最近ちょっとしたデータ整形・突合等々の処理をやることが多くて使ってたコマンドを共有。
初歩的な内容ばかりだけれどこれだけでもそれなり以上には捗る(はず)
元々はサーバログ調査とかで覚えたシェル芸
熟練のシェル芸人達からのコメントも大歓迎 :)
想定読者層
- プログラミングとか知らん
- Linuxあんまり詳しくない
- 何かのプログラミング言語はある程度わかるエンジニアだけどシェルあんまり使わない
まずはシェルの基本
シェルって?
OSカーネルのサービスへのアクセスを提供するソフトウェア。
OSの内部(カーネル)とユーザーの間にある外殻(シェル)であることが名前の由来。
あるいはエンジニアがよく開いてる黒い画面でカタカタ打ち込んでるやつ。コワクナイヨ。

[参考]
Wikipedia: シェル
シェルの概念と機能
[エンジニア向け参考]
Linux上でシェルが実行される仕組みを,体系的に理解しよう(bash 中級者への道)
OSカーネル
WindowsとかMac(iOS)とかLinuxとかのいわゆるOSの中でとっても頑張っているコアプログラム。
普通のエンジニアも普段意識することはない。というか意識しなくて済むように黒子として作られているのがOSカーネル。大佐ではない。
ターミナル
シェルを使うためのプログラム。
前述の通り黒い画面に白い文字が基本だが、見た目を魔改造している場合もあるので一概に黒くはない。
コマンド
シェルの機能を利用するための命令。別名おまじない。
ターミナルでコマンドを入力すると、裏でなんやかんやありまして実行結果を出力してくれる。

[エンジニア向け]
シェルのプログラムの内部に実装されているコマンドを内部コマンド、シェルから呼び出して使うコマンドを外部コマンドと呼ぶ。
Linuxの場合 lsは外部コマンド(実態は /bin/ls )、exec は内部コマンド。
パイプ
あるコマンドの出力と、次のコマンドの入力を繋いでくれる魔法のキーワード。 | を使う。
<コマンド1> | <コマンド2> という書き方をするとコマンド1の結果がコマンド2の入力になる。
コマンドは何を入力にしていて何を出力するのか、というのは使って調べて聞いて覚えていくのである。
$ cat test.txt // <- コマンド1
test
hoge
fuga
$
$ grep test - // <- コマンド2
test // <- キーボード入力
test // <- 出力
hoge // <- キーボード入力(testの文字列を含まないので出力なし)
fuga // <- キーボード入力(testの文字列を含まないので出力なし)
$
$ cat test.txt |grep test - // <- <コマンド1> | <コマンド2>
test
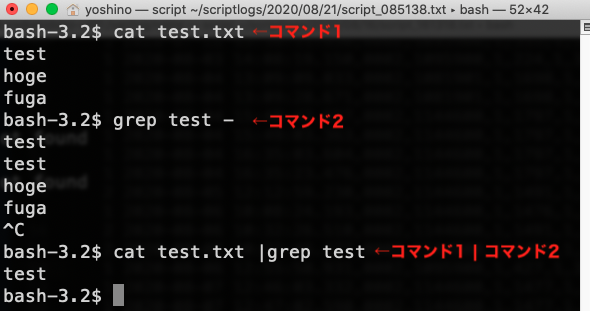
- コマンド1:
cat test.txt-
test.txtの中身を出力して!というコマンド。 - 出力は
test.txtの中身の文字。3行の文字(単語)が出力されている。
-
- コマンド2:
grep test -- キーボードから入力された文字のなかに
testという文字が含まれていたら入力された文字を出力する -
testと打ち込む(コマンド2の1行下)とtestと出力される(コマンド2の2行下)が、testを含まない文字を打ち込んでも何も出力されない(コマンド2の3行下、4行下)
- キーボードから入力された文字のなかに
- コマンド1 | コマンド2 とパイプする(この場合コマンド2の入力を示す
-は省略する)と、
[エンジニア向け]
コマンドの標準出力(1)を次のコマンドの標準入力(0)にメモリ上で繋いでくれる機能。
本題:便利なコマンド達
grep
検索コマンド。基本形は grep <検索文字列> <ファイル名>となり、「ファイルの中身に検索文字列が含まれているかを確認し、含まれる行を返す」。
ファイル名の指定はワイルドカード(*)が使えるので、複数ファイルの中身を横断的に調べることが可能。
$ cat test.txt
test
hoge
fuga
$ cat try.txt
try
fly
swing
$ grep t test.txt
test
$ grep t try.txt
try
$ grep t *.txt
test.txt:test
try.txt:try
パイプで grep に入力を渡す場合は、前述の通りパイプで渡された文字列に対して検索を行うことになることに留意が必要である(ファイル名をパイプで渡しても、そのファイルの中身を検索するのではなく、ファイル名の文字列が検索対象になってしまう)。
そのためgrepはパイプライン(パイプで繋いだコマンド列)の最初に持ってくるべきコマンドと考えておくのが無難。
$ ls
test.txt try.txt
$ ls |grep test
test.txt
awk
使いこなすと大概なんでもできてしまう万能薬。ただし使いこなすには相当の鍛錬が必要。
コマンドの顔をしているが実態はこれ自体が1つのプログラミング言語と言って良い(はず)。
[エンジニア向け参考] Wikipedia: AWK
テキストの整形に関しては本当になんでもできるが、一番手っ取り早くかつ有用なのが区切り文字を指定して指定した箇所のデータのみを抽出すること。
区切り文字はデフォルトで空白であるが、-F オプションで任意の区切り文字を指定できる。
また、区切った後のデータの抽出も $X (X:数字)で指定するだけなので非常に単純である。
$ cat awk.csv
1,test
2,hoge
3,fuga
$ cat awk.csv | awk -F ',' '{ print $1 }' // 区切ったデータの1番目を表示
1
2
3
$ cat awk.csv | awk -F ',' '{ print $2 }' // 区切ったデータの2番目を表示
test
hoge
fuga
カンマ区切りで複数のデータを並べることもできる(デフォルト区切り文字は空白)
$ cat awk.csv | awk -F ',' '{ print $1,$2 }'
1 test
2 hoge
3 fuga
-v 'OFS=<任意の文字列>' のオプションで複数のデータを抜き出した後任意の区切り文字を指定することもできる。OFSはOutput Field Separatorの略らしい。
[参考] awkコマンドの基本
$ cat awk.csv | awk -F ',' -v 'OFS=_' '{ print $1,$2 }'
1_test
2_hoge
3_fuga
利用法としてはgrepで必要な文字列を含む行を抽出した後、さらに必要な情報を絞り込むというイメージ。
$ cat awk.csv
1,test
2,hoge
3,fuga
$ grep hoge awk.csv | awk -F ',' '{ print $2}'
hoge
sed
awkと同じく文字列操作を行うためのコマンド。特に文字の置換やファイルの行編集でよく使われる。
awkでも同じことは大体できるが、用途を絞ればsedの方が書き方は楽(だと思う)。
正規表現で置換前後の文字を指定できるが、正規表現は頑張ってggりながら覚えよう。テキストエディタなどでも使えるのでシェル書かないエンジニアだとしても覚えて損は絶対にない。
[参考]
基本的な正規表現一覧
sedでこういう時はどう書く?
例:日付の書式を変える
「/」区切りを「-」区切りにする → パイプでgrep, awkと流した後に微修正するとか
$ echo "2020/08/29" | sed 's/\//-/g'
2020-08-29
ファイルの1行目を削除する
ヘッダ行削除したい時など
$ cat sed.csv
no,text
1,test
2,hoge
3,fuga
$ sed '1d' sed.csv
1,test
2,hoge
3,fuga
[エンジニア向け]
シェルスクリプトの中でループを書いて複数ファイルを一気に処理するパターンが多い
(以下は標準出力に書き出しているが、処理後の文字列を他ファイルに書き出すなどする)
$ ls -rlt ./csv
total 16
-rw-r--r-- 1 yoshino staff 21 8 28 21:07 awk.csv
-rw-r--r-- 1 yoshino staff 29 8 29 00:01 sed.csv
$ cat csv/awk.csv
1,test
2,hoge
3,fuga
$ cat csv/sed.csv
no,text
1,test
2,hoge
3,fuga
$ cat loopsed.sh
# !/bin/bash
ls ./csv | while read line
do
sed '1d' ${line}
done
$ sh loopsed.sh
2,hoge
3,fuga
1,test
2,hoge
3,fuga
uniq
重複する行を除いてくれたり、重複してる行だけを出してくれたり、重複の数を付けてくれたりするコマンド。
ただし直前行との比較しかしてくれないので、このコマンドの前にソート必須。
$ cat uniq.txt
test
hoge
test
fuga
$ cat uniq.txt | uniq
test
hoge
test
fuga
$ cat uniq.txt | sort | uniq
fuga
hoge
test
$ cat uniq.txt | sort | uniq -c
1 fuga
1 hoge
2 test
wc
テキストファイルの行数や単語数を調べてくれるコマンド(Word Count)。「What Color?」ではない。
大体 -l オプションで行数を数える。
bash-3.2$ cat uniq.txt
test
hoge
test
fuga
bash-3.2$ cat uniq.txt | wc -l
4
bash-3.2$ cat uniq.txt | sort | uniq | wc -l
3
まとめ
grep, awk, sed, uniq, wc (と、基本のlinuxコマンドと、多少の手作業)があれば割となんとかなるもんだと思うので、是非使いこなしてみよう。