以前の記事で、Dataiku DSSとpostgreSQLの接続初期設定の記事を書きましたが、今回はもう少し使いこなした系のチュートリアルをやってみました。
以前の記事で設定したconnectionはすでにあるものとして書きます。
今回実施したチュートリアルはこちらのDataiku DSS & SQLです。
Dataiku DSSはver 8.0.2を使いました。
プロジェクトの作成~データの確認
まずチュートリアル用のプロジェクトを作ります。
[+New Project] > [DSS Tutorials] > [Code] > [SQL in Dataiku DSS (Tutorial)]
プロジェクトができたら[GO TO FLOW]をクリック。
既に二つのデータセットがアップロードされています。
左側のordersデータセットは、t-shirtの注文ログデータです。
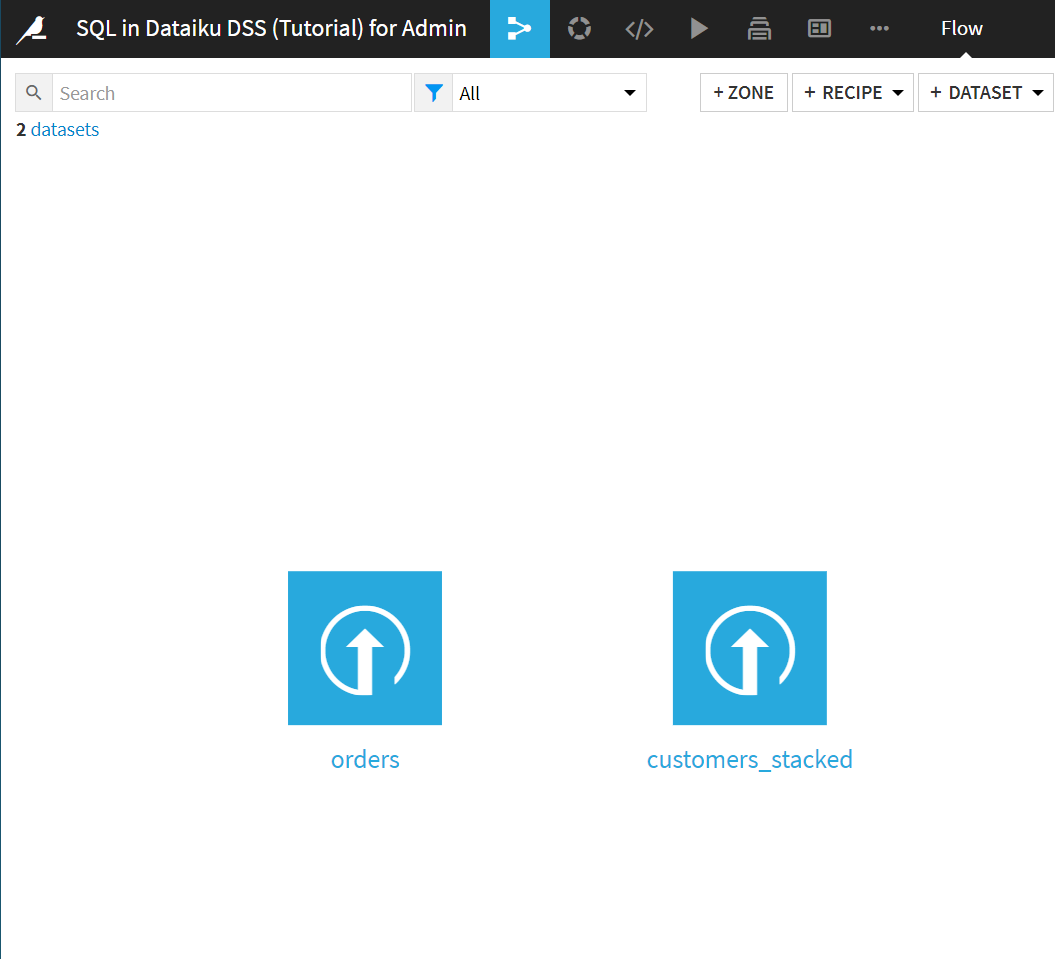
右側のcustomers_stackedはは、以下のようなデータで、顧客情報のデータのようです。
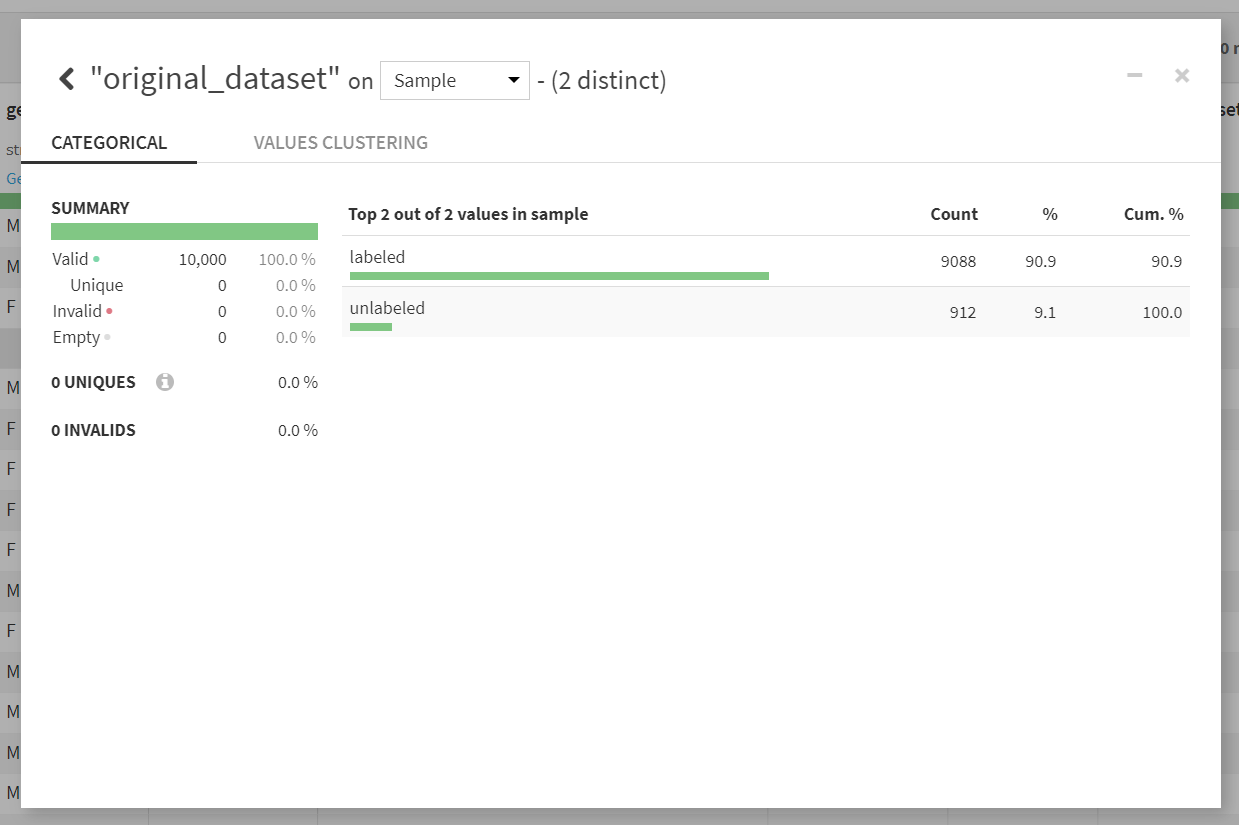
最右カラムのoriginal_datasetをAnalyzeで確認すると、labeledとunlabeledの2種類のカテゴリがあることがわかります。ラベルつきのデータとラベルなしのデータをスタックしたデータとなっているようです。
データベースへのデータ格納
Syncレシピを使ったデータベースへのデータ格納
ordersデータセットをpostgreSQLへインポートするためのSyncレシピを使ってみます。
Dataiku DSSはデフォルトでcsv読み込み時にすべてのカラムをstring型と認識します。
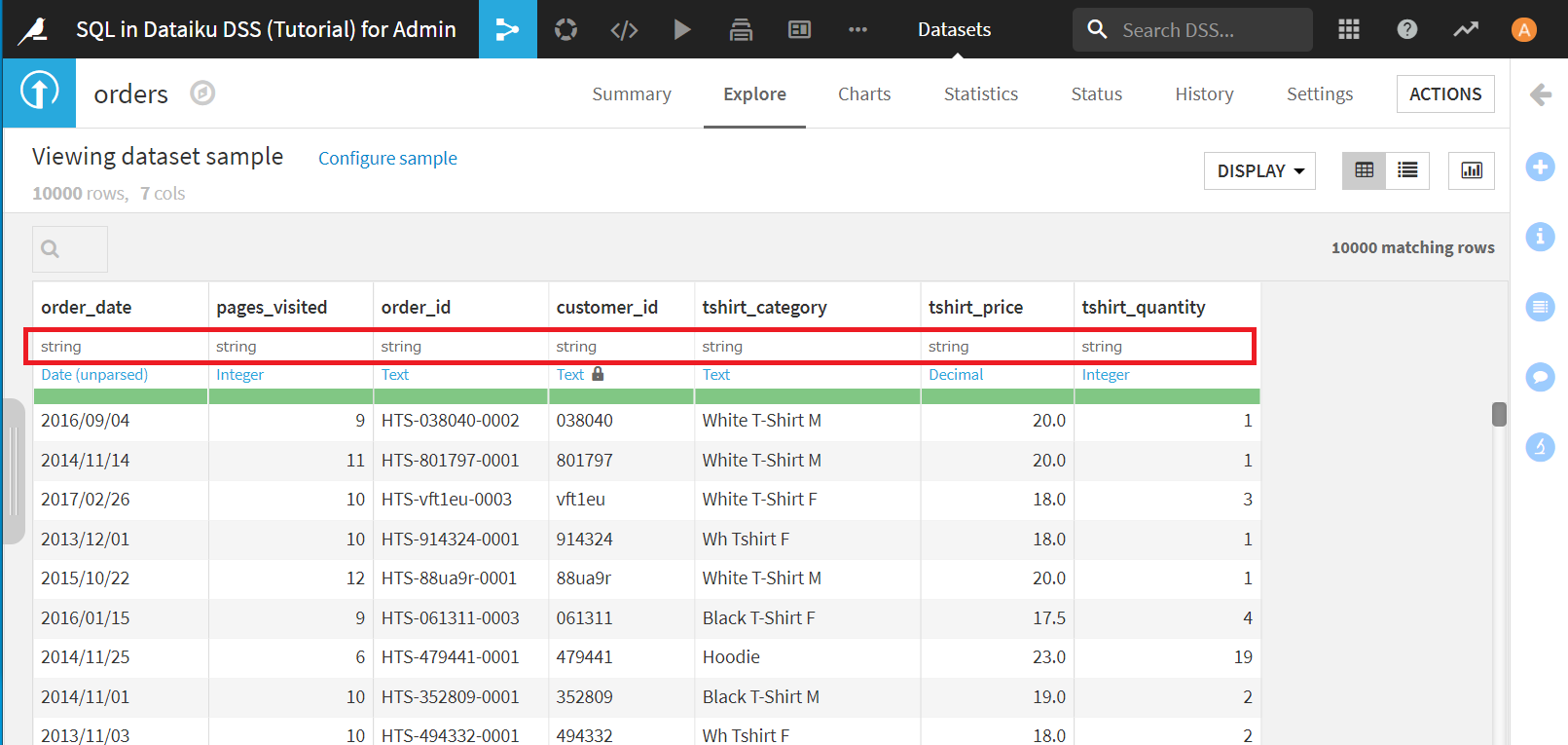
データベースに入れる段階で、適切な型を設定しておきます。Explore画面のグレーの型の文字クリックで変更可能です。pages_visitedとtshirt_qualityをintに、tshirt_priceをdoubleに設定します。
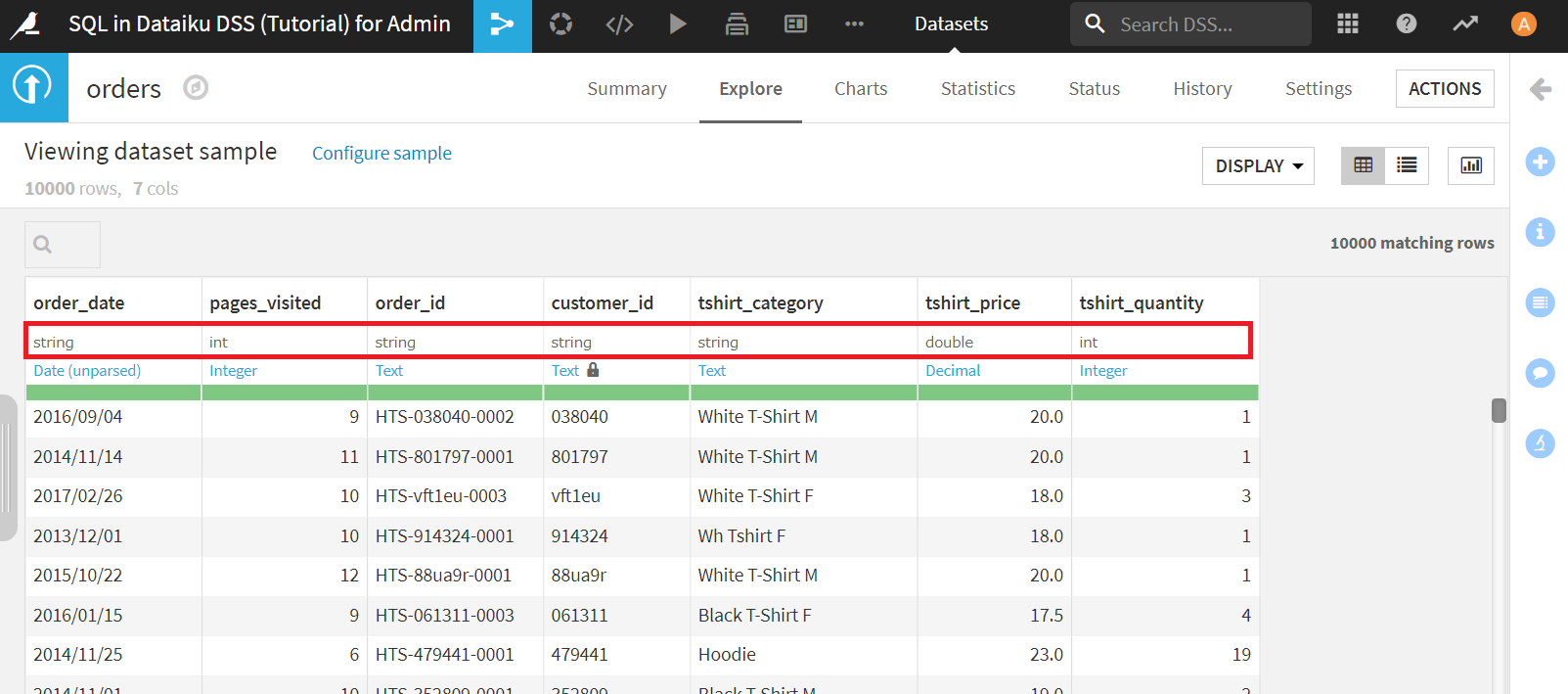
念のため、設定した型が適切かチェックします。
[Settings]>[Schema]>[CHECK NOW]をクリック。
以下のようにSchema and data are consisttent.と表示されればOKです。
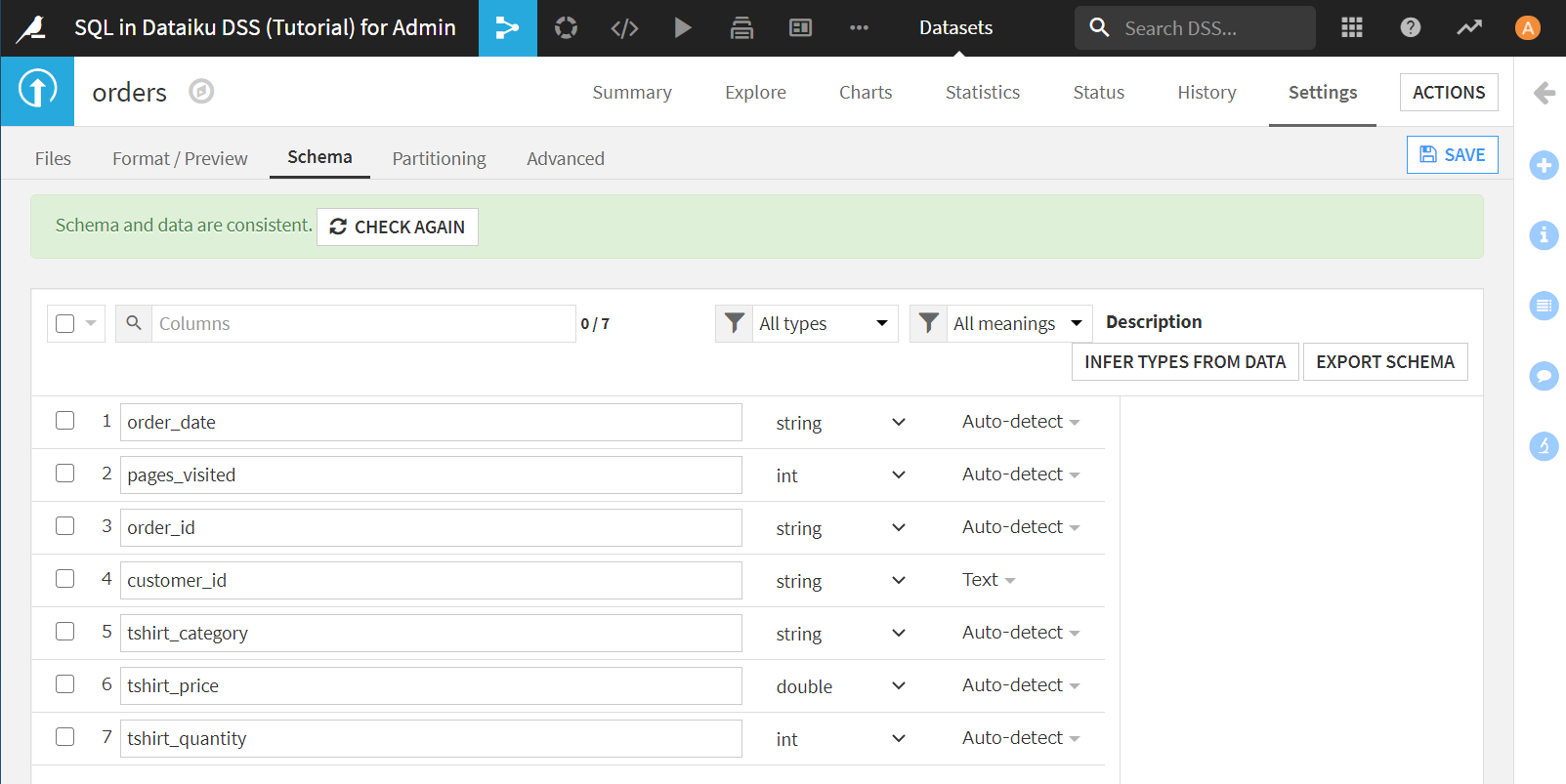
[INFER TYPES FROM DATA]>[SAVE]をクリックして、変更を保存します。
次に、[ACTION]>[Sync]をクリックし、Syncレシピを起動します。
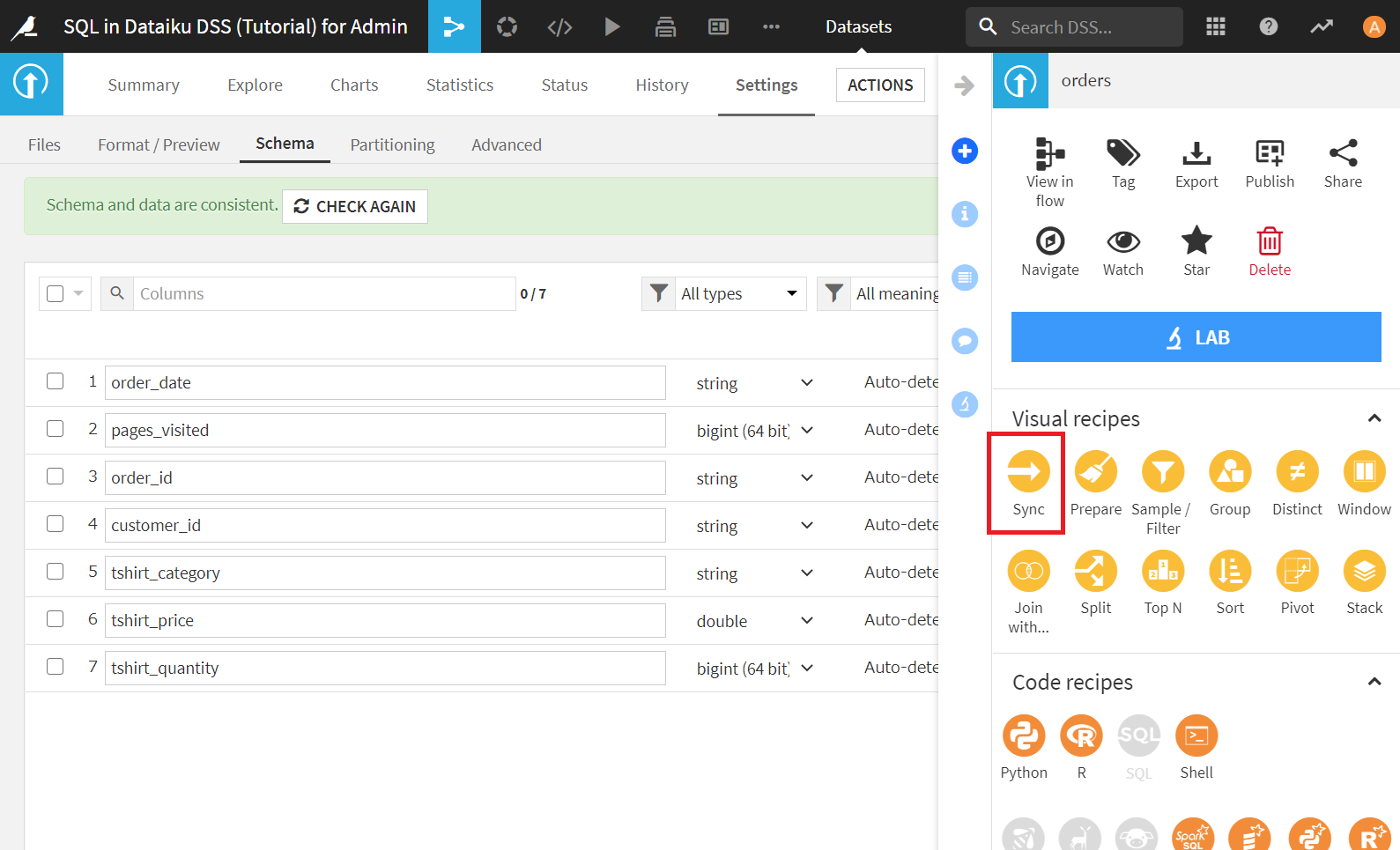
Store infoにPostgreSQL_tshirtを選択し、[CREATE_RECIPE]をクリック。
さらに[RUN]をクリック。Job succeededとでれば成功です。
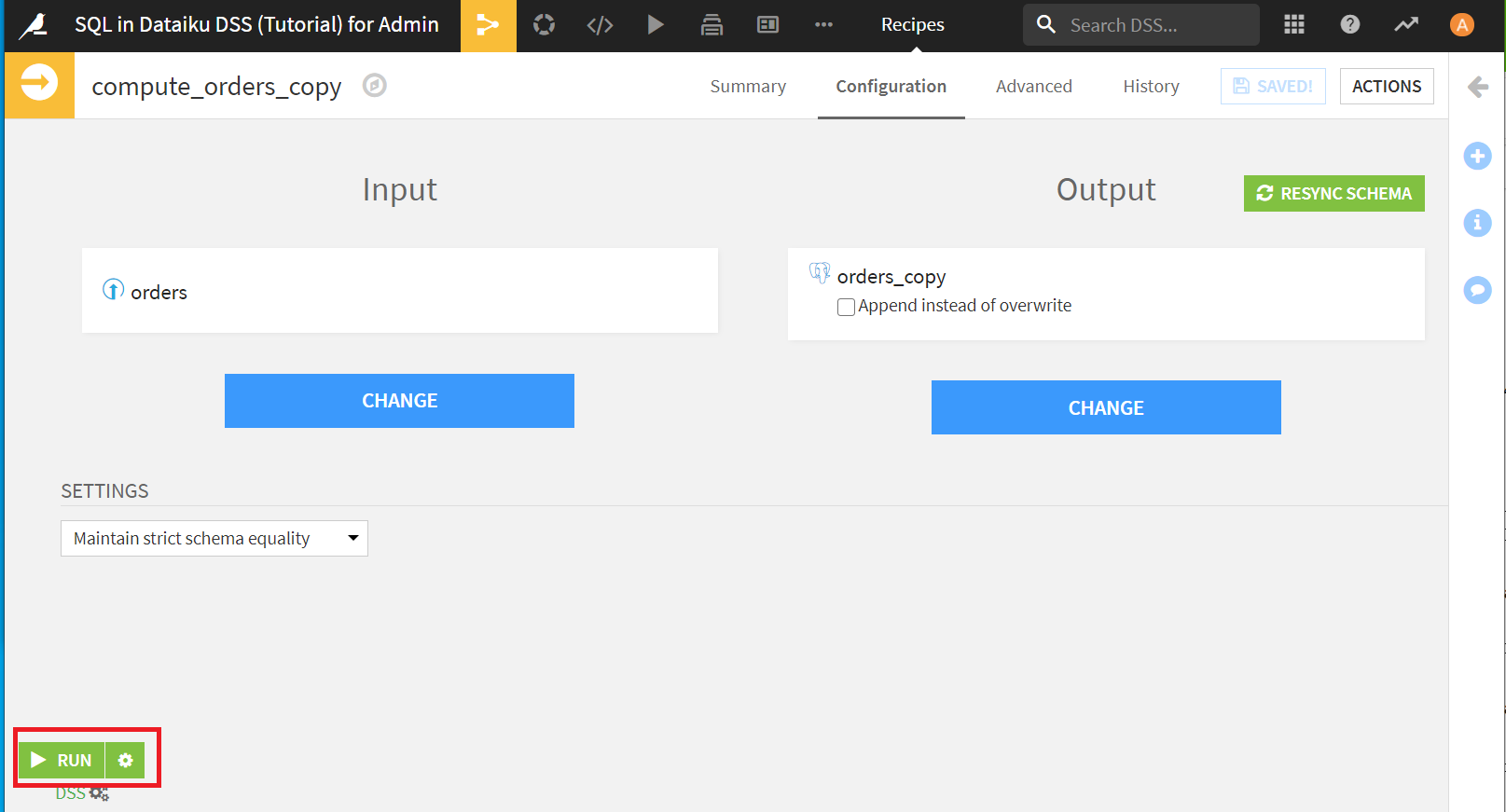
フローに戻って確認してみると、ordersデータセットからSyncレシピを用いてpostgreSQL内のデータとしてorders_copyが作成されているのがわかります。ちなみに、SCHEMAは先ほど変更した通りになっています。
Prepare Recipe経由でのデータベースへの格納
データ加工を行いたい場合は、Syncレシピを使わずにPreapareレシピを用いることで、データ加工後のデータをデータベースに格納することも可能です。
customers_stackedデータセットにprepareレシピを適用して、customers_stacked_preparedを作成します。ここでも、Store intoにはPostgreSQL_tshirtを指定します。
prepareレシピで以下の3処理を行い、[RUN]をクリック。
- birthdateカラムをdate parseします。Date formatはyyyy/MM/ddを選択します。また、birthdate_parsedカラムのstorage型がdateになっていますがstringにしておきます。dateのままだと、この後エラーが出ました。
- user_agentカラムに対してClassifyを実行し、user_agent_brandとuser_agent_os_columnsのみ残します。
- ip_addressカラムに対してResolve GeoIPを実施し、ip_address_countryとip_address_geopointのみ残します。
以上の操作で、データ加工済みのデータをpostgreSQLへ格納したcustomers_stacked_preparedができました。
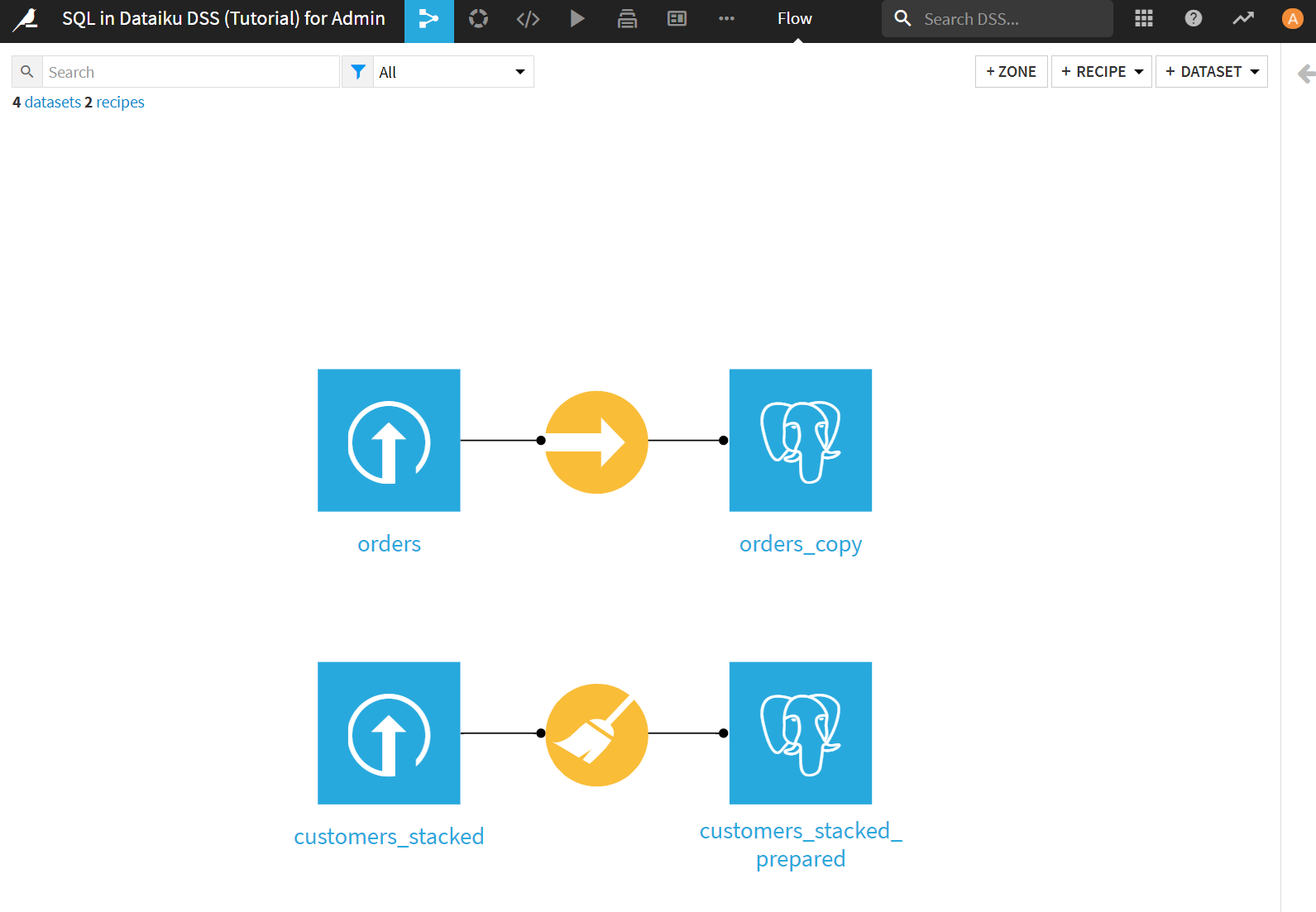
SQL Queryレシピを使ったデータセットの作成
データベース内のテーブルに対応するデータセットができたので、in-databaseでの処理というやつをやってみます。つまり、データベース側の機能を使ってデータ加工をします。
orders_copyデータセットを選択した状態で、SQLレシピをクリックします。
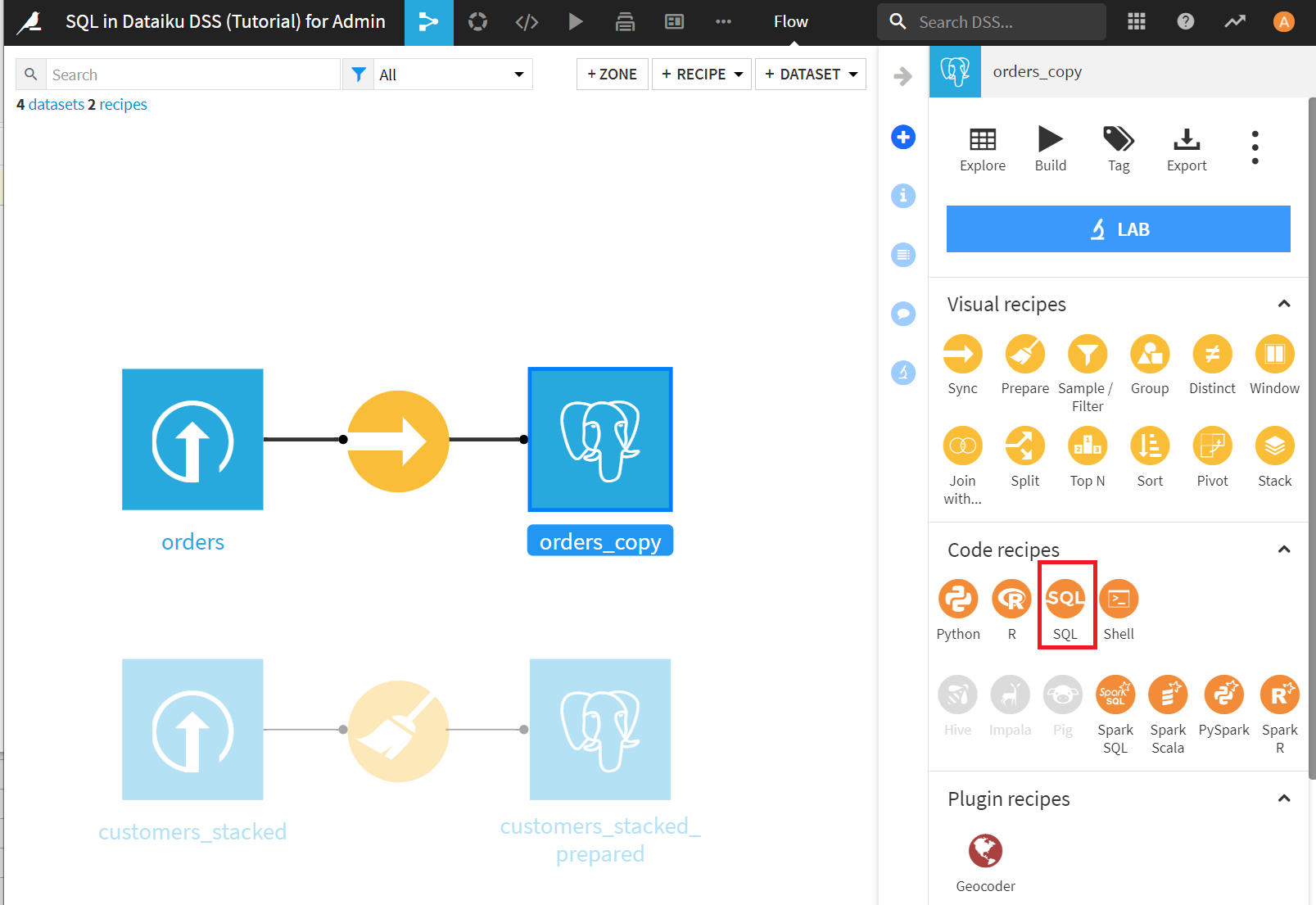
SQL queryをクリックします。
[SET]をクリックし、出力データセット名としてorders_by_customerを入力します。
[CREATE DATASET]クリック後に、[CREATE RECIPE]をクリックします。
デフォルトではこのようにSQL文がセットされた状態になっています。
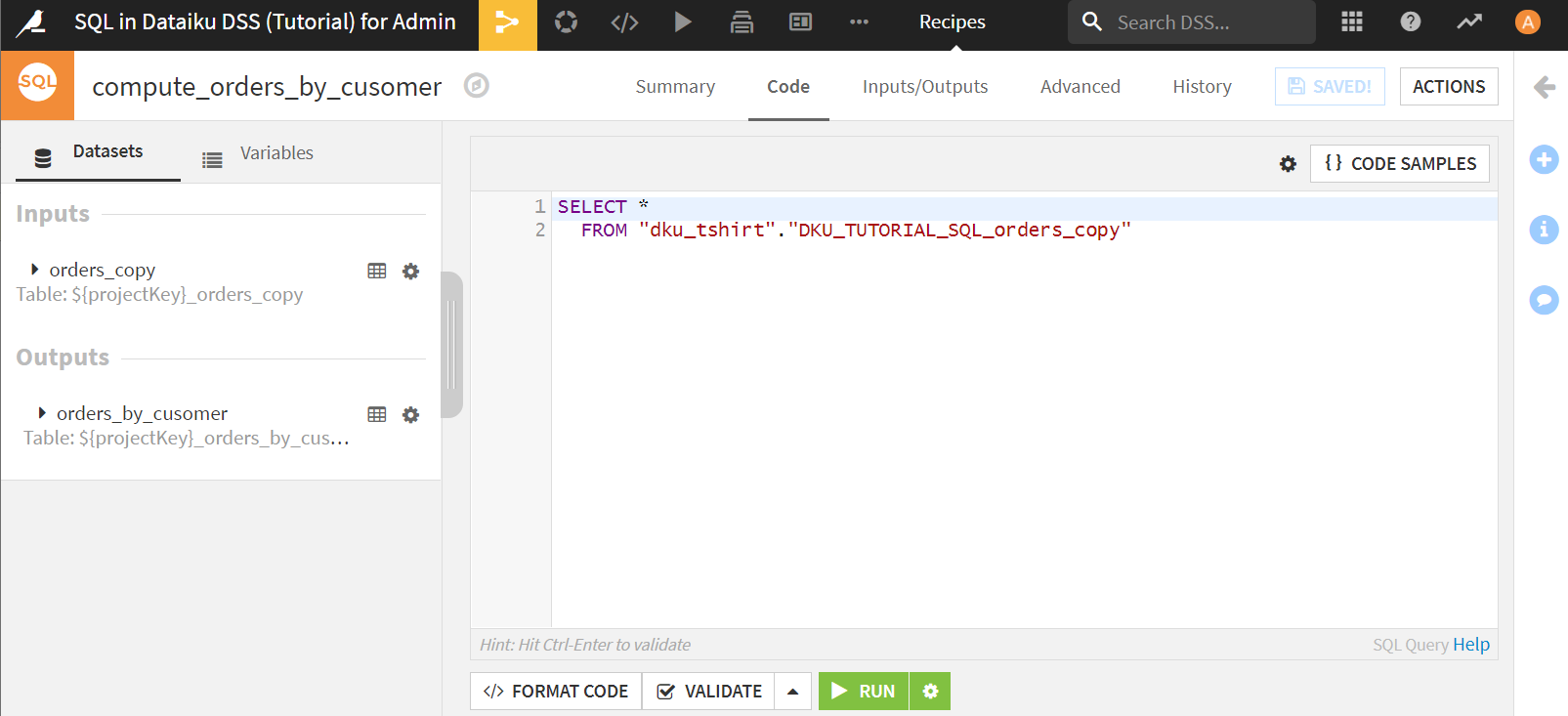
ここで、注文を顧客ごとにグルーピングし、過去の注文履歴を集計してみます。これはGroupレシピでも実行可能ですが、SQL文でも簡単に実装することができます。
入力されているSQL文を以下のように書き換えます。
SELECT customer_id,
AVG(pages_visited) AS pages_visited_avg,
SUM(tshirt_price*tshirt_quantity) AS total
FROM "dku_tshirt"."DKU_TUTORIAL_SQL_orders_copy"
GROUP BY customer_id;
[VALIDATE]クリックで構文チェックしておきます。
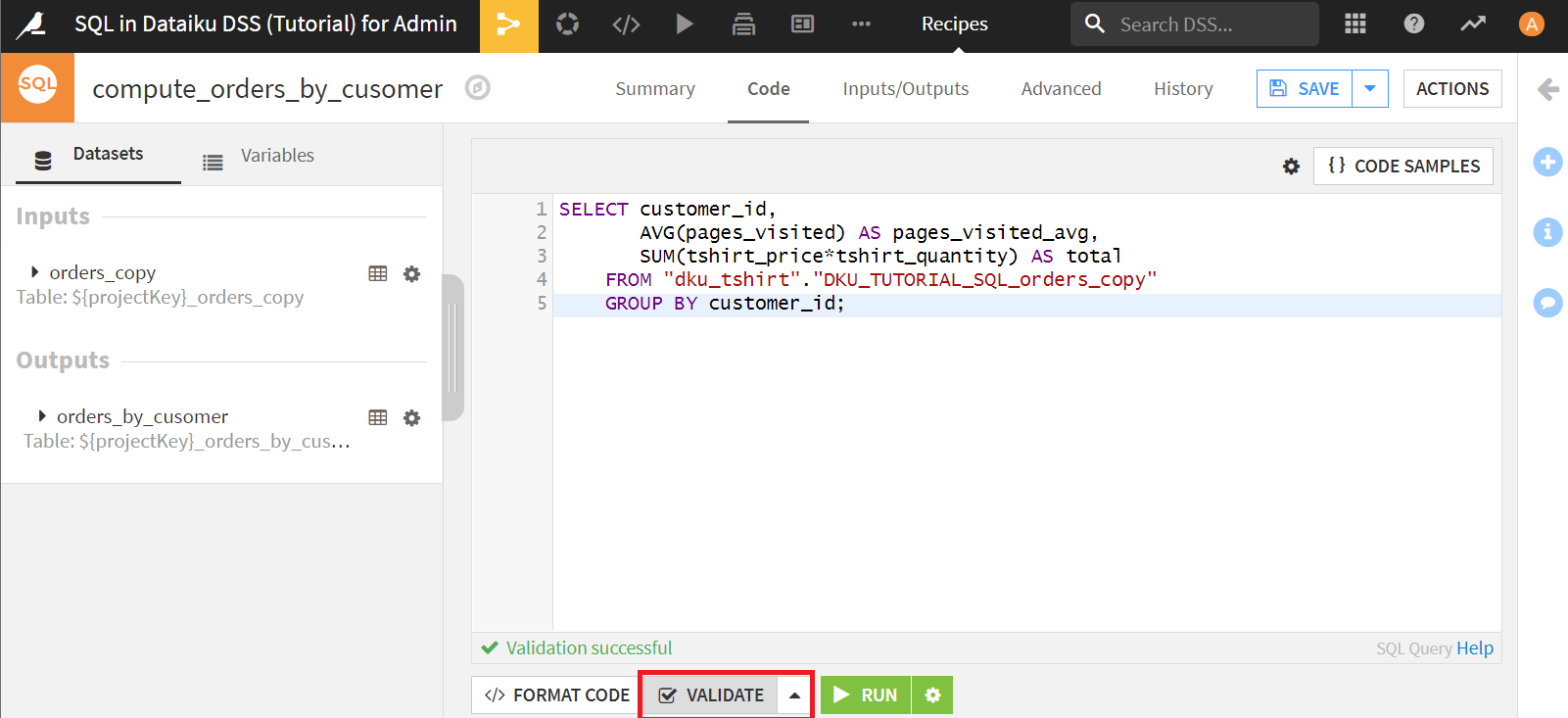
問題なければ[RUN]をクリック。
フローで確認すると、orders_by_customerデータセットができています。
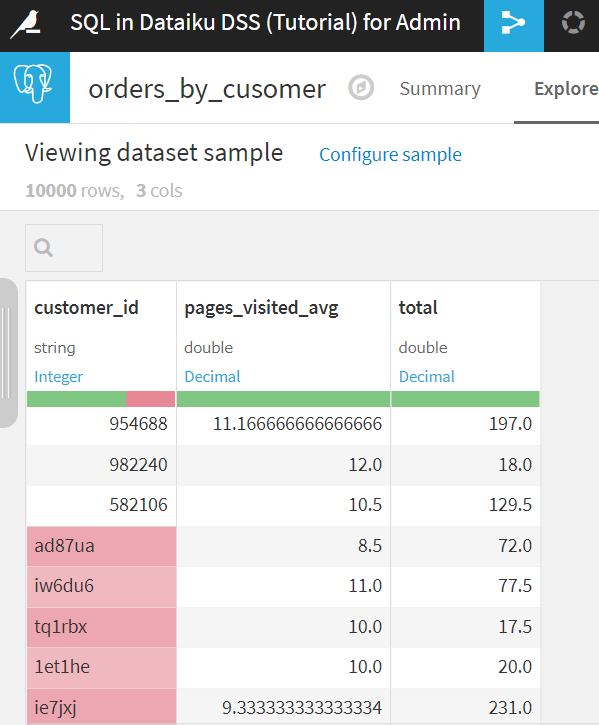
中を見てみると、ちゃんとcustomer_idごとにデータが集計されていることがわかります。
ビジュアルレシピを使用したデータベースの操作
ビジュアルレシピを使ったデータベースの操作を行ってみます。ここでは、テーブルに紐づけられたデータセットを結合して、また別のテーブルに紐づけたデータセットに格納するといった操作を行います。
customers_stacked_preparedを選択して、[Join with...]をクリック。
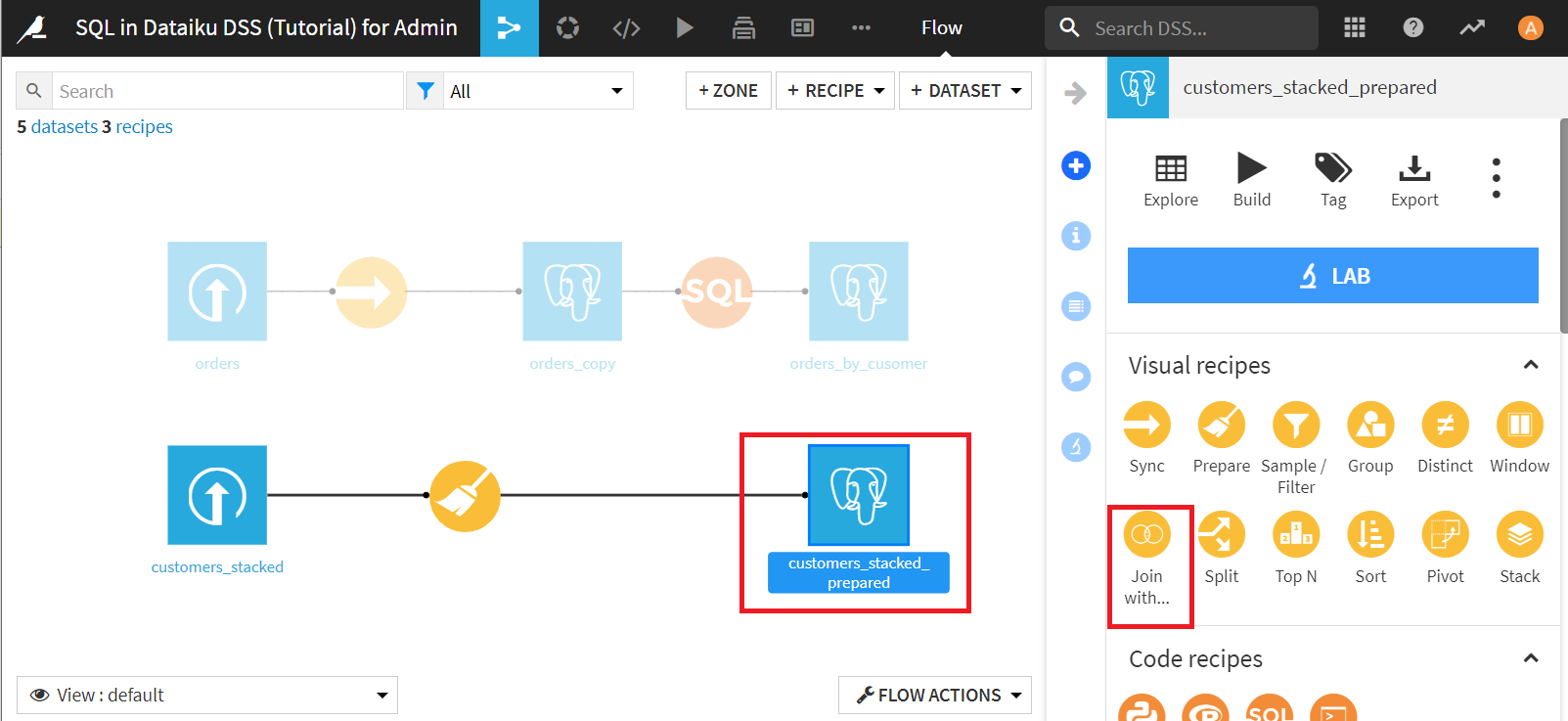
二番目のデータせセットにorders_by_cusomerを設定し、出力データセットにcustomers_enrichedを設定し、[CREATE RECIPE]をクリック。
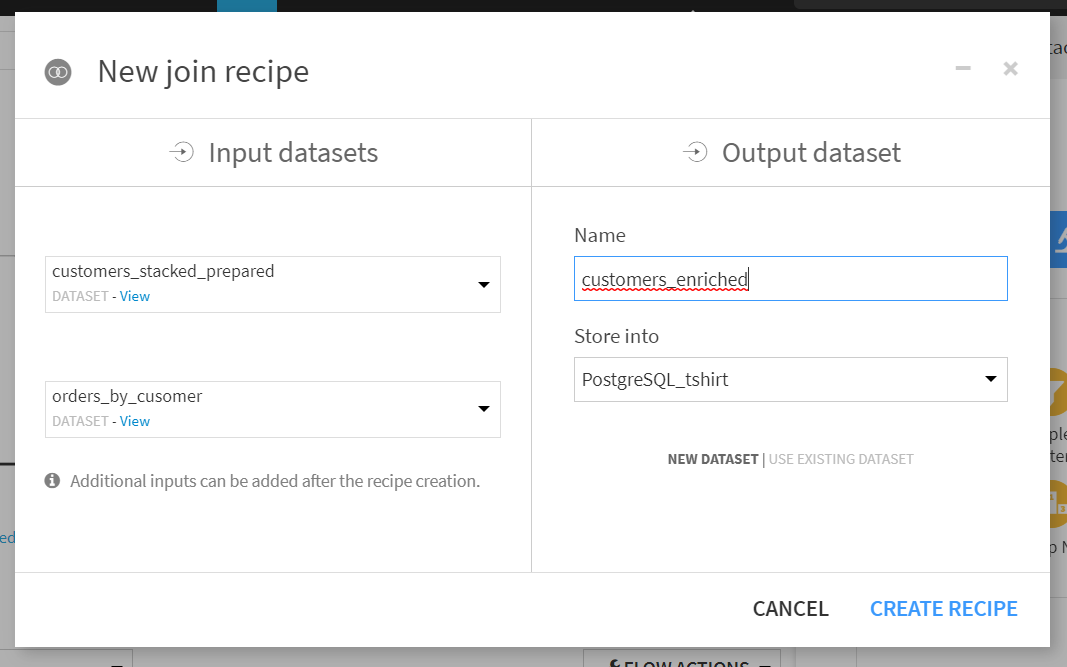
過去に注文したことのある顧客だけに絞りたいので、JOIN TYPEをINNER JOINに変更します。ちなみにJOIN TYPEは[Join]で変更可能です。
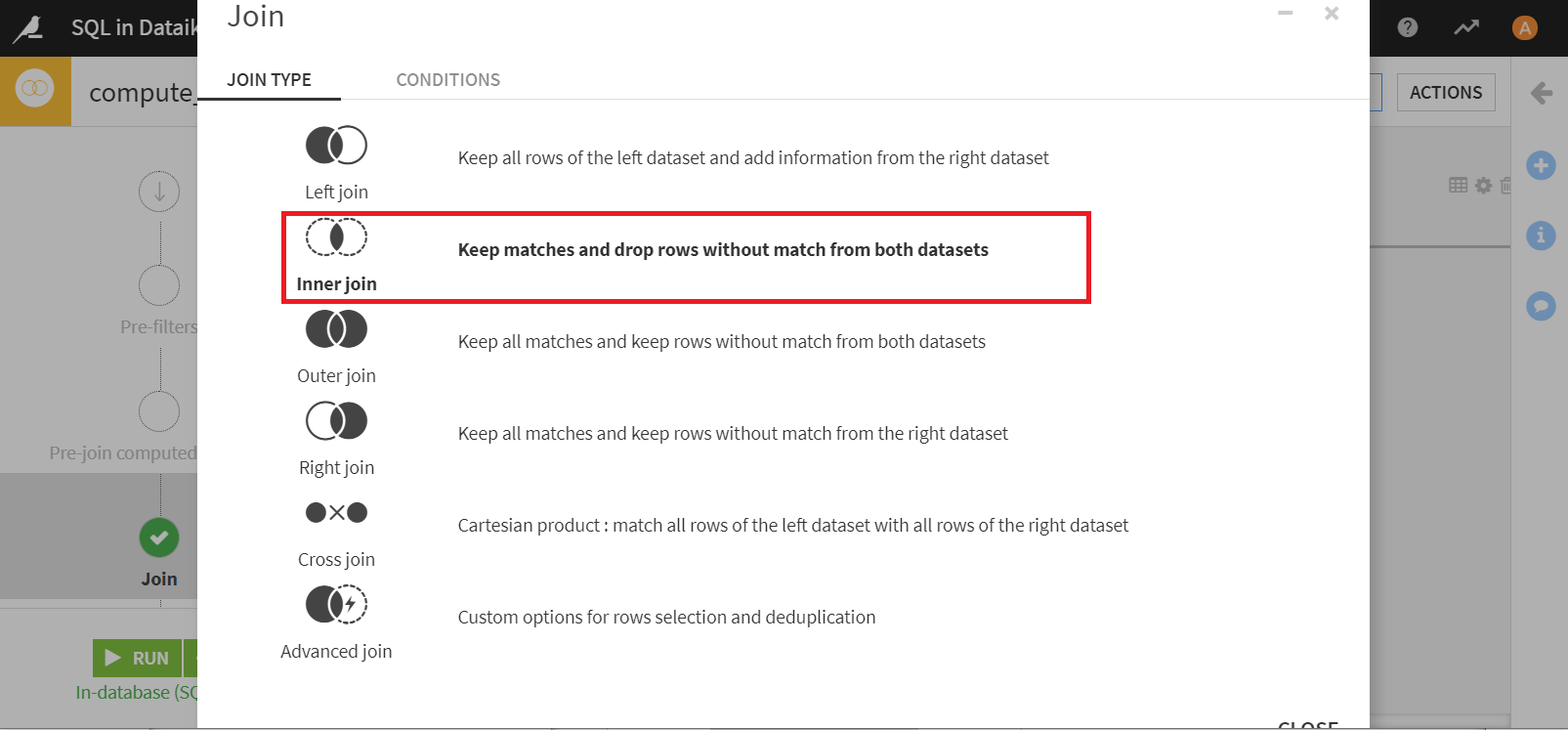
[Selected columns]で、出力カラムを調整することができます。customer_IDとcutomer_idは重複するカラムのため、orders_by_customerデータセットのcustomer_idを削除します。
最後に[Output]>[VIEW QUERY]でSQL文を確認します。
特に問題ないのでこのまま[RUN]をクリックします。
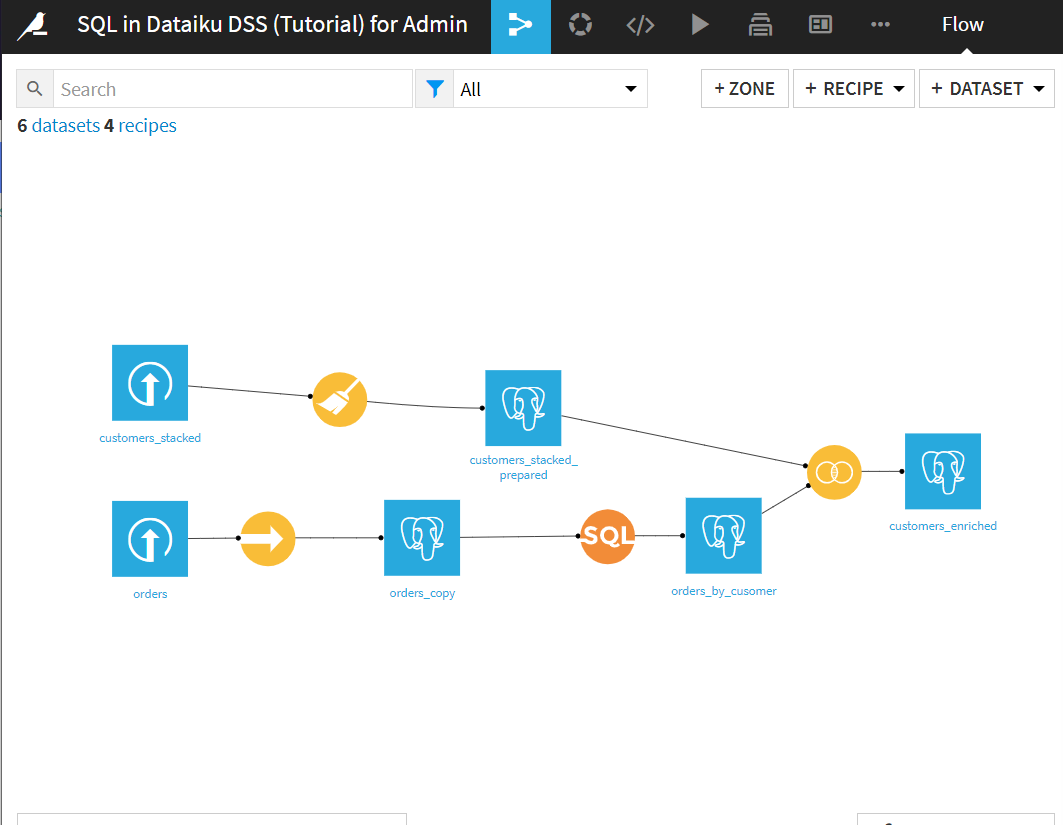
フロー上から、二つのpostgreSQLデータセットがJOINされてひとつのデータセットが作成されていることがわかります。SQL文をうたなくても、テーブルの結合を行うことができました。
データベースを利用した可視化
データベースを利用することでチャートの描画を速くすることができるようです。これは実データ扱うときには便利そう。
さきほど作ったcustomers_enrichedデータセットでチャートを描いてみます。
X軸にpages_visited_arg、Y軸にCount of recordsを設定します。Sampling&EngineのExecution engineをIn-databaseにして[SAVE]をクリック。
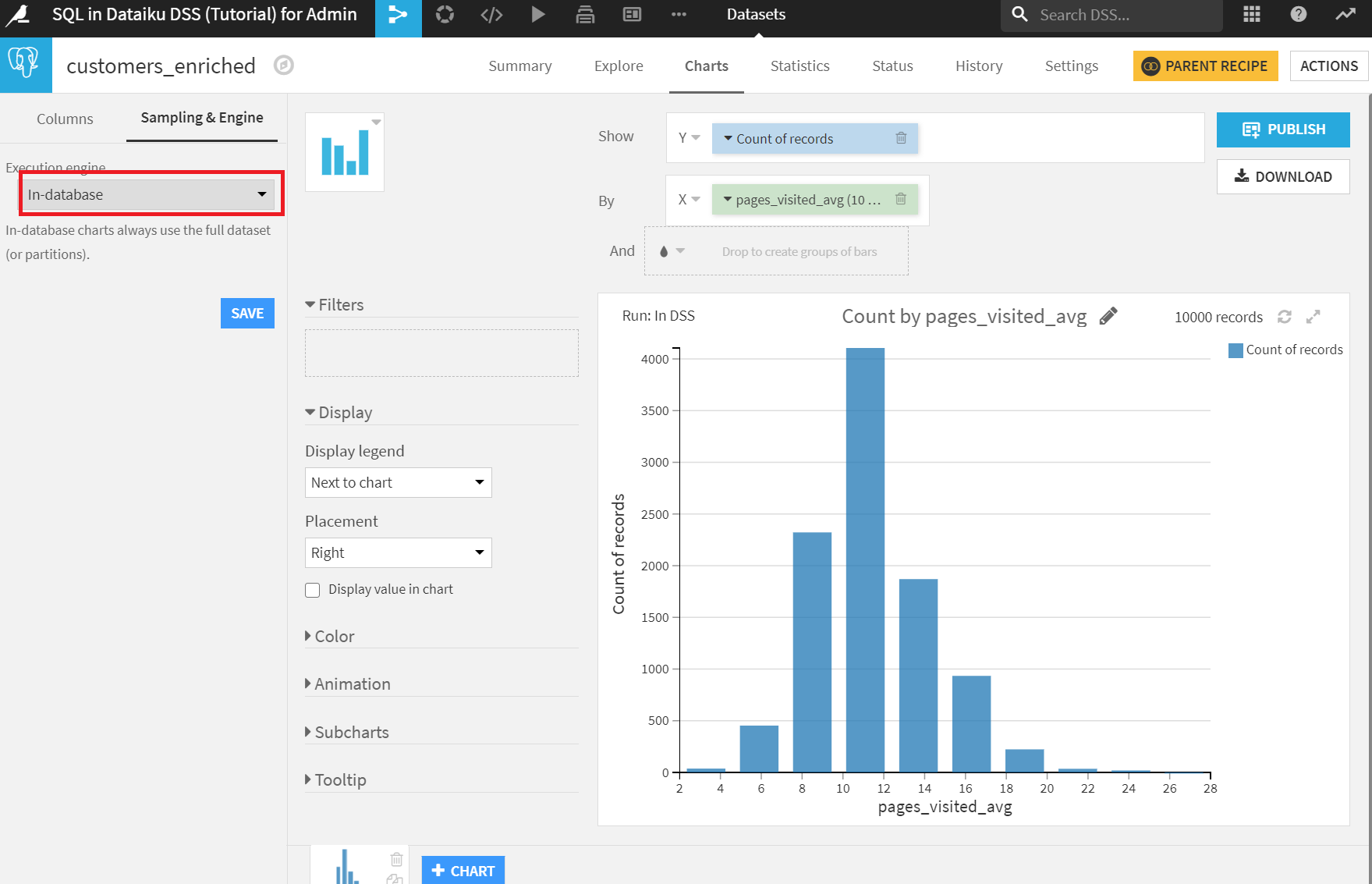
ヒストグラムの形状はあまり変わっていませんが、右側のrecords数が変化していますね。In-databaseの場合、全データで描画していることがわかります。今回はレコード数がすくないのであまりありがたみがないのですが、どのくらい速いのかについては、どこかで試してみたいところです。
SQL notebook
pythonやRのように、SQL notebookが用意されています。
[Lab]>[New Code Notebook]> [SQL]>[CREATE]でSQL notebookが作成できます。
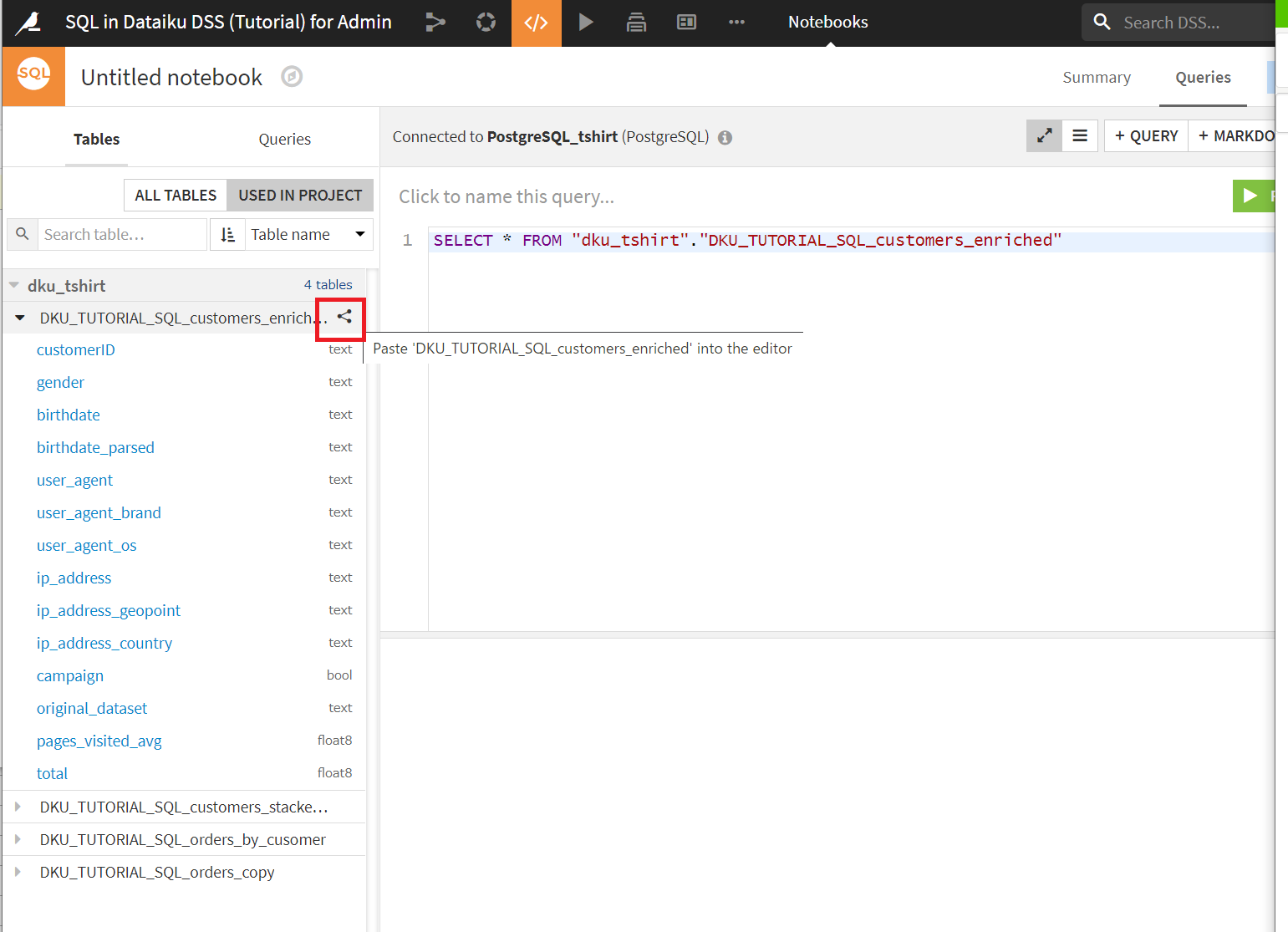
左側の[ALL TABLES]クリックで、アクセス可能なテーブルのリストが表示されます。
[+query]でSQL文を入力できるようになります。左側のテーブル一覧あたりを押すことで自動的にSQL文が挿入されるのがちょっと面白いです。
左側の赤で囲ってあるところを押すと、右側にSQL文が自動で入力されています。
[RUN]ボタンをクリックすると、下側にSQL文の結果のサンプルが表示されます。
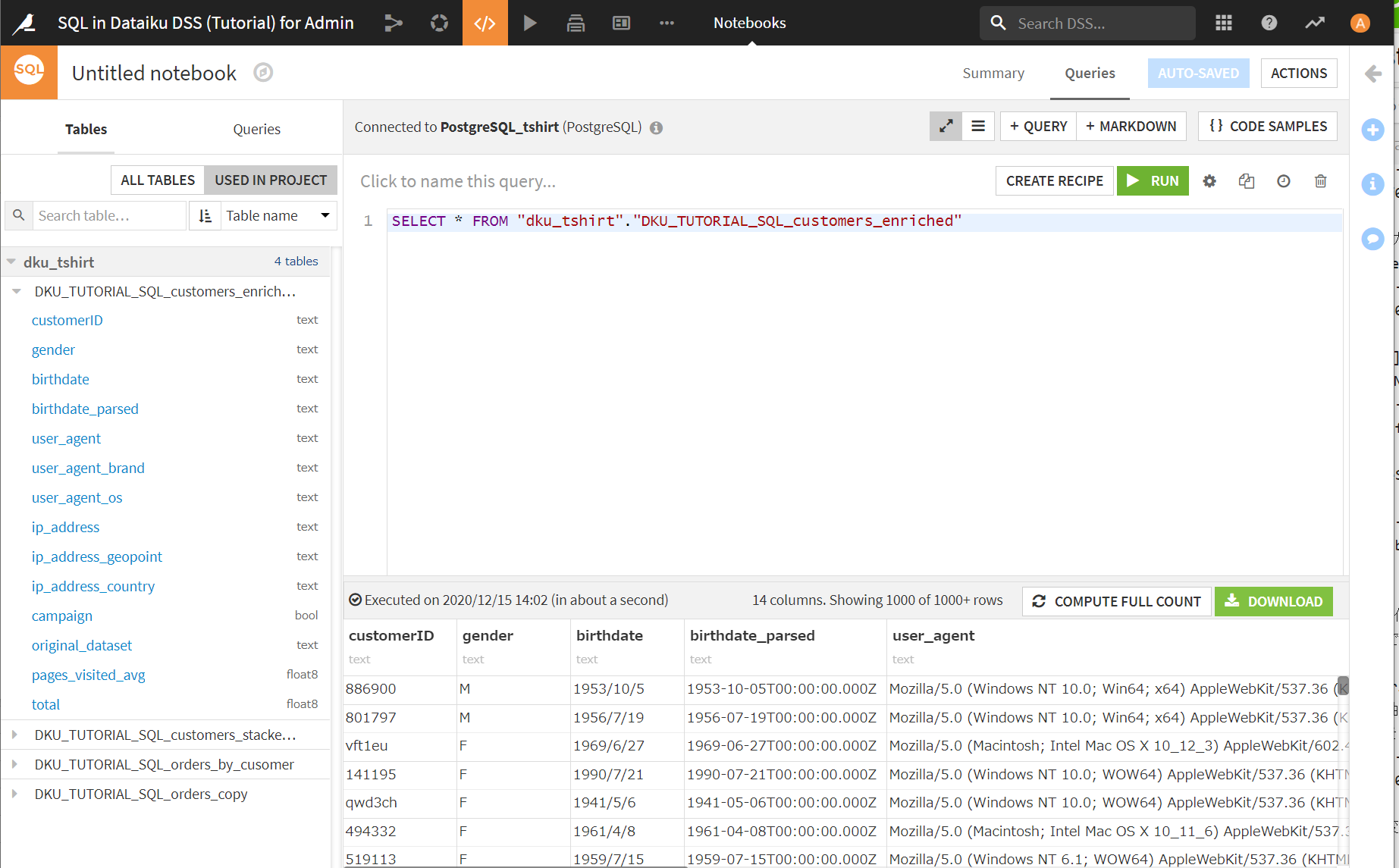
[+QUERY]ボタンでさらに構文を追加するといった使い方ができるようです。
SQL文をいろいろ書いてみて、結果を確認したいといった場合に使いやすそうです。
まとめ
今回は以下についてチュートリアルにのっとってやってみました。実務で使いどころ多そうな印象です。他にもいろいろなデータストレージに対応しているのでまた試してみたいです。
- Dataiku DSSからのpostgreSQLデータベースへのデータ格納
- Dataiku DSS上でのpostgreSQLデータベースの操作
- Dataiku DSS上でのデータベースを利用した可視化
- SQL notebook
以上