TensorFlow2.0 Advent Calendar 2019の11日目です。
tf.data.Dataset APIを用いてテキストの前処理を行う方法をまとめたいと思います。
本記事では以下の順に説明します。
- tf.data.Dataset APIとは何か、また、その有効性は何かを説明
- 実際にテキストの前処理の手続きを説明
- performance向上のtipsのまとめ
説明が長いので(コードも長いですが。。。)コードだけ見て俯瞰したい場合はこちらから参照できます。
(注意として、本記事の内容は十分な検証ができているとは言えないです。コードは動きますが、パフォーマンスの向上に寄与しているのかいまいち把握しきれていないところがいくつかあります。随時更新していきますが、参考程度に留めておいていただけたらと思います。)
同アドベントカレンダーでは以下の記事が関連します。こちらも参考にされるといいかなと思います。
-
3日目: tf.data.Dataset APIの基本的な紹介がされています(TensorFlowで使えるデータセット機能が強かった話)
-
7日目: tf.data.Dataset APIで、Mecabを使った分かち書きの手順が紹介されています(Mecabとtf.dataを使ってlivedoorニュースコーパスを分かち書きする)
-
10日目: joblibで並列化してmapの高速化を図っています。本記事ではtf.dataの.map自体がもっている並列化機能を紹介しますが、どちらが速いのか追って検証したいです。(というか、組み合わせれそうです)(【TF2.0応用編】TFの例の強いデータセット機能で汎用的なDataAugmentationを並列化しハイスピードで実現した件)
1. tf.data.Dataset API
典型的な学習プロセスは、以下のような流れになると思います。
- データの読み込み: ローカルストレージ、インメモリ、クラウドストレージから読込
- 前処理: CPUで処理
- 学習用のデバイスにデータを渡す: GPU, TPUに渡す
- 学習: GPU, TPUで処理
データセットが大きくなってくると1~4の処理を一つずつやっていくと、リソースが足りなくなってきます。
(特に画像だと数GBであることがざらにあるので1. データの読み込みだけでも一度には処理できなくなります)
なので、バッチに分けて(例えば、数枚の画像毎に)1 ~ 4までの処理を一気通貫で行う。ということを繰り返すことが推奨されます。これはパイプライン処理と言います。
愚直なパイプラインをしくと、この一連のプロセスは、以下のようにオーバーヘッド部分に無駄な待ち時間が発生し得えます。

https://www.tensorflow.org/guide/data_performance
tf.data.Dataset APIでは以下のようにオーバーヘッドの処理を分散させて、余計な待ち時間を削減させる機能があります。
- prefetch: CPUとGPU/TPUでそれぞれ並列に処理
- map: 前処理の並列処理
- read_file: 読み込みの並列処理
これらについては後述します。まず、先にtf.data.Dataset APIの使い方を知るためにもテキストの前処理について書きます。
2. テキストの前処理の流れ
では、tf.data.Dataest APIを使ってテキストの前処理をやってみます。
順番は前後すると思いますが、標準的なテキストの前処理の流れは以下のようなものだと思います。
- load: テキストの読み込み・シャッフル
- standarize: ストップワード削除、置換、小文字に統一、など
- tokenize: 分かち書き(日本語の場合)
- encode: idに置き換え
- split: trainとtest用にデータ分割
- padding: ゼロ埋め
- batch: バッチデータとして取得
2.1. load
まずはじめに、dataset loaderをつくります。処理の流れは以下の様になります。
- local discにデータをダウンロード
- local discのデータを指定
- ラベルづけ
- データのシャッフル
local discにデータをダウンロード
昨今扱うデータセットのサイズがでかくなっているので、最初からlocal discにデータがあるケースはそこまで多くないと思います。なので、以下のようなケースが考えられます。
- 外部ストレージからダウンロード
- クラウドストレージからダウンロード
- Databaseから取得
ここでは、単に(認証の必要のない)外部ストレージからデータを取得する例を紹介します。
以下で、cowper.txt, derby.txt, butler.txtというテキストファイルをlocal discにダウンロードできます。 (ダウンロードが簡単なため、こちらの英語のテキストデータを使いますが、実際には日本語に対する前処理を想定しています)
なお、ダウンロードしたlocal discのpathのリストを返す関数になっています。適宜ダウンロードの仕方を置き換えた上で、アウトプットを揃えれば、以下同様な手続きが流用できると思います。
def download_file(directory_url: List[str], file_names: List[str]) -> List[str]:
file_paths = [
tf.keras.utils.get_file(file_name, directory_url + file_name)
for file_name in file_names
]
return file_paths
# download dataset in local disk
directory_url = 'https://storage.googleapis.com/download.tensorflow.org/data/illiad/'
file_names = ['cowper.txt', 'derby.txt', 'butler.txt']
file_paths = download_file(directory_url, file_names)
local discのデータを指定 & ラベルづけ & データのシャッフル
残りの処理は以下の様にまとめられます。これでtextとlabelをiterationしてくれるDatasetができます。
def load_dataset(file_paths: List[str], file_names: List[str], BUFFER_SIZE=1000):
# loadする複数ファイルを指定
files = tf.data.Dataset.list_files(file_paths)
# 各ファイル毎にmap関数を適用 (labeling_map_fnは後述(dataの読み込み & ラベルづけ))
datasets = files.interleave(
labeling_map_fn(file_names),
)
# dataのshuffle
all_labeled_data = datasets.shuffle(
BUFFER_SIZE, reshuffle_each_iteration=False
)
return all_labeled_data
datasets = load_dataset(file_paths, file_names)
text, label = next(iter(datasets))
print(text)
# <tf.Tensor: id=99928, shape=(), dtype=string, numpy=b'Comes furious on, but speeds not, kept aloof'>
print(label)
# <tf.Tensor: id=99929, shape=(), dtype=int64, numpy=0>
細かく処理をみていきます。
tf.data.Dataset.list_files(): loadする複数ファイルを指定
tf.data.Dataset.list_filesでつくったfilesは、以下のようにlocal discのpathを値としてもつDatasetインスタンスになっています。面倒ですが、Datasetインスタンスはイテレーションして中身を確認する必要があります。さらに面倒ですが、.numpy()メソッドを使うと値が取得できます。
print(files)
# <DatasetV1Adapter shapes: (), types: tf.string>
next(iter(files))
# <tf.Tensor: id=99804, shape=(), dtype=string, numpy=b'/Users/username/.keras/datasets/cowper.txt'>
next(iter(files)).numpy()
# b'/Users/username/.keras/datasets/cowper.txt'
.interleave(): 各ファイル毎にmap関数を適用してflatなDatasetを返す
datasetにmap functionを適用した後に、結果をflatにして結合します。今回の使い方でいうと、まずテキストファイルを読みこみ、1行ずつiterationするようなDatasetを返すmap funcitonを定義します。そしてそれを、.interleave()にわたすと、ファイルごとに別々のDatasetが作られるのではなく、全ファイルの中から一行ずつiterationされるflatなDatasetがつくられます。
参考: 公式ドキュメント
.shuffle(): dataのshuffle
名前からもわかるようにDatasetをシャッフルしてくれます。iteration時にbuffer_sizeの中からrandomにデータを抽出します。繰り返しiterationを行い、buffer_sizeをこえると、次のbuffer_size分のデータの中から抽出します。なので、大きいbuffer_sizeにしたほうが乱雑さは保証されます。しかし、buffer_sizeが大きいとその分リソースを食うのでトレードオフになります。
また、reshuffle_each_iteration=Falseとすると、iterationを何度開始しても同じ順番でシャッフルしてくれます。defaultではTrueなので単に.shuffle()を呼んだ後は、next(iter(dataset))や、for data in dataset:と書く度に異なる順番でiterationされてしまいます。良いか悪いかはさておき、要注意です。
labeling_map_fn: dataの読み込み & ラベルづけ
ファイル名がラベルになっていて、各行が1つのテキストデータである.txt ファイルを読み込む方法を紹介します。
標準的な処理だと思いますが、データの形式によって、適宜置き換えて頂ければと思います。
ここでは、以下のmap functionを.interleave()にわたすことでflatなテキストとラベルをもつDatasetを得ます。
- ファイルごとに
tf.data.TextLineDataset()でファイルを読み込みこんでDataset instanceを生成。 -
.map(labeler)でファイル名と一体一のラベルidをわりふります。
def labeling_map_fn(file_names):
def _get_label(datasets):
"""
datasetの値(file path)からfile名をパースし、
file_namesのインデックス番号をlabel IDとする
"""
filename = datasets.numpy().decode().rsplit('/', 1)[-1]
label = file_names.index(filename)
return label
def _labeler(example, label):
"""datasetにlabelを追加する"""
return tf.cast(example, tf.string), tf.cast(label, tf.int64)
def _labeling_map_fn(file_path: str):
"""main map function"""
# テキストファイルから1行ずつ読み込み
datasets = tf.data.TextLineDataset(file_path)
# file pathをlabel IDに変換
label = tf.py_function(_get_label, inp=[file_path], Tout=tf.int64)
# label IDをDatasetに追加
labeled_dataset = datasets.map(lambda ex: _labeler(ex, label))
return labeled_dataset
return _labeling_map_fn
途中、tf.py_functionという関数を使っています(doc)。 これは、Dataset APIのmap functionの引数はTensor objectが渡されるためです。Tensor objectはpythonでは直接値を参照できませんが、tf.py_functionでwrapしてあげると引数にnext(iter(dataset))としたときと同じ型の値が渡ります。なので、.numpy()で値を参照でき、馴染みのあるpythonの処理を書くことができます。
ただし、パフォーマンスに若干難があるようなので極力使わないようにしたいです。
2.2. standarize & 2.3. tokenize
ここではいろいろな処理を一気に行います。pythonのライブラリや、ベタ書きしたものを使う想定です。
tensorflowにもテキストに対する処理はたくさんありますが、結構大変なのでpythonで書いたものをそのまま使うことを想定します。少なくとも分かち書きはtensorflowではできないので、日本語だと必須の行程になると思います。
例 (janome使用)
janomeはpythonで実装されている形態素解析でpip installだけで使えるので便利です。以下の様にanalyzerという標準化のパイプラインを柔軟に構築できます。
from janome.tokenizer import Tokenizer
from janome.analyzer import Analyzer
from janome.charfilter import (
RegexReplaceCharFilter # 文字列置換
)
from janome.tokenfilter import (
CompoundNounFilter, # 複合名詞化
POSStopFilter, # 特定の品詞を除去
LowerCaseFilter # lowercaseに変換
)
def janome_tokenizer():
# standarize texts
char_filters = [RegexReplaceCharFilter(u'蛇の目', u'janome')]
tokenizer = Tokenizer()
token_filters = [CompoundNounFilter(), POSStopFilter(['記号','助詞']), LowerCaseFilter()]
analyze = Analyzer(char_filters, tokenizer, token_filters).analyze
def _tokenizer(text, label):
tokenized_text = " ".join([wakati.surface for wakati in analyze(text.numpy().decode())])
return tokenized_text, label
return _tokenizer
これだけで、以下の様に標準化・分かち書きされます。
text, _ = janome_tokenizer()('蛇の目は形態素解析器です。Easy to Use.', 0)
print(text)
# 'janome 形態素解析器 です easy to use.'
tf.py_functionでラップ
上記関数をDatset apiから呼びます。
そのためには、ここでもtf.py_functionを使って変換します。outputの型を指定する必要があります。そして、その関数を.map()でdatasetにわたすことで呼び出せます。
def tokenize_map_fn(tokenizer):
"""
convert python function for tf.data map
"""
def _tokenize_map_fn(text: str, label: int):
return tf.py_function(tokenizer, inp=[text, label], Tout=(tf.string, tf.int64))
return _tokenize_map_fn
datasets = datasets.map(tokenize_map_fn(janome_tokenizer()))
2.4. encode
encode (stringをIDに変換)するためにtensorflow_datasets.text APIを使います。
とくに、encodeには、tfds.features.text.Tokenizer()とtfds.features.text.TokenTextEncoderが便利です。
vocabulary作成
まずは、vocabularyを作成する必要があります。先に作っておく場合は以下は省略できます。
ここでは、学習データからvocabularyを作成します。tfds.features.text.Tokenizer()を使ってtokenを取得し、set()で重複を削除します。
import tensorflow_datasets as tfds
def get_vocabulary(datasets) -> Set[str]:
tokenizer = tfds.features.text.Tokenizer().tokenize
def _tokenize_map_fn(text, label):
def _tokenize(text, label):
return tokenizer(text.numpy()), label
return tf.py_function(_tokenize, inp=[text, label], Tout=(tf.string, tf.int64))
dataset = datasets.map(_tokenize_map_fn)
vocab = {g.decode() for f, _ in dataset for g in f.numpy()}
return vocab
vocab_set = get_vocabulary(datasets)
print(vocab_set)
# {'indomitable', 'suspicion', 'wer', ... }
encode
ここでは、tfds.features.text.TokenTextEncoder()を使って、vocabularyに含まれるtokenをIDに変換します。以下のencode_map_fn()をdatasets.map()にわたして使います。
def encoder(vocabulary_set: Set[str]):
"""
encode text to numbers. must set vocabulary_set
"""
encoder = tfds.features.text.TokenTextEncoder(vocabulary_set).encode
def _encode(text: str, label: int):
encoded_text = encoder(text.numpy())
return encoded_text, label
return _encode
def encode_map_fn(encoder):
"""
convert python function for tf.data map
"""
def _encode_map_fn(text: str, label: int):
return tf.py_function(encoder, inp=[text, label], Tout=(tf.int64, tf.int64))
return _encode_map_fn
datasets = datasets.map(encode_map_fn(encoder(vocab_set)))
print(next(iter(datasets))[0].numpy())
# [111, 1211, 4, 10101]
2.5. split
datasetをtrainとtestに分割します。最初からわかれている場合は以下は省略できます。
Dataset APIではdatasetの分割は以下の様にすごく簡単に実装できます。
def split_train_test(data, TEST_SIZE: int, BUFFER_SIZE: int, SEED=123):
"""
TEST_SIZE = test dataの数
note: because of reshuffle_each_iteration = True (default),
train_data is reshuffled if you reuse train_data.
"""
train_data = data.skip(TEST_SIZE).shuffle(BUFFER_SIZE, seed=SEED)
test_data = data.take(TEST_SIZE)
return train_data, test_data
2.6. padding & 2.7. batch
tf.data.Dataset apiではpaddingとbatch化は同時に行えます。
そのままですが、epochsはエポック数、BATCH_SIZEはバッチサイズです。
注意すべきことは以下です。
-
drop_remainder=Trueにするとデータをbatch化したときに、きりよくバッチサイズに達しなかったiterationの最後のデータを使用しなくなります。 - padded_shapesでpaddingするサイズ (=最大長)を指定できます。この引数を指定しなければ、バッチごとの最大長にpaddingされます。
train_data = train_data.padded_batch(BATCH_SIZE, padded_shapes=([max_len], []), drop_remainder=True)
test_data = test_data.padded_batch(BATCH_SIZE, padded_shapes=([max_len], []), drop_remainder=False)
ここで、max_lenは以下の様にdatasetから求めてもいいですし、決め打ちで入力してもいいと思います。
文書最大長の取得
ほとんどのモデルではtokenの最大長が必要になります。ここでデータセットから取得します。決めで入力する場合は以下の処理は飛ばせます。
def get_max_len(datasets) -> int:
tokenizer = tfds.features.text.Tokenizer().tokenize
def _get_len_map_fn(text: str, label: int):
def _get_len(text: str):
return len(tokenizer(text.numpy()))
return tf.py_function(_get_len, inp=[text, ], Tout=tf.int32)
dataset = datasets.map(_get_len_map_fn)
max_len = max({f.numpy() for f in dataset})
return max_len
テキストの前処理の流れのまとめ
以下のような流れでtf.data.Dataset APIを使った実装を見ていきました。
- load: テキストの読み込み・シャッフル
- standarize: ストップワード削除、置換、小文字に統一、など
- tokenize: 分かち書き(日本語の場合)
- encode: idに置き換え
- split: trainとtest用にデータ分割
- padding: ゼロ埋め
- batch: バッチデータとして取得
学習時には、以下の様に、.fit()メソッドにわたすだけです。
model.fit(train_data,
epochs=epochs,
validation_data=test_data
)
3. performance向上のtips
冒頭で説明したように、前処理の一連のプロセスは、以下のようにオーバーヘッド部分に無駄な待ち時間が発生し得えます。
https://www.tensorflow.org/guide/data_performance
tf.data.Dataset APIでは以下のようにオーバーヘッドの処理を分散させて、余計な待ち時間を削減させる機能があります。
- prefetch: CPUとGPU/TPUでそれぞれ並列に処理
- map: 前処理の並列処理
- read_file: 読み込みの並列処理
参考: Optimizing input pipelines with tf.data
prefetch
CPUとGPU/TPUでそれぞれ並列に処理を実行させます。
tf.experiments.AUTOTUNEで自動的に調節されます。
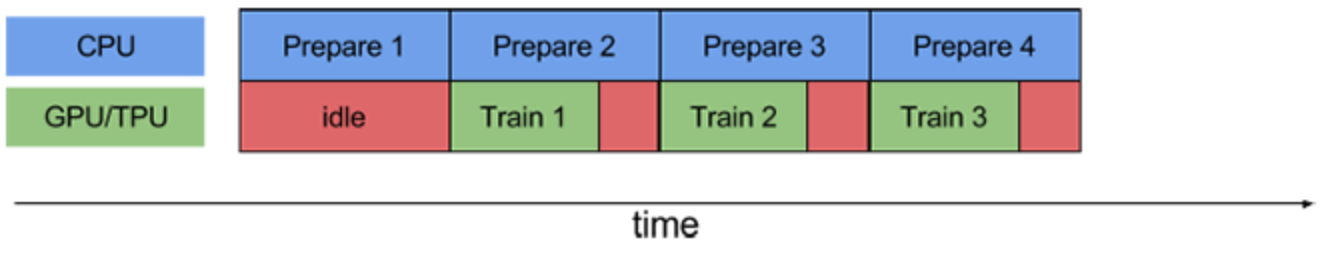
https://www.tensorflow.org/guide/data_performance
面倒なことは必要ありません。以下の処理を最後に加えるだけです。(本記事ではtrain_dataとtest_dataに対して行う)
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
map
map関数も分散処理をさせられます。
こちらもtf.experiments.AUTOTUNEで自動的に調節してくれます。
また、あまり遅くなるようであれば先に.batch()メソッドを使ってから渡すという手もあります。
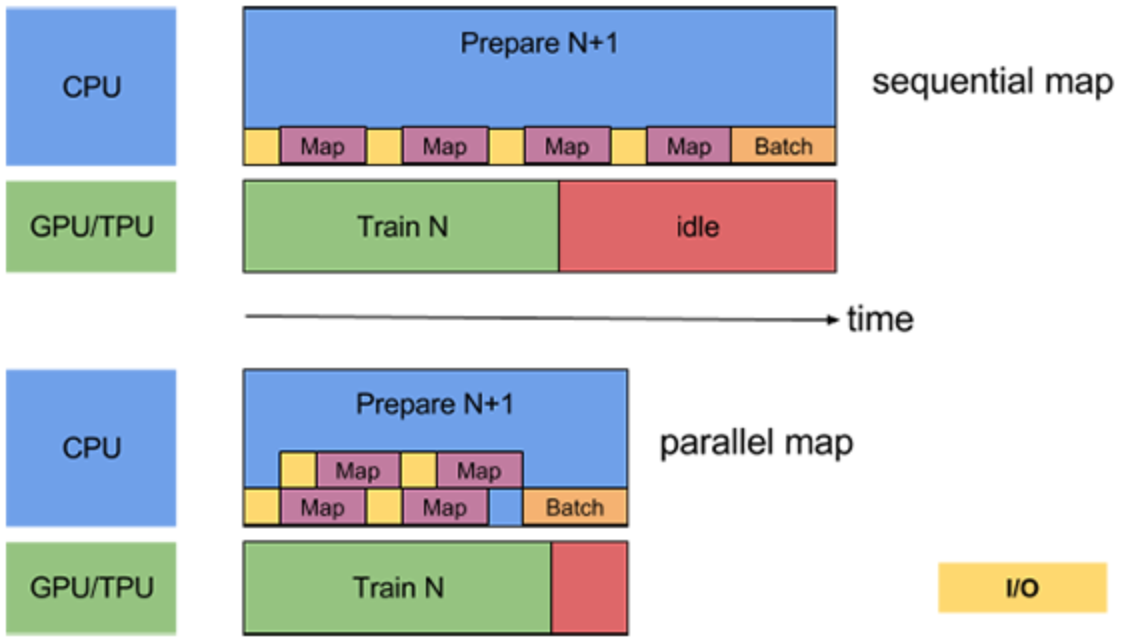
https://www.tensorflow.org/guide/data_performance
以下の様に、.map()メソッドに引数を加えるだけです。
dataset = dataset.map(map_func, num_parallel_calls=tf.data.experimental.AUTOTUNE)
read file
複数ファイルを読み込むときも、処理を分散させて同時にreadできます。
特にremote storageからdataを読み込むときはI/Oがボトルネックになる可能性が高いです。
(本記事ではlocal discから読み込んでいるのであまり効果はないかもしれません。)
 https://www.tensorflow.org/guide/data_performance
https://www.tensorflow.org/guide/data_performance
以下の様に、.interleave()メソッドに引数を加える必要があります。
dataset = files.interleave(
tf.data.TFRecordDataset, cycle_length=FLAGS.num_parallel_reads,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
cache
文脈はかわりますが、performance向上のためには、.cache()が有効です。
以下の様に書くと、in memoryにcacheされます。
dataset = dataset.cache()
以下の様に引数にstringをわたすとin memoryではなく、ファイルに保存されます。
dataset = dataset.cache('tfdata')
まとめ
長くなりましたが、tf.data.Dataset APIを用いたテキストの前処理を行う方法を紹介しました。まとまったコードはこちらから参照できます。
特に、tf.data.Dataset APIの紹介、テキストの前処理の手続き、performance向上のtipsをまとめました。
説明が長くなってしまいましたが、最後まで読んでくださってありがとうございました!
何かの参考になれば嬉しいです!