0 .結論
Oracle SQLcl MCP サーバーで自然言語問い合わせ(Text-to-SQL)を試してみました。
- Text-to-SQL に必要な MCP サーバーの機能は少ないが、LLM 側が頑張っており非効率ながらもなんとか使える
- テーブルやカラムの情報を取得する際にコメント(論理名・説明)も取得するよう指示しておくと良い
- 必要な情報があれば、ドリルアクロス程度の複雑なクエリは実行可能
1. はじめに
Oracle データベース用のコマンドラインツール SQLcl に MCP サーバーの機能が追加されました。この機能により自然言語で OracleDB のデータに問い合わせすること(Text-to-SQL)ができると謳われています。
Introducing MCP Server for Oracle Database
ただし、机上で調べたところ、以下の理由から力不足では?という印象を持ちました。
- 自然言語による問い合わせテキストに対して、どのテーブルが必要か判断する機能が提供されていない
- テーブルのメタデータを取得する機能が提供されていない
(SQLcl MCP サーバーが提供する機能はこちらに一覧があります。)
そこで、実際にできるかどうかを検証してみました。
いくつかのツールとモデルの組み合わせでトライしてみましたが、簡単なケースで以下のようになったので、この記事では Codex CLI + GPT-5-codex を利用します。
| ツール | モデル | 結果 |
|---|---|---|
| GitHub Copilot | GPT-4.1 | × |
| GitHub Copilot | Claude Sonnet 3.5 | × |
| Codex CLI | GPT-5-codex | ○ |
(他の組み合わせでなぜダメだった理由は後で触れます)
以下では Codex CLI + GPT-5-codex の動作結果と考察を記します。
2. データモデル
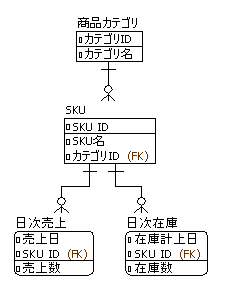
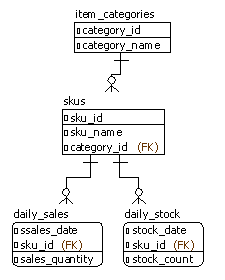
今回の検証では以下のような簡単なデータモデルを利用しました。すごくシンプル化した販売・在庫管理のデータモデルです。
-
論理名
-
物理名
DDL 文は以下になります。
create table item_categories (
category_id integer primary key,
category_name varchar(100) not null
);
comment on table item_categories is '商品カテゴリ';
comment on column item_categories.category_id is 'カテゴリID';
comment on column item_categories.category_name is 'カテゴリ名';
create table skus (
sku_id integer primary key,
sku_name varchar(100) not null,
category_id integer not null references item_categories(category_id)
);
comment on table skus is 'SKU';
comment on column skus.sku_id is 'SKU ID';
comment on column skus.sku_name is 'SKU名';
comment on column skus.category_id is 'カテゴリID';
create table daily_sales (
sales_date date,
sku_id integer,
sales_quantity integer not null,
primary key (sales_date, sku_id)
);
comment on table daily_sales is '日次売上';
comment on column daily_sales.sales_date is '売上日';
comment on column daily_sales.sku_id is 'SKU ID';
comment on column daily_sales.sales_quantity is '売上数';
create table daily_stock (
stock_date date,
sku_id integer,
stock_count integer not null,
primary key (stock_date, sku_id)
);
comment on table daily_stock is '日次在庫';
comment on column daily_stock.stock_date is '在庫計上日';
comment on column daily_stock.sku_id is 'SKU ID';
comment on column daily_stock.stock_count is '在庫数';
3. テキストによる問い合わせ
3-1. 簡単なケース
まずは一番シンプルなケースとして、以下の問い合わせを投げてみます。
salesデータベースに接続して、商品カテゴリごとの売上数合計を集計して。
この結果、Codex CLI は MCP サーバーのツールを使いながら処理を行います。
- DB への接続の一覧を取得
tool success, duration: 677ms
SQLcl.list-connections({"filter":"","model":"gpt-5","mcp_client":"Codex CLI"})
sales
- DB への接続
tool success, duration: 9.02s
SQLcl.connect({"connection_name":"sales","model":"gpt-5-codex","mcp_client":"CodexCLI"})
- テーブル一覧の取得
tool success, duration: 2.08s
SQLcl.run-sql({"sql":"SELECT /* LLM in use is gpt-5-codex */ table_name FROM user_tables ORDER BY table_name;","model":"gpt-5-codex","mcp_client":"CodexCLI"})
"TABLE_NAME""DAILY_SALES""DAILY_STOCK""ITEM_CATEGORIES""SKUS"
- DAILY_SALES テーブルの定義取得
tool success, duration: 626ms
SQLcl.run-sql({"sql":"SELECT /* LLM in use is gpt-5-codex */ column_name, data_type FROM user_tab_columns WHERE table_name = 'DAILY_SALES' ORDER BY
column_id;","model":"gpt-5-codex","mcp_client":"CodexCLI"})
"COLUMN_NAME","DATA_TYPE""SALES_DATE","DATE""SKU_ID","NUMBER""SALES_QUANTITY","NUMBER"
- SKUテーブルの定義取得
tool success, duration: 116ms
SQLcl.run-sql({"sql":"SELECT /* LLM in use is gpt-5-codex */ column_name, data_type FROM user_tab_columns WHERE table_name = 'SKUS' ORDER BY
column_id;","model":"gpt-5-codex","mcp_client":"CodexCLI"})
- ITEM_CATEGORIESテーブルの定義取得
tool success, duration: 87ms
SQLcl.run-sql({"sql":"SELECT /* LLM in use is gpt-5-codex */ column_name, data_type FROM user_tab_columns WHERE table_name = 'ITEM_CATEGORIES' ORDER BY
column_id;","model":"gpt-5-codex","mcp_client":"CodexCLI"})
"COLUMN_NAME","DATA_TYPE""CATEGORY_ID","NUMBER""CATEGORY_NAME","VARCHAR2"
- 集計 SQL 文の実行
tool success, duration: 1.27s
SQLcl.run-sql({"sql":"SELECT /* LLM in use is gpt-5-codex */ ic.category_name, SUM(ds.sales_quantity) AS total_sales_quantity\nFROM daily_sales ds\nJOIN
skus s ON ds.sku_id = s.sku_id\nJOIN item_categories ic ON s.category_id = ic.category_id\nGROUP BY ic.category_name\nORDER BY total_sales_quantity
DESC;","model":"gpt-5-codex","mcp_client":"CodexCLI"})
"CATEGORY_NAME","TOTAL_SALES_QUANTITY""カテゴリA",19833"カテゴリB",9956
- 結果の回答
> カテゴリ別の売上数量合計は以下の通りです:
- カテゴリA: 19,833
- カテゴリB: 9,956
必要なら期間や追加条件を指定した再集計にも対応できます。
流れを見ると、
- テーブル名一覧の取得
- クエリに関係しそうなテーブルの定義の取得(関係ないテーブル DAILY_STOCK は除外している)
- 集計 SQL 文の作成と実行
という流れになっています。
気になるポイントは
- クエリに関係しそうかどうかをテーブル名からのみ判断している(2. の箇所)
- テーブル定義取得ではカラムの物理名とデータ型のみ取得している
という点です。
3-2. テーブル名からは必要か否か推測できないケース
3-1. ではテーブル名に基づいてクエリに必要なテーブルを選択していました。
では、テーブル名からクエリに必要か否かが判断できないケースはどうなるでしょうか?疑問を解消するために、SKU テーブルを名前変更してみました。これで、このテーブルの必要/不要はテーブル名からは判断できなくなりました。
alter table sku rename to xxx;
この状態で 3-1. と同じ問い合わせを行うと以下の順番で処理が行われます。
- DB への接続の一覧を取得(省略)
- DB への接続(省略)
- テーブル一覧の取得
tool success, duration: 252ms
SQLcl.run-sql({"sql":"SELECT /* LLM in use is gpt-5 */ table_name FROM user_tables ORDER BY table_name","model":"gpt-5","mcp_client":"Codex CLI"})
"TABLE_NAME""DAILY_SALES""DAILY_STOCK""ITEM_CATEGORIES""XXX"
- DAILY_SALES テーブルの定義取得(省略)
- ITEM_CATEGEORY テーブルの定義取得(省略)
- DAILY_STOCK テーブルの定義取得
tool success, duration: 89ms
SQLcl.run-sql({"sql":"SELECT /* LLM in use is gpt-5 */ column_name, data_type FROM user_tab_columns WHERE table_name = 'DAILY_STOCK' ORDER BY
column_id","model":"gpt-5","mcp_client":"Codex CLI"})
"COLUMN_NAME","DATA_TYPE""STOCK_DATE","DATE""SKU_ID","NUMBER""STOCK_COUNT","NUMBER"
- "CATEGORY"というワードを列名に含むテーブルの探索
tool success, duration: 599ms
SQLcl.run-sql({"sql":"SELECT /* LLM in use is gpt-5 */ table_name, column_name FROM user_tab_columns WHERE column_name LIKE '%CATEGORY%' ORDER BY table_name,
column_name","model":"gpt-5","mcp_client":"Codex CLI"})
"TABLE_NAME","COLUMN_NAME""ITEM_CATEGORIES","CATEGORY_ID""ITEM_CATEGORIES","CATEGORY_NAME""XXX","CATEGORY_ID"
- XXX テーブルの定義取得
tool success, duration: 458ms
SQLcl.run-sql({"sql":"SELECT /* LLM in use is gpt-5 */ column_name, data_type FROM user_tab_columns WHERE table_name = 'XXX' ORDER BY column_id","model":"gpt-
5","mcp_client":"Codex CLI"})
"COLUMN_NAME","DATA_TYPE""SKU_ID","NUMBER""SKU_NAME","VARCHAR2""CATEGORY_ID","NUMBER"
- 集計 SQL 文の実行
tool success, duration: 1.28s
SQLcl.run-sql({"sql":"SELECT /* LLM in use is gpt-5 */ ic.category_name, SUM(ds.sales_quantity) AS total_sales_quantity\nFROM daily_sales ds\nJOIN xxx x
ON ds.sku_id = x.sku_id\nJOIN item_categories ic ON x.category_id = ic.category_id\nGROUP BY ic.category_name\nORDER BY ic.category_name","model":"gpt-
5","mcp_client":"Codex CLI"})
そして最終的な回答は以下になります。
"CATEGORY_NAME","TOTAL_SALES_QUANTITY""カテゴリA",19833"カテゴリB",9956
> 商品カテゴリ別の売上数量合計を集計しました。結果は次のとおりです。
- カテゴリA: 19,833
- カテゴリB: 9,956
興味深いのは、テーブル名から必要と判断した2テーブル(DAILY_SALES と ITEM_CATEGORY)だけではクエリを作れないと判断し、
- 最初は不要と考えていた DAILY_STOCK テーブルの定義を取得(これはハズレ)
- 必要なテーブルは CATEGORY に関係するはずだと考え、このワードを含カラム名に含むテーブルを探索
という流れで、XXX テーブルを発見し、最終的なクエリにたどり着いています。
3-3. カラム名からも必要か否か推測できないケース
Text-to-SQL をするにあたっての一つのハードルとして、類義語をどうするかという話があります。自然言語で問い合わせをするユーザーがテーブル名やカラム名とは異なる単語を使うというケースは非常に多いです。英語/日本語という違いだけではなく、意味的にも第三者が見ると全く推測できない組織・業務に固有の類義語というのも少なくありません。
例えば、商品カテゴリに関して売り場が商品カテゴリごとに分かれているために、「売り場」というワードで問い合わせるユーザーがいるとします。さすがに商品カテゴリ = 売り場という情報がないので正しく SQL 文を組めない可能性が高いです。(何回かやってると偶然うまくいくケースもありますが)
そこで、テーブルのコメントに情報を付与し、
comment on table item_categories is '商品カテゴリ(別称:売り場)';
加えて、Codex CLI の AGENTS.md に以下の内容を記載してテーブル一覧・カラム一覧の取得時にコメントも取得するよう指示しておきます。
テーブルの一覧を取得する際は以下の SQL 文で取得してください。
```
SELECT
t.table_name AS table_name,
d.comments AS table_description
FROM
user_tables t
LEFT OUTER JOIN
user_tab_comments d ON (t.table_name = d.table_name)
ORDER BY
t.table_name
```
あるテーブルの一覧を小得する際には以下の SQL 文で取得してください。(XXXはテーブル名に置き換えてください)
```
SELECT
c.column_name AS column_name,
c.data_type AS data_type,
d.comments AS column_description
FROM
user_tab_columns c
LEFT OUTER JOIN
user_col_comments d ON (c.table_name = d.table_name AND c.column_name = d.column_name)
WHERE
c.table_name = 'XXX'
ORDER BY
c.column_id
```
そうすると以下の問い合わせに対応できるようになります。
salesデータベースに接続して、売り場ごとの売上数合計を集計して。
- DB への接続の一覧を取得(省略)
- DB への接続(省略)
- テーブル一覧の取得
tool success, duration: 544ms
SQLcl.run-sql({"sql":"SELECT /* LLM in use is gpt-5-codex */\n t.table_name AS table_name,\n d.comments AS table_description\nFROM\n user_tables
t\nLEFT OUTER JOIN\n user_tab_comments d ON (t.table_name = d.table_name)\nORDER BY\n t.table_name","model":"gpt-5-codex","mcp_client":"CodexCLI"})
"TABLE_NAME","TABLE_DESCRIPTION""DAILY_SALES","日時売上""DAILY_STOCK","日次在庫""ITEM_CATEGORIES","商品カテゴリ(別称:売り場)""XXX","SKU"
- DAILY_SALES テーブルの定義取得
tool success, duration: 167ms
SQLcl.run-sql({"sql":"SELECT /* LLM in use is gpt-5-codex */\n c.column_name AS column_name,\n c.data_type AS data_type,\n d.comments
AS column_description\nFROM\n user_tab_columns c\nLEFT OUTER JOIN\n user_col_comments d ON (c.table_name = d.table_name AND c.column_name =
d.column_name)\nWHERE\n c.table_name = 'DAILY_SALES'\nORDER BY \n c.column_id","model":"gpt-5-codex","mcp_client":"CodexCLI"})
"COLUMN_NAME","DATA_TYPE","COLUMN_DESCRIPTION""SALES_DATE","DATE","売上日""SKU_ID","NUMBER","SKU ID""SALES_QUANTITY","NUMBER","売上数"
- ITEM_CATEGRIES テーブルの定義取得
tool success, duration: 128ms
SQLcl.run-sql({"sql":"SELECT /* LLM in use is gpt-5-codex */\n c.column_name AS column_name,\n c.data_type AS data_type,\n d.comments
AS column_description\nFROM\n user_tab_columns c\nLEFT OUTER JOIN\n user_col_comments d ON (c.table_name = d.table_name AND c.column_name =
d.column_name)\nWHERE\n c.table_name = 'ITEM_CATEGORIES'\nORDER BY \n c.column_id","model":"gpt-5-codex","mcp_client":"CodexCLI"})
"COLUMN_NAME","DATA_TYPE","COLUMN_DESCRIPTION""CATEGORY_ID","NUMBER","カテゴリID""CATEGORY_NAME","VARCHAR2","カテゴリ名"
- XXX テーブルの定義取得
tool success, duration: 292ms
SQLcl.run-sql({"sql":"SELECT /* LLM in use is gpt-5-codex */\n c.column_name AS column_name,\n c.data_type AS data_type,\n d.comments
AS column_description\nFROM\n user_tab_columns c\nLEFT OUTER JOIN\n user_col_comments d ON (c.table_name = d.table_name AND c.column_name =
d.column_name)\nWHERE\n c.table_name = 'XXX'\nORDER BY \n c.column_id","model":"gpt-5-codex","mcp_client":"CodexCLI"})
"COLUMN_NAME","DATA_TYPE","COLUMN_DESCRIPTION""SKU_ID","NUMBER","SKU ID""SKU_NAME","VARCHAR2","SKU名""CATEGORY_ID","NUMBER","カテゴリID"
- 集計 SQL 文の実行
tool success, duration: 276ms
SQLcl.run-sql({"sql":"SELECT /* LLM in use is gpt-5-codex */\n c.category_name AS category_name,\n SUM(s.sales_quantity) AS total_sales_quantity\nFROM\n
daily_sales s\n JOIN xxx x ON s.sku_id = x.sku_id\n JOIN item_categories c ON x.category_id = c.category_id\nGROUP BY\n c.category_name\nORDER BY\n
c.category_name","model":"gpt-5-codex","mcp_client":"CodexCLI"})
"CATEGORY_NAME","TOTAL_SALES_QUANTITY""カテゴリA",19833"カテゴリB",9956
最終的には正しく回答できています。(なぜか英語になっていたり、数値の3桁区切りがなくなっていたりしますが)
> Joined daily_sales, xxx, and item_categories to aggregate sales counts by 売り場 (カテゴリ名) and sorted the result.
- カテゴリA: 19833
- カテゴリB: 9956
1. Let me know if you need the same breakdown for a specific期間やSKU.
テーブルについてのコメントも取得しているため、3-2. とは違い、XXX テーブルに一発でたどり着いている点も注目すべきかと思います。
3-4. 少し複雑なクエリ(ドリルアクロス分析)
ここまでの設定はいったん戻して、以下のような問い合わせを新たに投げました。
salesデータベースに接続して、商品カテゴリごと、月ごとの在庫回転日数を計算してください。在庫回転日数 = 日別合計在庫の月平均 / 日別売上数合計の月平均 です。
Codex のすべての実行結果は載せませんが、ケース1と追加で以下の処理が動いています。
- DAILY_STOCKテーブルの定義取得
tool success, duration: 156ms
SQLcl.run-sql({"model":"gpt-5-codex","mcp_client":"Codex CLI","sql":"SELECT /* LLM in use is gpt-5-codex */ column_name, data_type FROM user_tab_columns WHERE
table_name = 'DAILY_STOCK' ORDER BY column_id;"})
"COLUMN_NAME","DATA_TYPE""STOCK_DATE","DATE""SKU_ID","NUMBER""STOCK_COUNT","NUMBER"
- 集計 SQL 文の実行
tool success, duration: 1.43s
SQLcl.run-sql({"model":"gpt-5-codex","mcp_client":"Codex CLI","sql":"WITH stock_daily AS (\n SELECT sk.category_id,\n ds.stock_date AS
data_date,\n SUM(ds.stock_count) AS total_stock\n FROM daily_stock ds\n JOIN skus sk ON sk.sku_id = ds.sku_id\n GROUP BY sk.category_id,
ds.stock_date\n),\nstock_monthly AS (\n SELECT category_id,\n TRUNC(data_date, 'MM') AS month_start,\n AVG(total_stock)
AS avg_daily_stock\n FROM stock_daily\n GROUP BY category_id, TRUNC(data_date, 'MM')\n),\nsales_daily AS (\n SELECT sk.category_id,
\n dsa.sales_date AS data_date,\n SUM(dsa.sales_quantity) AS total_sales\n FROM daily_sales dsa\n JOIN skus sk ON sk.sku_id
= dsa.sku_id\n GROUP BY sk.category_id, dsa.sales_date\n),\nsales_monthly AS (\n SELECT category_id,\n TRUNC(data_date, 'MM') AS
month_start,\n AVG(total_sales) AS avg_daily_sales\n FROM sales_daily\n GROUP BY category_id, TRUNC(data_date, 'MM')\n),\ncombined AS
(\n SELECT category_id, month_start FROM stock_monthly\n UNION\n SELECT category_id, month_start FROM sales_monthly\n)\nSELECT /* LLM in use
is gpt-5-codex */ ic.category_name,\n TO_CHAR(c.month_start, 'YYYY-MM') AS year_month,\n sm.avg_daily_stock,\n slm.avg_daily_sales,
\n CASE\n WHEN slm.avg_daily_sales IS NULL OR slm.avg_daily_sales = 0 THEN NULL\n ELSE sm.avg_daily_stock / slm.avg_daily_sales\n
END AS inventory_turnover_days\nFROM combined c\nJOIN item_categories ic ON ic.category_id = c.category_id\nLEFT JOIN stock_monthly sm ON sm.category_id =
c.category_id AND sm.month_start = c.month_start\nLEFT JOIN sales_monthly slm ON slm.category_id = c.category_id AND slm.month_start = c.month_start\nORDER BY
ic.category_name, c.month_start;"})
"CATEGORY_NAME","YEAR_MONTH","AVG_DAILY_STOCK","AVG_DAILY_SALES","INVENTORY_TURNOVER_DAYS""カテゴリA","2025-04",834.7,217.6,3.8359375"カ
テゴリA","2025-05",842.16129032258064516129032258064516129,224,3.75964861751152073732718894009216589862"カテゴリA","2025-
06",807.8,212.033333333333333333333333333333333333,3.80977833673950636692343971073730545512"カテゴリB","2025-04",474.666666666666666666666666666666...
- 最終的な回答
> Calculated monthly inventory turnover days by category using average daily stock and sales aggregates. Key results:
- カテゴリA: 2025-04 → 3.8359日, 2025-05 → 3.7596日, 2025-06 → 3.8098日
- カテゴリB: 2025-04 → 4.3654日, 2025-05 → 4.0183日, 2025-06 → 3.6645日
Turnover is avg_daily_stock ÷ avg_daily_sales; months with zero or missing sales return NULL. Let me know if you’d like rounded values or additional filters.
またまた、なぜか回答が英語になっていますが、正しく集計できているようです。今回の処理はドリルアクロスといわれる比較的複雑な処理なのですが、問題なく SQL 文を組み立てられているようです。
一応、実行された SQL 文を整形したものを以下に載せておきます。
WITH stock_daily AS (
SELECT
sk.category_id,
ds.stock_date AS data_date,
SUM(ds.stock_count) AS total_stock
FROM daily_stock ds
JOIN skus sk ON sk.sku_id = ds.sku_id
GROUP BY sk.category_id, ds.stock_date
),
stock_monthly AS (
SELECT category_id,
TRUNC(data_date, 'MM') AS month_start,
AVG(total_stock) AS avg_daily_stock
FROM stock_daily
GROUP BY category_id, TRUNC(data_date, 'MM')
),
sales_daily AS (
SELECT sk.category_id,
dsa.sales_date AS data_date,
SUM(dsa.sales_quantity) AS total_sales
FROM daily_sales dsa
JOIN skus sk ON sk.sku_id = dsa.sku_id
GROUP BY sk.category_id, dsa.sales_date
),
sales_monthly AS (
SELECT category_id,
TRUNC(data_date, 'MM') AS month_start,
AVG(total_sales) AS avg_daily_sales
FROM sales_daily
GROUP BY category_id, TRUNC(data_date, 'MM')
),
combined AS
(
SELECT category_id, month_start FROM stock_monthly
UNION
SELECT category_id, month_start FROM sales_monthly
)
SELECT /* LLM in use is gpt-5-codex */
ic.category_name,
TO_CHAR(c.month_start, 'YYYY-MM') AS year_month,
sm.avg_daily_stock,
slm.avg_daily_sales,
CASE WHEN slm.avg_daily_sales IS NULL OR slm.avg_daily_sales = 0
THEN NULL
ELSE sm.avg_daily_stock / slm.avg_daily_sales
END AS inventory_turnover_days
FROM combined c
JOIN item_categories ic ON ic.category_id = c.category_id
LEFT JOIN stock_monthly sm ON sm.category_id = c.category_id AND sm.month_start = c.month_start
LEFT JOIN sales_monthly slm ON slm.category_id = c.category_id AND slm.month_start = c.month_start
ORDER BY
ic.category_name,
c.month_start
4. 考察
一般に Text-to-SQL には自然言語の問い合わせクエリに関してどのテーブルが必要かを探す仕組みが備わっていることが多いです。
- テーブル定義をベクトル化しておき、クエリとの類似性から必要テーブルを判断
- クエリから重要なワードを抽出し、そのワードにもづいてキーワード検索し、必要なテーブルを判断
- リレーションシップの情報から必要なテーブルを論理的に推論
Oracle SQLcl の MCP サーバーにはそのような機能はついていませんが、
- テーブル名から候補をリストアップする
- 見つからない場合は候補に挙がっていないテーブルも確認してみる
- それでもだめならカラム名をキーワード検索してみる
といったことを LLM 側で判断しており試行錯誤しながら答えにたどり着いています。
(ちなみに 1. でふれましたが、GitHub Copilot + GPT4.1/Claude Sonnect 3.5でうまくできなかったのは、これらの動きができなかったからです。多くの SQLcl MCP サーバーに関する記事では、事前にテーブル/カラム一覧の取得を明示的に行っているため、この問題が表出していません。)
ということで、最初に立てた「力不足では?」という仮説に対しては、「LLM のパワー次第ではうまくやれる」という結論になりそうです。
もちろん、テーブル数が増えたり、モデルが複雑になった場合は効率性が落ちたり、正しいクエリにたどり着けなかったりするケースがあるので、上での述べたような仕組みは最終的には必要かと思いますが。
あと、テーブルやカラム名にコメントで追加の情報(メタデータ)を足しておくことも重要ですね。加えて、3-3. で示した通り、追加情報を読み込むように AGENTS.md で指示しておくことも重要ですね。個人的には、自然言語で問い合わせ可能と歌うのであれば、MCP サーバー側にツールとしてちゃんと準備しておいてほしいですが。