この記事はRetty Advent Calendar 2017 における 22日目の記事です。
昨日は @saku さんの swiftで丸画像をパフォーマンス高く表示する方法 でした。
はじめに
趣味のBot開発から気づけばWebフレームワークの負荷試験を行なっていました。
Software Engineerの@tkngueです。普段業務としては、Data Engineer/Web Service開発/データ分析やってます
「速さは正義」 とは皆の共通の認識で、言うまでもないことだと思うのですが
本記事では、速さってなんだろうって考えてみます。
TL;DR
- 負荷試験における 速さは面で捉えよう: 品質を50%'ile - 90%'ile - 99%'ile ... で定義する
- 品質を評価する手段にも気をつかおう: Coordinated Omission は大きな測定誤差を生みます
- Goも早いけど、nodeもPythonのjaprontoもむっちゃ早い
何の速度を品質と考えるか?
改めて 「速さは正義」 とは皆の共通の認識です。
計測する前に今一度速さってなんだろうって考えて見ます。
Webページにおける様々な指標たち
サービス上の品質を表す速さの指標ですが、ひとえにこの指標は実に様々です。
速さの指標としてあげられそうなものを 列挙して見ました。
-
応答時間(response time): あるリクエストを送ってから, レスポンスが帰ってくるまでの時間 ( リクエストの待機状態 + サーバの処理時間(Service Time))。小さいほど良い
-
スループット (Throughput): 単位時間あたりの処理量(リクエスト数 や データ転送量)。大きいほど良い。
-
レイテンシ(latency): あるシステムの遅延時間。ネットワークや機能単位の反応の遅さを評する際に用いられることが多い。小さいほど良い。
-
Time To First Byte (TTFB): あるリクエストを送ってから、最初のバイトが帰ってくるまでの時間
-
Time To First Intractive: あるリクエストを送ってから、ユーザ操作可能な状態に入るまでの時間
-
Start Render Time: あるリクエストからコンテンツのレンダリングが始まるまでの時間 (〜 DOMコンテンツのレンダリングタイム)
-
Load Time: HTML内の全てのコンテンツのダウンロードが終わるまでの時間
-
Speed Index: First View が表示される 速さを指標化したもの (単位は時間ではない)
などなど ...
ちょっと調べるだけでたくさんの指標がでてきました。
目的に合わせて、計測すべき指標は正しく決める必要があります。
「応答時間」と「スループット」はやや混同されやすいですが別物です
「応答時間」は「アプリケーション」、後者は「バッチ処理」でとりわけ大事となる概念です
今回は「Webフレームワークの速度」を測るので「応答時間(Response Time)」に着眼をおきます。
応答時間をいかに測るか?
最初に 「(相加)平均応答時間」 は
Webサービスの応答時間を表す指標として ほとんど意味がないです。
「応答時間の中央値」は平均よりは少しは意味を持ちますが、それでも不十分です。
その理由をこれから説明していきます。
そもそも 応答時間の分布は正規分布ではない
まず応答時間の分布は 正規分布 ではありません。
応答時間の場合、中央値 < 平均値 で (相加)平均を指標にすると 値は大きい方に引っ張られるため
タイムアウトの設定値(= 応答時間の上限値)で平均値はいくらでもずれてしまうからです
なので 「(相加)平均応答時間」 はWebサービスの応答時間を表す指標として 意味がありません
そして、正規分布出ないため応答時間の分散($+ \sigma $など)をつかって議論することは 意味がありません。
中央値(50%位)で速さを定義するのは不十分
平均値がダメなら中央値でしょうか?
駄目ではないですけど、不十分そうです。
次の例を考えて見ます。
- 50%位(中央値)で 100ms で 99%位で10秒かかるシステム
- 50%位(中央値)で 200ms で 99%位で1秒かかるシステム
のどちらが良いでしょう?
99%位とは 100人がアクセスしたとき応答時間の早い順に並び替えたとき
上から99人目の人の反応時間です。 50%位は中央値と同じですね。
中央値だけ見れば、前者の方が良さそうに見えます。
1%くらいなら10秒かかっても許容できる範囲と言えるでしょうか?
ユーザさんが平均してサイト内で40ページぐらいアクセスすると考えて見ましょう
ユーザさんの観点から考えた場合「1ページでも遅いページがあるとイラっとする」のは普通のことだと思います。
とあれば、考えるべきは「ユーザさんが一番遅いと感じるページでいくらの速度がでるか?」ということでは
ないでしょうか
では「ユーザさんが1ページでも遅いページに遭遇しない」確率は一体どれぐらいでしょう。
確率として 40ページにアクセスする時99%位以上の遅いページに一度でも遭遇する確率$p_a$は
$ p_a = 1 - 0.99^{40} = 0.669 (66.9%) $
と 40ページもアクセスすれば, 3人に2人は遅いページに遭遇することがわかります。
これは許容できる範囲といえるでしょうか?
Webサービスで考えた場合、後者の99%位が 1[s] であることの方がまだ良さそうです。
となると必要なのは 後者の平均 200 [ms/req.] という 一見遅く見えるシステムとなります
応答時間は面で捉える
以上の観点から、応答時間を測定する際には
応答時間の中央値でなく、悪い場合の応答速度(99%位, 99.9%位 ... )にも留意する必要がある
ことがわかります。
これを達成するためには、縦が応答時間で横軸がパーセンタイルのような面の情報で捉えるのが良さそうです。
システムの
図時が大変な場合には 中央値との最大値の応答時間、少なくとも2つの値を見る必要があります。
Coordinated Omission (CO)
計測を行う際には
- 「どの値」を測るか
だけでなく
- 「どの様」に測るか
についても留意することも同様に大切です。
Coordinated Omission は 負荷試験の際に起こる問題で
実際の性能よりもサーバの性能を良く 見せます
日本語文献がほとんどなく定訳がそもそも存在していないため、
日本語に訳すのが難しいのですが愚直に翻訳するならば「調整された省略」。
少し意訳すると「協調的欠落」となるのでしょうか。何かいい翻訳あれば教えてください
一般的なベンチマークの負荷試験を行う時
- タイムスタンプの計測: $t_0$
- サーバに同期的なリクエストを送り, レスポンスを受け取る
- タイムスタンプの計測: $t_1$
- 反応時間 = $t_1 - t_0$
このような手順を負荷試験中に大量に繰り返し、
統計的な平均処理を経て応答時間の計測されることになります。
この方法の問題点は
「リクエストを送る間隔$t_r$よりもサーバの応答時間$t_s$の方が十分に小さい」と
暗に仮定してしまっている点です。
これがどういう誤った計測を起こしうるかを図示してみます
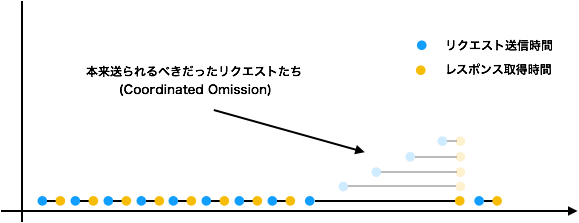
前述の同期的な手順で 計測した場合、1度だけ応答時間が遅くなったとします。
測定方法が同期的であるため、計測する側は前の結果が帰ってくるまで
次の送信を 待つ ことになります。
この待っている間に送れなかったリクエストが Coordinated Omissionです。
ここから単純に「平均反応時間 =反応時間の総和 / リクエスト数」とすることのマズさが 伝わると思います。
同様に中央値でも サンプル数が偏ることになるため精度の悪化を引き起こします。
この問題によりどの程度、平均の計測がいかにずれるか実際に計算して見ます
スレッド数1で秒間100リクエストの負荷試験を10秒間行なった場合を考えます
通常は1msで返すサーバが、どこかで1sだけ停止し、反応に1sかかったとします
Coordinated Omissionを考慮しなかった場合の計測上は
$ t_r = (9 \cdot 100[req./s] \cdot 1 [ms] + 1 \cdot 1 [req./s] \cdot 1 [s] ) / (900 + 1) = 2 [ms/req.] $
となりますが
正しくは 1sかかっている間にも0.01sごとにリクエストが送られるはずなので
$ 1000 [ms] + 990 [ms] + 980 [ms] + ... + 10 [ms] = 100 \cdot (10 + 1000) / 2 = 50500 [ms]$
の時間を考慮に入れてやる必要が出ます。
となると、正しくは
$ t_r = (900 + 50500) / 1000 = 514 [ms/req.] $
であるはずです。
平均でみれば $514ms$ (2msの約250倍) のずれとなり
使い物にならない値がでることがわかります。
どの負荷試験ツールを選ぶか?
- siege : https://github.com/JoeDog/siege
- Apache Bench(AB): https://github.com/CloudFundoo/ApacheBench-ab
- wrk : https://github.com/wg/wrk
など様々な負荷試験ツールがあります。(c.f. denji/awesome-http-benchmark)
その中でもwrkは高負荷のストレステストにも利用できる良いツールですが
上記のCoordinated Omissionの補正を入れることができていません。
そこで今回の計測にはCoordinated Omissionに対する補正が加えられた
giltene/wrk2 を利用します。
wrk2はwrkを拡張した負荷試験ツールです。
- siegeやabなどに比べて超高負荷なストレステストが可能
- nginxのstatic filesのベンチマークをできるほど高い負荷をかけることができる
- wrkと同様にluaスクリプトによる柔軟な負荷試験が可能
- Coordinated Omissionに対する補正を行っている
- 中央値だけでなく99%位や99.9%位の値が表示可能
といった特徴を兼ね備えています
様々なフレームワークの負荷試験
さて、これでやっと本題に入ることができます
wrk2を利用し, Webフレームワークの負荷特性の測定を行います
マシン
- macOS Sierra 10.12.6
- Processsor : 3.3GHz Core i7 (物理2cores/論理4cores)
- Memory : 16 GB 2133MHz LPDDR3
各種サーバはローカルホストで起動する。
つまり 負荷をかけるマシンとかけられるマシンが同一となっております。
負荷試験用コマンド
以下のコマンドを各種サーバに対して実行する
wrk -U -d ${interval} -c ${connection} -R ${qps} http://localhost:${n_port}
下記のパラメータの範囲で、interval=30 の負荷試験を行います
- connection={10, 100, 1000, 10000}
- qps={1000, 10000, 100000}
## 実験対象
当方 Pythonista のため, Pythonフレームワークが厚めのベンチマークになります
### Python (3.6.1)
主に [こちら](https://github.com/squeaky-pl/japronto/tree/master/benchmarks) のベンチマークコードを利用
#### http.server
```sh
python -m http.server port_num
flask
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, World!'
app.run(port=8886)
tornado
from tornado import web
from tornado.httputil import HTTPHeaders, responses
from tornado.platform.asyncio import AsyncIOMainLoop
import asyncio
loop = uvloop.new_event_loop()
asyncio.set_event_loop(loop)
AsyncIOMainLoop().install()
class MainHandler(web.RequestHandler):
def get(self):
self.write('Hello world!')
# skip calculating ETag, ~8% faster
def set_etag_header(self):
pass
def check_etag_header(self):
return False
# torando sends Server and Date headers by default, ~4% faster
def clear(self):
self._headers = HTTPHeaders(
{'Content-Type': 'text/plain; charset=utf-8'})
self._write_buffer = []
self._status_code = 200
self._reason = responses[200]
port_num = 8888
app = web.Application([('/', MainHandler)])
app.listen(port_num)
loop.run_forever()
aiohttp
import uvloop
import asyncio
from aiohttp import web
async def handle(request):
name = request.match_info.get('name', "Anonymous")
text = "Hello, " + name
return web.Response(text=text)
asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())
app = web.Application(loop=asyncio.get_event_loop())
app.router.add_get('/', handle)
web.run_app(app, port=8880)
sanic
from sanic import Sanic
from sanic.response import text
app = Sanic()
@app.route("/")
async def test(request):
return text({"hello": "world"})
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8882)
japronto
from japronto import Application
def hello(request):
return request.Response(text='Hello world!')
app = Application()
app.router.add_route('/', hello)
app.run(port=8885)
PHP (7.1.8)
<?php
echo("Hello World");
NodeJS (8.4.0)
nodejs
const http = require('http');
var srv = http.createServer( (req, res) => {
res.sendDate = false;
if(req.url == '/') {
data = 'Hello world!'
status = 200
} else {
data = 'Not Found'
status = 404
}
res.writeHead(status, {
'Content-Type': 'text/plain; encoding=utf-8',
'Content-Length': data.length});
res.end(data);
});
srv.listen(8888, '0.0.0.0');
http-server(JS)
http-server
Go (1.9)
package main
import (
"fmt"
"net/http"
)
func handler(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello, World")
}
func main() {
http.HandleFunc("/", handler)
http.ListenAndServe(":8889", nil)
}
実験結果
Overview
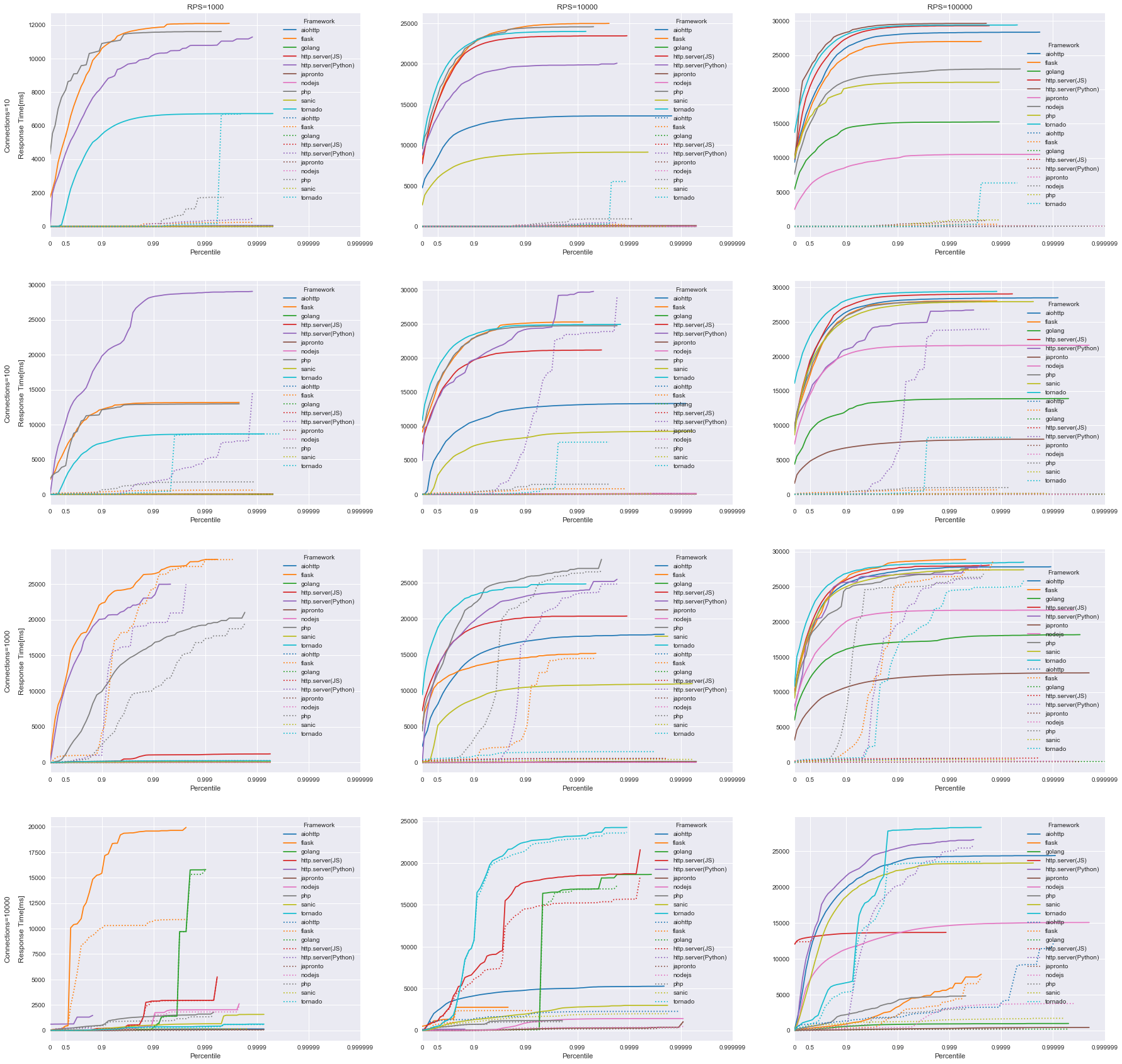
結果を図示します
横軸は 1/ (1-Percentile) を刻みとして対数表示、
縦軸は反応時間で、グラフごとに範囲がバラバラであることに注意してください。
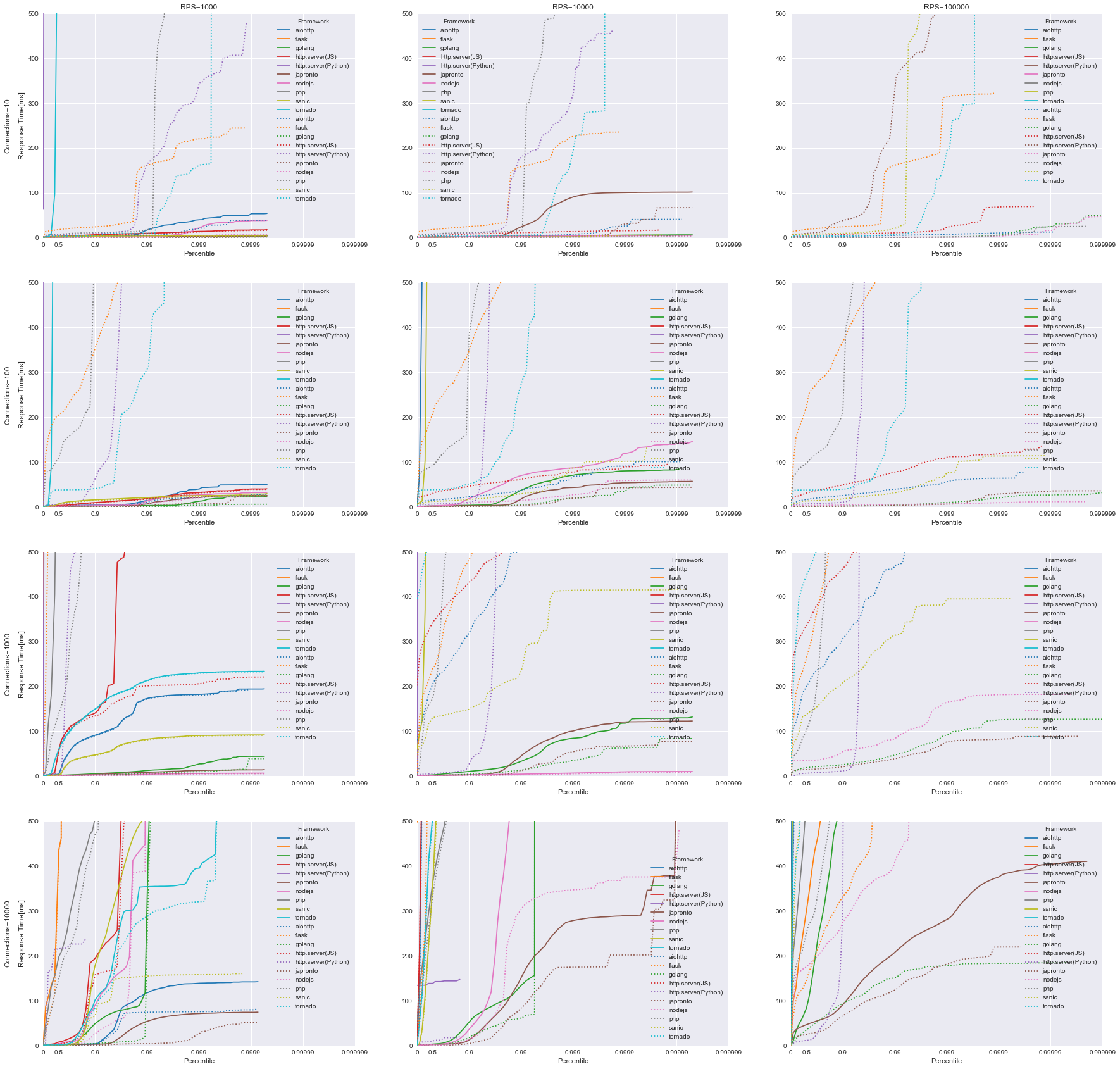
反応時間 (0 ~ 500ms)をそれぞれ拡大
実験条件ごとの Req / sec 数 (スループット数) [CO補正済み]
| Connections | 10 | 100 | 1000 | 10000 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RPS | 1000 | 10000 | 100000 | 1000 | 10000 | 100000 | 1000 | 10000 | 100000 | 1000 | 10000 | 100000 |
| Framework | ||||||||||||
| aiohttp | 999.74 | 5752.23 | 5686.64 | 997.20 | 6546.94 | 5848.58 | 960.08 | 4758.90 | 4762.32 | 414.55 | 2807.49 | 3279.15 |
| flask | 544.48 | 544.98 | 543.13 | 537.52 | 540.80 | 543.69 | 152.88 | 609.77 | 466.86 | 12.61 | 4.16 | 111.22 |
| golang | 999.79 | 9996.28 | 49196.48 | 997.41 | 9959.78 | 50558.34 | 960.81 | 9525.85 | 37914.50 | 142.15 | 822.68 | 6275.75 |
| http.server(JS) | 999.67 | 2181.22 | 2250.82 | 997.05 | 2916.44 | 2956.03 | 959.91 | 2817.22 | 2924.45 | 147.90 | 443.95 | 27.26 |
| http.server(Python) | 533.54 | 534.25 | 503.72 | 299.72 | 477.69 | 477.69 | 19.58 | 304.42 | 390.01 | 0.19 | 0.19 | 86.01 |
| japronto | 999.76 | 9995.98 | 69741.97 | 997.37 | 9959.54 | 77544.21 | 959.95 | 9526.35 | 58601.91 | 416.73 | 3557.22 | 34776.59 |
| nodejs | 998.92 | 9995.93 | 25105.95 | 981.86 | 9958.92 | 27703.97 | 959.97 | 9526.63 | 23954.82 | 142.53 | 3554.70 | 17371.52 |
| php | 532.36 | 539.82 | 2.69 | 540.22 | 530.58 | 524.40 | 377.32 | 413.12 | 487.13 | 43.70 | 15.22 | 63.53 |
| sanic | 999.63 | 7131.09 | 2.51 | 982.37 | 8157.27 | 8087.92 | 959.97 | 7363.80 | 6614.63 | 415.09 | 3321.56 | 4947.23 |
| tornado | 998.24 | 1998.27 | 1950.41 | 997.32 | 1670.53 | 1782.56 | 959.52 | 1389.42 | 923.35 | 413.72 | 297.02 | 115.97 |
実験条件ごとの Socket Error総数 ( read/write/connection error + timeout )
| Connections | 10 | 100 | 1000 | 10000 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RPS | 1000 | 10000 | 100000 | 1000 | 10000 | 100000 | 1000 | 10000 | 100000 | 1000 | 10000 | 100000 |
| Framework | ||||||||||||
| aiohttp | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 155.0 | 4.0 | 4.0 | 24384.0 | 17284.0 | 19029.0 |
| flask | 0.0 | 10.0 | 10.0 | 0.0 | 123.0 | 100.0 | 11712.0 | 6632.0 | 12392.0 | 27536.0 | 33157.0 | 36389.0 |
| golang | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 79.0 | 77.0 | 148.0 | 35708.0 | 39420.0 | 40952.0 |
| http.server(JS) | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 39008.0 | 36875.0 | 35134.0 |
| http.server(Python) | 340.0 | 335.0 | 465.0 | 2384.0 | 2857.0 | 2788.0 | 13591.0 | 13826.0 | 14869.0 | 35184.0 | 35377.0 | 32720.0 |
| japronto | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 13.0 | 4.0 | 2.0 | 24300.0 | 19755.0 | 19758.0 |
| nodejs | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 14.0 | 39.0 | 30.0 | 35704.0 | 17638.0 | 17283.0 |
| php | 20.0 | 35.0 | 20.0 | 0.0 | 291.0 | 250.0 | 10904.0 | 12534.0 | 12785.0 | 40078.0 | 35591.0 | 36901.0 |
| sanic | 0.0 | 0.0 | 10.0 | 0.0 | 0.0 | 0.0 | 222.0 | 1.0 | 33.0 | 26603.0 | 19648.0 | 17645.0 |
| tornado | 30.0 | 20.0 | 20.0 | 300.0 | 200.0 | 300.0 | 261.0 | 1031.0 | 7001.0 | 24284.0 | 25332.0 | 25343.0 |
考察
CO補正の効果について
図中の点線がCO補正なし, 実線がCO補正ありの結果となっています。
おどろくほどに点線と実線がずれていますね。
遅いフレームワークほど顕著にずれが生じていることがわかります
対コネクション数特性について
コネクション数が多くなればなるほど(Connections 10 -> 10000)
全体の性能自体が大きく劣化する様子が伺えます。
これはコネクションあたりのオーバーヘッドが問題となって
システム全体の性能を圧迫してしまっている状態です。
これはC10K問題として知られます.
コネクション数が増加した時、たまに改善した様に見えてしまっているのは
socket errorによって見かけ上早くなったように見えるためで
実際に早いというわけではありません (表 参照)
今回の負荷試験では、socket数に限界がきてしまいました。
対RPS特性について
コネクション数と同様にリクエスト数が増加すると、全体としての性能が大きく低下することが
見て取れるかと思います。
今回の実験においてもっとも負荷が少ないCPS=10, RPS=1000 の時においても、
一部のフレームワークは 90%位の速度は2000[msec]以上かかってしまうことがわかります
コネクション数と同様にRPS が増加した時、改善した様に見えるのは
対コネクション数特性と同じなのですが socket error によって見かけ上早くなったように見えるためです。
表の 実験設定のRPS設定値 と 実際のReq./sec を比べていただくとわかると思います。
Pythonでフレームワークを比較して見る
おおよそ
flask < http.server < tornado <<< aiohttp < sanic <<< japronto
の結果となりました。
japrontoの速さは圧巻で、それに sanic, aiohttpが続くという結果になりました。
sanic と aiohttp で 6000〜 ぐらいのスループットがでます。
tornado と aiohttpでここまで差がついてしまったのには驚きです。
ノンブロッキングI/O だからといって速い訳ではない、ということですね。
言語を超えたフレームワークを比較して見る
python(japronto) v.s. nodejs v.s. golang で 比較した時
この3つは かなりいい勝負をしていますね。
golangは速さは評判通りですが
今回やった実験では Python(japronto) の方がgolangよりも
高RPS時のスループットや中央値の応答時間がでる結果となりました。
nodejsはコネクション数の増加にやや弱い感じですね。
japrontoがこんだけ早い理由は中身は ほぼC/C++で 様々な最適化をかけているためです。
まとめ
今回の記事では、サービスにおける速さの品質と
負荷試験の際に起こりうるCoordinated Omissionについて解説を行い、
種々のフレームワークに対してwrk2を負荷試験を行ない、比較を行なって見ました
Pythonフレームワーク中においても、その性能差は歴然でした。
Coordinated Omission によって測定精度が顕著に悪化(〜 数百倍 )することもわかりました。
今回の実験は、リクエストを送るマシンと受け取るマシンが同一ということもあり
正確に測定するためには別環境に離して、負荷試験を行ってやる必要があるなど
議論の余地はあると思います
とはいえ
速度観点からフレームワークの選定を行う際には一つの基準となると思います。
ただし今回はフレームワークのエンドポイントに直接負荷試験をかける、と形になりましたが
実際にはPythonだったらgunicron, wsgiなどをフロントに立てるなどします。
ゆえに実際のサービスの構成と今回構築した実験の構成は大きく異なる可能性の方が大きくなりますので
この結果だけで全てを語るには足りませんのでご注意しておきます
終わりに
この記事では 最初に負荷試験におけるノウハウとして計測ツールの導入と
計測の際に発生しうる計測誤差の一つである Coordinate Omissionについて説明しました。
それを踏まえた上で、言語横断家的に様々なWebフレームワークをテストして見ました
この結果から、CO補正後とCO補正前では計測に明らかな乖離が発生しており、
COにより性能高く見せられてしまうことがわかりました。
本条件における負荷試験は環境(ネットワークI/O, メモリ, CPU数)で結果が強く作用されますゆえ
お使いの環境で実際に計測することが大事です。
噂通りgolang が優秀であったものの、 nodejsやPythonのjaprontoがパフォーマンスに優れていることが
改めてわかりました。
長い記事にお付き合いいただき、ありがとうございました!