よく使うのでメモ代わりに。
随時更新しています。
前処理が全体の工程の9割ですね...。
更新履歴
2021/6/29
このカラムのみ取り出してファイル保存したい
2020/8/27
・日付のdatetime変換、タイムゾーン変換を追加しました。
2020/6/29
・groupbyの処理、datetime処理等追加しました。
2020/6/17
・NaNの処理や全角半角処理、重複の処理等、いくつか処理を追加しました。
2020/4/16
・目次をつけて見やすくしました。
・カラムごとの集計や平均等、計算方法を追記しました。
全角半角処理はこちらをどうぞ
日付の処理(datetime変換、タイムゾーン変換)はこちらをどうぞ
Pythonで日付のタイムゾーン(時差)を変換(文字列から)
リストの処理
2次元リストを1次元にしたい
リストのリストになってるものをただのリストにしたい場合にすること。
text_listが2次元のリスト。
text_list = sum(text_list, [])
文章のリストがあるとして、全部で何単語あるのか確認したい
text_listが全文章が入ったリスト
print(sum(len(line) for line in text_list))
リストの重複を確認したい
print(set(list))
pandas df の処理
pd.concatで→←方向にがっちゃんこしたい
axis=1にする。
df2 = pd.concat([df,df1],axis=1)
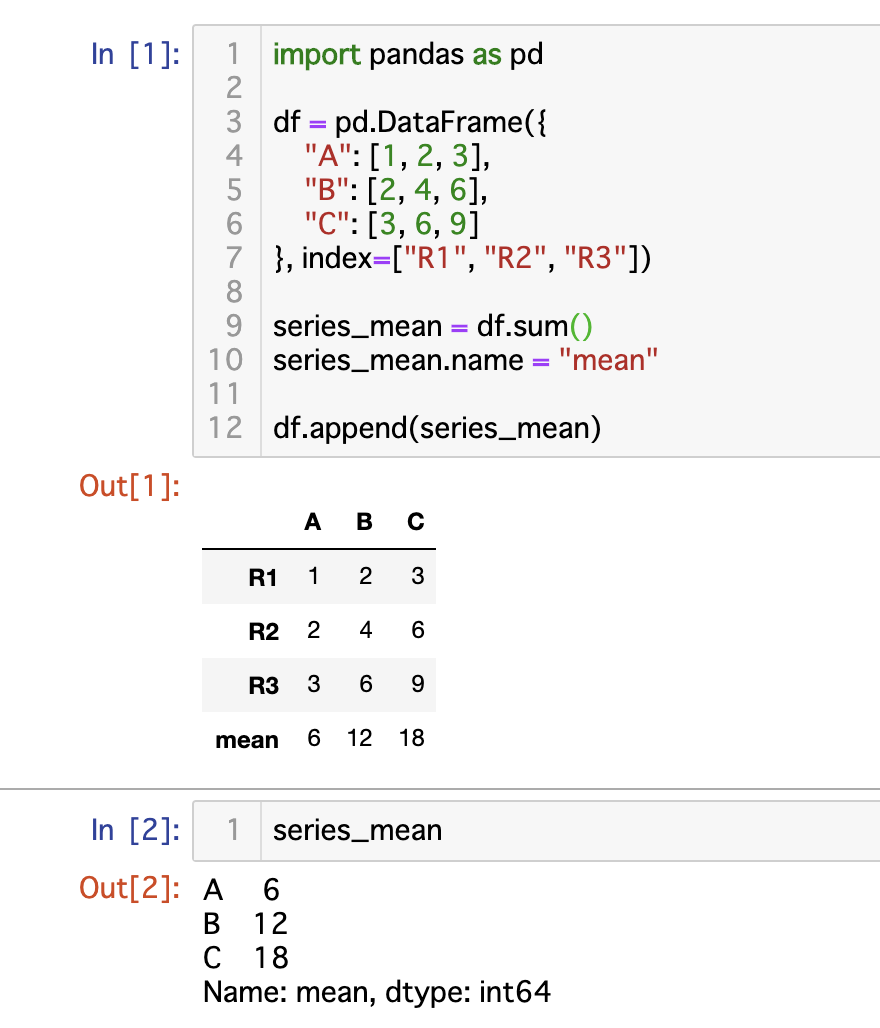
pandas dfの列の合計値を出し、最終行に追加したい
こちらのサイトから引用しました。
pandasで新しい行を追加(合計値の行を追加)
import pandas as pd
df = pd.DataFrame({
"A": [1, 2, 3],
"B": [2, 4, 6],
"C": [3, 6, 9]
}, index=["R1", "R2", "R3"])
series_mean = df.sum()
series_mean.name = "mean"
df.append(series_mean)
pandas dfの重複した行や値を確認・削除したい
### 重複した行がないかチェック
### True と Falseの数がそれぞれ返ってくる。Trueが重複しているもの。
print(df_check.duplicated('EMPLOYEE').value_counts([]))
### カラム名「EMPLOYEE」に重複がないかチェック
print(df_check.duplicated('EMPLOYEE').value_counts([]))
### 重複している行をprint。keep=Falseにするとすべての重複している行を見れる。
print(df_check[df_check.duplicated('EMPLOYEE', keep=False)])
### 重複している行を削除
df_check = df_check.drop_duplicates()
### 重複している行を削除 - 行番号を指定しての場合
df_check_drop = df_check.drop(df_check.index[[63, 221, 312]])
dfから特定のカラムのみ取り出し、新たなdfをつくりたい
df_new = df.loc[:, ["カラム名1", "カラム名2"]]
# もしくは
df_new = df[["カラム名1", "カラム名2"]]
都道府県のカラムから、東京都のみのデータを取り出したい
tokyo = ['東京'] #リスト型にしないとエラーになる。複数のキーを入れてOK
df1 = df[df['都道府県(カラム名)'].isin(tokyo)]
「123-456」をハイフンで分割して、二つのカラムにしたい。
df1 = df['郵便番号(カラム名)'].str.split('-', expand=True)
dfからこの値を取り出したい
# 行、列名で検索
# 行名は指定しておらず、勝手に番号がふられている場合は、''なしで番号を指定してあげると良い。
df.loc[0,'genka']
# 行、列の番号で検索
df.iloc[0,0]
# 行番号のみ指定
df.iloc[0]
リストにあるコードでヒットするデータを、元データから削除したい
# 削除対象のコードが入ったリスト = df_del
for i in range(len(df_del)):
#削除対象のコード取得
code = df_del.iloc[i,'コード(カラム名']
#削除対象の行を元データから検索。
df_s = df[df['コード(カラム名)']== code]
#ヒットした行を削除
df = df.drop(index=df_s.index)
行番号を指定して削除したい
df2 = df1.drop(index=[134, 189, 1089, 2285])
データの並び替えがしたい
# 複数のカラムで並び替えする場合は、左から順に優先して並び替えがされる。
# あいうえお順になる。
df2 = df2.sort_values(['カラム1','カラム2','カラム3'])
小数点、切り捨てしたい
# 2は小数点第二位。例えば4だと第4位まで残す。
df2['カラム1'] = round(df2['カラム1'], 2)
# 0で小数点切り捨て。
数字をカンマ(,)区切りにしたい
df3['カラム名'] = df3['カラム名'].map('{:,}'.format)
二つのカラムを一つにしたい。
pd.merge後、カラムが二つかぶってしまったときなどに。
# カラム「都道府県_y」を削除。
# ただし、「都道府県_x」の値が空白で、「都道府県_y」には「東京都」と入っている場合、「都道府県_x」に東京都と入れたい。
# あらかじめ、NaNを''にしておく.
df_outer['都道府県_x'] = df_outer['都道府県_x'].fillna('')
df_outer['都道府県_y'] = df_outer['都道府県_y'].fillna('')
for i in range(len(df_outer)):
data = df_outer.loc[i, '都道府県_x']
if data == '':
df_outer.loc[i, '都道府県_x'] = df_outer.loc[i, '都道府県_y']
pandas df 空白の処理
NaNのややこしさよ...。
NaN = Not a Number
CSVを読み込んだときや、mergeしたときに、空白がNaNになる。
NaNのdtypeはfloat。
pandasで空白行を削除したい
import pandas as pd
import numpy as np
# サンプルdf作成
df = pd.DataFrame(np.random.randn(10, 2), columns=list('AB'))
df['Tenant'] = np.random.choice(['Babar', 'Rataxes', ''], 10)
# 空白をまずNaNに置き換え
df['Tenant'].replace('', np.nan, inplace=True)
# Nanを削除 inplace=Trueでdfが上書きされる。 df = df.dropnaにするとエラーでるよ
df.dropna(subset=['Tenant'], inplace=True)
# ちなみにカラム番号が振られてる場合は、それを指定してもOK
df.dropna(subset=[0], inplace=True)
pandasで、このカラムとこのカラムが空白だったら削除したい
# subsetを複数に。how="all"で、指定したすべてのカラムが空白の場合に削除となる
df.dropna(subset=['Column_A','Column_B'], how="all", inplace=True)
pandasで空白行削除後、行数の番号を新しいものにしたい
### 行数の番号を0からにする###
df.index = range(len(df))
### 行に新たな名前をつける###
df.index = ['a', 'b', 'c', 'd', 'e', 'f']
ちなみにカラム名を変えるにはdf.columns。
df.columns = ['カラム名1', 'カラム名2']
NaNを空白にしたい
df.fillna('')
ただしdtypeがobjectになる。
NaNの行のみ抽出したい
# カラム名を指定すると、特定のカラムの値が空白のもののみ抽出。
df1 = df[df['カラム名'].isnull()]
pandas df csv読み込み時の処理
カラム数がばらばらの行があるCSVをpandasで読み込みたい
読み込むときにカラム数を適当につけてあげると良い
for文使って30個カラムつくる。
col_names = [ 'c{0:02d}'.format(i) for i in range(30)]
df = pd.read_csv('namae.csv',names=col_names)
空白行も読み込みたい
skip_blank_linesをFalseにする。
df = pd.read_csv('namae.csv', skip_blank_lines=False)
ヘッダーがないCSVを読み込みたい
header=None にして 自動的に番号をふる。
または、names = ['カラム名1','カラム名2']と指定していく
df = pd.read_csv('Data.csv', header=None)
空白をNaNにしたくない
NaNになると、その後のdtypesで問題が起こりやすいので...
# na_filter=Falseにする。
# dtype='object'にしておくのも便利。
df = pd.read_csv('データ.csv', dtype='object', na_filter=False)
Pandas DataFrame カラムごとの処理
このカラムの文字列をきれいにしたい
str.replaceを使って、いらない文字列を一括で削除する
# ?の前にはバックスラッシュを忘れない。(?を?として認識させるために)
df_new_drop['product url']=df_new_drop['product url'].str.replace('\?Inch=0', '')
# つなげること可能
df_new_drop['Lead Time']=df_new_drop['Lead Time'].str.replace('当天', '1').str.replace('起','').str.replace('天','')
カラム名を変更したい
# 新たなdfの名前をつけると安心。
df2 = df1.rename(columns={'古いカラム名': '新しいカラム名'})
# もしくは
df2.rename(columns={1: '得コード真ん中'}, inplace=True) #Trueにする
# (カラム名が数字の場合には、''はつけなくて良い)
このカラムをなくしたい
df_old = df_old.drop('Unnamed: 0', axis=1).drop('Recommend', axis=1)
df_07_en4 = df_07_en4.drop(['large cate url', 'middle cate url',
'product cate url','Unnamed: 0_x','Unnamed: 0_y'], axis=1)
この文字をこのカラムすべての値に足していきたい
# 'product url'というカラムのすべての値の最後に「/」を足したい。
for index, row in df_new_drop.iterrows():
df_new_drop.at[index, 'product url'] += '/'
「田中花子」の最初の2文字だけ取りたい
df['名前'] = df_t5['名前'].str[:2]
「クラス」が「D」のものは削除したい
df = df[df['クラス'] != 'D']
カラムの値が0だったら削除したい
# 一度0をNaNに置き換えるのも手
df['Column_A'].replace(0.0, np.nan, inplace=True)
df.dropna(subset=['Column_A'], inplace=True)
「クラス」がNaNのもののみ抽出したい
df = df[df['クラス'].isnull()]
このカラムのみ取り出してファイル保存したい
to_csvが使えないのでpickleが便利そうです
import pickle
# ユニーク値のみsetで取り出し、リスト化
list = list(set(df['名前']))
# テキストファイルとして保存
f = open('name_list.txt','wb')
pickle.dump(list,f)
# 読み込みはこれ
f=open('name_list.txt', 'rb')
list = pickle.load(f) #リストとして読み込まれる
参考:
pythonでlistをファイルに保存し、読み込む方法(numpyも同様!)
Pandas DataFrame データ型の処理
データを読み込むときに指定
dtype で指定する。すべてのカラムのデータタイプを指定しなくてもOK。
object が string=文字列。
df = pd.read_csv(df_this_month, names = ["product url","Supplier","Lead Time"],
dtype = {'Lead Time':'object'})
データを読み込んだあとに指定
astype で指定。 str = string
# データ名['カラム名'] =
df['Lead Time']= df['Lead Time'].astype(str)
Pandas DataFrame 計算の処理
カラムごとに集計したり平均したりしたいときに。
このカラムの合計を出したい
df = df.groupby('カラム名').sum()
合計したあと、そのカラムがインデックス扱いされてしまうので、それを防ぎたい
as_index=Falseを引数に加える。
df = df.groupby('カラム名', as_index=False).sum()
いくつかのカラムでまとめて集計とか平均とかしたい
groupby()には、 何もせずに残しておきたいカラム名 を入れる。
np.sum合計
np.mean平均
max 最大値
min 最小値
count 数カウント
nunique 個々の戸数カウント
np.maxでも'max'でもふるまいは同じ。
df2 = df2.groupby(['カラム1','カラム2'], as_index=False).agg({'合計したいカラム名': np.sum, '平均したいカラム名':np.mean, 'カウントしたいカラム名':'count', 'それぞれの個数をカウントしたいカラム名':'nunique',})
最新の日付の数字を取りたい
df1 = df.loc[df.groupby(['グループ化したいカラム','カラム2'], as_index=False)['日付カラム'].idxmax()][['数字の入ったカラム','残したいカラム']]
# idx.maxで最大値のインデックス番号を取ってくる
# 最新の日付はmaxで求めれば良い
# 日付カラムがdatetimeになっていないといけないので注意!
groupbyの注意点
gyoupbyするカラム(グループ化するカラム)にひとつでもNaNがある行は削除されてしまいます。
防ぐには、groupbyするカラムをあらかじめstrに変更する必要。
pd.seriesの処理
seriesをリストにしたり、data frameにしたい
# dfからカラムをひとつ取り出す。
employee_list = df_jyoushi['EMPLOYEE']
# pd.seriesをリストにする
employee_list = employee_list.values.tolist()
# pd.seriesをdfにする
employee_list = pd.DataFrame(employee_list)
データの縦横処理(pivot)
このカラム横に持ってきたい、縦に持っていきたいという作業
「年度」に入ったデータをそれぞれ別のカラムに展開したい
df5 = df4.set_index(['何もしないカラム','何もしないカラム2'])
.pivot(columns="年度")['年度別に表示したいデータ(売上とか)']
.reset_index()
.rename_axis(None, axis=1)
↑を元に戻したい(pivot)
df_melt = pd.melt(df, id_vars=['何もしないカラム','何もしないカラム2'], var_name='年度', value_name ='年度に紐づいたデータ=値(売上とか)')
正規表現を使った処理
この記事が詳しいです。
分かりやすいpythonの正規表現の例
dfのカラムに入った住所を都道府県とそれ以外に分けたい
# 正規表現のパターンを作成
ptn = '(...??[都道府県])'
# 上のptnを使って都道府県のみ抽出。新たなdfができる
pref = df1['住所1'].str.extract(ptn, expand=True)
# 元データの住所カラムから都道府県削除
df1['住所'] = df1['住所'].str.replace(ptn, '')
# 都道府県カラムを元データに挿入
df1 = pd.concat([df1, pref], axis=1)
参考:
なるべく短い正規表現で住所を「都道府県/市区町村/それ以降」に分けるエクストリームスポーツ
その他
dfのすべての行を表示したい
pd.set_option('display.max_rows', 5000) #max5000行表示
# 注意!
# dfの行数より多い数字を設定しないと効きません
# jupyter notebookの動きや読み込みが重くなるので使いすぎに注意
日付をdatetimeで読み込みたい
import datetime
df = pd.read_csv('データ.csv',
parse_dates=[15], #日付の入ったカラムの番号(左から0から数えて何番目か)
date_parser=lambda date: pd.to_datetime(date, format='%Y/%m/%d'))
# formatは、日付がどんな表式で入っているか。
# '%Y/%m/%d'は、2020/06/01という表現。