サンプルプログラムのMNISTは10文字のみの判別だが、この文字数を増やすことを考える。データは日本の古文書で機械学習を試す(4)で人文学オープンデータ共同利用センターの日本古典籍くずし字データセットからダウンロードした「好色一代男」を使う。
学習用データ、テスト用データを作成する
まずは、ダウンロードした「好色一代男」の文字データから、サンプルプログラムと同じ形式(numpyのarray)の学習用データ、テスト用データを作成する。
ダウンロードしたファイルを解凍すると、charactersフォルダの下に、文字コードごとのフォルダがあり、その中に文字の画像が保存されている。このデータを読み出して、numpyのarrayに格納するコードを書く。
1回しか出てこない文字を学習させても意味がないので、
・文字画像が3個以上入っている文字コードのみを対象にする。
・各文字コードの画像のうち、80%を学習用データ、20%をテスト用データとする。ただし、各文字コードでテスト用データが最低1個入るようにする。
・読み込んだ画像のうち、どれを学習用にしてどれをテスト用にするかは乱数で決定する。
という方針でデータを作成した。
また、各文字コードに番号をふって、正解データは番号で表現しているが、後でどの番号が何の文字かを確認するために、対応関係を200003076chars.csvというファイルに書き出した。
# 【ダウンロードした「好色一代男」の文字画像データをすべて読み込んでデータ化】
import glob, os, random
from keras.utils import np_utils
import numpy as np
np.random.seed(0) # 乱数の種を固定(学習データとテストデータに分割するため)
img_root = "../200003076/characters/*"
img_rows = 28
img_cols = 28
X_train = []
X_test = []
Y_train = []
Y_test = []
nb_classes = 0
mark = ""
file = open('200003076chars.csv', 'w')
chars = glob.glob(img_root) # 画像のルートディレクトリ内のファイル/ディレクトリ一覧
for char in chars:
if os.path.isdir(char) and len(glob.glob(char+"/*.jpg")) >= 3: # ディレクトリ内に画像ファイルが3個以上あれば
img_files = glob.glob(char+"/*.jpg")
test_count = int(len(img_files) * 0.2) # 1文字種のデータ数の20%をテストデータとする(最低1文字種に1個)
if test_count == 0:
test_count = 1
test_indexes = np.random.randint(0, len(img_files), test_count) # 何個目のファイルをテストデータにするかを乱数で選択
for img_index, img_file in enumerate(img_files): # ディレクトリ(文字種)ごとのファイル一覧取得
x = img_to_traindata(img_file, img_rows, img_cols) # 各画像ファイルを読み込んで行列に変換
if img_index in test_indexes: # テスト用データ
X_test.append(x)
Y_test.append(nb_classes)
mark="test"
else: # 学習用データ
X_train.append(x)
Y_train.append(nb_classes)
mark="train"
file.write(str(nb_classes) + "," + os.path.basename(char) + "," + str(len(img_files)) + "," + str(len(img_files)-test_count) + "," + str(test_count) + "\n") # 文字種ごとのインデックス、文字コード、ファイル数、学習、テストデータ数をファイル書き出し
nb_classes = nb_classes + 1 # 判別文字種数をインクリメント
file.close()
# listからnumpy.ndarrayに変換
X_train = np.array(X_train, dtype=float)
X_test = np.array(X_test, dtype=float)
Y_train = np.array(Y_train, dtype=float)
Y_test = np.array(Y_test, dtype=float)
# 文字種を表す数字をカテゴリカルデータ(ベクトル)に変換
Y_train = np_utils.to_categorical(Y_train, nb_classes)
Y_test = np_utils.to_categorical(Y_test, nb_classes)
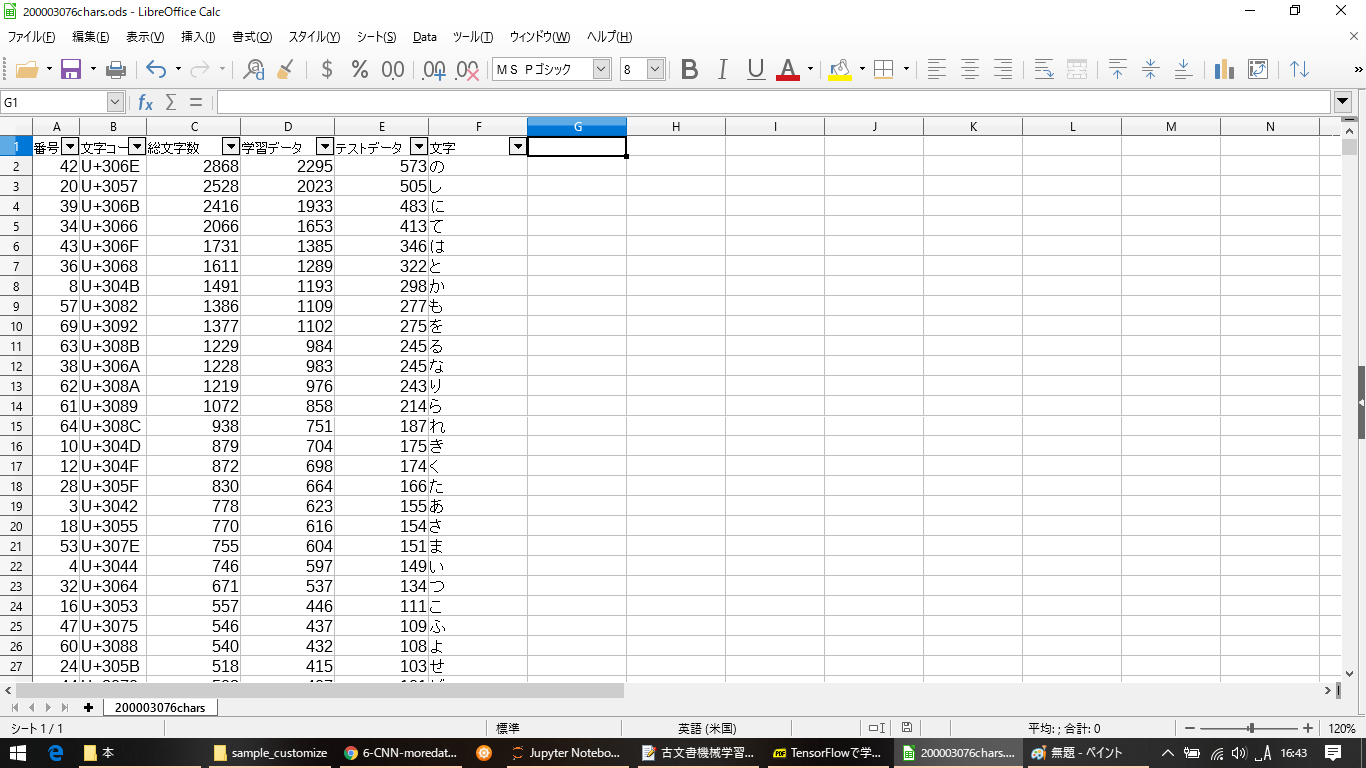
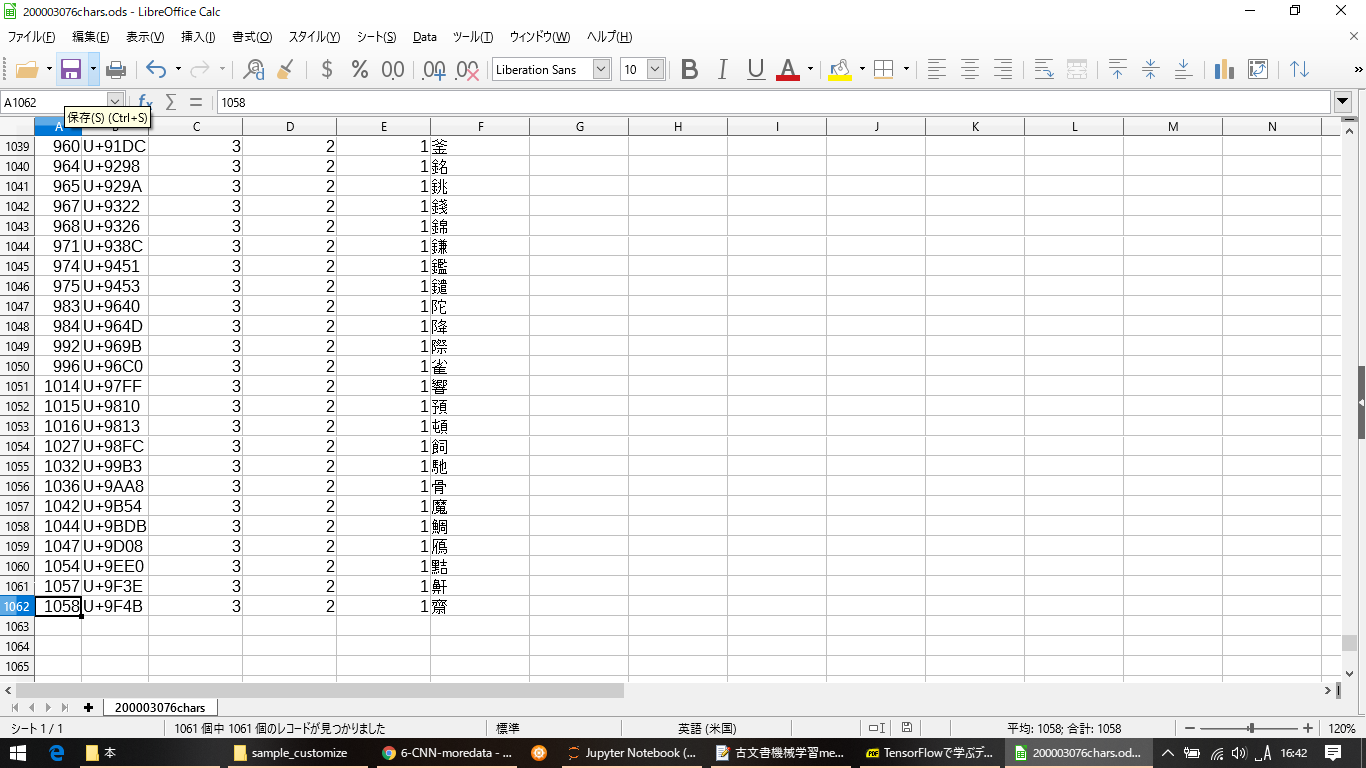
全部で1061種類の文字63073文字のデータとなった。出力したCSVファイルの一番左の列に =UNICHAR(HEX2DEC(RIGHT(B2,4))) のような式を入れて、文字コードに対応する文字を表示させ、文字数が多い順にソートすると次のようになった。(先頭と末尾の画像を示す。) 数が多いのはひらがなで、少ない方になると活字になっていても読めない字もある(汗)
学習させてみる
データができたので、早速学習させてみる。学習用のコードはほとんどサンプルプログラムのままだが、日本の古文書で機械学習を試す(3)でチューニングした結果をもとに、最適化関数はadam、バッチサイズは32に変更した。エポックは前回の日本の古文書で機械学習を試す(5)から、70に設定してみた。識別する文字数はnb_classesで設定するが、上のデータ読み込みのところで、既に1061に設定されている。
# 【パラメータ設定】
input_shape = (img_rows, img_cols, 1)
nb_filters = 32
# size of pooling area for max pooling
pool_size = (2, 2)
# convolution kernel size
kernel_size = (3, 3)
# 【モデル定義】
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
model = Sequential()
model.add(Conv2D(nb_filters, kernel_size,
padding='valid',
input_shape=input_shape))
model.add(Activation('relu'))
model.add(Conv2D(nb_filters, kernel_size))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=pool_size))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 【各エポックごとの学習結果を生成するためのコールバックを定義(前回より精度が良い時だけ保存)】
from keras.callbacks import ModelCheckpoint
import os
model_checkpoint = ModelCheckpoint(
filepath=os.path.join('kosyoku_models','model_kosyoku_{epoch:02d}_{val_acc:.3f}.h5'),
monitor='val_acc',
mode='max',
save_best_only=True,
verbose=1)
# 【パラメータ設定】
batch_size = 32
epochs = 70
# 【学習】
result = model.fit(X_train, Y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(X_test, Y_test),
callbacks=[model_checkpoint])
# 【テストデータに対して信頼度を表示】
score = model.evaluate(X_test, Y_test, verbose=1)
print('Test score:', score[0])
print('Test accuracy:', score[1])
学習結果は
Test score: 0.5634596059351544
Test accuracy: 0.8901060070881995
となった。判別文字数が10種類のときは、0.94~0.97ぐらいの精度が出ていたので、それに比べるとかなり落ちるが、文字数をいきなり約100倍にした割には落ちていないとも言えるか??
ついでなので、前回日本の古文書で機械学習を試す(5)と同じように、RNNでも試してみた。RNNのコードは前回と同じなので省略する。
学習経過をプロットしてみるとこうなった。rnn(フォントの具合でmnに見える?)のラベルがついたものが横方向のRNN、rnn_tが縦方向のRNNの結果だ。プロット用のコードも前回とほぼ同じなので省略する。
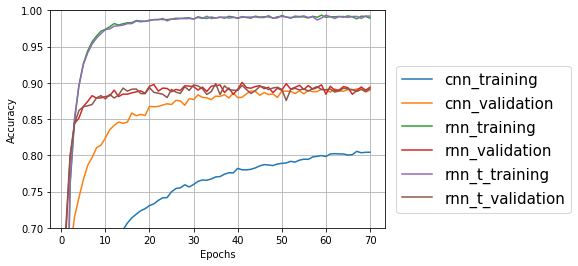
テスト用データ(validation)のグラフはCNNより、RNN(横)、RNN(縦)のほうが学習が早いが、最終的にすべて0.90あたりで収束している。画像処理にはCNNが適しているというのは古文書の文字には当てはまらないのか?? ひらがなの場合、同じ文字でも元になる文字が違ったり、漢字の場合でも、崩し方が複数種類あったりするので、種類別の教師データを作る必要があるのかもしれない。
判別失敗した文字を調べる
どんな文字が間違えやすいのかをチェックするため、間違えた文字をCNN、RNN(横)、RNN(縦)ごとにカウントしてファイル出力してみた。
# 【間違えた文字をカウントしてファイルに書き出す】
file = open('200003076miss.csv', 'w')
miss_count1= [0] * nb_classes
miss_count2= [0] * nb_classes
miss_count3= [0] * nb_classes
for i, x in enumerate(X_test):
# 正解データ
correct_index = np.where(Y_test[i] == True)[0][0] # データがTrueになっている箇所のインデックス
# 各モデルでどの文字かを判別す
preds_cnn_index = model_cnn.predict(np.array([x])).argmax()
preds_rnn_row_index = model_rnn_row.predict(np.array([X_test_RNN[i]])).argmax()
preds_rnn_col_index = model_rnn_col.predict(np.array([X_test_RNN_Trans[i]])).argmax()
# 間違っているものをカウント
if correct_index != preds_cnn_index:
miss_count1[correct_index] = miss_count1[correct_index] + 1
if correct_index != preds_rnn_row_index:
miss_count2[correct_index] = miss_count2[correct_index] + 1
if correct_index != preds_rnn_col_index:
miss_count3[correct_index] = miss_count3[correct_index] + 1
# 文字ごとの間違い数をファイルに書き出し
for i in range(nb_classes):
file.write(str(i)+","+str(miss_count1[i])+ ","+str(miss_count2[i])+ ","+str(miss_count3[i])+"\n")
file.close()
データ数が少ない文字に対して誤り率を出すと極端な値になるので、テストデータが11個以上ある文字の中で、誤り率が高い順にソートしてみた。(間違いカウントしたCSVファイルは最初に作った文字数カウント用CSVとマージしてある。)
CNNの誤り率が高い順にソート
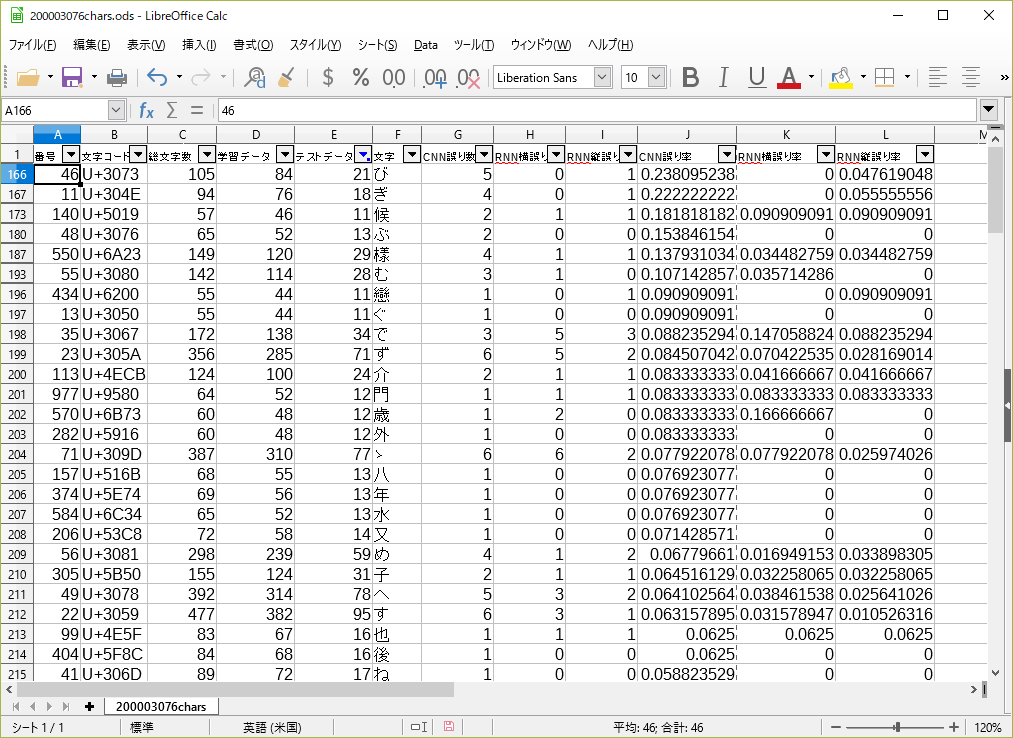
RNN(横)の誤り率が高い順にソート
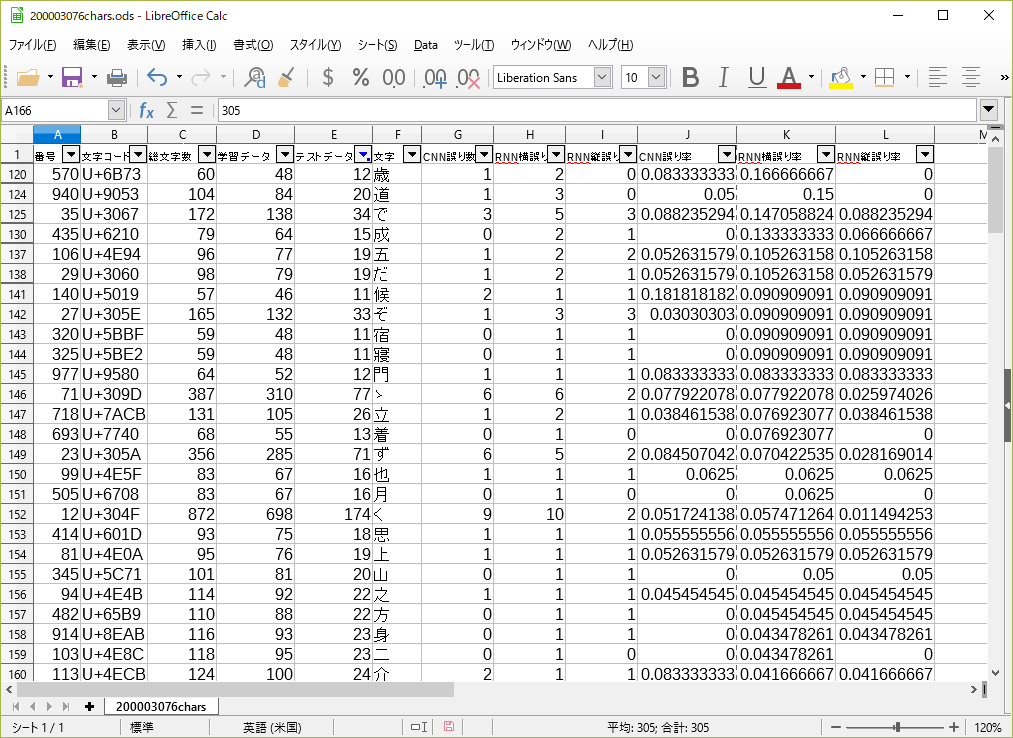
RNN(縦)の誤り率が高い順にソート
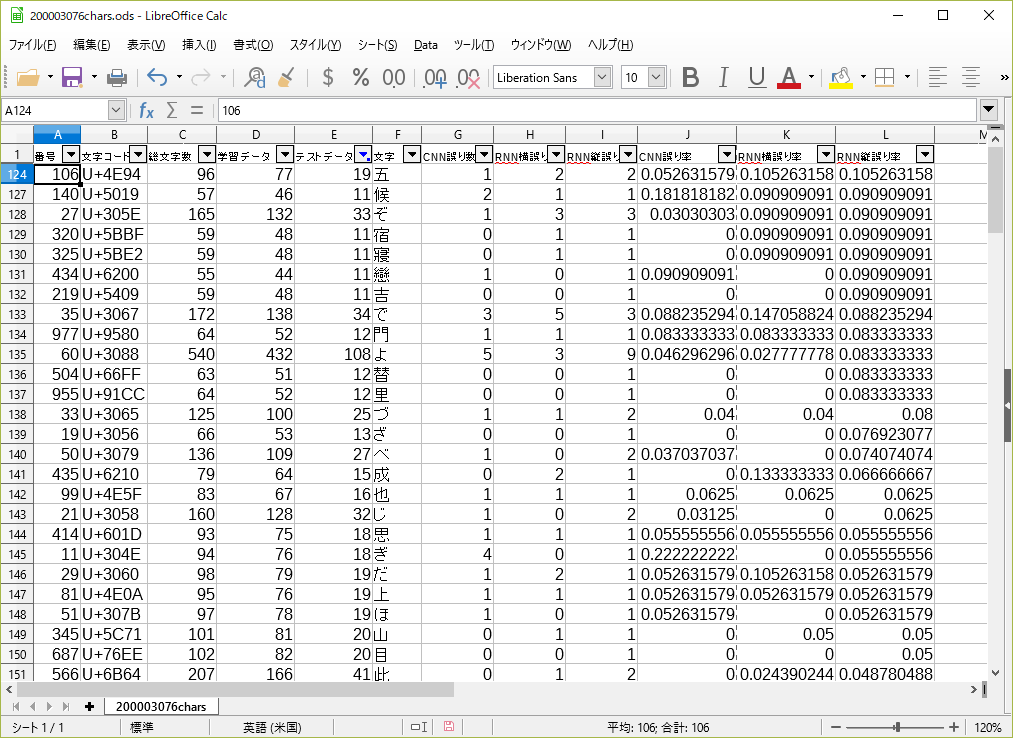
CNNとRNNの組み合わせ
上位に挙がっている文字が微妙に違うので、前回と同じようにCNNとRNNを組み合わせてみた。CNNとRNNの学習中にテストデータの精度が一番高くなったエポックのモデルを読み込んで組み合わせた。
組み合わせパターンは
・CNN + RNN(横)
・CNN + RNN(縦)
・CNN + RNN(横)/2 + RNN(縦)/2
の3種類を試した。
# 【CNN+RNNで正解率を出す】
# CNN+RNN横、CNN+RNN縦、CNN+(RNN横+RNN縦)/2の3パターン
# CNN、RNNのモデル読み込み
from keras.models import load_model
model_cnn = load_model('kosyoku_models/model_kosyoku_68_0.892.h5')
model_rnn_row = load_model('kosyoku_models/model_kosyoku_rnn_41_0.901.h5')
model_rnn_col = load_model('kosyoku_models/model_kosyoku_rnn_trans_35_0.899.h5')
# CNNとRNN2種類の加算で精度チェック
miss_count1 = 0
miss_count2 = 0
miss_count3 = 0
for i, x in enumerate(X_test):
# 正解データ
correct_index = np.where(Y_test[i] == True)[0][0] # データがTrueになっている箇所のインデックス
# 各モデルで判別結果のベクトルを求める
preds_cnn = model_cnn.predict(np.array([x]))
preds_rnn_row = model_rnn_row.predict(np.array([X_test_RNN[i]]))
preds_rnn_col = model_rnn_col.predict(np.array([X_test_RNN_Trans[i]]))
# ベクトルを加算
preds1 = (preds_cnn + preds_rnn_row) / 2
preds2 = (preds_cnn + preds_rnn_col) / 2
preds3 = (preds_cnn + preds_rnn_row*0.5 + preds_rnn_col*0.5) / 2
## どの文字かを判別する
pred_index1 = preds1.argmax() # 確率の一番高い文字の番号
pred_index2 = preds2.argmax()
pred_index3 = preds3.argmax()
# 間違っている場合にインクリメント
if pred_index1 != correct_index:
miss_count1 = miss_count1 + 1
if pred_index2 != correct_index:
miss_count2 = miss_count2 + 1
if pred_index3 != correct_index:
miss_count3 = miss_count3 + 1
print("正解率1 ", 1-miss_count1/len(X_test))
print("正解率2 ", 1-miss_count2/len(X_test))
print("正解率3 ", 1-miss_count3/len(X_test))
結果はこうなった。やはり3種類全部のスコアを足したほうが精度が上がる。
正解率1 0.921643109540636
正解率2 0.923851590106007
正解率3 0.9310070671378092
おまけ、学習経過のaccとevaluateのaccuracyが全然違った話
学習経過をプロットした中で、CNNの学習用データに対する精度(acc)が異常に悪いのが気になったので、学習用データについてもevaluateしてみた。
# 【学習データに対して信頼度を表示】
score = model.evaluate(X_train, Y_train, verbose=1)
print('Train accuracy:', score[1])
結果は
Train accuracy: 0.9639047766269903
となった。あれ?プロットしたときは0.8までしか達していないのは何??ということで調べてみたら、KerasのFAQに、「学習データのlossがテストデータのlossよりかなり大きいのはなぜ?」という項目があった。
ちなみに、テストデータの val_accの値は、プロット値とevaluateの値が同じ値(表示桁数が違うので丸め誤差が出ているぐらい)だった。
lossが大きい=accが小さいということなので、多分同じ意味だろうと思い、読んでみると、学習用データのlossはそのエポックの最終的なlossではなく、各バッチの平均値で、テストデータのlossはそのエポックで生成されたモデルを使って求めた値らしい。evaluateはモデルを使って求めた値だから、学習用データに対する精度としては、evaluateの値のほうが正しいのだろう。
FAQの最初の方に、学習用モデルとテスト用モデルは違っていて、学習用モデルにはdropoutやL1/L2重み正則化が入っているけど、テストモデルではオフになっていると書いてあるが、こちらのほうはまだよく意味が理解できていない。
どちらにしても、学習経過をプロットするときに、学習用データのresult.history['acc']やresult.history['loss']を、テストデータのresult.history['val_acc']やresult.history['val_loss']比較してもあまり意味はなさそうだ。過学習のチェックという意味では学習用データのプロットも意味があるのだろうが…
追記:実は古文書じゃなかった!?
最近気付いたのだが、「古文書」とは「特定の対象に意志を伝達するために書かれたもののうち古いもの」つまり、古い証文、命令書、嘆願書、手紙のようなものを指し、日記、文学作品、著述、変産物などは、厳密には古文書とは言わないらしい。
つまり、今回使った「好色一代男」は「古文書」ではないということだ。しかも、ダウンロード元のサイトによると、「好色一代男」は「版本」なので、手書きの写本でももない。
素人的には、くずし字で書いてある古い本や書類はすべて古文書なのだと思っていたけれど、そうではなかった。
じゃ、これは何というのかというと、ダウンロード元に書いてある通り「古典籍」というのだろうか?記事のタイトルはシリーズ化してしまったので、とりあえずこのままにしておく。(2019/4/23