はじめに
タイトルは、「Cプログラミング入門以前 著:村山 公保」からお借りしました。
つまり、機械学習を学ぶ訳じゃないけど、機械学習には必要な技術っていっぱいあるよね。
って話をします。
まず自己紹介したいと思います。
経歴
大学学部・院共に人工知能研究室におりました。
最初はボルツマンマシンなどを元に色々研究していましたが、
訳あって院生時代はとある会社に研究アルバイトとして採用していただきまして、
修論もそこでの研究成果を書かせていただいて、卒業しました。
機械学習に入る前の時代
自分は割とプログラムは書けた方だったのですが、
知らない単語はそもそも検索のしようがないので、
ずっと技術学びたい・・・!って思いながらも検索できず、
苦悩の日々を過ごしました。
研究室に入ってから、Qiitaの存在を知り、Pythonを知ることができ
機械学習を学ぶことができました。
全てはQiitaのおかげで、言葉が分からなくて検索もできなかった頃から
徐々にワードを知ることができ、結果的に機械学習を学ぶことができました。
基本的に「機械学習、どう学んだか」についてはこれで終わりです。
あとはおまけみたいなものですが、お読みいただけると幸いです。
(おもちゃ付きのガムみたいな)
機械学習入門以前。
今回は、Qiitaへの感謝も込めて
機械学習の文中では出てこないけど、機械学習する上では必須のツール
などについて用語を羅列して、簡単な説明をしていきます。
お付き合いください。
Linux編
機械学習とLinuxは切っても切り離せない関係にあります。
Macじゃ力不足だし、WindowsだとPython入れるのが面倒だし
ゆえに機械学習では、半ば強制的にLinuxを使うことになります。
その方法や便利コマンド、必要な知識などについて解説していきます。
windowsでLinuxを扱う
Windows10には最近Windows Subsystem for Linuxと呼ばれる機能があります。
コレを使うことでwindows上に擬似的にLinux環境を使うことができます。
インストール方法などはググればいくらでも出てきます。
Microsoft公式のツールです。
SSH
SecuredShellの略でSSHです。
基本的には遠隔サーバにログインするための機能だと思ってください。
つまり、これを使うとリモートサーバにアクセスができます。
SSHを使うと何が嬉しいかというと、Macのインターフェースを使いながら
計算自体そのものはLinuxに任せることができるということです。
また、自分の使うインターフェースはMacかWindowsかどうかは問われません。
どちらでも使うことができます。
セキュリティ上の注意
自宅サーバや研究室サーバなどで、外部公開しながらSSHをしたい場合もあります。
その場合はsshd.conf上の設定で以下の点を守れば基本的には持ちます。
- PermitRootLoginをnoにする。
- PasswordAuthenticationをnoにする。
- (noにしても本体目の前にして直にアクセスする上ではpasswordでログインできます)
- 公開鍵認証に設定する。
公開鍵認証上でSSHをするとパスワード不要でセキュアにリモートに入れますので
公開鍵認証にしましょう。てかネットに晒すならそれ以外の選択肢はないです。
仕組み等はここでは詳しくは説明しません。
簡単に言えば、
-
ssh-keygenをすれば公開鍵と秘密鍵ペアができるから - 公開鍵をauthorized_keysに設定してsshd_config色々設定して
- アクセスする側の
~/.ssh/configにIdentityFile ~/.ssh/id_rsaみたいに設定
すれば安全にログインできます。
詳しくはggってください。
tmux
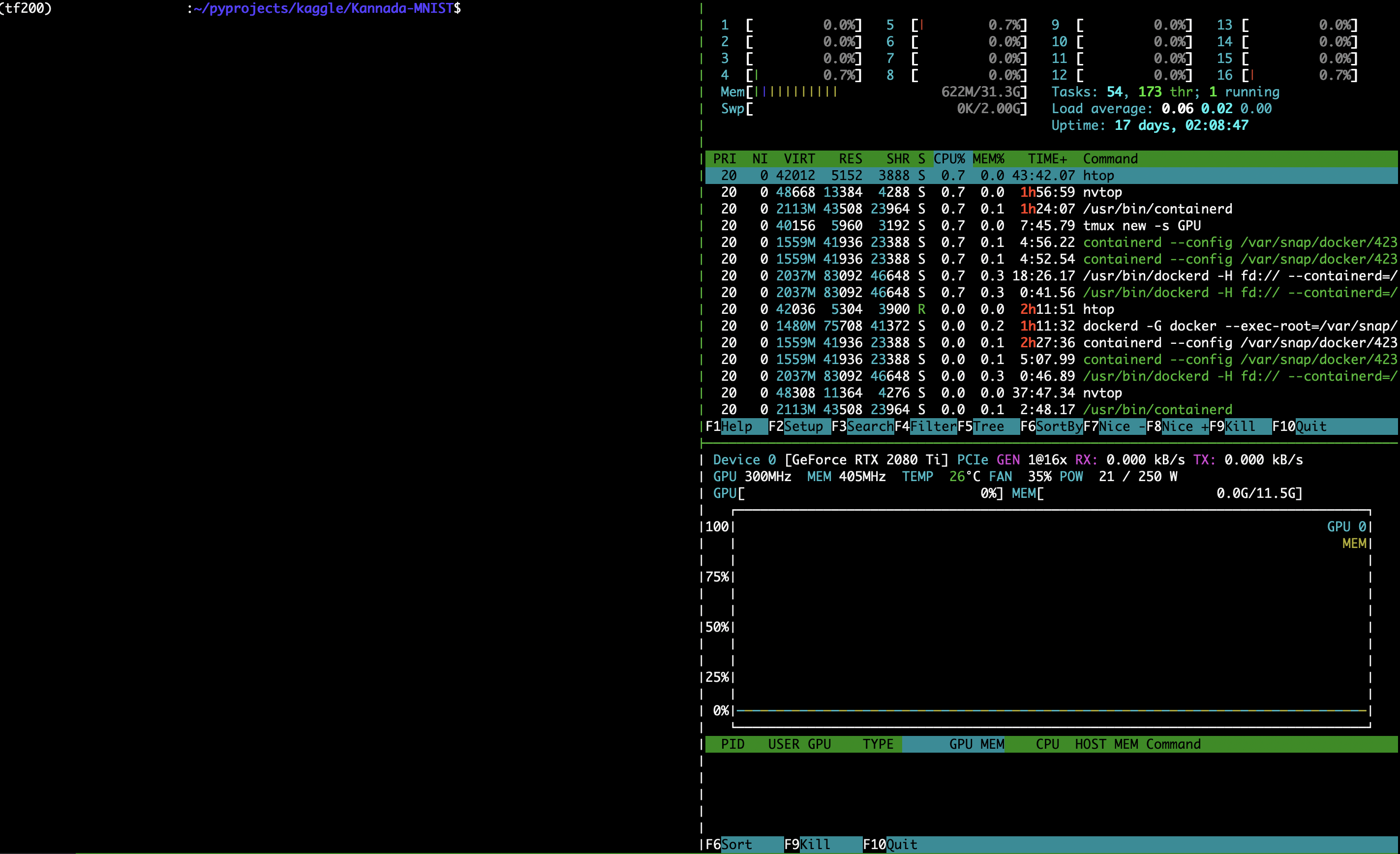
SSHでリモートに接続しながら計算を行っていると、
長い計算時間の間にネットワークが切れたりすると計算結果が無に帰ります。
SSHが切れてもずっと状態を保持し続けたいですよね?
tmuxには、実はそれが可能なのです。
tmuxにはセッションという概念があります。
それはSSHが切れても擬似ターミナルを永遠にプロセス内に残しておくことができるのです。
tmuxはubuntu18.04LTSにはおそらく入ってるかと思われますので、インストールはしなくて大丈夫です。
新しいセッションを立ち上げる
tmuxのセッションの起動のさせ方は
tmux new -s session_name
です。session_nameは自由に名前をつけてあげてください。
tmuxは基本prefixキーというのを最初に押してなんでも操作します。
prefixキーはデフォルトでctrl+bなのですが、ctrl+aにしておくと
めちゃめちゃ捗るのでおすすめです。
セッションをlogout
セッションそのものを無くしたいときはlogoutしましょう。
セッションを保持したまま元のshに戻る
デタッチと呼ばれる操作です。prefix,dの順番に押しましょう
SSHから切断されたあと、セッションに戻る
tmux aとターミナルに入力しましょう
画面を分割する。
tmuxは画面を分割することもできます。
prefix, %と入力すると縦に画面が割れます。
prefix, "と入力すると横に画面が割れます。
時計を表示
実は時計も表示できます。
tmux clock-modeとするとできます。
全体のチートシート
prefix, ?でも出ますが、
https://qiita.com/nmrmsys/items/03f97f5eabec18a3a18b
こちらの記事参考にしていただけると良いかと思います。
~/.tmux.conf
tmuxも色々設定ができます。
色々といっても設定は様々で、私は以下の二つの記事を参考にしました。
達人に学ぶ.tmux.confの基本設定
tmux で Prefix key が押されているかどうかを表示する
自分が常に使っている設定は以下の通りです。
# prefixキーをC-aに変更する<img width="727" alt="スクリーンショット 2019-12-21 1.33.27.png" src="https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/182970/b5e6f309-53c3-0174-2b76-682a65156b75.png">
set -g prefix C-a
# C-bのキーバインドを解除する
unbind C-b
# 設定ファイルをリロードする
bind r source-file ~/.tmux.conf \; display "Reloaded!"
# C-a*2でtmux内のプログラムにC-aを送る
bind C-a send-prefix
# | でペインを縦に分割する
bind | split-window -h
# - でペインを横に分割する
bind - split-window -v
# 256色端末を使用する
set -g default-terminal "screen-256color"
# prefixキーが押されているか確認できるようにする
set-option -g status-left '#[fg=cyan,bg=#303030]#{?client_prefix,#[reverse],} #H[#S] #[default]'
基本的にコレで事足ります。
htop
htopはリソースを見ることができるツールです。

コレで実際どのくらいのCPUリソースに負荷が掛かっているのかを見ることができます。
nvtop
nvtopはhtopのGPU版です。

htopもあればnvtopもあるといった感じでしょうか。
GPUを使っているのかどうかもコレで見ることができます。
ubuntuだと19.04の場合はaptとかで入れられるけど、
基本はソースをビルドする必要あり。
vi/vim
SSH上など、Linux上で何かとファイルをいじる可能性は高いです。
そんな時に使うのはviとVimです。viとvimの違いは、
vi+色々な機能=vimです。viだけだと色々と面倒臭いです。
vi、vimコマンドで開けます。
基本的に以下のことを覚えておけば大丈夫でしょう。
normalモード
カーソルを動かしたり、undoしたり検索したりするのも基本ここでやります
知っておくと便利な機能を列挙します。
:q 終了
:q! 強制終了
:w 上書き
:100 100行目に移動
/word wordを検索(+nで次の一致単語に移動)
u Undo(windowsで言うctrl+z的な動作)
dd 現在の行削除(windowsで言うctrl+x的な動作)
yy 現在の行をコピー(ctrl+c的な動作)
p ペースト(ctrl+v的な動作)
hjkl ←↓↑→に対応(macだと日本語入力でzhとすると←と出たりします)
insertモード
iキーやOとか押すとinsertモードになります。
インサートモードであれば、文字を入力できます。
normalモードに戻る時はESCを押しましょう。
(macでESCキーが元に戻ったのはVimmerが原因...?)
詳しくはググればいくらでも操作方法がありますので、
是非調べてみてください
その他コマンド
find
文字通りファイルを探してくれます。
find [start_dir]
使い方的には
find ~/ | grep 特定したいファイル
とかでファイルの在りかを探せたりします。
tree
ファイルをTree形式で見せてくれます。
全体構成を把握したい時はこれをいつも使ってます。
ログが大量に流れちゃうのが問題ですが(
wc
ファイル行数を確認します
tsvファイルでどれくらいの行数か知りたい時とかに有効
あるいはfindさせて
df/du
ファイルサイズを測ってくれます。
dfは全体のファイルサイズの容量を、
duは個別のファイルサイズの容量をそれぞれ見せてくれます。
df -h
Filesystem Size Used Avail Use% Mounted on
udev 16G 0 16G 0% /dev
tmpfs 3.2G 1.5M 3.2G 1% /run
/dev/sdb3 916G 33G 837G 4% /
tmpfs 16G 88K 16G 1% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 16G 0 16G 0% /sys/fs/cgroup
-hオプションは容量に対して単位表示をしてくれます。
FileSystemの項にあるのがdev(device)とその具体的な名前です。
/dev/sdb3がSSDとかの具体的なハードウェアになります。
基本的にsd[x][n]と名前をつけられます。詳しくはggってください。
一方、個別のファイル容量をみたい場合はduコマンドが有効です。
例えばカレントのフォルダで容量一覧をみたい場合は
du -hs ~/*
とするとカレントに個別に乗っかってるファイル容量を全てみてくれます。
どれが重いか見せてくれるわけです。
grep
大量のログから該当する表記だけ抽出して見たい場合に使います。
find ~/ | grep filename
と言ったパイプ処理でログを流してあげて、
filenameに該当する部分だけを抽出できます
後述のregexにも対応しています。
cat
ファイルを直で出力できます。パイプを組み合わせて
cat /var/log/auth.log | grep sudo
とかでファイル内検索とかしてあげられます。
less/head/tail
120GBとかいうクソ馬鹿デカtsvが送られた時に
vim logfile.tsvとかやると死ぬほど時間かかります。
(そもそもそう言うレベルのtsvはparquetで送ろうね!)
そんな時に、lessコマンドは一部だけ読み込んで、
画面表示してくれます。
headは先頭数行分を表示してくれます。
tailは最後から数行分を表示してくれます。
jq
jsonファイルをいい感じにしてくれます。
詳細はこちら:jq コマンドを使う日常のご紹介をご参照ください。
sed
文字列を置き換えてくれます。
s/a/b/g→aをbに変換
よくエンジニア界隈でも、パッとs/の/が/gとかslackで飛ばされたりするくらい、
共通言語化しています。
python編
Pythonは知ってるけどインストールとかどーすんの?って人だったり
色々知ってるけどLinuxでバージョン管理するのどーしたらいいか迷う...
みたいな人におすすめです。
version管理編
pyenv
ユーザごとにPythonバージョンをインストールしてくれます。
詳細はこちら:【永久保存版】pyenv+venvをubuntuに入れる【もう迷わない】
pyenvをインストールしたら、
pyenv install python-versionで希望のpythonバージョンを入れましょう。
基本的にはanacondaとかより一番シンプルなやつを持ってきた方がいいです。
pyenv install 3.6.9とか
そうすると、個人フォルダにpythonを入れてくれるので、他のユーザの環境を汚染したりしません。
venv
venvはpythonのパッケージ管理ツールです。
基本となるpythonをpyenvで選んであげて、
venvで環境を作成してpipとかしてあげるとGoodです。
詳細はこちら:【永久保存版】pyenv+venvをubuntuに入れる【もう迷わない】
IDE編
vscode
vscodeにはssh機能が付いていて、公開鍵設定を自動で読んで
いい感じに秘密鍵を使ってSSHしながらリモートサーバのファイルをいじれたりします。
一方でvenvあたりのパッケージとかを謎に読もうとして、
コーディングにはあまり向いていない印象です。
(venv+vscodeでいい感じにコーディング中にコード候補とか出してくれるのあったら情報求む!)
jupyter_notebook
Jupyter_notebookとは、Webブラウザ上で起動するIDEです。
基本的にリモートサーバ上で起動させて、
notebookを書き込んでは計算だけはリモート鯖にやらせたい時に便利です。
Google Colaboratory
環境は全部Google側が用意してくれる系のIDEです。
環境構築等一切やらなくて済むのが特徴です。
Googleのリソースを使ってPythonをコーディングできます。
ありがたいことにGPUやTPUリソースも使わせてくれます。
基本はJupyter notebookと同じですが、リソースはGoogleが管理っていうだけですね。
便利ライブラリ編
tqdm
進捗管理バーを出してくれます。
DeepLearningやその他クッソ重い処理が今どれくらい進んでいるのか、
すぐに把握できるのがいい点です。
データサイエンスは基本クソデカファイルを処理するので、
進捗バーがあるとだいたい何分(時には30時間とか)かかるからその間switchでゲームしよ
なんてこともできるわけです。機械学習には必須です。
使い方は公式を参照してください。
multiprocessとか、数値モニタリングとかの機能も備わってます。
pandas
tsvとかparquetファイルをテーブル的にいい〜感じに処理してくれるツールです。
データサイエンスやる上ではほぼ必須でしょう。
使い方などはkaggleやってると嫌でも覚えます。
matplotlib
グラフを表示できます。
基本的にKaggleやってると嫌でも遭遇します。
他の手段としてはseaborn,plotlyなどがあります。
Pickle
pythonのオブジェクトなんでも保存します。
途中の状態を保存しておきたいですよね。
Kerasで作ったmodelを保存したいとか、長時間かけて作ったXGBoostのモデルを保存したいとか
そういった時に、丸ごと保存するのがpickleです。
丸ごと保存したpickleは、その機能も全部保存されるので、
解凍してすぐ予測用に使いたいとかでも、機能します。
その他覚えておくと良い概念
regex
正規表現っていうやつです。
大量にある文章中の電話番号を検索して取りたいって時にこれを使うとヨシ
電話番号の例だと
\d{3,4}[-]?\d{3,4}[-]?\d{4}
とかで取れます。(なんもわからんと怪文書なんですけどね)
Docker
いわゆる仮想マシンではないんですが、MySQLとかのミドルウェアを切り離して
独立化させて、環境を汚さないようにできるのがDockerです。
Dockerの知識がないと、MySQLとかを本体にインストールして・・・
ああっ失敗したみたいな面倒なことが発生します。
DockerはMySQLやnginxといったサービスを分割してコンテナという単位に押し込んでしまいます。
このコンテナという物はいくらでも捨てて、いくらでも生産できるので、
環境の構築が非常に楽です。
詳しくは、Dockerで検索すれば非常に大量の情報が出てくるので、
そちらを参考にされると良いかと思われます。
LocalForwarding/ポートフォワーディング
計算だけは強いGPUのクソでっかいデスクトップPCに計算させて、
コーディングとか指示だけは手元のMacから。みたいな都合のいい使い方をしたい場合は、
ポートフォワーディング+jupyterNotebookをおすすめします。
ポートフォワーディングについては以前記事を書きましたので、そちらで紹介します。
データサイエンティストなら誰もが通る、リモートサーバのJupyter Notebook (Lab)へのアクセス方法まとめ
ケース別、逆引き辞書
case1. MacBook使いたいけどGPUも欲しい。どうしたらいい?
答え
基本操作はMacBookで、強いPCとして1台別に用意しましょう。
強いPCはなんでも大丈夫です。ゲーミング用のGPUマシンを購入しても大丈夫ですし、
GCP,AWSを使った方が大抵の場合お得だったり簡単だったりします。
なんでも大丈夫ですが、基本必要なやることは、
GPUサーバでsshd設定ちゃんとして、なんとかして
ポートフォワーディングしてjupyterをlocalhostで表示させるようにすればおk
case2. 自宅に強いubuntuPCを置いて、家の中だけでいいからSSHでアクセスしたりしたい。
答え
強いPCにubuntuをインスコして、ルータ内設定のDHCPで強いPCだけ固定しましょう
大抵macアドレスとかで認識してるので、
このmacアドレスにDHCPで172.168.1.22を必ず指定してあげてね
と設定すればおk
あとはSSH設定して、公開鍵を送って、172.168.1.22にSSHしたらいい。
case3. インターネットを経由して外から自宅サーバにSSHアクセスするには?
答え
結構やばいからある程度知識得てからやった方がいい。 やる方法はいくらでもあります
まずセキュリティの知識をsshd_configあたりググって得てから、
ルータ側で、どの内側ポートをどの外側ポートに出せばいいか設定したげればおk
環境とプロバイダによりきりなんですが、基本外側ipは変わりまくるので、
DDNSという技術を使うと固定のドメインにアクセスすれば外からアクセスできるという感じです。
case4. 強いPC用意するお金ありませんけど機械学習できますか?
Colabratory使ってくれ!...GPUもあるぞ!
基本Colab使うのがGoodでしょう。無料ですし
でも使いすぎると結構切られたり、めっちゃ遅くなったりします。
その時はGCP使いましょ。お金そんなかからないから大丈夫だって〜〜〜〜〜
case5. みんなで共用のGPU鯖建てたい、環境構築どうしたらいい?
pyenv+venv使おう!それで全てがうまくいくよ。
pyenvはsudo権も不要でインストール可能なので、権限管理も簡単です。
aptのバージョン依存とかもないと思って基本は大丈夫なので
(インストール時ビルドは走るから、無の状態でやってね〜は流石に無理ですが。)
sudo権なども管理しやすく、便利です。
case6. githubとかにnotebookを管理したいけどどうしたらいい?
colabの機能を使うとcommit+pushとかできて、差分も見やすいよ
こちらの記事Colabratoryって画面上だけでGitHubにPushして差分まで見れちゃうって知ってた?
でできます。
case7. 研究上で、モデルのバージョン管理とか面倒で何かいい方法ある?
GCPやAWSにあります。
GCPならAIプラットフォーム、AWSならSageMakerとか!
case8. 学習データってどうやって集めたらええの・・・
スクレイピング、KaggleDatasets、論文、GCP/AWSアノテータ活用などなど
これは場合によるんですが、
研究の場合、一つのデータセットで成績を競うみたいなやつだと元の論文があるからそれ参考にでいい。
独自研究の場合、クローリング/スクレイピングとかで検索すればやり方は出てきます。
本当に新しくデータセット作りたい場合、Cloudにもアノテーション機能があります。それを利用してみては?
おわりに
何かこれどうしたらいいの?みたいな質問はなるべくここのCaseに挙げて回答していく所存ですので、
何かあればぜひ質問してください。
長いおまけに付き合っていただき、ありがとうございました。