まえがき
Data Engineering Design Patterns の 5 章の感想を残していきます。5 章は Data Value Design Patterns と銘打たれています。エンドユーザーやデータ配信先システム向けにデータの価値を高めるための処理デザインのパターンについて述べられています。
2-4 章の感想については以下になります。この書籍を読む背景や感想を残していく方針について知りたい場合は、最初の記事を参照してください。
5 章の内容
- Data Enrichment
- Pattern: Static Joiner
- Pattern: Dynamic Joiner
- Data Decoration
- Pattern: Wrapper
- Pattern: Metadata Decorator
- Data Aggregation
- Pattern: Distributed Aggregator
- Pattern: Local Aggregator
- Sessionization
- Pattern: Incremental Sessionizer
- Pattern: Stateful Sessionizer
- Data Ordering
- Pattern: Bin Pack Orderer
- Pattern: FIFO Orderer
- Summary
Static Joiner パターンと Late Data
この書籍における Data Enrichment はあるデータセットに対して別のデータセットの情報を付与することで、データが持つ情報をより豊かにしようという意味です。
Static Joiner パターンはその中でも、2つのデータセットを結合(Join)することでデータエンリッチを実現するパターンになります。
書籍にある例では、
- Webサイトの訪問イベントデータ
- ユーザーのプロファイルデータ(マスターデータ)
がある状態で、訪問イベントデータをユーザーの属性を用いて分析するために、処理するイベントデータとユーザーのプロファイルデータ(全件)を結合するといったケースが挙げられています。(以下の図は私が作成)
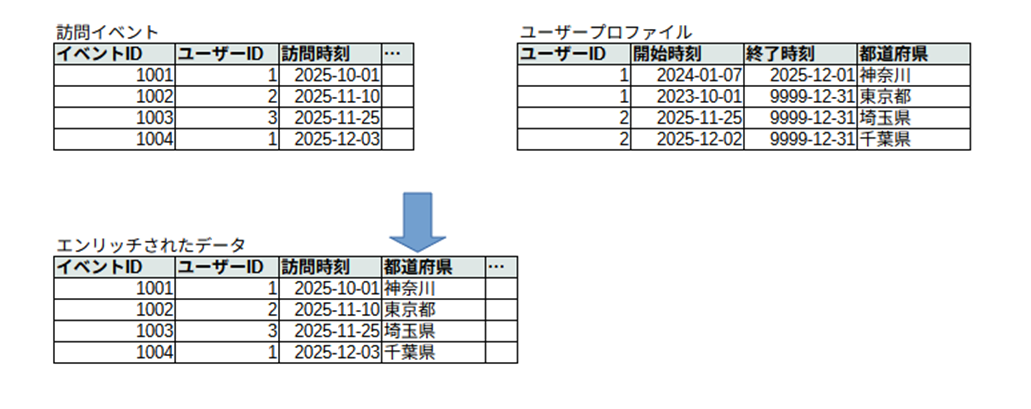
(もう一つの Dynamic Joiner とは、ストリーミングデータ同士 でエンリッチするために、バッファリングした 直近一部 のデータのみを用いて結合するという違いがあります)
注意点として、「データ遅延への対応」と「べき等性の確保」の 2 つが挙げられていますが、ここでは前者の「データ遅延への対応」について、少し触れたいと思います。
先の図の例では、2025-12-03 までの訪問イベントデータをエンリッチしようとしていますが、その前提としてユーザープロファイルの履歴も 2025-12-03 更新分まで反映されている必要があります。ただし、ユーザープロファイルのデータを見るだけでは、
- マスターのデータソース側でも 2025-12-03 には変更がなかった
- マスターのデータソース側では 2025-12-03 の変更があったが、何かしらの理由でその変更データの連携が遅延しており、反映されていない
の区別がつきません。
書籍では、この問題を解決する際に Readiness Marker パターンを利用できると紹介されています。2 章の感想でも触れましたが、以下のような実装方法を指します。
- フラグファイルを配置する
- Delta Lake のコミットログに完了を書き込み
- パーティション作成(パーティションあり = データ取り込み完了)
DWH においてユーザープロファイルなどのマスターデータについて対策する場合、いつ(日 or 日時)までの変更を反映済みかをテーブルデータ/ファイルデータとして別に持っておくことが多いかなと思います。私も多くのケースではこの方法を採用します。(こういうのを業務日付管理テーブルとか、バッチ日付管理テーブルとか呼んでいます)
ただ、このように管理する実装は、
- バックフィルの際にそのデータも変更が必要
- dbt などでは実装しづらい
などの問題があり、どういう実装が良いんでしょうね。
Wrapper パターンと Marklogic の Envelope パターン
Wrapper パターンとは、複数のソースから取得したスキーマが異なるデータセットに対して、
- 統一的に横断活用したい
- ただし、オリジナルなデータは保持して使えるようにしたい
という要望を満たすためのパターンです。
例を挙げると、
- A 支店の注文データ
| 注文番号 | 注文日 | 顧客ID |
|---|---|---|
| 1001 | 2025-12-01 | A001 |
- B 支店の注文データ
| オーダー No | オーダー時刻 | 顧客コード |
|---|---|---|
| 1002 | 2025-12-02 10:00:00 | B002 |
というデータセットがあった場合に、
| 支店 | 注文 ID | 注文日時 | 顧客ID | オリジナルデータ |
|---|---|---|---|---|
| A | 1001 | 2025-12-01 00:00:00 | 1 | {"注文番号": 1001, "注文日": "2025-12-01", "顧客ID": "A001" |
| B | 1002 | 2025-12-02 10:00:00 | 2 | {"オーダーNo": 1002, "オーダー時刻": "2025-12-02 10:00:00", "顧客コード": "B002" |
と、横断で利用する項目について以下のような統一を行い、共通項目として切り出すというアプローチです。
- カラム名(上の例では「注文番号」、「オーダーNo」という列名を「注文ID」に統一)
- 値フォーマット(時刻フォーマットを YYYY-MM-DD HH:MI:SS に統一)
- コード体系(顧客ID/顧客コードを統一された別のルールで裁判された顧客IDに統一)
(上の例ではオリジナルデータを JSON に残していますが、共通項目の方を JSON で保持する方法や、両方ともテーブルカラムとしてフラットに持つ方法が書籍では紹介されています)
この共通項目のことをエンベロープと呼ぶのですが、この考え方は昔からあって、例えば Marklogic では Envelope パターンと紹介されています。
デザインパターンの命名としては Wrapper パターンは一般的すぎるので、Envelope パターンの方が分かりやすいかなと思うのですが、どうでしょうか。
スキューを防ぐソルティング
Distributed Aggregator パターンは複数のノード上でカウントや合計などの集計を行う際に、集計キーでデータを再分散することで実現しようとするパターンです。(正直、これをデータエンジニアが意識して実装するケースはほとんどなく、プラットフォームの機能に任せることが多いので、デザインパターンというには違和感があるのですが)
例えば、key と val という列を持つレコードの集合に対して、key ごとに val の合計を 2 台のノードで分散して求めるとします。この場合、key に基づいてデータをノードに再分散することにより、各ノードで並列的に合計を処理する仕組みを指します。

このアプローチでよく遭遇する問題としてスキュー(非対称、つまりデータの分布が偏っている)です。上の図の例では key = 1 と key = 2 のレコードの数を同じにしましたが、例えば key = 1 の方が多い場合は以下のようになります。

key = 1 のレコードが再分散された先であるノード 1 では、処理する件数がノード 2 より多くなっており、結果として最終結果を得るまでの全体の処理時間が延びることになります。
ただし、普通の DWH においては以下のように再分散する前に事前集計を行います。

この方法では、ノード 1 とノード 2 での処理件数は変わらないため、処理時間は伸びなさそうに見えます。
この工夫(通常は DWH クエリエンジンが自動で処理する)でかなり問題が軽減されるケースも多いのですが、
- 事前集計を 1 ノード内で実施する際に CPU へ均等にレコードを分散できないため、事前集計の処理時間が伸びる
- 集計キーのカーディナリティーが非常に高い場合(かつノード数が多い場合)、事前集約してもあまり件数が減らず、結果としてスキューが解消できない
といった場合も少なくありません。
このスキューの問題に対して、書籍ではソルティング(salting)という手法を提案してます。ランダムな値(ソルト)を集計キーに付与した上で一度集計するという方法です。こうすることで、上の例における key = 1 のレコードは複数のノードに分散されるため、スキューが改善するという仕組みです。
with pre_sum
as
(
select
key,
uniform(1, 4, random()) salt,
sum(val) sum_val
from
...
group by
key,
salt
)
select key, sum(sum_val) from pre_sum group by key;
(uniform(1, 4, random()) は Snowflake において 1,2,3,4 の数字をランダムに返します)
私個人の経験からすると、乱数を付与するのではなく別のカラムをソルトとして利用するケースの方が多い気もしますが、今でもたまに使う方法です。(乱数を使うと再現性も気になりますが、Oracle だと dbms_random を呼び出さないといけないのでオーバーヘッドがちょっと気になる。他の DBMS では杞憂ですが…)
話をソルティングに戻しますが、この手法は集計というより結合におけるskewed join対策として使うことが多い気もします。
ここまでスキューの話をしてきましたが、最近は DBMS 側で
- 再分散時にスキューを検知して再分散先を動的に切り替える
- 集計処理の内部アルゴリズム自体の工夫
などもあり、スキューで困る機会は多少減っている気もします。(なくなったわけでもないですが)
ちなみに、ここまでの話は加算メトリクス(件数カウント、合計など)を求める際に使える方法で、非可算メトリクスを求める場合や、セッションキーごとにストリーミング処理する場合はまだまだ頭が痛い問題です。
パーティション分割とスキュー
Local Aggregator パターンは、前述の Distributed Aggregator パターンで課題になりやすい再分散を取り除くために、事前にデータを処理する単位で分散しておこうというアプローチです。前の例では、key ごとにハッシュパーティションでレコードを分散させておけば、再分散は不要になります。
ただ、このアプローチもいろいろ問題があって、
- パーティション方法を変更する場合は、データをすべて再割り当てする必要がある
- 特に、ストリーミング処理の場合は、現在処理中のデータを処理し終わるまでプロデューサーがデータ書き込みできない(ストップ・サ・ワールド)
- 異なるキーで集計したいというニーズの両方に対応できるハッシュ分散はない(key1 でハッシュ分散したら、key2 で集計したい場合は再分散が必要)
という課題が書籍では挙げられています。
これ以外の話として、ハッシュ分散自体がスキューを生み出しやすいという課題もあるかと思っています。ハッシュ分散は比較的均等にデータを分散する方法だと思われていますが、私は過去に以下のような事象を見たことがあります。
- カーディナリティー 2,000 万のデータを 128 分散させたが、一番大きいパーティションと一番小さいパーティションで倍半分ぐらいの件数差が発生
- カーディナリティー数百のデータを数百のパーティションに分散させたが、2/3 ぐらいのパーティションは空になった
(後者は私が設計したわけではなく、さすがにバッドパターンではあるのですが)
結局、ハッシュ分散って難しく、Snowflake など最近の DWH ではそもそも指定させないことが多いですよね。Kafka などでのストリーミング処理では必要なことも多いですが。
Bin Pack Orderer パターン
あまりストリーミング系のシステムを担当したことがなく、Bin Pack Orderer パターンのアルゴリズムを知らなかったので、自分の知識の整理のため、説明を残しておきたいと思います。(もし勘違いがあったらごめんなさい)
説明の題材としては、key と time からなるデータを配信する処理なのですが、配信データを受ける先では key ごとにストリーミング処理などを行う都合で、key内の time 順序でデータを配信する必要があります。
一番単純な方法は time でソートして 1 件ずつ配信する方法です。

この方法は確実ですが、レコードごとのリクエストを初期化やネットワークのオーバーヘッドが大きくなります。
この問題を回避するために部分コミットを伴うバルク処理を行います。(以下では 3 件ごとバルク処理を行う想定)

これでオーバーヘッドの問題は解消されますが、部分コミット(一部のレコードのみが成功することがある)が問題を生む可能性があります。例えば最初のバルク処理で
- key = 1, time = 09:04:00 のレコード:失敗
- key = 2, time = 09:04:00 のレコード:成功
- key = 1, time = 10:00:00 のレコード:成功
となった場合、後から失敗した 1 番目のレコードを再送する必要がありますが、その結果として 3 番目のレコード(key が同じ)と本来配信される順序が入れ替わってしまいます。
この問題を解決するために、以下のように 3 つのビンに分割してそれぞれバルク処理で配信します。
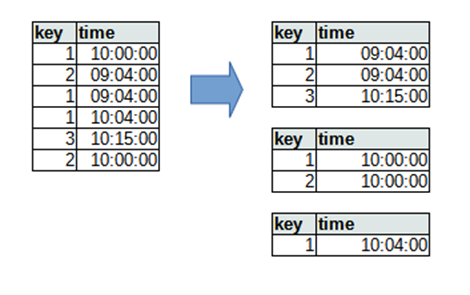
どのようにデータを分割しているかというと、
- 1 つのビンの中では key が重複しないようにする
- ある key のレコードに注目した場合、(N 番目のビンの time) < ( N+1 番目のビンの time)となるようにする
という条件を満たすようにします。アルゴリズムとしては何パターンかありそうですが、単純には key, time でソートし、順番にビンへ詰めていく(前のレコードと同じ key だったら次のビンへ、異なる key だったら 1 番目のビンへ)という方法が書籍では紹介されています。
この方法が部分コミットの問題をどう解決するかというと、例えば 1 番目のビンで
- key = 1, time = 09:04:00 のレコード:失敗
- key = 2, time = 09:04:00 のレコード:成功
- key = 3, time = 10:15:00 のレコード:成功
となった場合、1 番目のレコードを後で再送する必要がありますが、2/3 番目のレコードとは key が異なるため、後で送っても key ごとにストリーミング処理する受け手側としては問題ないという仕組みです。
ちなみに、1 番目のビンのレコードがすべて成功してから 2番目のビンの配信に移ります。(これは同じ key のレコードが time の順番で配信されるためには必須)
以上が Bin Pack Orderer の(私なりの)説明になります。
要は完全な順番を守った配信は難しいけれど、配信先は key ごとに順番が守れていれば OK というケースでは、パフォーマンスと順序性の両立が可能という話かと思います。