前回、日本の古文書で機械学習を試す(12)では、転移学習でImageDataGeneratorを使ったが、他クラス分類の場合、各クラスのデータ数を平均化したほうが良いらしいので、転移学習ではなく普通の学習で、ImageDataGeneratorを使ってデータ数を平均化してみる。
そもそも、クラスごとの学習データ数がどうなっているのかを確認するため、日本の古文書で機械学習を試す(10)で出力しておいた5books_chars.csvを開いて、文字種ごとの画像ファイル数でソートしてみた。その結果、1クラスの画像が最大10498枚~最小1枚とかなり差があり、
5000枚以上 -> 8クラス
1000枚以上 -> 42クラス
100枚以上 -> 259クラス
10枚以上 -> 1306クラス
1枚 -> 832クラス
と、なかなかとんでもない偏りっぷりだった。
文字認識の場合、よく使う文字は形のバリエーションも多そうだし、確実に認識したい、たまにしか出てこないものは間違えても仕方がないという面もありそうだが、それにしても偏りすりぎなので、
・1000枚より多いときはランダムに1000枚選ぶ
・100枚~999枚のときはそのまま
・99枚以下のときは水増しして100枚になるようにする
という方針で平均化してみた。
学習データ作成
前回、ImageDataGeneratorで水増しした画像を表示したときに30度では傾きすぎだったので、傾きはプラスマイナス10度までに設定した。それ以外の設定は前回と同じ。
学習データは前回までと同じ人文学オープンデータ共同利用センターの日本古典籍くずし字データセットからダウンロードした「好色一代男」「雨月物語」「おらが春」「養蚕秘録」「物類称呼」の5作品のデータを使うが、1文字種あたりのファイル数を数える必要があるので、あらかじめ5作品のデータを1つのフォルダにまとめてから読み込むように変更した。
img_to_traindata関数は前回定義したものと同じなので省略する。テストデータも前回までと同じく「当世料理」のデータを使うが、日本の古文書で機械学習を試す(11)のテストデータ作成コードをRGB->グレイスケールに変えた(img_to_traindataの最後の引数を0にした)だけなのでコードは省略する。
# 画像水増し用generator定義
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(
rotation_range=10, # 10°までランダムに回転
width_shift_range=0.1, # 水平方向にランダムでシフト
height_shift_range=0.1, # 垂直方向にランダムでシフト
shear_range=0.19, # 斜め方向(pi/16まで)にランダムに引っ張る
zoom_range=0.1 # ランダムにズーム
)
# 学習データ生成
img_rows = 32
img_cols = 32
import glob, os
import numpy as np
np.random.seed(0) # 乱数の種を固定
# 5作品の文字画像データのディレクトリ(5作品分を1つのディレクトリにまとめた)
img_root = "./5books_characters/*"
char_index_dict = {} # 文字コード -> 画像番号
nb_classes = 0 # 文字種数
X_train = []
Y_train = []
chars = glob.glob(img_root) # 画像のルートディレクトリ内のファイル/ディレクトリ一覧
for char in chars:
if os.path.isdir(char): # ディレクトリなら(ディレクトリ名はUTF-8文字コード)
char_code =os.path.basename(char) # 文字コード = ディレクトリ名
if(char_code in char_index_dict.keys()): # 既に辞書にある文字コードなら
y = char_index_dict[char_code]
else: # 辞書にない文字コードなら
y = nb_classes
char_index_dict[char_code] = y # 文字種から番号を調べるためのdict
nb_classes = nb_classes + 1 # 判別文字種数をインクリメント
img_files = glob.glob(char+"/*.jpg") # ディレクトリ内の画像ファイルを全部読み込む
### データ数を均一化する
data_count = len(img_files)
if data_count > 1000: # 1000枚より多いときはランダムに1000枚選ぶ
# 0からdata_count-1までの乱数を1000個生成
#use_indexes = np.random.randint(0, data_count, 1000) # これは1000個中で重複する乱数が選択されるからダメ
use_indexes = np.random.choice(range(data_count), 1000, replace=False) # これは重複なしで1000個
for img_index, img_file in enumerate(img_files): # ディレクトリ(文字種)内の全ファイルに対して
if data_count <= 1000 or img_index in use_indexes: # 1000枚以下なら全データ、1000枚超なら乱数と一致するカウントの場合のみ
x = img_to_traindata(img_file, img_rows, img_cols, 0) # 各画像ファイルを読み込んで行列に変換(grayscale)
X_train.append(x)
Y_train.append(y) # 学習用データ(出力)に正解の文字種番号を追加
if data_count < 100: # 100枚未満のとき
x = np.expand_dims(x, axis=0) # 画像データの軸を1つ追加
gen = train_datagen.flow(x, batch_size=1) # 画像データを水増しするためのgenerator
# 画像を何個水増しするかを決定(文字コードごとに全部で100個になるように、1つの画像の水増し数を決定)
gen_num = 100 // data_count - 1
if img_index < 100 % data_count:
gen_num = gen_num + 1
# 指定個数だけ画像を水増しして学習データに追加
for i in range(gen_num):
new_img = next(gen)
X_train.append(new_img[0])
Y_train.append(y)
# 学習データをlistからnumpy.ndarrayに変換
X_train = np.array(X_train, dtype='float32')
Y_train = np.array(Y_train, dtype='int16')
# 文字種を表す数字をカテゴリカルデータ(ベクトル)に変換
from keras.utils import np_utils
Y_train = np_utils.to_categorical(Y_train, nb_classes)
# Y_trainの型を表示
print(Y_train.shape)
最後のprintの結果は、(431565, 3578)、学習データ数は431565個、判別する文字数は3578種類 となった。学習データの数は前回まで227975個だったので約2倍弱になっている。
試しに、いくつかのクラス(文字種)で学習データがいくつあるかを表示させてみた。後で考えたら、np_utils.to_categoricalの変換をする前に数えたほうが楽だったのだが、変換してしまったものは仕方がないので、np.whereでTrueの位置のインデックスを取得してカウントした。
Y_trainは2次元配列なので、y_count[0]は値がTrueになる行番号のarray[0,1,2,...431564]、y_count[1]は値がTrueになる列番号のarrayになる。y_count[1]が特定の値(クラス)になるデータ数を数えた。
y_count = np.where(Y_train == True)
print(np.sum(y_count[1] == 0))
print(np.sum(y_count[1] == 1))
print(np.sum(y_count[1] == 12))
print(np.sum(y_count[1] == 40))
print(np.sum(y_count[1] == 200))
print(np.sum(y_count[1] == 2000))
print(np.sum(y_count[1] == 3500))
print(np.sum(y_count[1] == 3577))
結果を見ると、意図した通り、100~1000個の間の数になっている。
100
618
1000
124
1000
100
100
100
ちなみに、上のコードでコメントアウトしてあるが、最初は1000個以上のときに、ランダムに1000個取り出すために、np.random.randint を使っていたのだが、データ数をカウントしてみると1000個になっているものが見つからず、おかしいなぁと思っていたら、np.random.randint では、1000個独立に乱数を取り出す=重複した数が選ばれることもあるので、重複した分だけ1000個より少なくなるのだった。np.random.choice に変えるとうまくいった。
学習
日本の古文書で機械学習を試す(8)の「複数作品のデータを使ってモデル生成」と同じ畳み込み3層のモデルを生成した。
# 再現性を得るための設定をする関数を定義
# https://keras.io/ja/getting-started/faq/#how-can-i-obtain-reproducible-results-using-keras-during-development
import tensorflow as tf
import random
import os
from keras import backend as K
def set_reproducible():
os.environ['PYTHONHASHSEED'] = '0'
np.random.seed(1337)
random.seed(1337)
## 転移学習のときにエラーになるのでtfのsession関係はコメントアウト
#session_conf = tf.ConfigProto(intra_op_parallelism_threads=1, inter_op_parallelism_threads=1)
tf.set_random_seed(1337)
#sess = tf.Session(graph=tf.get_default_graph(), config=session_conf)
#K.set_session(sess)
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
# 【パラメータ設定】
batch_size = 32
epochs = 20
input_shape = (img_rows, img_cols, 1)
nb_filters = 32
# size of pooling area for max pooling
pool_size = (2, 2)
# convolution kernel size
kernel_size = (3, 3)
# 【モデル定義】
model = Sequential()
model.add(Conv2D(nb_filters, kernel_size, # 畳み込み層
padding='valid',
activation='relu',
input_shape=input_shape))
model.add(Conv2D(nb_filters, kernel_size, activation='relu')) # 畳み込み層
model.add(MaxPooling2D(pool_size=pool_size)) # プーリング層
model.add(Conv2D(nb_filters, kernel_size, activation='relu')) # 畳み込み層
model.add(MaxPooling2D(pool_size=pool_size)) # プーリング層
model.add(Dropout(0.25)) # ドロップアウト(過学習防止のため、入力と出力の間をランダムに切断)
model.add(Flatten()) # 多次元配列を1次元配列に変換
model.add(Dense(128, activation='relu')) # 全結合層
model.add(Dropout(0.2)) # ドロップアウト
model.add(Dense(nb_classes, activation='softmax')) # 全結合層
# モデルのコンパイル
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 【各エポックごとの学習結果を生成するためのコールバックを定義(前回より精度が良い時だけ保存)】
from keras.callbacks import ModelCheckpoint
import os
model_checkpoint = ModelCheckpoint(
filepath=os.path.join('transfer_models','model_expand100_{epoch:02d}_{val_acc:.3f}.h5'),
monitor='val_acc',
mode='max',
save_best_only=True,
verbose=1)
# 【学習】
set_reproducible()
result = model.fit(X_train, Y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(X_test, Y_test),
callbacks=[model_checkpoint])
学習結果
前回までと同じコードで、学習結果を表示させてみた。途中でテストデータに対する精度が一番良かったのは17/20エポック目で0.563だった。
431565/431565 [==============================] - 637s 1ms/step
Train score: 0.2813108302552428
Train accuracy: 0.9343528784771703
4813/4813 [==============================] - 7s 1ms/step
Test score: 2.3155917460027267
Test accuracy: 0.5350093497522601
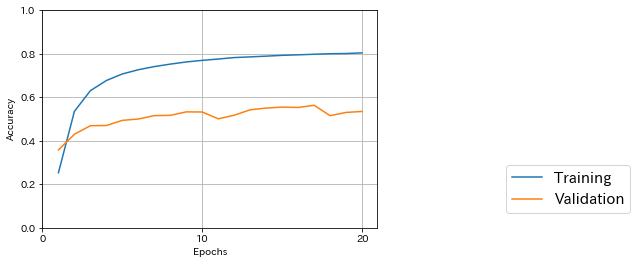
水増ししていないデータで学習させたときの最高精度は日本の古文書で機械学習を試す(10)の0.605なので、水増ししたことにより精度が少し落ちている。古文書の文字識別の場合、似たような(ちょっと違う)データを増やしてもあまり意味がないということだろうか。
おまけ
テストデータも偏っていそうだったので、調べてみた。
# テストデータの各クラス(文字コード)のデータ数を数える
count_vec = np.sum(Y_test != 0, axis=0)
print(np.sum(count_vec == 0)) # データが1個もないクラスの数
print(np.sum(count_vec != 0)) # データが1個以上あるクラスの数
出力はこうなった。
2086
1492
なんと、半分以上のクラス(文字種)がテストされていない!! テストデータの作り方については再考する必要がある。
学習データに使った5作品+テストデータに使った1作品のデータをごちゃまぜにして、クラス(文字種)ごとに学習データとテストデータに分ければ、テストデータと同じ作品のデータが学習データにも含まれることになるので、精度は上がる可能性が高い。水増しデータも混ぜればデータの類似度が高くなる分だけさらに精度は上がるかもしれない。
でも、できれば学習データとは別の作品のデータでテストをしたい。テストデータ用にもう少し多くの作品データをダウンロードするしかないのだろうか。