はじめに
背景
MPIに関する、ロボ太氏のこのtweetを見て、そう言えばどうやって(主に標準出力のとりまとめに関して)各プロセスが連携してるのかな、という点とバッファ制御が気になったためざっくり調べてみました。
注意
今回特に、環境等詳細に書いてませんので、鵜呑みにせず必ず自分で裏を取ってご利用ください。
加えて、用語についても結構テキトーにつけたものを使ったりしていますのでご注意を。
なお、試したのはLinux環境で、MPIとしてはIntel, SGI-MPT, OpenMPIの3種類です。また、Fortranについては一切触れていません。C/C++が対象です。
標準出力のバッファリングって
バッファリングって?
先に一応「バッファリング」について。
標準出力からデータを出力する場合、Cならばstdout、C++ならばstd::coutを通じて行うわけですが、printfやstd::ostream::operator<<を呼んだからと言って、即座に出力が反映されるとは限りません。
なぜならば、実際に出力を担当するOSのAPI(writeやsend)を細切れに呼ぶのは、一般に性能的に不利ということになっており、標準ライブラリではそれをある程度バッファーに溜めて塊にして、一括で吐き出すようにしているからです。
この挙動をバッファリングと呼びます。
標準ライブラリでのバッファリング
バッファリングには次の3種類のモードが用意されています。
- アンバッファード
バッファリング無効、出力関数を呼ぶたびに即座に吐き出す - フルバッファード
バッファーが一杯になるか、flush操作を行うまで出力をため込む - 行バッファード
フルバッファードに近いが、改行があると行単位で吐き出す
Cのstdioの場合、制御はsetbuf/setvbufで行います。デフォルトの制御は、標準出力が接続されているファイル/デバイスによって変わり、TTY/PTYの場合は行バッファード、それ以外はフルバッファードです。
なお、flush操作はfflush関数で行います。
C++のiostream場合、制御はstd::ios_base::unitbufというフラグをstd::coutにセットするかどうか(std::cout.setfあるいはunsetf)で行います。セットしていればアンバッファード、セットしていなければフルバッファードで、行バッファードはありません。デフォルトはフルバッファードです。
なお、flush操作はI/Oマニピュレータstd::flushあるいはstd::endlで行います。
…と、このようにC,C++で制御が別になっているのですが、C/C++コード混在のケースで出力の順序が乱れると通常は困りますので、デフォルトで両者が同期するようになっています。
つまり、C++側でフルバッファードになっていても、C側がそうでない場合、C側に引っ張られることになります。
ただこの挙動は、std::ios_base::sync_with_stdio(false) によって無効化できます。
MPIの仕組み
仕組み概要
MPIが何かとざっくり言うと、動員できるノードやら実行するプロセス数を指定すると、複数ノードで同一の ( 場合によってはヘテロな場合も ) プログラムを起動して、協調して計算を行うためのフレームワーク、ライブラリ、ツール群のことです。
そこで、起動したプログラム間の連携として、InfiniBand等の高速ネットワークを…とか色々あるのですが、今回考えるのは「標準出力の流れ」です。なので、次の図のような三者を考えれば十分です。
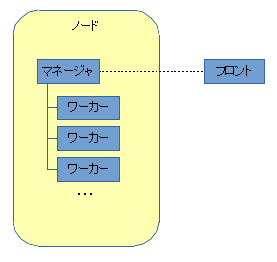
これは勝手につけた用語ですが、
- フロント
要するに、mpirunやmpiexec等、MPIを起動し全体を統括するツール。最終的な標準出力のとりまとめ役でもある。 - マネージャ
各ノード(複数)上で動くプログラムを管理するプログラム - ワーカー
MPIのフレームワークに従って動作する一般のアプリケーション、目的に沿った計算処理を担当する
という分類になります。
なお、上の図ではフロントとそれ以外があたかも別ノードで動くかのように描いていますが、同じである可能性もあります。
MPI毎の違い
Intel MPI
まずはIntel MPIです。大体次の図のようになっています。
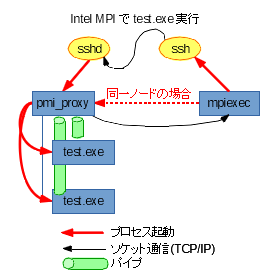
役割と対応は次の通りです。
- フロント
mpiexec ( mpirun等で起動しても呼ばれるのは mpiexec ) が該当します。
昔は予め mpd を起動しておいて…という方式が多かったのですが、今は hydra と呼ばれる、mpd を介さない方式がおそらく標準です。( なので正確には mpiexec.hydra というべきか ) - マネージャ
pmi_proxy が該当します。
自ノードの場合はフロントから直に、遠隔ノードの場合は、ssh を使って起動します。
※ただし slurm 等のリソースマネージャ/ジョブスケジューラが代わりになる環境もありえます。これはOpenMPIでも同様です。
マネージャは、起動後フロントにTCP/IPで接続を行い、ワーカーからパイプで渡された出力を集約してフロントに送ります。
※余談ですが、フロントがlistenするポートは基本不定なので(環境変数等である程度絞れるとは言え)、ファイアウォールでマジメに制御しようとすると大変です。
SGI MPT
次はSGI MPTです。
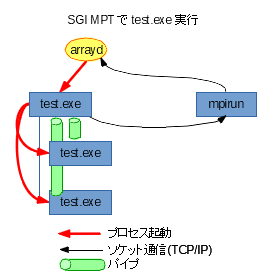
役割と対応は次の通りです。
- フロント
mpirun が該当します。 - マネージャ
特別なプログラムは実はなく、ワーカーとして指定したプログラムがマネージャとして振る舞います。
※なので他のMPIに慣れてると奇妙に思えるかもしれませんが、mpirunでシェルスクリプトを指定した場合、スクリプト自体は1プロセスしか起動せず、そこから呼び出されたMPIプログラムがワーカーを(複数)生み出すことになります
役割分担については先ほどのIntel MPIに似てますが、フロントからマネージャの起動は、SGI MPT付属のarraydというデーモンを ( たとえローカルノードであっても ) 要します。
OpenMPI
最後にOpenMPIです。
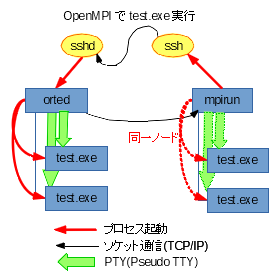
役割と対応は次の通りです。
- フロント
mpirun が該当します。 - マネージャ
ortedが該当します。が、ローカルノードの場合は、mpirunがマネージャを兼任し、直接ワーカーを起動します。
上2つのMPIと大きく違うのは、ローカルノードの扱いについてもそうなのですが、マネージャ・ワーカー間の遣り取りがPTYになるところです。
※なので、wallとかshutdownで一斉通知があると、出力が混信することになるのでは…?
MPIでの標準出力のバッファリング
出力経路の再整理
MPIプログラムで出力を行った場合、それが最終的にフロントに集約されて出力される時、どうなっているかという所を見ていきます。
上で整理した通り、MPI実行時はフロント・マネージャ・ワーカーの3種類のプログラムが連携します。そして、ワーカーの出力はマネージャを経由してフロントに集約されます。
なので、バッファリングについても、その経路毎に整理する必要があります。すなわち、
- ワーカー→マネージャ
- マネージャ→フロント
- フロント→最終的な出力先
の3か所です。
MPI毎のバッファリングの相違
Intel MPI
Intel MPIの場合、行の途中でも平気で各ワーカーの出力が混じる挙動を示します。つまりバッファリングが無効化されているように見えます。
これは、MPI_Init時にMPIライブラリが内部的にsetbuf/setvbufを呼んでワーカーをアンバッファード状態にすることが原因です。
つまり、ワーカー→マネージャの部分がバッファリング無効、マネージャ→フロント、フロント→最終的な出力先では特に制御なくそのまま垂れ流すので、全体としてバッファリング無効に見えるということです。
そのため、MPI_Init後に、setbuf/setvbufを呼んでバッファリングを再度設定すれば、バッファリングを有効にすることができます。
なお、MPI_InitあるいはMPI:Initどちらでも、std::coutのフラグ変更は行っていないようなので、pure C++なアプリであれば、C,C++の同期を無効化することでもバッファリングが有効になります。
※2018/10/21追記: @n_so5 さんにコメント頂いた通り、mpiexec時のオプション-ordered-outputにより行バッファード相当の動きになるようです。それであれば setbuf/setvbuf は必要なくなるでしょう。ただし、出力の最後の改行を忘れないようにと、マニュアルに注意書きがありました。また、標準エラーも影響を受けるようです。以下、Intel MPI 2019 Developer Reference2.3.1章より抜粋します。
-ordered-output
Use this option to avoid intermingling of data output from the MPI processes. This option affects both the standard output and the standard error streams.
NOTE
When using this option, end the last output line of each process with the end-of-line '\n' character. Otherwise the application may stop responding.
SGI MPT
SGI MPTの場合、行単位で出力がまとまっている、行バッファード相当の挙動を示します。
この裏の仕組みはちょっと複雑になっています。
- ワーカー→マネージャ
Intel MPIと同じく、MPI_Init時にアンバッファード状態にする - マネージャ→フロント
特に制御なし - フロント→最終的な出力先
フロントがワーカー毎に出力を分別して独自にバッファリングする ( 行バッファード )
つまり、フロントの頑張りによってバッファリングがなされているということです。逆に言えば、MPIアプリ(ワーカー)側で勝手にバッファ制御をさせたくない、ということかもしれません。
OpenMPI
OpenMPIも、SGI MPTと同様、行バッファード相当の挙動を示します。
この仕組みは非常に単純で、ワーカー→マネージャ間の出力がPTYであり、それに対するstdoutの制御がデフォルトで行バッファードになるからです。その他マネージャ→フロント、フロント→最終的な出力先で特別何か制御しているようには見えません。
つまり、OpenMPI自体はバッファリング制御に特に手出しはせず、標準ライブラリに任せている格好になります。
まとめ
ということで、各MPIでの制御の違いを見てきました。
それぞれのMPIで違いはあるものの、確実にバッファリングを効かせたいのであれば、MPI_Init直後にsetbuf/setvbufを呼ぶのが良いのではないかと思います。
※2018/10/21 追記: Intel MPIも実行時オプション-ordered-outputで行バッファード相当にできるので、今回取り上げた3つのMPIの場合、プログラム側に手を入れなくても良さそうです。
参考
以下、Intel MPIで挙動を試した時のソースと操作ログを参考までに載せておきます。
$ cat /etc/centos-release
CentOS Linux release 7.4.1708 (Core)
$ mpirun --version
Intel(R) MPI Library for Linux* OS, Version 2018 Update 1 Build 20171011 (id: 17941)
Copyright (C) 2003-2017, Intel Corporation. All rights reserved.
$ icpc --version
icpc (ICC) 18.0.1 20171018
Copyright (C) 1985-2017 Intel Corporation. All rights reserved.
$ mpiicpc -std=gnu++11 -o test test.cpp
$ mpirun -np 2 ./test
abababababababababbababababababababababa
abababababababababababababababababababab
a
bbabaababababababababababababababababab
a
bababbaababababbaababababababababababab
babaabababababababababababababababababab
$ mpirun -np 2 ./test --nosync
aaaaaaaaaaaaaaaaaaaa
bbbbbbbbbbbbbbbbbbbb
aaaaaaaaaaaaaaaaaaaa
bbbbbbbbbbbbbbbbbbbb
aaaaaaaaaaaaaaaaaaaa
bbbbbbbbbbbbbbbbbbbb
aaaaaaaaaaaaaaaaaaaa
bbbbbbbbbbbbbbbbbbbb
aaaaaaaaaaaaaaaaaaaa
bbbbbbbbbbbbbbbbbbbb
$ mpirun -np 2 ./test --setvbuf
aaaaaaaaaaaaaaaaaaaa
bbbbbbbbbbbbbbbbbbbb
aaaaaaaaaaaaaaaaaaaa
bbbbbbbbbbbbbbbbbbbb
aaaaaaaaaaaaaaaaaaaa
bbbbbbbbbbbbbbbbbbbb
aaaaaaaaaaaaaaaaaaaa
bbbbbbbbbbbbbbbbbbbb
aaaaaaaaaaaaaaaaaaaa
bbbbbbbbbbbbbbbbbbbb
$ mpirun -np 2 ./test --nosync --unitbuf
abababbaabababababababababababababababab
a
bababababababababababababababababababab
babababababababababababababababababababa
ababababbabababababababababababababababa
abababababababababababababababababababab
$ mpiicpc -std=gnu++11 -o test2 test2.cpp
$ mpirun -np 2 ./test2
abababababbaababababababbaababababababab
babaabababbaabababababababababababababab
babababababababababababababababababababa
ababababbaabababababbabaabababababababab
a
bababababababababababababababababababab
$ mpirun -np 2 ./test2 -f
aaaaaaaaaaaaaaaaaaaa
aaaaaaaaaaaaaaaaaaaa
aaaaaaaaaaaaaaaaaaaa
aaaaaaaaaaaaaaaaaaaa
aaaaaaaaaaaaaaaaaaaa
bbbbbbbbbbbbbbbbbbbb
bbbbbbbbbbbbbbbbbbbb
bbbbbbbbbbbbbbbbbbbb
bbbbbbbbbbbbbbbbbbbb
bbbbbbbbbbbbbbbbbbbb
$ mpirun -np 2 ./test2 -l
aaaaaaaaaaaaaaaaaaaa
bbbbbbbbbbbbbbbbbbbb
aaaaaaaaaaaaaaaaaaaa
bbbbbbbbbbbbbbbbbbbb
aaaaaaaaaaaaaaaaaaaa
bbbbbbbbbbbbbbbbbbbb
aaaaaaaaaaaaaaaaaaaa
bbbbbbbbbbbbbbbbbbbb
aaaaaaaaaaaaaaaaaaaa
bbbbbbbbbbbbbbbbbbbb
$
# include <mpi.h>
# include <iostream>
# include <thread>
# include <string>
# include <cstdio>
static char stdoutbuf[8192];
int main(int argc, char **argv) {
MPI::Init(argc,argv);
MPI::COMM_WORLD.Set_errhandler(MPI::ERRORS_THROW_EXCEPTIONS);
int rank = MPI::COMM_WORLD.Get_rank();
for ( int i=1; i<argc; i++ ) {
std::string opt(argv[i]);
if ( opt == "--nosync" ) {
// detach C++-iostream from C-stdio
std::ios_base::sync_with_stdio(false);
}
else if ( opt == "--setvbuf" ) {
// re-setvbuf for C-stdio
std::setvbuf(stdout,stdoutbuf,_IOFBF,sizeof(stdoutbuf));
}
else if ( opt == "--unitbuf" ) {
// disable buffering on C++-iostream
std::cout.setf(std::ios_base::unitbuf);
}
else if ( rank == 0 ) {
std::cerr << "invalid option: " << opt << std::endl;
std::this_thread::sleep_for(std::chrono::milliseconds(10));
}
}
char c='a'+rank;
for ( int i=0; i<5; i++ ) {
MPI::COMM_WORLD.Barrier();
for ( int j=0; j<20; j++ ) {
std::cout << c;
std::this_thread::sleep_for(std::chrono::milliseconds(10));
}
std::cout << std::endl;
}
MPI::Finalize();
}
# include <mpi.h>
# include <iostream>
# include <thread>
# include <string>
# include <cstdio>
static char stdoutbuf[8192];
int main(int argc, char **argv) {
MPI::Init(argc,argv);
MPI::COMM_WORLD.Set_errhandler(MPI::ERRORS_THROW_EXCEPTIONS);
int rank = MPI::COMM_WORLD.Get_rank();
if ( argc > 1 ) {
std::string opt(argv[1]);
if ( opt == "-f" ) {
// full buffered
std::setvbuf(stdout,stdoutbuf,_IOFBF,sizeof(stdoutbuf));
}
else if ( opt == "-l" ) {
// line buffered
std::setvbuf(stdout,stdoutbuf,_IOLBF,sizeof(stdoutbuf));
}
}
char c='a'+rank;
for ( int i=0; i<5; i++ ) {
MPI::COMM_WORLD.Barrier();
for ( int j=0; j<20; j++ ) {
std::cout << c;
std::this_thread::sleep_for(std::chrono::milliseconds(10));
}
std::cout << '\n';
}
std::cout << std::flush;
MPI::Finalize();
}