要約
- postgresをレイクハウスにできるpg_mooncakeを動かしてみた
- icebergテーブルへのクエリはpg_duckdbを用いて実行される
- S3などのObject Storageをデータソースに設定でき、HTAP的な仕組みをpostgresで構築することができる
はじめに
Big Data is Deadが世にでてから3年近くが経過しました。
このブログでは「ほとんどのユーザーは真に「ビッグ」なデータを扱っておらず、ストレージとコンピューティングの分離が可能となった現代においてデータ量に囚われすぎるな」と主張している、と自分は認識しています。
MotherDuckの記事なのでポジショントークは多分に含まれていますし、印象は読み手の多様なコンテキストに依存しますが概ね正しい気がします。
(最近だとData Mesh is Dead (And That’s Actually Good News)みたいな記事も見て、記事の内容はよかったんですがxxx is deadとxxx is all you need構文やめて欲しくなりました。)
ともかく、ビッグデータだからと必要以上にリッチなインフラストラクチャを準備する必要はなく、技術スタックも変化してきているように思えます。
アドホックな分析なら S3(Parquet) x DuckDB x Marimo、みたいな構成で十分だったりします。
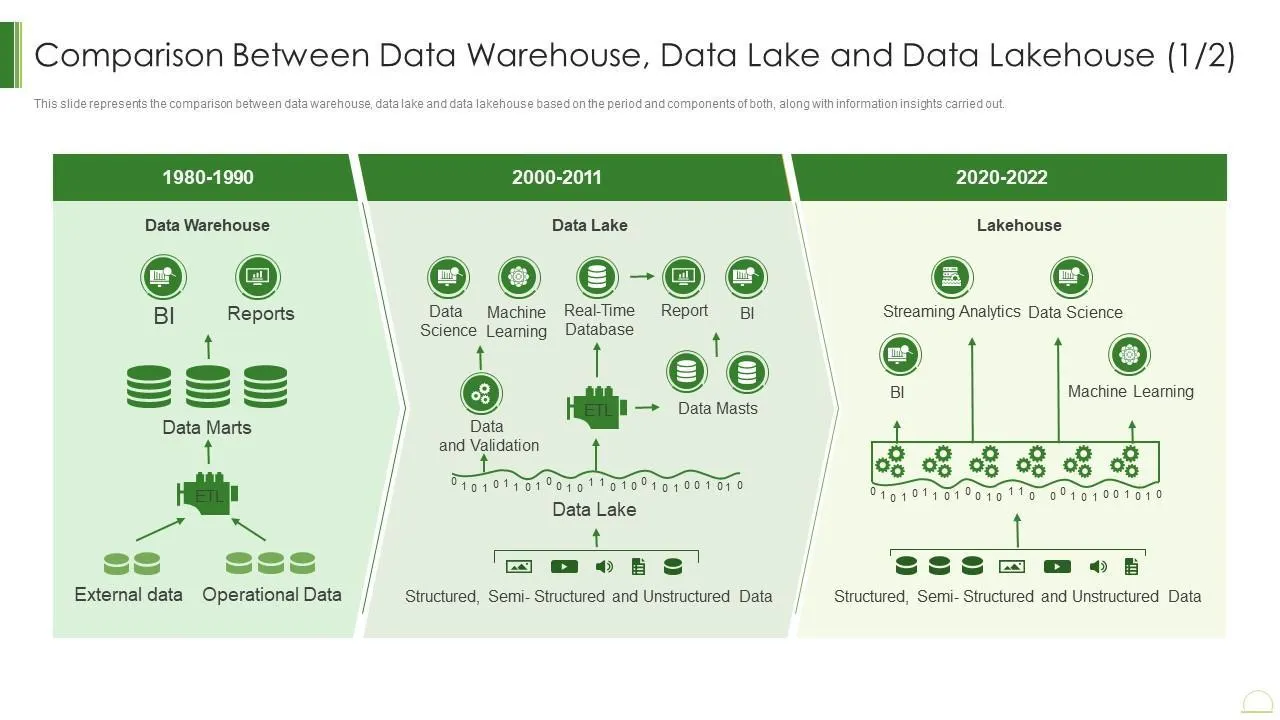
また最近のトレンドとして近年は
- データウェアハウスからデータレイクハウスへの、大袈裟に言うならパラダイムの移行
- Open Table Formatの普及
などがあると思います。
(source)
こういった中で、今年になって
- MotherDuckによるDuckLakeの発表
- DatabricksによるLakeBaseの発表
- Snwoflakeによるpg_lake発表
- Databricksによるpg_mooncakeの買収
などレイクハウスに関わるニュースが多く流れ込んできました。
今回は、Postgres上でのレイクハウス構築を可能とする(かもしれない)pg_mooncakeを触ってみます。
pg_mooncake
v1とv2で大きく変わっていますが、v2の話をしています。
まだ発展途上かつ最近Databricksに参画し、OSSとしての開発は止まっているように見えます。
pg_mooncakeはPostgresの拡張機能として開発されており、Data Lakehouseを簡単に構築できると謳われています。
開発元であるMoonCakeLabsによるmoonlinkとduckdbのpostgres拡張であるpg_duckdbを組み合わせています。
Moonlink
MoonlinkはデータのIngestionを担当し、例えばPostgresであれば論理レプリケーションによるCDCイベントを受け取りオブジェクトストレージに同期します。Postgres → Object Storageはニアリアルタイムの同期っぽいです。他にもevent streams(Kafka)、OTELに対応しているようです。
┌──────────moonlink───────────┐
│ ┌───────────────────────┐ │ ┌───────Iceberg───────┐
│ │ │ │ │ obj. store │
Postgres ───►│ │┌ ─ ─ ─ ─ ┐ ┌ ─ ─ ─ ─ ┐│ │ │┌───────┐ ┌─────────┐│
│ │ │ │ ││ │ │ ││
Kafka ───►│ ││ index │ │ cache ││ ├──►│ index │ │ parquet ││
│ │ │ │ ││ │ │ ││
Events ───►│ │└ ─ ─ ─ ─ ┘ └ ─ ─ ─ ─ ┘│ │ │└───────┘ └─────────┘│
│ │ nvme │ │ │ │
│ └───────────────────────┘ │ └─────────────────────┘
└─────────────────────────────┘
pg_duckdb
pg_duckdbはPostgresの拡張機能で、postgres上のデータをduckdbの強力なクエリエンジンを用いて実行することができます。pg_mooncakeでは、スキャン対象が通常のテーブルかIcebergテーブルかで、用いるクエリエンジンを切り替えてくれます。
※pg_duckdbはPostgresのBackground Workerとして動作するためDuckDBの性能にはある程度制限があるはずです、、
動かしてみる
チュートリアルをそのままやってもつまらないので、オブジェクトストレージにS3を設定してみます。
READMEのチュートリアルではDockerHubのイメージを利用していますが、S3のクレートが入っていないため自前でビルドする必要があります。
git clone --recurse-submodules https://github.com/Mooncake-Labs/pg_mooncake.git
-moonlink = { path = "src/moonlink" }
+moonlink = { path = "src/moonlink", features = ["storage-s3"]}
$ docker build -t mooncake_s3 .
$ docker run --name mooncake_s3_container --rm -e POSTGRES_PASSWORD=password mooncake_s3
(別のターミナル)
$ docker exec -it mooncake_s3_container psql -U postgres
psql (18.0 (Debian 18.0-1.pgdg12+3))
Type "help" for help.
postgres=# CREATE EXTENSION pg_mooncake CASCADE;
CREATE EXTENSION
postgres=# \dx
List of installed extensions
Name | Version | Default version | Schema | Description
-------------+---------+-----------------+------------+----------------------------------------
pg_duckdb | 1.1.0 | 1.1.0 | public | DuckDB Embedded in Postgres
pg_mooncake | 0.2.0 | 0.2.0 | public | Real-time analytics on Postgres tables
plpgsql | 1.0 | 1.0 | pg_catalog | PL/pgSQL procedural language
(3 rows)
pd_mooncakeは0.2.0、pg_duckdbは1.1.0が入っています。
チュートリアルのクエリを変更してS3の設定を追加します。
そのために、S3のバケットとアクセスキーを作成します。
アクセスキーは極力作成したくないですが、心を無にして作ります。
postgres=# CREATE TABLE trades(
id bigint PRIMARY KEY,
symbol text,
time timestamp,
price real
);
CREATE TABLE
postgres=# CALL mooncake.create_table('trades_iceberg', 'trades', NULL, '{
"mooncake": {
"skip_index_merge": true
},
"iceberg": {
"storage_config": {
"s3": {
"region": "ap-northeast-1",
"bucket": "<bucket_name>",
"access_key_id": "<access_key_id>",
"secret_access_key": "<secret_access_key>"
}
}
},
"wal": {
"storage_config": {
"s3": {
"region": "ap-northeast-1",
"bucket": "<bucket_name>",
"access_key_id": "<access_key_id>",
"secret_access_key": "<secret_access_key>"
}
}
}
}'
);
CALL
この例では通常のPostgresのtradesテーブルを作った後、trades_icebergというiceberg テーブルを作成しています。このときにstorage configを指定することで、データソースをS3とすることができます。
postgres=# INSERT INTO trades VALUES
(1, 'AMD', '2024-06-05 10:00:00', 119),
(2, 'AMZN', '2024-06-05 10:05:00', 207),
(3, 'AAPL', '2024-06-05 10:10:00', 203),
(4, 'AMZN', '2024-06-05 10:15:00', 210);
INSERT 0 4
postgres=# SELECT avg(price) FROM trades_iceberg WHERE symbol = 'AMZN';
avg
-------
208.5
(1 row)
S3を見てみると、先程作成したバケットの、s3://<bucket_name>/_wal/配下にwalデータが追加されています。
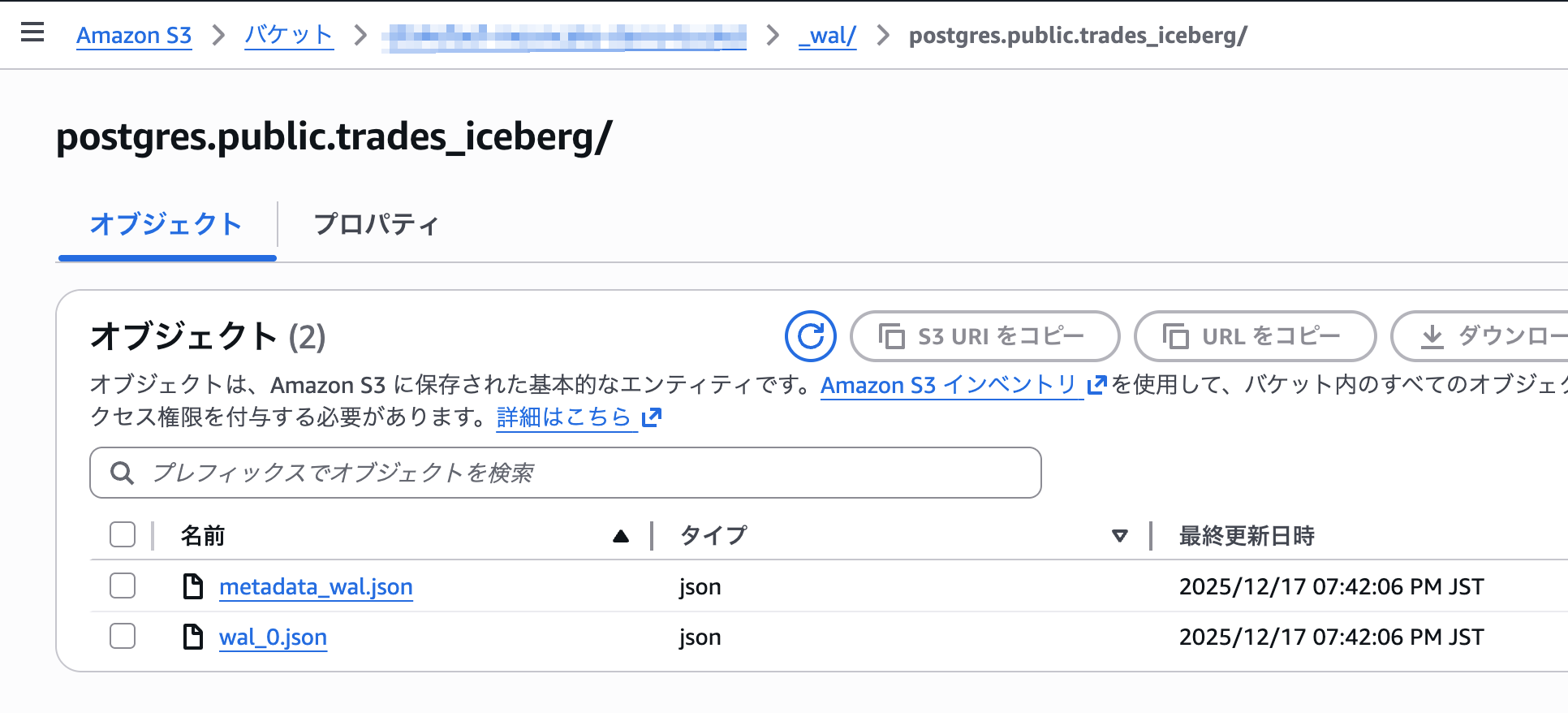
しばらく待つとs3://<bucket_name>/postgres配下にもparquet, puffinファイルが追加されています。

また、pg_duckdb@1.1.0はduckdb>=1.4.2に依存しているため、Icebergの書き込みをサポートしています。
postgres=# UPDATE trades SET price=300 WHERE id=2;
UPDATE 1
postgres=# SELECT avg(price) FROM trades_iceberg WHERE symbol = 'AMZN';
avg
-----
255
(1 row)
無事にicebergテーブルにも書き込まれていることが確認できました。
ただ以下の記事にあるように、Icebergテーブルのスキャンが含まれるクエリはDuckDBのクエリエンジンで実行されるため一部機能や性能に制限があります。
↑神記事