このコンテンツはMaruLabo × JAWS-UG AI #3でハンズオンの課題として使うために作成したものです。
Jupyter Notebookとすぐに実行するためのDockerfileをGitHubにて公開しています。
当記事のプログラム中で画像を表示する部分がありますが、データセットの規約の関係上、一部の出力画像は掲載しておりません。
KerasによるAlexNetを用いた犬猫分類モデルの実装
TensorFlowをバックエンドに、Kerasを用いて犬猫分類モデルを構築します。モデル構成はAlexNet(論文)を用います。
犬猫のデータセットはDogs vs. Cats Redux: Kernels Editionを用います。訓練用データセット(./train/*.jpg)とテスト用データセット(./test/*.jpg)を事前に用意してください。
%matplotlib inline
import os, sys, cv2, random
import numpy as np
import pandas as pd
from PIL import Image
import matplotlib.pyplot as plt
from matplotlib import ticker
import seaborn as sns
np.random.seed(722)
from keras.initializers import TruncatedNormal, Constant
from keras.models import Sequential
from keras.optimizers import SGD
from keras.layers import Input, Dropout, Flatten, Conv2D, MaxPooling2D, Dense, Activation, BatchNormalization
from keras.callbacks import Callback, EarlyStopping
from keras.utils.np_utils import to_categorical
Using TensorFlow backend.
データを準備します。ここでは、画像をすべて224x224のサイズにリサイズしています。
AlexNetでは本来、256x256の画像データからランダムに224x224に切り抜いた画像を入力として扱っています。データ増強はオーバーフィットを抑える効果がありますが、データが増えることにより訓練に時間がかかるため、今回は224x224のまま入力として扱います。
訓練データは25000枚、テストデータは12500枚です。
ROWS = 224
COLS = 224
CHANNELS = 3
TRAIN_DIR = 'train/'
TEST_DIR = 'test/'
CACHE_DIR = 'cache/'
FORCE_CONVERT = False
def read(name):
return cv2.imread(name, cv2.IMREAD_COLOR)
def convert(img):
return cv2.resize(img, (ROWS, COLS), interpolation=cv2.INTER_CUBIC)
def save(name, img):
cv2.imwrite(CACHE_DIR + name, img)
return img
def ls(dirname):
return [dirname + i for i in os.listdir(dirname)]
# 毎回変換していると時間がかかるので、一度変換したらキャッシュします
# キャッシュ用のディレクトリを作ります
if not os.path.exists(CACHE_DIR):
os.mkdir(CACHE_DIR)
if not os.path.exists(CACHE_DIR + TRAIN_DIR):
os.mkdir(CACHE_DIR + TRAIN_DIR)
if not os.path.exists(CACHE_DIR + TEST_DIR):
os.mkdir(CACHE_DIR + TEST_DIR)
sys.stdout.write('Loading... ')
train_files = ls(CACHE_DIR + TRAIN_DIR)
train = np.array([read(i) for i in train_files])
test_files = ls(CACHE_DIR + TEST_DIR)
test = np.array([read(i) for i in test_files])
print('Done!')
if FORCE_CONVERT or len(train) < 25000:
sys.stdout.write('Process train data... ')
train = np.array([save(TRAIN_DIR + i, convert(read(TRAIN_DIR + i))) for i in os.listdir(TRAIN_DIR)])
train_files = ls(CACHE_DIR + TRAIN_DIR)
print('Done!')
if FORCE_CONVERT or len(test) < 12500:
sys.stdout.write('Process test data... ')
test = np.array([save(TEST_DIR + i, convert(read(TEST_DIR + i))) for i in os.listdir(TEST_DIR)])
test_files = ls(CACHE_DIR + TEST_DIR)
print('Done!')
print("Train shape: {}".format(train.shape))
print("Test shape: {}".format(test.shape))
Loading... Done!
Train shape: (25000, 224, 224, 3)
Test shape: (12500, 224, 224, 3)
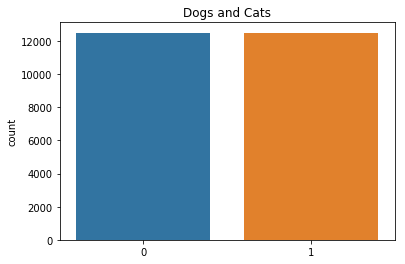
ラベルデータを用意します。このデータセットではファイル名の先頭の文字列がそのままラベルになっているので、犬を0、猫を1としてラベルの配列を作ります。その後、to_categorical関数によりOHVに変換しています。
また、データが均等であることを確認するために、データの枚数をグラフで表示しています。
labels = []
for i in train_files:
if 'dog' in i:
labels.append(0)
else:
labels.append(1)
sns.countplot(labels)
plt.title('Dogs and Cats')
labels = to_categorical(labels)
print(labels)
[[ 1. 0.]
[ 1. 0.]
[ 0. 1.]
...,
[ 1. 0.]
[ 0. 1.]
[ 1. 0.]]
データセットの一部を表示してみます。
train_dogs = [i for i in train_files if 'dog' in i]
train_cats = [i for i in train_files if 'cat' in i]
def show_train_image(i):
dog = read(train_dogs[i])
cat = read(train_cats[i])
pair = np.concatenate((dog,cat), axis=1)
plt.figure(figsize=(10,5))
plt.imshow(pair)
plt.show()
for i in range(0,5):
show_train_image(i)
補足:データの利用規約の関係から出力は省略しています。
AlexNetを構築します。極力元の論文どおりに実装していますが、元の論文ではBatchNormalizationではなくLocal Response Normalizationというものが用いられています。Kerasからは実装が削除されてしまったのでBatchNormalizationを使います。実際のところ、LRNは効果が薄く、最近は全く使われていません。また、フィルタサイズが大きくなっています。
def conv2d(filters, kernel_size, strides=1, bias_init=1, **kwargs):
trunc = TruncatedNormal(mean=0.0, stddev=0.01)
cnst = Constant(value=bias_init)
return Conv2D(
filters,
kernel_size,
strides=strides,
padding='same',
activation='relu',
kernel_initializer=trunc,
bias_initializer=cnst,
**kwargs
)
def dense(units, **kwargs):
trunc = TruncatedNormal(mean=0.0, stddev=0.01)
cnst = Constant(value=1)
return Dense(
units,
activation='tanh',
kernel_initializer=trunc,
bias_initializer=cnst,
**kwargs
)
def AlexNet():
model = Sequential()
# 第1畳み込み層
model.add(conv2d(96, 11, strides=(4,4), bias_init=0, input_shape=(ROWS, COLS, 3)))
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
model.add(BatchNormalization())
# 第2畳み込み層
model.add(conv2d(256, 5, bias_init=1))
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
model.add(BatchNormalization())
# 第3~5畳み込み層
model.add(conv2d(384, 3, bias_init=0))
model.add(conv2d(384, 3, bias_init=1))
model.add(conv2d(256, 3, bias_init=1))
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
model.add(BatchNormalization())
# 密結合層
model.add(Flatten())
model.add(dense(4096))
model.add(Dropout(0.5))
model.add(dense(4096))
model.add(Dropout(0.5))
# 読み出し層
model.add(Dense(2, activation='softmax'))
model.compile(optimizer=SGD(lr=0.01), loss='categorical_crossentropy', metrics=['accuracy'])
return model
モデルを構築し、summary関数で構造を表示します。
訓練データのうち25%をバリデーションデータとして扱います。最大15エポック、かつvalidation lossを監視して改善が見受けられない場合は早急に訓練を打ち切ります。
メモリが足りない場合はバッチサイズを減らしてみてください。
データをシャッフルするため、実行のたびに訓練結果は変わります。
追記:AWSのp2.xlarge(K80x1)だと60s/ep程度かかるようです。
model = AlexNet()
model.summary()
early_stopping = EarlyStopping(monitor='val_loss', patience=3, verbose=1, mode='auto')
history = model.fit(train, labels, epochs=15, batch_size=128, shuffle=True, validation_split=0.25, callbacks=[early_stopping])
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_6 (Conv2D) (None, 56, 56, 96) 34944
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 27, 27, 96) 0
_________________________________________________________________
batch_normalization_4 (Batch (None, 27, 27, 96) 384
_________________________________________________________________
conv2d_7 (Conv2D) (None, 27, 27, 256) 614656
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 13, 13, 256) 0
_________________________________________________________________
batch_normalization_5 (Batch (None, 13, 13, 256) 1024
_________________________________________________________________
conv2d_8 (Conv2D) (None, 13, 13, 384) 885120
_________________________________________________________________
conv2d_9 (Conv2D) (None, 13, 13, 384) 1327488
_________________________________________________________________
conv2d_10 (Conv2D) (None, 13, 13, 256) 884992
_________________________________________________________________
max_pooling2d_6 (MaxPooling2 (None, 6, 6, 256) 0
_________________________________________________________________
batch_normalization_6 (Batch (None, 6, 6, 256) 1024
_________________________________________________________________
flatten_2 (Flatten) (None, 9216) 0
_________________________________________________________________
dense_4 (Dense) (None, 4096) 37752832
_________________________________________________________________
dropout_3 (Dropout) (None, 4096) 0
_________________________________________________________________
dense_5 (Dense) (None, 4096) 16781312
_________________________________________________________________
dropout_4 (Dropout) (None, 4096) 0
_________________________________________________________________
dense_6 (Dense) (None, 2) 8194
=================================================================
Total params: 58,291,970
Trainable params: 58,290,754
Non-trainable params: 1,216
_________________________________________________________________
Train on 18750 samples, validate on 6250 samples
Epoch 1/15
18750/18750 [==============================] - 36s - loss: 4.6541 - acc: 0.5245 - val_loss: 3.2625 - val_acc: 0.5008
Epoch 2/15
18750/18750 [==============================] - 35s - loss: 0.9666 - acc: 0.6317 - val_loss: 0.7646 - val_acc: 0.5144
Epoch 3/15
18750/18750 [==============================] - 35s - loss: 0.5565 - acc: 0.7352 - val_loss: 0.6393 - val_acc: 0.6290
Epoch 4/15
18750/18750 [==============================] - 35s - loss: 0.4595 - acc: 0.7864 - val_loss: 0.6367 - val_acc: 0.7058
Epoch 5/15
18750/18750 [==============================] - 35s - loss: 0.4066 - acc: 0.8185 - val_loss: 0.4046 - val_acc: 0.8091
Epoch 6/15
18750/18750 [==============================] - 35s - loss: 0.3604 - acc: 0.8404 - val_loss: 0.3839 - val_acc: 0.8248
Epoch 7/15
18750/18750 [==============================] - 36s - loss: 0.3170 - acc: 0.8600 - val_loss: 0.4346 - val_acc: 0.8005
Epoch 8/15
18750/18750 [==============================] - 35s - loss: 0.2880 - acc: 0.8778 - val_loss: 0.6159 - val_acc: 0.7440
Epoch 9/15
18750/18750 [==============================] - 35s - loss: 0.2518 - acc: 0.8948 - val_loss: 0.7515 - val_acc: 0.6846
Epoch 10/15
18750/18750 [==============================] - 36s - loss: 0.2191 - acc: 0.9087 - val_loss: 0.4569 - val_acc: 0.8051
Epoch 00009: early stopping
訓練履歴をグラフで示します。
def plot_history(history):
plt.plot(history.history['acc'],"o-",label="accuracy")
plt.plot(history.history['val_acc'],"o-",label="val_acc")
plt.title('model accuracy')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.ylim(0, 1)
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
plt.show()
plt.plot(history.history['loss'],"o-",label="loss",)
plt.plot(history.history['val_loss'],"o-",label="val_loss")
plt.title('model loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.ylim(ymin=0)
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
plt.show()
plot_history(history)
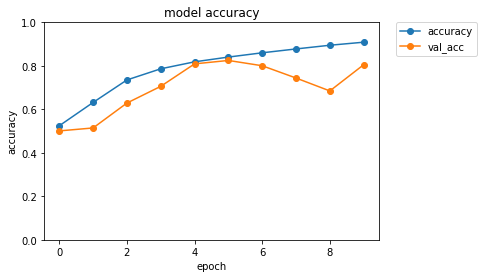
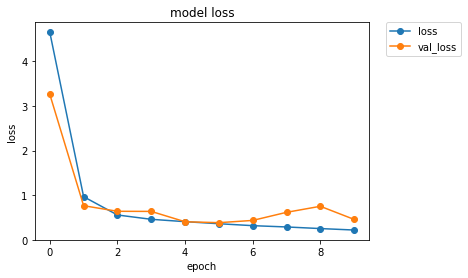
テストを行い、結果の一部を画像とともに表示します。
結構間違えます。明確な指針が有るわけではないですが、私個人の見解としては、実用的な正答率は98%が最低ラインだと思います。
もし90%だとしたら、「10回に1回間違えた」と考えれば、それがどれだけ悪い結果なのか容易に想像がつくと思います。98%でも、「50回に1回は間違えた」わけです。
predictions = model.predict(test, verbose=0)
for i in range(0,20):
print('Dog : {}'.format(predictions[i][0]))
print('Cat : {}'.format(predictions[i][1]))
if predictions[i][0] > predictions[i][1]:
print('I am {:.2%} sure this is a Dog.'.format(predictions[i][0]))
else:
print('I am {:.2%} sure this is a Cat.'.format(predictions[i][1]))
plt.imshow(test[i])
plt.show()
補足:データの利用規約の関係から出力は省略しています。
Improvement
冒頭でも述べたように、今回はオーバーフィットを減らすためのデータ増強を行っていません。
AlexNetは、ランダムな切り抜き、平行移動、水平反射、RGB強度の変更などを行い、精度が改善したことを論文で示しています。
実際にこういったデータ増強は大きな効果を示すことが知られています。論文中でも、データの増強を行わない場合はオーバーフィットに悩まされる結果になったと述べられています。
ランダムな切り抜き、平行移動、水平反射などは画像認識では今や一般的で、十分に効果が期待できます。また、RGB強度の変更は自然画像に対して特に有効であると言われています。手法はこれらだけではなく、画像にノイズを加えたり、回転を行う方法などもあります。
実際にデータを増強し、精度が改善することをぜひ確認してみてください。
参考文献
-
Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "Imagenet classification with deep convolutional neural networks." Advances in neural information processing systems. 2012. [pdf]
-
Srivastava, Nitish, et al. "Dropout: a simple way to prevent neural networks from overfitting." Journal of Machine Learning Research 15.1 (2014): 1929-1958. [pdf]
-
TensorFlow https://www.tensorflow.org/
-
Keras (ja) https://keras.io/ja/