1. はじめに
ClickHouse 社が「Postgres managed by ClickHouse」(ベータ)を発表した公式ブログに、次の一文があります。
Currently, 14 of 22 TPC-H queries are fully pushed down, delivering over 60x performance improvements compared to standard Postgres.
(拙訳: 現時点で 22 本の TPC-H クエリのうち 14 本が完全にプッシュダウンされ、標準的な Postgres と比べて 60 倍以上の性能向上が得られています)
ここで出てくる用語を先に整理します。
- HTAP(Hybrid Transactional/Analytical Processing): 1 つの基盤で、トランザクション処理(OLTP=Online Transaction Processing。注文登録などの細かい更新)と分析処理(OLAP=Online Analytical Processing。集計・分析の重いクエリ)の両方をこなす考え方です
- CDC(Change Data Capture): 変更データキャプチャ。ソース DB(ここでは Postgres)の変更を、別のシステム(ここでは ClickHouse)へ継続的に複製する仕組みです
-
FDW(Foreign Data Wrapper): 外部データラッパー。PostgreSQL から「外部にあるテーブル」をあたかもローカルのテーブルのように参照する仕組みです。
pg_clickhouseはこの FDW を使って ClickHouse のテーブルを Postgres から参照させます - フェデレーテッドクエリ(federated query): 複数の異なるデータベースを横断して、1 つの SQL で扱う方式です。今回は Postgres を入口に、FDW 経由で ClickHouse のデータをそのまま参照します
- プッシュダウン(pushdown): 今回の構成ではPostgres 側で実行するはずだった処理(絞り込み・集計・結合)を、ClickHouse 側で実行させる最適化です。プッシュダウンされる範囲が広いほど、Postgres へ戻すデータ量が減って速くなります
- TPC-H: 分析クエリの定番ベンチマークで、22 本の業務分析クエリから成ります
-
SF(Scale Factor): TPC-H のデータ量を決める倍率です。SF1 はデータ量およそ 1GB(
lineitem約 600 万行)、SF10 はその 10 倍のおよそ 10GB(約 6,000 万行)で、数字が大きいほどデータが増えます
今回は、この「14/22 がプッシュダウン」「最大 60 倍以上」という公式の数字を、自分の手で再現できるかを検証しました。ポイントは、SF1(小)と SF10(大)の 2 つの規模で測ったことです。
検証ゴール
| No | ゴール | 確認方法 |
|---|---|---|
| 1 | 22 本中 14 本が完全プッシュダウンされるか |
EXPLAIN の Remote SQL: でプッシュダウン範囲を分類 |
| 2 | 公式の「最大 60 倍以上」を再現できるか | Postgres 単体経由と ClickHouse 経由(FDW)の実行時間を比較 |
| 3 | データ量(SF)を上げると倍率はどう動くか | SF1 と SF10 で倍率を取り、クエリ別に比較 |
結論(先出し)
- プッシュダウン本数 14/22 は再現できました。これはデータ量(SF)に依存せず、クエリの構造で決まります
- 「60 倍以上」は SF1 では再現せず、SF10 で再現しました。SF1 では ClickHouse 経由が速いのは 8 本だけで、ネットワーク往復や起動のオーバーヘッドが小さいデータでは目立ちます
- データ量を 10 倍にすると、5 本のクエリで倍率が逆転しました(Postgres が速い → ClickHouse が速い)。ClickHouse が有利なクエリは 8 本 → 13 本に増え、最大倍率は q20 で 371 倍に達しました
- つまり公式の数字はデータ量に強く依存します。SF1 だけ見ると過小評価、SF10 で本領が出る、という結果でした
2. 検証環境・構成
2.1. 構成
「Postgres managed by ClickHouse」では、ClickHouse は Postgres に同梱されません。Managed Postgres と ClickHouse Cloud の 2 つのサービスを用意します。両者は次の 2 段階で連携します。
(1) データ複製(CDC): まず Postgres のテーブルを、ネイティブな CDC(ClickPipes)で ClickHouse へ複製しておきます。これは「クエリを投げる前」の準備フェーズです。
(2) クエリ実行(フェデレーテッドクエリ / FDW): クエリ時は、Postgres を入口にして pg_clickhouse の外部テーブル経由で ClickHouse に問い合わせます。複製済みデータに対して分析クエリを投げるフェーズです。
public 経路はローカルテーブルだけで完結し、Postgres の外には出ません。ch 経路だけが FDW 経由で ClickHouse に出ていきます(今回は両サービスとも公開エンドポイント経由=パブリックインターネットで接続しており、PrivateLink などのプライベート接続は使っていません。3.1 章の IP 許可リストもこの前提です)。ただし ch 経路でも、ClickHouse 側でどこまで処理されるか(プッシュダウンの範囲)はクエリの構造で変わり、常に全部がプッシュダウンされるわけではありません(4 章で分類します)。
検証の肝は search_path(参照するスキーマの探索順)の切り替えだけで、同じ 22 本のクエリを 2 経路で実行できるようにした点です。
-
publicスキーマ … Postgres 単体で実行(ベースライン) -
chスキーマ …pg_clickhouseの外部テーブル経由で ClickHouse を参照(処理はクエリに応じて ClickHouse 側にプッシュダウン)
クエリ本文は両経路で完全に同一です。これで「経路の違い」だけを比較できます。
CDC(ClickPipes)の初期ロードは、8 テーブルすべてが Completed になり、lineitem は 59,986,052 行(600 パーティション)が ClickHouse 側へ複製されました。

この構成の位置づけ(透過 HTAP との違い)
本構成は「単一エンジンが行と列を内部で使い分ける」タイプの HTAP(例: Google Cloud AlloyDB の列エンジン、Oracle Database In-Memory)とは異なります。実体は CDC で ClickHouse にデータを複製し、Postgres から FDW(pg_clickhouse)で参照・結合するフェデレーション構成で、考え方としては AWS の RDS/Aurora → Redshift の Zero-ETL に近いものです。
- 本構成で列指向の恩恵を受けるには、外部テーブル(
chスキーマ)を明示的に参照する必要があります。Postgres のローカルテーブルにそのままクエリを投げると行ストアで実行され、ClickHouse 側は使われません。公式ブログも現状は「外部テーブルを作って分析する」モデルと述べ、「トランザクションと分析を適切なエンジンへ自動振り分け(auto-routing)する」ことは今後の改善目標として挙げています。つまり本記事執筆時点(2026 年 6 月/pg_clickhouse0.3)では、透過的な自動ルーティングは提供されていません(将来変わる可能性があります) -
pg_clickhouseの価値は「速さ」より「統合」と認識しています。純粋な分析クエリだけなら ClickHouse を直接参照する方が(FDW の往復ぶん)速くなります。FDW の利点は、Postgres という単一の入口で、OLTP の最新データと ClickHouse の分析データを 1 つの SQL で結合できる点にあると考えてます
2.2. 環境
| 項目 | 値 |
|---|---|
| Managed Postgres | PostgreSQL 17.10(サーバ。SHOW server_version; で確認)、16 vCPU / 64 GB RAM(m8gd.4xlarge 相当)、東京リージョン ap-northeast-1 |
| ClickHouse Cloud | バージョン 25.12、Mini(3 vCPU / 12 GiB RAM)、東京リージョン |
| 拡張 |
pg_clickhouse 0.3(clickhouse_fdw、driver = binary) |
| 複製 | ネイティブ CDC(ClickPipes、初回ロード+増分) |
| ベンチマーク | TPC-H(dbgen / qgen で生成) |
| データ規模 | SF1(lineitem 6,001,215 行)/ SF10(lineitem 59,986,052 行) |
| クライアント | このPC(Windows 11、psql 17.10) |
| 主指標 |
EXPLAIN (ANALYZE, VERBOSE) の Execution Time(サーバ側実行時間、各 3 回平均) |
クライアントは psql でクエリを投げるだけの役割で、実際の処理はサーバ側で行われます。主指標の Execution Time はサーバ側の実行時間なので、クライアントの性能やネットワーク遅延の影響を受けません。
両エンジンのスペックは揃っていません。Postgres 側が 16 vCPU / 64 GB RAM なのに対し、ClickHouse 側は 3 vCPU / 12 GiB RAM(Mini)と、CPU コア数で約 5 倍の差があります。本来ベンチマークはハードウェアを揃えるべきですが、今回はマネージドサービスの既定構成のまま測っています。つまり以下の倍率は「エンジン性能の差」と「ハードウェアの差」が混ざった値です。この前提は考察(6.4 章)で改めて扱います。
参考までに、両サービスの実際の画面です。
-
ClickHouse

-
Managed PostgreSQL

3. セットアップで追加が必要になった設定
ここでは、同じ構成を組むときに追加で必要になった設定を 2 点共有します。どちらも環境固有の話ではなく、同じ構成なら誰でも当たる内容です。公式のどこかに正式な手順があるのかもしれませんが、筆者がチュートリアルをたどった範囲では見つけられず、実機で確かめて判明した点です。
3.1. ClickHouse 側の IP 許可リストに「Postgres の送信元 IP」を追加する
pg_clickhouse のクエリは Postgres サーバ側から ClickHouse へ接続しに行きます。ClickHouse Cloud の IP Access List は「ClickHouse に入ってくる接続(ingress)の送信元 IP」を許可するための機能です。したがってここに登録すべきは、接続してくる側=Managed Postgres の送信元(egress)IP になります。
ここで紛らわしいのが、ClickHouse Cloud が公開している static-ips.json の egress_ips(ap-northeast-1 は 35.73.179.23 / 54.248.225.163 / 54.65.53.160)です。これは ClickHouse 自身が外へ出ていくとき(ClickHouse → 外部)に使う IP で、今回必要な「ClickHouse へ入ってくる接続の許可」とは向きが逆でした。実際、今回 Managed Postgres が使った送信元 IP(後述の画面ではマスク)はこの一覧に含まれておらず、ingress 許可へ別途追加する必要がありました。接続元の IP は、ClickHouse 側の system.processes / system.query_log の address 列で特定できます。
許可漏れがあると、接続は TLS(暗号化通信)の確立段階で弾かれ、OpenSSL error: unexpected eof while reading のように出ます。
最終的には、実際に効いた Managed Postgres の送信元 IP(マスク済み)の 1 件だけを「Specific locations」で許可しています。

この送信元 IP が常に固定なのか、再起動やスケール変更で変わるのかは、今回は確認できていません(ClickHouse Cloud 側のように一覧化された公開情報を、Managed Postgres の egress については見つけられませんでした)。変わる可能性に備えて、PostgreSQL 側の送信元 IP を確認する方法を知っておくと安心です。今回は ClickHouse 側の system.processes(接続元アドレスが見えるシステムテーブル)を FDW 経由で覗いて特定しました。
-- ClickHouse の system.processes を FDW 経由で覗き、現在の送信元 IP を確認する
-- (ch_srv は FDW のサーバ名。セットアップ時に CREATE SERVER 済みの前提)
CREATE SCHEMA IF NOT EXISTS chmeta;
CREATE FOREIGN TABLE chmeta.ch_processes (query text, address text)
SERVER ch_srv OPTIONS (database 'system', table_name 'processes');
SELECT DISTINCT address FROM chmeta.ch_processes; -- 内部 IP 以外のパブリック IP が送信元
3.2. 日付リテラルは「純粋な日付」で渡す
TPC-H のクエリには date '1998-12-01' - interval '90 day' のような日付演算が含まれます。これを Postgres 側でそのまま評価するとタイムスタンプ(1998-09-02 00:00:00)になり、ClickHouse の Date32 型へ変換しようとして次のエラーになります。
Cannot convert string '1998-09-02 00:00:00' to type Date32
対処は単純で、あらかじめ計算した純粋な日付リテラルに置き換えます。今回は元クエリの日付演算を手元で計算し、リテラルへ書き換えました(Before / After)。
-- Before: Postgres では動くが、ClickHouse 委譲時に Date32 変換エラー
WHERE l_shipdate <= date '1998-12-01' - interval '90' day
-- After: あらかじめ計算した純粋な日付リテラルに置換
WHERE l_shipdate <= date '1998-09-02'
該当したのは Q1 / Q4 / Q5 / Q6 / Q10 / Q12 / Q14 / Q15 / Q20 の 9 本でした。
4. プッシュダウンの分類
プッシュダウンされた範囲は、EXPLAIN (ANALYZE, VERBOSE) の出力にある Remote SQL: 行で判定できます。これは「pg_clickhouse が実際に ClickHouse へ送った SQL」です。ここに集計や結合まで含まれていれば「完全プッシュダウン」、素の列取得しか含まれていなければ「プッシュダウンなし」、その中間が「部分プッシュダウン」です。
判定の結果、完全プッシュダウンは 22 本中 14 本で、公式の数字と一致しました。この本数は SF1 でも SF10 でも変わりません(クエリ構造で決まるため)。
4.1. 完全プッシュダウンの例(Q1・Q6)
Q1 は集計とグループ化、並び替えまで丸ごと ClickHouse 側にプッシュダウンされています。
-- Q1 の Remote SQL(集計・GROUP BY・ORDER BY までプッシュダウン)
SELECT l_returnflag, l_linestatus,
sum(l_quantity), sum(l_extendedprice),
sum((l_extendedprice * (1 - l_discount))),
sum(((l_extendedprice * (1 - l_discount)) * (1 + l_tax))),
avg(l_quantity), avg(l_extendedprice), avg(l_discount), count(*)
FROM "default".lineitem
WHERE ((l_shipdate <= '1998-09-02'))
GROUP BY l_returnflag, l_linestatus
ORDER BY l_returnflag ASC NULLS LAST, l_linestatus ASC NULLS LAST
Q6 はさらにシンプルで、単一の合計値だけを返します。Postgres へ戻るのは 1 行だけです。
-- Q6 の Remote SQL(フィルタ+集計をプッシュダウン、戻りは 1 行)
SELECT sum((l_extendedprice * l_discount))
FROM "default".lineitem
WHERE ((l_shipdate >= '1994-01-01')) AND ((l_shipdate < '1995-01-01'))
AND ((l_discount >= 0.05)) AND ((l_discount <= 0.07))
AND ((l_quantity < 24))
4.2. 部分プッシュダウンの例(Q19・Q22)
一方、相関サブクエリ(外側の行ごとに内側を評価する構造)を含むクエリは、内側が 行ごとにパラメータ化された Remote SQL として ClickHouse へ繰り返し送られます。下は Q22 の一部です。{p1:Decimal} がパラメータで、外側の行のたびに値が変わります。
-- Q22 の Remote SQL(パラメータ {p1} 付き=外側の行ごとに評価)
SELECT c_custkey, c_phone, c_acctbal
FROM "default".customer
WHERE ((c_acctbal > {p1:Decimal}))
AND ((substringUTF8(c_phone, 1, 2) IN ('13','31','23','29','30','18','17')))
ORDER BY substringUTF8(c_phone, 1, 2) ASC NULLS LAST
このタイプは、ネットワーク往復が多発するため FDW 経由だと不利になりやすく、後述のとおり Postgres 単体の方が速いままでした。
5. 計測結果
Postgres 単体(pg)と ClickHouse 経由(chfdw、FDW)の実行時間を、SF1 と SF10 で各 3 回ずつ計測しました。下表の 倍率は「Postgres ÷ ClickHouse」 で、1.00 を超えると ClickHouse の方が速いことを意味します。
5.1. SF1 ↔ SF10 クロスオーバー表
| クエリ | SF1 倍率 | SF10 倍率 | 挙動 |
|---|---|---|---|
| q01 | 1.81 | 3.27 | ClickHouse 有利が拡大 |
| q02 | 3.67 | 59.44 | ClickHouse 急拡大(≒公式 60 倍) |
| q03 | 0.50 | 2.50 | ★逆転 Postgres→ClickHouse |
| q04 | 0.16 | 0.50 | Postgres 有利(差は縮小) |
| q05 | 1.23 | 4.95 | ClickHouse 有利が拡大 |
| q06 | 0.46 | 1.56 | ★逆転 Postgres→ClickHouse |
| q07 | 3.40 | 3.17 | ClickHouse 有利(ほぼ横ばい) |
| q08 | 0.07 | 0.17 | Postgres 有利 |
| q09 | 0.56 | 1.13 | ★逆転 Postgres→ClickHouse |
| q10 | 0.32 | 0.78 | Postgres 有利(差は縮小) |
| q11 | 1.05 | 24.69 | ClickHouse 急拡大 |
| q12 | 0.80 | 1.95 | ★逆転 Postgres→ClickHouse |
| q13 | 0.90 | 1.39 | ★逆転 Postgres→ClickHouse |
| q14 | 0.27 | 0.69 | Postgres 有利(差は縮小) |
| q15 | 0.34 | 0.47 | Postgres 有利 |
| q16 | 0.22 | 0.23 | Postgres 有利(横ばい) |
| q17 | 18.01 | 89.62 | ClickHouse 有利が拡大 |
| q18 | (timeout) | (timeout) | 両経路とも 300 秒で打ち切り |
| q19 | 0.04 | 0.06 | Postgres 有利(強) |
| q20 | 18.82 | 371.45 | ClickHouse 急拡大 |
| q21 | 1.42 | 1.80 | ClickHouse 有利が拡大 |
| q22 | 0.06 | 0.10 | Postgres 有利(強) |
q18 は SF1・SF10 とも、Postgres 単体・ClickHouse 経由の両経路で 300 秒の上限に達し、打ち切りました。
5.2. 逆転した 5 本(クロスオーバー)
SF1 では Postgres が速かったのに、SF10 で ClickHouse が逆転したのは次の 5 本です。実行時間(ミリ秒、3 回平均)も併記します。
| クエリ | SF1: Postgres | SF1: ClickHouse | SF1 倍率 | SF10: Postgres | SF10: ClickHouse | SF10 倍率 |
|---|---|---|---|---|---|---|
| q03 | 285.5 | 574.9 | 0.50 | 6942.0 | 2773.1 | 2.50 |
| q06 | 172.4 | 378.5 | 0.46 | 2412.5 | 1542.6 | 1.56 |
| q09 | 759.7 | 1368.7 | 0.56 | 9482.5 | 8370.4 | 1.13 |
| q12 | 362.2 | 454.8 | 0.80 | 2848.2 | 1463.4 | 1.95 |
| q13 | 973.8 | 1079.7 | 0.90 | 16174.2 | 11607.7 | 1.39 |
SF1 では ClickHouse 経由の実行時間がほぼ一定(数百ミリ秒)なのに対し、Postgres はデータ 10 倍でほぼ素直に 10 倍前後に伸びています。Postgres 側の伸び方が急なため、ある規模で追い抜かれる——これがクロスオーバーの正体です。
クロスオーバー組の 1 つ Q6 を、SF10 の実機で両経路の EXPLAIN (ANALYZE, VERBOSE) を並べてみます。
-- ClickHouse 経由(search_path=ch,public)
Foreign Scan (actual time=1350.044..1350.046 rows=1 loops=1)
Relations: Aggregate on (lineitem)
Remote SQL: SELECT sum((l_extendedprice * l_discount)) FROM "default".lineitem
WHERE ((l_shipdate >= '1994-01-01')) AND ((l_shipdate < '1995-01-01'))
AND ((l_discount >= 0.05)) AND ((l_discount <= 0.07)) AND ((l_quantity < 24))
Execution Time: 1363.782 ms
-- Postgres 単体(search_path=public)
Finalize Aggregate (actual time=2465.617..2471.591 rows=1 loops=1)
-> Gather (Workers Planned: 2, Workers Launched: 2)
-> Parallel Index Scan using idx_lineitem_shipdate on public.lineitem
(actual time=96.856..2408.432 rows=379755 loops=3)
Rows Removed by Filter: 2653300
Execution Time: 2484.277 ms
ClickHouse 側は集計を丸ごとプッシュダウンし、戻りは 1 行だけ(Execution Time: 1363.782 ms)。Postgres 側は 2 ワーカーで並列インデックススキャンしつつ約 265 万行を Filter で捨てており(Execution Time: 2484.277 ms)、この 1 回でも約 1.8 倍 ClickHouse が速い結果でした。SF1 では逆(Postgres が速い)だったクエリが、SF10 で立場を入れ替えています。
5.3. 「60 倍以上」はどこで出たか
公式の「最大 60 倍以上」は、SF1 では現れませんでした(SF1 の最大は q20 の 18.82 倍)。SF10 で再現しています。
| クエリ | SF10 倍率 | 補足 |
|---|---|---|
| q20 | 371.45 | 相関サブクエリだが集計が ClickHouse 側で完結 |
| q17 | 89.62 | 平均値計算が重く、列指向が効く |
| q02 | 59.44 | 公式「60 倍」に最も近い |
| q11 | 24.69 | 結合+集計の完全プッシュダウン |
5.4. 逆転しなかった Postgres 有利のクエリ
逆に、SF を上げても Postgres が速いままだったのが q08 / q16 / q19 / q22 です。倍率はほとんど動きませんでした(例: q19 は 0.04 → 0.06、q22 は 0.06 → 0.10)。これらは 4.2 章で見た部分プッシュダウンで、相関サブクエリのために ClickHouse へ多数の往復が発生するタイプです。
6. 考察
6.1. 倍率の逆転は「プッシュダウンの有無」ではなく「規模」で決まる
完全プッシュダウン本数 14/22 は SF1・SF10 で不変でした。一方で倍率は SF1 と SF10 で大きく動き、5 本(q03 / q06 / q09 / q12 / q13)が逆転しました。つまり 「プッシュダウンされるかどうか」と「速いかどうか」は別軸 です。
SF1 ではクロスオーバー組の ClickHouse 側実行時間が数百ミリ秒で、Postgres 側(数百ミリ秒)と拮抗します。SF10 では Postgres 側が約 10 倍に伸びる一方、ClickHouse 側の伸びは緩やかでした(例: q03 は Postgres 285→6942ms に対し ClickHouse 575→2773ms)。
この差は、ClickHouse 経由にはデータ量に比例しない固定費(ネットワーク往復、Mini インスタンスの起動・スケジューリング)が乗っており、小規模ではその固定費が支配的、大規模では列指向スキャンと集計の優位が固定費を上回るため、と考えられます。固定費そのものの内訳は本検証では分解できていないため、要追加検証です。
6.2. 部分プッシュダウンでは Postgres 有利が動かない
q08 / q16 / q19 / q22 は SF を上げても倍率がほぼ動かず、Postgres 有利のままでした。これらの Remote SQL: は、相関サブクエリが {p1:...} のようにパラメータ化され、外側の行ごとに ClickHouse へ送られる形でした(4.2 章)。
行ごとの往復回数がデータ量とともに増えるため、ClickHouse の列指向の利点よりネットワーク往復の累積が支配的になり、規模を上げても逆転しにくいと考えられます。
6.3. 公式の数字の読み方
ClickHouse のブログ「Fast, scalable, enterprise-grade Postgres natively integrated with ClickHouse」は「14/22 が完全プッシュダウン」「最大 60 倍以上」と述べています。
本検証では 14/22 は再現、「60 倍以上」は SF10 の q02(59.44 倍)で実質再現し、q17・q20 ではそれを上回りました。一方で SF1 では最大 18.82 倍にとどまりました。
したがって公開数値はある程度のデータ規模を前提にした最大値であり、小規模データでは再現しないと考えられます。再現検証では最低 2 つの規模で倍率の動きを見るのが妥当です。
6.4. 倍率には「ハードウェアの差」も含まれる(重要な前提)
2.2 章で触れたとおり、本検証の Postgres(16 vCPU / 64 GB RAM)と ClickHouse(3 vCPU / 12 GiB RAM)はスペックが揃っていません。したがって本記事の倍率は、エンジンの差とハードウェアの差が混ざった値です。この点を割り引いて読む必要があります。
ただし、この非対称はむしろ ClickHouse 側に不利な条件です。
- ベンチマーク実行中、ClickHouse の CPU 使用率は上限の 3 コアに張り付いていました(下図)。ClickHouse は計算資源を使い切って頭打ちになっており、Postgres(16 コア)の方が CPU 的には余裕があります
- それでも SF10 では ClickHouse が 13 本で速く、最大 371 倍(q20)でした
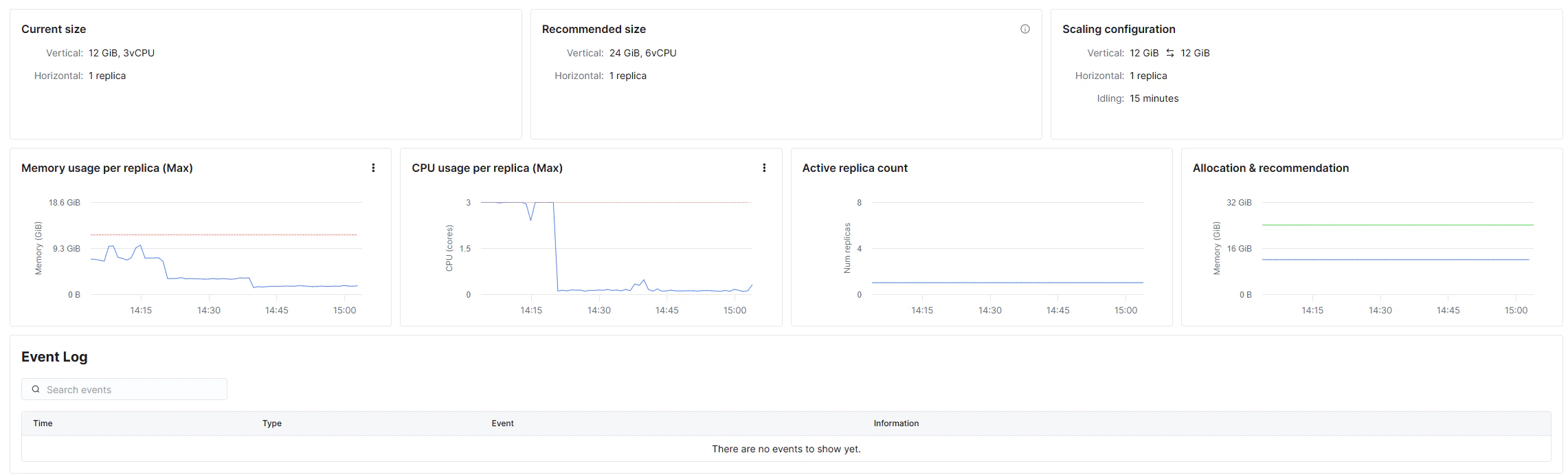
CPU コア数で約 5 倍不利な ClickHouse が、大規模データで Postgres を上回ったという結果は、列指向ストレージとプッシュダウンの効率を保守的な条件で示せたものと考えられます。仮にハードウェアを揃えれば、ClickHouse 側の倍率はさらに広がる可能性があります。
逆に言えば、SF1 で ClickHouse が振るわなかったのは「小さい箱だから」ではなく、6.1 章で述べた固定オーバーヘッドが小データでは相対的に大きいためと考えられます。スペック差だけでは SF1→SF10 の倍率逆転を説明できません。
7. まとめ
| 観点 | 結論 |
|---|---|
| プッシュダウン本数 | 14/22 が完全プッシュダウン(公式どおり、SF 非依存) |
| 「60 倍以上」 | SF1 では再現せず、SF10 で再現(q02 59 倍、q20 371 倍) |
| データ量の影響 | SF1→SF10 で 5 本が逆転、ClickHouse 有利が 8→13 本に増加 |
| 効くクエリ | 集計・結合を丸ごとプッシュダウンでき、かつデータが大きいもの |
| 効きにくいクエリ | 相関サブクエリで行ごとに往復する部分プッシュダウン(q08/q16/q19/q22) |
| 前提(要注意) | Postgres 16 vCPU vs ClickHouse 3 vCPU とスペック非対称。倍率はハード差を含む(ClickHouse 側に不利な条件での結果) |
pg_clickhouse は「大規模で、集計・結合が重い分析クエリ」で本領を発揮します。小規模データだけで評価すると、固定オーバーヘッドに埋もれて効果を見誤ります。導入を検討する際は、自分の代表クエリを、実データに近い規模で測るのが結論です。