前回、VGG16を使った転移学習を試したが、転移学習の際に、ImageDataGeneratorを使って学習データを水増しした例がたくさんあったので、これを試してみる。
ImageDataGeneratorの設定
テストデータ、学習データは、前回日本の古文書で機械学習を試す(11)で作成、保存したものを読み込んで使う。
import numpy as np
X_train = np.load('X_train_rgb_float32.npy')
X_test = np.load('X_test_rgb_float32.npy')
Y_train = np.load('Y_train_rgb.npy')
Y_test = np.load('Y_test_rgb.npy')
img_rows = 32
img_cols = 32
nb_classes = len(Y_train[0])
次に画像のどこをどのようにいじって水増しするかを定義する。Kerasのドキュメントにたくさんのパラメータが解説されているが、文字データなので、あまりいじる余地はない。90度とか180度回転させたり、左右反転させたりすると、文字として認識不能なものになってしまう。
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(
rotation_range=30, # 30°までランダムに回転
width_shift_range=0.1, # 水平方向にランダムでシフト
height_shift_range=0.1, # 垂直方向にランダムでシフト
shear_range=0.19, # 斜め方向(pi/16まで)にランダムに引っ張る
zoom_range=0.1 # ランダムにズーム
)
train_generator = train_datagen.flow(X_train, Y_train, batch_size=batch_size, seed = 16)
モデル定義も前回と同じものを使用し、前回と異なるのは、fitのかわりにfit_generatorを使うところ。samples_per_epochは、元の学習データのデータ数を指定している。これで、1エポックで使うデータ数は元データと変わらないが、エポックごとにランダムに変形された画像が学習に使われることになる。
実行すると、「samples_per_epochではなく、Keras 2 APIのsteps_per_epochを使うように」という警告が出たが、steps_per_epoch = samples_per_epoch / batch_size で自動変換してくれた。
result_t = model_t.fit_generator(
train_generator,
samples_per_epoch=X_train.shape[0],
epochs=epochs,
verbose=1,
validation_data=(X_test, Y_test),
callbacks=[model_checkpoint])
前回と同じコードで学習結果を表示してみた。途中でテストデータに対する精度が一番良かったのは7/20エポック目で0.270だった。
227975/227975 [==============================] - 4465s 20ms/step
Train score: 2.640619109681416
Train accuracy: 0.5417787038052418
4813/4813 [==============================] - 94s 19ms/step
Test score: 4.504762656570298
Test accuracy: 0.2536879285269063
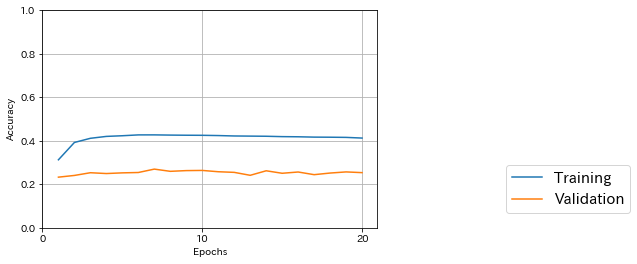
前回の、ImageDataGeneratorを使わない転移学習と比べても精度が落ちている。学習にかかる時間は前回とほぼ同じだった。
前回も過学習を起こしていたわけではないし、ランダムに変形することで、文字としておかしいデータが紛れてしまっている可能性もあるので、精度が落ちたのは予想通りだった。
水増しされた画像を表示してみる
前回定義したimg_to_traindata関数で、画像を1つ読み込み、上で定義したtrain_datagenを使って水増しして表示させてみた。
# 好色一代男の中の「中」の1文字のデータを読み込む
img_file = '../200003076/characters/U+4E2D/U+4E2D_200003076_00046_1_X1469_Y1253.jpg'
img_rows = 32
img_cols = 32
x = img_to_traindata(img_file, img_rows, img_cols, 1) # 元画像
images = [] # 画像を格納する配列
images.append(x) # 配列の先頭に元画像を格納
# データを水増し
xx = np.expand_dims(x, axis=0) # 画像データの軸を1つ追加
gen = train_datagen.flow(xx, batch_size=1)
for i in range(15): # 水増しデータを15個作る
new_img = next(gen)
images.append(new_img[0])
# 水増し結果を表示
import matplotlib.pyplot as plt
%matplotlib inline
fig = plt.figure(figsize=(8,2)) # 全体の表示領域のサイズ(横, 縦)
fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.5, wspace=0.05)
for n, img in enumerate(images):
for i in range(2):
ax = fig.add_subplot(2, 8, n+1, xticks=[], yticks=[]) # 縦分割数、横分割数、何番目か、メモリ表示なし1
ax.imshow(img)
結果はこうなった。左上が元画像で、残りの15個が水増ししたデータ。傾きはプラスマイナス30度までに設定してみたが、いくつかの画像はどう見ても傾きすぎだ。さらに、水増しデータは元データに比べてエッジがぼんやりしている感じだ。
