はじめに
今回の記事は、前回の記事「TensorFlowで使えるデータセット機能が強かった話」「【TF2.0応用編】tf.data.DatasetでDataAugmentationをクッソ早くする」で少し上がっていたDataAugmentationの、さらに強化版の話です。
tf.data.Datasetによる速度面での強化と、keras.preprocessing.image系を利用しながら
並列処理できるコードを実現することに成功しました。
実際の仕組みや、ここまでに至った経緯などはコードの次に載せようと思います。
以下にそのコードを載せます
環境整備
まずは実験環境を整備しましょう。
import tensorflow as tf
import tensorflow.keras as keras
import matplotlib.pyplot as plt
import sklearn
import numpy as np
from tqdm import tqdm
(tr_x,tr_y),(te_x,te_y)=keras.datasets.cifar10.load_data()
tr_x, te_x = tr_x/255.0, te_x/255.0
tr_y, te_y = tr_y.reshape(-1,1), te_y.reshape(-1,1)
model = keras.models.Sequential()
model.add(keras.layers.Convolution2D(32,3,padding="same",activation="relu",input_shape=(32,32,3)))
model.add(keras.layers.Convolution2D(32,3,padding="same",activation="relu"))
model.add(keras.layers.Convolution2D(32,3,padding="same",activation="relu"))
model.add(keras.layers.MaxPooling2D())
model.add(keras.layers.Convolution2D(128,3,padding="same",activation="relu"))
model.add(keras.layers.Convolution2D(128,3,padding="same",activation="relu"))
model.add(keras.layers.Convolution2D(128,3,padding="same",activation="relu"))
model.add(keras.layers.Convolution2D(128,3,padding="same",activation="relu"))
model.add(keras.layers.Convolution2D(128,3,padding="same",activation="relu"))
model.add(keras.layers.MaxPooling2D())
model.add(keras.layers.Convolution2D(256,3,padding="same",activation="relu"))
model.add(keras.layers.Convolution2D(256,3,padding="same",activation="relu"))
model.add(keras.layers.Convolution2D(256,3,padding="same",activation="relu"))
model.add(keras.layers.GlobalAveragePooling2D())
model.add(keras.layers.Dense(1000,activation="relu"))
model.add(keras.layers.Dense(128,activation="relu"))
model.add(keras.layers.Dense(10,activation="softmax"))
model.compile(loss="sparse_categorical_crossentropy",metrics=["accuracy"])
DataAugmentationの一例
データの確認
まずはkeras.preprocessing.image.random_rotateを.mapでできるように表現してみましょう。
from tensorflow.keras.preprocessing.image import random_rotation
from joblib import Parallel, delayed
def r_rotate(imgs, degree):
pics=imgs.numpy()
degree = degree.numpy()
if tf.rank(imgs)==4:
X=Parallel(n_jobs=-1)( [delayed(random_rotation)(pic, degree, 0, 1, 2) for pic in pics] )
X=np.asarray(X)
elif tf.rank(imgs)==3:
X=random_rotation(pics, degree, 0, 1, 2)
return X
@tf.function
def random_rotate(imgs, label):
x = tf.py_function(r_rotate,[imgs,30],[tf.float32])
X = x[0]
X.set_shape(imgs.shape)
return X, label
これで、実際に動きます。動かしてデータをみてみましょう。
labels = np.array([
'airplane',
'automobile',
'bird',
'cat',
'deer',
'dog',
'frog',
'horse',
'ship',
'truck'])
tr_ds = tf.data.Dataset.from_tensor_slices((tr_x,tr_y)).shuffle(40000).batch(128).map(random_rotate)
plt.figure(figsize=(10,10),facecolor="white")
for b_img,b_label in tr_ds:
for i, img,label in zip(range(25),b_img,b_label):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(img)
plt.xlabel(labels[label])
break
plt.show()

スピードテスト
実際にどれくらいのスピードになるかチェックしてみましょう。
まずは、「【TF2.0応用編】tf.data.DatasetでDataAugmentationをクッソ早くする」でのスピードは以下の通りでした。
Train on 50000 samples
50000/50000 [==============================] - 9s 175us/sample - loss: 2.3420 - accuracy: 0.1197
Train on 50000 samples
50000/50000 [==============================] - 7s 131us/sample - loss: 2.0576 - accuracy: 0.2349
Train on 50000 samples
50000/50000 [==============================] - 7s 132us/sample - loss: 1.7687 - accuracy: 0.3435
Train on 50000 samples
50000/50000 [==============================] - 7s 132us/sample - loss: 1.5947 - accuracy: 0.4103
Train on 50000 samples
50000/50000 [==============================] - 7s 132us/sample - loss: 1.4540 - accuracy: 0.4705
CPU times: user 1min 33s, sys: 8.03 s, total: 1min 41s
Wall time: 1min 14s
次に、先ほどの実装でのコードと結果を載せます。
%%time
tr_ds = tf.data.Dataset.from_tensor_slices((tr_x,tr_y)).shuffle(40000)
tr_ds = tr_ds.batch(tr_x.shape[0]).map(random_rotate).repeat(5)
tr_ds = tr_ds.prefetch(tf.data.experimental.AUTOTUNE)
for img,label in tr_ds:
model.fit(x=img,y=label,batch_size=128)
Train on 50000 samples
50000/50000 [==============================] - 9s 176us/sample - loss: 1.3960 - accuracy: 0.5021
Train on 50000 samples
50000/50000 [==============================] - 9s 173us/sample - loss: 1.2899 - accuracy: 0.5430
Train on 50000 samples
50000/50000 [==============================] - 9s 175us/sample - loss: 1.2082 - accuracy: 0.5750
Train on 50000 samples
50000/50000 [==============================] - 9s 171us/sample - loss: 1.1050 - accuracy: 0.6133
Train on 50000 samples
50000/50000 [==============================] - 7s 132us/sample - loss: 1.0326 - accuracy: 0.6405
CPU times: user 52 s, sys: 15.4 s, total: 1min 7s
Wall time: 48.7 s

最大90%でGPUが動きながら、CPUで前処理のMapが働いているといった感じでしょうか。
トータルで48.7秒ですから、25秒ほど短縮出来ています。
また、Mapしない場合での時間は、35.1秒でしたから、相当早くDataAugmentationができることがわかります。
そして、同じ要領でやればkeras.preprocessing.image系は全てできることになります。
Kerasで可能なDataAugmentationを移植する
下準備
def show_data(tf_dataset):
for b_img,b_label in tf_dataset:
for i, img,label in zip(range(25),b_img,b_label):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(img)
plt.xlabel(labels[label])
break
plt.show()
random_shift
最大何%分ランダムでずらすか指定出来ます。
from tensorflow.keras.preprocessing.image import random_shift
from joblib import Parallel, delayed
def r_shift(imgs,wrg,hrg):
pics=imgs.numpy()
w = wrg.numpy()
h = wrg.numpy()
if tf.rank(imgs)==4:
X=Parallel(n_jobs=-1)( [delayed(random_shift)(pic,w,h,0,1,2) for pic in pics] )
X=np.asarray(X)
elif tf.rank(imgs)==3:
X=random_shift(pics, w,h, 0, 1, 2)
return X
@tf.function
def tf_random_shift(imgs, label):
x = tf.py_function(r_shift,[imgs,0.3,0.3],[tf.float32])
X = x[0]
X.set_shape(imgs.shape)
return X, label
tr_ds = tf.data.Dataset.from_tensor_slices((tr_x,tr_y)).shuffle(40000).batch(128).map(tf_random_shift)
plt.figure(figsize=(10,10),facecolor="white")
show_data(tr_ds)

random_shear
歪ませることが出来ます。(詳細はぶっちゃけ私もよく知らないです)
from tensorflow.keras.preprocessing.image import random_shear
def r_shear(imgs,degree):
pics=imgs.numpy()
degree = degree.numpy()
if tf.rank(imgs)==4:
X=Parallel(n_jobs=-1)( [delayed(random_shear)(pic,degree,0,1,2) for pic in pics] )
X=np.asarray(X)
elif tf.rank(imgs)==3:
X=random_shear(pics,degree,0,1,2)
return X
@tf.function
def tf_random_shear(imgs, label):
x = tf.py_function(r_shear,[imgs,30],[tf.float32])
X = x[0]
X.set_shape(imgs.shape)
return X, label
tr_ds = tf.data.Dataset.from_tensor_slices((tr_x,tr_y)).shuffle(40000).batch(128).map(tf_random_shear)
plt.figure(figsize=(10,10),facecolor="white")
show_data(tr_ds)

random_zoom
ランダムでズームします。
from tensorflow.keras.preprocessing.image import random_zoom
def r_zoom(imgs,range_w,range_h):
pics=imgs.numpy()
zoom_range = (range_w.numpy(),range_h.numpy())
if tf.rank(imgs)==4:
X=Parallel(n_jobs=-1)( [delayed(random_zoom)(pic,zoom_range,0,1,2) for pic in pics] )
X=np.asarray(X)
elif tf.rank(imgs)==3:
X=random_zoom(pics,zoom_range,0,1,2)
return X
@tf.function
def tf_random_zoom(imgs, label):
x = tf.py_function(r_zoom,[imgs,0.5,0.5],[tf.float32])
X = x[0]
X.set_shape(imgs.shape)
return X, label
tr_ds = tf.data.Dataset.from_tensor_slices((tr_x,tr_y)).shuffle(40000).batch(128).map(tf_random_zoom)
plt.figure(figsize=(10,10),facecolor="white")
show_data(tr_ds)

なんか等倍っぽいですね...改良しましょう。
改良
from tensorflow.keras.preprocessing.image import random_zoom
import random
def zoom_range_gen(random_state):
while True:
x=random.uniform(random_state[0],random_state[1])
yield (x,x)
def r_zoom(imgs):
pics=imgs.numpy()
random_state = [0.5,1.5]
if tf.rank(imgs)==4:
X=Parallel(n_jobs=-1)( [delayed(random_zoom)(pic,(x,y),0,1,2) for pic,(x,y) in zip(pics,zoom_range_gen(random_state))])
X=np.asarray(X)
elif tf.rank(imgs)==3:
zoom_range=next(zoom_range_gen)
X=random_zoom(pics,zoom_range,0,1,2)
return X
@tf.function
def tf_random_zoom_enhanced(imgs, label):
x = tf.py_function(r_zoom,[imgs],[tf.float32])
X = x[0]
X.set_shape(imgs.shape)
return X, label
データを確認してみましょう
tr_ds = tf.data.Dataset.from_tensor_slices((tr_x,tr_y)).shuffle(40000).batch(128).map(tf_random_zoom_enhanced)
plt.figure(figsize=(10,10),facecolor="white")
show_data(tr_ds)

いい感じですな!!
別のAugmentationも実装する。
次に、こちらのブログ「NumPyでの画像のData Augmentationまとめ」でのAugmentationをこちらで実装する
KerasでのAugmentationはNumpyベースなので、NumpyベースのAugmentationはこれで実装できます。
猫ちゃんの画像については、ブログ「NumPyでの画像のData Augmentationまとめ」から引用させて頂きます。
内容についてもこちらの実装から引用させて頂きます。コード内に出典も書かせて頂きます。
random-flip

こちらより引用させて頂きました
ランダムで左右逆転させるのを実装しましょう。これはTF系ですでに実装済みなのでそれを流用します。
@tf.function
def flip_left_right(image,label):
return tf.image.random_flip_left_right(image),label
@tf.function
def flip_up_down(image,label):
return tf.image.random_flip_up_down(image),label
tr_ds = tf.data.Dataset.from_tensor_slices((tr_x,tr_y)).shuffle(40000).batch(128)
tr_ds = tr_ds.map(flip_left_right).map(flip_up_down)
plt.figure(figsize=(10,10),facecolor="white")
show_data(tr_ds)

random-clip
ここではブログ内のScale Augmentationを利用します。

こちらより引用させて頂きました
実装もブログの方を参考にさせて頂きました。
from PIL import Image
def random_crop(pic, crop_size=(28, 28)):
try:
h, w, c = pic.shape
except ValueError:
raise ValueError("4Ds image can't decode")
# 指定した区間で画像の左上の点を決める
top = np.random.randint(0, h - crop_size[0])
left = np.random.randint(0, w - crop_size[1])
# サイズに合うように右下の点を決める
bottom = top + crop_size[0]
right = left + crop_size[1]
# 左上の点と右下の点の交差する部分だけを切り抜く
pic = pic[top:bottom, left:right, :]
return pic
def scale_augmentation(pic, scale_range=(38, 80), crop_size=32):
scale_size = np.random.randint(*scale_range)
Ppic = Image.fromarray(pic)
Ppic = Ppic.resize((scale_size,scale_size),resample=1)
pic = np.asarray(Ppic)
return random_crop(pic, (crop_size, crop_size))
def r_crop(imgs):
pics=imgs.numpy()
pics=np.asarray(pics * 255.0,dtype=np.uint8)
random_state = (38,60)
crop_size=32
if tf.rank(imgs)==4:
X=Parallel(n_jobs=-1)([delayed(scale_augmentation)(pic,random_state,crop_size) for pic in pics ])
X=np.asarray(X)
elif tf.rank(imgs)==3:
X=scale_augmentation(pics,random_state,crop_size)
X=X/255.0
return X
@tf.function
def tf_random_crop(imgs, label):
x = tf.py_function(r_crop,[imgs],[tf.float32])
X = x[0]
X.set_shape(imgs.shape)
return X, label
tr_ds = tf.data.Dataset.from_tensor_slices((tr_x,tr_y)).shuffle(40000).batch(128)
tr_ds = tr_ds.map(tf_random_crop)
plt.figure(figsize=(10,10),facecolor="white")
show_data(tr_ds)

random-erasing

こちらより引用させて頂きました
これを実装します。実装はブログの方を参考にさせて頂きました。
def random_erasing(pic, p=0.5, s=(0.02, 0.4), r=(0.3, 3)):
# マスクするかしないか
if np.random.rand() > p:
return pic
# マスクする画素値をランダムで決める
mask_value = np.random.random()
try:
h, w, c = pic.shape
except ValueError:
raise ValueError("4Ds image can't decode")
# マスクのサイズを元画像のs(0.02~0.4)倍の範囲からランダムに決める
mask_area = np.random.randint(h * w * s[0], h * w * s[1])
# マスクのアスペクト比をr(0.3~3)の範囲からランダムに決める
mask_aspect_ratio = np.random.rand() * r[1] + r[0]
# マスクのサイズとアスペクト比からマスクの高さと幅を決める
# 算出した高さと幅(のどちらか)が元画像より大きくなることがあるので修正する
mask_height = int(np.sqrt(mask_area / mask_aspect_ratio))
if mask_height > h - 1:
mask_height = h - 1
mask_width = int(mask_aspect_ratio * mask_height)
if mask_width > w - 1:
mask_width = w - 1
top = np.random.randint(0, h - mask_height)
left = np.random.randint(0, w - mask_width)
bottom = top + mask_height
right = left + mask_width
pic[top:bottom, left:right, :].fill(mask_value)
return pic
def r_erase(imgs):
pics=imgs.numpy()
if tf.rank(imgs)==4:
X=Parallel(n_jobs=-1)([delayed(random_erasing)(pic) for pic in pics ])
X=np.asarray(X)
elif tf.rank(imgs)==3:
X=random_erasing(pics)
return X
@tf.function
def tf_random_erase(imgs, label):
x = tf.py_function(r_erase,[imgs],[tf.float32])
X = x[0]
X.set_shape(imgs.shape)
return X, label
tr_ds = tf.data.Dataset.from_tensor_slices((tr_x,tr_y)).shuffle(40000).batch(128)
tr_ds = tr_ds.map(tf_random_erase)
plt.figure(figsize=(10,10),facecolor="white")
show_data(tr_ds)

CIFAR10だとちょっとかぶっちゃったり、わからないのも多少出てきてしまっていますね...
汎用的にAugmentationを実装する上で大事なこと
ここからはコードを作成する上での注意点です。
基本的なことなので、なーんだと思われる方もいらっしゃるかと思いますが、
意外にも落とし穴ばかりだったので、ここにメモします。
tf.data.Dataset.mapについて
結構ここで落とし穴があるんですが、mapしている最中の挙動はTensor型になります。
...何が言いたいかというと、.mapで扱われるTensorではEager Executionが発動しません。
つまり、通常の掛け算などは@tf.functionで綺麗にTF系オペレーションに変換できますが、
そうでない.numpy()などの、実数値が伴ってないとできない操作は使用できません。
x+y=zみたいな式として記載されているだけと思っていただければわかりやすいかと思います。
そこで何を使えば良いかというと、Eager modeをオンにする操作です。
どうすればいいかというと、tf.py_functionを使うということです。
そもそもEager ModeとGraph Modeって何だっけ
Graphモードは計算式のような存在です。TF1.x系でSess.runとかやってたのはこれです。
数式 x+y=zみたいな存在を一旦設計し、それから変数に値を代入することで(つまり、SessionをRunすることで)
2+3=5 ZのTensorは初めて5という数値が出てきます。ここがTF1.x系の解りづらかった所です。
Eager Modeとは、式を入力したら即時実行した値を出力するといった感じです。
Sess.runを自動実行してくれるし、Graphは保持してるから解りやすいみたいな感じでしょうか。
(自分は全然ここら辺詳しくないので、公式ガイドを参考にして頂けると幸いです。)
(間違っていたら教えてください)
tf.py_functionについて
tf.py_functionとは、Guideにもある通り、一部分だけEager Modeで実行することができる機能です。
ここではつまり、ブラックボックスな関数f(x)を設定して、何が出てくるかだけを指定するだけでGraph Modeで実行してくれる
といった感じになります。
式としては、x+f(a,b)=yみたいな式をTF側は欲しい訳で、ここで必要となるのは入力と、出力のデータ型です。
def function(入力1,入力2):
#ここではEager Modeで実行される
#何かの処理
return 出力1,出力2
[出力1,出力2] = tf.py_function(function,[入力1,入力2],[出力1の型,出力2の型])
具体的にはこうなります。
def function(data1,data2):
return data1+data2,data1*data2
@tf.function
def process(tensor1,tensor2):
[data1,data2]=tf.py_function(function,[tensor1,tensor2],[tf.float32,tf.float32])
return data1, data2
つまり、ここでのfunction関数は、実行時にEager Modeで実行されるため、Tensorに値が入ったtf.Tensorになります。
tf.TensorとTensorはEager ModeとGraph Modeとで違うので要注意です
py_functionで指定された関数内の挙動
これはEager Modeで実行され、tf.Tensorが運ばれてきますから、初手.numpy()して結果もnumpyで返して大丈夫です。
多くの勘違いを産む点がここにあるのです。
tf.data.Dataset.mapはあくまで最初はGraphモードで最初は動きます。その上で一部Eagerモードで動かす必要があるのです。
全体を図にまとめると
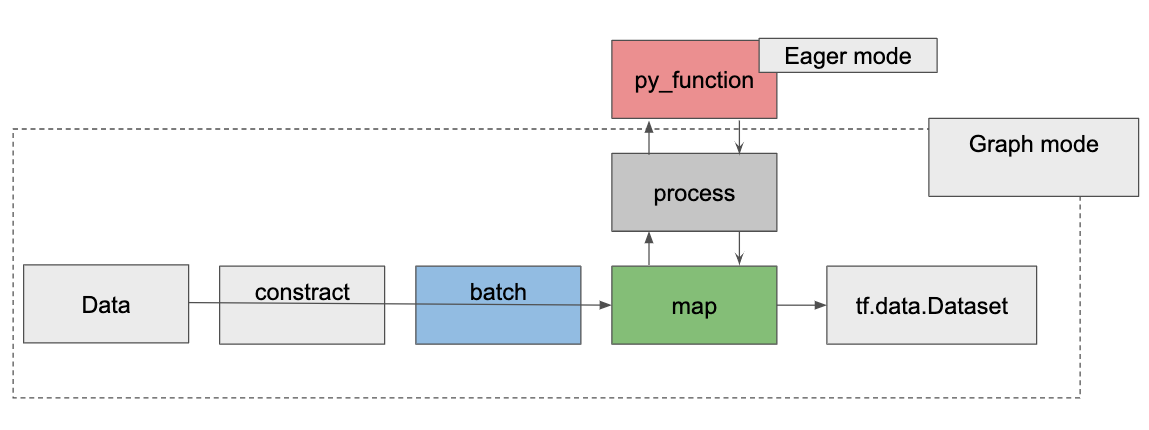
これがtf.data.Dataset.from_tensor_slicesの挙動だと思われます。(正確な情報ではないので、ごめんなさいですが)
そしてデータ排出のときは次のようになります。
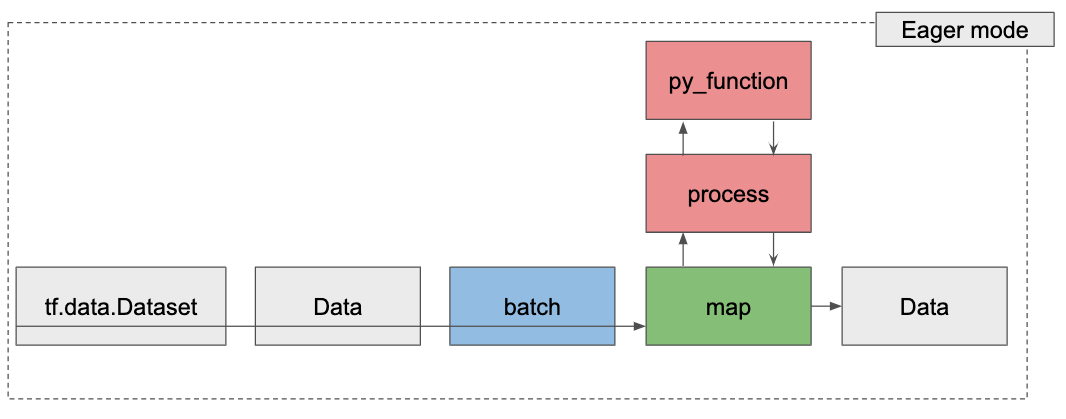
これを意識してコーディングすれば、謎のバグなどに惑わされずに、スムーズにコーディングすることができるでしょう。
おわりに
これで、汎用的なDataAugmentationの開発方法はお伝えできたのかなと考えてます。
他にもこんなのを作ってみたい!っていう方もどしどし同じ方法で作っていただければと思います。
自分はpy_functionの謎が解けて本当にホッとしております。
ぜひご活用ください。
謝辞
実装する上で、こちらのブログ「NumPyでの画像のData Augmentationまとめ」はかなり役に立ちました。
この場を持って感謝の意を表します。