導入
今年のAdvent Calendarとして、既にWhitespaceでFizzBuzz(207bytes)を公開したのですが、既存のQuine実装 ( WhiteSpaceでQuine(406B) ) を見直している中でもっと縮められることに気付いたため、2日遅れになりましたが「esolang Advent Calendar 2022」の一環(12/23分)として記事にしたものです。
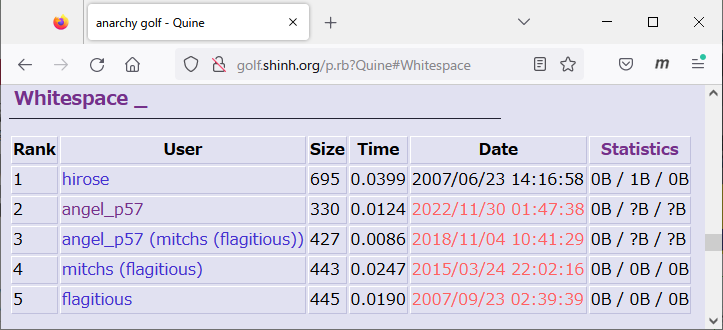
新実装では、コード文字数330bytesを実現し、次のようにanagolのQuine問題に投稿済みとなっています。
※stackexchangeのQuine問題にも簡単に解説を投稿しています。
実装内容
実装方針
Quineの実装方法については、以前の406B版の解説等でも触れているのですが、Whitespace の場合は「本体コードを3進法でエンコードした数値を最初に push する」「その最初の push 命令に相当する文字列を出力する ( あるいは出力予約する )」「エンコードした数値をデコードして出力する」という3段階を踏むのが現実的です。
その上で、前回の実装を見直したところ、2点実装として改善の余地がありました。
- デコード方法の効率化
3進法の桁 0,1,2 から、実際に出力する s,t,n の文字コード 32,9,10 への変換処理がデコードの中心となりますので、より簡単な数式 ( 演算回数の少ない数式 ) の方が、コード長的にも有利となります。
そうして前回の数式 $c=mod(−23d,−24)+32$ を見ると、演算回数は掛け算×1、剰余算×1、加算×1 の計3回です。しかし、実は $c=mod(d,−24)+32$ でも十分で、掛け算1回分を節約することができます。そのため、今回はこちらの数式でデコードを実装しました。
※前回のコードに適用するだけでも、30文字程度の短縮効果があるはずです。 - 処理の共通化
「最初の push 命令に相当する文字列を出力する」「エンコードした数値をデコードする」この2つは単純化して考えると、前者は2進数の展開、後者は3進数の展開ということで、n進数の展開という意味では類似の処理になっています。
以前のコードでは両者を別々に実装していたわけですが、効率よく共通のコードにまとめられれば全体の短縮につながります。ということで、今回はn進法のnの部分もパラメータにとる共通関数として実装しました。
コード全体
では、実装内容の説明にあたり、まずは Quine 330B のコード全体を示します。
でまあ、お約束ながら空白文字だけだとさっぱり見えませんので、空白・タブ・改行を s,t,n に変換したバージョンと、以前の記事WhiteSpaceアセンブラ・逆アセンブラの紹介で変換したコードを載せます。以降、この変換したコードの方で説明を行います。
sssttstssstttttttsttsstsstttssstststttsssstttststtstttttsttssssssstttstttttttttstttssstssstsstssstttststtstssttsstttsssststttsstststtttttssttsssssstssstststtttststtsststttssstsststtssssssststsstssssssssssnssstsssssnsnstnsstnsssnsssstsnnstnsssttnnssnsntstsstntstssnsntssnsnsstsstsnnstnnsssnsnttsttsstttsssntsttssstsssssntssstnssntn
push +2636263872820036273590233982665123397718151559108318308901888(201b) # 0000: sssttstssstttttttsttsstsstttssstststttsssstttststtstttttsttssssssstttstttttttttstttssstssstsstssstttststtstssttsstttsssststttsstststtttttssttsssssstssstststtttststtsststttssstsststtssssssststsstssssssssssn
push +32(6b) # 0205: ssstsssssn
dup # 0215: sns
putc # 0218: tnss
putc # 0222: tnss
dup # 0226: sns
push +2(2b) # 0229: ssstsn
call null # 0235: nstn
push +3(2b) # 0239: sssttn
mark null # 0245: nssn
swap # 0249: snt
copy +1(1b) # 0252: stsstn
div # 0258: tsts
dup # 0262: sns
jzero +0(0b) # 0265: ntssn
dup # 0270: sns
copy +2(2b) # 0273: stsstsn
call null # 0280: nstn
mark +0(0b) # 0284: nsssn
swap # 0289: snt
mod # 0292: tstt
push -24(5b) # 0296: sstttsssn
mod # 0305: tstt
push +32(6b) # 0309: ssstsssssn
add # 0319: tsss
putc # 0323: tnss
ret # 0327: ntn
デコード処理詳細
実装方針の章でも説明した通り、共通化デコード処理の部分がQuineの中核となるのですが、n進法の展開をする上で1つ問題となる点があります。
それは、最上位の桁は必ず非0となるという点です。例えば 196=0b11000100 という数字がある場合、それを push するコードは sssttssstssn であって、0 の桁に相当する s が先頭に3つ余分に現れた形になっています。しかし、桁数を明示的に設定でもしない限り、先頭にこの3つの0を余分につけて2進数展開処理するのは無理があります。
ここは仕方がないので、先頭の2つは2行目 ( 205B目 ) の push +32 からの3行分の処理で個別に出力を行い、1つはn進数展開の中で吸収するようにしました。
※個別出力の数を増やすと、1文字で20文字弱はコード長が嵩むので、共通化のメリットを食い潰すおそれがあります。
上位の桁を先に出力する関係上、再帰で組むことになりますが、分岐処理の数の節約も考慮し、次の疑似Rubyコードのような実装としました。実際のコードでは10行目 ( 245B目 ) の mark null 以降、最後までの部分が該当します。
※ DECODE は、実装方針の章で説明した $c=mod(d,−24)+32$ の計算
def n_adic_expand(x,n)
x /= n
if x != 0
n_adic_expand(x,n)
end
putc DECODE(x % n)
end
これにより、先ほど例に挙げた 196=0b11000100 の場合、末尾1桁を削った上で先頭にsを付け足し、sttsssts という出力が得られます。
ここで、末尾1桁を削ったのは、次の3進数展開の結果をつなげることを考慮したものです。
今度 196=21021(3) を処理した場合、同じく末尾1桁を削って先頭に s を付け足すと、出力は sntsn となります。最初の個別の s×2 出力も併せると ss+sttsssts+sntsn → sssttssstssn + tsn ということで、push 196 に相当する sssttssstssn の部分が吸収できています。この場合のデコードされたコードは 3進数展開して先頭と末尾を削った tsn ということになります。
逆に言うと、XXXXX という本体コードをエンコードする場合、nXXXXXs あるいは nXXXXXt と先頭・末尾に付け足した上で3進数評価します。先頭は n で固定、末尾は3進数評価した結果が偶数になるように s,t を選びます。
これで共通処理の関数部分が定義できました。後は、6行目 ( 226B目 ) 以降の処理で、最初は2を引数として call、次は 3 を引数として call する代わりに直接 mark 以降の処理に進んで実行するのみです。
※3進数展開の処理から ret で戻る必要はないので、2回目は mark に直接進むだけで済みます。最後の ret は戻る場所がないのでエラーで終了します。
おまけ:さらなる短縮ネタ?
さて、短縮済みコードを見てみると、実はもう1点気になるところが残っています。
それは、冒頭の空白2文字出力用の push +32 です。
anagol や ideone の Whitespace 実装では、256を超える数字を putc した場合、mod 256 とした文字コードで出力が行われるという挙動が見られます。
であれば、敢えて 32 を push しなくても、最初に push したエンコード済みデータを使いまわしして、もっと文字数の短い dup で代替する道があるのではないか? という点です。
その場合、エンコード済みデータを mod 256 で 32 の数値となるよう調整が必要となります。そして実のところその調整自体には成功しました。ところが別の面で不都合があり、そもそもコード実行に失敗してしまう結果となりました。
失敗の理由については、あくまで処理系の挙動を見た上での推測となりますが、単に mod 256 した文字コードで出力するだけでなく、数値の下位22~32ビット目が全て 0 になっていることの確認を先に行っていることが原因のように見えました。調整した数値は非常に大きいもので、下位22~32ビット目に 1 となるビットがあったため、それにより putc した瞬間にエラーとなり、実行に失敗してしまったということになります。
※もっと突っ込んで言うと、インタープリタの実行環境である Haskell が、下位32bit 部分で Unicode としての有効範囲 ( 0~0x10FFFF ) に収まっているかのチェックを行っているのではないかと推測しています。
mod 256 での調整だけなら 1/256 の確率なのでなんとかできるにしても、更に 11bit 分の調整が必要となると、流石にそう都合の良い数値を見つけることができませんでした。
残念な結果ですが、一歩実行環境の内部に踏み込んで挙動を知ることができたと前向きに捉えるところかなと思います。
おわりに
これで、Jellyfish版Quine、Functional()版Quineときて、2022年末でのQuineネタは以上となります。
既に十分縮めたと思っていても、まだまだネタが残っている場合もあるため、皆さんもお好みの言語でQuineを見直してみるのも楽しめるのではないでしょうか。