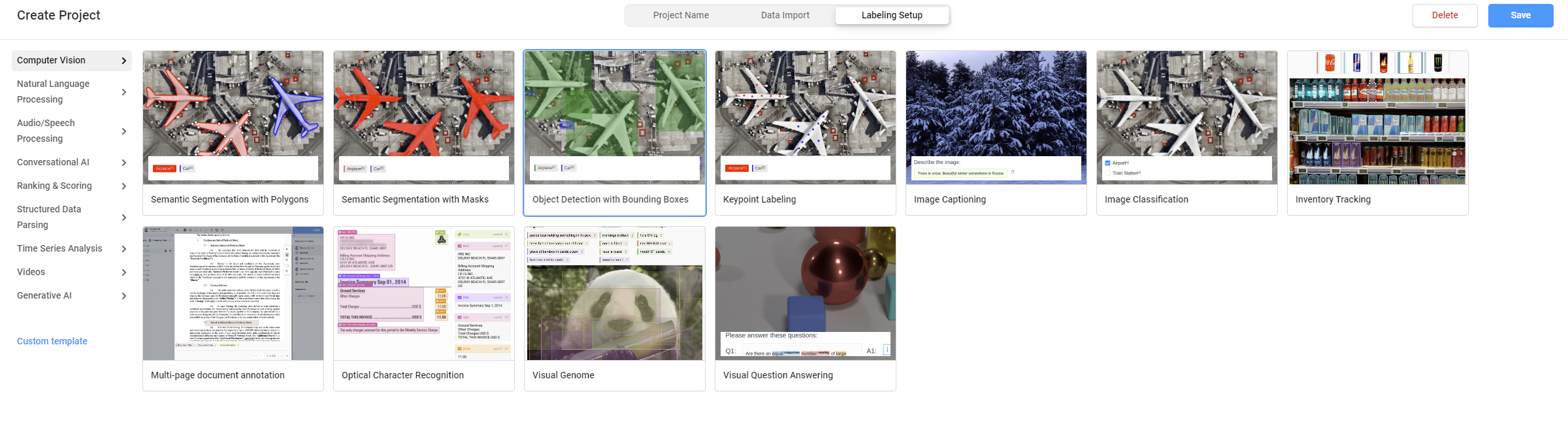
画面が切り替わるので,次の画面でLabelsに元からある2つのタブを削除し,Add label namesからアノテーションしたい物体名のタブを追加します。
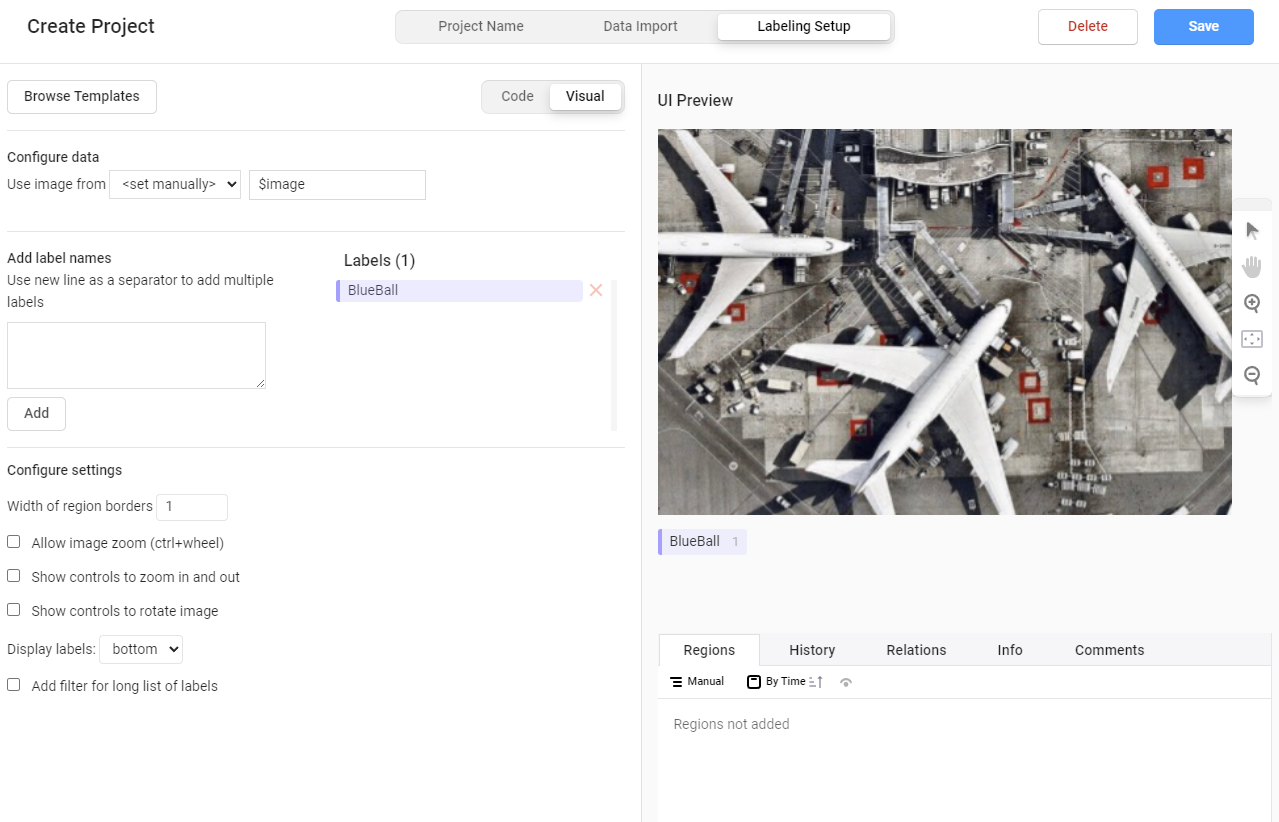
右上のSaveをクリックすると下のような画面になります。
それぞれの画像をクリックすることでアノテーション作業を行う事ができます。
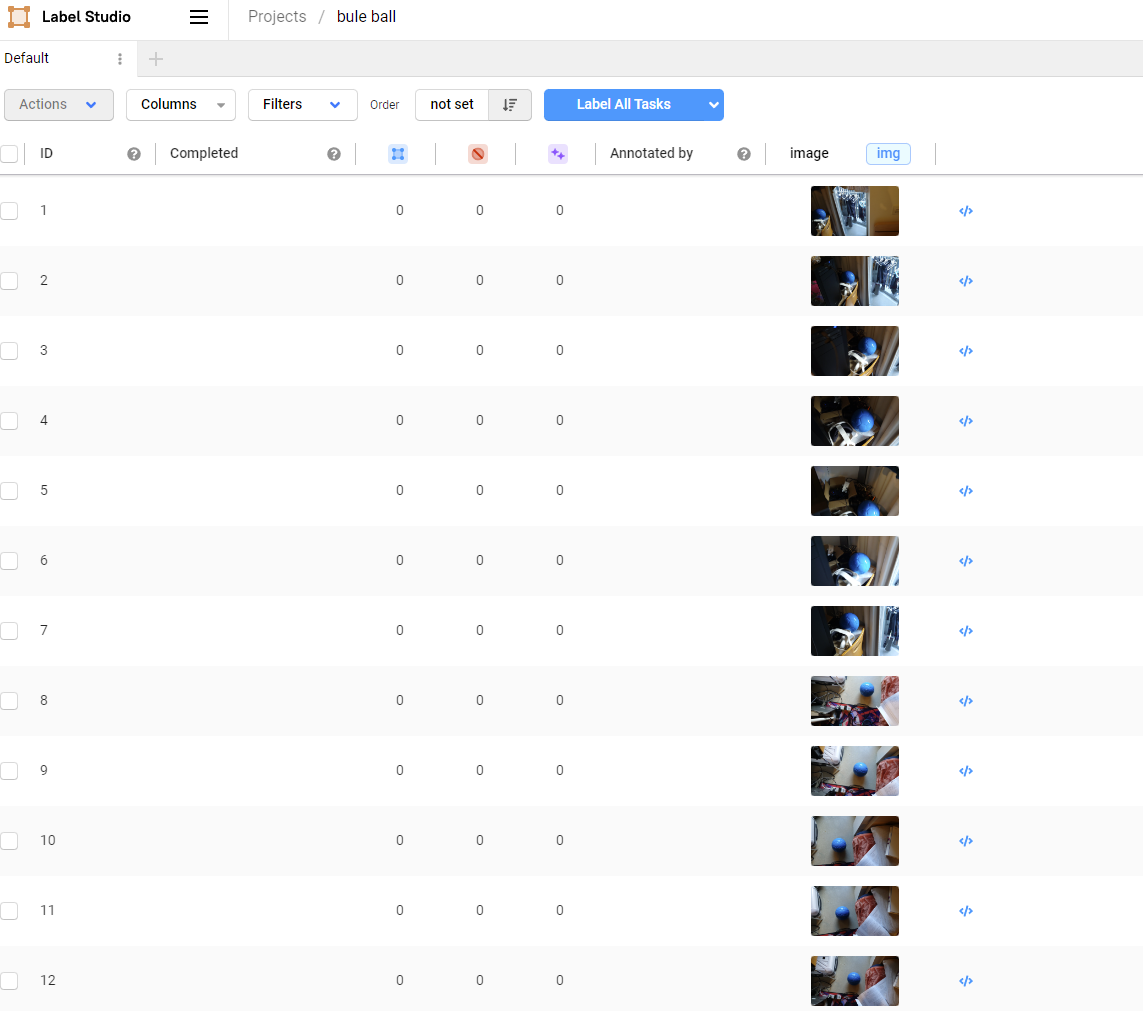
ラベル番号の数字キーを押してからカーソルで検出したい物体を範囲選択し,枠を作成します。枠を削除したい場合はクリックしてからbackspaceを押してください。一枚のアノテーションが完了するごとに右下のSubmitを選択します。
すべて完了したら左上のプロジェクト名をクリックしてひとつ前の画面に戻ります。
右上のExportを選択すると以下のような画面が表示されるので,YOLOを選択してExportをクリックします。
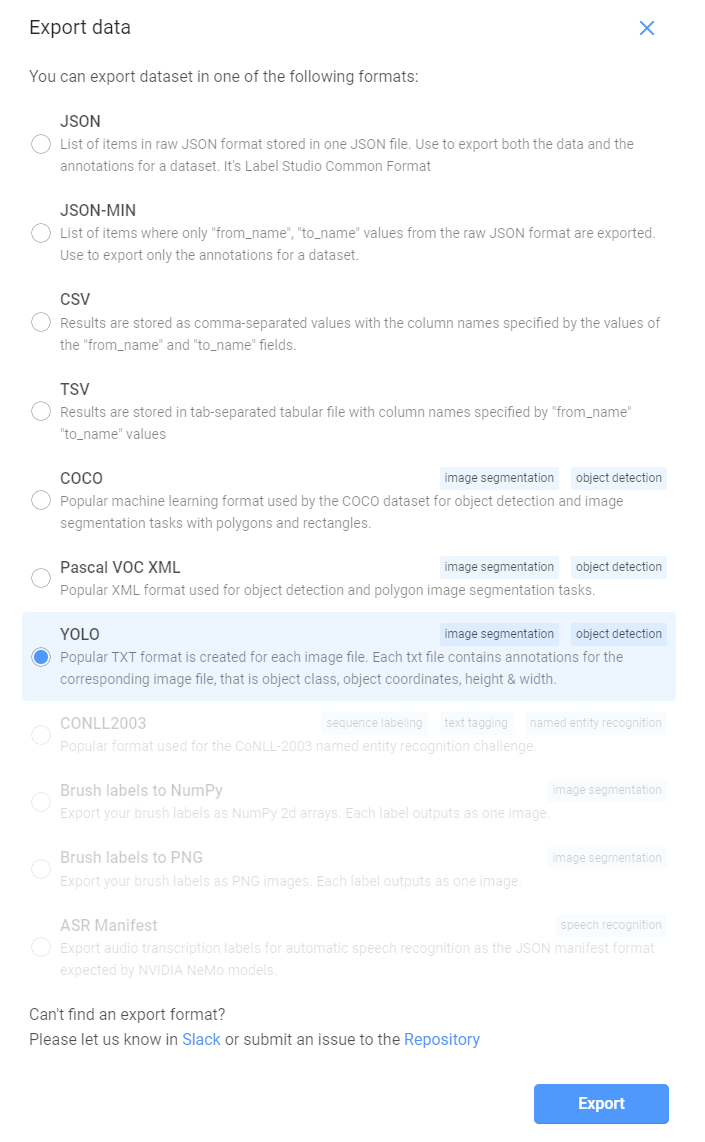
するとzipファイルがダウンロードされるので,それを解凍すると以下のようなファイルが入っているはずです。
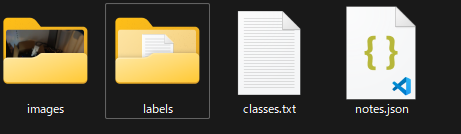
ファインチューニングにはこのうちのimages,labelsフォルダを利用します。
※ 複数のラベルでアノテーションを行った場合,classes.txtにラベル名が列挙されているはずであり,この順番がlabelsに格納されているデータの中身の番号に対応しています。
例えばclasses.txtが以下のような内容であったとします。
blue
red
purple
この場合,blueが0,redが1,purpleが2に対応します。
例えばlabels内のアノテーションデータが以下のようであったとします。
1 0.5912740899357601 0.357839638353557 0.16113490364025693 0.29312395907684985
0 0.4071199143468951 0.6400190340233166 0.16862955032119914 0.3549845348560552
この場合,1行目のデータは冒頭に1とあるのでredに対応しており,2行目のデータはblueに対応しているという事になります。この順序がデータセットを作る際に必要になってくるので,複数のラベルでファインチューニングをする場合は覚えておいてください。
データセットの作成
trainとvalという名前のフォルダを作成し,その中にそれぞれimages,labelsフォルダを作成します。先ほど解凍したフォルダの中にあったimagesとlabelsフォルダ内のデータを5:1程度で分割して新たに作成したimages,labelsフォルダ内に格納します。分割するimagesとlabelsのファイル名は合わせてください。(この程度であれば手作業で分割した方が早いと思います)
作業を行うと次のようなフォルダ構成になります。
次に上の画像にもあるように,データセットフォルダの下にデータセットの情報を記したdata.yamlを作成します。
# yamlファイルから各画像フォルダまでの相対パス(相対パスで上手くいかない時は絶対パスにする)
train: ./train/images/
val: ./valid/images/
# データセットが含むクラス
nc: 1 # クラス数
names: ['BlueBall'] # クラス名の配列。複数クラスならば`classes.txt`に書かれている順番にする
トレーニング
以上でデータセットを作成できたので,トレーニングを行っていきます。ultralyticsをインストールしていない場合は入れておいてください。
pip install ultralytics
以下のコードで学習ができます。なお,学習にGPUを使用したい場合はGPU版のPytorchが使えるようにしておく必要があります。
from ultralytics import YOLO
model = YOLO('yolov8n.pt') # yolov8n/s/m/l/xのいずれかを指定。多クラスの検出であるほど大きいパラメータが必要
model.train(data='./path_to_yaml_file/data.yaml', epochs=300, batch=20) # 先ほど作成したデータセット内のyamlファイルまでのパスを指定
train()に指定するエポック数については過学習になると自動的に学習が終わるので十分大きな値を指定しておけば問題ありません。バッチサイズは大きくした方が早く学習が終わるので,GPUメモリが許す限り大きな値とした方が良いと思われます。
トレーニングが完了するとスクリプトのある場所から見て./runs/detect/train/weights/下にbest.ptというファイルが生成されます。この重みファイルを用いることでファインチューイング後のモデルを使用できます。
テスト
YOLOのモデルのファインチューニングができたので,さっそくテストしてみましょう。OpenCVがインストールされていない場合は,以下のコマンドで入れておいてください。
pip install opencv-python
次のコードは動画を読み込んで物体検出をし,マーカーを付けた動画を保存するサンプルプログラムです。
import cv2
from ultralytics import YOLO
model = YOLO('./runs/detect/train/weights/best.pt') # best.ptまでの相対パス
video_path = './path_to_video/video_name.mp4' # テストしたい動画
cap = cv2.VideoCapture(video_path)
annotated_frames = []
while cap.isOpened(): # フレームがある間繰り返す
ret, frame = cap.read()
if ret:
results = model.track(frame, persist=True) # 物体をトラッキング
annotated_frame = results[0].plot()
else:
break
annotated_frames.append(annotated_frame)
# annotated_framesをmp4として保存
height, width, layers = annotated_frames[0].shape
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
video = cv2.VideoWriter('./annotated_video.mp4', fourcc, 30, (width, height))
for frame in annotated_frames:
video.write(frame)
video.release()
cap.release()
cv2.destroyAllWindows()
print('finished')
認識結果
https://youtu.be/Rh-3O0PoEXg
おわりに
今回はYOLOv8のファインチューニングの解説をしました。実はYOLOv8の後継的な存在としてYOLO-NASというバージョンもあるのですが,YOLOv8の方はトラッキング機能等が実装されており便利だったのでこちらを選びましたが,ここらへんは用途によって選択の余地がありそうです。個人的な感想としては,ファインチューニング自体はとても簡単かつ検出結果も高精度で感心した一方,アノテーションは想像以上に面倒だったという感じです。このような地道な作業が昨今のAIブームを裏から支えているのかと思うと頭が下がります。
参考文献