この記事で伝えたいこと(忙しい人向け)
- 新人ほど「保守していく」ことの感覚が腹落ちしにくいのではないか説
- 我々は保守しやすいコードを書くべきであり、保守しやすいコードを達成するための手段として原理原則やデザインパターンが存在している
- 保守ってなんで必要なんだっけ?という体系的な理解を持ったうえで、具体的なテクニックを学んでいくことが大事
本記事はあくまで私見です。内容に違和感などあればコメントください。
// 追記(2023/12/9)
なんとミノ駆動 さんにコメントいただけました。
もちろん良いコード/悪いコードで学ぶ設計入門 ―保守しやすい 成長し続けるコードの書き方は読んで影響を受けてます。
とってもうれしい。
想定読者
- 新卒 ~ 2年目くらいまでのプログラミング初心者
- Webアプリの保守開発をしているエンジニア
- 3ヶ月前くらいの自分(未経験からエンジニアになって1年くらい)
こんなことないでしょうか
- 先輩などから原理原則の観点を共有してもらったり、そのうえで自分なりに勉強をしているはずなのに、実務ではなかなか手が動かない
- 変更指示に対して、「先輩が言っているんだし正しいんだろうな」とその場では指示の理由や目的が分からないまま修正を行うことがある(分かっていないため別の機会で同じ指摘を受けることがある)
- 自身のコーディングには判断基準や根拠がなく、なんとなくの判断に頼ることがある
- 上記が積み重なって「全然できるようにならないな......」と自信を失うことがある
- 上記のように伸び悩んでいる後輩や新人がいる
コメントや指摘を受けた際には「なるほど!」と一時的に理解できても、他の類似ケースに対応できなかった、観点は分かっていたはずなのに思い浮かばなかった、「そのときそのときでの最適」が分からず完全感覚プログラマーが僕の名だった.........。
私は半年くらいずっとこれでした。自身の経験からこの原因の1つは、「保守していくことの全体像が見えていなかった」ことだと思っています。
いままで「原理原則をマスターするんや!」「デザインパターン?なんやかっこええやん」と具体的な「手段」ばかり勉強していましたが、おもしろいくらい全然使いこなせるようにならないんですよね。勉強した感覚だけはある一方、それらをうまく使いこなせない期間が続くと、
「プログラミング勉強したけど分からんし開発者向いてないわこれ........」
と、どんどんつらく、苦しくなります。
身につかない理由の1つは、「保守していく」という感覚が腹落ちしていないから説
小手先のテクニックや個別のプログラミング原理原則「だけ」を勉強していても、その知識をいつ、どこで、なんのために使用すべきかが分からない、分からないから使えない、うまくいかないから苦しくなってモチベも下がっていく。最悪なループですね。
このループから抜け出すためのヒントは、
「それぞれの原理原則やテクニックはあくまで表現のための手段であり、それらの手段はすべて1つの目的につながっているイメージ」
なんだと思います。
なので、単にテクニックや原理原則を学ぶだけでなく、それらの知識を実践的に活用するために、なんでその原則が存在するんだっけ?プログラミングを通じて達成したいものって何だっけ?を一度考えてみることをおすすめします。
古代中国で書かれた文献には、こんな言葉があるそうです。
─── 子曰く、「保守の果実は、未熟なる手には宿らぬと知らんや」と。
意訳すると、「子(孔子)は言いました、保守することの利益(あるいは保守に対する意識)は、経験の少ない者にどうして知ることができようか (いや知ることなどできるはずがない)」ということです。
これは、新人プログラマなど経験のまだまだ浅い人に「コードは保守していくものだ」という感覚は得にくく、保守の大切さを本当の意味で理解するには、同じコードを何度も見た経験やコードの理解に苦しんだ経験を積むことが必要である、という教えです。
実際私は未経験からプログラマーになったわけですが、配属後1年くらいの時点では、これから長い期間同じコードを保守し続けるという実感があまり湧いていませんでした。それよりも「Javaの勉強したらなんか良いコード書けるようになりそう」「原理原則?デザインパターン?学んだらどっかで使えそう」という感じで完全に手段が目的化していました。
おそらく今まで読んだいろいろな本の中で、「なんで保守は大事なのか」みたいな内容がいたるところにあったんでしょうけど、まったく記憶にないです。知らないものは見えない、関心のないものは引っかからない、見えてないんだから仕方ない。(しかたないよね???)普通の新人は「はやく一人前にならなきゃ」の気持ちが先行するはずなので、意識がそこまで回ってないかもしれません。
とにかく、「保守しやすいコードが大切なのだ」という観点をなるべく早く腹落ちさせるために、「なぜ保守しやすいコードが大切なのか」をちゃんと理解することから始めるべきかなと思いました。
我々はプログラミングを通して何を達成すべきか
ビジネスにおいて最も重要な使命は、お客様に価値を提供することですよね。我々開発者は、例えばWebアプリケーションやその他のサービスを通じて、お客様に価値ある体験と利益をもたらすという役割を担っているわけです。開発者として、製品開発の視点から顧客に真の価値を提供することが我々の責務であり、その使命に全力で取り組む必要があります。
そして、その価値提供を実現するためには、「機能追加 / 拡張と継続的な保守のバランス」をとりながら「現存のサービスの品質向上」をしていくことが不可欠になります。
「新規機能開発と継続的な保守のバランス」が大切なのは、新規機能をたくさんリリースしても、不具合だらけではまったく意味がないし、逆に既存のサービスの保守ばかりしていても、時代とともに変化するお客様のニーズに応えられず、競争優位を保つことが難しくなるためです。
そして、「現存のサービスの品質向上」をきちんと考えてコードの安定性や効率性を維持することで、お客様が安心して利用できる環境・サービスの提供につながり、それが結果として企業にもポジティブな影響を与えます。
つまり上記の理由から、お客様の期待に応え続けるためには、変化に柔軟でかつ効果的・効率的な開発プロセスを構築、維持していくことが重要になるわけですね。
私事ですが、Webアプリケーションエンジニアとしての業務を考えると、基本は以下のようになります。
- 新規機能開発や既存機能の拡張
- 不具合修正などの保守
- お客様からの問い合わせなどの顧客対応
というかほぼこれです。サービスの規模が大きくなるほど、実装済みかつ稼働中のコードが増えるため、新規機能開発を専門に担当しない限り、自然と保守の割合(というより、見なくてはいけない範囲)も増えていくことになります。
従って、保守しやすいコードこそが顧客価値提供の根幹と言ってもいいでしょう。
保守しやすいコードとはなにか
保守しやすいコードとは、変更に強く理解しやすいコード、つまり変更容易性が高く、理解容易性が高いコードです。 一般的に言われる「きれいなコード」「いいコード」とはつまりこういうことで、上記が満たされたコードであると私は理解しています。
変更容易性とは、「ソフトウェアが変更に対してどれだけ容易に適応できるか」を示す特性であり、この変更容易性が高いとは、ソフトウェアに対する新機能の追加、既存機能の変更、バグ修正などの変更を簡単かつ安全に行うことができるということ。
理解容易性とは、コードが他の開発者やメンテナンス担当者によって理解しやすいかどうかを示す特性であり、理解容易性が低い状態のコードは複雑度が高くてバグの温床となります。そのため、自分以外の他の開発者と協力して保守していく上で、理解容易性が高いコードは不可欠です。
上記を追求することが、コードの集合体であるソフトウェアの品質を向上させ、保守性を高める。これにより、新しい機能の追加や変更がスムーズに行え、柔軟かつ持続可能な、保守しやすいコードになっていく。結果、顧客価値提供の可能性を大きくすることができ、ビジネスにとっても良い結果をもたらす。
ゆえに我々はそういうことを日々意識してコーディングしなければいけないのだ!!!!
すべての原理原則は、保守しやすいコードを維持し続けるためのtipsである
さて、プログラミングにおける原理原則やデザインパターンは、基本的にはすべて「保守しやすいコード」という大きな目的を達成するための手段です。なぜなら、基本的にプログラミングの原理原則は、変更に強い または 理解しやすい(あるいは その両方)を満たすために存在しているからです。
実際、過去のエンジニアたちが「保守しやすいコード」を求めた結果、いろんな設計思想や設計指針、オブジェクト指向、原理原則やデザインパターンが生まれてきたわけです。
参考:
- 新人プログラマに知っておいてもらいたい人類がオブジェクト指向を手に入れるまでの軌跡
- オブジェクト指向のいろは
- オブジェクト指向は単なる【整理術】だよ
- [初心者]オブジェクト指向でなぜつくるのか
- デザインパターン (ソフトウェア)(wikipedia)
- デザインパターンを出自から深く理解する / understanding design pattern from the origin
さらに、以下の記事で、テスト駆動開発で有名な @t_wada さんもこんなことを言っています。
Maintainability(保守性)は、Testability(テスト容易性)、Understandability(理解容易性)、Modifiability(変更容易性)から構成されています。テスト容易性とは、テストのやりやすさ。理解容易性は、ソフトウェアが理解しやすいかどうか。変更容易性は、ソフトウェアが変更しやすいかどうか。この3つの要素によって保守性は構成されています。
(引用元:【誤解あるある】システム開発の品質とスピードはトレードオフなのか?)
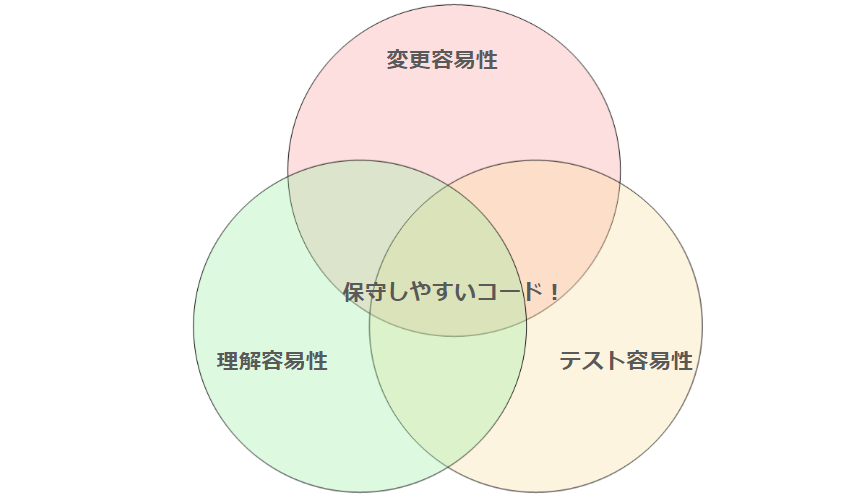
上記では、保守しやすいコードを実現するための観点は、変更容易性、理解容易性、およびテスト容易性の3つが指摘されています。ゆえに、「基本的にプログラミングの原理原則は、変更に強い または 理解しやすい(あるいは その両方)を満たすために存在している」は間違いではなさそうですよね。
「いやでも、変更に強い・理解しやすいの2つじゃなくて、そこにテスト容易性を加えた3つの観点なのでは?」と思うかもしれませんが、私は「いったん変更容易性と理解容易性の2つの観点を考えられるようになる」が目標でいいと思います。理由は単純で、変更容易性と理解容易性が満たされているコードはだいたい単体テストが書きやすいからです。(ただの1年半の経験談ですが、、)
「テストがないコードはレガシーコードだ!」という時代です。テストの書きにくいクラスを一度リファクタしてからテストが書けるコードに修正し、やっとの思いでテストをあててから修正ができた、など苦労してきた方も大勢いるでしょう(なみだ)実際、レガシーコード改善ガイドには「レガシーコードのジレンマ」として、
コードを変更するためには、テストを整備する必要がある。多くの場合、テストを整備するためには、コードを変更する必要がある。
との記載もありますし。
単体テストが保守性の向上に寄与することは確かですが、そのためにはまずテスト可能なコードでなければならないはずで、我々が新しくコードを追加するときくらいはテスト書きやすいコードを書きたいですよね。なので、変更容易性と理解容易性の観点をコーディングの基本に据えることが重要であり、新人プログラマがまず頭に入れておくべき第一目標だと考えています。
変更容易性と理解容易性だけ分かっておけば、原理原則は知らなくてもいい(暴論)
なかなか乱暴なこと言ってますが、的を得ているとも思います。繰り返しますが、原理原則やデザインパターンが目指すべき先は保守しやすいコード、すなわち変更容易性と理解容易性が高いコードだからです。
例えば、SRP原則を知らなくても、変更の影響範囲を限定するためにメソッドで単位で責務の分離を考えたり、驚き最小の原則を知らなくても、第三者が自分の書いたコードを読むことを考慮して適切な命名を意識したりはできそうですよね。効率が悪くて遠回りにはなりそうですが、保守しやすいコードは何なのか?の意識だけあれば、小手先の原理原則に気を取られてそれぞれの理解が曖昧で、脳みそパンク(OutOfMemory)したままコーディングしている人より「いいコード」は書けそうですよね。(ここで胸熱タイトル回収)
また、この意識があれば、チームメンバーと建設的な議論ができるようになります。変更容易性・理解容易性にコンフリクトするような指摘に対しては、無視してOK!「ご指摘いただいたそれは変更容易性 or 理解容易性の観点から(略)」と先輩レビュワーとも対等な関係で話ができるようになると思うからです。
保守しやすいコードのために変更容易性・理解容易性があるという意識をしたうえで、議論の中で知らなかった観点があれば脳みそに if 文が1つ加わって、観点(実現の手段)が増えます。脳内 if 文で適切な条件分岐ができれば、自分にとってもチームにとっても、より生産性の高い議論ができるし、書けるコードはどんどん良くなっていくし、判断に迷う葛藤の時間も減るし、いいことばっかりです。
ゆえに、脳内の適切な条件分岐(= 判断のための観点)を意図的に増やすための「過去からの経験知」こそが原理原則であり、デザインパターンです。つまり保守性の向上や品質の高いコードを実現するために、具体的な手法としてそれらを学ぶべきという意識が大事なんです。「保守性の理解がさき、原理原則デザインパターンはあと。」みつをも言うてます。
現状、理解しているイメージ
ここまでの内容はつまり、以下のような図に落とし込めます。
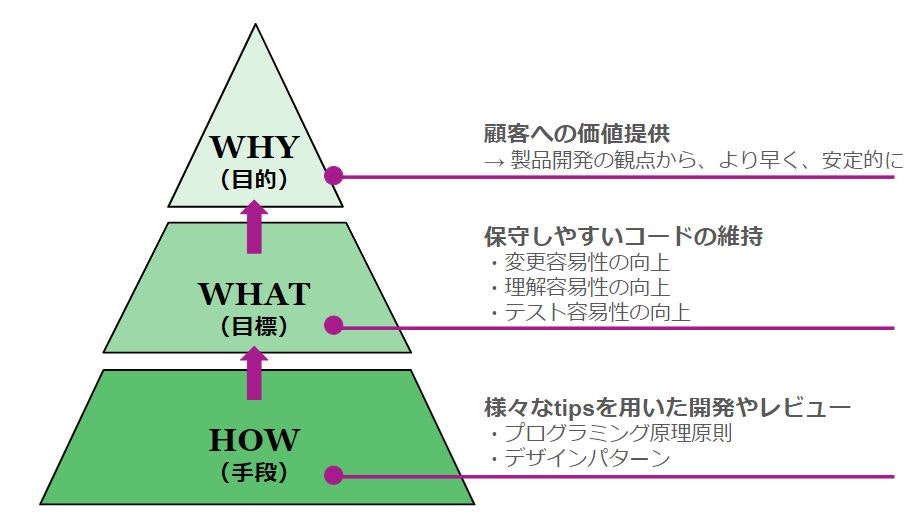
この理解(イメージ)が最初から持てていれば、勉強してるんだけどできるようにならないみたいな負のループからは抜け出せる気がしています。
繰り返しにはなりますが、特にコーディングするうえで意識すべきは大目標である「変更容易性」と「理解容易性」です。とりあえずこの意識だけあればなんとかなります。
【ゆる募】
最初は、以下のように分けようかと思ってました。
- 目的:顧客価値提供
- 目標:保守しやすいコード(変更 / 理解 / テスト容易性)
- 設計指針(中間目標):関心の分離 / 高凝集化 / 疎結合化
- 手段:プログラミング原理原則・デザインパターン・etc...
ですが、「設計指針」と「手段」の粒度の違いがうまく説明できないと思ってやめました。この辺でなにか「こういう観点どう?」みたいなのがあれば後学のためにコメントをいただきたいです。
個人的には原理原則やデザインパターンはいったん「関心の分離」「高凝集化」「疎結合化」を経由する気がしているので、「指向性として」は間違いではないと思っているんですよね...。
おわりに
というわけで、原理原則やデザインパターンを覚えようとするばかりでうまくいかなかった負のループからこうやって抜け出しました、という内容でした。もし私と同じように新人プログラマアンチパターンにハマっている人がいたら、この記事が前に進むためのきっかけになれたら嬉しいです。
p.s. 私が言いたかったことは以下の記事でうまいことまとめられていました。
知識についておいしいところをつまみ食いしようとしたり、文法やパラダイムについての理解を自分なりに整理できていない場合、知識ではなく、tipsになってしまい応用が利かず、無限にtipsを追い求めてしまう。
(引用元:ペアプログラミングして気がついた新人プログラマの成長を阻害する悪習 > 体系的知識を身につける)
ここから下はおまけです。時間があったらぜひのぞいてみてください。
保守しやすいコードを目指して(tips集 / 随時更新)
以下は、あくまで私自身が勉強した / 教えてもらった原理原則や考え方などが、変更容易性と理解容易性にどう結びついているかを備忘録的にまとめたものになっています。すべての原理原則は「保守しやすいコード」につながっている。これがわかった瞬間、今までいろんなとこで目にしてきた原理原則がすっきりと腹落ちというか、ロジックでつながるようになった気がしてます。
なので基本的に以下では主に変更容易性と理解容易性の2つに言及してます。
目標(満たしたい観点)
変更容易性
変更容易性は、達人プログラマーではETC(Easier To Change)原則と呼ばれたりしています。ETC変則は原則というか、変更容易性が高い = Easier To Changeな状態だよね、ETCな状態目指そうね、という思想みたいな気がします。多くの原則はETC原則を達成するために存在していると言っても過言じゃないと思います。
ETCな状態ってつまり以下のようなことだと思います。
変更容易性が高い(Easier To Change)な状態である = コードが変更や拡張に対して柔軟である = 修正箇所が少ない かつ 影響範囲が少ない
- 変更時の修正箇所が局所的(見るべき箇所が少ない)
- ロジックが散らばっていない(高凝集)
- 影響範囲が小さい(考慮すべき箇所が少ない)
- モジュールごとの依存関係が少ない(疎結合)
理解容易性
理解容易性は言葉の通りの意味ですね。理解容易性が高い状態は、かみ砕いて言えば以下だと思っています。
理解が容易である = 該当の処理がすぐ特定できる かつ 誰が見ても同じ解釈になる かつ 解釈に至るまでのスピードが速い
- 該当の処理がすぐ特定できる
- ロジックにまとまりがある(高凝集)
- 外部の状態に依存していない
- 誰が見ても同じ解釈になる
- 明確な命名規則
- 適切なコメントアウトやドキュメンテーション
- 解釈に至るまでのスピードが速い
- シンプルで直感的なロジック
- 役割ごとに適切に分割されたクラスやメソッド
設計指針
関心の分離
ソフトウェアの変更容易性と理解容易性を高めるための設計原則。
関連する機能を独立したモジュールに分割することで、変更の影響範囲を限定できる。
また、異なる関心事を別々のモジュールに分離することで、各モジュールの役割と責任を明確にし、コードの読みやすさを向上させることができる。
変更容易性:
一部の変更が他の部分に与える影響を最小限に抑えることができるため、変更が容易になる。
理解容易性:
独立した「部分」だけで理解することができるため、全体の理解が容易になる。
参考
凝集度
凝集度は、関心の分離を実現するための重要な観点。
高凝集モジュールは関連する機能や処理が一箇所にまとまっていて、影響範囲が局所的になるため変更コストが下がる。また関連する処理がまとまるため、処理の役割や責任が明確になる。
一方、低凝集モジュールでは関連するロジックが散在しており、変更コストが高くなりがち。また、関連ロジックが散在しているため、コードを探し回ったり理解に苦しむ可能性が高くなる。
変更容易性:
凝集度を高めること、つまり関連する要素をまとめて関心や役割に合わせて適切にグループ化することで、変更の影響範囲を制限できる。
理解容易性:
特定の機能を担当するコンポーネントに関連するコードが集中するため、その機能の理解がしやすくなる。また、他のコンポーネントとの依存関係も少なくなるため、全体の理解も容易になる。
参考:
- オブジェクト指向のその前に-凝集度と結合度/Coheision-Coupling
- 良いコードとは何か - エンジニア新卒研修 スライド公開
- 論理的凝集のサンプルを考えてみた
- 高凝集なコード
- 存在感の薄い「凝集度」に光を当てる - LCOMでクラスを凝集度を測定しよう
結合度
結合度とは、モジュール間の関係の強さを表す指標のこと。結合度が高い(モジュール同士が強く結びついている)場合、変更容易性が低下する。
- 特定の場所を変更すると、それに結びついている他のモジュールも影響を受ける可能性がある。なくても確認するコストがかかる
- モジュールを利用する場合に、利用するモジュールと結びついている他のモジュールも必要なため利用が難しくなる
- モジュールのコード単体だけでは処理が理解しにくくなる
そこで、できるだけ疎結合(モジュール間の関係を緩やかにする)を目指す必要がある
変更容易性:
異なるモジュール・コンポーネント間の依存関係が低くなり、特定の変更が他の部分に影響を与えずに行えるため、変更が容易になる。
理解容易性:
依存関係が少なくなると個々のコンポーネントを独立して理解することができ、全体の理解が容易になる。また、疎結合化で依存関係の理解が容易になるため、全体の構造も理解しやすくなる。
参考:
プログラミング原理・原則
DRY原則(Don't Repeat Yourself)
「コードの重複をしてはいけません」と誤解しがちだが、それはOAOO原則。本質は「知識の二重化はよくないよね」という原則。車輪の再発明は防ごう。
ここで言う知識とは?ミノ駆動 さんは以下のように説明している。(バカ分かりやすい)
知識とは一体何でしょうか。
粒度、技術レイヤー、様々な観点で考えることができますが、その内のひとつに、ソフトウェアが対象とするビジネス知識があります。
ビジネス知識とは何でしょうか。
それはソフトウェアで扱うビジネス概念です。
引用元:単一責任原則で無責任な多目的クラスを爆殺する > DRY原則の誤用と密結合
つまり知識の重複とは、「ビジネス概念の重複」であり、「共通している同じコード」のことではない。まったく同じコードでもドメインが違えば知識が異なる可能性があるので要注意。また、ミスって共通化の罠に陥った場合、論理的凝集が生み出されることが多い。
変更容易性:
変更すべき「知識」が一か所にまとまり、考慮すべき影響範囲が小さくなるので変更容易性が上がる。
理解容易性:
「知識」の重複がなくなれば、いろいろな場所を見に行く必要がなくなる。
参考:
単一責任の原則(Single Responsibility Principle / SRP原則)
SOLID原則のS。変更の理由は一つ以上あってはいけないということ。
「1つのクラス・メソッドには1つの責任!」簡単に見えるけどちゃんと考えたらなかなか難しい原則。「あるクラス(メソッド)が1つのアクター(呼び出す側の総称) “ のみ “ に使われる状態」がベストな状態だよね、という話です。そのアクターの要求に対して変更するだけでよく、影響範囲を考えずにすむため変更コスト低くなるよねーて。
上記のDRY原則とも関連が深く、「知識」ごとにクラスやメソッドを分割できていれば自然とDRYなコードになっていく。
変更容易性:
各クラスやモジュールは単一の責任を持つようになり、一部の変更が他の部分に影響を与えることが少なくなる。
理解容易性:
クラスが単一の責任を持つ場合、そのクラス・メソッドの役割や目的が明確になり、コードの理解がしやすくなる。
参考:
オープン・クローズドの原則(Open/closed principle / 開放閉鎖の原則)
コードは「拡張に対して開いている」「修正に対して閉じている」という、2つの属性を同時に満たすように設計します。
(引用元:プリンシプル オブ プログラミング)
- 使う側(呼び出すクラス)
- 使われる側(呼び出されるクラス)
- 組み合わせる人(インターフェース)
上の3つの登場人物とその関係性がめっちゃ大切。
「拡張に対して開いていて、修正に対して閉じている」というのは、例えば使われる側(呼び出されるクラス)が増えたとしても使う側(呼び出すクラス)に変更を加えなくてもいい設計にしよう、てこと。
デザインパターンはOCP原則の具体化だったりするみたい。
※ Strategy / Observer / Template Method / Bridge / Decoratror / Adapterパターンなど
変更容易性:
既存のコードを変更せずに機能を追加できるため、拡張や変更が容易になる。
理解容易性:
既存のコードの振る舞いや仕様を変更するリスクを最小限に抑え、振る舞いを予測しやすくなる。
参考:
リスコフの置換原則(Liskov substitution principle)
派生クラスが基底クラスと置換可能であるべきであり、以下の条件を満たす。
- 派生クラスでオーバーライドされたメソッドは基底クラスのメソッドと同じ数・型の引数をとらなければならない
- 派生クラスでオーバーライドされたメソッドの返り値の型は基底クラスのメソッドの返り値の型と同じでなければならない
- 派生クラスでオーバーライドされたメソッドの例外は基底クラスのメソッドの例外と同じ型でなければならない
子クラスが親クラスと同じ動作を実行できない場合、バグる可能性がある。また、リスコフの置換原則を守らないと、オープン・クローズドの原則で実現したい「拡張には開いていて変更には閉じている」が実現できなくなってしまう。なぜなら、派生型が基本型の代替として機能しなくなり、既存のコードに修正が必要になる可能性があるから。
変更容易性:
基底クラスの振る舞いや仕様を変更することなく、派生クラスを追加・修正できるため、ソフトウェアの拡張や変更が容易になる。
理解容易性:
基底クラスと派生クラスが置換可能であり、互換性があるため、コードの理解と予測が容易になる。また、新たな派生クラスを追加しても既存のコードには影響を与えず、機能や振る舞いの理解が容易になる。
参考:
インターフェース分離の原則(Interface segregation principle)
インターフェース分離の原則は、インターフェースの実装クラスが必要なメソッドのみを使用し、使わないメソッドの依存を避けるために特化したインターフェースを作りましょうという設計原則。
結論、インターフェースに焦点を当てたSRP、みたいな理解でよくね?と思った。
変更容易性:
各クライアントが必要なメソッドのみに依存するため、インターフェースの変更が発生した場合でも、影響範囲を最小限に抑えることができる。よって新しい要求や変更への対応が容易になる。
理解容易性:
インターフェースが特化されているため、クライアントは必要とする機能に特化したメソッドを利用できる。これによりコードの意図や役割が明確になり、クライアントコードの理解が容易になる。また、インターフェースの変更が頻繁に行われず、インターフェースの責任と関連するメソッドの集約が行われるため、コーディングの一貫性が向上する。
参考:
依存性逆転の原則(Dependency inversion principle)
上位のモジュールは下位のモジュールに直接依存せず、どちらのモジュールも抽象に依存するべきであるという設計原則。
簡単に言ってしまえば、依存先の矢印を全部インターフェースなどの「抽象」に向けようという話。
いままで依存されていたクラスを依存する側にする(これで依存性が逆転する)と疎結合化、というより結合がなくなるのでいい設計になる。
変更容易性:
上位のモジュールは下位の具体的な実装に依存せず、抽象に依存するため、下位の実装の変更や交換が容易になる。
理解容易性:
上位と下位のモジュールが抽象に依存するため、実装の詳細には意識を向けず、抽象化されたインターフェースや抽象クラスを通じてコミュニケーションが行われる。これにより、コードを理解する際に不必要な実装の詳細に深入りする必要がなくなり、モジュール間の関係が明確になる。
参考:
- 「依存関係逆転の原則(DIP)」を学んだ
- 依存関係逆転の原則の重要性について(←図がめっちゃわかりやすい)
デメテルの法則
オブジェクト間の結合度を低く保つために、利用する側のオブジェクトが直接操作することができるのは自身の直接の友達だけにしなさい!!!!の原則。
オブジェクト間の結合度を低く保つために、オブジェクトは自身の直接関係するオブジェクトに対してのみメッセージを送るべきであり、それ以外のオブジェクトに直接アクセスしてはいけない。メソッドチェーンが見えたら黄色信号。
変更容易性:
オブジェクトの疎結合化 → 依存関係の減少 → 変更が局所化 → 影響範囲が制限されるので変更によるリスクが低くなる。
理解容易性:
他のオブジェクトの内部構造や処理の詳細を意識せずに、個々のオブジェクトを独立して理解できるようになる。また、疎結合化でテストがしやすくなる。
参考:
尋ねるな、命じよ。の原則(Tell, Don't Ask.)
オブジェクト間のコミュニケーションにおいて、直接問い合わせるのではなく必要な情報や操作を " 伝える " ことを推奨する原則。
インスタンスを使った必要な処理は、インスタンスを持っているオブジェクト(クラス内)で処理させましょう。
変更容易性:
カプセル化・モジュールの疎結合化が促進される。そのため、一方のオブジェクトが変更される場合でも、他のオブジェクトの変更を最小限に抑えることができる。
理解容易性:
クラスが自身のインスタンスに対する処理を集めることで、高凝集化する。別クラスに重複コードが生まれなくなるし、見なきゃいけない箇所がぐっと減る。
参考:
- ポリモーフィズムを活用するとなぜ if や switch が消えるのか? > ダックタイピングによって条件分岐を消したコード
- 結局のところgetter/setterは要るのか?要らないのか? > getter/setterメソッドを置き換える
KISS原則(Keep It Simple, Stupid / Keep It Short and Simple)
シンプルなコーディングできるやつが一番すごいの原則。
書いた本人も1週間経ったら何やってるか分からなくなることさえある。怖い。
NG例:
・賢さアピールしたくて歯茎むき出しでコーディングしたんかなーみたいなコード
・不要な条件分岐や重複したコードを含む、長くて読みにくいコード
・単純なデータ処理に対して複雑なアルゴリズムの実装
変更容易性:
シンプルな設計は、余分な複雑さや不要な機能を排除するため、バグを埋め込みにくい。
理解容易性:
シンプルに可読性が高い。
参考:
YAGNI原則(You Are’nt Going to Need It)
必要最低限でいい。つまり、汎用性のもたらす再利用性や拡張性よりも、まず「使える」ことに価値を置くような単純性を考える。「これあった方がいいかな......」はだいたい使われない。悲しいことに。
オープン・クローズドの原則のコンフリクトしている気がする。
変更容易性:
不要な機能が存在すると、変更や修正が必要な箇所が増え、保守や拡張がつらくなる。
理解容易性:
不要な機能が存在すると、見なきゃいけないコードは増えるし「この処理なに???」てなる。
参考
コマンド・クエリ分離の原則
主作用と副作用をちゃんと分ける。
基本的な考えは、オブジェクトのメソッドを明確に2つのカテゴリに分類するというものである。
・問い合わせ:結果を返し、システムの状態を変更しない(副作用がない)
・コマンド:システムの状態を変更し、値を返さない
(引用元:コマンド・問い合わせの分離)
変更容易性:
オブジェクトの状態の変更と情報の取得に関わるロジックが明確に分離され、責務が明確になる。変更に対するリスクが低くなり、保守や拡張が容易になる。
理解容易性:
メソッドの役割や目的が明確になると、目的や動作が名前から推測しやすくなり、ソースコードを読む他の開発者が処理の意図をより理解しやすくなる。
参考:
驚き最小の原則
コードやAPIの振る舞いを予測可能で意図通りのものにすることを目指す原則。
「え、この命名のくせになんでそんなことしてんの?」みたいなことをなくしましょう原則。
変更容易性:
変更に伴う予期せぬ副作用やバグの発生リスクを低減できる
理解容易性:
逆に、この原則が満たされていないと予測不可能な振る舞いによってバグを埋め込むリスクが高まる
参考:
PIE原則(Program Intently and Expressively)
「コードの意図を表現してプログラミングせよ」
保守するにおいて、コードは「書きやすさ」よりも「読みやすさ」を優先すべき。どう考えても読んでいる時間のほうが長いから。つまり理解容易性を常に意識してコーディングすることは、ソフトウェアが長生きすればするほど、自分にもチームにも大きな価値をもたらすよということ。
ソフトウェアの動作を把握するには、コードを読むしかありません。よって、わかりやすいコードを書いて、コードで意図を伝えるしかないのです。
(引用元:プリンシプル オブ プログラミング)
コードでは「What」「How」までしか表現不可能なので、コメントなどを利用して「Why」を埋め込むと効果的な場合がある。歴史のあるソフトウェアだと「このコード何で存在してるの?」みたいなコードが山のようにある。。。
変更容易性:
実装当時の設計思想が分かれば、コードの目的や振る舞いが明確になる。つまり、変更の判断がしやすくなる。
理解容易性:
社内ドキュメントなどは陳腐化していく、つまり現在のコードこそがドキュメント。第三者が仕様を把握しやすいような、理解容易性が高まるようなコーディングをしようねというコーディング哲学?
参考:
SLAP原則(Single Level of Abstraction Principle)
抽象化レベルの統一。本の見出しや章立てみたいなイメージ。
マークダウンで言えば、
# 抽象
## まんなか
### 具体
みたいな感じ。
メソッドや関数が同じレベルの抽象度を持つようにすることで、処理の流れを理解しやすくし、コードの理解や変更が容易になる。高い抽象度と低い抽象度のコードが混在してしまうと、コードの意図が明確でなくなり、処理の追加や変更が難しくなることがある。
抽象度がそろっていると、こんなことができる
- Aさん:なんとなく処理の流れが見たいだけだから抽象度高い部分まででOK
- Bさん:不具合原因特定したいからもうちょい具体的な処理まで読んでみる
可読性というか、目的の処理を把握するまでの効率がよくなる。
変更容易性:
メソッドや関数が単一の抽象化レベルで構成されるため、特定の機能や処理の変更が行いやすくなる。
理解容易性:
抽象度の同じコードが概念的に連続するため、コードを理解しやすくなる。また、抽象度が分離していれば、必要な処理だけ見ればよくなる。
参考:
- 汝、SLAPを愛せよ。
- コーディング原則の一つSLAP
- SLAPを覚えてリファクタリングをしよう
- コードレビューでprivate methodを使い倒しつつSingle Level of Abstractionを意識してみる
デザインパターン
デザインパターンと言えばGoFの23種のデザインパターンがあまりにも有名ですが、他にもいろいろと有用なパターンは存在している。デザインパターンは、再利用可能なソフトウェアコンポーネントの作成や、ソフトウェアの保守性や拡張性の向上などに役立つ手法。GoFの23種のデザインパターン以外にもさまざまな問題に対応するためのパターンが存在するので、目的に応じて使っていきたい。
GoFのデザインパターン
23種類もあるのであとで勉強したら載せる。
参考:
完全コンストラクタ
コンストラクタでインスタンス化するときに、インスタンスの不正な状態をはじく。正常なオブジェクトしか生成されないので、不正な値を気にしなくてよくなるし、いたるところでバリデーションロジックが追加されることを防ぐことができる。デメリットは値の変更が必要な時に毎回初期化が必要でメモリを多少圧迫することくらいでしょうか。
変更容易性:
新しい初期化パラメータが追加された場合はコンストラクタで対応可能。初期化処理で変更が必要なのはコンストラクタのみに制限されるので、他のコードやメソッドへの影響は最小限に抑えられる。
理解容易性:
コンストラクタを参照することでオブジェクトの初期化フローを把握しやすい。また、オブジェクトがどのような状態を持ち、どのような操作が許容されるかを理解しやすくなる。
参考:
値オブジェクト(Value Object)
システムを機能させるうえで必要な関連データをクラスとして扱って、オブジェクトとして表現したもの。値オブジェクトでは、それぞれの関連データ(業務に必要な概念など)をインスタンス変数として持っている。
- 不変性(完全コンストラクタの利用)
- 交換可能(setterはつくらずインスタンス生成をコンストラクタだけに制限)
- 等価性(比較メソッドの実装など)
を満たすように設計すると高凝集なコードの実現に近づく。
変更容易性:
値オブジェクトとして扱うことで、異なる型の代入を防ぐことができるためバグを埋め込みにくくなる。また、不変性という特徴により、変更が他のコードに与える影響を最小限に抑えることができる。
理解容易性:
ドメインに必要な情報が可視化され、またクラスやメソッドがそれらを説明することになるため、オブジェクトの性質や振る舞いを理解しやすくなる。
参考:
- 設計要件をギッチギチに詰めたValueObjectで低凝集クラスを爆殺する >ValieObject
- ドメイン駆動設計入門 Chapter 2 システム固有の値を表現する「値オブジェクト」のまとめと感想
- 3分でわかる値オブジェクト
- 【ドメイン駆動設計】なぜ値オブジェクトそのものを比較できるようにしなければならないのか?
DTO(Data Transfer Object)
DTOは、データをビジネスロジックから切り離し、異なる層やモジュール間でデータを効率的に転送するために使用される。DTOの目的は、ビジネスロジックとデータの構造・転送を切り離して、それぞれを独立に管理することで、ビジネスロジックの変更や拡張に影響せずにデータの構造や転送方法を変更できるようにすること。
理解容易性:
バックエンドのデータ構造変更によるフロントエンドや他のシステムへの影響を最小限に抑えられる。データの転送と交換を担当するDTOがカプセル化されることで、バックエンドの変更が他の部分に与える影響を防ぐ。
理解容易性:
DTOはシンプルなデータ保持クラスなので役割が明確であり、ビジネスロジックを持たないため、意図が明確になる。データ構造が明確に定義されているため、開発者はDTOを参照するだけでデータの内容やフィールドを把握することができる。
参考:
ファーストクラスコレクション
値オブジェクトの概念を用いて、ドメインで使われる配列やリストなどのコレクションを取り扱うための専用のクラスを作成すること。
メリットは多いが、大量のデータを扱う場合や、繰り返し操作が頻繁に行われる場合はパフォーマンスの劣化に注意が必要。専用のクラスを介することでオーバーヘッドが発生することがある。
変更容易性:
内部状態の変更を防ぐことにより、他の部分でコレクションを直接変更することがなくなり、バグを埋め込みにくい作りになる。ロジックがまとまるので影響範囲を制限できる。
理解容易性:
業務ルールの散在を防ぐことができるので、コレクションを扱うメソッドや操作が一箇所にまとまり、コードの理解と把握が簡単になる。
参考:
依存性注入(Dependency InjectionI)
クラス間の依存関係を柔軟にする手法で、コンポーネント(ソフトウェア内の部品)同士の疎結合化を実現する手法。
クラスが必要とする依存オブジェクトを外部から注入することで、依存関係を解決する。(コンポーネント間の依存関係が疎結合になる)
変更容易性:
依存性注入により、コンポーネント間の依存関係が疎結合になると、特定のコンポーネントの変更が他のコンポーネントに与える影響が最小限に抑えられ、変更の影響範囲が局所化される
理解容易性:
各コンポーネントが独立して動作できるため、コードの可読性が向上する。各コンポーネントの役割や責任が明確になり、全体の構造やロジックを理解しやすくなる
参考:
- 猿でも分かる! Dependency Injection: 依存性の注入
- DI (依存性注入) って何のためにするのかわからない人向けに頑張って説明してみる
- Java: 単体テストを書くためにstaticメソッドから脱却しよう #2 DI(Dependency Injection)
- デザインパターンとDI