以下のPython Web frameworkを使って単純なAPIを立てて、負荷試験をしてみました。
- Django (2.X)
- Flask
- FastAPI
- responder
- japronto
結果的に、ざっくりと以下が分かりました!
- performanceは「japronto >>> FastAPI > responder >>> Flask ~ Django」だと言えそう
- FastAPIとresponderはsingle workerだと秒間100~1000程度のrequestであればpython界で圧倒的なperformanceを誇るjaprontoとほとんど同水準
(検証に使用したコードはこちら。結果のプロットが見られる.ipynbファイルもあります。ただし、plotlyを使用したのでGithubからは見れませんので、cloneする必要があります)
目次
-
- Python Web Frameworkの概要
-
- 負荷試験の条件
-
- 結果
-
- まとめ
1. Python Web Frameworkの概要
Django
恐らくPythonのweb frameworkといえば第一に名前があがるのがこのframeworkだと思います。
典型的な構成は、以下のようになります。
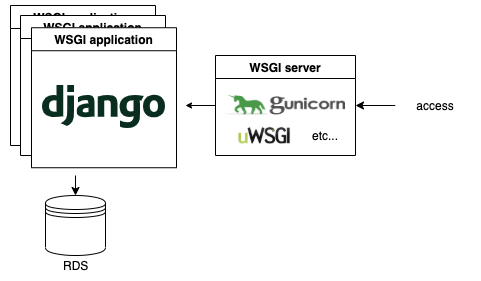
Djangoは色々入っている大きなframeworkですが、WSGI serverだけは別なので、比較の際はWSGI serverをそろえてあげる必要があります。
また、最近Django 3がでて、ASGIに対応したらしいです。(でたばかりで動作が怪しいみたいなので今回は見送ります)
Flask
Pythonのmicroframeworkで最も知名度が高いと思われます。
以下のようなWerkzeugというlibraryのラッパーとしてはじまっています。
Werkzeug is a comprehensive WSGI web application library. It began as a simple collection of various utilities for WSGI applications and has become one of the most advanced WSGI utility libraries.
https://www.palletsprojects.com/p/werkzeug/
典型的な構成は、以下のようになります。(RDSとの接続はSQLAlchemyというORMがよく使われるので書いていますが、他のORMも使えます)
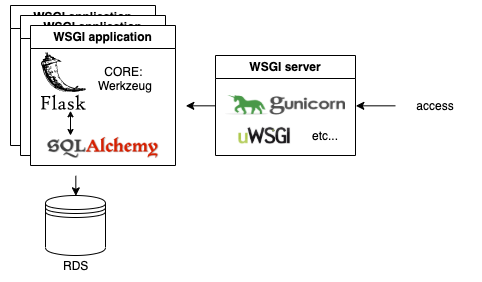
よって、Flaskと比較する場合は、WSGI serverを共通化する必要があることが分かります。また、DBが絡んだ比較をする場合は、基本的にはSQLAlchemyに揃える必要がありそうです。
responder
割と新しいPythonのmicroframeworkです。(2020年1月現在)
web applicationとしてはStarletteというlibraryのラッパーです。
responderは (正確にはStarletteは) ASGIになっていて全体的に非同期で動かせて、一般的にはDjango, FlaskなどのWSGIよりは高performanceだと言われています。
典型的な構成は、以下のようになります。(RDSとの接続は(確認した限り) Documentsで言及されていません。ググるとtortoise ORMというものがよく紹介されていたので書きました。しかし、Issuesを見るとSQLAlchemyも動くみたいです)
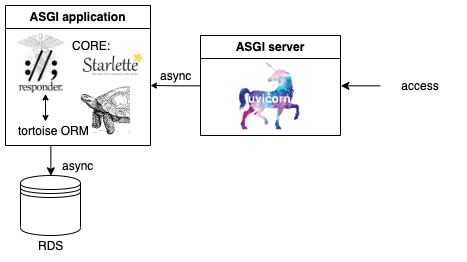
わかり易さのためにASGI applicationとASGI serverを分けて書いていますが、responderはuvicornもラップしているので、responderだけで完結しているかのように扱えます。
FastAPI
responderよりも数ヶ月後にでた新しいPythonのmicroframeworkです。(2020年1月現在)
responderと同様にStarletteのラッパーです。ですが、RDSのサポートが充実していたり、自動でSwaggerを作ってくれたりなど、よりproduction向きだと思います。(何よりもdocumentが手厚いです)
典型的な構成は、以下のようになります。(RDSとの接続はSQLAlchemyというORMがdocumentで紹介されています。しかし、他も使えるようです)
また、uvicornをgunicorn経由で使ってmultiworkerで動かすことも推奨されています。
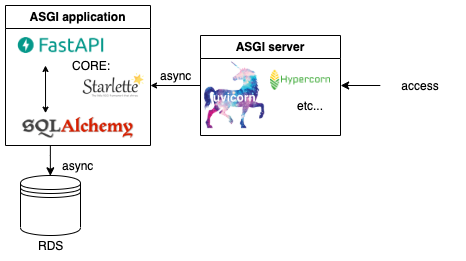
japronto
japrontoはほぼ自己完結しているweb serverです。
ほぼCで書かれており、異常に高パフォーマンスになっています。
officialのREADMEにはgolangやnode.jsを大きく上まっているというベンチマークが紹介されています。(wrkにより、1 thread, 100 connectionsで2400 requests/secの負荷を与えている)
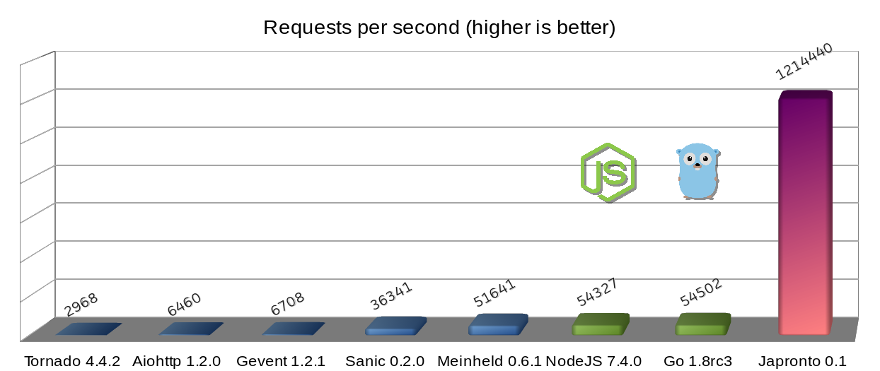
https://github.com/squeaky-pl/japronto#performance
ただし、productionでの利用は推奨されていません。開発も止まっているので、あくまで参考(最強の象徴)ということで紹介します。
今回はDBは扱わないこととします。
そこで、framework毎に、それぞれ使用する WSGI/ASGI serverは以下のようにまとめられます。
| WSGI/ASGI | application | server | |
|---|---|---|---|
| Django | WSGI | (pure) | gunicorn |
| Flask | WSGI | Werkzeug | gunicorn |
| responder | ASGI | starlette | uvicorn |
| FastAPI | ASGI | starlette | uvicorn |
| japronto | ASGI | (pure) | (pure) |
この時点でパフォーマンスは、(左から順に高パフォーマンス)
japronto > FastAPI ~ responder > Flask ~ Django
であることが予想できます。実際にどの程度の差があるのか調べたいと思います。
補足
Web Framework Benchmarksを参照すると、
japronto > FastAPI > Flask ~ Django > responder
になっていますが、細かい部分がよくわからないので、自分でもやってみます。
2. 負荷試験の条件
- 負荷試験ツール: wrk2
- 環境: 同一マシン上でweb serverと負荷試験ツールを同時に動かします (正確性を欠くので避けるべきですが、あくまでもframeworkの比較を行うのでそれぞれの条件が対等であれば十分だという考えでこの環境を採用します)
- 指標: latency
wrk2
今回は各framework毎に簡単な処理に対するlatencyを出力させて、可視化ツールでまとめて可視化することにします。なので、シンプルな負荷試験ツールが適していそうです。
そこで、CUI上で簡単に使えるwrk2を使用します。
install
macでは、homebrewを使えば簡単にinstallできます。
$ brew tap jabley/homebrew-wrk2
$ brew install --HEAD wrk2
使用環境
- Macbook pro:
- CPU: 2.9 GHz Intel Core i5
- memory: 8GM
latency
ここでは、applicationのperformanceの定義をlatencyの低さとします。
レイテンシ(latency): あるシステムの遅延時間。ネットワークや機能単位の反応の遅さを評する際に用いられることが多い。小さいほど良い。
(参考:負荷試験のためのノウハウと Webフレームワークの負荷試験 (Python,Node,Go,PHP))
WSGI/ASGI server
gunicornの設定は、uvicornにあわせてworker数1にします。
$ gunicorn \
--workers 1 \
--bind 0.0.0.0:8000 \
hello.wsgi
uvicornはdefaultの設定を使用します。
$ uvicorn main:app --no-access-log
Applications
get methodでたたき、query parameterを受け取って、
f"hello world, {query}"
をjsonで返すAPIをたてます。
各frameworkのコードをまとめて書きます。(Django以外は似たりよったりです)
Django
(viewのみ)
from django.http.response import JsonResponse
from django.views import View
class HelloQueryView(View):
def get(self, request, *args, **kwargs):
ids = request.GET.get('id', '')
return JsonResponse({"text": f"Hello python, {ids}!"})
Flask
from flask import Flask, jsonify, request
app = Flask(__name__)
@app.route('/query')
def hello_query():
ids = request.args.get('id')
return jsonify({"text": f"hello world, {ids}!"}), 200
if __name__ == '__main__':
app.run(debug=False)
responder
import responder
api = responder.API()
@api.route("/query")
async def hello_world_query(req, resp, *args, **kwargs):
ids = req.params.get("id")
resp.media = {"text": f"hello world, {ids}!"}
if __name__ == "__main__":
api.run(debug=False, access_log=False)
FastAPI
from fastapi import FastAPI
app = FastAPI()
@app.get("/query")
async def hello_query(id: str = None):
return {"text": f"hello world, {id}!"}
japronto
from japronto import Application
app = Application()
def hello_query(request):
ids = request.query.get("id")
return request.Response(json={"text": f"Hello python, {ids}!"})
app.router.add_route("/query", hello_query)
if __name__ == "__main__":
app.run()
3. 結果
以下5条件で負荷試験を行う。
- connection 10, requests/sec 100, duration 30s
- connection 50, requests/sec 500, duration 30s
- connection 100, requests/sec 1000, duration 30s
- connection 500, requests/sec 5000, duration 30s
- connection 1000, requests/sec 10000, duration 30s
縦軸をlatency[ms], 横軸をpercentileとして結果をプロットします。
connection 10, requests/sec 100, duration 30s
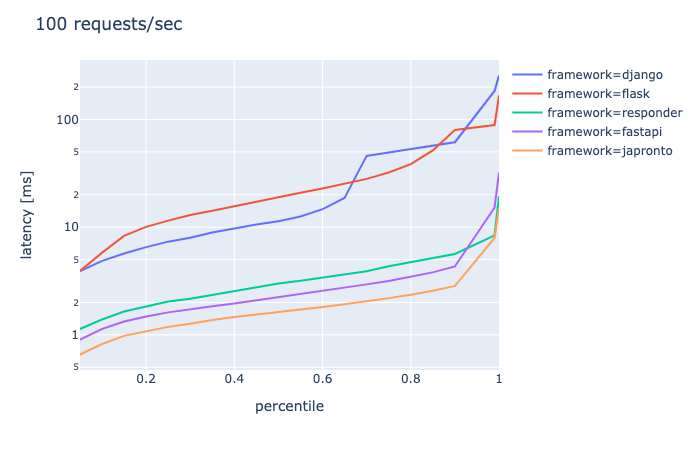
- DjangoとFlaskはもうきつそう
- ASGI系はどれも似たような感じ
- japrontoの一人勝ちではない
connection 50, requests/sec 500, duration 30s
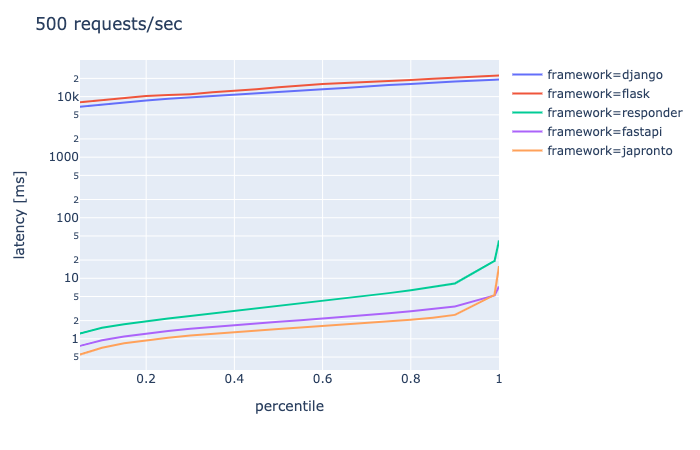
- DjangoとFlaskは終了
- ASGI系はどれも似たような感じだが、responderが一歩出遅れている
- japrontoの一人勝ちではない
connection 100, requests/sec 1000, duration 30s
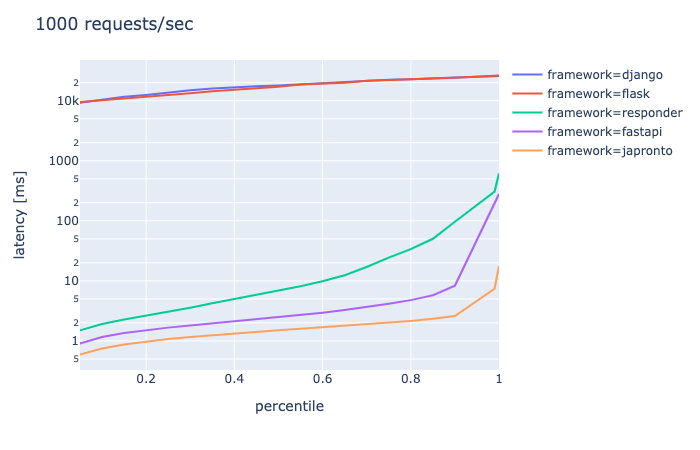
- japronto > FastAPI > responderの順位がはっきりしてきた
- FastAPIとresponderはギリギリ耐えている
connection 500, requests/sec 5000, duration 30s
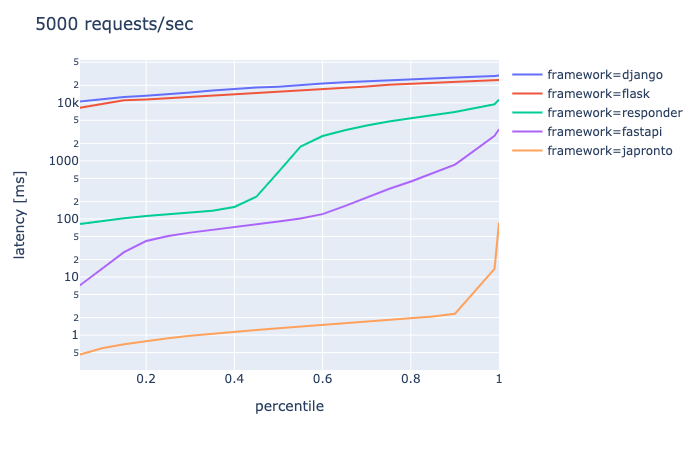
- responderは終了
- FastAPIはほぼ終了
connection 1000, requests/sec 10000, duration 30s
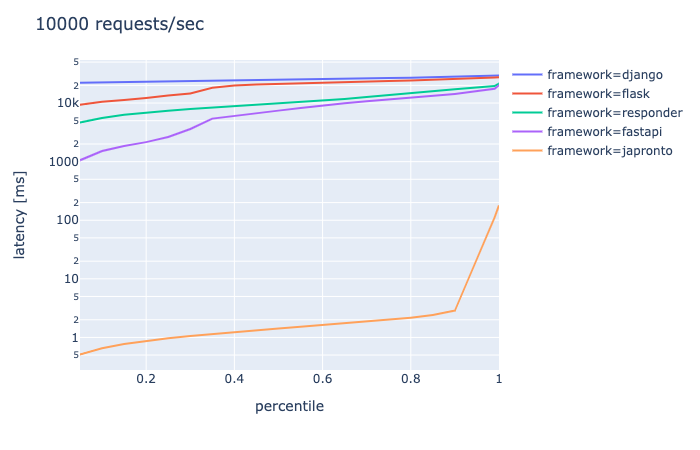
- responder, FastAPIは完全に終了
- japrontoは99.9パーセンタイル程度までは余裕
アクセス規模別の適用可能性
1秒間のリクエスト数の大きさ別に各Web frameworkがsingle workerで現実的(timeoutしない程度)なlatencyを保てるかを大まかに表にまとめると、以下のようになりそうです。(ただし、$O(100)$は100から1000ぐらいの値を指す)☓である領域に対処するにはマシンスペックを上げて対処するしかなさそうです。
| 秒間$O(100)$のrequest | 秒間$O(1000)$のrequest | |
|---|---|---|
| Django | ☓ | ☓ |
| Flask | ☓ | ☓ |
| responder | ○ | ☓ |
| FastAPI | ○ | △ |
| japronto | ○ | ○ |
4. まとめ
wrk2でPythonのweb frameworkのsingle workerでのlatencyを比較したところ、
- japronto >>> FastAPI > responder >>> Flask ~ Djangoだと言えそう
- FastAPIとresponderはsingle workerだと秒間$O(100)$のrequestであればpython界で圧倒的なperformanceを誇るjaprontoとほとんど同水準
だということがわかりました!
とはいえ、インフラに強く依存するはずなのであくまで参考程度ということで!
備考
これまでresponderを使っていましたが、FastAPIに乗り換えたいと思います![]()
-> 入門しました