はじめに
背景
これは、「多言語FizzBuzz Advent Calendar 2022」]の一環(12/11分)として、esolangの1つであるWhitespaceでFizzBuzzを「golf的に(なるべく短く)」実装したものです。
結果、コード文字数207bytesを実現し、anagolのFizzBuzzで1位となりました。
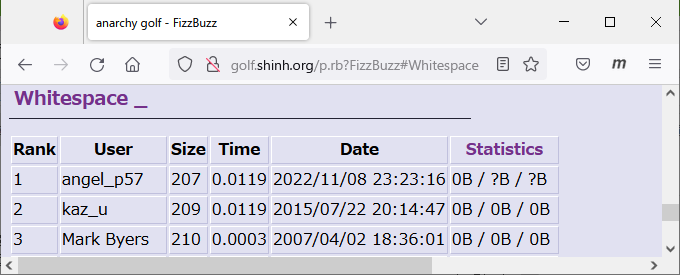
なお、本記事に先駆けてこのコードでエラー終了を解消した210bytes版をStackExchangeにも投稿しています。
WhiteSpaceについて
WhiteSpaceについては、以前の記事WhiteSpaceアセンブラ・逆アセンブラの紹介をご参照ください。
コードについても、そちらのツールでの書式に合わせて記載します。
なお、WhiteSpace を実行できるオンライン環境の中で、前述の anagol あるいは ideone.com では本コードの結果に再現性があるものの、tio.run では文字化けを起こして FizzBuzz としては不成立のコードになってしまいます。その点ご注意ください。
FizzBuzz実装
コード全体
まず、207Bのコード全体を以下に示します。
こちらにideoneでのオンライン実行結果もあります。
…。まあ、スペース・タブ・改行だけなので ( ボックス内を選択すれば浮かび上がりはするのですが ) ほとんど見えないと思います。そこで、次の、スペース・タブ・改行を s,t,n に変換したものの方がまだ見易いかも知れません。
sssnnsssnssstntssssnsssststtstsstnsstttnnstnssstttstttststnssttstnnstntssnntstnsnstnstnsstnssststsnsnssnstnsstssntsstnttsnnnnnssnstssttnsnttsttnttssnsnssssttsssstntstttnsstnsssssttttstsnsnstnsstnsssssnnssssnntn
ただ、これでもコードの内容の把握は厳しいと思いますので、以前の記事でも紹介した逆アセンブラで変換したコードを載せ、こちらをベースに解説していきます。
push +0(0b) # 0000: sssn
mark +0(0b) # 0004: nsssn
push +1(1b) # 0009: ssstn
add # 0014: tsss
dup # 0018: sns
push +361(9b) # 0021: ssststtstsstn
push -3(2b) # 0034: sstttn
call null # 0040: nstn
push +1909(11b) # 0044: ssstttstttststn
push -5(3b) # 0059: ssttstn
call null # 0066: nstn
mul # 0070: tssn
jzero -0(0b) # 0074: ntstn
dup # 0079: sns
puti # 0082: tnst
mark -0(0b) # 0086: nsstn
push +10(4b) # 0091: ssststsn
dup # 0099: sns
dup # 0102: sns
putc # 0105: tnss
mul # 0109: tssn
sub # 0113: tsst
jneg +0(0b) # 0117: nttsn
mark null # 0122: nssn
copy +3(2b) # 0126: stssttn
swap # 0133: snt
mod # 0136: tstt
jneg +0(1b) # 0140: nttssn
dup # 0146: sns
push +97(7b) # 0149: sssttsssstn
mod # 0160: tstt
putc # 0164: tnss
putc # 0168: tnss
push +122(7b) # 0172: sssttttstsn
dup # 0183: sns
putc # 0186: tnss
putc # 0190: tnss
push +0(0b) # 0194: sssn
mark +0(1b) # 0198: nssssn
ret # 0204: ntn
コード概要
では、細部の説明に入る前に、概要ということで処理の全体構造を説明します。
Rubyで主要部分の疑似コードを書くと、次のようになっています。
$n = 0 # カウンタ初期化
loop {
$n += 1
# 第2引数に応じて倍数判定を行い、第1引数に対応する Fizz/Buzz を出力
# 出力した場合は 0、しなかった場合は非 0 を返す
ret1 = fizz_or_buzz(361, -3)
ret2 = fizz_or_buzz(1909, -5)
# Fizz/Buzz どちらも出力してなければ数値出力
if ret1*ret2 != 0 # ! ( ret1 == 0 || ret2 == 0 ) と同等
print $n
end
# 改行出力とループ継続判定
nl = 10
putc nl
if $n - nl*nl < 0
next
end
break
}
これが、逆アセンブルコードの先頭から 117B目の jneg +0(0b) までに対応します。
この疑似コードを見ても分かると思いますが、アルゴリズム自体に特に奇をてらったところはありません。
※アルゴリズム自体が素直になるのは、Whitespaceでのgolfの特徴です。
細かい工夫としては、後で説明する fizz_or_buzz ( Fizz/Buzzの出力 ) から、倍数判定結果を 0/非0 でそれぞれ返して ( スタックに残して )、70B目の乗算(mul)の結果によってOR判定を実現しているところ、それから改行出力用の 10 ( NL の ASCIIコード ) を再利用して 100 を作り出し、ループ継続判定に使っているところでしょうか。
※既にある10から100を作る場合、dup(sns) による10の複製×2 と mul(tssn) による乗算の計10文字で済むため、素直な push 100 (sssttsstssn) の11文字より1文字短縮できます。
なお、Whitespaceの条件分岐は、jzero ( 0の時分岐 ) と jneg ( 負数の時分岐 ) の2種類しかないため、特にループ継続を117B目のような jneg で行う ( 継続条件外ならループから抜けて、以降の処理でエラーになって終わるので、終了分の分岐命令が節約できる ) というのは、golf ではとてもありがちです。
短縮のポイント
そうすると、短縮のポイントとなるのは、前述の疑似コードで fizz_or_buzz としていた倍数判定と Fizz/Buzz の出力の部分です。
こちらのRubyでの疑似コードは次のようになります。
def fizz_or_buzz(prefix_num, div)
# 倍数でなかった場合は第1引数がそのまま返る
ret = prefix_num
if ! ( $n % div < 0 ) # $n は主処理でのカウンタ
putc prefix_num % 97
putc prefix_num # 自動的に % 256 扱いされる
z = 122
putc z
putc z
ret = 0
end
return ret
end
この関数本体に相当するのは、122B目の mark null 以降です。
こちらを、それぞれ Fizz/Buzz用に 40B目と66B目の call null で関数呼び出しして使っています。
ここで頭を悩ませるのは、両者の違いである出力文字列の Fi と Bu の文字コードをどう作り分けるかです。そこで今回、倍数判定に使う 3,5 あるいは -3,-5 を加工するのではなく、文字コードの素も一緒に渡して、加工の手間を減らそうと思いきったのが良い結果につながりました。
そのため、第2引数の -3, -5 は倍数判定用に剰余算で使って終わります。ここで負の除数にしているのは、倍数でない場合の剰余が負の数になることで、140B目の jneg +0(1b) で一気に処理を飛ばせるからです。
そして一番のポイントは、Fi または Bu の一方は全く加工無しで使うようにしたことです。
anagol あるいは ideone の Whitespace 実装では、指定した数値の mod 256 で文字出力されるため、無理に ASCIIコードぴったりに合わせる必要はないのです。
なお、文字コードが小さい方を加工後にした方が楽なので、2文字目の i(ASCII 105), u(ASCII 117) の出力用に、361 ( 256+105 ), 1909 ( 256×7+117 ) を採用しました。これの 97 による剰余 ( 149B目の push +97(7b) から 160B目の mod )が丁度 F (ASCII 70), B (ASCII 66) を産むということです。
こうして加工の手間を極力抑えることで、使用する数値の桁が若干嵩むものの、補って余りある短縮効果が得られました。
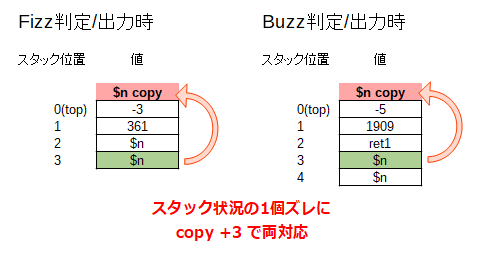
なお、1度目と2度目の関数呼び出しでは、戻り値を積んでいるかどうか、若干スタック状況に違いがあります。
その違いを吸収し、136B目の剰余算 mod に使う $n のコピー ( 126B目の copy +3(2b) ) を両対応できるよう、予め 18B目の dup で $n を複製しておいたのも細かい工夫です。
この複製のおかげで次の図のように、1個分のズレがあっても両対応できていることが分かります。
※この複製しておいた $n は、113B目からのループ継続判定処理で消費されるので、無駄になりません。
ところで、先ほど次のように説明しました。
anagol あるいは ideone の Whitespace 実装では、指定した数値の mod 256 で文字出力されるため、
ところが、tio.run の Whitespace実装は、インタプリタ自体の実装の違いか、あるいは実装に使っている Haskell自体の挙動の差か、256より大きい数値で putc しても、mod 256 されずに非ASCIIの文字が出力されてしまいます。
なので、今回の工夫は tio.run では使えないということになるようです。
おわりに
Whitespace は、使う文字こそ空白文字なので見辛いということもあり、敬遠されるかも知れませんが、いざ組んでみると結局は素直なアルゴリズムが一番短縮につながるため、結構golfとしての敷居が低いのではないかと思います。
この記事や私のツール等を参考に、挑戦してみるのも良いのではないでしょうか。