はじめに
データエンジニアリングにおけるデザインパターンを扱った書籍 "Data Engineering Design Patterns" の第 9 章 Data Quality Design Patterns の感想を残していきます。
- 書籍ページ
- 無料ダウンロード
本章ではデータ品質の担保方法や、スキーマの一貫性担保、データ品質のモニタリングにおけるデザインパターンを紹介しています。
データ品質には技術的アプローチと組織的アプローチの両面から対処が必要なのですが、本章では主に技術的なアプローチが中心になっています。内容もどこか聞いたことあるものが多いのですが、ちゃんと説明を読んだことがないものもあるので、そのあたりを脇道に逸れながら感想を残していきたいと思います。
- Write-Audit-Publish パターン(Audit-Write-Audit-Publish パターン)
- AWAPパターンの前チェックと後チェック(Audit-Write-Audit-Publish パターン)
- CHECK 制約における DBMS 差異(Constraints Enforcer パターン)
- スキーマ変更の後方互換性と前方互換性(Schema Compatibility Enforcer パターン)
- データベースリファクタリング(Schema Migrator パターン)
- Observabilityとauditの違い(Offline/Online Observer パターン)
- データ品質の難しさ
ちなみに、以前の 2~7 章についての感想は以下です。この書籍を読む背景や感想を残していく方針について知りたい場合は、2 章の記事を参照してください。
3 -8 章の感想はこちらを展開してください
本章で紹介されているデザインパターン
以下が本章で紹介されているデザインパターンです。(概要は私が自分の理解の元、言い直しています)
| セクション | デザインパターン | 概要 |
|---|---|---|
| Quality Enforcement | Audit-Write-Audit-Publish | 上流のデータをチェックし(Audit)、変換し(Write)、変換結果をチェックし(Audit)、下流に公開する(Publish)。 |
| Constraints Enforcer | DBMS やストレージの制約機能でデータ品質を担保する。 | |
| Schema Consistency | Schema Compatibility Enforcer | スキーマ変更における前方互換や後方互換を担保する。 |
| Schema Migrator | 破壊的スキーマ変更を下流への影響を抑えながら実施する。 | |
| Quality Observation | Offline Observer | データ生成パイプラインとは独立してデータ品質をチェックする。 |
| Online Observer | データ品質パイプラインの一部としてデータ品質をチェックする。 |
感想
Write-Audit-Publish パターン(Audit-Write-Audit-Publish パターン)
書籍で触れられている Audit-Write-Audit-Publish パターンを説明する前に、その前身である Write-Audit-Publish パターン(WAP パターン)について触れたいと思います。
データエンジニアリングの分野では有名な Write-Audit-Publish パターンですが、私は「データの公開前にデータのテストをする」という程度の軽い理解しかしていませんでした。例えば以下の手順を想定していました。
-- データの作成
create or replace table target_data__tmp
as
select ... from source_data;
-- ここで作成したデータに対してテストを実施
-- データの公開
alter table target_data__tmp swap with target_data;
(dbt でも内部では似たような動作をしています)
ただし、本来の Write-Audit-Publish パターンは、書籍によると以下の動画の 16:30 から説明されている内容だそうです。(DataWorks Summit 2017 の講演)
簡単に図で説明すると以下のようなものです。
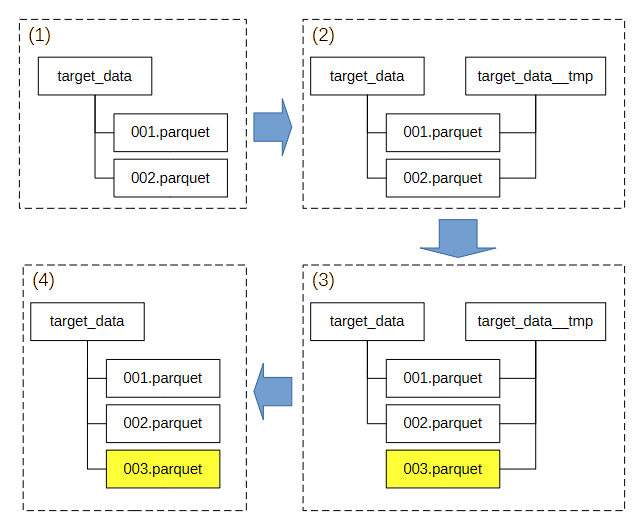
(1)
データセット target_data は 001.parquet と 002.parquet の 2 つのデータファイルからなります。
(2)
target_data と同じデータファイルを参照するスナップショットのデータセット target_data__tmp を作成します。
(3)
target_data__tmp にデータの更新を加えます(上の図では 003.parquet が追加)。イミュータブルなデータフォーマットであれば、target_data は更新後も更新前と同じデータファイルを参照します。
この後、target_data__tmp のデータをテストします。
(4)
テストをパスしたら、target_data が参照するデータファイルを切り替えます。
DataWorks Summit 自体が Hadoop 系のイベントであるため。かつ講演者の所属組織である Netflix が Spark を利用していることから、Hadoop 系の技術を前提に話されていますが、Snowflake など DWH の文脈とすれば、以下のように動かすことになるのでしょうか。これなら先に記載したやり方ではできなかった増分更新にも対応できますね。
-- クローンによりデータ更新用のテーブル作成
create table target_data__tmp clone target_data copy grants;
-- データの更新
merge target_data__tmp using source_data ...;
-- ここでデータのテストを実施
-- データの公開
alter table target_data__tmp swap with target_data;
これ dbt の incremental model の動きとは違うと思うのですが、dbt で実現する方法を後で調べてみたいと思います。(マクロを使って頑張っている人を見つけたのですが、それはちょっと避けたい…)
AWAPパターンの前チェックと後チェック(Audit-Write-Audit-Publish パターン)
Audit-Write-Audit-Publish(AWAP)パターンは、WAP パターンの先頭にもう一度 Audit(データのテスト)を行うデザインパターンです。
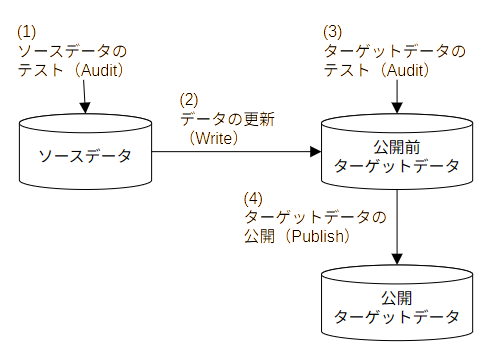
Audit(データのテスト)が 2 回出てきていますが、それぞれ役割が違います。
| Audit | 役割 |
|---|---|
| 1 回目 | ソースデータが想定通りか(パイプラインの上流でデータが壊れていないか)をチェック |
| 2 回目 | 本パイプラインにおけるデータの変換・更新でデータが壊れていないかをチェック |
要は、テストが通らなかった場合に原因がソースデータにあるか自身のパイプラインのロジックにあるかを切り分けるために、2 回のデータテストを実施しています。
目的が違うテストとはいえ、書籍のニュアンスとしては 1 回目のチェックは以下のような軽めのものを想定しているようです。
- 入力ファイルのフォーマットチェック
- 入力ファイル/テーブルのサイズ制御
- スキーマチェック
一方で、データ量が多い場合は NULL チェックのようなテストは 2 回目の方のみで実施すればカバーできると言及があります。いわゆるコスト優先の考え方かと思います。
もちろん、1/2 回目のどちらでテストすべきか or 両方でテストすべきかの判断はさまざまな点を考慮する必要があり一概に決定できるものではないのですが、以下の点を考慮すると両方で可能なら両方やるべきではと個人的には思うのですが、どうでしょうか。
- 誰が対処すべきか(上流システム側 or 自分たち)を明確にしたい
- 多くのケースはパイプラインのミスではなく、上流の仕様変更や上流データの品質悪化が問題の原因になりやすい(パイプライン自体はテストされている前提で)
- Snowflake や BigQuery などは計算リソースを柔軟に追加しやすいため、処理時間の問題は回避しやすい
CHECK 制約における DBMS 差異(Constraints Enforcer パターン)
Constraints Enforcer パターンは、要は DBMS / ストレージのデータ制約の機能でデータ品質を担保しようという話です。これ自体はよく知られた機能ですが、DBMS により差異があるので CHECK 制約を中心にそのあたりを触れたいと思います。
CHECK 制約で非決定関数を使えるか?
CHECK 制約の例として、Delta Lake を前提とした以下のサンプルコードが書籍には載っています。
ALTER TABLE default.visits ADD CONSTRAINT
event_time_not_in_the_future CHECK (event_time < NOW() + INTERVAL "1 SECOND")
これを見て、「Delta Lake では CHECK 制約に非決定関数(ここでは NOW() を使えるんだ…」と驚きました。
Oracle では非決定関数は利用できません。
- CHECK制約の条件は、次の構造を持つことができません。
- 副問合せおよびスカラー副問合せ式
- 決定的でないファンクションへのコール(CURRENT_DATE、CURRENT_TIMESTAMP、DBTIMEZONE、LOCALTIMESTAMP、SESSIONTIMEZONE、SYSDATE、SYSTIMESTAMP、UID、USERおよびUSERENV)
- (以下略)
他の DBMS だと以下のようです。
- PostgreSQL:可能
- MySQL:不可(ドキュメント)
- SQL Server:可能
(PostgreSQL/SQL Serverに関しては明確に利用可能というドキュメントは見つからなかったですが、実機で可能なことを確認済み)
非決定関数が使えるということは、データ挿入時には制約を満たしていたけど、後から参照したときには制約を満たしていない(データ挿入後に再評価はされない)ということが発生し得るので、許可されるべきではないと思うのですが…
DWH 系 DBMS における CHECK 制約の未サポート
Snowflake や BigQuery、Redshift などの DWH 系 DBMS では CHECK 制約は存在しません。一意キー制約や外部キー制約のように構文としてあるけれどデータチェックしないのではなく、そもそも構文としてありません。
一意キー/外部キー制約がこうなっている理由は以下になります。
- データロード時に 1 件ずつチェックすると、インデックスがないため非常に遅くなる
- ただし、Join Elimination などのオプティマイザ最適化のためにメタデータとしては必要
Join Elimination に関してはこちらの記事も参照してもらえればと思います。(タイトルは「使われない」とありますが、現時点では使われます)
一方、CHECK 制約に関しては、もちろんチェックを行う分だけデータロードが遅くはなりますが、データセット全体や他のテーブルを見る必要はないため(1 レコードに閉じてチェックできる)、それほど遅くなりません。実際、Oracle において CHECK 制約をつけたまま SQL*Loader でデータロードしても実際、そこまで遅くはなりません(当然、一意キー/外部キー制約をつけたままロードすると非常に遅い)。
NOT NULL 以外は DBMS ではチェックせず WAP/AWAP パターンなどを使ってチェックする方針というのは分かるのですが、CHECK 制約だけはあっても良いのではと思うのは私だけでしょうか。
スキーマ変更の後方互換性と前方互換性(Schema Compatibility Enforcer パターン)
Schema Compatibility Enforcer パターンの節では、スキーマの後方互換性(Backward Compatibility)と前方互換性(Forward Compatibility)について紹介されています。
| 互換性 | 内容 |
|---|---|
| 後方互換性 | 新しいスキーマを想定したデータコンシューマーはスキーマ変更前に生成されたデータも参照できる。 |
| 前方互換性 | 古いスキーマを想定したデータコンシューマーがスキーマ変更後に生成されたデータも参照できる。 |
後方互換性を満たすスキーマ変更の例として以下の 2 つが紹介されています。
- 属性の削除:新しいスキーマを想定したコンシューマーはそもそも削除された属性を見ないので問題ない
- オプショナルな属性の追加:古いスキーマ時に生成されたデータについては、追加された属性は NULL もしくはデフォルト値に見える
一方、前方互換性を満たすスキーマ変更の例としては以下の 2 つが紹介されています。
- 属性の追加:古いスキーマを想定したコンシューマーはそもそも追加された属性を見ないので問題ない
- オプショナルな属性の削除:新しいスキーマ時に生成されたデータについては、削除された属性は NULL と見える
ここで違和感あるのが、前方互換性の例にオプショナルな属性の削除が含まれている点です。SQL を想定すると、オプショナルとはいえ削除された属性を参照すればエラーになります。また、Python で JSON を扱う際(正確には dict ですが)にも、存在しない属性を参照すると KeyError が発生します。
一方で、Apache Avro や Protocol Buffers ではデフォルト属性値を返すことができるようです。
なので、互換性を満たすかどうかはデータフォーマットの機能に依存するということなのだと思います。
データベースリファクタリング(Schema Migrator パターン)
Schema Compatibility Enforcer パターンの節でスキーマの互換性について説明されていますが、実際互換性を保ったままでは以下のような変更が行えません。
- カラム名のリネーム
- データ型の変更(日付テキスト型をエポックタイムに変換するなど)
- 属性の削除
これらの変更をスムーズに行うにはどうしたらよいかというのが、本パターンの趣旨です。
ポイントはデータコンシューマー側に変更対応のための猶予期間を与えることです。
書籍で説明されている例ではユーザーのサイト訪問履歴(visits)においてどのページから来たかを表すカラムの名前を from_page から referral に変更するケースを挙げています。
- いきなりカラム名を変更するのではなく、
referralカラムを追加(既存レコードにはfrom_pageの値をコピーしておく) - データプロデューサーはしばらくの間、データ投入時に
from_pageとreferralに同じ値をセット(アプリ側で二重書きするほかに、トリガーを使うなどのアプローチもあり) - この間にデータコンシューマー(複数ありえる)は
from_pageの参照をreferralの参照に変更する - すべてのデータコンシューマーが変更を完了したら、データプロデューサーは
from_pageカラムを削除する
ここで、2. と 4. の間は数日~1 年といった長い期間を想定します。
このあたりの実際の実現方法については、「データベース・リファクタリング」という本が詳しいです。最近ではちょっと入手が難しい部類に入る本ですが。
ここまでやるかはケースバイケースなのですが、読んでおいて損はない本かなと思います。
Observabilityとauditの違い(Offline/Online Observer パターン)
この 9 章はデータ品質の章なのですが、次の 10 章は Data Observability の章になっています。最初にこの 2 つの章を見た際に何が違うんだ?と思いました。
実際に、別の書籍 "Data Quality Fundamentals" では Data Observability にも触れています。
その疑問に関して書籍("Data Engineering Design Pattern" のほう)ではシンプルに以下のように述べられて、個人的に納得したので紹介しておきます。
- Observability:データセットを監視するノンブロッキングなアプローチ
- Auditing:データを検証し、問題があればブロックするアプローチ
データ品質の難しさ
この章の先頭で、「サイトへの訪問者数が 50% 減ったけど、実はデータパイプラインのミスでした」みたいなシナリオが紹介されています。
このシナリオ、データ品質の本質的な難しさを表していると思っています。
具体的には、
- 訪問者数が何パーセント減ったら異常(アラートを挙げるべき)なのか?
- 訪問者数以外にモニタリングしないといけない KPI は何か?
などといった技術以外も含む課題がデータ品質の難しさなんですよね。
この章で述べているデザインパターンは、正直この手の問題の対応になってないんですよね…
上で触れた "Data Quality Fundamentals" では異常検知の活用 & 組織的なアプローチの提案になっており、面白い内容なのでお薦めです。