TensorFlowのconv2d系のレイヤーは以下があります(tf.contribは除く)。
tf.nn.conv2dtf.nn.depthwise_conv2dtf.nn.depthwise_conv2d_nativetf.nn.separable_conv2dtf.nn.atrous_conv2d
このうちのtf.nn.conv2d, tf.nn.depthwise_conv2d, tf.nn.separable_conv2dがどんなレイヤーなのか、入力とフィルタと出力のチャンネル数について整理します。
説明の簡便のためバッチサイズについては基本的には省略し[H,W,C]のテンソルを念頭に説明します。
ストライドについては説明を省略します。またtf.nn.depthwise_conv2d, tf.nn.separable_conv2dはtf.nn.atrous_conv2dの機能(rate引数)も持っていますがそれについても説明を省略します。
tf.nn.conv2d
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, data_format=None, name=None)
いわゆる畳み込み層。TensorFlowのドキュメントでは以下の式で説明されます。
output[b, i, j, k] =
sum_{di, dj, q} input[b, strides[1] * i + di, strides[2] * j + dj, q] *
filter[di, dj, q, k]
図にすると以下のようになります。深層学習の教科書でも似たような図で説明されます。
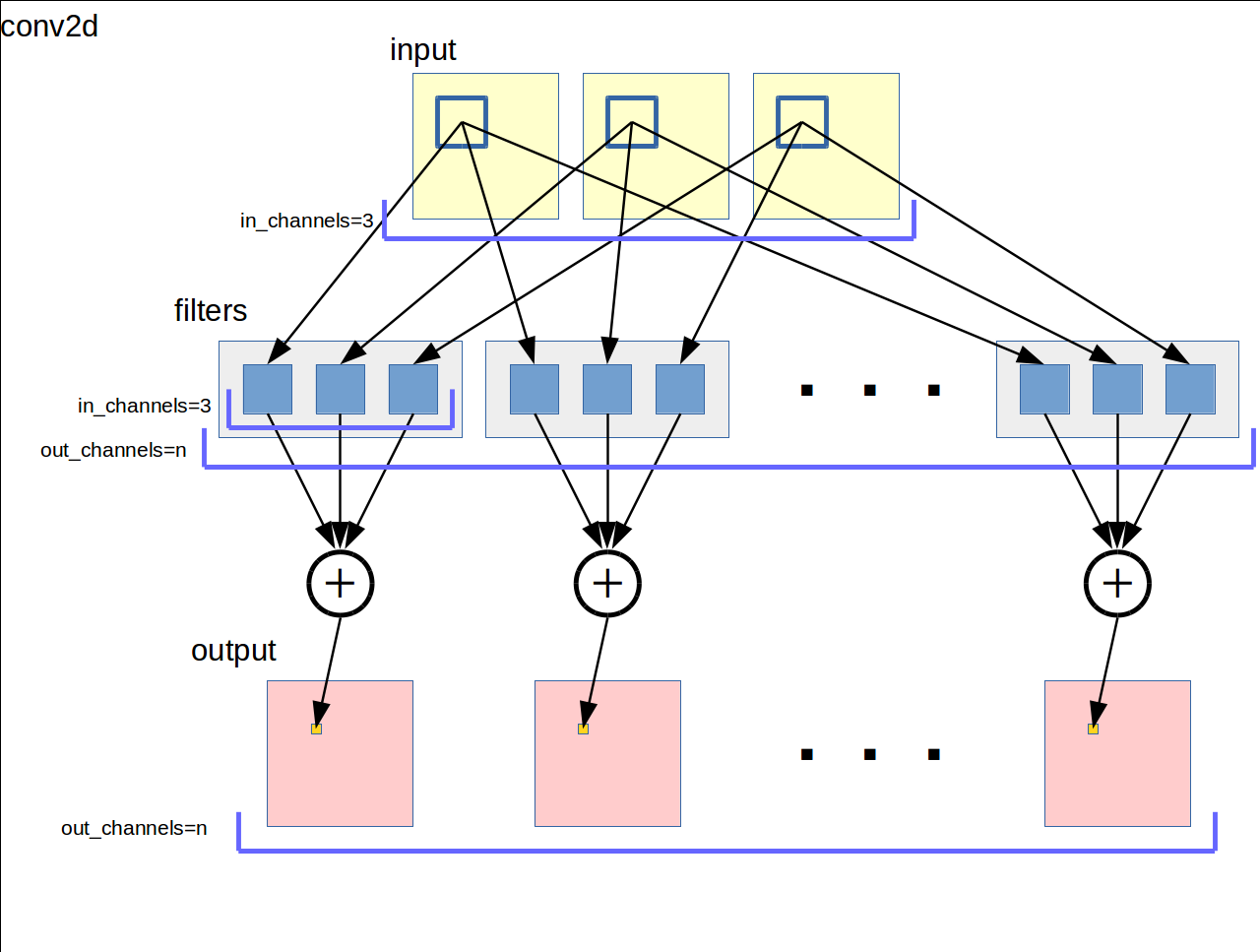
手順的に箇条書きに書き下します。
- 入力の各チャネルをフィルタサイズの窓で走査する
- 入力の各チャネルの窓領域にチャネルごとに異なるフィルタを適用する
- 各フィルタの出力の和をとって出力チャネルの値とする
- これを出力チャネルの数だけ行う
したがってフィルタの総数は入力チャネル数 * 出力チャネル数になります。ドキュメントでは [filter_height, filter_width, in_channels, out_channels] のshapeでフィルタ変数を確保するように書いてあります。
tf.nn.depthwise_conv2d
tf.nn.depthwise_conv2d(input, filter, strides, padding, rate=None, name=None)
大まかに言ってtf.nn.conv2dでは合計していた各フィルタの出力について和をとらずフィルタごとに個別の出力チャネルとするようなレイヤーです。TensorFlowのドキュメントでは以下の式で説明されます。
output[b, i, j, k * channel_multiplier + q] = sum_{di, dj}
filter[di, dj, k, q] * input[b, strides[1] * i + rate[0] * di,
strides[2] * j + rate[1] * dj, k]
図にすると以下のようになります。
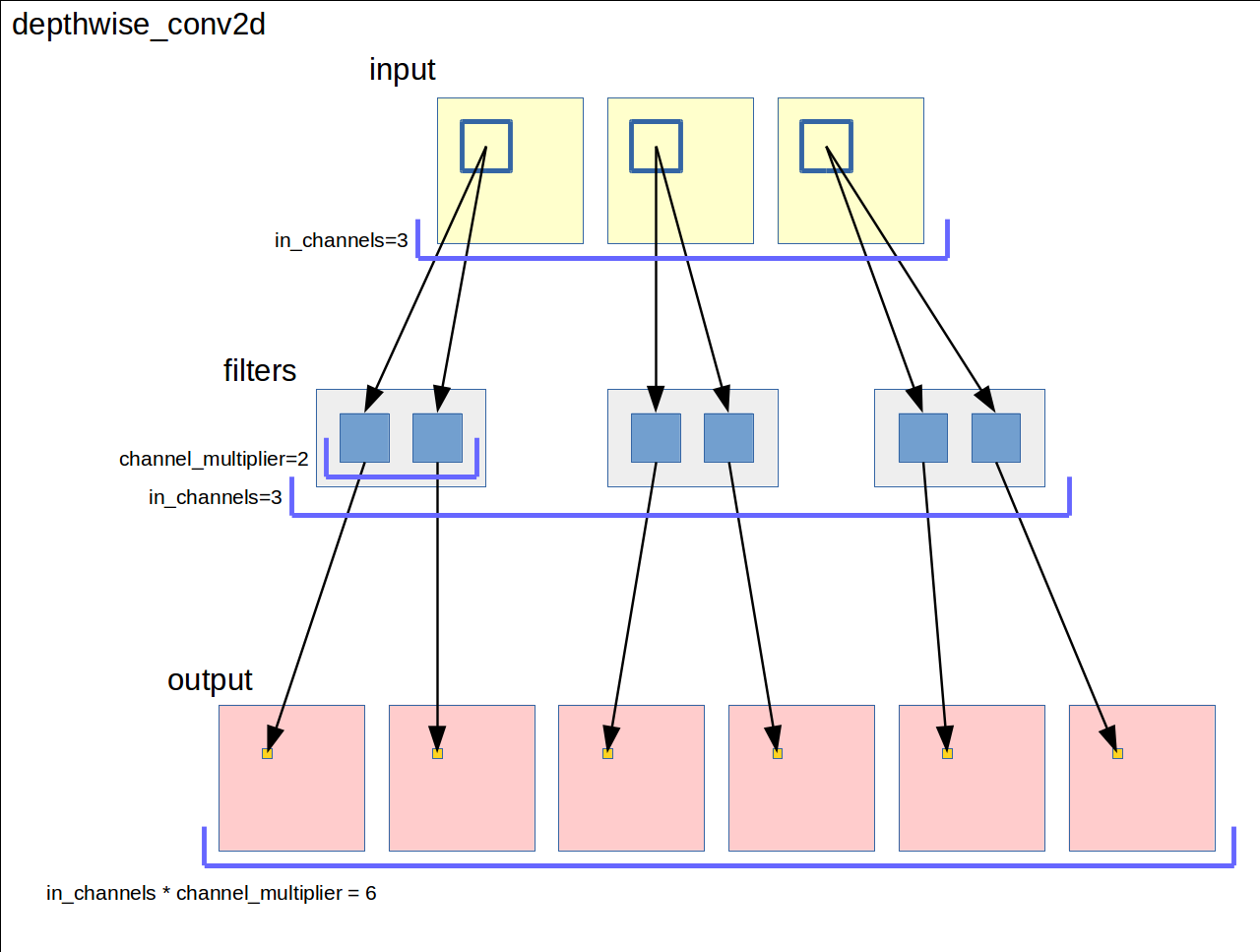
手順的に箇条書きに書き下します。
- 入力の各チャネルをフィルタサイズの窓で走査する
- 入力の各チャネルの窓領域にチャネルごとに
channel_multiplierの数だけ異なるフィルタを適用する - 各フィルタの出力をそのまま出力チャネルとする
出力チャネルの数は入力チャネル数 * channel_multiplierになります。
フィルタの総数も入力チャネル数 * channel_multiplierになります。ドキュメントでは [filter_height, filter_width, in_channels, channel_multiplier] のshapeでフィルタ変数を確保するように書いてあります。
tf.nn.separable_conv2d
tf.nn.depthwise_conv2dではフィルタの出力を個別の出力チャネルとしていたものを「個々の出力に重みを乗算したものの総和」を出力するようにしたのがtf.nn.separable_conv2dです。tf.nn.conv2dでは単に和をとっていたのに対してどのフィルタをどういう重みで加算するかまで学習します。TensorFlowのドキュメントでは以下の式で説明されます。
output[b, i, j, k] = sum_{di, dj, q, r]
input[b, strides[1] * i + di, strides[2] * j + dj, q] *
depthwise_filter[di, dj, q, r] *
pointwise_filter[0, 0, q * channel_multiplier + r, k]
ここでdepthwise_filterが普通の畳み込み層のフィルタ、pointwise_filterがフィルタの出力の和を取るときの重みです。どちらもバックプロパゲーションで学習することができます。
図にすると以下のようになります。
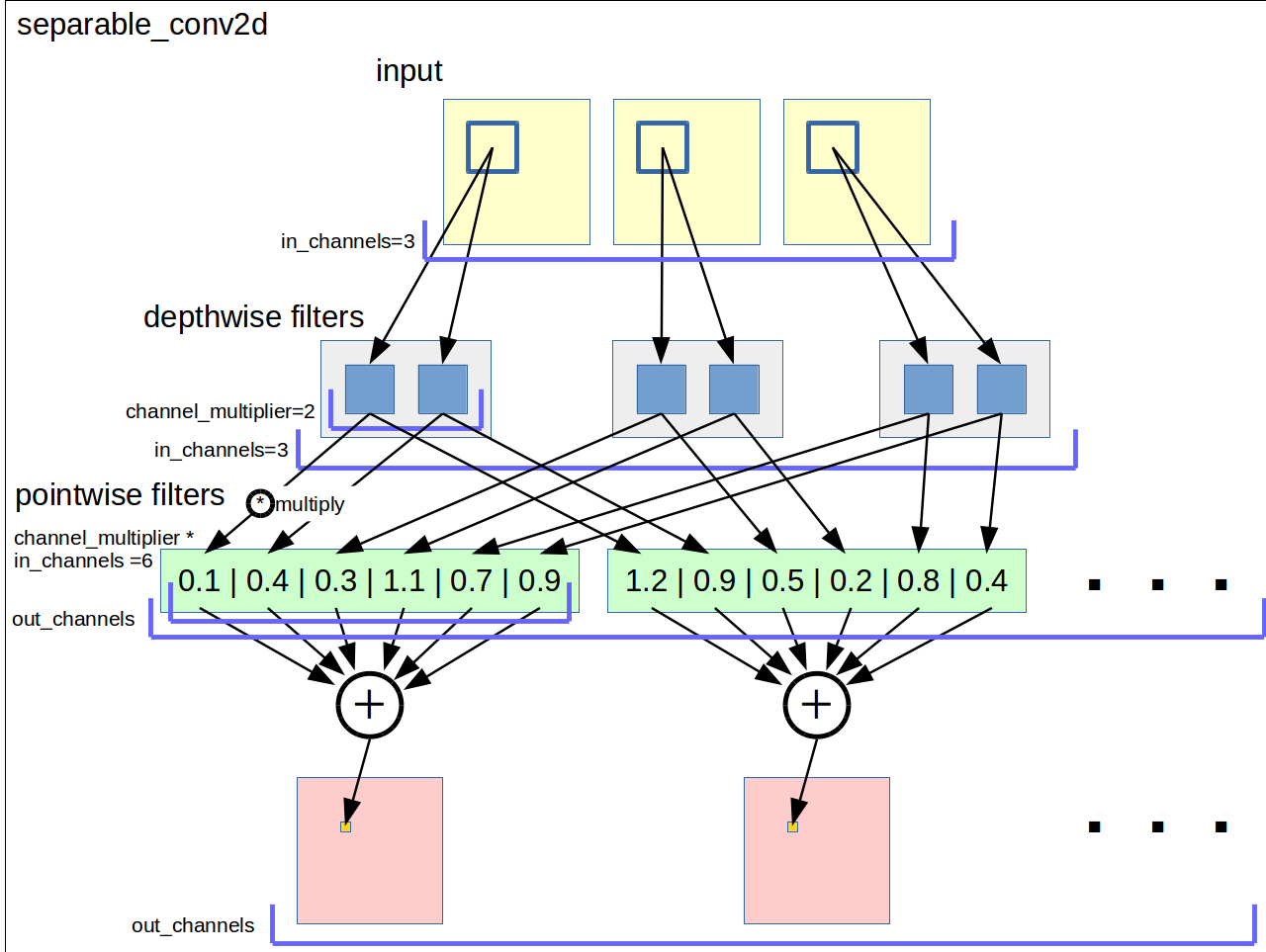
- 入力の各チャネルをフィルタサイズの窓で走査する
- 入力の各チャネルの窓領域にチャネルごとに
channel_multiplierの数だけ異なるフィルタを適用する - すべてのフィルタの出力について異なる重みを乗算して和をとり出力チャネルの値とする
- これを出力チャネルの数だけ行う
出力チャネル数は任意です。channel_multiplierの数も任意です。
depthwise_filterの総数は入力チャネル数 * channel_multiplierでありドキュメントでは[filter_height, filter_width, in_channels, channel_multiplier]のshapeでフィルタ変数を確保するように書いてあります。
pointwise_filterの総数は入力チャネル数 * channel_multiplier * 出力チャネル数でありドキュメントでは[1, 1, channel_multiplier * in_channels, out_channels]のshapeでフィルタ変数を確保するように書いてあります。
tf.nn.depthwise_conv2d, tf.nn.separable_conv2dの意味
ここからは私の考察です。それぞれの元論文は見つけていません。
tf.nn.depthwise_conv2dはフィルタの出力を更に加工したい時、あるいはチャネルごとフィルタごとの出力のまま畳み込み層を重ねていきたい時に使用するためのものだと思います。カスタムの畳み込み層を作りたいみたいな。
tf.nn.separable_conv2dはフィルタ後のチャネルの意味に重みをつけたい、あるいはフィルタ後のチャネルの組み合わせにおいて混ぜたくないチャネルがある、そういう組み合わせを学習するためのものだと思います。
どちらも「入力テンソルの各チャネルの意味が異なる」場合に使うと効果的なのだと考えています。RGB画像ではそれぞれのチャネルがすべて輝度値(的)という点において各チャネルの意味は同じです。ある画像のRチャネルだけを取り出してもGチャネルを取り出しても写真であれば何が写っているかはわかることの方が多いです。どのチャネルにも形状特徴が入っているのであるからチャネルごとの意味は等価であり加算して良い。これがtf.nn.conv2dで各フィルタの出力を加算してしまってもうまくいく理由なのかなと思います。
「入力テンソルの各チャネルの意味が異なる」ようなデータはいろいろ思い浮かびます。性質としては「同じ座標系(H, W)に乗った複数の異なる属性」というデータです。
- 気象データ(同じ地図に気圧、気温、雨雲、雨量、落雷などといった異なるデータ)
- 複合した画像データ(RGB+深度、RGB+温度など)
- ゲームの情報(敵味方の位置、勢力、射程などなど)
こういったデータについて「まだこの畳み込み層ではすべてのフィルタを合算したくない、ただしいくつかのチャネルの組み合わせについては相関があるかもしれない」という時にtf.nn.separable_conv2dでフィルタの組み合わせまで学習できると思います。
これはtf.nn.conv2dでも「組み合わせに入れたくないチャネルのフィルタを0にする」という学習がされれば実現されますが無駄なフィルタが多くなります(0フィルタは出力に何も影響しない)。tf.nn.separable_conv2dであればすべてのdepthwise_filterが非ゼロであってもpointwise_filterによる組み合わせで「使いたい組み合わせでは使う、使いたくない組み合わせでは使わない」というところまで学習できます。
以上になりますが画像系の論文をarXivで眺めていてもconv2d以外は見ないので画像系ではあんまり考えなくて良いと思います。「入力テンソルの各チャネルの意味が異なる」「チャネルの組み合わせが重要」と思われる入力データに当たったときに考えてみると良いと思います。