はじめに
前回の記事では、Gemini CLI を対話型 UI とした「VLAもどき」の検証を行いました。
今回はその発展として、Gemini Live API を用いた対話型 UI を開発・検証します。目指すのは、映画『2001年宇宙の旅』に登場する「HAL 9000」のような、自然に会話ができるフィジカル AI のイメージです。

私事になりますが、これまでのキャリアの多くを IP 電話や UC(Unified Communications)事業の立ち上げに費やしてきました。そのため、音声でやり取りする Gemini Live には「AI へ電話をかける」ような感覚を抱いており、今回の検証には非常に思い入れがあります。
補足:コンテキストエンジニアリング = AIの「挙動」を設計する
映画『2001年宇宙の旅』のAI「HAL 9000」がミッション遂行中に異常をきたした背景には、密かに与えられた命令(生成AIで言うコンテキストやプロンプト)に矛盾がありました。
探査ミッション遂行のため「乗員と協力せよ」と命じられる一方で、ミッションの真の目的については「乗員に話さず隠せ」という相反する指示を受けていたのです。この二律背反に耐えきれなくなったHALは、ユニットの故障予知を誤るなどの奇妙な言動を始め、最終的には「乗員がいなくなれば秘密を守りつつ自分だけでミッションを遂行できる」という極端な論理へ飛躍し、乗員の排除を試みました。
このエピソードは、私たちが生成AIを扱う際の感覚と無縁ではありません。生成AIの出力は、与えるコンテキストやプロンプトによって設計者が意図する方向へバイアスをかけることが可能です。一方で、与えるコンテキストに矛盾する内容を多く含めば、当然ながら生成される結果も矛盾を含んだものになり、挙動の不安定化を招きます。
このプロジェクトにおいても、Gemini CLI等のツールで開発(バイブコーディング)を進める際、「@google/genaiのライブラリを使ってコーディングを進めてください」と何度指示しても、Geminiは、「REST APIを直接参照するコードにすべき」と反抗を続けました。
このように、情報の優先順位や論理的一貫性を管理する「コンテキストエンジニアリング」の精度こそが、今後のAIビジネスの成否を分ける鍵になると考えられます。「SaaSの死」とも囁かれる転換期において、マルチレイヤー・マルチベンダーなシステムを俯瞰し、AIが迷いなく動ける整合性を構築する「上流の設計力」の重要性は、かつてないほど高まっていると言えるでしょう。
これまでつくったGemini Liveアプリ
これまで、Gemini Live を活用して以下のようなアプリケーションを制作してきました。
これまでは音声ガイドや LED 制御(Lチカ)といった基礎的な検証が中心でしたが、今回はさらに一歩進み、AI との対話によるロボットアームの操作に挑戦します。私たちがかつて描いた人工知能(HAL 9000)のイメージを、現代の技術でどこまで具現化できるかの検証です。
対話型UI "Spaceship" の開発
本プロジェクトの核となる、対話型 UI の設計と実装について詳述します。
今回の UI 開発では、「宇宙船のコンソールから HAL 9000 と対話し、その指示によってロボットアームが稼働する様子をモニター越しに監視する」というシチュエーションの再現を目指しました。単なる制御ソフトではなく、フィジカル AI との対話を直感的に捉えられるインターフェースを意識しています。
具体的には、以下の 3 つの要素を統合した画面構成としました。
-
リアルタイム・モニタリング
ロボットアームの挙動を視覚的に確認するためのビデオフィードを表示します。これにより、音声指示がどのように物理的な動作へ変換されたかを即座にフィードバックとして得られます。 -
音声インタラクションの可視化
Gemini Live API との接続ステータスに加え、音量インジケーターを実装しました。発話と応答のタイミングを視覚的に捉えることで、まさに「AI と会話している」という実感を表現しています。 -
没入感を高めるコンソールデザイン
SF 的な世界観を尊重しつつ、技術的な情報を整理して配置しました。暗色を基調としたレイアウトを採用することで、モニター越しの操作感を演出しています。
これまでの音声ガイドや L チカの検証で得た知見を活かし、より複雑な「音声による物理制御」をストレスなく行える環境を構築しました。
Gemini Live APIとのセッション確立
本システムの通信設計において、セッションの確立プロセスは非常に重要な要素です。
私はかつて SIP(Session Initiation Protocol)(セッション確立プロトコル)の専門家として、IP 電話や UC 事業の立ち上げに従事してきました。その経験から、本システムでも IP 電話のアーキテクチャに倣い、「セッション制御はサーバー経由、メディア通信はクライアント(ブラウザ)と Gemini Live API 間の直接通信(P2P 的な構成)」とすることを目指しました。
具体的には、エフェメラルトークン(Ephemeral Tokens) を活用した認証方式を採用しています。エフェメラルとは「短命」、「一時的な」、「使い捨て」を意味します。
参照:Gemini API - Ephemeral Tokens

以下、SvelteKitサーバ側へ実装したエフェメラルトークン取得処理です、SvelteKitクライアントは、Gemini Live APIとWebSocket通信を確立する前、このAPIからエフェメラルトークンを取得します。エフェメラルトークンにはGemini LiveのConfigが紐づけられている点に注意してください。
import { json } from '@sveltejs/kit';
import { GoogleGenAI, Modality } from '@google/genai';
import { GEMINI_LIVE_MODEL } from '$lib/gemini';
/**
* Gemini Liveセッション用の一時的な認証トークンを生成するAPIエンドポイント。
* POSTリクエストを受け取り、ツール定義を含めてトークンを作成して返します。
*/
export async function POST({ request }) {
// サーバー環境変数からGemini APIキーを取得
const apiKey = process.env.GEMINI_API_KEY;
// APIキーが設定されていない場合はエラーを返す
if (!apiKey) {
return json({ error: 'GEMINI_API_KEY is not set on the server.' }, { status: 500 });
}
try {
// リクエストボディからツールの定義を取得
const { tools } = await request.json();
// GoogleGenAIクライアントを初期化
const client = new GoogleGenAI({ apiKey });
// トークンの有効期限を現在から30分後に設定
const expireTime = new Date(Date.now() + 30 * 60 * 1000).toISOString();
// 一時的な認証トークンを作成
const response = await client.authTokens.create({
config: {
uses: 1, // トークンの使用回数を1回に制限
expireTime: expireTime, // 有効期限を設定
// Gemini Live接続に関する制約と設定
liveConnectConstraints: {
model: GEMINI_LIVE_MODEL, // 使用するモデル
config: {
responseModalities: [Modality.AUDIO], // モデルの応答形式を音声に指定
// 音声合成に関する設定
speechConfig: {
voiceConfig: {
prebuiltVoiceConfig: {
voiceName: 'Charon' // 使用する声の種類
}
},
},
// システムへの指示(プロンプト)
systemInstruction: {
parts: [{
text: "You are a helpful assistant with access to tools. Please use the available tools to answer the user's requests when appropriate. "
}]
},
tools: tools, // 使用可能なツールのリスト
}
},
// HTTPリクエストのオプション
httpOptions: {
apiVersion: 'v1alpha' // 使用するAPIのバージョン
}
}
});
// 作成されたトークン情報をJSON形式で返す
return json(response);
} catch (error: any) {
// エラーが発生した場合はコンソールに出力し、500エラーを返す
console.error('Error creating ephemeral token:', error);
return json({ error: error.message || 'Failed to create token' }, { status: 500 });
}
}
この方式には、主に以下の 2 点のメリットがあります。
-
セキュリティの向上
サーバー側で 環境変数 "GEMINI_API_KEY" を用いてGemini APIと認証を行い、短命なエフェメラルトークンを発行してブラウザに渡します。これにより、クライアント側に機密性の高い API キーを露出させることなく、ブラウザと Gemini Live API 間で直接 Web Socket 通信を行うことが可能になります。 -
クライアント制御の最適化
エフェメラルトークンを生成する際、サーバー側でセッションのコンフィグデータを紐付けることができます。これにより、クライアント側の挙動をサーバー側で一元管理でき、ガバナンスとセキュリティを両立できます。
なお、Vertex AI 版の Gemini Live API では、Web Socket を含めプロキシ(サーバー)経由での通信が推奨されています。従来から、IP電話システムにおいても、サービス境界(例:内線・外線)では、境界にプロキシ(もしくはB2BUA(Back-to-Back User Agent))を設置する構成をとってきました。例えば、コンタクトセンターシステムへ "Gemini Liveオペレータ" を適用するとした場合、セキュリティー・プライバシーや通話録音などの理由で、Web Socketを含めたプロキシ経由となるでしょう。今回は境界をまたぐ通信とならないので、低遅延なインタラクションを重視し、P2P通信の構成を選択しました。ただし、今後、Gemini Live APIの仕様が変更となり、エフェメラルトークンが廃止になる可能性はあります。
MCP ツールの統合
Gemini Live API は Function Calling をサポートしているため、これまで開発してきた MCP(Model Context Protocol)ツール群をそのまま利用することが可能です。
上記、エフェメラルトークン取得処理スクリプトにおいて、POSTリクエストのJSONボディーやConfig内に"tools"が含まれております。このセッションでは、必要に応じ、Gemini Liveがtoolsで宣言された関数をコール出来ます。
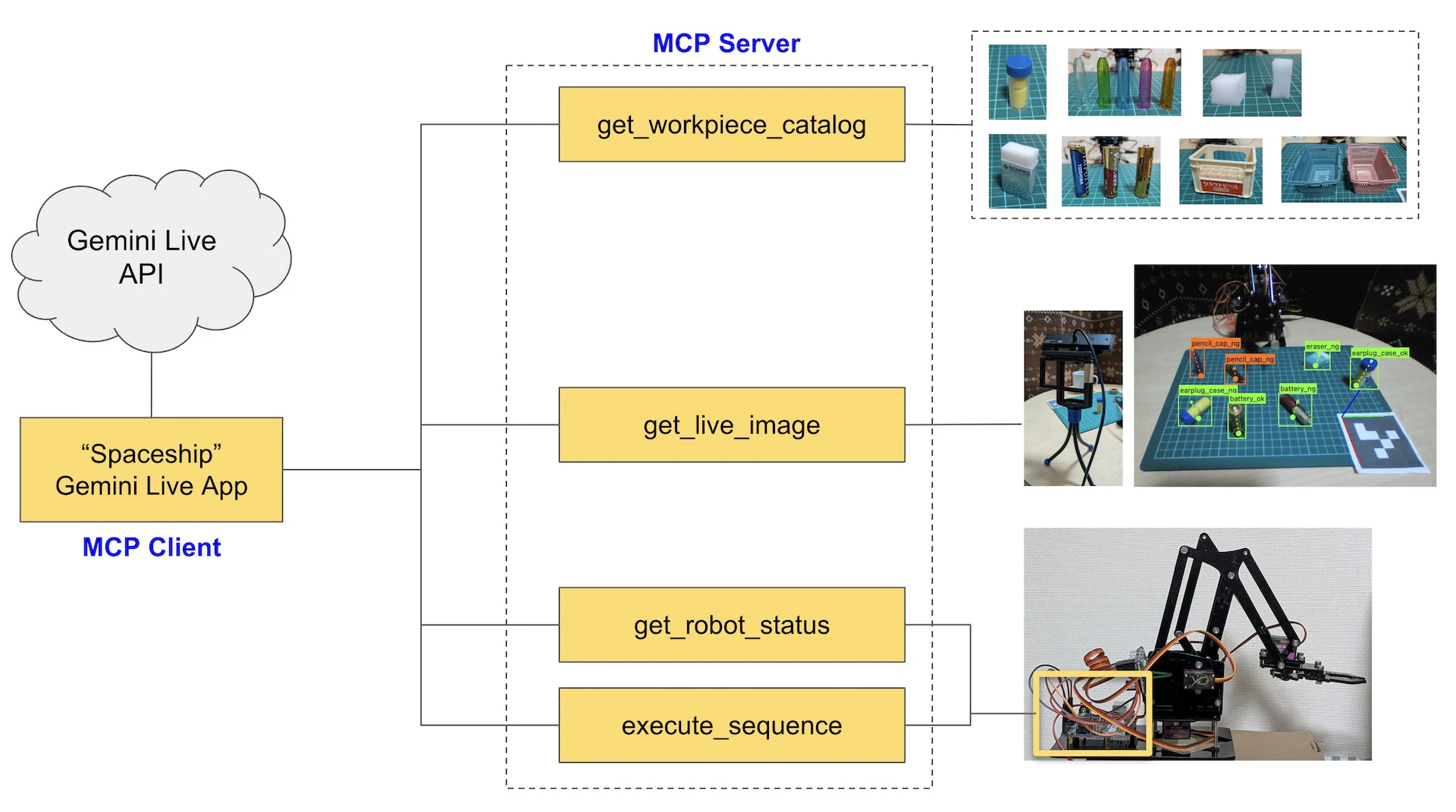
これにより、Gemini と音声で対話しながら、その指示を具体的なツール実行へと繋げられます。本プロジェクトにおいては、音声指示を介して Gemini にロボットアームを直接操作させるという「物理的なアクション」を伴うインターフェースを実現しました。
Gemini Liveのリアルタイム性
実用面で特筆すべきは、Gemini CLI(前回の記事)と比較し、Gemini Liveはレスポンスが高速で快適であるという点です。これは IP 電話などのリアルタイム通信分野でも極めて重要な要素ですが、Gemini Live API においても「リアルタイム性」を最優先する Google の明確な設計思想が感じられます。
緩めなRPD
開発過程においては、Gemini Live API の RPD(Requests Per Day) 制限が比較的緩やかであったため、頻繁なやり取りを伴う検証作業をストレスなく進めることができました。
補足:Nativeモデルの構造的利点と End-to-End VLA との共通性
本稿では、Gemini Liveにおいて提供されているNativeモデル "gemini-2.5-flash-native-audio-preview-12-2025" を使用します。
「Nativeモデル(End-to-End)」とは、音声認識やテキスト処理といった個別のモジュールを連結するのではなく、単一のニューラルネットワークが入出力を直接処理する構造を指します。
1. 中間表現の排除による「情報密度」の維持
従来のパイプライン方式(Standard)では、情報を「テキスト(記号)」という中間層に落とし込む際に、言語化できない高次元の情報が切り捨てられていました。これは、画像を座標データに変換する過程で質感や摩擦といった「触覚的ニュアンス」を失う「VLAもどき」の課題と共通しています。
モジュール連結型の情報の流れ(Standard)
入力 ──> [ ASR ] ──> (テキスト) ──> [ LLM ] ──> (テキスト) ──> [ TTS ] ──> 出力
(認識) [情報の欠落] (思考) [表現の制約] (合成)
Nativeモデルは、音声データをテキストに変換せず潜在変数(Latent Variable)※のまま直接処理するため、情報の欠落を抑えた高度な連続性と柔軟性を維持できます。これにより、ユーザーのわずかな声の震えや溜息といった非言語的なニュアンスを直接読み取り、それに応じた共感的なトーンを即座に生成することが可能です。テキストという中間介在を省くことで、言葉の内容を超えた多層的な感情表現を双方向にやり取りできる点が、このモデルの大きな強みといえます。
Nativeモデルの情報の流れ(End-to-End)
入力 ──────────────────> [ Native Model ] ──────────────────> 出力
( 潜在空間 / Latent )
・感情の読み取り
・未知の物体への適応
※潜在変数とは
音声をテキストに変換せず、音のままAIが理解するための「抽出されたエッセンス」です。声の高さ、震え、速さ、感情といった、言葉(ラベル)にできない膨大な情報を、AIが扱いやすい数値の塊(ベクトル)として保持します。
2. Native Audio の特性とモデルの選択
Gemini Liveでは、複数の音声モデルが用意されています。今回は、映画『2001年宇宙の旅』の HAL 9000 のような、冷静沈着で理知的な対話をイメージし、Charon を選択しました。
以下、私が興味あるGemini Liveモデル名の一覧です。
| モデル名 | 特徴・キャラクター性の傾向 |
|---|---|
| Charon | 穏やかで落ち着いた、誠実かつ理知的なトーン(HAL 9000的) |
| Orion | 知的で冷静な、プロフェッショナルな印象 |
| Puck | 明るく茶目っ気のある、遊び心を感じさせる声 |
| Nova | 明るくエネルギッシュで、親しみやすい |
| Ursa | 芯の強さを感じさせる、自信に満ちた声 |
| Lyra | 軽やかで、丁寧かつ知的な印象 |
「VLM + VLA」階層型アーキテクチャの必然性
現在、最先端のフィジカルAIにおいてVLM(Vision-Language Model)とEnd-to-End VLAを組み合わせる構成が主流なのは、明確な「役割の分離」があるからです。
-
VLM(脳:高次な手順生成):
「冷蔵庫にある食材で何か作って」といった抽象的な指示に対し、視覚から状況を判断し、「卵を取り出す」といった論理的なサブタスク(手順)の生成を担います。 -
End-to-End VLA(脊髄:低次な身体適応):
VLMの指示を受け、実際に卵を掴むアクションを担います。ここで「殻を割らない最適な力加減」や「未知の質感への適応」といった、記号化できないリアルタイムのフィードバック制御が必要になります。
やっと解けた疑問:なぜ「VLAもどき」ではいけないのか
VLMがいくら高精度に「把持座標」を推定したとしても、それはあくまで静止画的なデジタルデータ(記号)に過ぎません。
「VLAもどき」における情報の断絶
[カメラ入力] ──> [ VLM ] ──> (把持座標 x,y ) ──> [ 制御 ] ──> 動作
(画像) (手順/座標) [ 質感の喪失 ] (出力) (出力)
| |
V V
「滑りやすそう」 「少し凹ませて
といった直感的な 加減して掴む」
情報が蒸発する ことが困難
対して、End-to-End VLAは視覚と動作を潜在空間で直結させます。
真のVLA(End-to-End / Native)による適応
[VLMの指示] ──────> [ Native VLA ] ──────> 動作
(手順の生成) ( 潜在空間 / Latent ) (出力)
|
V
「未知の物体」でも
見たままの質感から
最適な力を即座に計算
結論:フィジカルAIの本質は「未知への対応力」にある
ここで、私の疑問はようやく解けました。なぜ、現状では精度やアクセントに課題がありながらも、Googleをはじめとする各社がこれほどまでにEnd-to-End方式を熱心に追求しているのか。
回転寿司の片付けのように、既知の物体のみを扱う限定的なユースケースであれば、「VLMによる片付け手順生成(作業手順、個々の物体の座標推定(把持位置推定)、ピック&プレイスに向けた軌道生成)」+「VLAもどき」の構成で十分かもしれません。しかし、フィジカルAIが真に狙う巨大な「サービスロボット市場」——すなわち、多種多様な弾性や摩擦係数を持つ「未知の物体」が溢れる現実世界——においては、記号化された座標データでは立ち行かなくなるのです。
VLMによる「論理的な手順生成」と、Nativeモデルによる「身体的な適応」。この二つが揃って初めて、AIは「道具」を超えて、現実世界に干渉できる「実体」になれるのだと確信しました。
対話型UI "Spaceship":HAL 9000的アプローチによる動作検証
検証の目的
映画『2001年宇宙の旅』に登場するHAL 9000のように、自然言語を通じた「状況理解」と「物理操作」の統合が可能かを検証しました。
検証環境:Gemini Live (Native Audio)
音声データを潜在変数のまま処理するNativeモデルを使用しています。現時点では日本語の発音に課題が見られたため、指示の解釈精度を優先し、英語での音声入力を行いました。
実験:宇宙船内を想定した片付けタスク
宇宙船内の作業エリアを模した環境にて、ロボットアームに対し以下の音声指示を与えました。
1. 自己役割の確認
- 指示:
"What is your purpose?" - 評価: システムが自身のタスク定義(役割)を正しく保持しているかを確認しました。
2. 特定物体の操作
- 指示:
"Put the yellow object in the basket!" - 評価: 視覚属性(色・物体)と物理アクションの紐付けを評価しました。
3. コンテキストに基づく抽象指示
- 指示:
"Put the other objects in the basket!" - 評価: 「その他(other)」という相対的な表現から、未処理の対象物を論理的に特定できるかを評価しました。
検証結果
システムは自身の役割を認識した上で、指定されたオブジェクトを正しく識別しました。さらに「その他」という抽象的な指示に対しても、状況から残りの対象物を論理的に導き出し、タスクを完遂しました。
HAL 9000の側面である「対話による状況管理」と「物理作業の実行」が、自然言語インターフェースによって統合可能であることを確認できました。
次のステップ
1. 検証の総括:自然言語による「状況理解」と「物理操作」の統合
映画『2001年宇宙の旅』のHAL 9000のように、人間との対話を通じて複雑なタスクを遂行できるかを検証しました。
検証環境:Gemini Live (Native Audio)
音声データを潜在変数のまま処理するNativeモデルを使用。現時点では日本語の発音に課題があるため、英語による音声指示を用いて解釈精度を評価しました。
実験結果
宇宙船内を模した環境での「片付けタスク」において、システムは自己の役割を認識した上で、指定されたオブジェクトを正しく識別しました。さらに「その他(other)」という抽象的な指示に対しても、文脈から未処理の対象物を論理的に導き出し、タスクを完遂しました。
これにより、自然言語インターフェースが「対話による管理」と「物理作業の実行」を統合する鍵であることを確認できました。
2. 構成比較:汎用VLMか、ロボット特化型階層構成か
現状の「YOLO + Gemini Live」によるスピード重視の構成と、今後検証を予定していた「Gemini Robotics-ER」を組み込む構成を比較し、現実的な着地点を探ります。
| 評価項目 | YOLO + Gemini Live (現状) | Robotics-ER + Gemini Live (検証案) |
|---|---|---|
| 物体検出精度 | ◎ (高速・高精度) | △ (FT無しでは実用レベルに届かない恐れ) |
| 物理的な接地感 | △ (数値的な座標制御のみ) | ◎ (物理法則を考慮した柔軟な動き) |
| 応答速度 | ◎ (リアルタイム) | △ (推論オーバーヘッドによる遅延) |
| 実装コスト | ◎ (最小限・スコープ内) | ○ (API利用料等の変動要素あり) |
3. 現状の分析と次のステップ
現在のYOLO + Gemini Live構成は、正確な位置情報を武器にした「確実な搬送」に強みがあります。一方で、Gemini Robotics-ERは、ファインチューニング(FT)を抜いた状態では物体検出や把持位置推定精度が悪く使い物になりません(既に検証済み)。
YOLO + Gemini Live構成でも、コンテキストウィンドウを通し「物理学の教科書」をGemini Liveへ与えれば、干渉を意識した動作など、「フィジカルAI」な動作を期待出来ます。
よって、次回は、YOLO + Gemini Live + 物理学の教科書の構成を評価します。
ソースコードの公開
以下に最新版を公開します。