前回、日本の古文書で機械学習を試す(6)で作ったCNNのモデルの精度を上げるため、ニューラルネットワークの層構造を色々いじってみる。層構造は、[日本の古文書で機械学習を試す(1)から前回までずっと、人文学オープンデータ共同利用センターからダウンロードしたサンプルプログラムのまま(=KerasのMNISTサンプルのまま)だった。
調整前の層構造
サンプルのプログラムの層構造はこうなっている。
input_shape = (img_rows, img_cols, 1)
nb_filters = 32
kernel_size = (3, 3)
pool_size = (2, 2)
model = Sequential()
model.add(Conv2D(nb_filters, kernel_size, # 畳み込み層
padding='valid',
input_shape=input_shape))
model.add(Activation('relu')) # 活性化関数
model.add(Conv2D(nb_filters, kernel_size)) # 畳み込み層
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=pool_size)) # プーリング層
model.add(Dropout(0.25)) # ドロップアウト層
model.add(Flatten()) # 多次元配列を1次元配列に変換
model.add(Dense(128)) # 全結合層
model.add(Activation('relu'))
model.add(Dropout(0.5)) # ドロップアウト層
model.add(Dense(nb_classes)) # 全結合層
model.add(Activation('softmax'))
まだ理解が不十分だが、各層の役割は、初心者的には以下のように理解した。
畳み込み層(Conv2D)がCNNのキモの部分で、画像の左上端から右下端まで、kernel_sizeのフィルタをかけながら、画像の特徴を抽出する。nb_filtersはフィルタの数=抽出する特徴の数を表すパラメーター。
プーリング層は画像を縮小して詳細を消し、特徴部分だけを目立たせる処理。
ドロップアウト層は過学習防止のため、入力と出力の間をランダムに切断する。数字は切断する割合を表す。
全結合層は複数の中間ノードからのデータを1つの数値にまとめて出力する。
活性化関数は1つ前の層からの出力結果を0~1の間の値に割り当てるもの。ソフトマックス関数、シグモイド関数、ReLUなどを指定する。(各関数の内容はネットで調べると分かりやすいサイトがたくさん出てくるので省略。) これは前の層の引数としてまとめて書くこともできるようで、そのほうがスッキリするので、この後は、引数として指定することにした。
何を変えるか
各層の特徴を調べてみたところで、どこをどう変えたら精度が良くなるのか分からなかったので、手あたり次第に試すことにした。
- サンプルでは畳み込み層-畳み込み層-プーリング層だが、TensorFlowで学ぶディープラーニング入門 という本では、畳み込み層-プーリング層-畳み込み層-プーリング層という構成になっていたので、プーリング層を足してみる。
- 畳み込み層を追加してみる。(抽出できる特徴の種類が増えるかも?)
- 畳み込み用のフィルターの数 nb_filter を増やしてみる(抽出できる特徴の種類が増えるかも?)
- ドロップアウトの割合を小さくしてみる(過学習している感じがしなかったので)
- 畳み込み用のフィルターサイズkernel_sizeを大きく/小さくしてみる
- プーリングサイズpool_sizeを大きくしてみる(元が2なので小さくはできない)
乱数の種を固定
まず、再現性を確保するため、Kerasのマニュアルを参考にして、乱数の種を固定する関数を作る。学習の前に必ずこの関数を呼び出すようにする。
# 再現性を得るための設定をする関数を定義
import tensorflow as tf
import random
import os
def set_reproducible():
os.environ['PYTHONHASHSEED'] = '0'
np.random.seed(1337)
random.seed(1337)
session_conf = tf.ConfigProto(intra_op_parallelism_threads=1, inter_op_parallelism_threads=1)
tf.set_random_seed(1337)
sess = tf.Session(graph=tf.get_default_graph(), config=session_conf)
K.set_session(sess)
モデルを作って学習
パラメータを変えたモデルをひたすら作って学習させてみる。学習、テストデータは日本の古文書で機械学習を試す(6)で作成した「好色一代男」のデータを用いる。エポック70だと時間がかかるので、今回は40に減らした。2つの畳み込み層の間にプーリング層を追加したモデルのコードを例示する。(コード中の_kは「好色一代男」の頭文字)
batch_size = 32
epochs = 40
input_shape = (img_rows, img_cols, 1)
nb_filters = 32 # 畳み込みのフィルタ数
pool_size = (2, 2) # プーリングサイズ
kernel_size = (3, 3) # 畳み込みのカーネルサイズ
# 【モデル定義】
model_k2 = Sequential()
model_k2.add(Conv2D(nb_filters, kernel_size, # 畳み込み層
padding='valid',
activation='relu',
input_shape=input_shape))
############ 追加ここから
model_k2.add(MaxPooling2D(pool_size=pool_size)) # プーリング層
############# 追加ここまで
model_k2.add(Conv2D(nb_filters, kernel_size, activation='relu')) # 畳み込み層
model_k2.add(MaxPooling2D(pool_size=pool_size)) # プーリング層
model_k2.add(Dropout(0.25)) # ドロップアウト
model_k2.add(Flatten()) # 多次元配列を1次元配列に変換
model_k2.add(Dense(128, activation='relu')) # 全結合層
model_k2.add(Dropout(0.5)) # ドロップアウト
model_k2.add(Dense(nb_classes_k, activation='softmax')) # 全結合層
model_k2.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 【各エポックごとの学習結果を生成するためのコールバックを定義(前回より精度が良い時だけ保存)】
from keras.callbacks import ModelCheckpoint
import os
model_checkpoint_k2 = ModelCheckpoint(
filepath=os.path.join('layer_models','model_k2_{epoch:02d}_{val_acc:.3f}.h5'),
monitor='val_acc',
mode='max',
save_best_only=True,
verbose=1)
# 【学習】
set_reproducible() # 乱数の種を固定する関数
result_k2 = model_k2.fit(X_train_k, Y_train_k, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(X_test_k, Y_test_k),
callbacks=[model_checkpoint_k2])
# 【テストデータに対して信頼度を表示】
score = model_k2.evaluate(X_test_k, Y_test_k, verbose=1)
print('K2 Test score:', score[0])
print('K2 Test accuracy:', score[1])
学習経過をプロット
プーリング層追加、畳み込み層追加、ドロップアウト減少の学習経過(val_acc、テストデータに対する精度)をプロットしてみた。プロット用のコードは前回までと同じなので省略する。
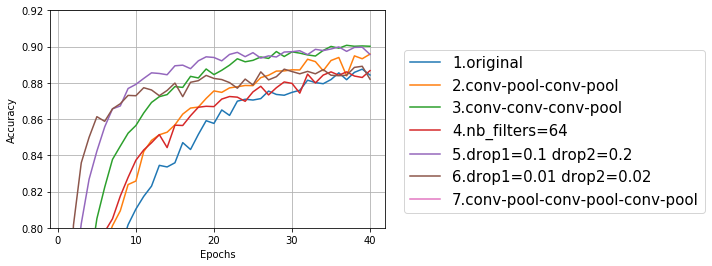
プロットしてみた結果、3の畳み込み3層にしたものと、5のドロップアウトを少し小さくしたものが良さそうだ。これらをベースにもう少し調整してみる。
8~14は、1回目のドロップアウトを0.1、2回目のドロップアウトを0.2に固定して、畳み込み層とプーリング層の組み合わせを変えた。8~11は畳み込み3層、12~14は畳み込み4層。
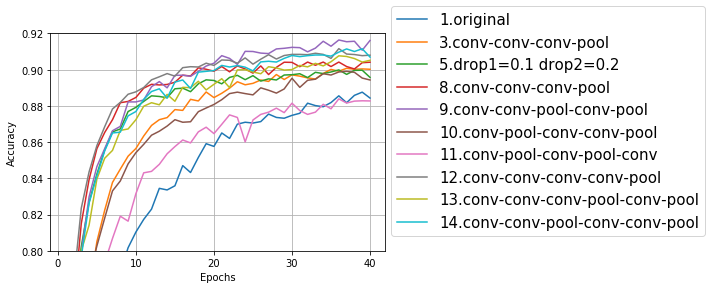
畳み込み4層のモデルも悪くはないが、一番良さそうなのは9の畳み込み3層プーリング2層のモデルだった。
次は層を9番の畳み込み-畳み込み-プーリング-畳み込み-プーリングに固定して、ドロップアウトの数字を細かくいじってみた。
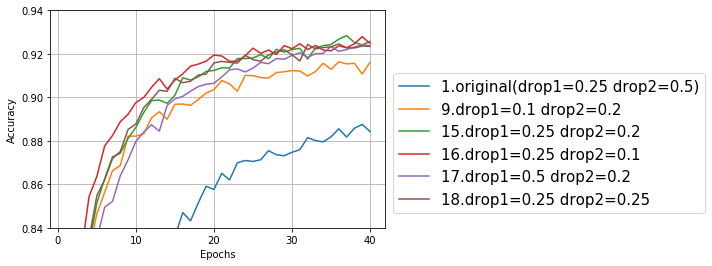
このグラフでは精度が上がってきたため、先ほどまでとは縦軸の目盛り範囲が異なっている。15~18は大差ないような気もするが、テストデータで最高精度を記録したのは15のdrop1=0.25(デフォルトと同じ)、drop2=0.2(デフォルトより小)だった。
最後に、15をベースにカーネルサイズ、プーリングサイズを変えてみる。
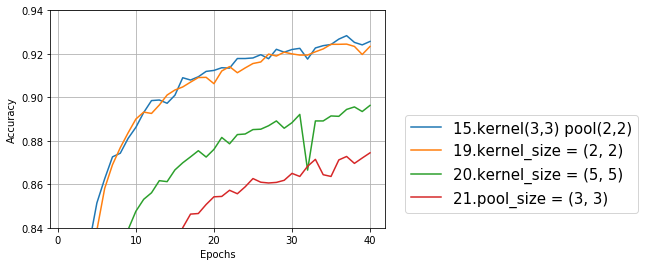
あれ?畳み込みってカーネルの真ん中のデータを、周囲のデータを使って書き換えるものだから、カーネルサイズって奇数じゃないといけないんだっけ?でも(1,1)だとさらに意味不明なので、(2,2)と(5,5)で試してみた。なぜか(2,2)は(3,3)とあまり変わらない結果だったが、元のカーネルサイズ(3,3)の精度は超えられなかった。今までの最高精度は、モデル15のエポック37の0.928だ。
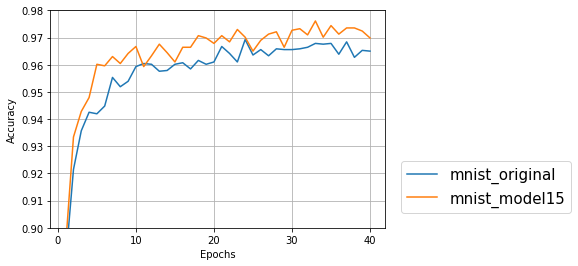
サンプルプログラムの10文字を判別するデータでも、モデル15で精度が上がるのか試してみた。サンプルデータでも少しだが精度が良くなっていた。
一番良かったモデルをRNNと組み合わせ
だんだんお約束となりつつあるCNN+RNNで、精度が上がるかチェック。RNNのモデルは、前回日本の古文書で機械学習を試す(6)で保存したものを使おうと思ったが、最初に血迷って学習データとテストデータを分ける乱数の種を前回と違うものにしてしまったので、新しい学習用データでRNNのモデルを作り直した。(前回学習用データとして使ったものが、今回テストデータに入ってしまうと、精度が上がったように見えてしまうため。) RNNのモデル自体は前回と同様なのでコードは省略。RNNについてもパラメータをチューニングするともう少し精度が上がるのかもしれないが、時間がないので今回はやめておく。
# 【CNN+RNNで正解率を出す】
from keras.models import load_model
model_cnn = load_model('layer_models/model_k14_37_0.928.h5')
model_rnn_row = load_model('layer_models/model_k_rnn_33_0.897.h5')
model_rnn_col = load_model('layer_models/model_k_rnn2_33_0.900.h5')
# RNN用のデータを生成
X_test_RNN = X_test_k.reshape(len(X_test_k), img_rows, img_cols)
X_test_RNN_Trans = X_test_RNN.transpose(0, 2, 1)
# CNNとRNN2種類の加算で精度チェック
miss_count1 = 0
miss_count2 = 0
miss_count3 = 0
for i, x in enumerate(X_test_k):
# 正解データ
correct_index = np.where(Y_test_k[i] == True)[0][0] # データがTrueになっている箇所のインデックス
# 各モデルで判別結果のベクトルを求める
preds_cnn = model_cnn.predict(np.array([x]))
preds_rnn_row = model_rnn_row.predict(np.array([X_test_RNN[i]]))
preds_rnn_col = model_rnn_col.predict(np.array([X_test_RNN_Trans[i]]))
# ベクトルを加算
preds1 = (preds_cnn + preds_rnn_row + preds_rnn_col) / 3
preds2 = (preds_cnn + preds_rnn_row*0.5 + preds_rnn_col*0.5) / 2
preds3 = (preds_cnn*2 + preds_rnn_row*0.5 + preds_rnn_col*0.5) / 3
## どの文字かを判別する
pred_index1 = preds1.argmax() # 確率の一番高い文字の番号
pred_index2 = preds2.argmax()
pred_index3 = preds3.argmax()
# 間違っている場合にインクリメント
if pred_index1 != correct_index:
miss_count1 = miss_count1 + 1
if pred_index2 != correct_index:
miss_count2 = miss_count2 + 1
if pred_index3 != correct_index:
miss_count3 = miss_count3 + 1
print("正解率1 ", 1-miss_count1/len(X_test_k))
print("正解率2 ", 1-miss_count2/len(X_test_k))
print("正解率3 ", 1-miss_count3/len(X_test_k))
CNNとRNNの重みづけを変えて3パターン試した。結果は以下のようになった。
正解率1 0.9436445543679887
正解率2 0.9431145658510732
正解率3 0.9380796749403763
CNN、RNN(横)、RNN(縦)のそれぞれ単体での精度は0.928、0.897、0.900なので、組み合わせると単体より高い数値が出た。CNN、RNN(横)、RNN(縦)の3つを単純に足した1番目のパターンが一番精度が良かった。日本の古文書で機械学習を試す(5)のMNISTのときは、2番目のほうが精度が良かったのだが、データとモデルが変わると違う結果が出た。
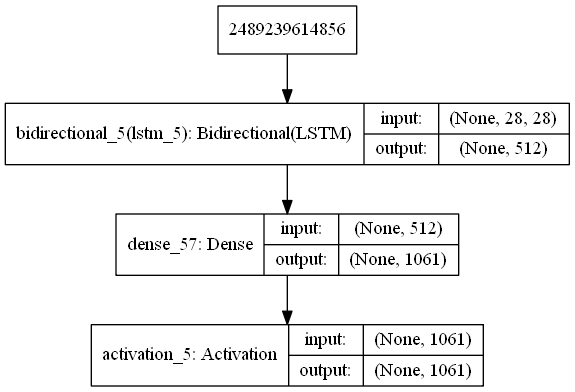
モデルの可視化
最後に、読み込んだモデルを可視化してみた。
from keras.utils import plot_model
plot_model(model_cnn, show_shapes=True, to_file='model.png')
importのところで、pydotがないというエラーが出たので、
> conda install pydot
でpydotを入れてから再度実行すると、model.pngに次のような画像が保存された。
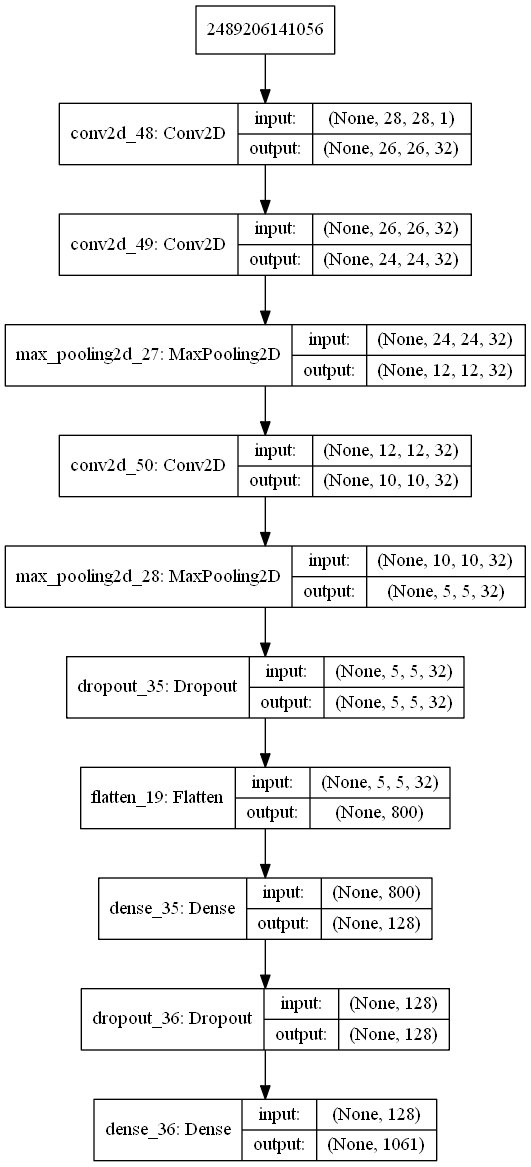
RNNのモデルはもっとシンプル。しかし、入力層?の最初の数字は何だろう?