学習済みのmodelにtrainする
はじめに
はじめまして。私はpythonのword2vecで遊んでいる者です。初めての投稿になります。
趣味でやっているだけなので記述は美しくないかもしれません...
改善点等ありましたらコメントで教えていただけると助かります!
ソースコードや説明が甘いところがあるとは思いますが温かい目で見てくださると幸いです。
学習済みmodelをloadして、そこにtrainする記事が見当たらなかったので
備忘録として残しておきたかっただけです。
環境
・macOS Mojave -10.14
・python3 -3.6.1
・mecab(mecab-ipadic-neologdインストール済み)
・gensim -3.7.1(バージョンが低いと新規登録できない)
やりたいこと
学習済みのword2vecのmodelに新規単語を追加したい。
準備
環境整備
・python3等の環境を整える
参考:Python3の環境をささっと整える(Mac版)
・word2vecが使えるようにする(mecabやその辞書の関係も)
参考:[Python3で「Mecab」と「Word2vec」をインストールする方法]
(https://blog.seiyamaeda.com/15121)
・gensim word2vecで学習されたmodelを用意する
参考:[【Python】Word2Vecの使い方]
(https://qiita.com/kenta1984/items/93b64768494f971edf86)
環境を確認
・pythonのバージョン確認
$ python3 --version
ex: Python 3.6.1
・gensimのバージョン確認
$ pip list | grep gensim
ex: gensim 3.7.1
*低いバージョンのgensimがインストールされている場合(再インストール)
$ pip uninstall gensim
$ pip install gensim
やってみた
modelに無い単語がkeyErrorになることを確認
私はかなりのキモヲタなので、推しvtuberのベクトルを調べたいなってことで
現在の推し、ハニーストラップの『周防パトラ』を例にやってみます。

[【パトラちゃん様のtwitter】←]
(https://twitter.com/patra_hnst)
このw2v.getVec()は単語が未登録(KeyError)になると全ての要素が0のベクトルを返す仕様です。
# coding: utf-8
from gensim.models import word2vec
import logging
import sys
import numpy as np
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
class W2v():
MODEL = None
def __init__(self):
if W2v.MODEL is None:
#学習モデル読み込み
W2v.MODEL = word2vec.Word2Vec.load("./wiki.model")
def similarity(self, word1, word2):
try:
print("近似度計算: "+word1+" - "+word2)
return W2v.MODEL.wv.similarity(word1, word2)
except KeyError as e:
print(e)
return -1.0
def getVec(self, word):
try:
return W2v.MODEL.wv[word]
except KeyError:
return np.zeros(200)
if __name__ == "__main__":
w2v = W2v()
word = "周防パトラ"
print(word + "=")
print(w2v.getVec(word))
#単語数の確認
print(len(W2v.MODEL.wv.vocab))
実行結果:

残念ながら、『周防パトラ』は学習データに存在せずKeyErrorになりました。
ですが何としても推しベクトル?を学習させたい...。というわけでここからが本題です。
コーパス
そもそも、modelを学習させるためにはコーパスが必要です。
コーパスはmecabを使ってテキストを半角スペースで単語ごとに区切ったものです。
つまり、コーパスを作るにはmecabの辞書に登録したい単語や、その単語に関連する単語が
登録されていなければいけないのです。(まぁ、手動でやるのも手なんですけどネ...)
今回は"vtuber"や"ハニーストラップ"等の『周防パトラ』に関連性が高そうで
辞書に登録されていない単語を"ユーザー辞書"に登録していく必要があります。
未登録語を調べる
mecabに必要な単語を繋げた文字列を投げて物理的に確かめます。
import sys
import MeCab
m = MeCab.Tagger("-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd")
text = m.parse("周防パトラvtuberバーチャルユーチューバーハニーストラップいちからカニカマASMR蒼月エリ堰代ミコ西園寺メアリ島村シャルロット")
print(text)
実行結果:
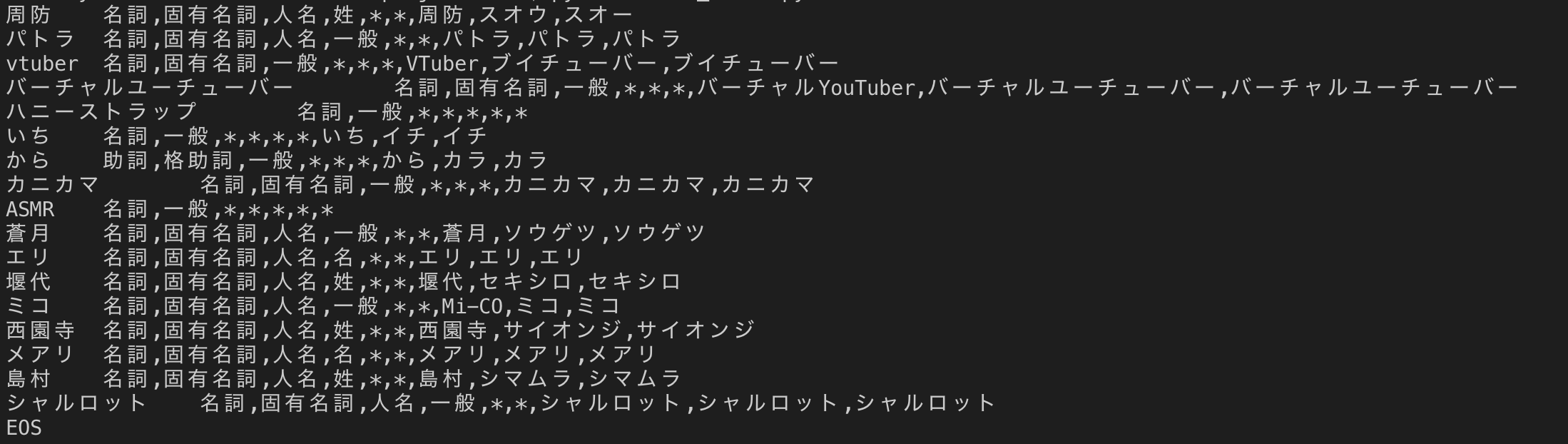
まぁ、思った通りの結果ですね。
というか、私がmodelを学習させた時には既にvtuberが話題になってたんだ...。
(しっかり"vtuber"がmecab-ipadic-neologdに登録されてるし...。)
固有名詞("周防パトラ"や"いちから")等は流石に登録されていませんでした。
"ハニーストラップ"はおそらく消去法で切り出されたのでしょう。
(ASMRもおんなじパターン???)
mecabの辞書って?
mecabは単語を切り分ける時、辞書を参照して単語を判定しています。
mecabには"システム辞書"と"ユーザー辞書"が存在していて
運用時には、一つの"システム辞書"と複数の"ユーザー辞書"を組み合わせることができます。
今回は"ユーザー辞書"に単語を登録していきます。
こちらを参考にさせてもらいました→[MeCabにユーザー辞書を追加する]
(https://qiita.com/urakarin/items/f975b006d6603bba606b)
ユーザー辞書生成:csvファイルを作る
周防パトラ,-1,-1,1,名詞,一般,*,*,*,*,*,*,*,mydic
ASMR,-1,-1,1,名詞,一般,*,*,*,*,*,*,*,mydic
ハニーストラップ,-1,-1,1,名詞,一般,*,*,*,*,*,*,*,mydic
いちから,-1,-1,1,名詞,一般,*,*,*,*,*,*,*,mydic
...
こんな感じのcsvファイルを作ります。本来ならこの作業もプログラムで
やったほうがいいですし、重みの設定とかもしたほうがいいですね。
まぁ、今回はメインじゃ無いので省きます。
ユーザー辞書生成:コンパイル
csvのままではmecabが辞書として使えないので、コンパイルが必要です。
以下のコマンドでコンパイルできます。通常はコピペでできるかと思います。
成功すると、user_dic.csvと同じディレクトリにuser_dic.dic
というファイルが生成されるはずです。
/usr/local/Cellar/mecab/0.996/libexec/mecab/mecab-dict-index \
-d /usr/local/lib/mecab/dic/ipadic \
-u user_dic.dic \
-f utf-8 \
-t utf-8 \
user_dic.csv
ユーザー辞書生成:mecabにPATHを設定
mecabにユーザー辞書の場所を教えなくてはなりません。
以下コマンドでファイルをviで開きます。
sudo vi /usr/local/etc/mecabrc
開くとこんな感じになってると思いますが、
;user_dic =
の所に先ほどコンパイルしてできたuser_dic.dicのパスを指定します。
;
; Configuration file of MeCab
;
; $Id: mecabrc.in,v 1.3 2006/05/29 15:36:08 taku-ku Exp $;
;
dicdir = ~~
; userdic = user_dic.dicのパス
; output-format-type = wakati
; input-buffer-size = 8192
; node-format = %m\n
; bos-format = %S\n
; eos-format = EOS\n
ユーザー辞書生成:確認
以下のコードでユーザー辞書が反映されているかを確認します。
import sys
import MeCab
m = MeCab.Tagger("-u 【user_dic.dicのパス】 -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd")
text = m.parse("周防パトラvtuberバーチャルユーチューバーハニーストラップいちからカニカマASMR蒼月エリ堰代ミコ西園寺メアリ島村シャルロット")
print(text)
実行結果:

ちゃんと先ほど登録した単語がパースされていますね。
これでようやくコーパスが作れます。
コーパスを作る
以下のコードでsuou_patra.txtをcorpus.txtにパースしていきます。
suou_patra.txtは『周防パトラ』をgoogleで検索してヒットしたページの
テキストのみを複数つなぎ合わせたものを、さらにコピペしてデータ量をかさ増し
しています。本当はhtmlを取ってきてやるのが良さそうなんですが、ここでは
地道に手作業です。最終的に60kB程になりました。これ、推しの情報を調べたので
苦ではありませんでしたが、そうでなければやりたく無い作業です;;
import MeCab
import re
import os
import sys
mecab = MeCab.Tagger('-u 【user_dic.dicのパス】 -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')
class Corpus:
def __init__(self, text):
self.text = text
self.formated = ""
self.corpus = []
self.format()
self.split()
def split(self):
node = mecab.parseToNode(str(self.formated))
while node:
PoS = node.feature.split(",")[0]
if PoS not in "BOS/EOS":#mecabの仕様で出てくるやつ、邪魔
self.corpus.append(node.surface)
node = node.next
def format(self):
ret= re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+', "", self.text)#URL
ret = re.sub(r"[0-9]+", "0", ret)#数字を0に
ret = re.sub(r"[!-/]", "", ret)#半角記号
ret = re.sub(r"[:-@]", "", ret)#半角記号
ret = re.sub(r"[[-`]", "", ret)#半角記号
ret = re.sub(r"[{|}-]", "", ret)#半角記号
ret = re.sub(r"[”’()【】〔〕《》=〜『』「」+*、。・_?!/◀▲:]", "", ret)#全角記号
ret = re.sub("[\n]", "", ret)#改行、スペース
self.formated = ret
def rtn_corpus(self):
ret = " ".join(self.corpus)
return ret
if __name__ == "__main__":
input_file = "suou_patra.txt"
output_file = "corpus.txt"
with open(input_file) as in_f:
lines = in_f.readlines()
with open(output_file, mode = "w") as out_f:
for l in lines:
text = Corpus(l).rtn_corpus()
out_f.write(text + " ")
実行すると、こんな感じのcorpus.txtが生成されていると思います。

新規単語が追加できるか試す
word2vecのmodelにはtrainという再学習のためのメソッドが用意されています。
古いバージョンではtrainしても新規単語を登録することはできませんでしたが、
最近のバージョンだとできるようになったようです。
では試しに以下のコードを実行してみます。
# coding: utf-8
from gensim.models import word2vec
import logging
import sys
import numpy as np
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
class W2v():
MODEL = None
def __init__(self):
if W2v.MODEL is None:
#学習モデル読み込み
W2v.MODEL = word2vec.Word2Vec.load("./wiki.model")
def similarity(self, word1, word2):
print("近似度計算: "+word1+" - "+word2)
try:
return W2v.MODEL.wv.similarity(word1, word2)
except KeyError as e:
print(e)
return -1.0
def getVec(self, word):
try:
return W2v.MODEL.wv[word]
except KeyError:
return np.zeros(200)
#再学習、上書きを行うメソッド
def updateTrain(self, corpus):
sentences = word2vec.Text8Corpus(corpus)
W2v.MODEL.build_vocab(sentences, update=True)
W2v.MODEL.train(sentences, total_examples=W2v.MODEL.corpus_count, epochs=W2v.MODEL.iter)
W2v.MODEL.save("wiki.model")
if __name__ == "__main__":
w2v = W2v()
word = "周防パトラ"
w2v.updateTrain("corpus.txt")
print(word + "=")
print(w2v.getVec(word))
#単語数の確認
print(len(W2v.MODEL.wv.vocab))
実行結果:
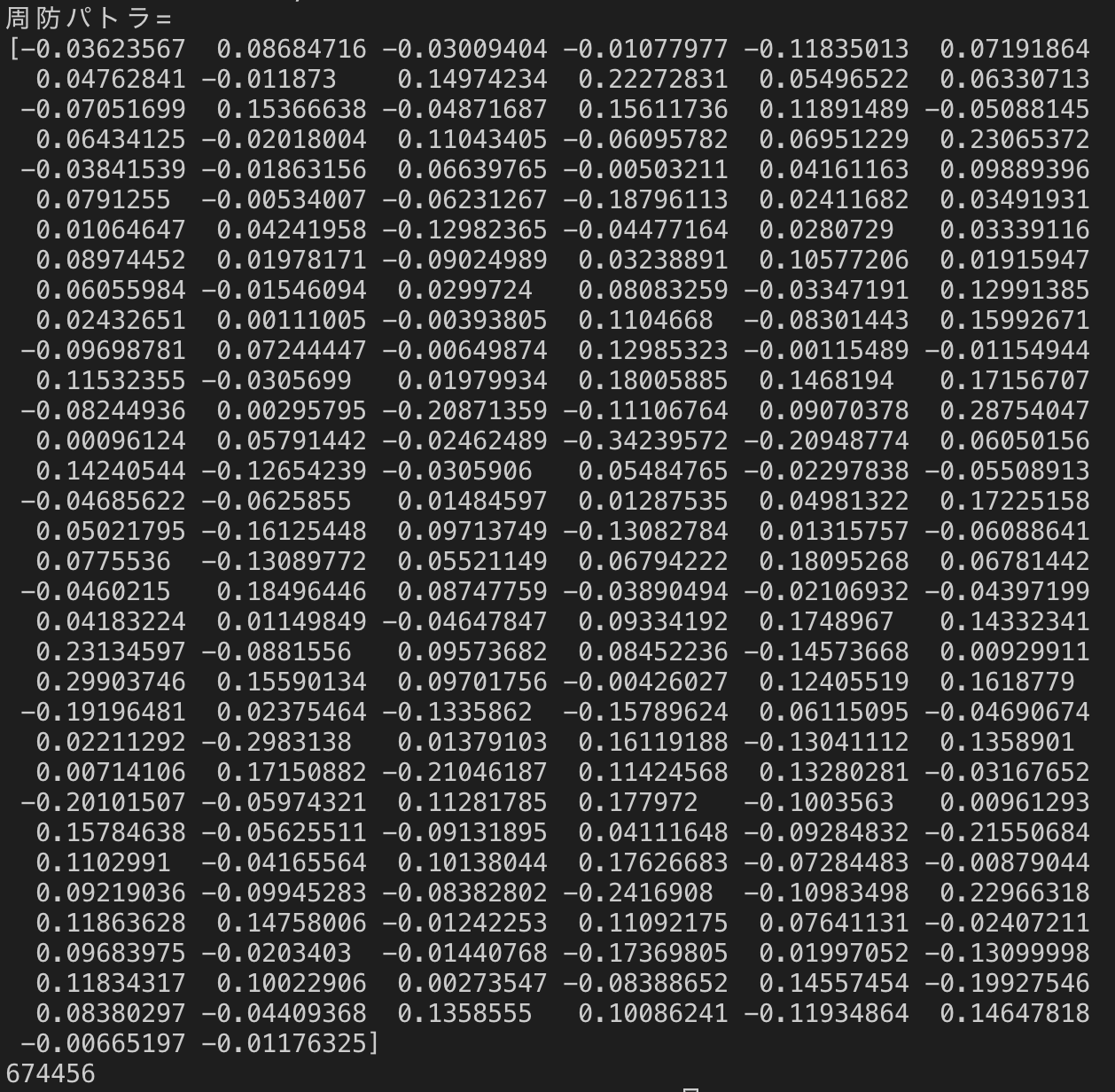
よっしゃ!『周防パトラ』のベクトルが追加学習できました!!!!
捕捉ですけど、単語数は674,450から6単語増えて674,456になってました。
遊んでみる
せっかくなので、類似度が高いものを10件取ってきてみます。
# coding: utf-8
from gensim.models import word2vec
import logging
import sys
import numpy as np
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
class W2v():
MODEL = None
def __init__(self):
if W2v.MODEL is None:
#学習モデル読み込み
W2v.MODEL = word2vec.Word2Vec.load("./wiki.model")
def similarity(self, word1, word2):
print("近似度計算: "+word1+" - "+word2)
try:
return W2v.MODEL.wv.similarity(word1, word2)
except KeyError as e:
print(e)
return -1.0
def most_similar(self, word, max_size):
try:
return W2v.MODEL.most_similar(positive=[word], topn=max_size)
except KeyError as e:
return []
def getVec(self, word):
try:
return W2v.MODEL.wv[word]
except KeyError:
return np.zeros(200)
#再学習、上書きを行うメソッド
def updateTrain(self, corpus):
sentences = word2vec.Text8Corpus(corpus)
W2v.MODEL.build_vocab(sentences, update=True)
W2v.MODEL.train(sentences, total_examples=W2v.MODEL.corpus_count, epochs=W2v.MODEL.iter)
W2v.MODEL.save("wiki.model")
if __name__ == "__main__":
w2v = W2v()
word = "周防パトラ"
result = w2v.most_similar(word, 10)
for r in result:
print(r[0], '\t', r[1])
#単語数の確認
print(len(W2v.MODEL.wv.vocab))
実行結果:
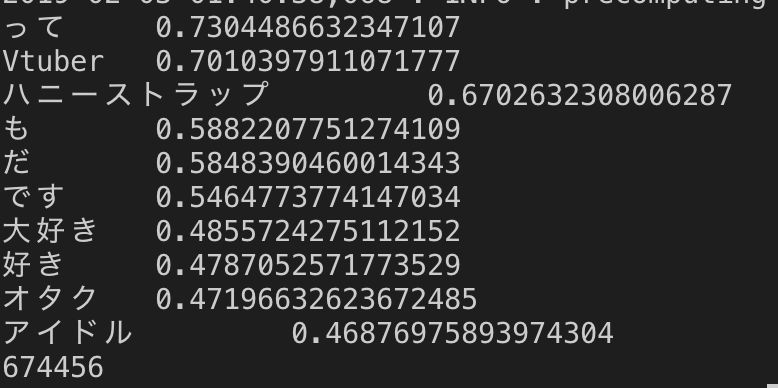
まぁ、名詞以外のゴミが入っているのは気になりますが、"Vtuber","ハニーストップ"が上位に来ているので成功ですね。コーパスにする時に、名詞や動詞のみでやると更に精度が上がりそうです。ちゃっかり、"オタク"が上位に来ているのが面白い、流石はパトラちゃん様...。他のメンバーもやってみたいし、自動でコーパスを生成するプログラムなんてのも面白いかな〜なんて思います。
今回はここまで。ありがとうございました!!ハニスコ!!!