はじめに
この記事はTF2.0AdventCalendarで、tf.data.Datasetを使うことによる副作用的な物を検証したものになります。
実際、tf.data.Datasetを使ってmodel.fit_generatorがどれくらいの速度になるのかを検証しました。
CIFAR10で検証
データセットを用意しましょう。
import tensorflow as tf
import tensorflow.keras as keras
import matplotlib.pyplot as plt
import sklearn
import numpy as np
from tqdm import tqdm
(tr_x,tr_y),(te_x,te_y)=keras.datasets.cifar10.load_data()
tr_x, te_x = tr_x/255.0, te_x/255.0
tr_y, te_y = tr_y.reshape(-1,1), te_y.reshape(-1,1)
tr_ds = tf.data.Dataset.from_tensor_slices((tr_x,tr_y)).batch(128)
for img,label in tr_ds:
print(img.shape,label.shape)
break
(128, 32, 32, 3) (128, 1)
正常に出力されているようです。
モデルに入れる
検証用のモデルを作りましょう。
model = keras.models.Sequential()
model.add(keras.layers.Convolution2D(32,3,padding="same",activation="relu",input_shape=(32,32,3)))
model.add(keras.layers.Convolution2D(32,3,padding="same",activation="relu"))
model.add(keras.layers.Convolution2D(32,3,padding="same",activation="relu"))
model.add(keras.layers.MaxPooling2D())
model.add(keras.layers.Convolution2D(128,3,padding="same",activation="relu"))
model.add(keras.layers.Convolution2D(128,3,padding="same",activation="relu"))
model.add(keras.layers.Convolution2D(128,3,padding="same",activation="relu"))
model.add(keras.layers.Convolution2D(128,3,padding="same",activation="relu"))
model.add(keras.layers.Convolution2D(128,3,padding="same",activation="relu"))
model.add(keras.layers.MaxPooling2D())
model.add(keras.layers.Convolution2D(256,3,padding="same",activation="relu"))
model.add(keras.layers.Convolution2D(256,3,padding="same",activation="relu"))
model.add(keras.layers.Convolution2D(256,3,padding="same",activation="relu"))
model.add(keras.layers.GlobalAveragePooling2D())
model.add(keras.layers.Dense(1000,activation="relu"))
model.add(keras.layers.Dense(128,activation="relu"))
model.add(keras.layers.Dense(10,activation="softmax"))
model.compile(loss="sparse_categorical_crossentropy",metrics=["accuracy"])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 32, 32, 32) 896
_________________________________________________________________
conv2d_1 (Conv2D) (None, 32, 32, 32) 9248
_________________________________________________________________
conv2d_2 (Conv2D) (None, 32, 32, 32) 9248
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 16, 16, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 16, 16, 128) 36992
_________________________________________________________________
conv2d_4 (Conv2D) (None, 16, 16, 128) 147584
_________________________________________________________________
conv2d_5 (Conv2D) (None, 16, 16, 128) 147584
_________________________________________________________________
conv2d_6 (Conv2D) (None, 16, 16, 128) 147584
_________________________________________________________________
conv2d_7 (Conv2D) (None, 16, 16, 128) 147584
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 8, 8, 128) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 8, 8, 256) 295168
_________________________________________________________________
conv2d_9 (Conv2D) (None, 8, 8, 256) 590080
_________________________________________________________________
conv2d_10 (Conv2D) (None, 8, 8, 256) 590080
_________________________________________________________________
global_average_pooling2d (Gl (None, 256) 0
_________________________________________________________________
dense (Dense) (None, 1000) 257000
_________________________________________________________________
dense_1 (Dense) (None, 128) 128128
_________________________________________________________________
dense_2 (Dense) (None, 10) 1290
=================================================================
Total params: 2,508,466
Trainable params: 2,508,466
Non-trainable params: 0
_________________________________________________________________
いい感じに重そうですね。
データセットを入れてみる。
まずは通常の入れ方
%%time
model.fit(tr_x,tr_y,batch_size=128,epochs=5)
Train on 50000 samples
Epoch 1/5
50000/50000 [==============================] - 7s 145us/sample - loss: 0.6238 - accuracy: 0.7833
Epoch 2/5
50000/50000 [==============================] - 7s 135us/sample - loss: 0.5584 - accuracy: 0.8104
Epoch 3/5
50000/50000 [==============================] - 7s 136us/sample - loss: 0.4936 - accuracy: 0.8303
Epoch 4/5
50000/50000 [==============================] - 7s 139us/sample - loss: 0.4467 - accuracy: 0.8479
Epoch 5/5
50000/50000 [==============================] - 7s 136us/sample - loss: 0.4016 - accuracy: 0.8631
CPU times: user 35.5 s, sys: 4.15 s, total: 39.6 s
Wall time: 35.1 s
nvtopでの画像がこちら
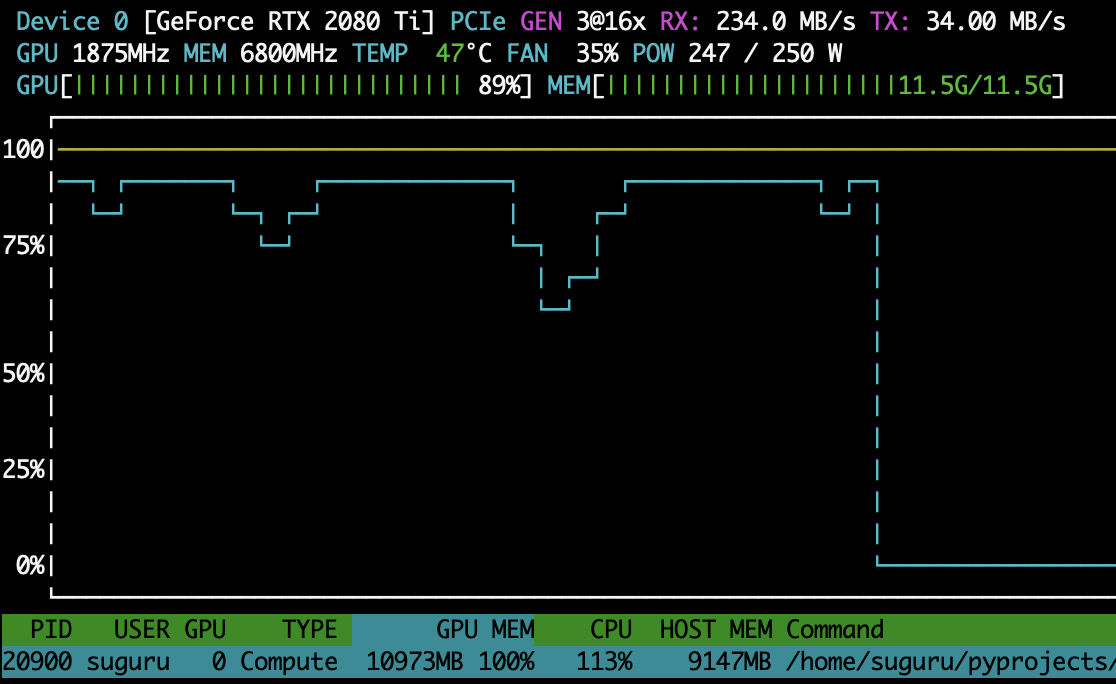
結構いい感じにGPUを使ってるように見えます。
tf.data.Datasetで入れる
次にtf.data.Datasetでデータを入れましょう。
%%time
model.fit_generator(tr_ds,epochs=5)
Epoch 1/5
391/391 [==============================] - 12s 31ms/step - loss: 2.3748 - accuracy: 0.1219
Epoch 2/5
391/391 [==============================] - 12s 31ms/step - loss: 1.9375 - accuracy: 0.2519
Epoch 3/5
391/391 [==============================] - 12s 31ms/step - loss: 1.6902 - accuracy: 0.3601
Epoch 4/5
391/391 [==============================] - 12s 31ms/step - loss: 1.5300 - accuracy: 0.4300
Epoch 5/5
391/391 [==============================] - 12s 30ms/step - loss: 1.3649 - accuracy: 0.4988
CPU times: user 58.7 s, sys: 1.63 s, total: 1min
Wall time: 1min 1s
あら。倍かかっちゃってますね。
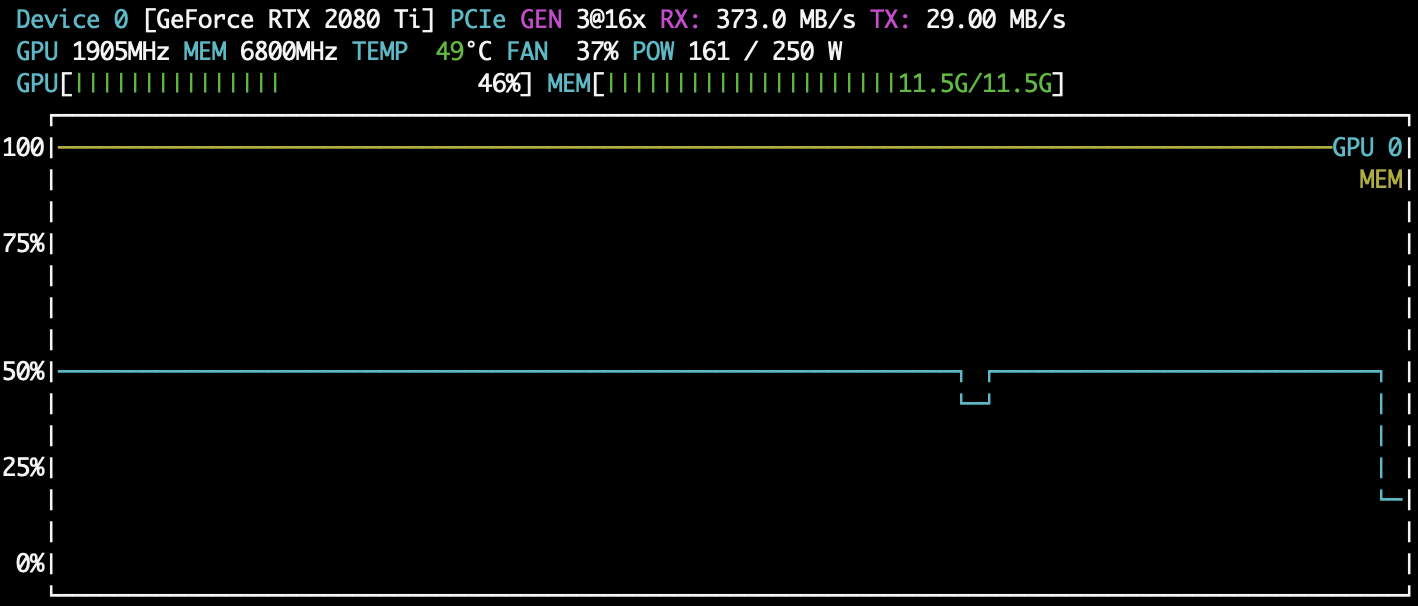
nvtopを見てみましょう

あまり実力を発揮できていませんね💦
keras.preprocessing.image.ImageDataGenerator()でチャレンジ
めちゃめちゃ遅かったこいつ、keras.preprocessing.image.ImageDataGenerator()はどうでしょうか
%%time
datagen = keras.preprocessing.image.ImageDataGenerator()
model.fit_generator(datagen.flow(tr_x, tr_y, batch_size=128),
steps_per_epoch=len(tr_x) / 128, epochs=5)
Epoch 1/5
391/390 [==============================] - 16s 40ms/step - loss: 14.5061 - accuracy: 0.1000
Epoch 2/5
391/390 [==============================] - 16s 40ms/step - loss: 14.5057 - accuracy: 0.1000
Epoch 3/5
391/390 [==============================] - 16s 40ms/step - loss: 14.5065 - accuracy: 0.1000
Epoch 4/5
391/390 [==============================] - 16s 40ms/step - loss: 14.5067 - accuracy: 0.1000
Epoch 5/5
391/390 [==============================] - 16s 40ms/step - loss: 14.5067 - accuracy: 0.1000
CPU times: user 1min 3s, sys: 1.37 s, total: 1min 4s
Wall time: 1min 18s
さらに遅い・・・通常モードですらこんな重いんですね。
これはtf.data.Datasetが重いってこと?
実はtf.data.Datasetが重いというより、Kerasのfit_gerenatorが重いっぽいんですよね。
tf.data.Datasetはフルバッチにすることもできるため、それでfitさせてみましょう。
%%time
tr_ds = tf.data.Dataset.from_tensor_slices((tr_x,tr_y)).batch(tr_x.shape[0]).repeat(5)
for x,y in tr_ds:
model.fit(x,y,batch_size=128)
Train on 50000 samples
50000/50000 [==============================] - 9s 178us/sample - loss: 2.4252 - accuracy: 0.1054
Train on 50000 samples
50000/50000 [==============================] - 7s 134us/sample - loss: 2.1042 - accuracy: 0.2025
Train on 50000 samples
50000/50000 [==============================] - 7s 137us/sample - loss: 1.7758 - accuracy: 0.3369
Train on 50000 samples
50000/50000 [==============================] - 7s 134us/sample - loss: 1.5804 - accuracy: 0.4166
Train on 50000 samples
50000/50000 [==============================] - 7s 136us/sample - loss: 1.3802 - accuracy: 0.4969
CPU times: user 38.2 s, sys: 6.05 s, total: 44.2 s
Wall time: 39.6 s
あら、めっちゃ早いじゃないっすか!nvtopもこの通り
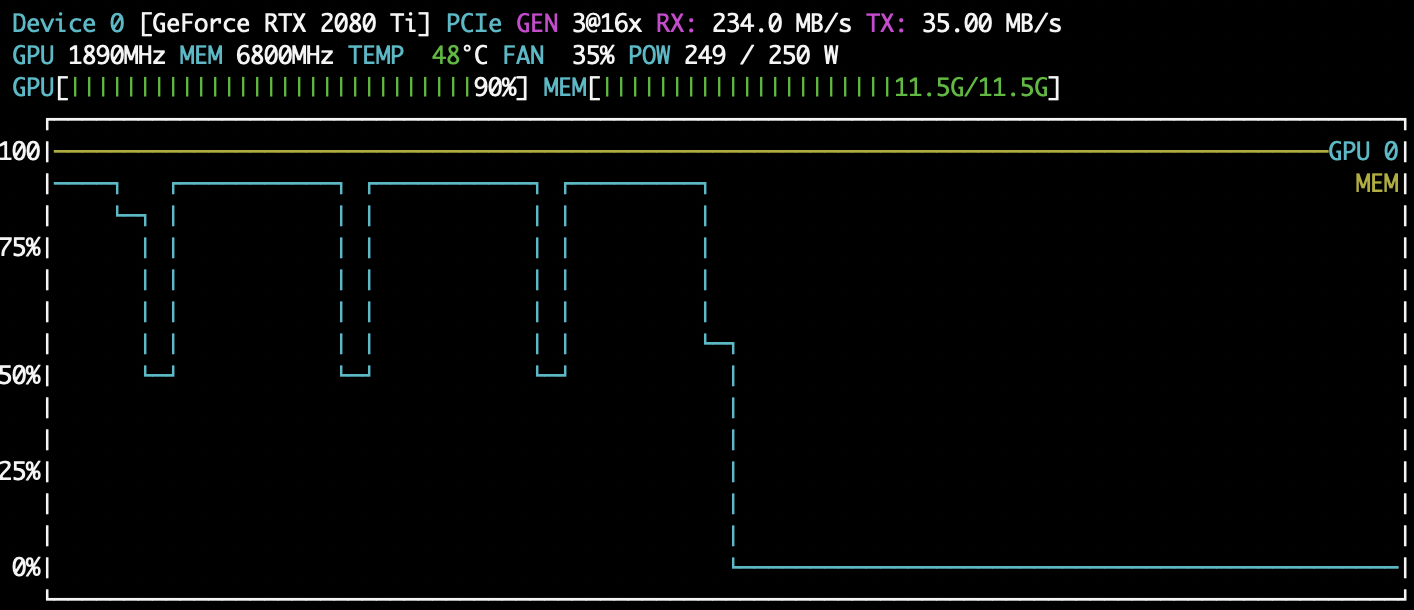
それ、tf.data.Dataset使う意味ある?
意味あります。なぜって・・・それはDataAugmentationに決まってるじゃないっすか!!
通常、フルバッチデータに個々にランダムなTransformをして、それをepoch分連続して出力なんて骨が折れる作業です。
でも、先日のAdventCalendarを思い出してください。こいつはそれがフルバッチでできるんです。素敵すぎませんか?
なら、速度検証だ!
やることは以下の2つです。
- random rotate
- random flip(h,v)
速度検証していきましょう。
ImageDataGeneratorでやる
データ確認
%%time
datagen = keras.preprocessing.image.ImageDataGenerator(
horizontal_flip=True,
vertical_flip=True,
rotation_range=30,
)
labels = np.array([
'airplane',
'automobile',
'bird',
'cat',
'deer',
'dog',
'frog',
'horse',
'ship',
'truck'])
plt.figure(figsize=(10,10),facecolor="white")
for b_img,b_label in datagen.flow(tr_x,tr_y,batch_size=25):
for i, img,label in zip(range(25),b_img,b_label):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(img)
plt.xlabel(labels[label])
break
plt.show()

速度検証
%%time
datagen = keras.preprocessing.image.ImageDataGenerator(
horizontal_flip=True,
vertical_flip=True,
rotation_range=30,
)
model.fit_generator(datagen.flow(tr_x, tr_y, batch_size=128),
steps_per_epoch=len(tr_x) / 128, epochs=5)
Epoch 1/5
391/390 [==============================] - 18s 47ms/step - loss: 1.5626 - accuracy: 0.4296
Epoch 2/5
391/390 [==============================] - 18s 46ms/step - loss: 1.4149 - accuracy: 0.4894
Epoch 3/5
391/390 [==============================] - 18s 46ms/step - loss: 1.3278 - accuracy: 0.5236
Epoch 4/5
391/390 [==============================] - 18s 47ms/step - loss: 1.2493 - accuracy: 0.5516
Epoch 5/5
391/390 [==============================] - 18s 46ms/step - loss: 1.1884 - accuracy: 0.5787
CPU times: user 2min, sys: 4.74 s, total: 2min 5s
Wall time: 1min 30s
うーむ、遅いですね。
フルバッチtf.data.Datasetでやる
まずデータ確認をしましょう
import tensorflow_addons as tfa
@tf.function
def rotate_tf(image,label):
if image.shape.__len__() ==4:
random_angles = tf.random.uniform(shape = (tf.shape(image)[0], ), minval = -30*np
.pi / 180, maxval = 30*np.pi / 180)
if image.shape.__len__() ==3:
random_angles = tf.random.uniform(shape = (), minval = -30*np
.pi / 180, maxval = 30*np.pi / 180)
return tfa.image.rotate(image,random_angles),label
@tf.function
def flip_left_right(image,label):
return tf.image.random_flip_left_right(image),label
@tf.function
def flip_up_down(image,label):
return tf.image.random_flip_up_down(image),label
tr_ds = tf.data.Dataset.from_tensor_slices((tr_x,tr_y)).shuffle(40000)
tr_ds = tr_ds.batch(25).map(flip_up_down).map(flip_left_right).map(rotate_tf)
plt.figure(figsize=(10,10),facecolor="white")
for b_img,b_label in tr_ds:
for i, img,label in zip(range(25),b_img,b_label):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(img)
plt.xlabel(labels[label])
break
plt.show()

うーん、なんか荒い?
これでフルバッチでやってみましょう。
速度検証
tr_ds = tf.data.Dataset.from_tensor_slices((tr_x,tr_y)).shuffle(40000)
tr_ds = tr_ds.batch(tr_x.shape[0]).map(flip_up_down).map(flip_left_right).map(rotate_tf).repeat(5)
for img,label in tr_ds:
model.fit(x=img,y=label,batch_size=128)
Train on 50000 samples
50000/50000 [==============================] - 8s 153us/sample - loss: 2.3030 - accuracy: 0.1447
Train on 50000 samples
50000/50000 [==============================] - 7s 133us/sample - loss: 2.0370 - accuracy: 0.2188
Train on 50000 samples
50000/50000 [==============================] - 7s 133us/sample - loss: 1.8615 - accuracy: 0.2985
Train on 50000 samples
50000/50000 [==============================] - 7s 133us/sample - loss: 1.7357 - accuracy: 0.3570
Train on 50000 samples
50000/50000 [==============================] - 7s 133us/sample - loss: 1.6400 - accuracy: 0.3976
CPU times: user 1min 42s, sys: 15.8 s, total: 1min 58s
Wall time: 42.2 s
DataAugmentationしているのにも関わらず、このスピードが出てます。素晴らしい・・・
注意点
スピードの一番の要は、4Dイメージをバッチで一気に処理することによってオーバヘッドが減らせるっていうだけなので、
ImageDataGeneratorのようなバッチを排出するタイプだと遅いってことです。
おわりに
まとめると
- 一気にまとめると早いので
tf.data.Datasetはおすすめ - だけど画像は荒いし、画像処理できるtf系はかなり限られている
- Augmentationの機能は今後に期待するしかない(自分が実装してTFAにプルリクしてもいいんですが...)
今後時間があれば、tf.data.Datasetに対応した画像処理系を作ろうかと思ってます。
追記
普通にこう書けばええんちゃう?
%%time
datagen = keras.preprocessing.image.ImageDataGenerator(
horizontal_flip=True,
vertical_flip=True,
rotation_range=30,
)
for i,(x,y) in zip(range(5),datagen.flow(tr_x, tr_y, batch_size=tr_x.shape[0])):
model.fit(x,y,batch_size=128,epochs=1)
確かに学習中は早いみたいです。
Train on 50000 samples
50000/50000 [==============================] - 7s 132us/sample - loss: 0.9494 - accuracy: 0.6730
Train on 50000 samples
50000/50000 [==============================] - 7s 140us/sample - loss: 0.9275 - accuracy: 0.6797
Train on 50000 samples
50000/50000 [==============================] - 7s 132us/sample - loss: 0.9019 - accuracy: 0.6894
Train on 50000 samples
50000/50000 [==============================] - 7s 132us/sample - loss: 0.8842 - accuracy: 0.6968
Train on 50000 samples
50000/50000 [==============================] - 7s 132us/sample - loss: 0.8769 - accuracy: 0.6957
CPU times: user 1min 20s, sys: 4.96 s, total: 1min 25s
Wall time: 1min 24s
でも、Wall Time(実際にかかった時間)をみると遅いんですよこれが。
毎回Batchごとに負荷が1CPUにかかってしまっていて、ボトルネックになっている関係で重いです。
同じ処理でもtf.data.Datasetの方が早かったりします。
さらに追記
mapにkerasのpreprocessをちゃんぽんしたらKerasの贅沢な機能も使えるし早いんちゃうん?
という疑問が浮かんできました。早速実験します。
import tensorflow as tf
import tensorflow.keras as keras
from tensorflow.keras.preprocessing.image import random_rotation
labels = np.array([
'airplane',
'automobile',
'bird',
'cat',
'deer',
'dog',
'frog',
'horse',
'ship',
'truck'])
(tr_x,tr_y),(te_x,te_y)=keras.datasets.cifar10.load_data()
tr_x, te_x = tr_x/255.0, te_x/255.0
tr_y, te_y = tr_y.reshape(-1,1), te_y.reshape(-1,1)
def r_rotate(imgs, degree):
pics=imgs.numpy()
_=0
if tf.rank(imgs)==4:
X = np.zeros(pics.shape)
for i,pic in enumerate(pics):
X[i]=random_rotation(pic, degree, 0, 1, 2)
elif tf.rank(imgs)==3:
X=random_rotation(pics, degree, 0, 1, 2)
return X,_
@tf.function
def random_rotate(imgs, label):
x = tf.py_function(r_rotate,[imgs,30],[tf.float32,tf.int32])
X = x[0]
X.set_shape(imgs.shape)
return X, label
tr_ds = tf.data.Dataset.from_tensor_slices((tr_x,tr_y)).shuffle(40000).batch(128).map(random_rotate)
plt.figure(figsize=(10,10),facecolor="white")
for b_img,b_label in tr_ds:
for i, img,label in zip(range(25),b_img,b_label):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(img)
plt.xlabel(labels[label])
break
plt.show()

うまくできているようです。
速度検証しましょう
%%time
tr_ds = tf.data.Dataset.from_tensor_slices((tr_x,tr_y)).shuffle(40000)
tr_ds = tr_ds.batch(tr_x.shape[0]).map(random_rotate,num_parallel_calls=tf.data.experimental.AUTOTUNE).repeat(5)
tr_ds = tr_ds.prefetch(tf.data.experimental.AUTOTUNE)
for img,label in tr_ds:
model.fit(x=img,y=label,batch_size=128)
Train on 50000 samples
50000/50000 [==============================] - 9s 175us/sample - loss: 2.3420 - accuracy: 0.1197
Train on 50000 samples
50000/50000 [==============================] - 7s 131us/sample - loss: 2.0576 - accuracy: 0.2349
Train on 50000 samples
50000/50000 [==============================] - 7s 132us/sample - loss: 1.7687 - accuracy: 0.3435
Train on 50000 samples
50000/50000 [==============================] - 7s 132us/sample - loss: 1.5947 - accuracy: 0.4103
Train on 50000 samples
50000/50000 [==============================] - 7s 132us/sample - loss: 1.4540 - accuracy: 0.4705
CPU times: user 1min 33s, sys: 8.03 s, total: 1min 41s
Wall time: 1min 14s
前回ImageDataGeneratorで1min 30sくらいでしたから、若干高速に出来るくらいなようです。
ですが、自分のやり方が下手くそなので、分散処理できずにfor文で処理して1CPUに負荷がかかってしまっています。
なので、一旦はprefetchで高速化できたと行ったところでしょうか。
今後も実装していきます。