経緯
前回、ER図ランチについての記事を書きましたが(🍄マリオカートのER図に付いて考える)、
実際に図をいくつか書いてみて、データの成り立ちが何となくわかってきたかな?というタイミングで
実践的にクエリを書いていくことになりました。
今回は
Google BigQueryの画面を初めて見る人が、実際にSELECT文を書いてみた
という方式の回です。
ランチをしながら1時間で行うことのできた内容となります。
このBigQueryの機能、最初から出会いたかった。
🔰
0.何のためにやるの?
参加者はPMの方々+エンジニアの方々。
PMでも分析クエリが書けるようになれば、クエリの作成を都度お願いしなくてもいい。
自分で書くのが1番早いですし、
PVやUU等の簡単なデータ抽出なら、サッと書いてデータを見れるようになろう!・・・を目指します。
今回の記事は構文についてあまり触れませんが、
BigQueryの機能の使い方に重きを置いて紹介してみます。
1.必要なデータセットを準備する
今回はGoogle Cloud Platform(GCP)を使用しました。
データセット(テーブルの集合体)をGoogleが無料で一般公開しており、
・とりあえずSQLを書いて実行してみたい!
・クエリ書く練習したいけど環境がない・・・!こまった
という人にうってつけのようです。もちろんブラウザ上で動作します。
その中で、**「SF Film Locations(SF映画のロケ地)」**のデータセットを使用します。
(もちろん、一覧から探して興味のあるカテゴリで練習するのが1番です!)
2.どんなデータを取りたいか設定する
クエリを書く=欲しいデータが具体的に決まっている、という事がほとんどだと思います。
こんなデータ取ってみたいな、を決めてみましょう。
・今回設定されたお題
・ ジョージ・ルーカスの映画
・ ロケ地の多い映画上位30件
・ 配信タイトル数が多い配給会社上位30社
・ 最新の映画10件
・使えるようになりたいキーワード
SELECT・・・取得項目
FROM・・・取得テーブル
WHERE・・・絞り込み条件
ORDER BY・・・並び替え
GROUP BY・・・集計単位
LIMIT・・・取得件数
それでは実際に書いていきます。
3.BigQueryのデータセットページにアクセスする
**「SF Film Locations」**のページにアクセスします。
このデータセットにどんなデータが入っているのか、という説明が書かれています。
「データセットを表示」をクリックし、クエリのエディタを開きましょう。

これがクエリを書くエディタ画面。
san_francisco_film_locationsが選択された状態で開きました。
左のリストでは、他のデータセットを一覧で見ることができます。
bigquery-public-data(プロジェクト名) > san_francisco_film_locations(データセット名)
という階層が左のリストから確認できます。
もし色々クリックして迷子になってしまったら、
リソースの検索にデータセット名(san_francisco_~)を入力してソートすることも可能です。
4.どんなデータが入っているか見てみる
1で述べたとおり、データセットはテーブルの集合体です。
データセット san_francisco_film_locations をクリックして展開してみると、
film_locations というテーブルが入っていることが確認できます。
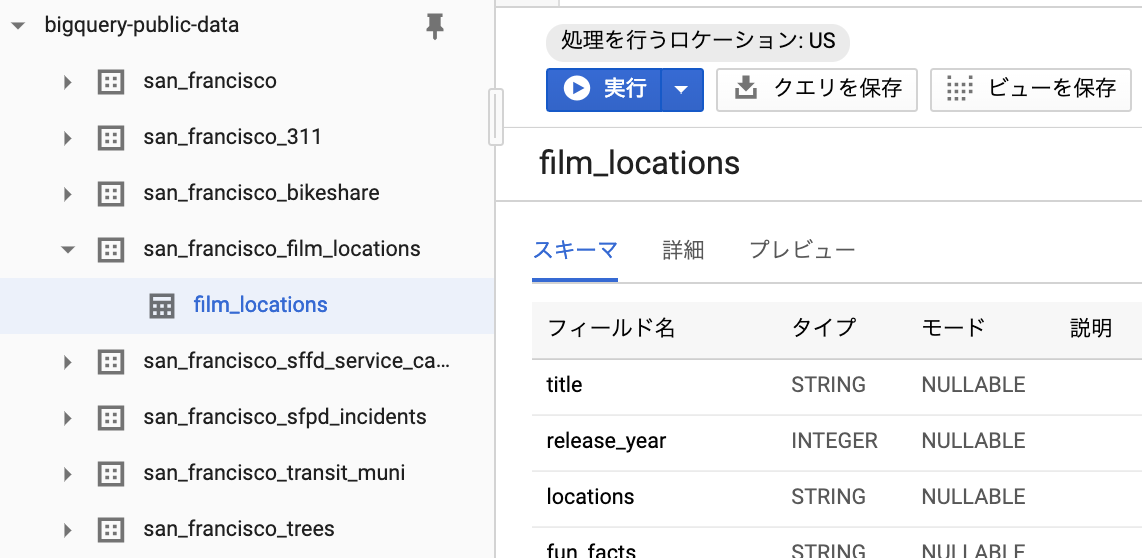
テーブルをクリックで、以下のようなテーブル情報を見ることもできます。
頻繁に使う部分なので、どうやって辿り着くか覚えておくと便利です。
・スキーマ:
フィールド名一覧と、フィールドごとの型(入るデータが文字列なのか、数値なのか など)
・詳細:
テーブルの作成日時、情報 など
・プレビュー:
テーブルに格納されているデータのプレビュー
5.とりあえず取得してみる
まず、基本的なSQLの構文で取得してみます。
SELECT [カラム名] FROM [テーブル名]
に沿ってデータを取得してみます。
最初は構文としてとりあえず全取得してみようという事で、
「*(アスタリスク)」を*SELECT*の後に入れ、テーブル名に film_locations を入力します。
SELECT * FROM film_locations
実行してみると、エラーが出ました。

左のリソース一覧を見るとわかりますが、
自分が複数のプロジェクトにアクセスできる場合、万が一同じテーブル名が存在していたら**どれ?**となる場合もありますよね。
それと同じで、正しいパスを指定してあげて分かりやすくなるように修正します。
--[プロジェクト名].[データセット名].[テーブル名]で記述してみた
SELECT * FROM `bigquery-public-data.san_francisco_film_locations.film_locations`
プロジェクト名はテーブルの詳細→表IDから確認できます。
正しい記述をしたのち、バッククォートで囲んで実行してみます。
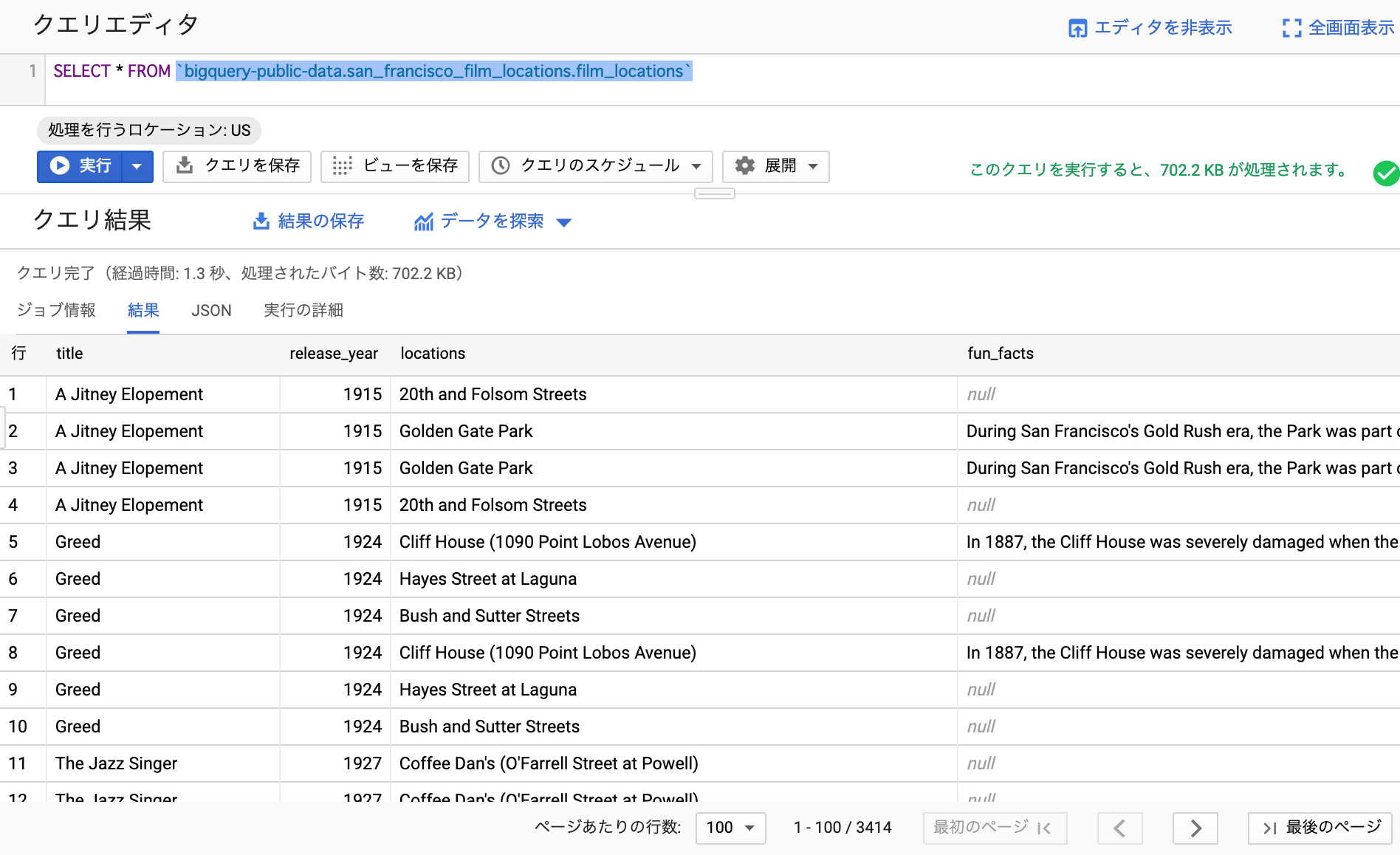
めでたく初取得できました!
6.条件を追加して絞り込む
さらに詳しく文を書いていきます。
2.で設定されたお題に沿ってクエリを書いていきましょう。
冒頭で述べた通り、構文については軽くで触れます。
・ ジョージ・ルーカスの映画を抽出
director のカラムが「ジョージ・ルーカス」の行を抽出します。
SELECT * FROM `bigquery-public-data.san_francisco_film_locations.film_locations`
WHERE director = 'George Lucas'
ジョージの綴りがわからなければ、部分一致で指定することもできます。
しかし、ジョージから始まる director が複数人いたら全部ヒットしてしまうので、注意して使用しましょう。
SELECT * FROM `bigquery-public-data.san_francisco_film_locations.film_locations`
WHERE director LIKE 'George%'
前方一致だと上記の書き方になります。%部分がほにゃららを意味します。
*LIKE*は色んなパターンで一致させられるので、調べてみてくださいね。
ちなみに今回の問題で使用すると、George **という人物が複数人いるので、あくまで綴り確認用に使用すると良いでしょう。
以下、他のお題についても書いてみました。
・ ロケ地の多い映画上位30件
*COUNT*関数を使って指定項目の数をカウントします。
クエリ
SELECT
title
,COUNT(locations)
FROM
`bigquery-public-data.san_francisco_film_locations.film_locations`
GROUP BY
title
実行結果
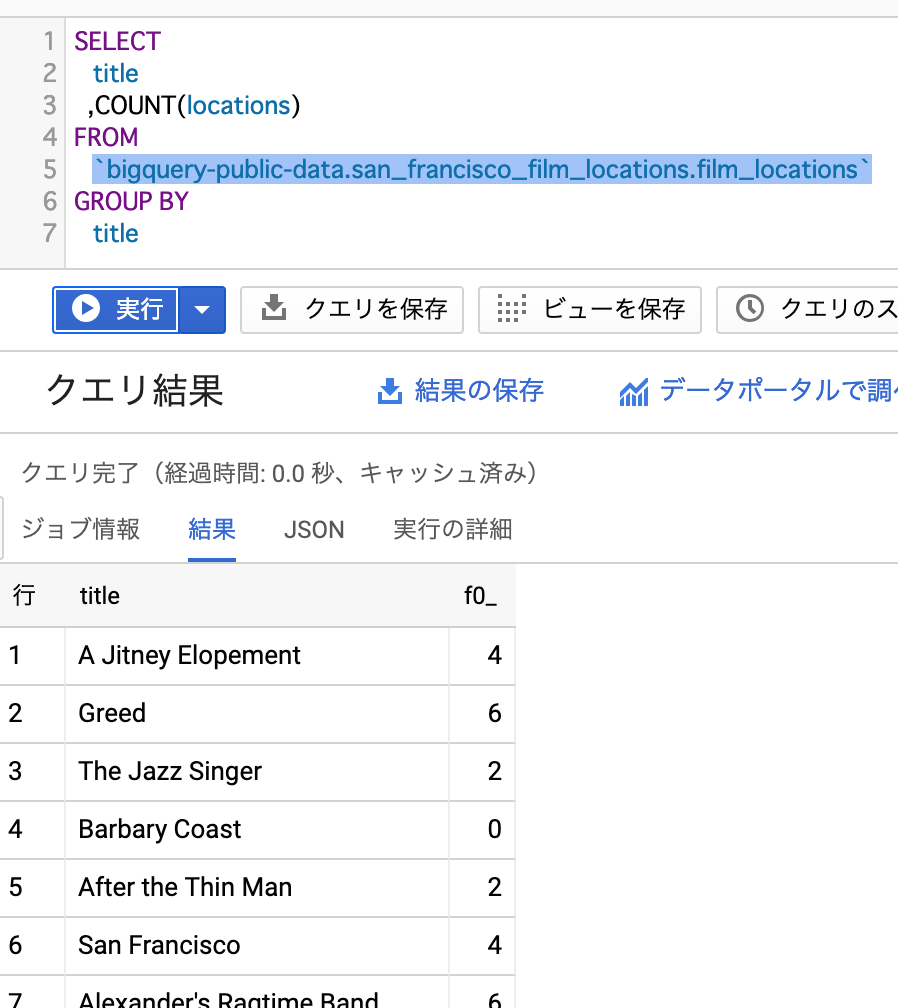
このままだとランキング付けされていないので、*ORDER BY [並び変えたいカラム名]で並び替えます。
デフォルトは昇順です。
今回は降順にしたいのでDESCをカラム名の後に入れます。
また、「f0_」という列名になっているので、AS [列名]*で新しいカラムに名前を付けてあげます。
クエリ
SELECT
title,
COUNT(locations) AS location_count
FROM
`bigquery-public-data.san_francisco_film_locations.film_locations`
GROUP BY
title
ORDER BY
location_count DESC
LIMIT
30
実行結果
30件取れました。

・ 配信タイトル数が多い配給会社上位30社
SELECT
distributor,
COUNT(DISTINCT title) AS title_count
FROM
`bigquery-public-data.san_francisco_film_locations.film_locations`
GROUP BY
distributor
ORDER BY
title_count DESC
LIMIT
30

・ 最新の映画10件
「最新の」:release_year の降順
「映画」:title ごとに1行ずつ
「10件」:LIMIT で10件に制限
SELECT
DISTINCT title,
release_year
FROM
`bigquery-public-data.san_francisco_film_locations.film_locations`
ORDER BY
release_year DESC,
title
LIMIT
10

7.学習まとめ
今回は
BigQueryのデータセットを使ってSQL文を実行する方法、
また、基本的な構文について学びました。
SELECT・・・取得項目
FROM・・・取得テーブル
WHERE・・・絞り込み条件
ORDER BY・・・並び替え
GROUP BY・・・集計単位
LIMIT・・・取得件数
SQL文については、基本の基本な部分は完了となります。
どんなに長いクエリでも、シンプルな記述の集まりです。
何百行もあるクエリを目の前にした時、**こんなの読めない・・・!**と最初は思うものですが、
分解していくと意味がわかるようになります。
BigQueryで練習して慣れてみましょう!
8.さらにやってみて欲しいこと
・可読性を意識する
クエリを読みやすくするために、インデントを追加するなどして見やすくします。

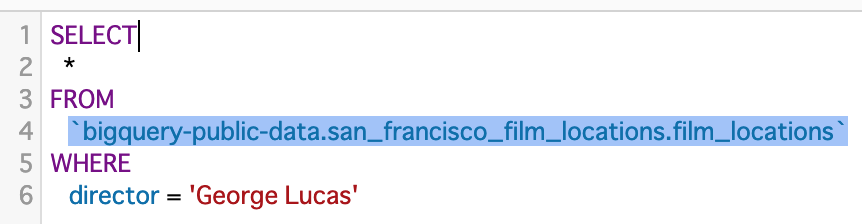
とても見やすいです。
自分で書いたクエリなら中身がわかるのは当然。
ですが、他の人から見ても読みやすい書き方を意識することで、自然と綺麗な書き方ができると思います。
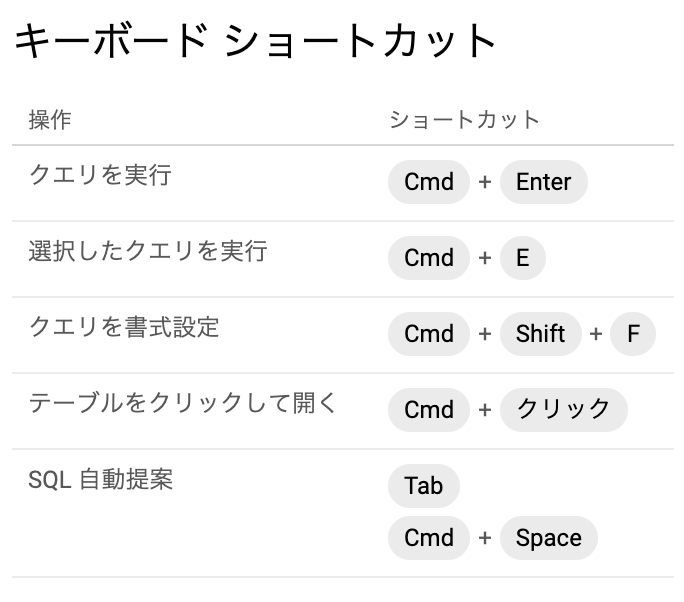
BigQueryでは便利な成形機能があるので、以下のものを使用してみても良いかもしれません。
1.command + shift + F
(「ショートカットメニュー」→「クエリを書式設定」で確認できる)
2.「展開」→「フォーマット」

・コメントを挿入する
BigQueryに限らず、SQL文の中ではコメントを書くことができます。
長いクエリを書いているうちに、分からなくなってきたらコメントで残してみましょう。
これは他の人に向けて読みやすくする為にも使用することがあります。
--ここで全部取ってるよ
SELECT * FROM `bigquery-public-data.san_francisco_film_locations.film_locations`
/*複数行コメントは
こんな感じで*/
9.次のステップは?
次のステップとしては、以下のようなものがあるかなと思います。
・複数テーブルにまたがってSELECTする(JOIN)
・すでにある値からさらに計算する(%や日付の加算・減算)
・条件によって値を分岐(100以上の値ならフラグを立てる)
これらは、用途に合わせた関数を使うことになります。
検索するとたくさんの関数が出てくるので、最初はどれを使えば良いか迷うことも多いはずです。
結果の値がイメージできなければ、とりあえず書いてみる!のをオススメします。
(特に慣れていないと専門用語が多く、結局どれを使えば良い?となるので)
🔰
やってみれば怖くない、とりあえずチャレンジしてみましょう〜!
とても良い練習台でした。
今回も主催の方々、ありがとうございました。