タイトル通りKerasを用いてAlexNetを構築し,Cifar-10を用いて学習させてみます.やりつくされている感はありますが,私自身の勉強を兼ねてということで.
AlexNetとは
2012年のImageNetを用いた画像認識コンペILSVRCでチャンピオンに輝き,Deep Learningの火付け役となったモデルです.5つの畳み込み層,3つの全結合層などから構成されています.具体的な構成は以下の通りです.
| Layer | Kernel_size | Filters | Strides | Padding | Output_size |
|---|---|---|---|---|---|
| Conv_1 | (11, 11) | 96 | (4, 4) | 0 | (None, 55, 55, 96) |
| Max_pool_1 | (3, 3) | - | (2, 2) | - | (None, 27, 27, 96) |
| Conv_2 | (5, 5) | 256 | (1, 1) | 2 | (None, 27, 27, 256) |
| Max_pool_2 | (3, 3) | - | (2, 2) | - | (None, 13, 13, 256) |
| Conv_3 | (3, 3) | 384 | (1, 1) | 1 | (None, 13, 13, 384) |
| Conv_4 | (3, 3) | 384 | (1, 1) | 1 | (None, 13, 13, 384) |
| Conv_5 | (3, 3) | 256 | (1, 1) | 1 | (None, 13, 13, 256) |
| Max_pool_5 | (3, 3) | - | (2, 2) | - | (None, 6, 6, 256) |
| FC_6 | - | - | - | - | (None, 4096) |
| FC_7 | - | - | - | - | (None, 4096) |
| FC_8 | - | - | - | - | (None, 1000) |
AlexNetの構築
構築にあたりこちらの記事を参考にさせていただきました.ありがとうございました.
論文における入力は(224, 224, 3)となっていますが,1層目の畳み込み層の出力が合わないため,(227, 227, 3)としています.
また,LRNの代わりにBatchNormalizationを用いています.
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D, BatchNormalization
from keras.optimizers import SGD
from keras.initializers import TruncatedNormal, Constant
num_classes = 1000
image_size = 227
channel = 3
def conv2d(filters, kernel_size, strides=(1, 1), padding='same', bias_init=1, **kwargs):
trunc = TruncatedNormal(mean=0.0, stddev=0.01)
cnst = Constant(value=bias_init)
return Conv2D(
filters, kernel_size, strides=strides, padding=padding,
activation='relu', kernel_initializer=trunc, bias_initializer=cnst, **kwargs
)
def dense(units, activation='tanh'):
trunc = TruncatedNormal(mean=0.0, stddev=0.01)
cnst = Constant(value=1)
return Dense(
units, activation=activation,
kernel_initializer=trunc, bias_initializer=cnst,
)
def AlexNet():
model = Sequential()
#conv1
model.add(conv2d(96, 11, strides=(4, 4), padding='valid', bias_init=0,
input_shape=(image_size, image_size, channel)))
#pool1
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2,2)))
model.add(BatchNormalization())
#conv2
model.add(conv2d(256, 5))
#pool2
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2,2)))
model.add(BatchNormalization())
#conv3
model.add(conv2d(384, 3, bias_init=0))
#conv4
model.add(conv2d(384, 3))
#conv5
model.add(conv2d(256, 3))
#pool5
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2,2)))
model.add(BatchNormalization())
#fc6
model.add(Flatten())
model.add(dense(4096))
model.add(Dropout(0.5))
#fc7
model.add(dense(4096))
model.add(Dropout(0.5))
#fc8
model.add(dense(num_classes, activation='softmax'))
model.compile(optimizer=SGD(lr=0.01), loss='categorical_crossentropy', metrics=['accuracy'])
return model
model = AlexNet()
model.summary()
重みは平均0, 標準偏差0.01としたガウス分布で初期化,バイアスは2,4,5番目の畳み込み層及び全結合層は1で,それ以外の層は0で初期化したと論文に書かれており,上のコードにおけるtrunc, cnstがそれにあたります.その他に関しては,上の表と見比べていただければある程度理解できると思います.
出力は以下の通りです.
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 55, 55, 96) 34944
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 27, 27, 96) 0
_________________________________________________________________
batch_normalization_1 (Batch (None, 27, 27, 96) 384
_________________________________________________________________
conv2d_2 (Conv2D) (None, 27, 27, 256) 614656
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 13, 13, 256) 0
_________________________________________________________________
batch_normalization_2 (Batch (None, 13, 13, 256) 1024
_________________________________________________________________
conv2d_3 (Conv2D) (None, 13, 13, 384) 885120
_________________________________________________________________
conv2d_4 (Conv2D) (None, 13, 13, 384) 1327488
_________________________________________________________________
conv2d_5 (Conv2D) (None, 13, 13, 256) 884992
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 6, 6, 256) 0
_________________________________________________________________
batch_normalization_3 (Batch (None, 6, 6, 256) 1024
_________________________________________________________________
flatten_1 (Flatten) (None, 9216) 0
_________________________________________________________________
dense_1 (Dense) (None, 4096) 37752832
_________________________________________________________________
dropout_1 (Dropout) (None, 4096) 0
_________________________________________________________________
dense_2 (Dense) (None, 4096) 16781312
_________________________________________________________________
dropout_2 (Dropout) (None, 4096) 0
_________________________________________________________________
dense_3 (Dense) (None, 1000) 4097000
=================================================================
Total params: 62,380,776
Trainable params: 62,379,560
Non-trainable params: 1,216
_________________________________________________________________
Cifar-10の学習
画像の入力サイズが違う(Cifar-10は32x32)ため,モデルを少々変更します.変更に際してはこちらの記事を参考にさせていただきました.ありがとうございました.
構成は以下の通りです.赤字が変更箇所になります.
| Layer | Kernel_size | Filters | Strides | Padding | Output_size |
|---|---|---|---|---|---|
| Conv_1 | (3, 3) | 96 | (1, 1) | 1 | (None, 32, 32, 96) |
| Max_pool_1 | (2, 2) | - | (2, 2) | - | (None, 16, 16, 96) |
| Conv_2 | (5, 5) | 256 | (1, 1) | 2 | (None, 16, 16, 256) |
| Max_pool_2 | (2, 2) | - | (2, 2) | - | (None, 8, 8, 256) |
| Conv_3 | (3, 3) | 384 | (1, 1) | 1 | (None, 8, 8, 384) |
| Conv_4 | (3, 3) | 384 | (1, 1) | 1 | (None, 8, 8, 384) |
| Conv_5 | (3, 3) | 256 | (1, 1) | 1 | (None, 8, 8, 256) |
| Max_pool_5 | (2, 2) | - | (2, 2) | - | (None, 4, 4, 256) |
| FC_6 | - | - | - | - | (None, 4096) |
| FC_7 | - | - | - | - | (None, 4096) |
| FC_8 | - | - | - | - | (None, 10) |
作成したものはこちらに置いておきます.
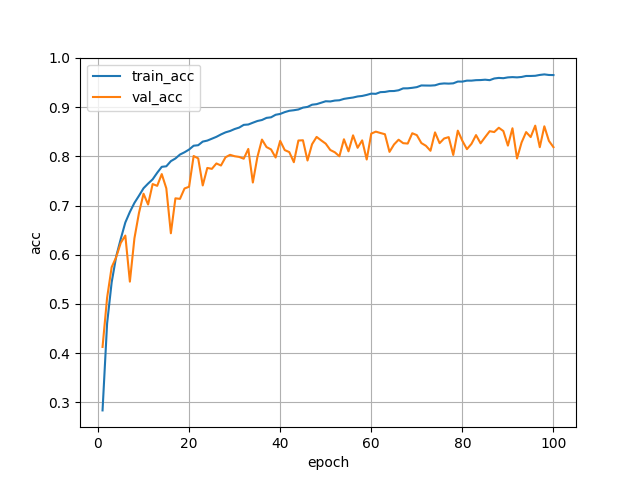
結果は以下のようになりました.val_accは最高で86%です.
おわりに
AlexNetにおけるCifar-10の精度は89%だそうです(参考).LRNやPCA Color Augmentationを使用することで精度向上できるのかな?気が向いたらやってみたいと思います.
参考論文
A. Krizhevsky, I. Sutskever, and G. E. Hinton : ImageNet Classification with Deep Convolutional Neural Networks, In Advances in Neural Information Processing Systems. [PDF]