アドベントカレンダーも最終日になりました。最後は、今年@1060ki 、 @Kansei と共に参加したJPHACKSというハッカソンで作成した、スライド操作用アプリ**HyPre** の紹介です。(ロゴなどはデザイナーの方に作成して頂きました!)

Fintech = Finger × Technology ?
ばかげたことを言っているように聞こえるかもしれませんが、至って真面目です。
今回僕たちは、指にテクノロジーの魔法をかけました。(正確にはテクノロジーに指をスパイスとして加えました)
真面目にFintechやってる方々には深くお詫び申し上げます( )
HyPreとは何か
指パッチンなどの音を認識し、認識結果によってスライドを操ることのできるシステムです。

他にも、ベルやゴングの音で画面を暗転させるなど、プレゼンでよく使われる音を認識し、あなたのプレゼンテーションをよりイケてるものに昇華させます。HyPreを使うと、イキったプレゼンができます。
認識した音の種類によって、プレゼンテーション用アプリへの命令をカスタマイズできます。
例: 指パッチン -> 次のスライド, ベル -> 画面暗転
動作環境は、macOSです。
(Super Hyper Presentationの略です。)
入力デバイス
歴史
情報機器への入力インターフェースとして、今でこそ様々なデバイスが存在していますが、タイプライターの時代から今まで残り続けている超優秀な入力デバイスをご存知でしょうか。そう、キーボードです。でも、そんな優秀なキーボードを持ってしても、格好のつかない場面があるのです。それは、プレゼンテーションの場。かっこいいプレゼンをしている人たちの挙動を見ていると、ステージの上を歩き回っていることに気が付きます。実際に歩き回ってみると困ることがあります。
- ついパソコンから遠いとこまで来ちゃってキーボード押せない
- 裏方にスライド送ってもらおうとするけどタイミングが合わない
- 結局レーザーポインターなどの機器を手に持ってしまって、ボディランゲージが満足にできない
そんな場合に、指 はあなたの助けになってくれるでしょう。
次世代入力インターフェース、指
指で何ができるのか
答え: 指パッチンでスライドを操ることができる
指の可能性は無限大です。
それ結局インターフェースはマイクじゃね?
これはとても難しい問題です。
キーボードやマイクはマンマシンインターフェースとして分類できますが、指はもはや身体の一部です。
インターフェースの定義を確認してみましょう。
インターフェースの定義
もともと、英語としての interface には、境界面という意味があります。開発者が言うインターフェースは、コンピュータサイエンスやプログラムチックな意味合いが強く、ついついマイクを入力インターフェースとして連想してしまいますが、捉え方を少し変えてみます。
今回僕たちが繋いだのは、人間 と_プレゼン_ です。それらの境界として、指は含まれているでしょう。
次世代型インターフェース(仮)をどう実現したのか
HyPreの要件として、
- 指パッチンを始めとした、プレゼンでよく使われる音を認識することができる
- keynoteやPower Pointに対して、スライド送りや暗転の命令を送信することができる
- 認識した音によって命令をコントロールし、プレゼンテーションアプリに命令を送ることができる
が挙げられます。1番ハードルが高そうなのは2つ目でしょうか。
Windowsではどうすればいいのか知りませんが、macOSにはApple Scriptがあります。例えば、
osascript -e 'tell application "keynote"
activate
tell application "System Events"
keystroke return
end tell
end tell'
をターミナルで実行することで、keynoteに対してリターンキーのキーストロークの命令を送ることが可能です。
(osascriptをターミナルから実行するためには、ターミナルのアプリをアクセシビリティに登録しておく必要があります。)
スライド送りとは、即ちリターンキーを押下することに相当するので、Apple Scriptでreturn命令を送ることで実現させます(暗転はbをストローク)。
音の認識方法
音の認識には、AlexNetを使っています。音声データをメルケプストラムという2次元データ構造に変換し、画像/物体認識で有名なDeep Learningのモデルに学習をさせます。
マイク入力からメルケプストラムまでの変換は、こちらをめちゃくちゃ参考にさせていただきました。
モデルの構成
モデルは、Kerasを使って、ドットつなぎで書けるようにしてあります。
ドット×Deep Learningで流れを意識したモデリング
alexnet = model \
.input(conf.dims) \
.conv2d(48, 11, strides=(2, 3)) \
.max_pooling2d(3, strides=(1, 2)) \
.normalize() \
.conv2d(128, 5, strides=(2, 3)) \
.max_pooling2d(3, strides=(2, 1)) \
.normalize() \
.conv2d(192, 3, strides=(1, 2)) \
.conv2d(192, 3, strides=(1, 1)) \
.conv2d(128, 3, strides=(1, 1)) \
.max_pooling2d(3, strides=(1, 2)) \
.normalize() \
.flatten() \
.dense(256) \
.dropout(0.5) \
.dense(256) \
.dropout(0.5) \
.dense(conf.num_classes, activation='softmax')
まあ何の変哲もないAlexNetかなと。
学習する上で注意したこと
高い周波数、早い減衰が特徴です。他にそういった音を探してみると、実は結構見つかります。
- 爪を切る音
- 机などを叩くこと
- キーボードを押す音
HyPre使用中はキーボード使わないですし、プレゼン中に詰めを切る人もいないでしょう。
でも、机や椅子の脚にものをぶつける音などは、プレゼン中にも起こり得ると判断できます。
指パッチンやその他の音を学習させる上では、そういった音から、周波数、減衰の速さなどから明確に差別化することのできる音声データとカテゴリを混ぜ込む必要があります。
実際に学習に用いた音声データのカテゴリとしては、
- 指パッチン
- ベル
- ゴング
- ハサミで紙を切る音
- ドアをノックする音
- 話者の話し声
などです。ハサミと指パッチンの僅かな減衰の差であったり、減衰が似ていても周波数に差がでるノック音などを混ぜ込んであります。
最後の話者の話し声は、スピーチを誤認識して、プレゼンテーションアプリに命令が送られることがないよう、明確にカテゴライズしてあります。
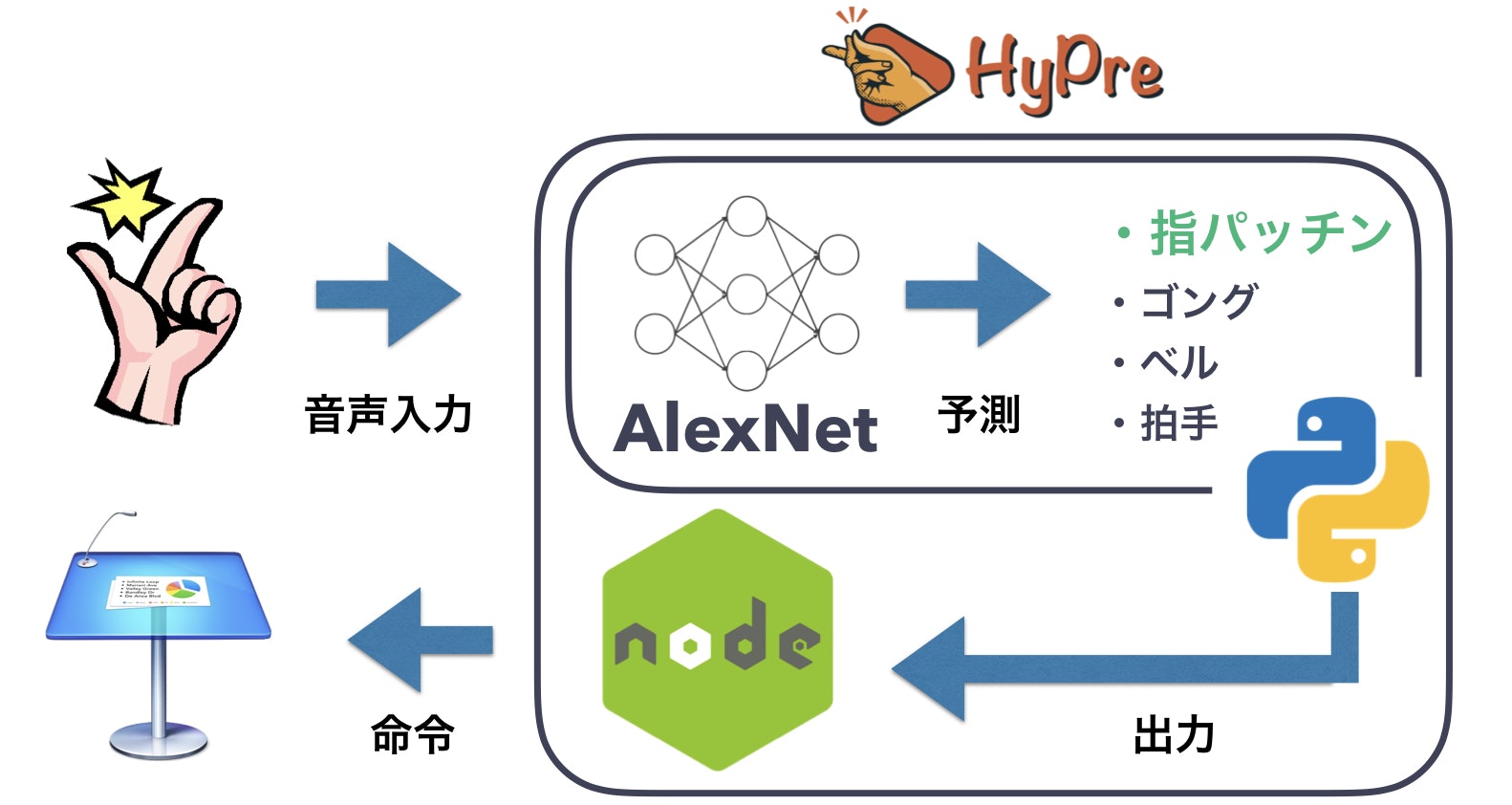
HyPreのアーキテクチャ
プレゼンテーション中にアプリをフロントに出しておくことはできない(プレゼンテーションアプリが全画面表示になる)ため、そもそも常にviewを持っている必要はありません。最低限、裏で音を認識してApple Scriptを叩いてくれれば、これまでの内容からきちんと動作しそうだとわかるので、常駐型のアプリケーションとして作成します。
さて、候補は次の2つになります。
- Swiftで常駐型デスクトップアプリを作成 & 音の認識はCoreMLで学習済みデータを使用
- 音声認識用にPythonプロセスを裏で立ち上げ、フロントアプリと通信させる
後者を採用しました。理由としては、Swift側からApple Scriptの命令が上手く送信できなかったことと、チームメンバーのスキルセットから決定をしました。アプリにはElectronを使用しました。
フロー図
実際の処理のフローはこのようになっています。
今後どうするか
できるだけ早く、OSSとしてGitHubでリリースしたいとチーム全員が考えています。
(一応PublicでGitHubに置いてます。)
現状の問題点は一重に、Pythonのプロセスに依存している(認識/マイク入力からメルケプストラムへの変換)だと言えます。
解決策として、TensorFlow.jsの利用とJSをゴリゴリ書くというアプローチをとります。
実装が完了次第アプリとしてリリースするので、是非プレゼンテーションでイキってもらえればと思います!