まえおき
落合陽一氏のdeep yohji
落合先生の講演で以下の話を聞いた。
ファッションデザイナー山本耀司は高齢であり、彼が死んでしまったらyohji yamamotoのデザインがなくなってしまう。
そこで、deep learningを使ってyohji yamamotoのデザインを生成した。
yohji yamamotoのファッションはググればパリコレの画像がすぐに見つかるとのこと。
deep learningで生成したyohjiと本物のyohjiでは見分けがつかないほどの質ができたようだ。

yohjiのデザインは特徴的で、自動生成に向いていると思った。
ユ◯クロのような大衆的なデザインを自動生成しても面白くない。
(Fashion-MNISTについては後ほど。。。)
yohjiだけじゃない
上記の課題は落合先生が好むyohjiに限った話ではない。
パリコレにも出演し、特徴的なファッションを創出するISSEY MIYAKEもデザイナーが高齢であり、彼がいなくなったら独創的なファッションが生まれなくなってしまう。
そこで、ISSEY MIYAKEの画像を学習し、DCGANによりISSEY MIYAKEの服を自動生成する取り組みを行った。
要は、落合先生の取り組みをいい感じにパクってみた。m(_ _)m
個人的にもDCGANを使ってみるにあたり、
- どの程度の画質が必要か、
- 何枚くらいの画像を準備する必要があるか、
- 実行にどの程度時間がかかり、
- どの程度のqualityのファッションがデザインできるのか
を掴みたかった。
理論と事例
GANとDCGANについて
GANについてググってみると、
高精度なニセ札を作るgeneratorと、高精度に偽造紙幣を見極めるdiscriminatorという2つのdeep learningがお互い学習しあい、誰にも見抜けないニセ札を生成するという構造になっているようだ。(ホコタテみたいな)
最初generatorが乱数を発生させて砂嵐みたいな適当な画像を生成する。
生成した砂嵐をdiscriminatorが読み込み、input画像に含まれるかどうかを0,1で真偽判定する。(砂嵐がinput画像の確率分布に近似しているかを識別する)
砂嵐は当然input画像に含まれないので偽と判定されなければならないが、generatorは、discriminatorが真と判定するような画像を作るためにinput画像を学習し、確率分布に沿った画像をまた出力する。
discriminatorが判定する。
generatorがまた生成する。
…これを何epochも繰り返し、generatorが生成した画像を取り出す。
(0 epoch目は砂嵐で、数万epoch繰り返して生成するときれいになっていくイメージ。)
画像内の隣り合うピクセル同士は似たような情報を持つことを考慮して、GANに畳み込み(CNN)を組み込んだものがDCGANのようだ。DCGANの方がより滑らかな画像ができるということらしい。
情弱の筆者にはGANの詳しい仕組みがよく理解できないが、
こちらのブログ(敵対的生成ネットワーク)が詳しいようだ。
その他、triwave33さんの以下qiita記事も詳しいようだ。
▽やΣ等の地球外文字を解読できるという宇宙人の方には、はじめてのGANがよいだろう。タイトルには「はじめて」となっているが、宇宙人以外の人間が初めて読んで理解できる記事ではない。
関連事例
DCGANを使った画像生成は多く文献が見つかる。
色々調べてみると、何万枚もの画像を学習しているケースが見られる。
generatorとdiscriminatorに使っているlayerの数、バッチ標準化、識別子はみんなそれぞれ異なるが、DCGANに関する論文で発表されているアルゴリズムを採用するケースが多いようだ。
たまたまジャンルがヲタク寄りに偏っているように見えるが、参考になった。
また、Fashion-MNISTを使って服を生成するケースもあるようだ。
前準備と実装
環境構築
- MacBook Air 13-inch Early 2015 Core i5
- Mac OS X 10.11 El Capitan
- Anacondaインストール済み
- Kerasをインストール
- opencvをインストール
conda install --channel https://conda.anaconda.org/anaconda opencv- 今回、上記関連事例のキルミーベイベーのソースを使用した。
import cv2のためにopencvが必要。
前準備
画像データ収集
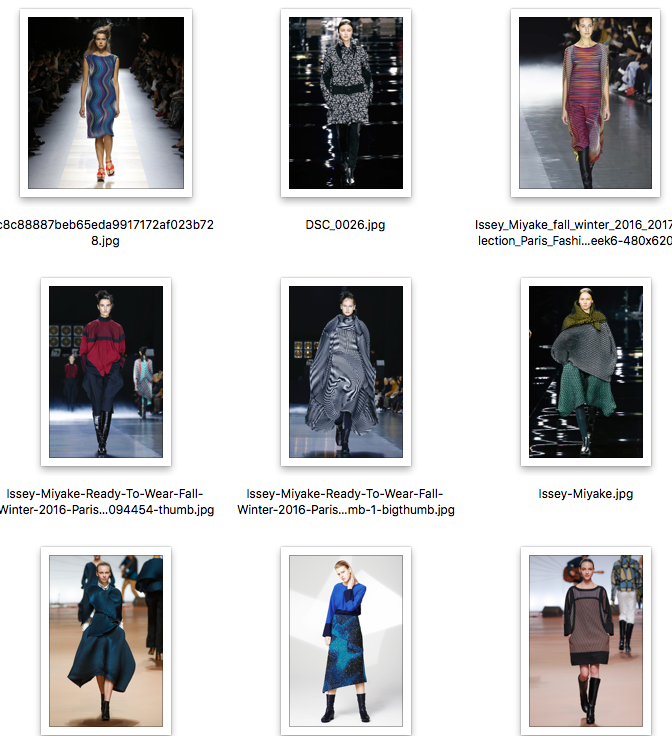
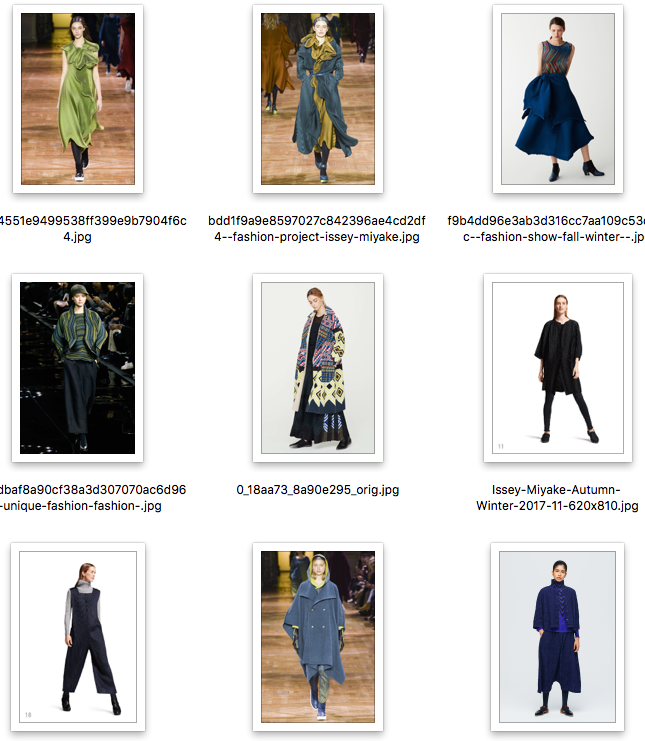
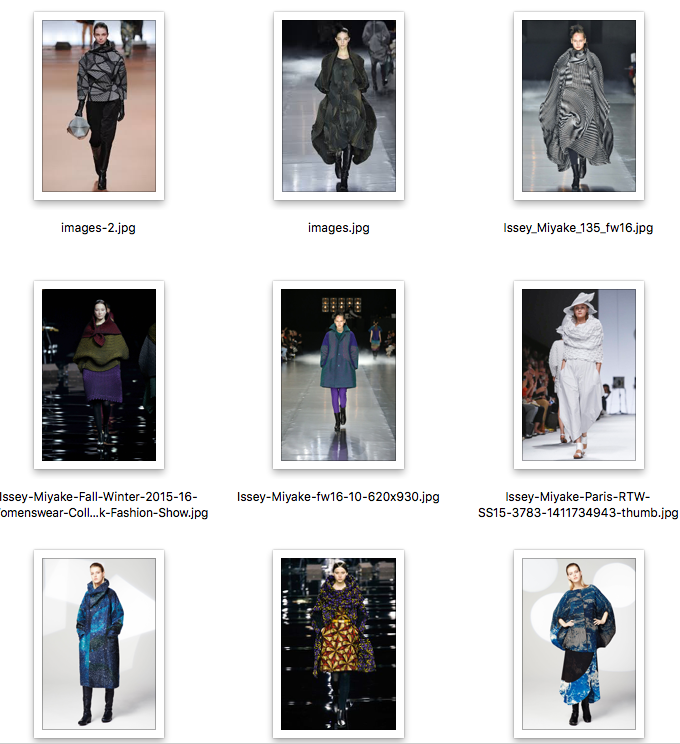
- ISSEY MIYAKEの服を画像検索で129枚取得。
- レディースだけを重複なくピックアップし、Homme(メンズ)は除いた。同じ画像が複数あると、DCGANの学習に偏りが生じてしまい独創的なファッションが生成できなくなることを危惧した。
- クロールしてもよかったが、単純検索でクロールすると同じ服の画像があったり、横向き・後ろ向き・複数人での写真があったり、ISSEY MIYAKE以外の服も混じるため、意外と厄介。今回はお試しなので手動の方が早いと判断。
- ファッションショーの写真が多い。その他、販売された服のフォト。
- RGB形式の画像のみを取得する点に注意。
- 枚数は疲れたところで止めた。
色使いや柄、服の形が特徴的である。BAOBAO柄も見られる。
画質修正
今回DCGANには、上述したキルミーベイベー生成に使われているkerasコードをほぼそのまま使用した。そのため、収集したinput画像の画質を128x128に統一した。
画質を統一するにあたり、上述したアイドル生成に使われているコードを使用した。
import better_exceptions
import os
import glob
from PIL import Image
files = glob.glob('input画像が入ったディレクトリ/*.jpg')
a = 0
for f in files:
a += 1
img = Image.open(f)
img_resize = img.resize((128, 128))
ftitle, fext = os.path.splitext(f)
img_resize.save('128x128に画質を修正した画像の保存先ディレクトリ/' + str(a) + '_(128x128)' + fext)
# print(a, end=", ")
パスを確認して実行
$ python resize_images.py
KerasでDCGAN
関連事例のキルミーベイベー生成のコードをほぼそのまま使用。
27 ~ 29 行目で作業ディレクトリ、input画像ディレクトリ、生成画像保存先ディレクトリのパスを指定する。
import better_exceptions
################
from keras.layers import Input, Dense, Reshape, Flatten, Dropout
from keras.layers import BatchNormalization, Activation, ZeroPadding2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam
from keras.utils import np_utils
import tensorflow as tf
from keras.backend import tensorflow_backend
import matplotlib.pyplot as plt
import os
import cv2
import numpy as np
np.random.seed(0)
np.random.RandomState(0)
tf.set_random_seed(0)
config = tf.ConfigProto(gpu_options=tf.GPUOptions(allow_growth=True))
session = tf.Session(config=config)
tensorflow_backend.set_session(session)
# root_dir = "/home/takusub/PycharmProjects/Samples/dcgan/kill_me_baby_datasets/"
root_dir = "/作業/ディレクトリ/パス/" ### keras_dcgan.pyが保存されているディレクトリのフルパス
input_img_dir = "128x128に画質を修正した画像の保存先ディレクトリ"
save_dir = "generatorが生成した画像の保存先ディレクトリ/"
class DCGAN():
def __init__(self):
self.class_names = os.listdir(root_dir)
self.shape = (128, 128, 3)
self.z_dim = 100
optimizer = Adam(lr=0.0002, beta_1=0.5)
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])
self.generator = self.build_generator()
# self.generator.compile(loss='binary_crossentropy', optimizer=optimizer)
z = Input(shape=(self.z_dim,))
img = self.generator(z)
self.discriminator.trainable = False
valid = self.discriminator(img)
self.combined = Model(z, valid)
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
def build_generator(self):
noise_shape = (self.z_dim,)
model = Sequential()
model.add(Dense(128 * 32 * 32, activation="relu", input_shape=noise_shape))
model.add(Reshape((32, 32, 128)))
model.add(BatchNormalization(momentum=0.8))
model.add(UpSampling2D())
model.add(Conv2D(128, kernel_size=3, padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(momentum=0.8))
model.add(UpSampling2D())
model.add(Conv2D(64, kernel_size=3, padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(3, kernel_size=3, padding="same"))
model.add(Activation("tanh"))
model.summary()
noise = Input(shape=noise_shape)
img = model(noise)
return Model(noise, img)
def build_discriminator(self):
img_shape = self.shape
model = Sequential()
model.add(Conv2D(32, kernel_size=3, strides=2, input_shape=img_shape, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
model.add(ZeroPadding2D(padding=((0, 1), (0, 1))))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(128, kernel_size=3, strides=2, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(256, kernel_size=3, strides=1, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
model.summary()
img = Input(shape=img_shape)
validity = model(img)
return Model(img, validity)
def build_combined(self):
self.discriminator.trainable = False
model = Sequential([self.generator, self.discriminator])
return model
def train(self, iterations, batch_size=128, save_interval=50, model_interval=10000, check_noise=None, r=5, c=5):
X_train, labels = self.load_imgs()
half_batch = int(batch_size / 2)
X_train = (X_train.astype(np.float32) - 127.5) / 127.5
for iteration in range(iterations):
# ------------------
# Training Discriminator
# -----------------
idx = np.random.randint(0, X_train.shape[0], half_batch)
imgs = X_train[idx]
noise = np.random.uniform(-1, 1, (half_batch, self.z_dim))
gen_imgs = self.generator.predict(noise)
d_loss_real = self.discriminator.train_on_batch(imgs, np.ones((half_batch, 1)))
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, np.zeros((half_batch, 1)))
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# -----------------
# Training Generator
# -----------------
noise = np.random.uniform(-1, 1, (batch_size, self.z_dim))
g_loss = self.combined.train_on_batch(noise, np.ones((batch_size, 1)))
print("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (iteration, d_loss[0], 100 * d_loss[1], g_loss))
if iteration % save_interval == 0:
self.save_imgs(iteration, check_noise, r, c)
start = np.expand_dims(check_noise[0], axis=0)
end = np.expand_dims(check_noise[1], axis=0)
resultImage = self.visualizeInterpolation(start=start, end=end)
# cv2.imwrite("images/latent/" + "latent_{}.png".format(iteration), resultImage)
cv2.imwrite(save_dir + "latent_{}.png".format(iteration), resultImage)
if iteration % model_interval == 0:
# self.generator.save("ganmodels/dcgan-{}-iter.h5".format(iteration))
self.generator.save("mb_dcgan-{}-iter.h5".format(iteration))
def save_imgs(self, iteration, check_noise, r, c):
noise = check_noise
gen_imgs = self.generator.predict(noise)
# 0-1 rescale
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i, j].imshow(gen_imgs[cnt, :, :, :])
axs[i, j].axis('off')
cnt += 1
fig.savefig(save_dir + '%d.png' % iteration)
# fig.savefig('images/gen_imgs/kill_me_%d.png' % iteration)
plt.close()
def load_imgs(self):
img_paths = []
labels = []
images = []
# for cl_name in self.class_names:
# img_names = os.listdir(os.path.join(root_dir, cl_name))
# for img_name in img_names:
# img_paths.append(os.path.abspath(os.path.join(root_dir, cl_name, img_name)))
# hot_cl_name = self.get_class_one_hot(cl_name)
# labels.append(hot_cl_name)
for cl_name in self.class_names:
if cl_name == input_img_dir:
img_names = os.listdir(os.path.join(root_dir, cl_name))
for img_name in img_names:
img_paths.append(os.path.abspath(os.path.join(root_dir, cl_name, img_name)))
hot_cl_name = self.get_class_one_hot(cl_name)
labels.append(hot_cl_name)
for img_path in img_paths:
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
images.append(img)
images = np.array(images)
return (np.array(images), np.array(labels))
def get_class_one_hot(self, class_str):
label_encoded = self.class_names.index(class_str)
label_hot = np_utils.to_categorical(label_encoded, len(self.class_names))
label_hot = label_hot
return label_hot
def visualizeInterpolation(self, start, end, save=True, nbSteps=10):
print("Generating interpolations...")
steps = nbSteps
latentStart = start
latentEnd = end
startImg = self.generator.predict(latentStart)
endImg = self.generator.predict(latentEnd)
vectors = []
alphaValues = np.linspace(0, 1, steps)
for alpha in alphaValues:
vector = latentStart * (1 - alpha) + latentEnd * alpha
vectors.append(vector)
vectors = np.array(vectors)
resultLatent = None
resultImage = None
for i, vec in enumerate(vectors):
gen_img = np.squeeze(self.generator.predict(vec), axis=0)
gen_img = (0.5 * gen_img + 0.5) * 255
interpolatedImage = cv2.cvtColor(gen_img, cv2.COLOR_RGB2BGR)
interpolatedImage = interpolatedImage.astype(np.uint8)
resultImage = interpolatedImage if resultImage is None else np.hstack([resultImage, interpolatedImage])
return resultImage
if __name__ == '__main__':
dcgan = DCGAN()
r, c = 5, 5
check_noise = np.random.uniform(-1, 1, (r * c, 100))
dcgan.train(
iterations=200000,
batch_size=32,
# save_interval=1000,
save_interval=50, ### epoch回数が50の倍数になったときに、generator生成画像を保存
model_interval=5000,
check_noise=check_noise,
r=r,
c=c
)
python3で実行
$ python keras_dcgan.py
実行結果
実行時間
- 約29時間で6,450 epochs実行した。
- FinderとiTerm2とActivity Monitor以外のアプリは終了。
- tmuxを常用しているので全部落としてもよかったが、下記メモリ消費量から、そこまでしなくても実行時間はそんなに変わらんと思った。
- 画質が128x128と低く、画像も129枚と少なかったせいか、python3に消費するメモリ量は2GB行かないくらいであった。MacBookAirで十分耐えれる。
- 画質や枚数を上げると多分MacBookAirでは無理。
- 学習実行中、python3に15threads生成されていた。2-coreのHyperThreadingマシンに対し、15threadsの並列処理はthread生成コストがかさみ、HPC面では非効率となっていると考えられる。
- CPU消費量はほぼフル活用していた。メモリが食われてないことを考慮すると、実行時間はCPU(GPU)パワーに大きく依存しているかもしれない。
loss値
6450 epochsでacc 96.88%
6447 [D loss: 0.317351, acc.: 93.75%] [G loss: 10.875727]
6448 [D loss: 0.008998, acc.: 100.00%] [G loss: 11.289600]
6449 [D loss: 0.101565, acc.: 93.75%] [G loss: 10.386852]
6450 [D loss: 0.085736, acc.: 96.88%] [G loss: 8.654783]
DCGANによって自動生成されたdeep ISSEY MIYAKE
0 epoch
- 砂嵐。Hello, Deep ISSEY MIYAKE!
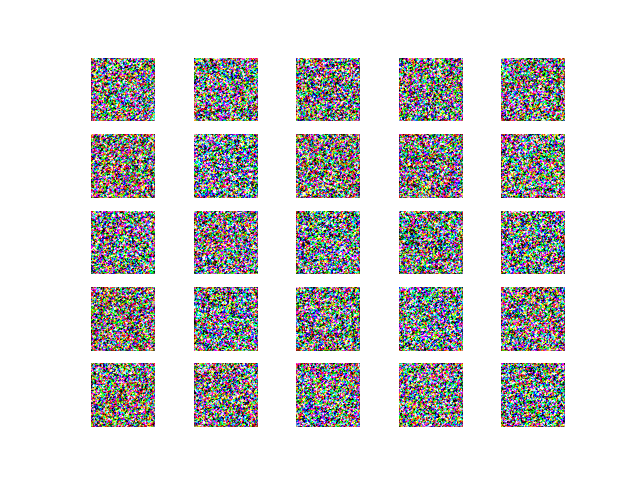
50 epochs
- なんとなく形が…
- でもよく分からんし、白黒。

300 epochs
- 誰かいる…。
- 色が付き始めた。


1,000 epochs
- 人であることはなんとなく分かる。
- カラーバリエーションも増えてきた。
- 2段目左端の服の色がこの後結構変わっていく。


1,900 epochs
- 色んな人がいる。
- 左上端の白い服の色がこの後変わっていく。
- 最下段中央の白い服の色がこのあと変わっていく。

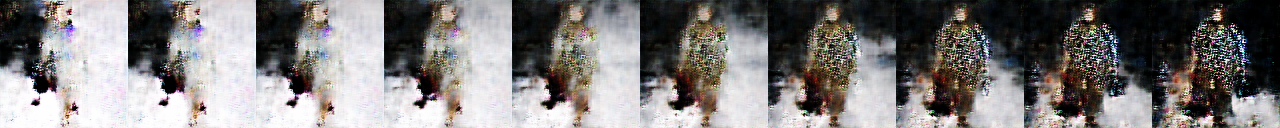
3,000 epochs
- 左上端の人の服が青くなった。カバンを持っているように見える。
- 2段目左端の人の服がグラデーションかかってきた。ISSEY MIYAKEにもグラデーションかかった服は見られる。
- 左から2列目など、ブツブツ模様ができている服が出てきた。実際ISSEY MIYAKEのファッションショーには目がチカチカするようなデザインが多く見受けられる。


4,000 epochs
- 最下段中央の服が黒くなってきた。
- 色使いやグラデーションがISSEY MIYAKEっぽいデザインになっている気がする。
- 少なくともユニ◯ロではこんなデザイン見ない気がする。


5,000 epochs
- また全体的に色が変わってきたが、形は大きくは変わらなくなった。
- 一部はファッションショーのステージが背景として生成されている。
- 背景と人との境界もはっきりしてきた。

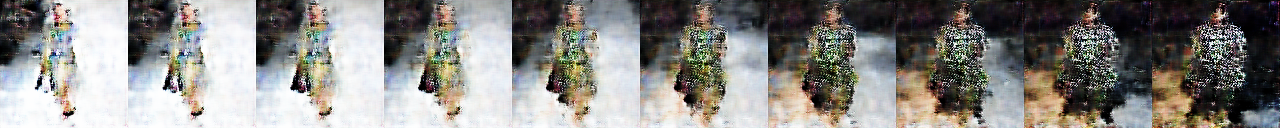
6,200 epochs
- 2,000 epochs以降で大きくは変わらないが、少しずつ鮮明になっている気がする。
- 細い人と太い人がいるように見えるが、実際ISSEY MIYAKEのファッションショーにはスラッとした服もあれば、大きく見せるような服もある。


考察
今回、ISSEY MIYAKEの画像をDCGANで学習して自動生成してみた。
学習に使用したISSEY MIYAKEのデザインが出ていると思われるものも観察できたが、
一方で、画質が荒くはっきりしないデザインもあった。
2,000epochs以降の改善が乏しいことからも、画質が128x128と低いことに原因があるように感じる。
また、背景と同化してしまっている画像も見受けられる。そこで今後は、
- 画像枚数を増やし、
- 服だけをトリミングし、
- 画質を上げて
分析実行できれば鮮明なdeep ISSEY MIYAKEを生成できるのではないかと考える。
アルゴリズムにももしかしたら改善の余地があるかもしれない。
今回、ソースコードを公開していただいた方には感謝したい。
筆者がやったことといえばせっせとISSEY MIYAKEの画像を129枚集めたことくらいである。
その他
エラー対処法
画像処理関係のエラーは闇が深いと感じた。
というのも、エラーメッセージをパッと見ただけでは本質的な原因がつかめないものばかりであったからだ。
cv2.error
OpenCV(3.4.1) Error: Assertion failed (scn == 3 || scn == 4) in cvtColor, file /opt/conda/conda-bld/opencv-suite_1527005509093/work/modules/imgproc/src/color.cpp, line 11115
Traceback (most recent call last):
File "keras_dcgan_mb.py", line 276, in <module>
c=c
│ └ 5
└ 5
File "keras_dcgan_mb.py", line 126, in train
X_train, labels = self.load_imgs()
└ <__main__.DCGAN object at 0x11bc7f5f8>
File "keras_dcgan_mb.py", line 217, in load_imgs
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
│ │ │ └ <module 'cv2' from '/Users/hoge/.pyenv/versions/anaconda3-4.2.0/lib/python3.5/site-packages/cv2.cpython-35m-darwin.so'>
│ │ └ None
│ └ <module 'cv2' from '/Users/hoge/.pyenv/versions/anaconda3-4.2.0/lib/python3.5/site-packages/cv2.cpython-35m-darwin.so'>
└ None
cv2.error: OpenCV(3.4.1) /opt/conda/conda-bld/opencv-suite_1527005509093/work/modules/imgproc/src/color.cpp:11115: error: (-215) scn == 3 || scn == 4 in function cvtColor
input画像の格納先ディレクトリパスを間違えていたり、画像ファイル以外のファイルが入っていると発生するエラー。
筆者は.DS_Storeが混じっていて発生した。
パスが違ったりファイルが違うことが原因のエラーなのにopencvで落ちるという分かりにくい厄介なエラーである。
Number of batches: 0
キルミーベイベー生成とは別のソースコードを実行した際に発生した。
学習はされているのに、画像が生成されない。
これは、画像が足りないことが原因だった。
BATCH_SIZE = 32で指定している数(32枚)以上の画像を集めないといけない。
エラーメッセージもなくただただ学習が実行し続けるだけの分かりにくい厄介なエラーである。
images = numpy.asarray(images)
これもキルミーベイベー生成とは別のソースコードで発生した。
ValueError: could not broadcast input array from shape (70,70,3) into shape (70,70)
これは画像データの中にRGB形式以外の画像(CMYK形式等)が混じっていることが原因。
Cmd+iで情報を確認すると、
Color space: RGBとなっていなきゃいけないところが、
Color space: CMYKになっちゃってる画像が紛れ込んでいた。
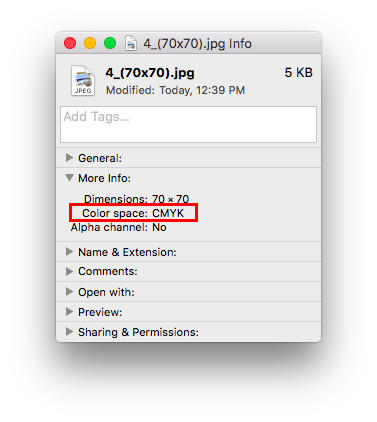
画像の形式によるエラーなのに、エラーメッセージはnumpyで発生するという分かりにくい厄介なエラーである。
より鮮明な画像が生成できたりしたら随時更新しようと思う。