はじめに
Introducing Ludwig, a Code-Free Deep Learning Toolbox
Uberがコードを書かなくても使える深層学習ツールludwigをリリースしたとのことで公式みながら早速使ってみる。
インストール
Installationに従う。
python -V
Python 3.6.1
pip install ludwig
python -m spacy download en
インストールが完了すると ludwig コマンドが使えるようになる。
学習させてみる
examplesにあるText Classificationをやってみる
ここではどうやらHomework #2: Text Categorization Due Apr 1, 9:59pm (Adelaide time)にある reuters-allcat-6.zip を教師データにしてるようなので、ダウンロードして使う。
cd text-classification && cd $_
wget http://boston.lti.cs.cmu.edu/classes/95-865-K/HW/HW2/reuters-allcats-6.zip; unzip reuters-allcats-6.zip; rm reuters-allcats-6.zip
モデルを定義する
model_definition.yaml
input_features:
-
name: text
type: text
encoder: parallel_cnn
level: word
output_features:
-
name: class
type: category
実行ファイルを作成する
text-classification.sh
# !/bin/sh
ludwig experiment \
--data_csv reuters-allcats.csv \
--model_definition_file model_definition.yaml
実行する
chomod +x text-classification.sh
./text-classification.sh
_ _ _
| |_ _ __| |_ __ _(_)__ _
| | || / _` \ V V / / _` |
|_|\_,_\__,_|\_/\_/|_\__, |
|___/
ludwig v0.1.0 - Experiment
Experiment name: experiment
Model name: run
Output path: results/experiment_run_1
ludwig_version: '0.1.0'
command: ('/Users/user/.pyenv/versions/ludwig/bin/ludwig experiment --data_csv '
'reuters-allcats.csv --model_definition_file model_definition.yaml')
dataset_type: 'reuters-allcats.csv'
(...中略...)
Using full raw csv, no hdf5 and json file with the same name have been found
Building dataset (it may take a while)
Loading NLP pipeline
Writing dataset
Writing train set metadata with vocabulary
Training set: 2868
Validation set: 389
Test set: 822
╒══════════╕
│ TRAINING │
╘══════════╛
Epoch 1
Training: 100%|█████████████████████████████████| 23/23 [01:58<00:00, 4.45s/it]
Evaluation train: 100%|█████████████████████████| 23/23 [00:25<00:00, 1.07it/s]
Evaluation vali : 100%|███████████████████████████| 4/4 [00:03<00:00, 1.21it/s]
Evaluation test : 100%|███████████████████████████| 7/7 [00:07<00:00, 1.02it/s]
Took 2m 35.3381s
╒═════════╤════════╤════════════╤═════════════╕
│ class │ loss │ accuracy │ hits_at_k │
╞═════════╪════════╪════════════╪═════════════╡
│ train │ 1.0197 │ 0.6464 │ 0.9826 │
├─────────┼────────┼────────────┼─────────────┤
│ vali │ 1.2768 │ 0.6324 │ 0.9692 │
├─────────┼────────┼────────────┼─────────────┤
│ test │ 0.9788 │ 0.6484 │ 0.9781 │
╘═════════╧════════╧════════════╧═════════════╛
Validation loss on combined improved, model saved
Epoch 2
Training: 100%|█████████████████████████████████| 23/23 [01:55<00:00, 4.10s/it]
Evaluation train: 100%|█████████████████████████| 23/23 [00:26<00:00, 1.11it/s]
Evaluation vali : 100%|███████████████████████████| 4/4 [00:03<00:00, 1.20it/s]
Evaluation test : 100%|███████████████████████████| 7/7 [00:07<00:00, 1.06it/s]
Took 2m 32.5552s
╒═════════╤════════╤════════════╤═════════════╕
│ class │ loss │ accuracy │ hits_at_k │
╞═════════╪════════╪════════════╪═════════════╡
│ train │ 0.8393 │ 0.6764 │ 0.9826 │
├─────────┼────────┼────────────┼─────────────┤
│ vali │ 0.8853 │ 0.6632 │ 0.9692 │
├─────────┼────────┼────────────┼─────────────┤
│ test │ 0.8229 │ 0.6873 │ 0.9781 │
╘═════════╧════════╧════════════╧═════════════╛
Validation loss on combined improved, model saved
Epoch 3
Training: 100%|█████████████████████████████████| 23/23 [01:51<00:00, 4.07s/it]
Evaluation train: 100%|█████████████████████████| 23/23 [00:23<00:00, 1.15it/s]
Evaluation vali : 100%|███████████████████████████| 4/4 [00:03<00:00, 1.06it/s]
Evaluation test : 100%|███████████████████████████| 7/7 [00:06<00:00, 1.09it/s]
Took 2m 26.5846s
╒═════════╤════════╤════════════╤═════════════╕
│ class │ loss │ accuracy │ hits_at_k │
╞═════════╪════════╪════════════╪═════════════╡
│ train │ 0.7676 │ 0.7103 │ 0.9826 │
├─────────┼────────┼────────────┼─────────────┤
│ vali │ 0.8054 │ 0.6915 │ 0.9692 │
├─────────┼────────┼────────────┼─────────────┤
│ test │ 0.7641 │ 0.7238 │ 0.9781 │
╘═════════╧════════╧════════════╧═════════════╛
Validation loss on combined improved, model saved
(...中略...)
Epoch 16
Training: 100%|█████████████████████████████████| 23/23 [02:02<00:00, 4.47s/it]
Evaluation train: 100%|█████████████████████████| 23/23 [00:28<00:00, 1.11s/it]
Evaluation vali : 100%|███████████████████████████| 4/4 [00:04<00:00, 1.14s/it]
Evaluation test : 100%|███████████████████████████| 7/7 [00:08<00:00, 1.11s/it]
Took 2m 44.5637s
╒═════════╤════════╤════════════╤═════════════╕
│ class │ loss │ accuracy │ hits_at_k │
╞═════════╪════════╪════════════╪═════════════╡
│ train │ 0.6644 │ 0.7374 │ 0.9847 │
├─────────┼────────┼────────────┼─────────────┤
│ vali │ 0.7771 │ 0.7121 │ 0.9717 │
├─────────┼────────┼────────────┼─────────────┤
│ test │ 0.7325 │ 0.7287 │ 0.9781 │
╘═════════╧════════╧════════════╧═════════════╛
Last improvement of loss on combined happened 3 epochs ago
EARLY STOPPING due to lack of validation improvement, it has been 3 epochs since last validation accuracy improvement
Best validation model epoch: 13
Best validation model loss on validation set combined: 0.7578277952566858
Best validation model loss on test set combined: 0.7275135337291263
╒═════════╕
│ PREDICT │
╘═════════╛
Evaluation: 100%|█████████████████████████████████| 7/7 [00:09<00:00, 1.21s/it]
/Users/btf/.pyenv/versions/ludwig/lib/python3.6/site-packages/sklearn/metrics/classification.py:1143: UndefinedMetricWarning: Precision is ill-defined and being set to 0.0 in labels with no predicted samples.
'precision', 'predicted', average, warn_for)
/Users/btf/.pyenv/versions/ludwig/lib/python3.6/site-packages/sklearn/metrics/classification.py:1143: UndefinedMetricWarning: F-score is ill-defined and being set to 0.0 in labels with no predicted samples.
'precision', 'predicted', average, warn_for)
===== class =====
accuracy: 0.7287104622871047
hits_at_k: 0.9781021897810219
loss: 0.732521887823323
overall_stats: { 'avg_f1_score_macro': 0.3449311442398679,
'avg_f1_score_micro': 0.7287104622871048,
'avg_f1_score_weighted': 0.7185596038520464,
'avg_precision_macro': 0.3574669484512109,
'avg_precision_micro': 0.7287104622871047,
'avg_precision_weighted': 0.7287104622871047,
'avg_recall_macro': 0.3400706094575441,
'avg_recall_micro': 0.7287104622871047,
'avg_recall_weighted': 0.7287104622871047,
'kappa_score': 0.5537654825893901,
'overall_accuracy': 0.7287104622871047}
per_class_stats: {<UNK>: { 'accuracy': 1.0,
'f1_score': 0,
'fall_out': 0.0,
'false_discovery_rate': 1.0,
'false_negative_rate': 1.0,
'false_negatives': 0,
'false_omission_rate': 0.0,
'false_positive_rate': 0.0,
'false_positives': 0,
'hit_rate': 0,
'informedness': 0.0,
'markedness': 0.0,
'matthews_correlation_coefficient': 0,
'miss_rate': 1.0,
'negative_predictive_value': 1.0,
'positive_predictive_value': 0,
'precision': 0,
'recall': 0,
'sensitivity': 0,
'specificity': 1.0,
'true_negative_rate': 1.0,
'true_negatives': 822,
'true_positive_rate': 0,
'true_positives': 0},
Neg-: { 'accuracy': 0.7627737226277372,
'f1_score': 0.7801578354002255,
'fall_out': 0.1561561561561562,
'false_discovery_rate': 0.1306532663316583,
'false_negative_rate': 0.29243353783231085,
'false_negatives': 143,
'false_omission_rate': 0.33726415094339623,
'false_positive_rate': 0.1561561561561562,
'false_positives': 52,
'hit_rate': 0.7075664621676891,
'informedness': 0.551410306011533,
'markedness': 0.5320825827249456,
'matthews_correlation_coefficient': 0.5416602438464253,
'miss_rate': 0.29243353783231085,
'negative_predictive_value': 0.6627358490566038,
'positive_predictive_value': 0.8693467336683417,
'precision': 0.8693467336683417,
'recall': 0.7075664621676891,
'sensitivity': 0.7075664621676891,
'specificity': 0.8438438438438438,
'true_negative_rate': 0.8438438438438438,
'true_negatives': 281,
'true_positive_rate': 0.7075664621676891,
'true_positives': 346},
Pos-earn: { 'accuracy': 0.9136253041362531,
'f1_score': 0.8404494382022473,
'fall_out': 0.1004784688995215,
'false_discovery_rate': 0.252,
'false_negative_rate': 0.04102564102564099,
'false_negatives': 8,
'false_omission_rate': 0.013986013986013957,
'false_positive_rate': 0.1004784688995215,
'false_positives': 63,
'hit_rate': 0.958974358974359,
'informedness': 0.8584958900748374,
'markedness': 0.734013986013986,
'matthews_correlation_coefficient': 0.7938186129402964,
'miss_rate': 0.04102564102564099,
'negative_predictive_value': 0.986013986013986,
'positive_predictive_value': 0.748,
'precision': 0.748,
'recall': 0.958974358974359,
'sensitivity': 0.958974358974359,
'specificity': 0.8995215311004785,
'true_negative_rate': 0.8995215311004785,
'true_negatives': 564,
'true_positive_rate': 0.958974358974359,
'true_positives': 187},
Pos-acq: { 'accuracy': 0.8029197080291971,
'f1_score': 0.44897959183673475,
'fall_out': 0.13157894736842102,
'false_discovery_rate': 0.5769230769230769,
'false_negative_rate': 0.5217391304347826,
'false_negatives': 72,
'false_omission_rate': 0.10810810810810811,
'false_positive_rate': 0.13157894736842102,
'false_positives': 90,
'hit_rate': 0.4782608695652174,
'informedness': 0.3466819221967965,
'markedness': 0.314968814968815,
'matthews_correlation_coefficient': 0.33044514553165377,
'miss_rate': 0.5217391304347826,
'negative_predictive_value': 0.8918918918918919,
'positive_predictive_value': 0.4230769230769231,
'precision': 0.4230769230769231,
'recall': 0.4782608695652174,
'sensitivity': 0.4782608695652174,
'specificity': 0.868421052631579,
'true_negative_rate': 0.868421052631579,
'true_negatives': 594,
'true_positive_rate': 0.4782608695652174,
'true_positives': 66},
Pos-coffee: { 'accuracy': 0.9841849148418491,
'f1_score': 0,
'fall_out': 0.015815085158150888,
'false_discovery_rate': 1.0,
'false_negative_rate': 1.0,
'false_negatives': 0,
'false_omission_rate': 0.0,
'false_positive_rate': 0.015815085158150888,
'false_positives': 13,
'hit_rate': 0,
'informedness': -0.015815085158150888,
'markedness': 0.0,
'matthews_correlation_coefficient': 0,
'miss_rate': 1.0,
'negative_predictive_value': 1.0,
'positive_predictive_value': 0.0,
'precision': 0.0,
'recall': 0,
'sensitivity': 0,
'specificity': 0.9841849148418491,
'true_negative_rate': 0.9841849148418491,
'true_negatives': 809,
'true_positive_rate': 0,
'true_positives': 0},
Pos-gold: { 'accuracy': 0.9951338199513382,
'f1_score': 0,
'fall_out': 0.0048661800486617945,
'false_discovery_rate': 1.0,
'false_negative_rate': 1.0,
'false_negatives': 0,
'false_omission_rate': 0.0,
'false_positive_rate': 0.0048661800486617945,
'false_positives': 4,
'hit_rate': 0,
'informedness': -0.0048661800486617945,
'markedness': 0.0,
'matthews_correlation_coefficient': 0,
'miss_rate': 1.0,
'negative_predictive_value': 1.0,
'positive_predictive_value': 0.0,
'precision': 0.0,
'recall': 0,
'sensitivity': 0,
'specificity': 0.9951338199513382,
'true_negative_rate': 0.9951338199513382,
'true_negatives': 818,
'true_positive_rate': 0,
'true_positives': 0},
Pos-housing: { 'accuracy': 1.0,
'f1_score': 0,
'fall_out': 0.0,
'false_discovery_rate': 1.0,
'false_negative_rate': 1.0,
'false_negatives': 0,
'false_omission_rate': 0.0,
'false_positive_rate': 0.0,
'false_positives': 0,
'hit_rate': 0,
'informedness': 0.0,
'markedness': 0.0,
'matthews_correlation_coefficient': 0,
'miss_rate': 1.0,
'negative_predictive_value': 1.0,
'positive_predictive_value': 0,
'precision': 0,
'recall': 0,
'sensitivity': 0,
'specificity': 1.0,
'true_negative_rate': 1.0,
'true_negatives': 822,
'true_positive_rate': 0,
'true_positives': 0},
Pos-heat: { 'accuracy': 0.9987834549878345,
'f1_score': 0,
'fall_out': 0.0012165450121655041,
'false_discovery_rate': 1.0,
'false_negative_rate': 1.0,
'false_negatives': 0,
'false_omission_rate': 0.0,
'false_positive_rate': 0.0012165450121655041,
'false_positives': 1,
'hit_rate': 0,
'informedness': -0.0012165450121655041,
'markedness': 0.0,
'matthews_correlation_coefficient': 0,
'miss_rate': 1.0,
'negative_predictive_value': 1.0,
'positive_predictive_value': 0.0,
'precision': 0.0,
'recall': 0,
'sensitivity': 0,
'specificity': 0.9987834549878345,
'true_negative_rate': 0.9987834549878345,
'true_negatives': 821,
'true_positive_rate': 0,
'true_positives': 0}}
Finished: experiment_run
Saved to: results/experiment_run_1
なんか学習が始まった。ludwig ludwig experimentはUser Guideによれば学習と推測を1コマンドで実行してくれる便利コマンドらしい。エポックごとに学習進捗とモデルがセーブされていっている模様
上記をみると16エポックまでやってBest validation modelをエポック13としている。精度は約0.72。各クラスごとの精度など詳しい報告も出力されている。
学習経過を可視化する
ludwig visualize コマンドで可視化する
ludwig visualize --visualization learning_curves --training_statistics ./results/experiment_run_1/training_statistics.json
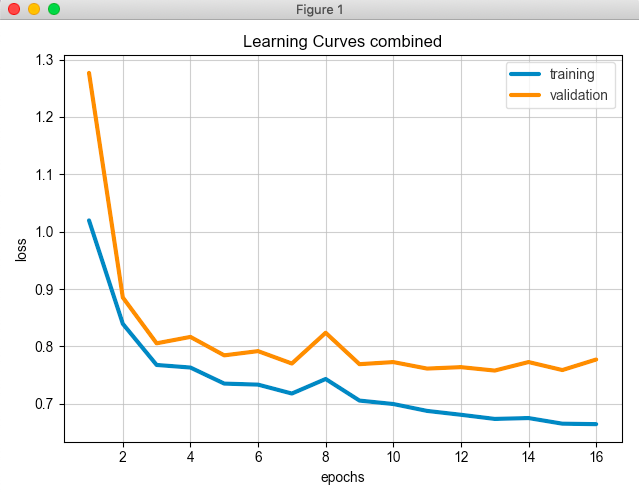
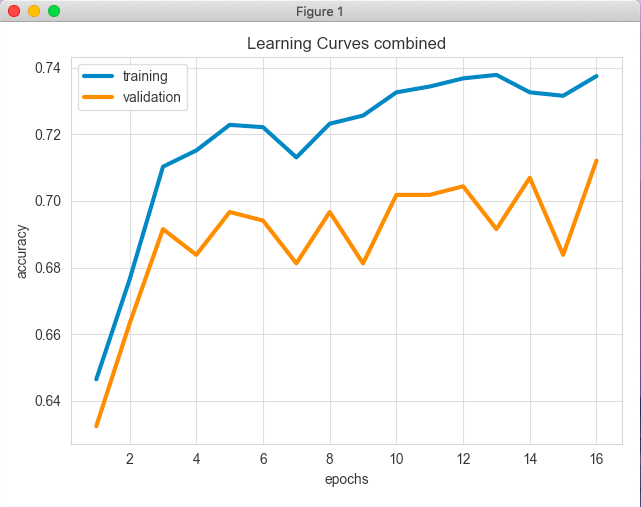
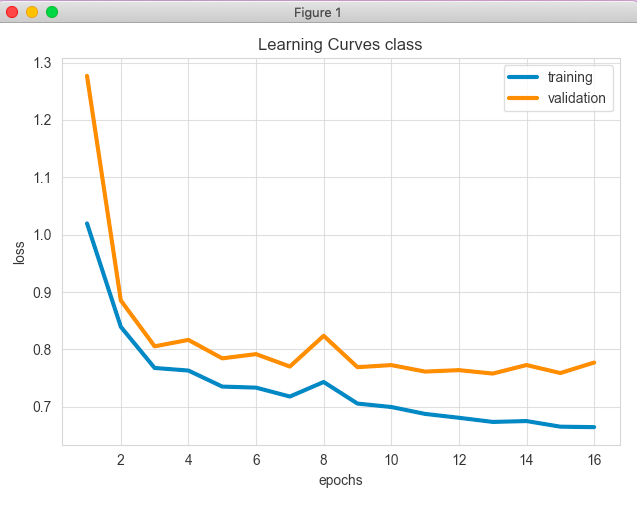
Pyplotっぽいのが表示された
まとめ
他にもいろいろあるみたいだけどとりあえずここまで。
いろんな推論をぱっと試せる感があっていい。おもしろいので時間があるときにひととおり使ってみようと思います。