はじめに
本記事は ソフトウェアテスト徹底指南書 〜開発の高品質と高スピードを両立させる実践アプローチ(以下、ソフトウェアテスト徹底指南書)の読書感想文です。
生成AIやCoding Agentの台頭により、爆速&爆量のコードが生成されている一方で、それらを活かしたうえでどう品質を担保していくかは大きなテーマになっているかと思います。大量のアウトプットに向き合いながらアジリティを高く保ち続けるための確かなテスト基盤が必要不可欠な一方で、質の高いテストには高度な知識と経験が必要なのもまた事実です。
しかしすべてのチームにテスト専門家がいるわけではなく(弊社もいません)、多くの場合「開発者がテストも担う」のが現実的な判断かと思います。つまり我々、開発者自身が視座を高め、テストに関する知識を身につけ、戦略的に品質を作り込んでいくアプローチが不可欠です。
本記事では、開発者自身が主体となって自信の持てるテスト戦略を設計し、計画に落とし込むための体系的な知識をおすそ分けできたらな~と思っています。
体系的に説明することに主眼を置いているので、全体的にやや抽象的な内容になっています
テスト戦略はなぜ必要か
テストの目的
JSTQBテスト技術者資格制度のシラバス(Version 2023V4.0.J02)には、テストに関して以下のように説明されています。
典型的なテスト目的は以下の通り。
- 要件、ユーザーストーリー、設計、およびコードなどの作業成果物を評価する。
- 故障を引き起こし、欠陥を発見する。
- 求められるテスト対象のカバレッジを確保する。
- ソフトウェア品質が不十分な場合のリスクレベルを下げる。
- 仕様化した要件が満たされているかどうかを検証する。
- テスト対象が契約、法律、規制の要件に適合していることを検証する。
- ステークホルダーに根拠ある判断をしてもらうための情報を提供する。
- テスト対象の品質に対する信頼を積み上げる。
- テスト対象が完成し、ステークホルダーの期待通りに動作するかどうかの妥当性確認をする。
ここから、テストの目的はざっくり、ソフトウェアの品質を検証・確証し、リスクを許容可能なレベルまで下げること と言えそうです。
テストが抱える限界
テストは品質を支える重要な手段とは言っても万能ではなく、ソフトウェアテストの7原則1 にあるように以下のような構造的な制約を抱えています。
- テストは欠陥があることは示せるが、欠陥がないことは示せない
- 全数テストは不可能(すべてをテストすることは非現実的)
- 早期テストで時間とコストを節約(欠陥の早期発見でコスト安)
- 欠陥の偏在(問題の多くは特定のモジュールに集中する)
- テストの弱化(同じテストの繰り返しで新たな欠陥の検出に対する効果は薄れる)
- テストはコンテキスト次第(唯一普遍的なテスト手法は存在しない)
- 「欠陥ゼロ」の落とし穴(バグゼロでもユーザーニーズを満たすとは限らない)
だから「戦略」が必要
テストだけに頼らず、設計レビューやペアプログラミング、静的解析、自動テストといった多層的なアプローチを組み合わせ、効率的に品質を作り込むこと。そして、「どこに・どれだけ・どんなリソースを投じるか」を意図を持って設計すること。それが テスト戦略 です。
専任QAの存在に関わらず、開発者全員が視座を上げてテスト戦略を意識し、実効性のある品質確保をしたいよね、というのがテスト戦略を設計・運用するモチベーションでございます。
よくあるテスト戦略
テスト戦略の考え方は非常にシンプルで、ISTQB Glossary(用語集)2 ではテスト戦略について以下のように定義されています。
test strategy
A description of how to perform testing to reach test objectives under given circumstances.(所与の条件下でテスト目標を達成するためのテスト実施方法の説明)
『ソフトウェアテスト徹底指南書』の中には、テスト戦略の構築について以下の記載があります。
テスト戦略の主なインプットはプロジェクトリスクです。(中略)テスト戦略は、これらインプットの発生や更新をトリガに、立案・変更します。そして戦略に対応する各種活動を駆動していきます。
なお、プロジェクトリスクが主なインプットのため、これからテスト戦略の策定を行おうという場合は、プロジェクトリスクを分析するのが一般的です。プロジェクトリスクのうち、リスクレベルが高く、かつテスト活動によるコントロールが必要なものへの対策を、テスト戦略として識別します。
要するに「何をどうテストするか(戦略)」は、「何が起きると困るか(プロジェクト/プロダクトリスク)」を考えて決めるということです。なぜなら、リスクが変われば必要なテストも変わるからです。
例えば「防ぎたいリスク」には典型的なケースとして以下のようなものが挙げられるかと思います。
- 「修正したら別の場所が壊れた」「前回動いていた機能が今回動かない」
- 「テスト段階で大きな設計ミスが発覚」「後半になって要件の認識ズレが判明」
- 「テストケースを作り始めたら、仕様が曖昧だと気づいた」「開発とテストの認識がズレていた」
- 「デプロイしたらパフォーマンスが劣化した」「本番環境の設定ミスってた」
これらのリスクに対して、すべて同じテスト方法で立ち向かうのは非効率です。以下では『ソフトウェアテスト徹底指南書』で「定番のテスト戦略」として取り上げられていた4つの戦略について簡単に触れます。
シフトレフトテストの戦略
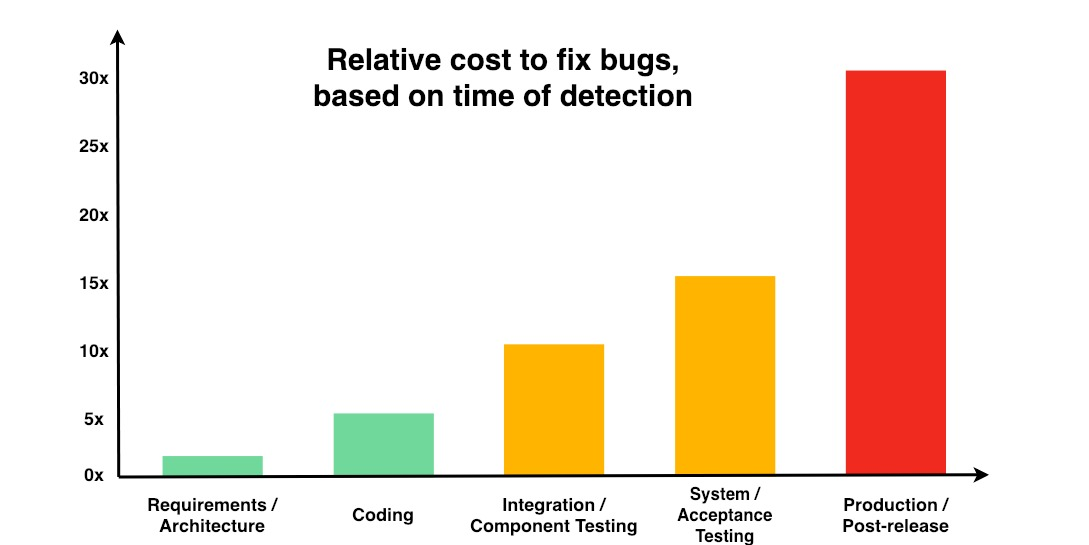
シフトレフトテストは、テスト活動を開発ライフサイクルの 早期段階に前倒しして実施する手法です。コーディング前の要件定義や設計段階から、レビューや静的テスト、テスト設計を開始し、開発とテストを並行・反復的に進めることで、テストが後ろ倒しにされることで起きうる各種リスクに対応できます。
開発プロセス後半に進むにつれて欠陥の検出と修正にかかる労力が爆増する話はもはや常識となっています(以下グラフは NIST 提供)
リグレッションテストの戦略
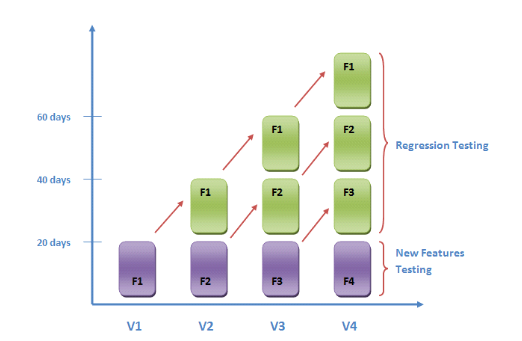
リグレッションテストは、ソフトウェアの変更によって 既存機能が意図せず壊れていないか を確認する手法になります。コードの修正や機能追加のたびに影響範囲を分析し、計画的に既存機能の再テストを実施することで、リリース後のデグレードを未然に防ぎます。
開発スピードが上がれば上がるほど、予期せぬデグレードのリスクは高まります。これに対抗するため、主要なユースケースを自動テスト化し、CIの中で毎回実行する仕組みを作るのが一般的かなと思います。
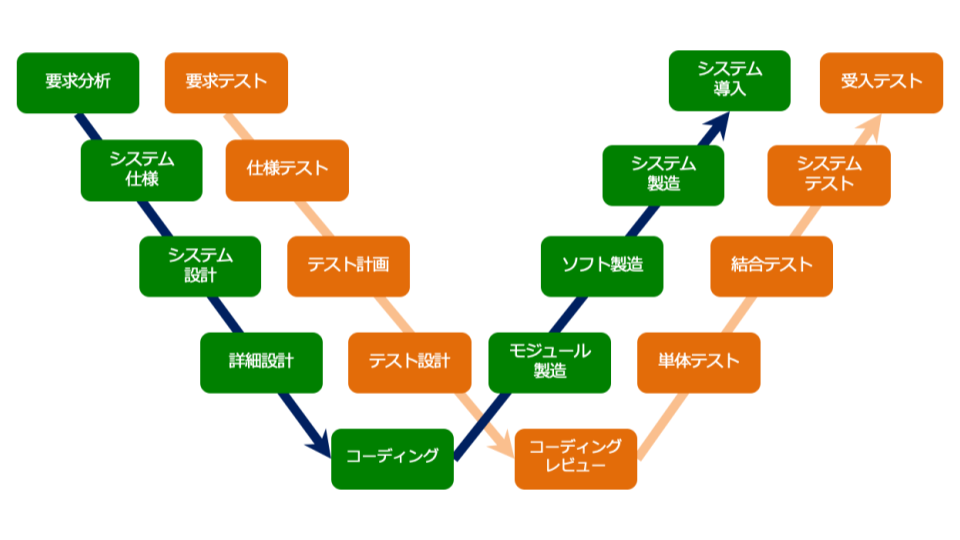
Wモデルの戦略
Wモデルは、開発工程(設計・実装)と並走して、対応するテスト工程(テスト設計・準備)を進めるモデルです。
元々はVモデルの進化版として提唱されたものですが、アジャイルや開発者主導の文脈においては、「実装する人が、実装前にテストコードや受入条件を考える」という動きに直結します。
例えば、コードを書く前に「この機能の正解は何か(テスト条件)」を考えることで、仕様の曖昧さを排除し、実装とテストの認識ズレを防ぐことができます。TDD(テスト駆動開発)やBDD(振る舞い駆動開発)も、この戦略の一種と捉えることができます。
出典: W字モデルとは?
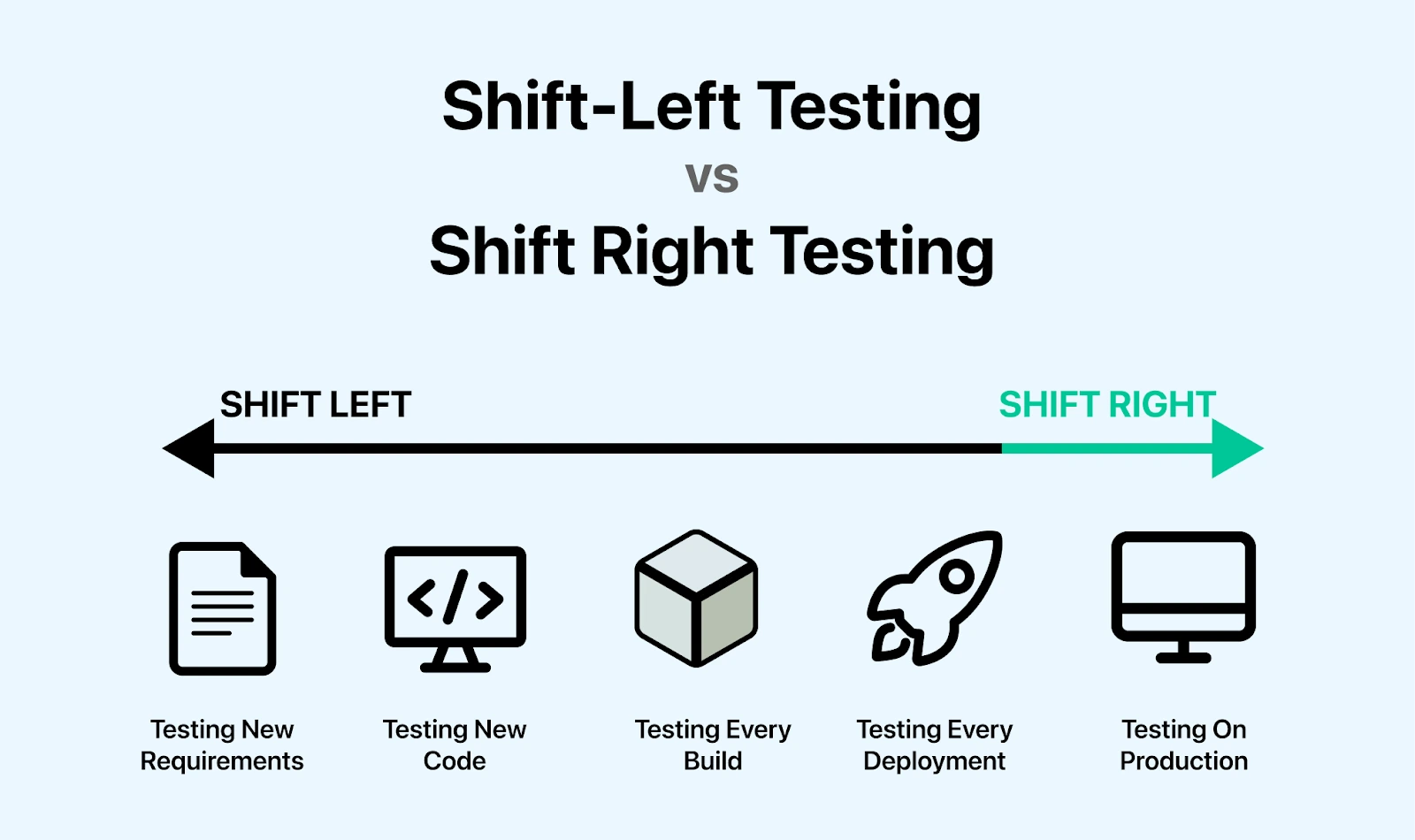
シフトライトテストの戦略
シフトライトテストとは、ソフトウェアを 本番環境にリリースした後に実施するテスト手法で、本番環境でしか確認できない条件や、実際のユーザー行動に基づくリスクを検証するのに適しています。
Netflixのカオスエンジニアリング なんかは有名なのではないでしょうか。
この戦略の目的は「システムがユーザーにとって信頼できる状態で稼働し続けているか?」を継続的に観測し、改善のフィードバックループを回すことです。その実践内容はSRE(Site Reliability Engineering)の活動領域と重なる部分が多く、専任のQAやSREが不在の組織においては、開発者が意識すべき重要な責務となります。
出典: Shift Right Testing: Know its Benefits, Types, and Tools
テスト戦略は「選ぶ」ではなく「組み合わせる」
代表的な4つのテスト戦略を取り上げましたが、それぞれの戦略が対象とするリスクは異なります。どのテスト戦略も得意領域が異なる、つまり守りたいものに重きを置きつつ、各種リスクやプロダクトのライフサイクルに応じて適切に組み合わせを考えることが効果的なテスト戦略の構築につながるわけです。
この「組み合わせ」の考え方を整理するのに役立つのが、アジャイルテストの4象限 です。
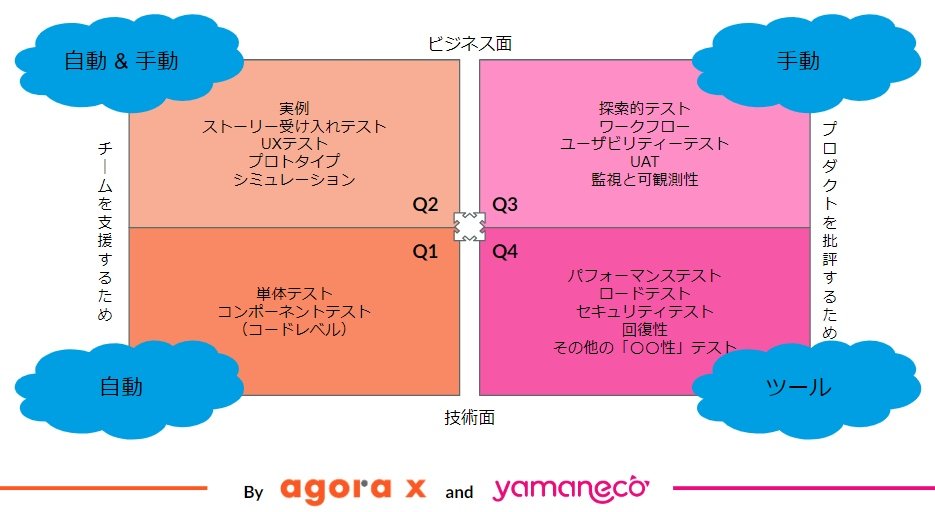
効果的なテスト戦略とは、この4つの象限すべてをバランスよくカバーする活動を計画することに他なりません。例えば、Q1のユニットテスト(シフトレフト)だけを徹底しても、ユーザーにとって使いにくいプロダクト(Q3の観点)ができてしまうかもしれません。また、リリース前のテスト(Q1, Q2, Q3)を完璧に行ったつもりでも、本番環境特有のパフォーマンス問題(Q4)が発生する可能性は残ります。
このように、まずプロジェクトのリスクを洗い出し、そのリスクに対応するために各種テスト戦略を適切に組み合わせ、具体的なテスト活動を計画する必要があります。
さて、我々が対応すべき「プロジェクト/プロダクトリスク」はどのようにして考え、特定したらよいでしょうか?
リスクと品質
どのテスト戦略を選定し、何を守っていくかを考えるためには、以下の2つの問いに答える必要があります。
- テスト戦略を通して守りたい品質特性は何か?
- 守りたい品質特性を脅かすリスクは何か?
品質をどう捉えるか
ソフトウェアテストは、欠陥を発見し、ソフトウェアアーティファクトの品質を評価するための一連の活動である。
JSTQBではソフトウェアテストについて上記のように説明されていますが、ここで言う「品質」をどう捉えたらよいでしょう。ソフトウェア品質についての定義や思想には以下のように様々あります。
システムの品質は,システムが様々な利害関係者の明示的ニーズ及び暗黙のニーズを満足している度合いであり,それによって価値を提供する。3
品質は誰かにとっての価値である4
品質とは要求への適合である5
いろいろある中で私が最もピンときた表現は、『品質とは、ある大切な人にとってある時点での価値のことである。』です。これは Web APIテスト技法 の著者Mark WinteringhamさんがGerald M. Weinbergさんの「品質は誰かにとっての価値である」から着想を得て定義した(っぽい)ものです。
テスト戦略を策定するうえではこの言葉に込められた「品質は個々人の主観的 / 流動的な概念である」という思想がとても大切だと思っており、なぜならユーザーにとっての価値(品質)を具体的に理解することがそのまま、テストで何を守るべきかの判断材料として活かせるからです。
品質目標の設定
とはいえ「価値」というだけでは抽象度が高く、また品質特性として挙げられるものは無数(例えば Test Eye Software Quality Characteristics)にあります。すべてをテストでカバーすることは現実的ではないため、うまく分類、優先順位付けをすることが重要です。
狩野モデルによる品質の分類
狩野モデルを用いることでユーザーの満足度の観点から品質の優先度を整理できます。
- 当たり前品質:あって当たり前だが、ないと不満(守るべき最低ライン)
- 一元的品質:あればあるほど満足度が高まる(改善の主戦場)
- 魅力的品質:あれば満足度が高まるがなくても仕方ないと受け入れられる(差別化要因)
- 無関心品質:あってもなくても満足度に影響を与えない
- 逆品質:あると逆に満足度が下がり、ないほうが嬉しい
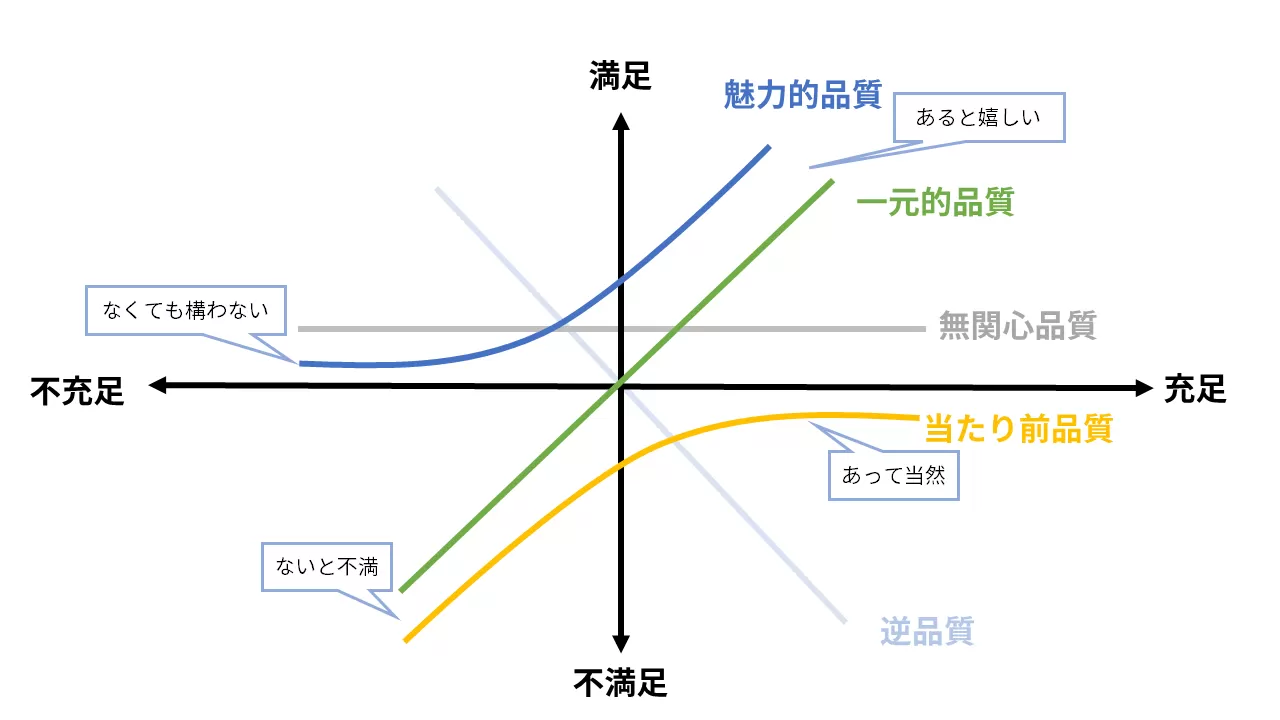
この分類により、「何を守るべきか(当たり前品質)」「何を改善すべきか(一元的品質)」「何で差別化するか(魅力的品質)」など、戦略の指針が立ちます。
SQuaREの品質モデル
ISO/IEC 25010(SQuaRE)では、より網羅的・体系的にソフトウェアの品質を分類しています。(誰にとって、いつ(どの局面で)、何の品質を、の3点を明確にすると分かりやすい)
-
利用時の品質モデル
- 誰が:エンドユーザーが
- いつ:実際の業務や生活でシステムを利用する際に
- 何を:目的達成の有効性や満足度として実感する「成果」の品質
-
製品品質モデル(外部品質)
- 誰が:ユーザーやテスト担当者が
- いつ:稼働中のシステムを実行・操作する際に
- 何を:機能の正しさや応答速度として観測できる「振る舞い」の品質
-
製品品質モデル(内部品質)
- 誰が:開発者や保守担当者が
- いつ:開発・保守の工程でソースコードや設計書を評価する際に
- 何を:保守性や移植性として判断する「作り込み」の品質
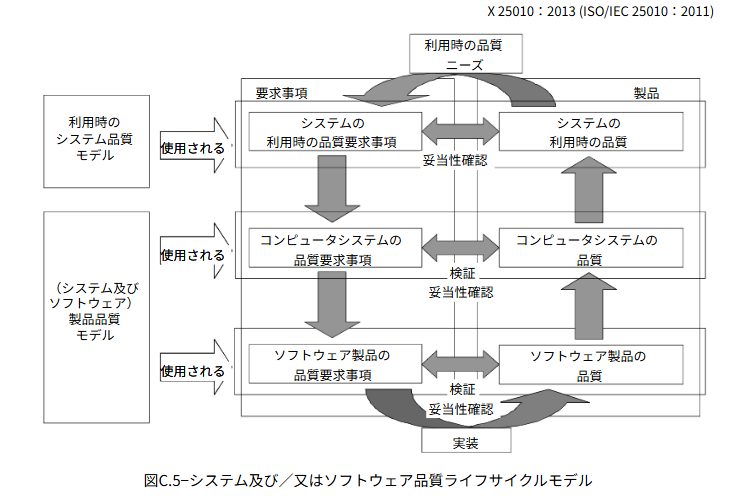
このように、狩野モデルで品質の優先度を定め、SQuaREの品質モデルで評価すべき具体的な品質特性を特定するというアプローチを取ることで、「ある大切な人にとってある時点での価値」という抽象的な品質を、計測可能で具体的なテスト目標へと落とし込むことができるようになりそうです。
品質に影響をおよぼすリスクの特定
上記モデルなどを活用してテスト戦略で守りたい品質特性を特定した後は、それらを脅かすリスクを考えます。つまり、守りたい品質特性にマイナスの影響を与える可能性が何かを特定します。
※ なお、ここでの議論はプロダクトの品質に関わるリスクに焦点を当てていますが、プロジェクト進行上の「プロジェクトリスク」も別途管理が必要です
JSTQBのシラバスでは、リスク識別の手法としてブレーンストーミングやインタビューなどが挙げられていますが、より体系的かつ網羅的にリスクを洗い出すための具体的な手法(先人の知恵BIG LOVE)と言えば例えば以下のようなものがあるかと思います。
- 発散型(自由な発想でリスクを洗い出す)
- トップダウン分析型(望ましくない事象から原因を掘り下げる)
-
ボトムアップ分析型(コンポーネントの故障から影響を分析)
- FMEA(障害モード影響解析)10
- 脅威モデリング型(特定の観点で体系的に分析)
これらもまた使い分けが大切であり、例えば、開発者の運用としては以下のような組み合わせが考えられます。
- 新機能開発時に「リスクストーミング」を実施して大まかなリスクを洗い出し、
- 特に信頼性が重要な決済機能については「FMEA」で詳細な分析を行い、
- セキュリティ専門家を交えて「アタックツリー」で脆弱性を潰していく
これらの手法を活用してリスクを具体的に特定することで、「どこに重点を置いてテストすべきか」という効果的なテスト戦略の構築に役立てることができます。
テスト戦略の最初のステップ
品質目標の設定とそれに関連するリスクの特定を終えたら、どのリスクを優先的にチェックしていくかの優先順位を決めることができます。この判断には、「品質特性そのもの」における「リスクの発生確率」「リスクの発生時の深刻度」を用いたリスクマップの作成が最も分かりやすそうです。
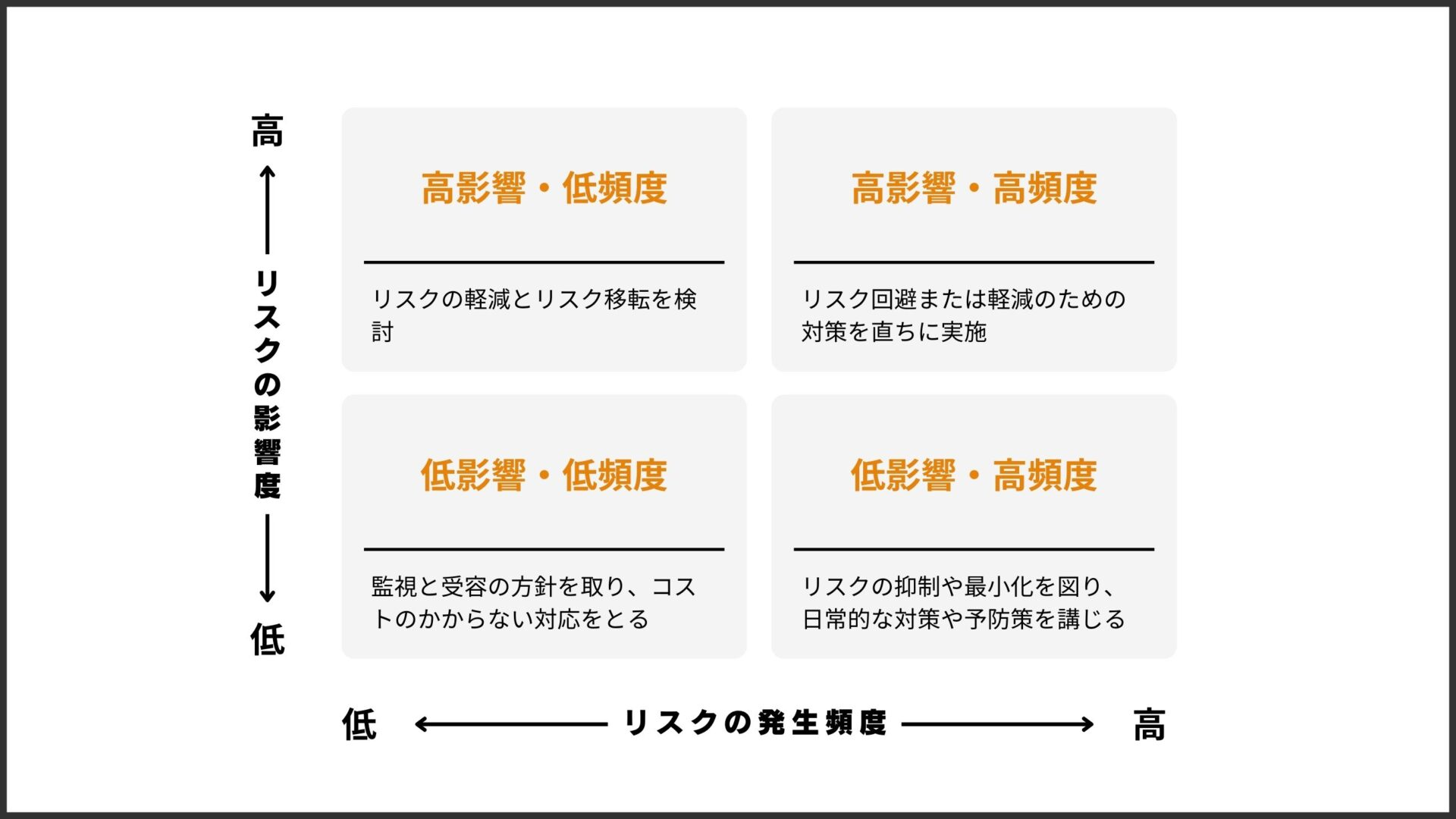
これでやっと「テスト戦略を通して守りたい品質特性」「守りたい品質特性を脅かすリスク」の2つが明らかになり、テスト戦略のためのインプット(具体的なリスク)が出揃ったはずです。これらが明確になって初めて、「どのようなテスト技法を使い、どのタイミングで、どれくらいの厚みでテストを行うか」という具体的な計画に落とし込むことができるようになります。
テストアーキテクチャの設計
ここまで「何をテストすべきか」について言及してきましたが、ここではそれらのリスクに効率的かつ効果的に対処するため、各種テスト活動を「どのように構造化し、組み合わせるか」、つまりテストアーキテクチャの設計について触れます。
例えば、決済処理のような高リスクかつビジネス上重要な領域には複数レベルでのテストを厚くする、UI変更の多い箇所はE2Eを最小限にして統合テストを充実させる、といった判断をアーキテクチャレベルで行います。
テスト活動の構造化(テストアーキテクチャ設計)により、以下の恩恵を受けることができるようになります。
- 各種テスト活動の全体像、それぞれの関係性や責務が体系的に理解できる
- 「どのテストを、どの粒度で、どれくらい書くべきか」という判断基準が明確になり、迷いなくテストの作成・実行に着手できる
- コストのかかるテスト(UIテストなど)と、高速に実行できるテスト(単体テストなど)のバランスを最適化し、フィードバックの速度を向上させる
この設計は、CI/CDパイプラインや開発プロセスそのものに組み込まれ、品質とアジリティを両立させた継続的な価値提供を支える基盤となります。
テストレベル
テストを階層化することで、テスト対象の範囲や粒度を定義することができます。また、各レベルの責任範囲が明確になるため、テストの重複による無駄や、境界部分の検証漏れを防ぐことができます。
代表的なモデルとしてテストピラミッド、テストトロフィーがありますが、プロダクトやチームの状況に合わせて、どのモデルをベースにするか、あるいは独自の階層をどう定義するかを決定するとよきかなと思います。
出典: What is the testing trophy and how does it help better test software?
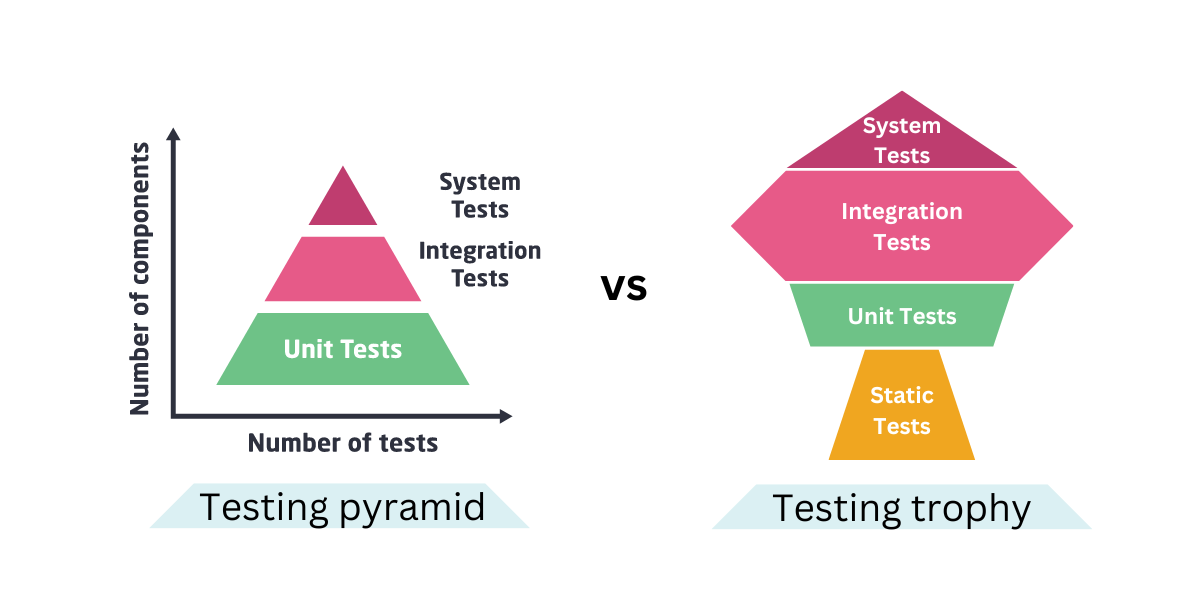
例えば、「ビジネスロジックの純粋関数が多い場合はユニットテストの価値が高い場合が多いのでテストピラミッドを選ぼう」、とか、「UIロジック+状態+副作用の組み合わせが多い場合は統合テストの価値が高いのでテストトロフィーに寄せよう」、などです。
ちなみにJSTQBのシラバス(Version 2023V4.0.J02)では、以下の5つのレベルで定義されています。これらをベースにしつつ、チームの実情に合わせて用語の認識をそろえてもよきかもしれません。
- コンポーネントテスト(ユニットテスト):コンポーネント単独
- コンポーネント統合テスト(ユニット統合テスト):コンポーネント間のインターフェ
ース、および相互処理 - システムテスト:システムやプロダクト全体の振る舞いや能力の全般
- システム統合テスト:テスト対象システムと他システム、外部サービスとのインターフェース
- 受け入れテスト:妥当性確認と、デプロイの準備ができていることの実証
テストタイプ
定義した各テストレベルで、どのような「観点(テストタイプ)」のテストを実施するかを割り当てていきます。これにより、「何を保証するためのテストか」が明確になります。
例えば以下のようにテストタイプを分類することができます。
- 機能テスト:仕様通り動くか
- リグレッションテスト:既存機能の保護
- 非機能テスト:
- パフォーマンス(レスポンスタイム検証や負荷テスト)
- セキュリティテスト(脆弱性スキャンやペネトレーションテスト)
- ユーザビリティ(ユーザビリティテスト、アクセシビリティテスト)
- 信頼性(カオスエンジニアリング)
このように「どのレベルで、どの観点のテストを、どの程度行うか」をマッピングすることで、「セキュリティテストは全レベルで行うが、静的解析はPRごと、ペネトレーションテストはリリース前に行う」といった具体的な運用設計が見えてきます。
テストスイート
テストレベルとテストタイプをマッピングしたら、それらをCI/CDパイプライン上で「いつ、どのように実行するか」という実行単位、すなわち「テストスイート」として設計します。
テストスイートは目的に応じてまとめられたテストケースの集合体です。開発者のフィードバックループを阻害しないよう、実行時間と重要度のバランスを見てグルーピングします。
- PR作成、コミット時に実行:
- 静的解析
- 全単体テスト
- 影響範囲の大きいコンポーネント結合テスト
- main/developブランチマージ時に実行:
- 全コンポーネント結合テスト
- 主要機能のAPIテスト
- 夜間バッチで日次実行:
- 全E2Eリグレッションテスト
- パフォーマンステスト
テストアーキテクチャ設計の文書化
設計したアーキテクチャやプロジェクト/プロダクト単位などで定義した内容は、例えば以下の情報とともにドキュメント化しておくとみんな幸せになれます。
- テスト戦略の概要: プロダクトの重要品質特性と、重点的にテストするリスク
- テストピラミッド/トロフィーの図解: チームが目指すテスト比率のイメージ
- テストレベルごとの責務と範囲: 「どこまでモックするか」などの指針
- 各テストスイートの目的・実行タイミング・合格基準
- 実行時間のSLO: 例「PRマージ前のテストは15分以内で完了すること」
- テスト失敗時ポリシー: Flakyテストへの対応方針など
最近だとAIコーディングアシスタントを活用するために、~/.claude/CLAUDE.mdや .github/instructions/**/*.instructions.md なんかにテストの方針や実装ルールを記述しておくのもよいかもですね。
テストの分析・設計・実行
さて、テストアーキテクチャに基づいて具体的なテストケースを作成していくのがこのステップになります。このプロセスはJSTQB/ISTQBでは「テスト分析」「テスト設計」「テスト実装」というステップに分けて定義されています(実際にはテスト計画やテスト完了など他のプロセスもありますが主要な3つに絞る)
- テスト分析:「何をテストするか」(What)を決める
- テスト設計:「どうやってテストするか」(How)を決める
- テスト実装:「実際に実行できる形」にする
テスト分析
テスト分析では、テストの元ネタであるテストベースを読み解き、テストすべき項目(テスト条件)を洗い出します。つまりテストインプットとなる所与のテストベースから、適切なテスト条件をアウトプットとして抽出する作業になります。
テストベースになるのは、例えば以下のようなドキュメントや情報です。
- ビジネス要件:ユーザーストーリー、ユースケース、受け入れ基準など、「この機能で何を実現したいのか」が書かれたもの
- 技術仕様:機能仕様書、アーキテクチャ設計書、API仕様書など、「システムがどう作られているか」が書かれたもの
- 品質要求:品質目標の設定で定義した品質特性、パフォーマンス要件、セキュリティ要件など、「どれくらい良いものであるべきか」を定義したもの
- その他:リスク分析の結果、過去の障害情報、法規制や業界標準など
これらの情報をヒントに、例えば以下のようなテストで確認すべき条件を網羅的にリストアップします。
- 例:「ユーザー登録機能」のテスト分析の場合
- 有効なメールアドレスとパスワードで登録できること(正常系)
- すでに登録済みのメールアドレスでは登録できないこと(異常系)
- パスワードが8文字未満の場合、エラーになること(境界値)
- パスワードが8文字丁度の場合、登録できること(境界値)
この段階では具体的な入力値までは決めず、「検証すべき観点」を網羅することに集中します。このアウトプットが、次の「テスト設計」のインプットとなります。
テスト設計
テスト分析で洗い出した「テストすべき項目(テスト条件)」を、今度は「どうやってテストするか」という具体的な手順に落とし込むのがテスト設計です。ここでは、抜け漏れなく効率的にテストを行うために、体系化された「テスト技法」を駆使します。(先人の知恵BIG LOVE)
-
ブラックボックステスト技法:
- システムの内部構造を知らなくても、入力と出力だけを見てテストする方法
- 同値分割/境界値分析
- ディシジョンテーブル
- 状態遷移
- システムの内部構造を知らなくても、入力と出力だけを見てテストする方法
-
ホワイトボックステスト技法:
- システムの内部構造(コード)を理解した上で、コードを網羅するようにテストする方法
- ステートメントカバレッジ(命令網羅)
- ブランチカバレッジ(分岐網羅)
- システムの内部構造(コード)を理解した上で、コードを網羅するようにテストする方法
-
経験ベースのテスト技法:
- テスターの経験や勘、過去の不具合事例を元に、欠陥がありそうな箇所を重点的にテストする方法
- エラー推測
- 探索的テスト
- テスターの経験や勘、過去の不具合事例を元に、欠陥がありそうな箇所を重点的にテストする方法
これらの技法を組み合わせることで「何を」「どういう値で」「どういう手順で操作し」「どうなればOKか(期待結果)」を明確にしたテストケースが作成できます。(また、テストに必要なデータ要件の定義やテスト環境設計、必要なツールなどもこの時点で定義します)
テスト実装
テスト実装は、設計したテストケースを実際に「実行可能な形」に整える作業を行います。具体的には、以下のような作業を行います。
- テスト手順書(テストプロシージャー)の作成:
- 誰が実行しても同じ結果になるよう、具体的な操作手順や確認事項をまとめる(手動テストの場合)
- 自動テストスクリプトの作成:
- 自動化する場合、テストケースをコードに落とし込み、テストスクリプトを作成する
- テストデータの準備:
- テストケースを実行するために必要な具体的なデータ(例:テスト用アカウント、CSVファイル、画像データなど)を用意、またはデータベースに投入する
- テスト環境の構築:
- テスト設計で定義された環境を構築する(基本的にはテスト環境のはず)
- 連携する外部システムがまだ完成していない場合にはその代役となるスタブやモックを用意することもある
- テストスイートの編成と実行計画:
- 作成したテストケース群を目的別にテストスイートとしてまとめる
- そしてテスト実行スケジュール(どのテストスイートをいつ、誰が実行するか)の計画も併せて行う
この「テスト分析 ⇒ テスト設計 ⇒ テスト実装」という一連のプロセスを経てようやくテスト実行のフェーズへ進めることができます。(開発者テストをしている人ならほとんどの場合やったことがあるかと思いますが...)
余談ですが、「テスト設計」の部分で私は前職の研修で ソフトウェアテスト技法練習帳 ~知識を経験に変える40問~ をやらせてもらったのですが、やっといてよかったなぁとしみじみ感じております。
自動テストの活用
なぜ自動テストしたいのか?
テスト戦略を考える上で、切っても切り離せないのが「自動テスト」です。手動テストオンリーはあまりに険しい道のりすぎる!
原則、ソフトウェアのリリースごとにすべてを手動テストする必要があるとしたら、
- リリースのたびに同じ確認を人間が繰り返す必要がある
- 疲労や集中力の低下に関わらずヒューマンエラーが発生するかも
- システム規模が大きくなればなるほど人力で全パターンを網羅するのは無理
- テスト工数が膨らみ、開発スピードや予算を圧迫し、詰む
最悪、必要なテストを通さずにリリースされてしまう(プロセス品質の欠如)、なんてことが起きてたら...とっても怖いですね。
自動テストの恩恵
そんなわけで自動テストよさそうって感じなのですが、自動テストは単に手動テストを機械に置き換えるだけではなく、ソフトウェア開発の品質、速度、そして文化そのものを向上させるための戦略的な投資たりえます。
自動テストの効果
『ソフトウェアテスト徹底指南書』では、多くの効果が語られていますが、開発者視点で特に重要なのは以下の2点に集約されると考えます。
-
品質と速度の両立(攻めのテスト)
- 長時間実行や複雑な条件網羅によるテスト有効性の拡大
- CIによる即時フィードバックと、それによる欠陥の早期発見
- リファクタリングの安全網としての機能
-
チーム文化とスキルの向上(守りのテスト)
- 「品質は全員で作り込む」という意識改革
- テスタビリティを意識することによる設計スキルの向上
- 単純作業からの解放による、より高度なテスト設計への注力
もちろん、「開発・テストスキルが必要」「学習・導入・保守コストがかかる」などの注意点もあるので、自動化のメリットを活かしつつ、欠点や注意点への対策も並行して行うことが必要です。
テストコードが開発者に与える4つの自信
テストを書いている人はみんな感じたことがあると思いますが、自動テストは、開発者に次の自信を与えてくれます。
-
コードが完成したという「自信」:
- 完成基準が明確になる
- 客観的な評価が可能になる
-
ほかのソフトウェア構成要素と統合して大丈夫という「自信」:
- 早すぎる統合は不幸を生む
- 各々の部品は、各テストレベルの品質基準をクリアしている
-
コードを変更しても壊れないという根拠のある「自信」:
- リファクタリングや機能追加時に既存機能の保護
- 予期しない副作用を即座に検知できる
-
コードの仕様・振る舞いが分かるという「自信」:
- 自然言語の曖昧さを排除し、期待される動作をコードで表現できる
- 迷った際に元の意図を確認できる
自動テストで確保すべき性質
自動テストで満たすべき性質として、しばしばFIRSTという原則が語られますが、これは以下の頭文字を取ったものです。
- Fast(高速に実行できる)
- Independent(他のテストから独立している)
- Repeatable(何度実行しても同じ結果になる)
- Self-validating(自己検証可能である)
- Timely(適時性がある)
これらはすべて重要ではあるものの、実際の開発現場においては「すべて同じ重要度」ではないかなと考えてます。経験則からこれらを整理すると、「テストとして成立するための最低条件(Must)」と「より良いテストにするための条件(Better)」の2つに分類できそうです。
テストとして成立するための最低条件(Must)
Self-validating(自己検証可能)とRepeatable(繰り返し実行可能)は テストとして機能するための最低条件 です。
- S: 結果を人間が目視確認するなら、それは自動テストではない
- R: 実行のたびに結果が変わるなら、何も保証できない
これらが欠けている場合、それは自動テストとして成立しません。
より良いテストにするための条件(Better)
一方で、Fast(高速)、Independent(独立)、Timely(適時)といった性質は、テストの本質的な成立条件ではなく、テストをより実用的かつ効果的なものにするための条件 です。
- F: テストが遅くても(極端な話「一晩かければ」通る場合でも)形式上はテストとして成立する
- I: きちんと順番を守って実行すれば一応は動作する
- T: 実装のずっと後に書かれたテストでも動作仕様を正しく検証できているならテストとして成立する
まずは「信頼できる」テストを
テストを書くにも技術がいりますが、最初から高速化やきれいな依存関係の整理にこだわりすぎて「テスト書くの ヤダァ」となってしまっては本末転倒です。まずは「自動で成功 or 失敗の判定ができ、いつでも同じ結果になる」状態を目指してテストを書くのがよいかなと思います。
テストレベルに応じた自動テストの構築
(テストアーキテクチャ > テストレベルの章でも触れましたが)自動テストを導入する際、すべてを同じ粒度で書こうとすると破綻するので、開発者が戦略的に使い分けるべき「自動テストにおける3つのレベル」について整理します。
ユニットテスト(単体テスト)
開発者が最も頻繁に触れるテストであり、品質の基盤となる層です。
主にビジネスロジック、ドメインロジック、アルゴリズムの確認を目的に、関数、クラス、モジュールなどの小さな単位でテストを行います。
- 「1単位の振る舞い」に集中する(DBやAPIなどの外部依存はモックやスタブに置き換え、ロジックそのものの正しさを検証する)
- 超高速: 数ミリ秒〜数秒で終わるため、コードを書くたびに実行可能(これが気持ちいい)
統合テスト(結合テスト)
単体テストだけでは見つけられない、「つなぎ目」の不具合を検出します。
「モジュール同士が想定通り連携できてるか?」の確認を目的に、コンポーネント間のインターフェース、DB・メッセージキュー・外部APIとの連携など、接点部分の相互処理などをテストします。
- 単体テストよりは遅いが、E2Eよりは速い
- テスト原則のRepeatable(繰り返し実行可能)を阻む不安定要因(ネットワーク、DB、外部システム)が混ざりやすい
- 特に「APIの入出力」や「主要なデータフロー」をこの層で自動化しておくと、改修時の安心感が段違い
E2Eテスト(システムテスト)
ユーザーの視点に最も近く、(UI -> バックエンド -> DB/外部連携までをまるっと含めた)実運用に近いテストです。
「システム全体として、ビジネス要件やユーザーシナリオを満たしているか?」の確認を目的に、主要なシナリオ(ブラウザや実機を通じた操作、あるいはシステム全体の入力から出力まで)をテストします。
- 壊れやすく、遅い(UIの変更でテストが落ちやすく、実行にも時間がかかる)
- ツールやプロダクトの種類に強く依存する
- 自動テスト基盤そのものの構築に時間がかかるため、専任メンバーや別チームで担当することも多いイメージ
ソフトウェアテストにおけるテストサイズ
『どこまでが単体テストでどこからが結合テストなんだっけ?』
テストピラミッドやテストトロフィーの話などに触れ、テストを書こうとするとそんなことを考えたりもしますが、「単体か結合か」というのは「テストレベル(何を対象に検証するか)」の話であり、もちろん設計意図としては大切な観点です。
しかし、私たち開発者が日々コードを書き、CIに組み込みつつ運用していくフェーズにおいては、より切実に効いてくる観点があります。それは「そのテストはどれくらい早く、どれくらい安定して回せるか」という物理的な制約の話、すなわち テストサイズ です。
テストサイズについてもいろいろな考え方がありますが、Google Testing Blog - Test Sizes の考え方が一般的(?)かなと思います。これは従来の「単体/結合/E2E」という人によって解釈が揺れがちで曖昧なラベリングではなく、システムリソースの消費量と依存範囲に着目して分類した考え方です。
-
Small:
- 単一のプロセス内で動作するテスト
- 外部リソース(ネットワークアクセス、ファイルシステム、データベースなど)の使用は禁止
- 実行時間は60秒まで
-
Medium:
- (Smallテストの制約を緩和し)単一のマシンに閉じた環境であれば外部リソースの利用を許容するテスト
- localhostの外へのアクセス(外部APIコールなど)は基本禁止
- 実行時間は300秒まで
-
Large:
- (Mediumテストの制約を緩和し)自動テストからリモートマシンへのネットワークアクセスなども許容するテスト
- 本番環境やそれと同等のインフラを利用したテストなどがこれに相当する
- 実行時間は900秒以上
(テスト戦略において)この「サイズ」の意識が重要なのは、CIパイプラインの最適化に直結するからです。
「単体テストだからコミット時に回す」「E2Eテストだから夜間に回す」という判断も間違ってないと思いますが、一方で、「Smallテストだからコミット時に全件回す」「Largeテストはマージ後のデプロイ前のみ」といったように、実行コスト(時間・リソース)ベースでデプロイメントパイプラインを設計するほうが、開発体験(DX)と品質保証のバランスを取りやすくなるのではないでしょうか。
「単体か結合か?」で迷ったら、「このテストはCIのどのタイミングで流れるべき重さ(=テストサイズ)なのか」という観点で分類してみると、運用しやすいテスト戦略が見えてくるはずです。
vs 既存コード:テストがなくテスト容易性の低いコードは、大外から攻める
(※ この章は テスト駆動開発のはじめの一歩|t_wadaさんに聞く1人で始める自動テストのコツと考え方 ##テストがなくテスト容易性の低いコードは、大外から攻める を言い換えただけです)
新規開発であれば理想的なテストピラミッド/テストトロフィーを築くことができますが、現実はそう甘くなく、「テストコードがなく、テストが書かれることも意識されていない、クラス間の結合度が密な地獄のようなコード(いわゆるレガシーコード)」を扱わねばならないこともあります。
こうしたコードに対して、依存をはがす手法や影響範囲を狭めるためにメソッド抽出をする手法などありますが、テストを書くためにプロダクションコードを破壊的に変更しなければならないこともあります。
そこで有効な戦略が「外から攻める」アプローチです(けっこう大変だと思いますが)
- 内部実装に依存しない防波堤を作る(外側からシステム全体を粗く包み込むようなテストを書く)
- リファクタリングの余地を確保する(手を入れたい機能に対して、振る舞いが変わっていないことを保証するテストを確保する)
- 徐々に内側へ攻め入る(より粒度の細かいユニットテストを追加していきながらリファクタリングを進める)
vs 新規コード:テストを書く(テスタビリティの高いコードを書く意識を持つ)
既存コードへの対処とは対照的に、新規開発においては「テスト容易性(テスタビリティ)を設計段階から組み込む」ことが開発者の最も重要な責務です!!!!(マジで)
経験則から、テストが難しいコードはそのほとんどが密結合(依存関係が多く複雑)で変更に脆弱な哀しみの構造になっています。逆に、テストを書きやすくするための設計を追求することは、結果として堅牢で保守性の高いプロダクトコードを生み出すことと同義です。
すごく主観的な話をすると、SOLID原則のSOIDを意識するだけで、コードの疎結合化は劇的に進む気がしています(先人の知恵BIG LOVE)
-
S(Single Responsibility Principle):単一責任の原則
- モジュールには1つだけの変更理由を持たせるようにつくる
- 責務が一つなら、テストケースもシンプルになる
- 単体テストで1単位の振る舞いを検証しやすい
-
O(Open-Closed Principle):開放閉鎖の原則
- 拡張するときは追加するだけ、変更の影響範囲が局所的(あるいは皆無)な構造を意識する
- 例えばStrategyパターンがその典型で、既存コードをいじらずに機能拡張ができる
- 新しい機能とそれに対するテストを追加するだけで済む
-
I(nterface Segregation Principle):インターフェース分離の原則
- インターフェースは目的に対して動的に手段を切り替えるものなので、利用する側の目的で分離させる(利用する側が利用しないメソッドを強制しない)
- テスト対象が必要とする最小限の依存で済むため、モックやテストダブルの作成が容易になる
- 逆にモックの設定がやたら多いのは肥大化したインターフェースのサインかも
-
D(Dependency Inversion Principle):依存性逆転の原則
- 使う側 -> 使われる側という一方向の矢印を、間に抽象をかますことで2つの矢印が抽象を向くように作り変える
- 具象ではなく抽象に依存することで結合度を下げることができる
- テスト時にもDI(依存性注入)しやすく、拡張性も高い
こんな感じの手法を使って、テストありきで考え、「このコードはどうやってテストするのか?」を常に自らに問いかけ、テストを書きやすくするための設計を自らに強制することで、プロダクトコードも勝手にきれいになっていきます。
※ L: Liskov Substitution Principle (リスコフの置換原則))をいれていないのは、継承はめちゃくちゃ難しいからです、憎いです(継承よりもコンポジション使いましょう)
※ 個人的にStrategyパターンめっちゃ好きです、激推しします
AI時代における自動テストとの向き合い方
AIによってコーディング体験は劇的に変わりました。自動テストをはじめるうえで重たかった「テスティングフレームワークやテスト設計の学習コスト」も「テストを生み出す実装コスト」も大幅に下がり、「テストを書くまでの最初の一歩」のハードルは確実に下がりました。
AIに指示を出せば驚異的なスピードでプロダクトコードを生成してくれますが、それと同じか速度でバグ(ドメインルールの間違い/業務要件の誤解などの仕様バグ)が混入するリスクも増えることを意味しており、もはや自動テストなしでAIの爆速&爆量のアウトプットを制御することは不可能です。
また、生成されたコードが必ずしもプロジェクト/プロダクトの文脈に即しているとは限りません。AIはプロジェクト/プロダクト全体を俯瞰したうえで「我々はどの品質特性を重視すべきで、それに対応するリスクは何で、どういう手法でそのリスクを低減するか」という意思決定までは代行してくれないからです。
(月並みな話で恐縮ですが)だからこそ、AIに完全に任せることができない領域に対して、人間(開発者)が責任を持つ必要があります。
AIの力を借りて実装コストを下げつつ、私たち開発者自身が適切なテスト戦略のもとで品質を評価し、ドメインから抽出された「守りたい品質」をユーザーへ安定的に届ける。それによって実現するフィードバックループの高速回転こそが、これからの開発チームに求められる競争力となるのではないでしょうか!
おわりに
『ソフトウェアテスト徹底指南書』やJSTQBの内容を引用しつつ、テスト戦略の設計から運用まで、開発者視点で体系的にまとめてみましたが、これら全てを教科書通りに厳密にやる必要はないと考えています。プロジェクトの規模やフェーズによって、やるべきこと・やらなくていいことは当然変わるからです。
ただ、「体系的な知識が前提にある状態」と「ない状態」とでは、日々の意思決定の質も、スピードも、納得感も全然違ってくると思います。また、これらは誰か一人が抱え込んで実践するものではないはずです。だからこそ、こうした知識をチームみんなで共有しあって当たり前の知識として持っておきたいよね、という思いでございます。(JSTQBみんな受験したらよいのでは)
弊組織でもメンバーみんなでいろいろと議論をしながら進めていますので、どこかのチームでこういったこのテスト戦略の話がネタにあがるとよいな~と思います!