IoTLT Advent Calendar 2019 17日目の記事です。
昨年に引き続きIoTLTのアドベントカレンダーを担当させていただくことになりました。よろしくお願いいたします。
昨年書いたやつ: IoTの台風の目!?EnOceanについて本気出して語ってみた
モチベーション & アイディア

突然ですが皆さん、家を出た時に「スマホ忘れた!家帰るのめんどい!!」的な絶望感に襲われた経験ありませんか。私はしょっちゅうあります。
常々このような悲劇をなんとか防止できないかと思っていたのですが、今回アドベントカレンダーのお話をいただいたのを契機に真面目に取り組んでみることにしました。
想定したのは "外出しようとした時にスマートスピーカーが忘れ物を教えてくれる" という仕組み。
スマホを忘れているのにスマホアプリに通知したところでどうしようもない訳で、気づきを与えるという意味でスマートスピーカーに喋らせる、というのは妥当なアイディアかな、と。
課題
上記の仕組みを実現するにあたり、以下の課題を解決する必要があります。
- どうやって「外出しようとした時」を検知するか?
- どうやって忘れ物があることを検知するか?
- どうやってスマートスピーカーを喋らせるか?
順を追って検討した内容を記載します。
1. 「外出しようとした時」の判断ロジック
結論としては、ここは割り切って「平日朝の特定時間にチェックする」ことにしました。これであれば忘れ物検知のスクリプトをcron設定するだけで、技術的課題はありません。
我が家では子供を保育園に預けている関係上、平日朝の外出タイミングはほぼ完全に一定になるという前提条件からこれでいけると判断しました。
外出の検知手法としてはマグネットセンサ+人感センサ or カメラである程度判断できるロジックは以前検討したことがあるのですが、それはまた次の機会に。
2. 忘れ物があることの検知方法
ここについては当初WiFiやBLEアドバタイズのスキャンでどうにかならないかなー、と甘く考えていました1。
が、やはりというかなんというかスリープ状態ではSSIDの公告もBLEアドバタイズも何も飛ばさないので検知のしようがないという事態に。スマホをWake on LANでもできれば良かったのですが…。
ということで、結局カメラを使った物体検出を試してみることにしました。なお当方、この手の技術は初心者です2。
どうせ夜寝る時にスマホ充電する場所は決まっているので、そこを画像撮影して何か物があれば忘れ物と判断、というロジックで試してみることにします。
3. スピーカーを喋らせる方法
ここはNode-RED様様ということで、Node-REDの node-red-contrib-cast ノードを利用すれば万事解決。
ほぼこちらの方の記事に書かれている内容が全てです。
Node-REDを使って簡単にGoogle Homeに喋らせよう by @dozensofdars
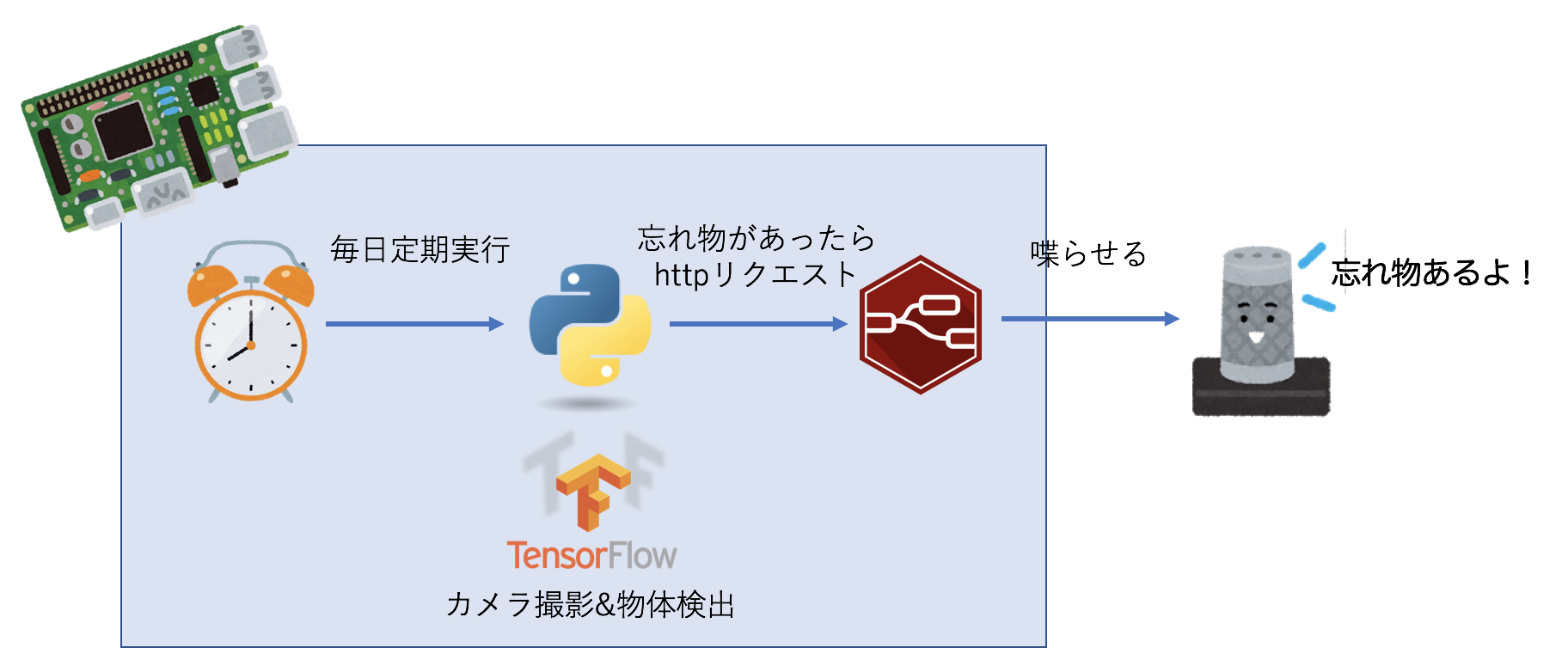
ということで、これらを組み合わせた構成はこのようになります。
-
Raspberry Pi 3 Model B
- Raspbian Stretch Lite (2019/4/8版)
- Node.js v12.13.1
- npm v6.13.4
- Node-RED v1.0.3
- Python v3.5.3
- TensorFlow v1.14.0
- numpy v1.16.4
-
Google Home mini
以下、環境構築についてかいつまんで記載します。
環境構築
Python / Tensorflow
参考:https://www.tensorflow.org/install/pip?lang=python3
$ sudo apt update
$ sudo apt install python3-dev python3-pip
$ sudo apt install libatlas-base-dev # required for numpy
$ pip3 install --user --upgrade tensorflow
virtualenvは利用しませんでした。
また、tensorflowのインストール時に以下のエラーが出ましたが、気にせずもう一度インストールコマンドを実行することで正常終了しました。
参考:https://kinformation.sakura.ne.jp/20171030-01
File "/usr/share/python-wheels/urllib3-1.19.1-py2.py3-none-any.whl/urllib3/connectionpool.py", line 594, in urlopen
http.client.RemoteDisconnected: Remote end closed connection without response
物体検出ライブラリ(YOLOv3-tiny)
TensorFlowを使って物体検出を行うための学習済みモデル、及びそれを利用した物体検出スクリプト。
YOLOv3だとRaspberry Pi 3には耐えきれないので、YOLOv3-tinyを使うことになります。
$ git clone https://github.com/kcosta42/Tensorflow-YOLOv3.git
$ cd Tensorflow-YOLOv3
$ make install
$ curl https://pjreddie.com/media/files/yolov3-tiny.weights > ./weights/yolov3-tiny.weights
$ python3 convert_weights.py --tiny
なお、make install 時に Pillow というパッケージのインストールに関しライブラリ不足でエラーー発生。
以下の参考サイトを参考に関連ライブラリを apt-get install することでエラー解消させました。
参考;https://qiita.com/paper2/items/b67d07813eba7f895635
Building wheels for collected packages: Pillow
no previously-included directories found matching '.azure-pipelines'
no previously-included directories found matching '.travis'
writing manifest file 'src/Pillow.egg-info/SOURCES.txt'
running build_ext
The headers or library files could not be found for jpeg,
a required dependency when compiling Pillow from source.
Please see the install instructions at:
https://pillow.readthedocs.io/en/latest/installation.html
ともあれここまでで仕立て完了。サンプル画像でテストしてみます。
python3 detect.py --tiny image 0.5 0.5 ./data/images/horses.jpg

多少精度はいまいちですが、検出はできています。
続いて、Raspiのカメラで撮影した画像でスマホを検出できるかのチャレンジです。

"laptop"としてなんとか認識されました。
ただし、相当理想的な環境で撮影の仕方を工夫してあげないとなかなか認識されません。ここは今後の課題。。。
Node-RED
こちらは公式で紹介されているインストールコマンド一発でした。
インストール後、自動起動設定は投入しておきます。
$ bash <(curl -sL https://raw.githubusercontent.com/node-red/linux-installers/master/deb/update-nodejs-and-nodered)
$ sudo systemctl enable nodered.service
あとはNode-REDの自動起動設定を行い、Node-REDエディタで「パレットの追加」から node-red-contrib-cast をインストールするのみです。
各要素のつなぎこみ
Node-REDのフロー作成

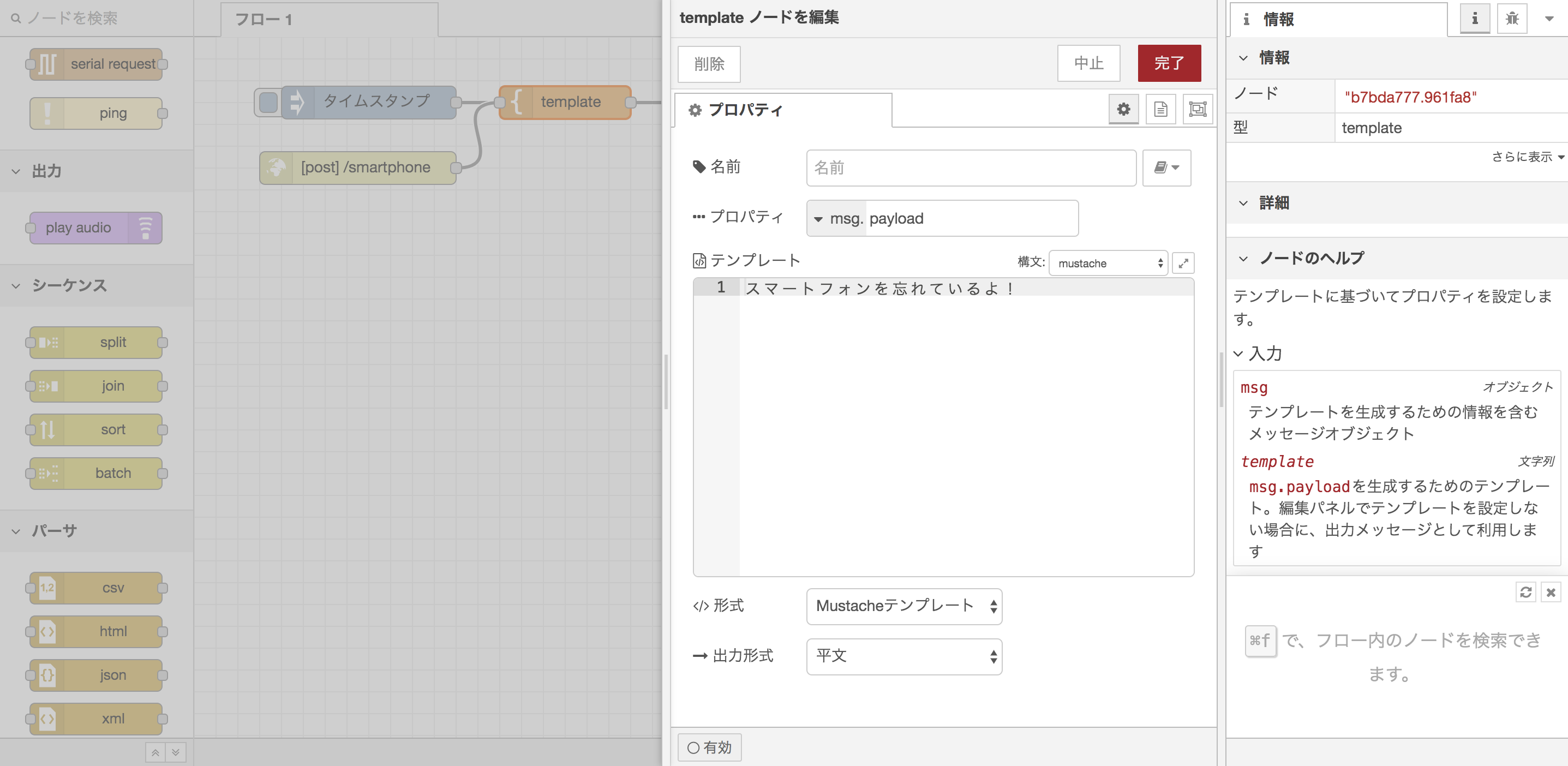
フローとしてはごく単純なcastノードのための設定と、python / TensorFlow側から忘れ物検知時にリクエストを受け付けるためのHTTP-in / HTTP-responseノードの設定程度です。簡単!
HTTP-inノードは空のPOSTリクエストを受け付けるようにしておきます。
TensorFlowの実行スクリプト修正
やるべきことは detect.py の実行結果として物体を検出したら、Node-REDで設定したHTTPエンドポイントにリクエストを投げつけることです。
Tensorflow-YOLOv3 のスクリプトを見ていくと、 core/utils.py で定義されている draw_boxes(img_name, boxes_dict, class_names, input_size) 関数内で物体の判定をしていることが読み解けますので、この中に物体検出をしたかどうかのカウントロジックと、httpリクエストを投げつけるコードを仕込んでおきます。
追加したのはこんな単純なコード程度です。(オリジナルファイルとのdiff)
1a2,3
> import json
> import urllib.request
21a24,38
> def gs_call():
> url = 'http://localhost:1880/smartphone'
> data = {}
> headers = {'Content-Type': 'application/json'}
>
> req = urllib.request.Request(url, json.dumps(data).encode(), headers)
> try:
> with urllib.request.urlopen(req) as res:
> body = res.read()
> except urllib.error.HTTPError as err:
> print(err.code)
> except urllib.error.URLError as err:
> print(err.reason)
> return body
>
28a46,47
> detected = 0
>
31d49
<
49a68,72
> detected += 1
>
> if detected > 0:
> print("detected")
> gs_call()
カメラ撮影との連携
detect.py を実行するとスピーカーが喋るところまで連携したので、あとはカメラを撮影する部分と detect.py の連動です。
これは単純にカメラ撮影するファイル置き場/ファイル名を決め打ちにしてしまい、シェルスクリプトでカメラ撮影→判定を連結してしまうことにします。
- カメラ撮影スクリプト(lost.py)
import picamera
with picamera.PiCamera() as camera:
camera.resolution = (1024, 768)
camera.capture('data/lost/image.jpg')
- 実行シェル(lost.sh)
# !/bin/sh
SRCDIR="/home/pi/Tensorflow-YOLOv3"
IMGFILE="${SRCDIR}/data/lost/image.jpg"
cd ${SRCDIR}
python3 ${SRCDIR}/lost.py
python3 ${SRCDIR}/detect.py --tiny image 0.5 0.5 ${IMGFILE}
これでカメラ撮影〜判定〜スピーカーが喋る、まで連動しました!!
あとはこの実行シェルをcrontabに入れ込めば終了です。
やってみた感想
とりあえず画像認識系を触る機会を作れたのは良かったです。
- 判定処理させるだけであってもまだそれなり以上に端末スペック要りそう
- 画像撮影の条件によって相当結果左右されそう
- モデルをトレーニングしてないからという理由もきっと多分にあるけれど
- TensorFlow周りはまだまだ発展途上なのでバージョン追従大変そう
- Node-REDも似たようなもんだったけれど
- 新しい技術に手を出す時には余裕を持って工数を見積もろう
というあたりが今回得られた知見でしょうか。
今回はともかく一連のシステムをつなぎ合わせるところまで走ってみましたが、主に物体検出の精度がまだまだイマイチで実用には全然届いていない状態です。
今後もう少し時間をかけてブラッシュアップして、どこかのLTででも供養できればいいなと思います :)