はじめに
この手順では、UPI(User Provisioned Infrastructure)を使って OCP(OpenShift Container Platform)の環境を構築していきます。省略系のOCPだとわかりにくいので、ここではOpenShiftと呼ぶ事にします。
OpenShiftとは
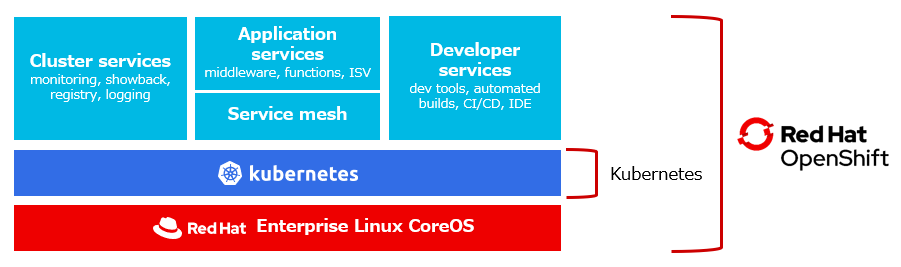
OpenShiftとは、Red Hatが提供する商用版の Kubernetes です。
オープンソースのKubernetesに、運用に必要な独自機能を追加したり、オープンソースの運用管理ツールや、開発ツールをバンドルした製品です。もちろんサポートが付いているのも大きな違いです。
例えば、監視用のOSSであるPrometheusや、ログ収集用のEFK(ElasticSearch/Fluented/Kafka)等の他に、CI/CDツールであるJenkis、Tekton もバンドルされています。
また、Red Hatの Middleware群もOpenShift上での使用に限り、提供されており、とりあえず OpenShiftを持っていればコンテナ環境を構築・運用するためのツール類が一通り揃っている。という形になっています。
UPIインストール
UPI(User Provisioned Infrastructure)インストールとは、ユーザーが自分で OpenShiftの環境構築に必要な、OSをインストールしたノードや、DNSの設定、ロードバランサーなどの環境をまず整え、その上にソフトウェアとしてのOpenShift(Kubernetesと、運用に必要な各種ツール)をインストールする方法です。
IPI環境へのインストール
UPIの対義語としてIPI(Installer Provisioned Infrastructure)という言葉があります。こちらは、AWS、Azure、GCPのような Public Cloud Providerが持っているインフラ構築用の APIを使用して UPIで手作業で行っていた、ノードの作成、ロードバランサーの設定、DNSの設定等をOpenShiftのインストーラーが自動で行う方法です。
正確を期すと、Public Cloud Providerのアカウントを準備しておく事と、OpenShiftで使用するドメインの取得と取得したドメインを、そのPublic Cloud ProviderのDNSサービスに登録しておく事は事前にする必要があります。
IPIは、インストーラーを実行すると指定した数のノードをデプロイし、DNSサーバーも自動で構成されるなど非常に楽なので、私もテストなどではこの方法を使用しています。
が、構成に細かなカスタマイズが必要な場合や、OpenShiftのインストーラーがIPIに対応してない環境(例えばオンプレミス)に環境を作成したい場合は、UPIによるOpenShiftのインストールが必要になります。
IPIインストールができる環境は、DNSサーバーやLoad Balancerや、ネットワークの構成をインストーラーからAPIを使用して構築・構成する必要があります。そのためIPIがサポートしている環境はAWSやAzure、GCP等の環境に限られています。が、後述しますがIPIの意味する所は最近、少し広がってきたようで、Baremetal IPI という言葉も出てきました。
IPI環境、UPI環境へのインストール
物理環境では厳密な意味での完全なIPIインストールというのはあり得ません。例えば物理環境では、少なくてもルーターやサーバーを設置してケーブルを配線するという環境準備が必要です。
しかし、OpenShift 4.6では、ネットワークの環境が整っていれば、OpenStackのIronic等で利用されているBare Metal Provisioningの技術を利用する事でインストーラーからノードのOSのデプロイを実行できるようになりました。これもBare Metal IPIと呼ぶようになりました。ただこの場合も、DNSやルーティングなどは、事前に手動でセットアップする必要があるので、Public Cloud Provider上のIPIとはできる範囲が違います。
参考:Deploying Installer Provisioned Infrastructure (IPI) of OpenShift on Bare Metal - 4.6
この手順で実行する内容
この手順では、物理環境であればどこにでも適用できるインストール方法であるBaremetal環境への UPI(User Provisioned Infrastructure)インストールをOpenShift 4.5を使用して実行してみます。
UPI(User Provisioned Infrastructure)ですので、自分で、OpenShifttを稼働させるためのDNSサーバー、Load Balancer、KubernetesのMasterノード、Workerノード等のインストールなどの周辺環境をProvisionしてあげる必要があります。
BareMetalと書いていますが、仮想マシンを物理マシンと同等とみなせる仮想化環境でも手順は同じです。
※VMware環境の場合は、OpenShift 4.5から、VMWare vSphere IPIインストールという方式が出てきました。機会があれば別記事で触れたいと思います。
1.環境のセットアップ
1.1.環境を設計する
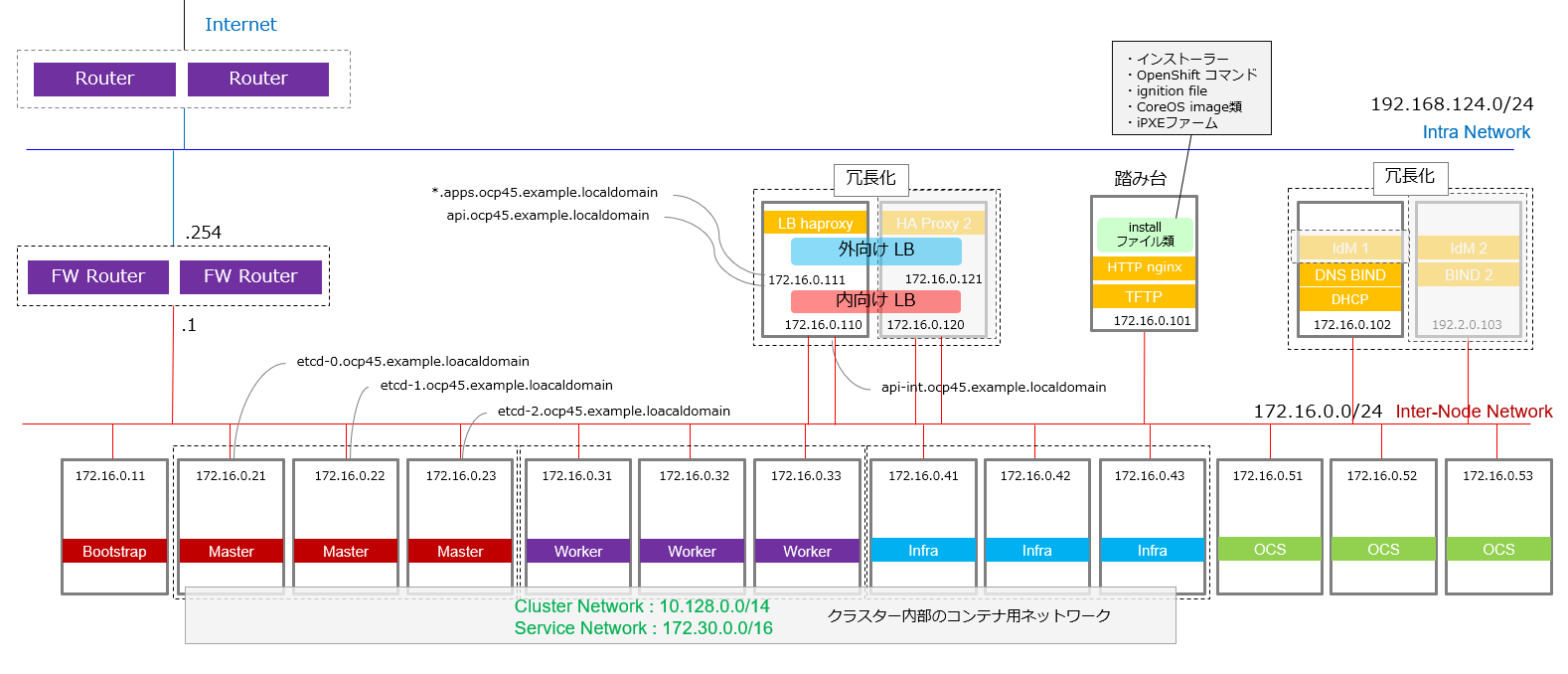
この手順では上記のような構成を構築しています。
手元の実験環境を作るものというよりは、本番環境で最低限必要なコンポーネントを何かを考えて、冗長化が必要なコンポーネントは分割しています。
この手順の制限
DNS(BIND)、LoadBalancer(HA Proxy)は、本番環境であれば冗長化するべき所ですが、手順が冗長になってしまい複雑になってしまうため、この手順の中では、触れていません。
また ID管理のコンポーネントであるIdM は、OpenShiftの動作確認後、後から追加構築できる部分でもあるので、時間的都合もありこの手順書では触れていません(後から追加できれば追加します)。
この構成のメリット・デメリット
この構成のメリットは、実際のフルの運用環境と比べると比較的構成が小さい事です。
一方で、OCPクラスタの中に監視やログ収集のコンポーネントやストレージまでが含まれています。そのため、頻繁に発生するKuberentesのアップデート時において、監視やログ収集がまともに機能しません。
OpenShiftは、クリック一つで全体をバージョンアップできるOTA(Over The Air)アップデートができますが、監視システムもまとめてアップデートされるためアップデート中にいろいろなWarningやエラーが上がっても、状況がつかめませんでした。
もともと物理サーバーの時代より監視サーバーは、監視対象と同じプラットフォームに同居させてはいけないというのは先人の知恵から言われていた事ですが、実際には仮想化が普及しはじめてから、同じ仮想化プラットフォーム上に監視サーバーが載っている例も多かったと思います。
これはvMontionやLive Migrationと言ったハイパーバイザーのアップデート時にコンポーネントを待避させる仕組みや、監視サーバーの分離度が仮想マシンという形で他と大きく分離しているという観点で、現実的に監視が停止する確率がそれほど高くなかったためだと思います。
一方で現状、3ヶ月に一回アップデートが走るKubernetesの世界では、監視は監視対象が乗るプラットフォームと分割するという原則は本番環境では特に守った方が良いと思いました。
が、いずれにしてもこの手順では、リソースの都合で、そこまでの環境を整備する事までは行っておらず、OpenShiftとOpenShiftに含まれているOSS製品の構築方法、分散ストレージであるOCS(OpenShift Container Storage) の構築の作業手順やその雰囲気を届ける事を目的としたいと思います。
1.1.1.Infraノード
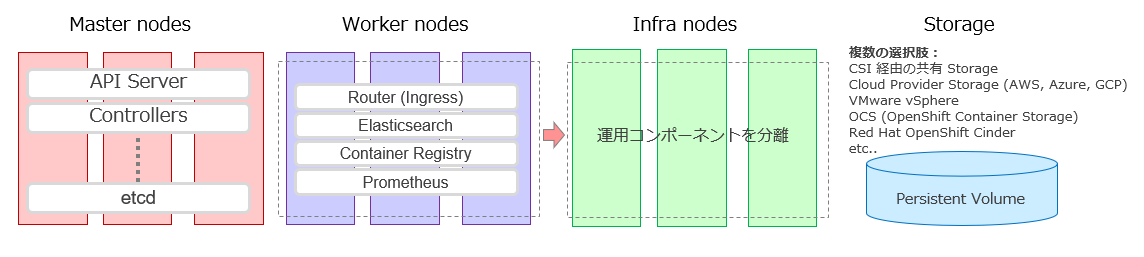
OpenShiftでは、ログ収集用の ElasticSearchや、コンテナを保管するためのContainer Registry、監視用の Prometheusさらに OpenShiftのIngress実装であるRouterと呼ばれるKubernetesを管理するための運用コンポーネントがあります。
こう言った運用コンポーネントは、ユーザーのアプリケーションに影響を与えないようにInfraノードに分離する事にします。
つまり以下のようなイメージです。
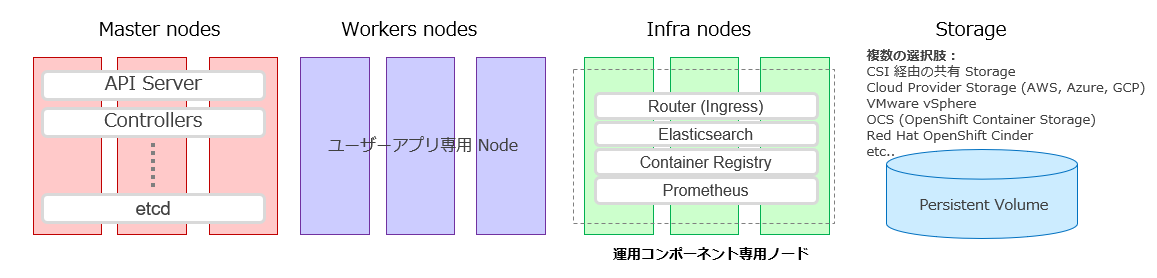
Infraノードは、こういった運用コンポーネントのみを配置する Workerノードを区別するためのOpenShift独自の呼び方ですが、技術的にはWorkerノードと同じものです。
ちなみに、Kubernetes では、Masterのみが正式に定義されているノードのRoleでWorkerノードという言葉はしばしば用いられますが、正式なRoleとしては定義されていません。(KubernetesのWorkerノードのkubectl get node の Role欄は <none>と表示されます)
OpenShift 4.xでは、MasterとWorkerがインストール時にノードのRoleとして事前に定義されており、さらにこの手順では追加でInfraというRoleを定義します。
1.1.2. PV 用の Storage の選択
ユーザーアプリケーションだけでなく、Elasticsearchや、Container Registry を構成するには、PV(Persistent Volume)を必要とします。Prometheusについては、PVがなくてもインストールは可能(OpenShiftをインストールすると自動で一緒にインストールされています)ですが、実際の運用を考えた場合、永続データ保管のためのPVは必要だと思います。
ストレージの選択は、ユーザー環境によって様々だと思います。
この手順では、分散ストレージであるOCS(OpenShift Container Storage)を使用する事にします。
ストレージ部分は、アーキテクチャーとしては疎結合なので、OCSの構築以外の部分の手順については、他のストレージを使用した場合もほぼ共通になります。
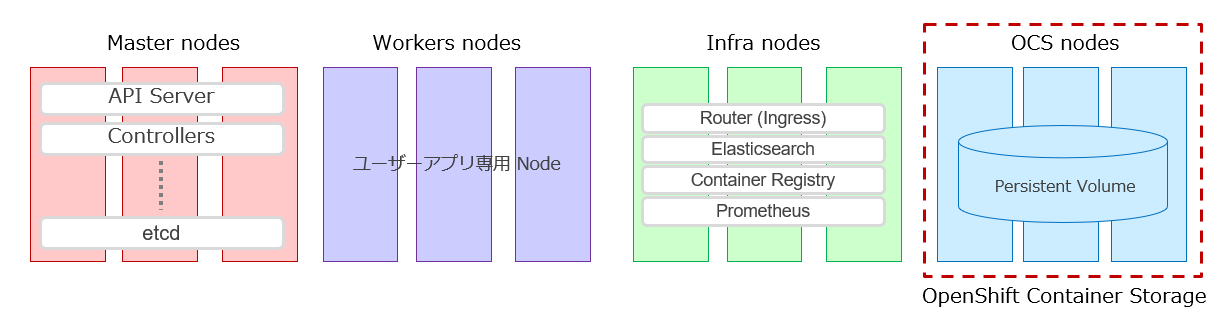
この手順で目指す最終構成は上記なようなものになります。OCS用のノードは3本用意する事にします。
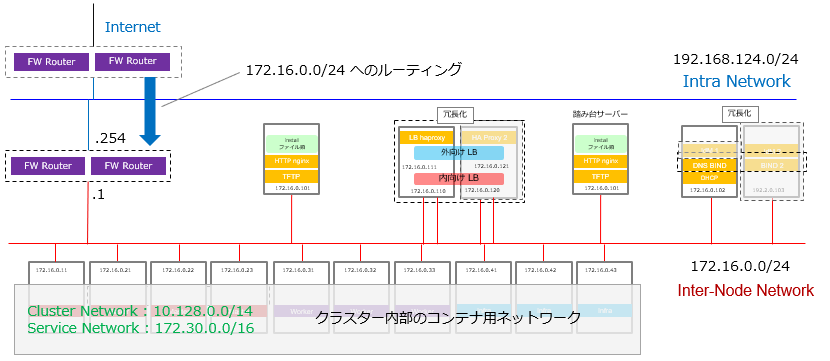
1.1.3. ネットワークの設計
ここでは4つのネットワークを定義しています。
-
Intra Network(社内ネットワーク): 192.168.124.0/24 -
Inter-Node Network(ノード間)ネットワーク:172.16.0.0/24 -
Cluster Network:10.128.0.0/14 -
Service Network:172.30.0.0/16
1)は社内のネットワークの想定です。
2)は Kubernetes のノード間を結ぶためのネットワーク + 外部からのリクエストを受け付ける LBもこのネットワークに所属させました。ネットワーク構成の取り方はいろいろな構成がありうるのですが、ここでは「外向け」ロードバランサーと「内向け」ロードバランサーを一体化して構成サーバーを減らす事に重点を置いて、このような構成を取りました。
3)と4)は OpenShift の内部で使用されている、仮想ネットワークです。3)と4)に関しては、Red Hat社が提供するマニュアルのサンプルで用いられているレンジをそのまま使用しています。マニュアルとの比較のしやすさも考えると、他と衝突していない限りこのまま使用するのをお勧めします。
1.1.4.Firewallの設計
この環境では、Inter-Node Networkと名付けたネットワークに全ての関連コンポーネントをつなぐ事にしたので、OpenShift関連の通信にFirewallが挟まるような構成になっておらず、特にコンポーネント間のFirewallに関する実験はしていません。
一方で、OpenShiftのコンポーネント間の通信で使用するポートについては以下に詳細があります。
1.1.5.IPアドレスのレンジについて
前述の 1)~4)は、どれもプライベートアドレスであるはずなので、グローバルIPと被っていると予期せぬ動作を引き起こす可能性があります。
プライベートIPアドレスとして使用できる範囲はRFC 1918で規定されているので、以下から取得されていて、社内の他のネットワークとも1)~4)で使用するレンジが被ってない事を確認します。
クラスA: 10.0.0.0~10.255.255.255/8
クラスB: 172.16.0.0~172.31.255.255/12
クラスC: 192.168.0.0~192.168.255.255/16
参考 :プライベートネットワーク
1.1.6. ルーティングテーブルの設定
この手順では、クラスターのノード間ネットワーク(Kubernetesの各ノード間をつなぐネットワークをそう名付けます)は、プライベートアドレスレンジである172.16.0.0/24としています。
172.16.0.0/24から、インターネットにアクセスできる必要がありますが、プライベートのアドレスであるため、そのままでは、このネットワークからパケットが外に出る事はできても、社内ネットワークまでは戻ってくる事ができますが、その後の帰り道がわかりません。
そのため、社内ネットワークに戻ってきた際に、172.16.0.0/24のネットワークへのルーティングを教えてあげる必要があります。
ここでは、社内と社外をつなぐ FW Routerで以下のコマンドを実行して、ルーティングを追加しています。
route add -net 172.16.0.0 netmask 255.255.255.0 gw 192.168.124.254 eno1.342
1.1.7.ノードのサイジング
ここでは以下のような CPU/Memory/Diskサイズのノードを使用しました。あくまでこのくらいのスペックがあれば、インストール、OpenShift の基本操作に問題がないように見える。というレベルなので、使用状況によって必要なスペックが違う事については留意して下さい。
1.1.7.1.OpenShift 関連ノードのサイジング
| サーバー | vCPU(HT-on) | Memory | Disk | OS | ホスト名 | IP Address | note |
|---|---|---|---|---|---|---|---|
| BootStrapノード | 4vCPU | 16GByte | 120G | CoreOS | bs.ocp45.example.localdomain | 172.16.0.11 | 一時的 |
| Masterノード | 4vCPU | 16GByte | 120G | CoreOS | m1.ocp45.example.localdomain | 172.16.0.21 | |
| 4vCPU | 16GByte | 120G | CoreOS | m2.ocp45.example.localdomain | 172.16.0.22 | ||
| 4vCPU | 16GByte | 120G | CoreOS | m3.ocp45.example.localdomain | 172.16.0.23 | ||
| Workerノード | 2vCPU | 8GByte | 120G | CoreOS | w1.ocp45.example.localdomain | 172.16.0.31 | |
| 2vCPU | 8GByte | 120G | CoreOS | w2.ocp45.example.localdomain | 172.16.0.32 | ||
| 2vCPU | 8GByte | 120G | CoreOS | w3.ocp45.example.localdomain | 172.16.0.33 | ||
| Infraノード | 4VCPU | 32GByte | 120G | CoreOS | i1.ocp45.example.localdomain | 172.16.0.41 | |
| 4VCPU | 32GByte | 120G | CoreOS | i2.ocp45.example.localdomain | 172.16.0.42 | ||
| 4VCPU | 32GByte | 120G | CoreOS | i3.ocp45.example.localdomain | 172.16.0.43 |
※各ノードのスペックは、OpenShift 4.5 のマニュアルを基準にしています。Minimum resource requirements
BootStrapノード
BootStrapノードは、Masterノードをセットアップするために必要なサーバーで、Masterノードのセットアップが完了した後は必要の無い、一時的なノードです。
BootStrapノードとMasterノードは、CoreOSが必須です。WorkerノードとInfraノードは、RHELもしくはCoreOSが選択できるのですが、この手順ではせっかくなのでコンテナ専用のOSであるCoreOSを使用します。
Masterノード
Masterノードは、3ノード必要です。
Workerノード
Workerノードは、ユーザーのアプリケーション・コンテナが載るノードです。最低2ノードからですが、この手順では3ノード作ります。
OpenShiftとしての最小構成ではMasterノードとWorkerノードを統合して合計で3ノードにする方法もありますが、この手法はEdgeロケーションでHWリソースが潤沢に取れない場合などのユースケースが想定されているため、この手順では採用しませんでした。
Infraノード
Infraノードと言う言葉は、OpenShift 独自の呼び方で、実体はWorkerノード です。Kubernetesの運用管理コンポーネントを、ユーザーアプリと分離したノード導入するために用意するノードです。
Infraノードには、Elastic Searchや、Kibana、Prometheus等のコンポーネントが導入されます。これらのコンポーネントは大量にリソースを消費しやすいため、ユーザーアプリが使用するノードとは分けて導入する事がベストプラクティスです。
1.1.7.2.周辺インフラ・サーバーのサイジング
| サーバー | vCPU(HT-on) | Memory | Disk | OS | ホスト名 | IP Address | note |
|---|---|---|---|---|---|---|---|
| 踏み台(bastion) | 2vCPU | 4GByte | 60G | RHEL 8.2 | bastion.example.localdomain | 172.16.0.101 | |
| DNS / DHCP | 2vCPU | 4GByte | 60G | RHEL 8.2 | ns1.example.localdomain | 172.16.0.102 | |
| 2vCPU | 4GByte | 60G | RHEL 8.2 | ns2.example.localdomain | 172.16.0.103 | 冗長用 | |
| LoadBalancer | 2vCPU | 4GByte | 60G | RHEL 8.2 | lb1.example.localdomain | 172.16.0.110/111 | |
| 2vCPU | 4GByte | 60G | RHEL 8.2 | lb2.example.localdomain | 172.16.0.120/121 | 冗長用 |
Kubernetes には含まれていませんが、Kubernetesを動かすために必要なサーバー群です。
踏み台(bastion)
OpenShiftインストール時に作業の起点となるサーバーです。kubectl、ocコマンドなどの実行場所です。
この例では、ノードに対するインストール・イメージなどの配布用にTFTPサーバーや、HTTPサーバー(nginx) も導入します。
可用性は必要無いので、冗長化は行っていません。
Load Balancer
この例では、ノード間の負荷分散装置のめに、Load Balancerとして、HA Proxyを使用しています。
クラスター内部のノード間通信の負荷分散用と、クラスター外部から来るアクセスの負荷分散の2種類のLoad Balancerが必要になります。
ここでは、内部用の Load Balancerと外部用の Load Balancerで一つのサーバーに別々のIPをアサインする設計にしています。
設計として冗長構成にするために、2本のLoad Balancerを用意していますが、構築手順としてはこの手順の中では触れていません。
DNS/DHCP
この手順ではInter-Nodeネットワークに所属するサーバーの名前解決のためのDNSサーバーとしてBINDを使用しています。
DHCPサーバーは、Masterノード、Workerノード、Infraノードに対して、DNSサーバーや、gatewayのIPアドレスを教えるため等に使われます。
DHCPサーバーは使用しますが、UPIインストールでは、これらのノード間の負荷分散を行うために、各ノードのIPアドレス、もしくは名前を事前にLoad Balancerに登録して置く必要があります。
そのため、DHCPで自由にIPアドレスを割り当てるのではなく、各ノードの MACアドレスを使用して、固定IPアドレスを割り振っています。
設計として冗長構成にするために、2本のDNS/HDCPサーバーを用意していますが、構築手順としてはこの手順の中では触れていません。
またDHCPサーバーは、ノードのセットアップ時にのみ使用されるため、大半の要件であれば、冗長化の必要は無いでしょう。
1.1.7.3. OpenShiftのDNS要件
以下の6つのドメイン名がOpenShiftととして必要になります。
| ドメイン名 | この手順の名前 | 用途 |
|---|---|---|
| api.<cluster_name>.<base_domain>. | api.ocp45.example.localdomain. | Kubernetes API |
| api-int.<cluster_name>.<base_domain>. | api-int.ocp45.example.localdomain. | Kubernetes API |
| *.app.<cluster_name>.<base_domain>. | *.ocp45.example.localdomain. | Routes |
この手順書では、
<cluster_name> = ocp45
<base_domain>= example.localdomain
としました。これらの値は、後でDNSに登録していきます。
また、この値は、インストール用の yamlのマニフェストファイルを作成する時にもう一度使うので覚えておきます。
ここまでで、環境の基本設計は出そろったので、図にまとめると以下のようになります(再掲)。
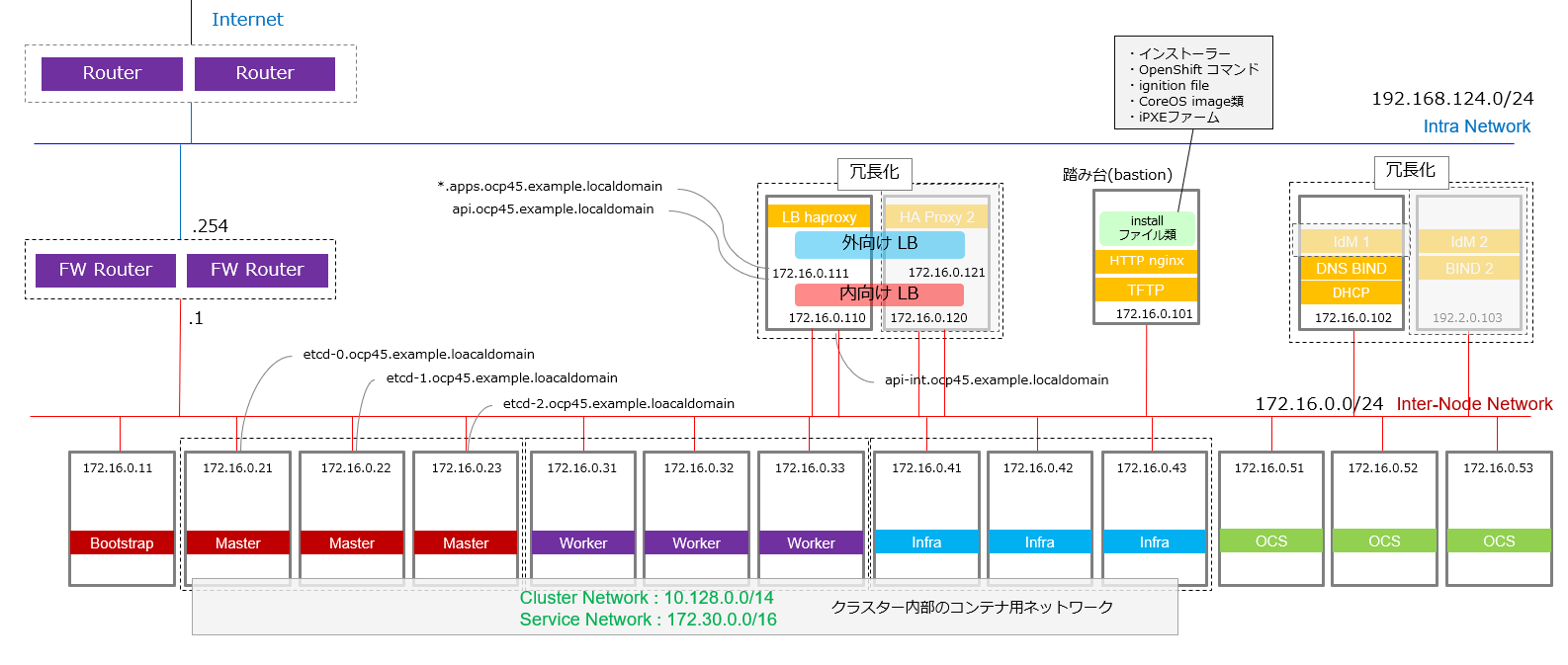
薄い灰色になっているHA ProxyとDNS BINDの冗長化構成の部分は、この手順では取り扱っていません。
1.2.必要なドメインをセットアップする
1.2.1 BIND サーバーをセットアップする
以下の手順を参考にして BIND サーバーをセットアップします。
RHEL8 上に BIND を構築する - Qiita
1.2.2.DNSサーバーの構成ファイルのカスタマイズ
/etc/named.conf、/etc/named/named.example.localdomain.zone、/etc/named/0.16.172.in-addr.arpa.zone を作成します。
IP逆引きの設定も必要です。
BIND設定ファイル(named.conf)
<前半は特に変更していないので省略>
logging {
channel default_debug {
file "data/named.run";
severity dynamic;
};
};
zone "." IN {
type hint;
file "named.ca";
};
include "/etc/named.rfc1912.zones";
include "/etc/named.root.key";
<順引き用の設定ファイルを参照>
zone "example.localdomain" {
type master;
file "/etc/named/named.example.localdomain.zone";
};
<逆引き用の設定ファイルを参照>
zone "0.16.172.in-addr.arpa" in {
type master;
file "/etc/named/0.16.172.in-addr.arpa.zone";
};
順引き用の設定ファイル
$ORIGIN example.localdomain.
$TTL 3600
@ IN SOA ns1.example.localdomain. root.example.localdomain.(
2000091802 ; Serial
3600 ; Refresh
900 ; Retry
3600000 ; Expire
3600 ) ; Minimum
IN NS ns1.example.localdomain.
bs.ocp45.example.localdomain. IN A 172.16.0.11
m1.ocp45.example.localdomain. IN A 172.16.0.21
m2.ocp45.example.localdomain. IN A 172.16.0.22
m3.ocp45.example.localdomain. IN A 172.16.0.23
w1.ocp45.example.localdomain. IN A 172.16.0.31
w2.ocp45.example.localdomain. IN A 172.16.0.32
w3.ocp45.example.localdomain. IN A 172.16.0.33
api-int.ocp45.example.localdomain. IN A 172.16.0.110
api.ocp45.example.localdomain. IN A 172.16.0.111
*.apps.ocp45.example.localdomain. IN A 172.16.0.111
逆引き用の設定ファイル
$TTL 3600
@ IN SOA ns1.example.local. root.example.local.(
2000091803 ; Serial
3600 ; Refresh
900 ; Retry
3600000 ; Expire
3600 ) ; Minimum
IN NS ns1.example.local.
;
11 IN PTR bs.ocp45.example.localdomain.
21 IN PTR m1.ocp45.example.localdomain.
22 IN PTR m2.ocp45.example.localdomain.
23 IN PTR m3.ocp45.example.localdomain.
31 IN PTR w1.ocp45.example.localdomain.
32 IN PTR w2.ocp45.example.localdomain.
33 IN PTR w3.ocp45.example.localdomain.
設定ファイルを作成したら、リロードして有効化させます。
named-checkconf -z /etc/named.conf # named.conf の書式確認 (書いた設定ファイルにエラーが無いか確認するコマンド)
systemctl reload named # 設定のリロード
1.3.Load Balancerをセットアップする
この手順では、Load Balancer として HA Proxyを使用します。
1.3.1.HA Proxyをセットアップする
以下の手順を参考にして HA Proxy をセットアップします。
RHEL 8 HA Proxy の設定方法
1.3.2.構成ファイルを編集する
一般的なセットアップが完了したら、構成ファイルを以下のように書き替えます。
# ---------------------------------------------------------------------
# Example configuration for a possible web application. See the
# full configuration options online.
#
# https://www.haproxy.org/download/1.8/doc/configuration.txt
#
# ---------------------------------------------------------------------
# ---------------------------------------------------------------------
# Global settings
# ---------------------------------------------------------------------
global
# to have these messages end up in /var/log/haproxy.log you will
# need to:
#
# 1) configure syslog to accept network log events. This is done
# by adding the '-r' option to the SYSLOGD_OPTIONS in
# /etc/sysconfig/syslog
#
# 2) configure local2 events to go to the /var/log/haproxy.log
# file. A line like the following can be added to
# /etc/sysconfig/syslog
#
# localdomain2.* /var/log/haproxy.log
#
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
# utilize system-wide crypto-policies
ssl-default-bind-ciphers PROFILE=SYSTEM
ssl-default-server-ciphers PROFILE=SYSTEM
# ---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
# ---------------------------------------------------------------------
defaults
# mode http
mode tcp
log global
# option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
# ---------------------------------------------------------------------
# main frontend which proxys to the backends
# ---------------------------------------------------------------------
# 以下はコメントアウト
# frontend main
# bind *:5000
# acl url_static path_beg -i /static /images /javascript /stylesheets
# acl url_static path_end -i .jpg .gif .png .css .js
# use_backend static if url_static
# default_backend app
frontend kubeapi
default_backend kube_api
mode tcp
bind *:6443
frontend machineconfig
default_backend machine_config
mode tcp
bind *:22623
frontend workerhttp
default_backend worker_http
mode tcp
bind *:80
frontend workerhttps
default_backend worker_https
mode tcp
bind *:443
# ---------------------------------------------------------------------
# static backend for serving up images, stylesheets and such
# ---------------------------------------------------------------------
# backend static
# balance roundrobin
# server static 127.0.0.1:4331 check
# ---------------------------------------------------------------------
# round robin balancing between the various backends
# ---------------------------------------------------------------------
# 以下はコメントアウト (SELinux に怒られる)
# backend app
# balance roundrobin
# server app1 127.0.0.1:5001 check
# server app2 127.0.0.1:5002 check
# server app3 127.0.0.1:5003 check
# server app4 127.0.0.1:5004 check
# internal domains is ocp45.example.localdomain
backend kube_api
mode tcp
balance roundrobin
option ssl-hello-chk
server bs bs.ocp45.example.localdomain:6443 check
server m1 m1.ocp45.example.localdomain:6443 check
server m2 m2.ocp45.example.localdomain:6443 check
server m3 m3.ocp45.example.localdomain:6443 check
backend machine_config
mode tcp
balance roundrobin
server bs bs.ocp45.example.localdomain:22623 check
server m1 m1.ocp45.example.localdomain:22623 check
server m2 m2.ocp45.example.localdomain:22623 check
server m3 m3.ocp45.example.localdomain:22623 check
backend worker_http
mode tcp
balance source
server w1 w1.ocp45.example.localdomain:80 check
server w2 w2.ocp45.example.localdomain:80 check
server w3 w3.ocp45.example.localdomain:80 check
backend worker_https
mode tcp
balance source
server w1 w1.ocp45.example.localdomain:443 check
server w2 w2.ocp45.example.localdomain:443 check
server w3 w3.ocp45.example.localdomain:443 check
balanceをroundrobinとsourceで分けていますが、はっきりとした意図はありません。使用しながらチューニングする必要があるかどうか見ていこうと思っています。
ここで行った設定を図に起こすと以下のようになります。
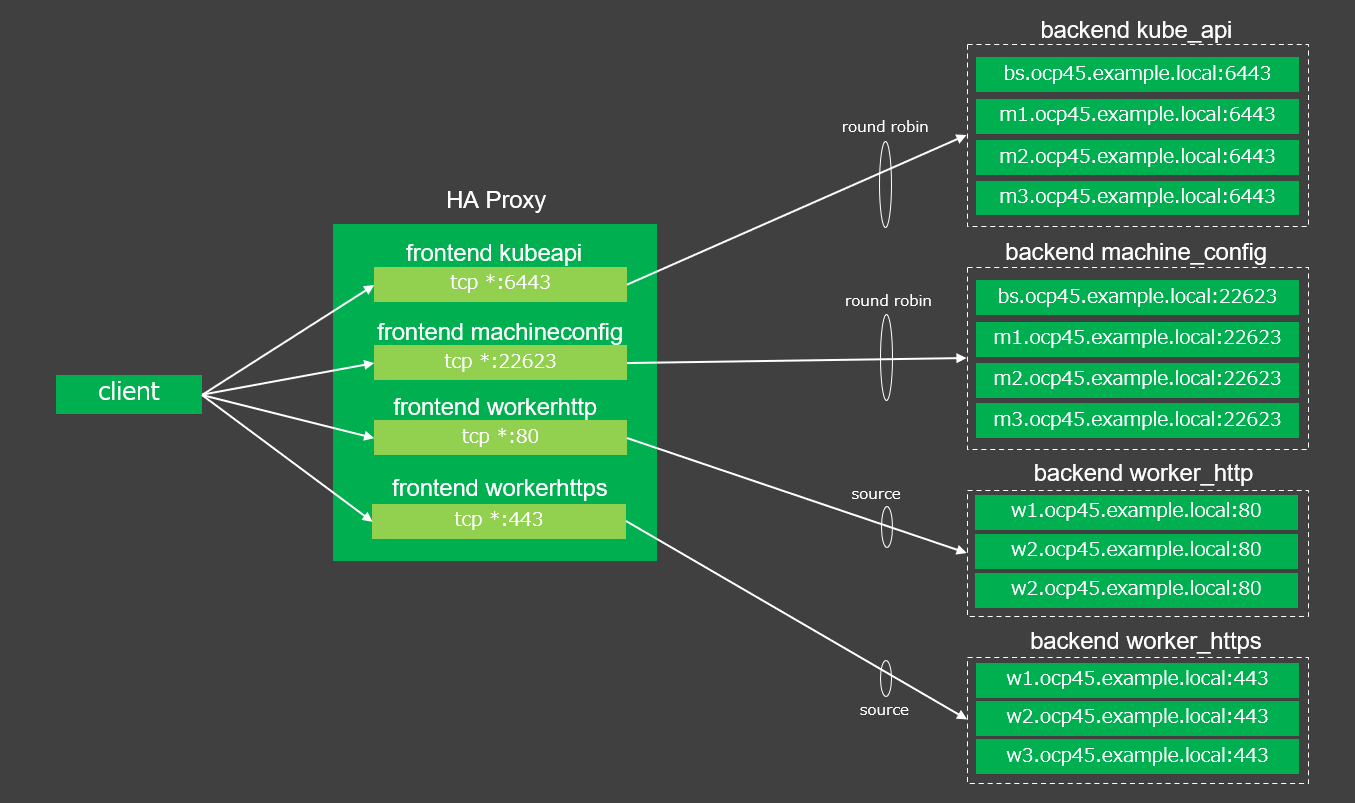
図中のclientは、OpenShiftクラスター内部のノードの場合もありますし、クラスター外部からのアクセスである場合もあります。
また、あくまでこれは初期構成で、インストールが進むにつれて構成を変更していきます。例えば、boostrap Node は、途中で要らなくなるので取り外します。
1.3.3.firewalld の設定
http(80)/https(443)/api-server(6443)を通すように設定します。これらはデフォルトで「サービス」として事前定義されています。
この環境でNICは、publicゾーンに所属しているので、pbulicゾーンに穴開けを行います。
firewall-cmd --add-service=https --zone=public --permanent
firewall-cmd --add-service=http --zone=public --permanent
firewall-cmd --add-service=kube-apiserver --zone=public --permanent
22623 tcp も開ける必用がありますが、これについては事前定義されていないため新規に定義します。
ここでは、「machine-config」という22623 /tcp を使う新しいサービスを作成してみます。
新しいサービス名の追加します。
firewall-cmd --permanent --new-service machine-config
「サービス」「machine-config」の説明を追加します。
firewall-cmd --permanent --service=machine-config --set-description="OpenShift machine config access"
新しい「サービス」「machine-config」のポート定義を追加します。
firewall-cmd --service=machine-config --add-port=22623/tcp --permanent
作成された新しい「サービス」のファイルを読み込みます。
firewall-cmd --reload
作成した「サービス」を firewalld を透過させる「サービス」として、ここではpublicゾーンに追加します。
firewall-cmd --add-service=machine-config --zone=public
1.3.4.SELinuxの設定
デフォルトでは、KubernetesのAPIアクセスに使用するポートへの haproxyのアクセスが許可されていません。そのため、systemctlでHA Proxyを起動しようとすると以下のようなエラーがでるはずです。
$ systemctl restart haproxy.service
Job for haproxy.service failed because the control process exited with error code.
See "systemctl status haproxy.service" and "journalctl -xe" for details.
$
以下のコマンドを実行する事で、行うべき SELinuxの設定を提案してくれます。ここでは、my-haproxyというファイル名に設定内容の提案を出力します。
$ ausearch -c 'haproxy' --raw | audit2allow -M my-haproxy
******************** IMPORTANT ***********************
To make this policy package active, execute:
semodule -i my-haproxy.pp
$ ls -ltr
-rw-r--r--. 1 root root 308 Oct 8 11:12 my-haproxy.te
-rw-r--r--. 1 root root 969 Oct 8 11:12 my-haproxy.pp
$
引き続き、次のコマンドを実行る事で、提案された SELinux の設定が適用されます。
semodule -i my-haproxy.pp
これで HA Proxy が起動するようになっているはずです。
1.4.踏み台サーバーをセットアップする
OpenShiftクラスターのインストール作業をするための踏み台サーバーを作成します。
特に構成に決まりは無いのですが、この例では、この踏み台サーバーには、OpenShiftクラスターのセットアップ時だけ動いていれば良いコンポーネントをインストールします。
例えば、インストールプログラムはもちろん、導入イメージや、導入イメージ配布用の HTTPサーバー、TFTPサーバーなどをインストールします。インストールプログラムを実行する起点ともなります。導入イメージとは言っても、ここで配置する以外にもインターネット上のContainer Registryにも導入コンテナのイメージを取得しに行くので、インターネットアクセスは必要になります。
踏み台サーバーは、インストール時しか使用しないため、ノートPC等でも代用もできますが、セットアップ後もノードの追加などにも使用するサーバーとなるので、実際の運用では恒久的に必要なサーバーになると思います。
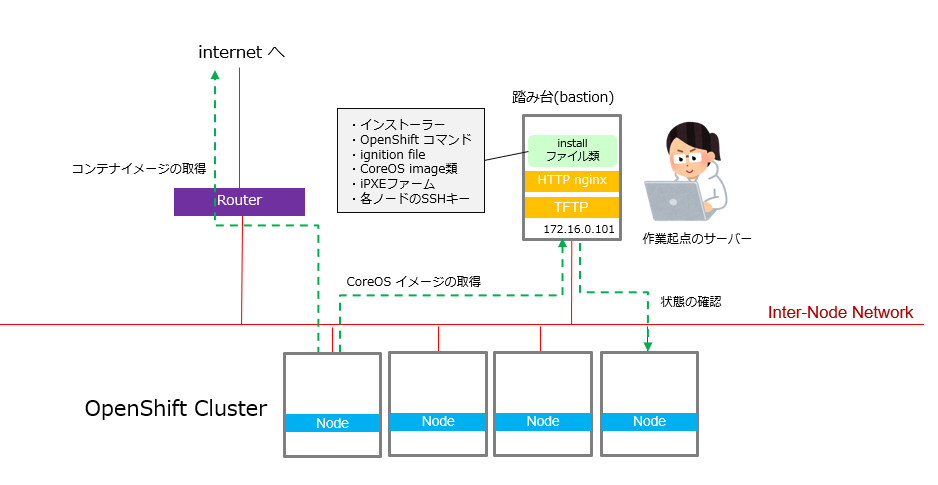
OpenShiftのノードに直接SSHしてアクセスできるサーバーにもなりますので、セキュリティ的にもしっかりとした対処が必要です。
インストール時だけでなく、運用時にも作業起点のサーバーになるのが、この踏み台サーバーです。
SSH Key の作成
踏み台サーバー上で、SSH Keyのペアを作成します。
Privateキーは、踏み台サーバーに保管され、Publicキーは後でインストールプログラムに渡す事で、各ノードにインストールされます。
どのディレクトリで作業しても良いのですが、手順のわかりやすさを考慮して
/root/openshift
ディレクトリを作成して、そこで作業する事にします。
$ mkdir /root/openshift # 作業ディレクトリを作成
$ cd /root/openshift # 作業ディレクトリに移動
sshのkeyペアを作成します。
ここで作成された公開鍵は、後で、BootStrapノード、Masterノード、Workerノード のCoreOSインストール時に、CorOS側に登録されます。
[root@bastion openshift]# ssh-keygen -t rsa -b 4096 -N ''
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa): # 鍵はデフォルトでは root の Homeディレクトリの .ssh 配下に作成される
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:hjrslmiGF7Et3Eua44VH9yEZPitlPQK0vp1ik9qIB4E root@bastion
The key's randomart image is:
+---[RSA 4096]----+
| . |
| . . |
|. o . |
|E .. o = |
| o =o @ S |
|. =++O O o |
| o.B&o+ . |
|..XO+= |
|.*+oo |
+----[SHA256]-----+
[root@bastion openshift]#
鍵は rootのHomeディレクトリの.ssh配下に生成されています。
/root/.ssh/id_rsa # 秘密鍵
/root/.ssh/id_rsa.pub # 公開鍵
作成したkeyペアは、後でインストールするCoreOSノードにログインできる鍵になります。
2. iPXE 環境の作成
iPXEというネットワークブートの方法を使用して、Bootstrap / Master / Worker ノードの RHEL CoreOS をインストールしていきます。
(この手順は、ネットワーク経由CoreOSをインストールする方法です。ISOイメージによる CoreOS インストールを選択した場合は、この手順は必要ありません)
当初はISOイメージによるインストールを行おうとしていたのですが、リモートワークの環境では何故かブート時のコンソールが上手く操作できない。と言う環境上の問題に出くわして、iPXEでの環境構築を行う事になりました。構築はそれなりに手間なので、本番環境で幾つもクラスターを継続的に作成していく需要がなければおすすめしません。
当初は想定していなかったのですが、この後、環境を破壊して、全てのノードを作り直さなければいけなくなる事が何度もありました。その時に、iPXEによるネットワークインストールにより、かなり時間を節約する事ができました。
実運用を考えるとiPXE等によるネットワークブートでOSをインストールする環境を作成しておく事をおすすめします。
2.1.必要なサーバーのインストール
以下を参考にして環境を構築します。
リンク先の汎用的な iPXE環境のサーバー構成は、この手順で想定しているサーバー構成と同じです。
2.2.DHCPサーバーを使った固定IPアドレスの割り振り
汎用的な手順でiPXE環境を構築した後、OpenShiftクラスターをインストールするためのカスタマイズを施します。
UPIインストールでは、事前にロードバランサーに BootStratp / Master / Workerノードを登録しておく必要があるため、それぞれの固定のIPが必要になります。
/etc/dhcp/dhcpd.conf を編集して、ノードの MACアドレスを基準して固定IPを割り振る設定をします。
どの部分を追加したかは設定ファイルの中にコメントで区切っています。
<省略>
# PXE Boot - start
class "pxeclients" {
match if substring (option vendor-class-identifier, 0, 9) = "PXEClient";
next-server 172.16.0.101; # TFTP Server address
if option arch = 00:07 { # x86-64
# Chain loading.
# 1st time, tell iPXE image place as boot file on TFTP server.
# 2nd time, tell iPXE script place on HTTP server.
if exists user-class and option user-class = "iPXE" { # the 2nd time. Go to HTTP Server to get iPXE script
filename "http://172.16.0.101/pxeboot.ipxe";
} else { # the 1st time. Go to TFTP to get iPXE.
filename "efi/ipxe.efi";
# filename "undionly.kpxe";
}
} else {
# filename "pxelinux/pxelinux.0";
filename "pxelinux.cfg/default";
# filename "menu/boot.ipxe";
}
}
# PXE Boot - end
# ここから MACアドレスに対して固定 IPを割り振る設定
host bs{
hardware ethernet 00:50:56:96:11:c2;
fixed-address 172.16.0.11;
}
host m1{
hardware ethernet 00:50:56:96:37:c8;
fixed-address 172.16.0.21;
}
host m2{
hardware ethernet 00:50:56:96:ec:a7;
fixed-address 172.16.0.22;
}
host m3{
hardware ethernet 00:50:56:96:e5:2f;
fixed-address 172.16.0.23;
}
host w1{
hardware ethernet 00:50:56:96:6b:da;
fixed-address 172.16.0.31;
}
host w2{
hardware ethernet 00:50:56:96:c1:c5;
fixed-address 172.16.0.32;
}
host w3{
hardware ethernet 00:50:56:96:e3:f5;
fixed-address 172.16.0.33;
}
}
MACアドレスは、実際にCoreOSのインストール対象のサーバーのNICのMACアドレスを確認し、実際の環境にあわせて書き替えて下さい。
2.3.CoreOSのインストールイメージを入手する
iPXEブートで使用するCoreOSのファイルを手に入れます。
以下より
https://mirror.openshift.com/pub/openshift-v4/dependencies/rhcos/4.5/
1)compressed metal RAW image
2)knernel
3)initramfs
をダウンロードします。
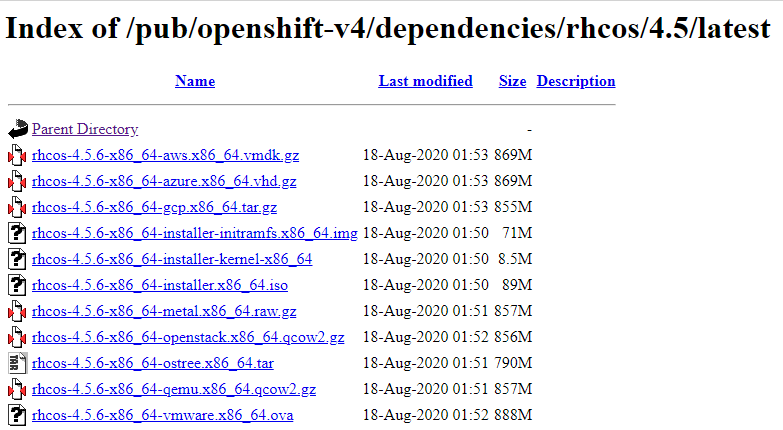
似たような名前のファイルが幾つかありますが、以下のフォーマットで名前が付いているものをダウンロードします。
Compressed metal RAW image: rhcos-<version>metal.<architecture>.raw.gz
kernel: rhcos-<version>-installer-kernel-<architecture>
initramfs: rhcos-<version>-installer-initramfs.<architecture>.img
ここでは、以下のファイルをダウンロードします。
rhcos-4.5.6-x86_64-installer-initramfs.x86_64.img
rhcos-4.5.6-x86_64-installer-kernel-x86_64
rhcos-4.5.6-x86_64-metal.x86_64.raw.gz
※ISOファイルであるrhcos-<version>-installer.<architecture>.isoは、ISOブートで CoreOSをインストールする時に使用します。この手順(iPXEブート)では使用しません。
2.2.1.ダウンロードしたファイルを HTTP サーバー(踏み台サーバー)にコピーする
これらのファイルも HTTP サーバー(踏み台サーバーに同じ) のディレクトリに配置します。ここでは nginx のルート(/usr/share/nginx/html)ディレクトリに配置しています。
cp * /usr/share/nginx/html
2.2.2.ファイルのアクセスを確認する。
HTTP サーバー上のファイルがアクセスできるか確認します。
以下のコマンドで HTTP 200 が返ってくれば OK です。
[root@bastion ~]# curl -D - -s -o /dev/null http://bastion.example.localdomain/rhcos-4.5.6-x86_64-installer-initramfs.x86_64.img
[root@bastion ~]# curl -D - -s -o /dev/null http://bastion.example.localdomain/rhcos-4.5.6-x86_64-installer-kernel-x86_64
[root@bastion ~]# curl -D - -s -o /dev/null http://bastion.example.localdomain/rhcos-4.5.6-x86_64-metal.x86_64.raw.gz
bastion.example.localdomainは、この環境でのHTTP サーバー(=踏み台サーバー)のホスト名です。
2.4.iPXEスクリプトの作成
iPXEインストール時の作業を記したiPXEスクリプトを作成します。内容はiPXE ブート環境をセットアップするのサンプルと同じものです。
/usr/share/nginx/html/pxeboot.ipxe
# !ipxe
# dhcp
# Some menu defaults
set menu-timeout 300000
isset ${menu-default} || set menu-default exit
:start
menu Please choose an type of node you want to install
item --gap -- -------------------------- node type -------------------------
item --key b bootstrap Install Bootstrap Node
item --key m master Install Master Node
item --key w worker Install Worker Node
item --gap -- -------------------------- Advanced Option --------------------
item --key c config Configure settings
item shell Drop to iPXE shell
item reboot Reboot Computer
choose --timeout ${menu-timeout} --default ${menu-default} selected || goto cancel
goto ${selected}
:bootstrap # ここはインストールしたい OS毎に異なる
kernel http://172.16.0.101/rhcos-4.5.6-x86_64-installer-kernel-x86_64 ip=dhcp rd.neednet=1 initrd=rhcos-4.5.6-x86_64-installer-initramfs.x86_64.img console=tty0 console=ttyS0 coreos.inst=yes coreos.inst.install_dev=sda coreos.inst.image_url=http://172.16.0.101/rhcos-4.5.6-x86_64-metal.x86_64.raw.gz coreos.inst.ignition_url=http://172.16.0.101/bootstrap.ign
initrd http://172.16.0.101/rhcos-4.5.6-x86_64-installer-initramfs.x86_64.img
boot
:master # ここはインストールしたい OS毎に異なる
kernel http://172.16.0.101/rhcos-4.5.6-x86_64-installer-kernel-x86_64 ip=dhcp rd.neednet=1 initrd=rhcos-4.5.6-x86_64-installer-initramfs.x86_64.img console=tty0 console=ttyS0 coreos.inst=yes coreos.inst.install_dev=sda coreos.inst.image_url=http://172.16.0.101/rhcos-4.5.6-x86_64-metal.x86_64.raw.gz coreos.inst.ignition_url=http://172.16.0.101/master.ign
initrd http://172.16.0.101/rhcos-4.5.6-x86_64-installer-initramfs.x86_64.img
boot
:worker # ここはインストールしたい OS毎に異なる
kernel http://172.16.0.101/rhcos-4.5.6-x86_64-installer-kernel-x86_64 ip=dhcp rd.neednet=1 initrd=rhcos-4.5.6-x86_64-installer-initramfs.x86_64.img console=tty0 console=ttyS0 coreos.inst=yes coreos.inst.install_dev=sda coreos.inst.image_url=http://172.16.0.101/rhcos-4.5.6-x86_64-metal.x86_64.raw.gz coreos.inst.ignition_url=http://172.16.0.101/worker.ign
initrd http://172.16.0.101/rhcos-4.5.6-x86_64-installer-initramfs.x86_64.img
boot
:exit
exit
:cancel
echo You cancelled the menu, dropping you to a shell
:shell
echo Type 'exit' to get the back to the menu
shell
set menu-timeout 0
goto start
:reboot
reboot
:exit
exit
最終的な上記のようなスクリプトを作成すれば良いのですが、各ラベル毎の解説をします。
2.4.1.BootStrap用の記述
:bootstrap
kernel http://172.16.0.101/rhcos-4.5.6-x86_64-installer-kernel-x86_64 ip=dhcp rd.neednet=1 initrd=rhcos-4.5.6-x86_64-installer-initramfs.x86_64.img console=tty0 console=ttyS0 coreos.inst=yes coreos.inst.install_dev=sda coreos.inst.image_url=http://172.16.0.101/rhcos-4.5.6-x86_64-metal.x86_64.raw.gz coreos.inst.ignition_url=http://172.16.0.101/bootstrap.ign
initrd http://172.16.0.101/rhcos-4.5.6-x86_64-installer-initramfs.x86_64.img
boot
この例で172.16.0.101は、踏み台サーバー(HTTPサーバー/TFTPサーバーが同居)のIPアドレスです。
rhcos-4.5.6-x86_64-installer-kernel-x86_64
rhcos-4.5.6-x86_64-metal.x86_64.raw.gz
rhcos-4.5.6-x86_64-installer-initramfs.x86_64.img
は、/usr/share/nginx/html(Nginxのルート) に配置されたCoreOS関連のファイル名ですが、実際にダウンロードしてきたファイル名に合わせます。
bootstrap.ignは、後の手順で作成し、/usr/share/nginx/htmlに配置します。
※2020/10/06時点でOCP4.5のマニュアルに記載されている iPXE用のスクリプトのサンプルの記述に誤記があり、そのままでは動作しないのでご注意下さい。Bug 1741922 - [DOCS] Failed to open file error during iPXE install
2.4.2.Master用の記述
:master
kernel http://172.16.0.101/rhcos-4.5.6-x86_64-installer-kernel-x86_64 ip=dhcp rd.neednet=1 initrd=rhcos-4.5.6-x86_64-installer-initramfs.x86_64.img console=tty0 console=ttyS0 coreos.inst=yes coreos.inst.install_dev=sda coreos.inst.image_url=http://172.16.0.101/rhcos-4.5.6-x86_64-metal.x86_64.raw.gz coreos.inst.ignition_url=http://172.16.0.101/master.ign
initrd http://172.16.0.101/rhcos-4.5.6-x86_64-installer-initramfs.x86_64.img
boot
基本的に :boostratpのラベル部分の記述と同じですが、Master 用の ignition ファイルmaster.ignを参照している部分が違います。
master.ignは、後の手順で作成し、/usr/share/nginx/htmlに配置します。
2.4.3.Worker用の記述
:worker
kernel http://172.16.0.101/rhcos-4.5.6-x86_64-installer-kernel-x86_64 ip=dhcp rd.neednet=1 initrd=rhcos-4.5.6-x86_64-installer-initramfs.x86_64.img console=tty0 console=ttyS0 coreos.inst=yes coreos.inst.install_dev=sda coreos.inst.image_url=http://172.16.0.101/rhcos-4.5.6-x86_64-metal.x86_64.raw.gz coreos.inst.ignition_url=http://172.16.0.101/worker.ign
initrd http://172.16.0.101/rhcos-4.5.6-x86_64-installer-initramfs.x86_64.img
boot
基本的に :boostratp、:masterのラベル部分の記述と同じですが、Worker 用の ignition ファイルworker.ignを参照している部分が違います。
worker.ignは、後の手順で作成し、/usr/share/nginx/htmlに配置します。
3.OpenShift の CLIコマンドとインストーラーを手に入れる
インストール・プログラムを配布しているcloud.redhat.comにアクセスします。(Red Hat のアカウントが必要です)
ここでは、ベアメタル(「Run on Bare Metal」のアイコン)を選びます。
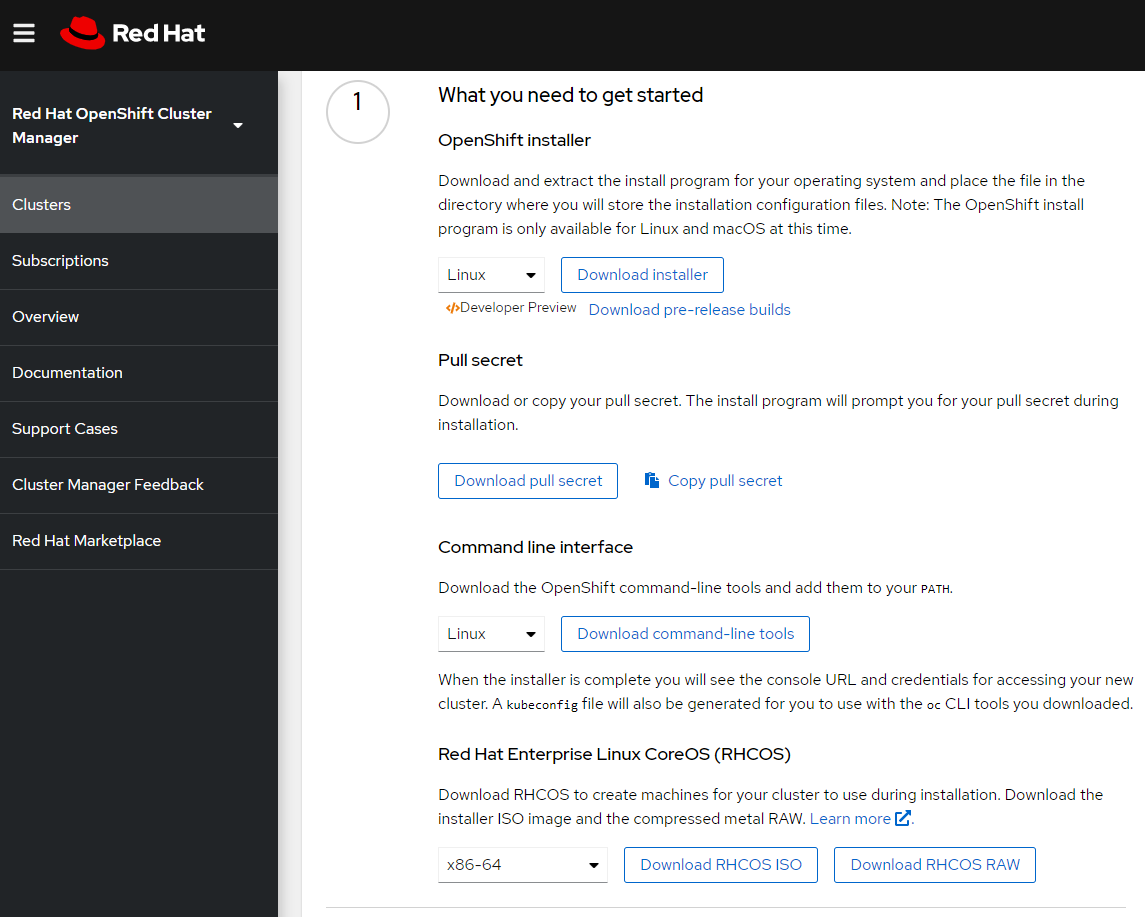
①にリストされている以下のものを、踏み台サーバー上にダウンロードします。合計で3つのファイルがあります。
- OpenShift installer (ここでは Linux を選択)
- Pull Secret
- Command line interface (ここでは Linux を選択)
以下もダウンロードできるようになっていますが、既にセクション「2.3.CoreOsのインストールイメージを入手する」でダウンロードしているので必要ありません。
- ISOイメージ / RAW イメージ
ファイルは、セクション「1.4.踏み台サーバーをセットアップする」で作成した /root/openshiftにダウンロードする事にします。
ダウロードしたものを解凍、必要無くなったtar.gzを削除すると以下のように見えるはずです。
$pwd
/root/openshift/
$ ls -ltr
total 604284
-rwxr-xr-x. 2 root root 78595112 Jul 28 12:00 oc # OpenShift の CLI コマンド
-rwxr-xr-x. 2 root root 78595112 Jul 28 12:00 kubectl
-rwxr-xr-x. 1 root root 368259072 Jul 28 12:13 openshift-install # OpenShift のインストーラーコマンド
-rw-r--r--. 1 root root 706 Jul 28 12:13 README.md
-rw-r--r--. 1 root root 2723 Aug 16 00:54 pull-secret.txt
oc コマンドと kubectl コマンドがパス無しで実行できるように PATH 変数に展開場所を追加しておきます。
$ export=$PATH:/root/openshift/ # <ocコマンドとkubectlのファイルの場所>
$ oc version # PATHが通って oc コマンドが実行できる事を念のため確認
Client Version: 4.5.5
$
4.installに必要な設定ファイルを作成する
この作業は、踏み台サーバー上での作業です。ステップが多いですが、作業の流れは以下のようになります。
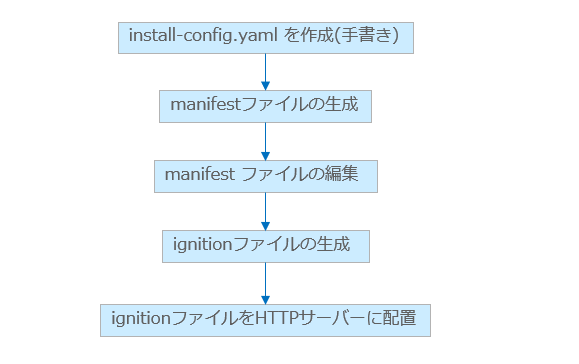
最終的に生成されるignitionファイルは、CoreOSの構成用のファイルで、インストール時に使用されます。
4.1.installation configuration file (YAML) を作成する
セクション「1.4.踏み台サーバーをセットアップする」 で作成した踏み台サーバー上の作業ディレクトリに移動します。
$ cd /root/openshift # 作業ディレクトリに移動
以下のような isntall-config.yaml と言うファイルを作成します。
[root@bastion openshift]# vi install-config.yaml
# 以下のようなファイルを作成します。
apiVersion: v1
baseDomain: example.localdomain (1)
compute:
- hyperthreading: Enabled (2)(3)
name: worker
replicas: 0 (4)
controlPlane:
hyperthreading: Enabled (2)(3)
name: master
replicas: 3 (5)
metadata:
name: ocp45 (6)
networking:
clusterNetwork:
- cidr: 10.128.0.0/14 (7)
hostPrefix: 23 (8)
networkType: OpenShiftSDN
serviceNetwork:
- 172.30.0.0/16 (9)
machineNetwork:
- cidr: 172.16.0.0/24 (10)
platform:
none: {} (11)
fips: false (12)
pullSecret: '{"auths": ...}' (13)
sshKey: 'ssh-ed25519 AAAA...' (14)
(1) ベースとなるドメイン名です。
(2) computeセクションの頭には-が必要な事に注意してください。controlPlaneセクションには-は要りません。現状ではどちらのセクションの一つmachine poolしか定義できませんが、将来的に複数のcomputeのmachine poolが指定できる可能性があるためこうなっています。
(3) Hyper Threading の設定です。サーバーのハードウェアが対応していれば、ONにしておきます。
(4) Worker ノードは、0 にしておきます。UPI (User Provisioned Infrastructure) の時は、この値は機能せず、後で Worker ノードを手動でデプロイする事になります。
(5) Masterノードの数です。3にします。
(6) 作成されるクラスターの名前です。(1)のベースドメイン名のサブドメイン名として使用されます。
(7) Pod のネットワークに使われる IPアドレスレンジです。クラスター内部のプライベートなネットワークです。公開されるネットワークでは無いので問題なければこの値をそのまま使います。(デフォルト値です)
(8) 個々の Node にアサインされるサブネットの Prefix です。23の場合、個々のノードに一つの/23のサブネットが cidr からアサインされます。2^(32-23)-2 = 510 のアドレスが Pod 用に使用できます。
(9) (7)と同じで Cluster内部のプライベートなネットワーク用のアドレスレンジです。公開されるネットワークでは無いので問題なければこの値をそのまま使います。(デフォルト値です)
(10) Master/Worker/Bootstrap Node 間のネットワークです
(11) bare metalでは指定できないので、ここはnoneでなければいけません。
(12) FIPSモードの有効化です。デフォルトではfalseです。
(13) ダウンロードした Pull Secret を貼り付けます。
(14) 作成したSSHの公開鍵を貼り付けます。前の手順で作成した/root/.ssh/id_rsa.pubの中身です。
※初出時にはじめの設計と絵とここの YAMLのアドレスレンジがずれておりました。お詫びして訂正致します。
4.2.Kubernetes manifest と Ignition config filesを作成する。
4.2.1.manifest ファイルの作成
インストール用のファイルがたくさん生成されるので、インストールファイル用のディレクトリを作っておきます。
installdir というディレクトリ名にします。
$ cd /root/openshift/ # この手順での、作業ディレクトリに移動
$ mkdir installdir
先ほど作成した install-config.yaml ファイルを installdir にコピーします。
コピーしたinstall-config.yamlファイルは、後の作業で消えてしまうので、オリジナルのinstall-config.yamlは再インストール時用に保管しておくために mv ではなく、cpにしておくのがおすすめです。
$ cp install-config.yaml ./installdir/install-config.yaml
install-config.yaml を元にインストールファイル群を installdir 内に作成します。
以下のコマンドでインストール用のファイル群が作成されます。
$ ./openshift-install create manifests --dir=installdir
INFO Consuming Install Config from target directory
WARNING Making control-plane schedulable by setting MastersSchedulable to true for Scheduler cluster settings
$
installdir 配下に新しいディレクトリが出来ている事を確認します。このディレクトリの中にインストール用の manifest ファイル(yaml)が大量に生成されているはずです。確認してみてください。
$ ls -ltr installdir/ # Directory が2つ出来ている
total 8
drwxr-x---. 2 root root 4096 Aug 16 02:10 manifests
drwxr-x---. 2 root root 4096 Aug 16 02:10 openshift
$ ls -ltr ./installdir/manifests/ # yml が生成されている。
-rw-r-----. 1 root root 444 Sep 28 20:51 cluster-infrastructure-02-config.yml
-rw-r-----. 1 root root 154 Sep 28 20:51 cluster-dns-02-config.yml
<出力略>
$ ls -ltr ./installdir/openshift/ # yml が生成されている。
-rw-r-----. 1 root root 2602 Sep 28 20:51 99_openshift-cluster-api_master-user-data-secret.yaml
-rw-r-----. 1 root root 1277 Sep 28 20:51 99_openshift-machineconfig_99-worker-ssh.yaml
<出力略>
4.2.2.control plane への Pod schedule の無効化
前段のステップで生成された manifest ファイルの一部を変更します。
通常、Kubernetes では、Master ノードにユーザーアプリの Pod を配置する事はありませんが、OpenShift では、最小構成の3ノード構成を取る場合に、Master にも ユーザーアプリの Pod を配置できるようになりました。デフォルトの設定はこの最小3ノード構成を取るように構成されます。
この手順では、一般的であるWorker ノードを持った構成にしたいため、Masterノードに ユーザーPodをスケジュール(配置)しないように構成を変更します。
installdir/manifests/cluster-scheduler-02-config.yml
を編集します。
apiVersion: config.openshift.io/v1
kind: Scheduler
metadata:
creationTimestamp: null
name: cluster
spec:
mastersSchedulable: false # true を false に変更
policy:
name: ""
status: {}
もしくは、一ヶ所の編集なので sed -i コマンドで置き換えてしまいます。
sed -i -e 's/mastersSchedulable: true/mastersSchedulable: false/' installdir/manifests/cluster-scheduler-02-config.yml
4.2.3.ignition ファイルの作成 (manifestファイルのignitionファイルへの変換)
ignition ファイルという CoreOS のインストール時に使用するファイルをコマンドで生成します。
ignitionファイル は、前のステップで作成された manifest ファイルを変換して作成されるファイルですが、manifestファイルと違い可読困難なファイルです。ignitionファイル群は、後の手順で、CoreOSのブート時に、CoreOSに渡されます。
OpenShift の boostrap、master、workerノード用にそれぞれ別の ignitionファイルが生成されます。
$ cd /root/openshift/ # この手順での、作業ディレクトリに移動
$ ./openshift-install create ignition-configs --dir installdir
INFO Consuming Openshift Manifests from target directory
INFO Consuming Master Machines from target directory
INFO Consuming Worker Machines from target directory
INFO Consuming OpenShift Install (Manifests) from target directory
INFO Consuming Common Manifests from target directory
$
*.ign というファイルが作成されているはずです。
$ tree installdir/
installdir/
├── auth
│ ├── kubeadmin-password
│ └── kubeconfig
├── bootstrap.ign
├── master.ign
├── metadata.json
└── worker.ign
1 directory, 6 files
$
ここで作成した .ing ファイルには、X509形式の証明書が含まれています。
証明書の期限は24時間になっており、24時間を超えて *.ign を使い回す事はできませんので、その場合は *.ign ファイルを再作成して下さい。
4.3.oc コマンド実行環境のセットアップ
踏み台サーバー上で、ocコマンドが使えるようにセットアップしておきましょう。この例では /root/openshift に oc コマンドを置いてあるので PATH変数に追加しておきます。
export PATH=$PATH:/root/openshift
また、oc コマンドがクラスターにアクセスするための認証情報は、この例だと /root/openshift/installdir/auth/kubeconfig にあります。このパスを export しておきます。
export KUBECONFIG=/root/openshift/installdir/auth/kubeconfig
これらの export の設定は、結局何度も使用する事になるので、.bash_profile 等にあらかじめ書いてしまって、ログイン時に自動設定されるようにしておくのがおすすめです。
5.インストールに必要な設定ファイルを HTTPサーバーに配置する
この作業は、踏み台サーバー(=HTTPサーバー) 上での作業です。
5.1.ignition ファイルを HTTP Serverにコピーする。
HTTP Server(踏み台サーバー) に、インストールに必要なイメージファイルや、作成したインストール用の構成ファイルをコピーします。
この例の場合は作業しているサーバー自体が HTTP Serverをインストールしているので、HTTP Server(踏み台サーバー) のディレクトリに RAW イメージと *.ign をコピーします。
[root@bastion openshift]# cp ./installdir/*.ign /usr/share/nginx/html/
※ダウンロードしたRAWイメージは、別途 /usr/share/nginx/html/ に配置しておきます。
5.2 アクセスができる確認する
HTTPサーバー(踏み台サーバー)のディレクトリーに配置したファイルがアクセスできるか確認します。
ファイルに HTTP アクセスできるか、適当なファイルを使って確かめます。
curl -I オプションは HTTP の HEAD リクエストなので、実際のいダウンロードはしません。
master.ign ファイルを使って確かめます。200 が返ってきていたらOKです。
[root@bastion openshift]# curl -I http://localhost/master.ign
HTTP/1.1 200 OK # 200 が返ってきていたらOK
Server: nginx/1.14.1
Date: Sun, 16 Aug 2020 07:32:45 GMT
Content-Type: application/octet-stream
Content-Length: 1835
Last-Modified: Sun, 16 Aug 2020 06:43:15 GMT
Connection: keep-alive
ETag: "5f38d583-72b"
Accept-Ranges: bytes
[root@bastion openshift]#
5.3 SELinux の落とし穴
Webサーバー上に配置したファイルで、rhcos-4.5.2-x86_64-metal.x86_64.raw.gz だけは、アクセスしようとすると 403 (forbitten) が返ってくるはずです。
[root@bastion openshift]# curl -I http://localhost/rhcos-4.5.6-x86_64-metal.x86_64.raw.gz
HTTP/1.1 403 Forbidden
Server: nginx/1.14.1
Date: Sun, 16 Aug 2020 08:21:42 GMT
Content-Type: text/html
Content-Length: 169
Connection: keep-alive
これはSELinux が原因です。セキュリティコンテキストを確認してみます。
# SELinux のコンテキストの確認
$ ls -lZ /usr/share/nginx/html/work/
total 874428
-rw-r--r--. 1 root root unconfined_u:object_r:httpd_sys_content_t:s0 298610 Aug 16 02:43 bootstrap.ign
-rw-r--r--. 1 root root unconfined_u:object_r:httpd_sys_content_t:s0 1835 Aug 16 02:43 master.ign
-rwxrwxrwx. 1 root root unconfined_u:object_r:admin_home_t:s0 895104623 Aug 16 03:14 rhcos-4.5.2-x86_64-metal.x86_64.raw.gz
-rw-r--r--. 1 root root unconfined_u:object_r:httpd_sys_content_t:s0 1835 Aug 16 02:43 worker.ign
rhcos-4.5.2-x86_64-metal.x86_64.raw.gz だけが、`[admin_home_t]` という「タイプ」を持っている事がわかる。
これを他のファイルと同じように、タイプを [httpd_sys_content_t] に変更します。
# タイプを変更
$ semanage fcontext -a -t httpd_sys_content_t /usr/share/nginx/html/work/rhcos-4.5.2-x86_64-metal.x86_64.raw.gz
# semanage コマンドを実行しただけだと変わらない
$ ls -lZ /usr/share/nginx/html/work/
total 874428
-rw-r--r--. 1 root root unconfined_u:object_r:httpd_sys_content_t:s0 298610 Aug 16 02:43 bootstrap.ign
-rw-r--r--. 1 root root unconfined_u:object_r:httpd_sys_content_t:s0 1835 Aug 16 02:43 master.ign
-rwxrwxrwx. 1 root root unconfined_u:object_r:admin_home_t:s0 895104623 Aug 16 03:14 rhcos-4.5.2-x86_64-metal.x86_64.raw.gz
-rw-r--r--. 1 root root unconfined_u:object_r:httpd_sys_content_t:s0 1835 Aug 16 02:43 worker.ign
# restorecon コマンドで反映
$ restorecon /usr/share/nginx/html/work/rhcos-4.5.2-x86_64-metal.x86_64.raw.gz
[root@bastion openshift]# restorecon /usr/share/nginx/html/work/rhcos-4.5.2-x86_64-metal.x86_64.raw.gz
# もう一度確認。無事タイプが変更になっている。
[root@bastion openshift]# ls -lZ /usr/share/nginx/html/work/
total 874428
-rw-r--r--. 1 root root unconfined_u:object_r:httpd_sys_content_t:s0 298610 Aug 16 02:43 bootstrap.ign
-rw-r--r--. 1 root root unconfined_u:object_r:httpd_sys_content_t:s0 1835 Aug 16 02:43 master.ign
-rwxrwxrwx. 1 root root unconfined_u:object_r:httpd_sys_content_t:s0 895104623 Aug 16 03:14 rhcos-4.5.2-x86_64-metal.x86_64.raw.gz
-rw-r--r--. 1 root root unconfined_u:object_r:httpd_sys_content_t:s0 1835 Aug 16 02:43 worker.ign
6.ネットワーク環境の疎通確認
手順が非常に長い上に、フルスタックな作業のため、どうしてもセットアップでミスをしがちです。
OpenShiftクラスターの導入に移る前に正しくノードがセットアップされているかできるだけ確認しておきます。
Inter-Nodeネットワーク上のサーバーで以下のコマンドを実行してネットワークの設定を確認します。
ping -c 2 api.ocp45.example.localdomain # ロードバランサーで解決される
ping -c 2 api-int.ocp45.example.localdomain # ロードバランサーで解決される
ping -c 2 test.apps.ocp45.example.localdomain # ロードバランサーで解決される
dig +short bs.ocp45.example.localdomain # ノードが無いと ping は返ってこないが、dig で名前解決はできる
dig +short m1.ocp45.example.localdomain # ノードが無いと ping は返ってこないが、dig で名前解決はできる
dig +short m2.ocp45.example.localdomain # ノードが無いと ping は返ってこないが、dig で名前解決はできる
dig +short m3.ocp45.example.localdomain # ノードが無いと ping は返ってこないが、dig で名前解決はできる
dig +short w1.ocp45.example.localdomain # ノードが無いと ping は返ってこないが、dig で名前解決はできる
dig +short w2.ocp45.example.localdomain # ノードが無いと ping は返ってこないが、dig で名前解決はできる
dig +short w3.ocp45.example.localdomain # ノードが無いと ping は返ってこないが、dig で名前解決はできる
dig +norec -x 172.16.0.11 +short # Bootsrap Node のIPの逆引き
dig +norec -x 172.16.0.21 +short # Masterノード 1 のIPの逆引き
dig +norec -x 172.16.0.22 +short # Masterノード 2 のIPの逆引き
dig +norec -x 172.16.0.23 +short # Masterノード 3 のIPの逆引き
dig +norec -x 172.16.0.31 +short # Workerノード 1 のIPの逆引き
dig +norec -x 172.16.0.32 +short # Workerノード 2 のIPの逆引き
dig +norec -x 172.16.0.33 +short # Workerノード 3 のIPの逆引き
# インターネットアクセス
wget https://quay.io/v2/
(CoreOSが、必要なモジュールをダウンロードする時に、ここにアクセスします。401 UNAUTHORIZED。が返ってくればOK)
名前の逆引きは、現時点でマニュアルに要件が載っていませんでしたが、この逆引きの値がoc get nodesコマンドを実行した時のノード名に使われているように見えます。逆引き設定が無い場合は、ノードが、localhostになってしまい、インストールが失敗しました。
もし一つでも上手くいかない場合は、もう一度ネットワーク環境を確認してみてください。
7.OpenShift クラスターのインストール
7.1.CoreOS のインストールの概要
iPXE環境が正しく設定されていれば、物理サーバーの起動スイッチを押すだけで、CoreOSがインストールされるはずです。
少し複雑ですが、以下の図にかかれている作業がサーバーの電源ON後、自動で実行されます。
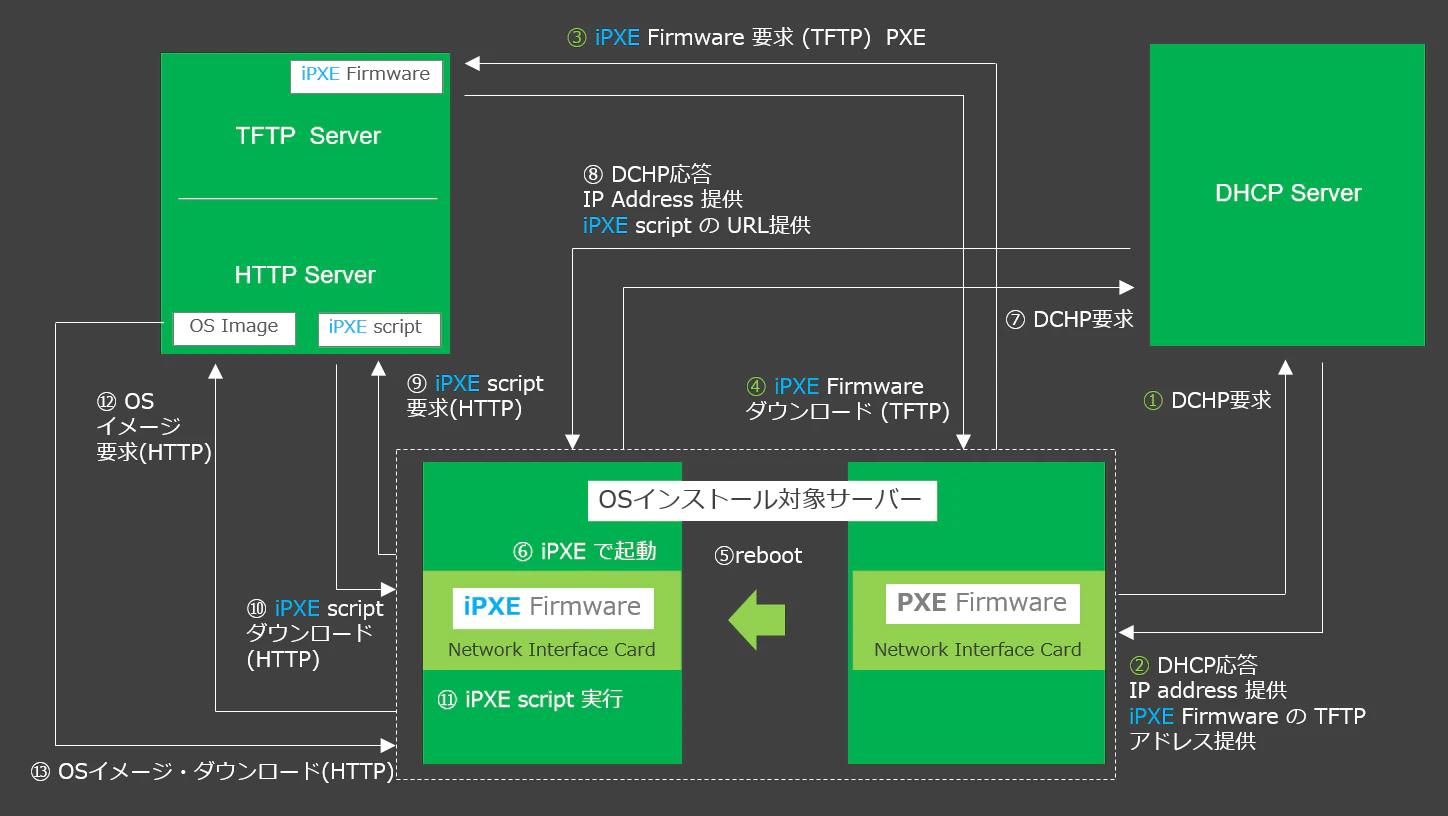
トラブルが起きない限りは、TFTPサーバーには、iPXEファームウェアを取りに行く、HTTPサーバーには、CoreOSのインストールに必要なものを取りに行く。という事だけイメージできれば大丈夫だと思います。
この要領で、まずは 合計7本 (Bootstrap x 1、Master x 3、Worker x 3) の CoreOSノードを準備します。
7.2.Cluter Node インストールの概要
あくまでOpenShift4.5 のインストーラーの動きを外部やログから観察した限りでの動きですが、OpenShift Clusterに所属するノードのインストール時の動きは以下のように動いているように見えます。
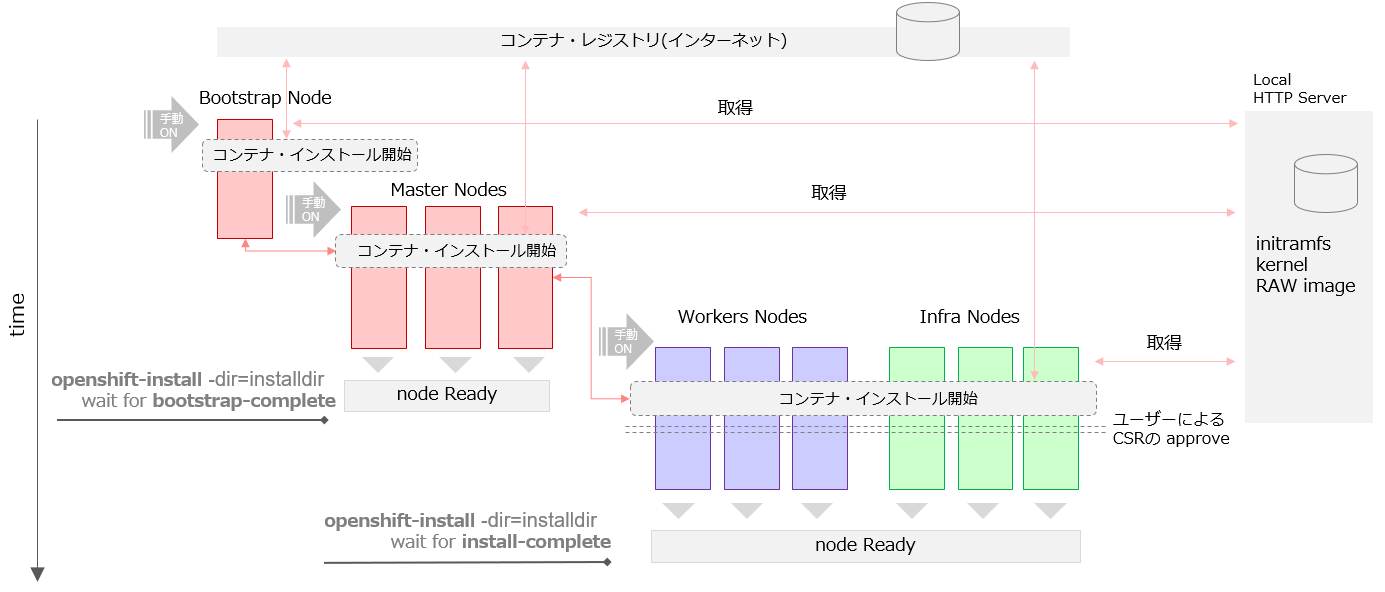
※Masterノード以降は直接 Internet 行ってるのかは未確認!(いつかトレースを取って確認したい)
各ノードの電源をONにするとiPXEにより CoreOSのインストールがはじまり、その後、必要なContainerのインストールがはじまります。
Masterノードは、途中で次のステップに進むためにBoot Strapの準備が整っているか確認を行います。
Worker(Infra) ノードは、途中で次のステップに進むためにMasterノードの準備が整っているか確認を行います。このようにBootStrap=>Master=>Workerは、それぞれ依存関係にあります。
順番に自動でタイミングを見ながらインストールが進みますが、各ノードの起動タイミングは、大体順番に起動していく程度の緩い感覚で開始して行けば大丈夫です。経験上、連続で立ちあげていって、起動順序が多少前後しても、依存相手の準備完了を待つだけなので問題ありません。
また、Worker(Infra)ノード は、インストールの途中でユーザーが手動でCSR(Certificate Signing Request)という証明書の元になる情報に署名approveを行って証明書を作成してあげる必要があります。
7.3.BootStrapノードの起動
BootStrapノードを起動して、iPXEブートメニューに進みます。
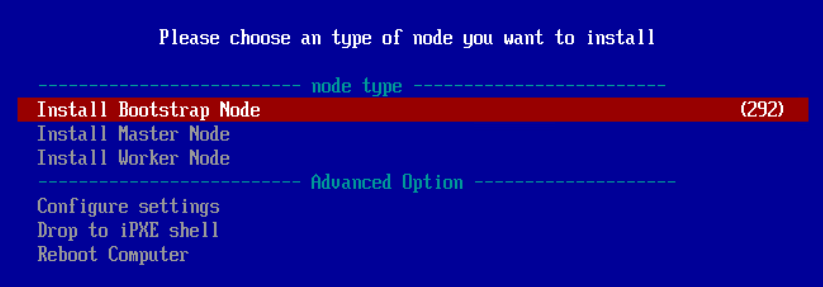
メニューを選択したら後は、待つだけです。
以下のエラーがでるかもしれませんが、無視できるものだそうです。

7.4.Masterノードの起動
Masterノードを起動して iPXEブートメニューに進みます。
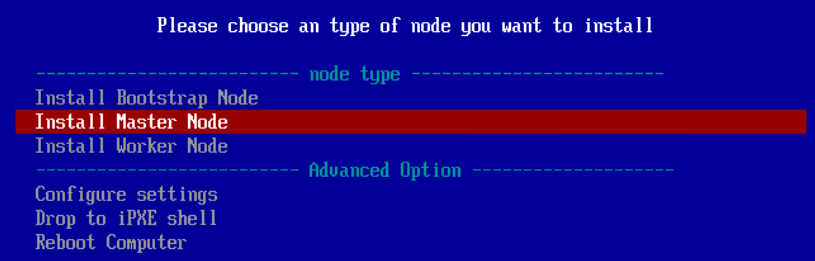
メニューを選択したら後は待つだけです。
Masterノードでも BootStrap と同様に、以下のエラーがでるかもしれませんが、無視できるものだそうです。

動きとしてMasterノードは BootStrapノードの準備ができるのを待ち続け、その後、自らのインストールを開始します。BootStrapノードとMasterノードの起動が多少前後しても問題はありません。Masterノードを素早く立ちあげても、BootStrapノードの準備完了まで待つ事になります。
Masterノードは、3本あるので、この作業を後2回繰り返します。特に Masterノード間に依存関係があるわけではないので、3本のノードをさくさくとONにして大丈夫です。
経験側ですが、このMasterノードのインストール作業時の2本目、3本目の Masterノード のブートは手早く行った方が良いと思います。再現試験はしていませんが、あまり間を開けると失敗する事があるような気がします。
7.5.「openshift-install ~ wait-for bootstrap-complete」の実行
※インストール時間を短縮したい場合は、先にセクション「7.6.Workerノードの起動」を実行して、ここに戻ってきても大丈夫です。
BootStrap の起動シークエンスをモニターするコマンドを実行します。
このコマンドでは、BootStrapノードが立ち上がり、その後、3本の Masterノードが立ち上がるまでをモニターします。
./openshift-install --dir=installdir wait-for bootstrap-complete --log-level=debug
[root@bastion openshift]# ./openshift-install --dir=installdir wait-for bootstrap-complete --log-level=debug
INFO Waiting up to 20m0s for the Kubernetes API at https://api.ocp45.example.localdomain:6443...
<省略>
DEBUG Still waiting for the Kubernetes API: the server could not find the requested3/version?timeout=32s: EOF resource resource
DEBUG Still waiting for the Kubernetes API: Get https://api.ocp45.example.local:644 resource 3/version?timeout=32s: EOF resource
DEBUG Still waiting for the Kubernetes API: Get https://api.ocp45.example.local:6443/version?timeout=32s: EOF 3/version?timeout=32s: EOF 3/version?timeout=32s: EOF
INFO API v1.18.3+b0068a8 up
INFO Waiting up to 40m0s for bootstrapping to complete...
DEBUG Bootstrap status: complete
INFO It is now safe to remove the bootstrap resources
DEBUG Time elapsed per stage:
DEBUG Bootstrap Complete: 14m54s
DEBUG API: 6m13s
INFO Time elapsed: 14m54s
[root@bastion openshift]#
コマンドが終了しれば、BootSrap のシークエンスは完了です。この時点で、BootSrtap Nodeが作成され、それを元に Msater Nodeが作成される所までが完了しています。
全体が完了しているわけではないので、次のステップに進みます。
7.6.Workerノードの起動
Workerノードの CoreOSのインストールも BootStrap, Master同様です。が、後述しますが、少し追加の手順が必要になります。
まずは、BootStrap、Master と同じようにインストールを開始します。
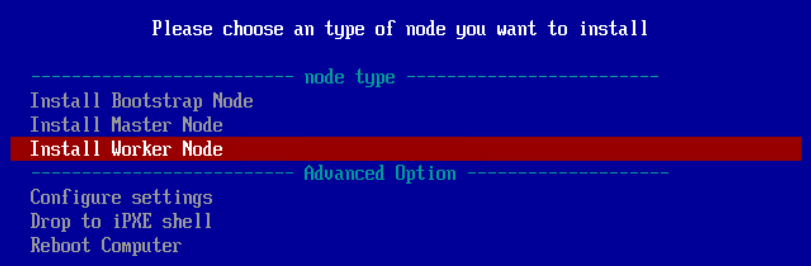
Workerノードの起動時に以下のログが表示されますが、これはMasterノードの起動を確認している時のログで、これ自体はエラーではありません。

7.7.Workerノード のCSRの approve
この手順は、セクション「7.5.「openshift-install ~ wait-for bootstrap-complete」の実行」で実行したコマンドが完了し、セクション「7.6.Workerノードの起動」も開始している事が前提になります。
CSR(Certificate Signing Request)は証明書の元になる情報への署名要求で、approve をする事で署名され、証明書になります。oc get csr コマンドを実行して Pending になっているものを探します。
これらの CSRは、Workerノードに紐付くもので、Workerノードがクラスターに参加する時に必ず行う必要があります。
もしPendingが表示されていない場合は、Workerノードの準備が整うと必ず表示されるものなので、Workerノードの起動後、数分待って再度コマンドを実行してみて下さい。
oc get csr
[root@bastion openshift]# oc get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
csr-7ftsc 25m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,Issued
csr-8557v 24m kubernetes.io/kubelet-serving system:node:m1.ocp45.example.local Approved,Issued
csr-8cjss 11m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending
csr-8v6ns 24m kubernetes.io/kubelet-serving system:node:m3.ocp45.example.local Approved,Issued
csr-nnzww 10m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending
csr-qqh7s 24m kubernetes.io/kubelet-serving system:node:m2.ocp45.example.local Approved,Issued
csr-wtcdk 25m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,Issued
csr-zlrhb 25m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,Issued
[root@bastion openshift]#
oc adm certificate approve コマンドで Pending 状態のものを approve します。
[root@bastion openshift]# oc adm certificate approve csr-8cjss csr-nnzww
certificatesigningrequest.certificates.k8s.io/csr-8cjss approved
certificatesigningrequest.certificates.k8s.io/csr-nnzww approved
[root@bastion openshift]#
上記の例では、コピペで、approve 対象の CSR名を一つ一つコピペで貼り付けていますが、マニュアルには以下のワンライーナーのコマンドを使う方法も紹介されています。
oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
approve すると、今度はすぐに別の Pending のCSRが出てきます。Peding が無くなるまで、approve を繰り返します。
初めの CSR の approve から数分以内に次の Pending が表示されるはずです。oc get csrコマンドを使って確認し、新しい Pending の状態のものが確認できたら approve します。
一つの Workerノード (Infraノード) 辺り、2回 CSR の approve を要求されます。(クライアント・リクエストCSRと、サーバー・リクエストCSRと言うようです)
もしWroker Nodeが 6本ある場合は、12回 CSRのapproveが必要になるはずです。
一つ approve してみます。
[root@bastion openshift]# oc get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
csr-7ftsc 27m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,Issued
csr-8557v 27m kubernetes.io/kubelet-serving system:node:m1.ocp45.example.local Approved,Issued
csr-8cjss 13m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,Issued
csr-8v6ns 27m kubernetes.io/kubelet-serving system:node:m3.ocp45.example.local Approved,Issued
csr-frwfk 1s kubernetes.io/kubelet-serving system:node:w1.ocp45.example.local Pending
csr-nnzww 12m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,Issued
csr-qqh7s 27m kubernetes.io/kubelet-serving system:node:m2.ocp45.example.local Approved,Issued
csr-wtcdk 27m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,Issued
csr-zlrhb 27m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,Issued
[root@bastion openshift]# oc adm certificate approve csr-frwfk #
certificatesigningrequest.certificates.k8s.io/csr-frwfk approved
approve すると、以下のようにすぐに別の Pending が現れるはずです。1つのWorkerノードにつき2回要求されます。
[root@bastion openshift]# oc get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
csr-7ftsc 27m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,Issued
csr-8557v 27m kubernetes.io/kubelet-serving system:node:m1.ocp45.example.local Approved,Issued
csr-8cjss 13m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,Issued
csr-8v6ns 27m kubernetes.io/kubelet-serving system:node:m3.ocp45.example.local Approved,Issued
csr-frwfk 22s kubernetes.io/kubelet-serving system:node:w1.ocp45.example.local Approved,Issued
csr-hpw9z 15s kubernetes.io/kubelet-serving system:node:w2.ocp45.example.local Pending
csr-nnzww 13m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,Issued
csr-qqh7s 27m kubernetes.io/kubelet-serving system:node:m2.ocp45.example.local Approved,Issued
csr-wtcdk 27m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,Issued
csr-zlrhb 27m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,Issued
[root@bastion openshift]# oc adm certificate approve csr-hpw9z
certificatesigningrequest.certificates.k8s.io/csr-hpw9z approved
Pending状態のものが無くなれば完了です。
[root@bastion openshift]# oc get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
csr-7ftsc 28m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,Issued
csr-8557v 28m kubernetes.io/kubelet-serving system:node:m1.ocp45.example.local Approved,Issued
csr-8cjss 14m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,Issued
csr-8v6ns 28m kubernetes.io/kubelet-serving system:node:m3.ocp45.example.local Approved,Issued
csr-frwfk 44s kubernetes.io/kubelet-serving system:node:w1.ocp45.example.local Approved,Issued
csr-hpw9z 37s kubernetes.io/kubelet-serving system:node:w2.ocp45.example.local Approved,Issued
csr-nnzww 13m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,Issued
csr-qqh7s 28m kubernetes.io/kubelet-serving system:node:m2.ocp45.example.local Approved,Issued
csr-wtcdk 28m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,Issued
csr-zlrhb 28m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,Issued
[root@bastion openshift]#
通常であれば、CSR を approve した直後に、Worker ノードが oc get nodes で表示されるはずです。
CSR を全て approve したら、oc get nodes を実行して Workerノードが Ready になるのを確認します。
[root@bastion openshift]# oc get nodes
NAME STATUS ROLES AGE VERSION
m1.ocp45.example.local Ready master 31m v1.18.3+47c0e71
m2.ocp45.example.local Ready master 31m v1.18.3+47c0e71
m3.ocp45.example.local Ready master 31m v1.18.3+47c0e71
w1.ocp45.example.local Ready worker 4m13s v1.18.3+47c0e71
w2.ocp45.example.local Ready worker 4m5s v1.18.3+47c0e71
[root@bastion openshift]#
全てのノードのReady が確認できたらセットアップはほぼ完了です。
7.8.「openshift-install ~ wait-for install-complete」のコマンドの実行
これまでの手順で全てのインストール手順は完了のように見えますが、クラスター内部では、まだコンテナ等のインストールが続いていて、Cluster としては Readyにはなっていません。
OpenShiftのコンソール用のPodなどは、Workerノードに配置されるため、WorkerノードのCSRが approveされてから Podの作成が始まります。
残りのPodの作成の完了(Cluster Ready)を暫く待つ必要があります。
7.8.1.「openshift-install ~ wait-for install-complete」の実行
OpenShiftClusterがReadyになるまでをモニターするためのコマンド ./openshift-install --dir=installdir wait-for install-complete を実行します。
以前使用した BootStrapプロセスの完了のモニターに使用したコマンドとは、後半の wait-for install-completeの部分が違っているので注意して下さい。
./openshift-install --dir=installdir wait-for install-complete
[root@bastion openshift]# ./openshift-install --dir=installdir wait-for install-complete
INFO Waiting up to 30m0s for the cluster at https://api.ocp45.example.local:6443 to initialize...
INFO Waiting up to 10m0s for the openshift-console route to be created...
INFO Install complete!
INFO To access the cluster as the system:admin user when using 'oc', run 'export KUBECONFIG=/root/openshift/installdir/auth/kubeconfig'
INFO Access the OpenShift web-console here: https://console-openshift-console.apps.ocp45.example.local
INFO Login to the console with user: "kubeadmin", and password: "KBB5q-7reSE-gUKSf-ssZPx"
INFO Time elapsed: 5m19s
[root@bastion openshift]#
コマンドを実行した後は待つだけです。上記の例では 5分ほどで完了しています。
7.8.2.「openshift-install ~ wait-for install-complete」実行中の観察
インストールの手順としては、前述のステップで完了ですが、インストール中に、インストール中の実行状況を確認する方法について補足します。
7.8.2.1.実行ログ
./openshift-install --dir=installdir wait-for install-complete のログは installdir/.openshift_install.log として作られます。もう一つターミナルを開いて、このログを横からtailする事で、進捗を見ることができます。ただし、このログから得られる情報は、それほど多くはありません。
[root@bastion installdir]# tail -f .openshift_install.log
time="2020-09-23T04:18:08-04:00" level=debug msg="OpenShift Installer 4.5.5"
time="2020-09-23T04:18:08-04:00" level=debug msg="Built from commit 01f5643a02f154246fab0923f8828aa9ae3b76fb"
time="2020-09-23T04:18:08-04:00" level=info msg="Waiting up to 20m0s for the Kubernetes API at https://api.ocp45.example.localdomain:6443..."
time="2020-09-23T04:18:08-04:00" level=debug msg="Still waiting for the Kubernetes API: Get https://api.ocp45.example.localdomain:6443/version?timeout=32s: http: server gave HTTP response to HTTPS client"
time="2020-09-23T04:18:38-04:00" level=debug msg="Still waiting for the Kubernetes API: Get https://api.ocp45.example.localdomain:6443/version?timeout=32s: http: server gave HTTP response to HTTPS client"
time="2020-09-23T04:19:08-04:00" level=debug msg="Still waiting for the Kubernetes API: Get https://api.ocp45.example.localdomain:6443/version?timeout=32s: http: server gave HTTP response to HTTPS client"
上記のログはインストールが完了を、API Server の応答が確認できるまで待っているログです。一見エラーに見えますが、定期的な起動確認チェックですので、これ自体はインストールの失敗を示すものではありません。(もちろん、ずっとこの状態が続くとインストールが失敗します)
7.8.2.2.Podの状態の観察
以下の方法でも、インストール中の進捗を確認する事ができます。
以下は oc get pods --all-namespaces で Running と Completed 以外の状態のPodを確認する事で、進捗を確認している例です。
最終的に全て Running が Completed になるので、Cluster Ready 時には、 Running と Completed 以外の状態のPodは、なくなります。
[root@bastion openshift]# oc get pods --all-namespaces | grep -v Running | grep -v Completed
NAMESPACE NAME READY STATUS RESTARTS AGE
openshift-console console-86bfd57fc9-k8sbm 1/1 Terminating 0 3m52s
openshift-kube-apiserver kube-apiserver-m1.ocp45.example.local 0/4 Init:0/1 0 54s
[root@bastion openshift]#
もし状態が Completed や Running にならないPodがある場合は、以下のコマンドでログを確認できます。
oc logs <pod_name> -n <namespace>
また、Podの状況調査には以下のコマンドも有効です。出力量は多いですが、Podの各種設定やイベント等も表示されます。
oc describe pods <pod_name> -n <namespace>
いずれのコマンドも<namespace>の指定を忘れると、Podがありませんのようなメッセージが返ってくるので注意しましょう。
7.8.2.3.Operatorの状態の観察
oc get clusteroperators で、Operator のインストール状況を確認できます。AVAILABLEの欄が最終的に全てTRUEになります。
[root@bastion openshift]# oc get clusteroperators
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE
authentication Unknown Unknown True 11m
cloud-credential 4.5.11 True False False 16m
cluster-autoscaler 4.5.11 True False False 3m14s
config-operator 4.5.11 True False False 3m26s
console 4.5.11 Unknown True False 5m17s
csi-snapshot-controller
dns 4.5.11 True True True 10m
etcd 4.5.11 True False False 10m
image-registry 4.5.11 True False False 4m48s
ingress False True True 4m46s
insights 4.5.11 True False False 4m48s
kube-apiserver 4.5.11 True True False 9m22s
kube-controller-manager 4.5.11 True False False 9m9s
kube-scheduler 4.5.11 True False False 9m11s
kube-storage-version-migrator 4.5.11 False False False 11m
machine-api 4.5.11 True False False 4m47s
machine-approver 4.5.11 True False False 5m34s
machine-config 4.5.11 True False False 10m
marketplace 4.5.11 True False False 4m7s
monitoring Unknown True Unknown 4m47s
network 4.5.11 True True False 12m
node-tuning 4.5.11 True False False 11m
openshift-apiserver 4.5.11 True False False 5m49s
openshift-controller-manager 4.5.11 True False False 4m36s
openshift-samples 4.5.11 True False False 3m8s
operator-lifecycle-manager 4.5.11 True False False 10m
operator-lifecycle-manager-catalog 4.5.11 True False False 10m
operator-lifecycle-manager-packageserver 4.5.11 True False False 6m25s
service-ca 4.5.11 True False False 11m
storage 4.5.11 True False False 4m46s
[root@bastion openshift]#
これらの情報を使用して、インストールが上手く進行しているか確認する事ができます。
7.8.3.コンソールアクセスの確認。
OpenShift Cluster が Ready になるとコマンドが終了し、https://console-openshift-console.apps.ocp45.example.local のようなコンソールのログインURLと、password: "KBB5q-7reSE-gUKSf-ssZPx"のように kubeadmin のパスワードが表示されます。
[root@bastion openshift]# ./openshift-install --dir=installdir wait-for install-complete
<省略>
KUBECONFIG=/root/openshift/installdir/auth/kubeconfig' <= 環境の情報
INFO Access the OpenShift web-console here: https://console-openshift-console.apps.ocp45.example.local <= Console URL
INFO Login to the console with user: "kubeadmin", and password: "KBB5q-7reSE-gUKSf-ssZPx" <= userid / password
INFO Time elapsed: 5m19s
[root@bastion openshift]#
コンソールの URL にアクセスすると、以下のような警告が出ますが、これは OpenShiftが使用している証明書が安全だとは、ブラウザが判断できないために表示されるものです。これは証明書の発行者がOpenShiftクラスターであり、ブラウザーに事前登録されているCA(Certification Authority:認証局) の一覧にないためです。この警告は無視して構いません。
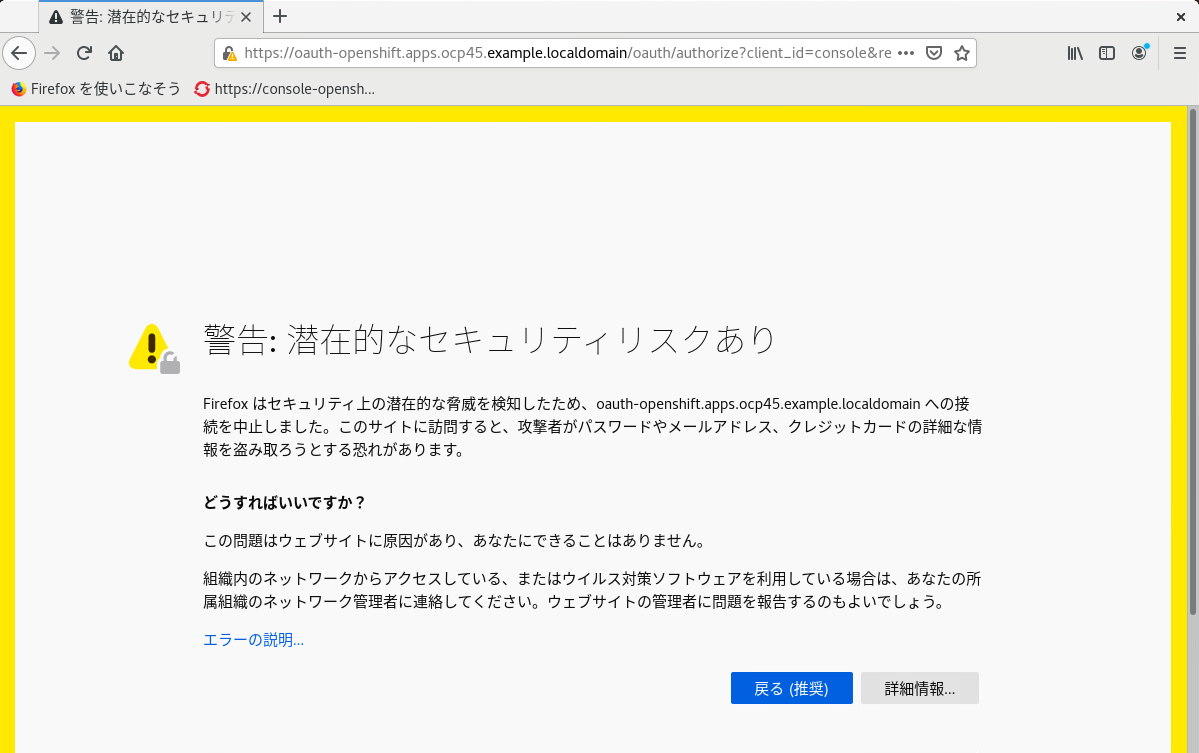
kubadminでログインできれば、Cluster のセットアップはひとまず完了です。
ちなみに、ログインのためのパスワードを忘れてしまった時は
./openshift-install --dir=installdir wait-for install-complete
をもう一度実行すると表示されます。
7.8.4.OpenShift Consoleにアクセスできない場合
OpenShift Consoeleは、OpenShiftの ingress(HTTP LB)実装であるRouter経由で外部からアクセスされます。
このRouterは、Workerノードにスケジュールされ、外部LoadBalacer(この環境ではHA Proxy)からトラフィクを割り振られなければいけません。
OpenShift Consoleにアクセスできない場合は、RouterのPodがどこにあるか以下のように確認できます。
# はじめに ingress の Pod名を突き止める。
[root@bastion ~]# oc describe node | grep ingress
openshift-ingress-operator ingress-operator-56f5778d85-ddncf 20m (0%) 0 (0%) 40Mi (0%) 0 (0%) 14h
openshift-ingress router-default-55596bdcbb-n87pm 100m (0%) 0 (0%) 256Mi (0%) 0 (0%) 14h
openshift-ingress router-default-55596bdcbb-xsgv6 100m (0%) 0 (0%) 256Mi (0%) 0 (0%) 14h
# Node名 を確認
[root@bastion ~]# oc describe pod router-default-55596bdcbb-n87pm -n openshift-ingress | grep Node:
Node: s2.ocp45.example.localdomain/172.16.0.52
# Node名 を確認
[root@bastion ~]# oc describe pod router-default-55596bdcbb-xsgv6 -n openshift-ingress | grep Node:
Node: s3.ocp45.example.localdomain/172.16.0.53
例えば初期インストール時に、ユーザーアプリケーション用のWorkerノードと、分散ストレージ用に使う予定のWorkerノードを同時に作成した場合、Routerがストレージ用のノードに配置されてしまう事がありえます。
そして、もし、そのストレージ用のノードがLoad Balancer配下に入ってない場合、OpenShift Consoleにアクセスできないばかりか、ユーザーのアプリにも外部からアクセスできない事になります。
7.8.5.OpenShift Consoleの証明書エラーを消す
OpenShiftのConsoleで使用されているHTTPS証明書は、自己証明書です。
証明書の署名をしているCA(Certificate Authority)は、ブラウザーにインストールされてないため、通常以下のような警告がでます。
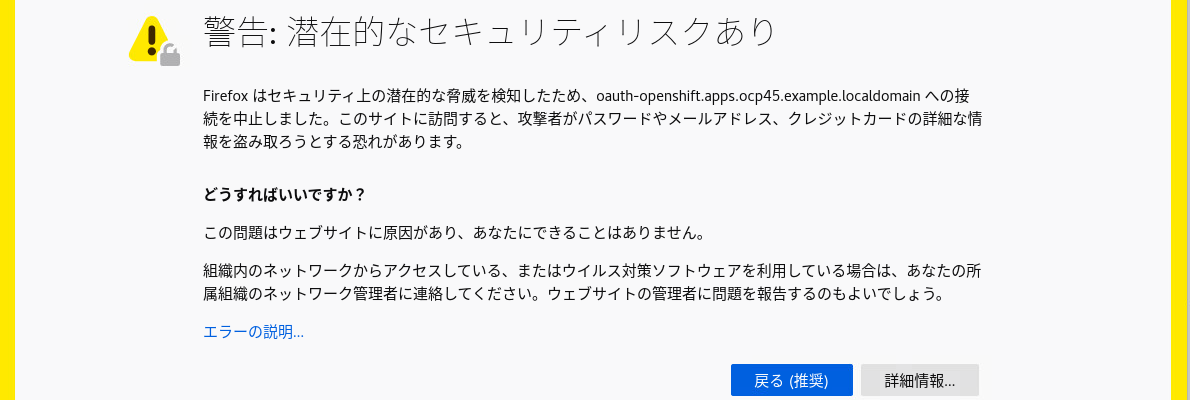
このルートCAの証明書は、Router(Ingress)により発行されています。実体はSecretに保存されていて以下の方法で取り出す事ができます。
oc get secret router-ca -n openshift-ingress-operator -o jsonpath="{.data.tls\.crt}" | base64 -d > router-ca.crt
作成したrouter-ca.crtをブラウザーにインストールします。ブラウザによって手順は違いますが、Firefoxの場合は、オプション→プライバシーとセキュリティから証明書を表示をクリックします。
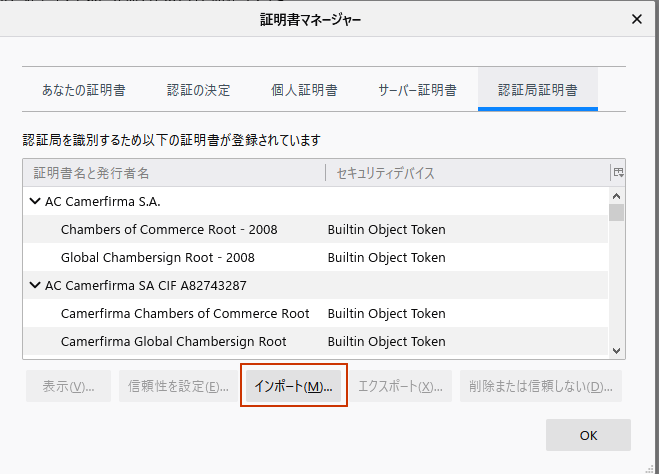
インポートから、作成したrouter-ca.crtをインポートします。
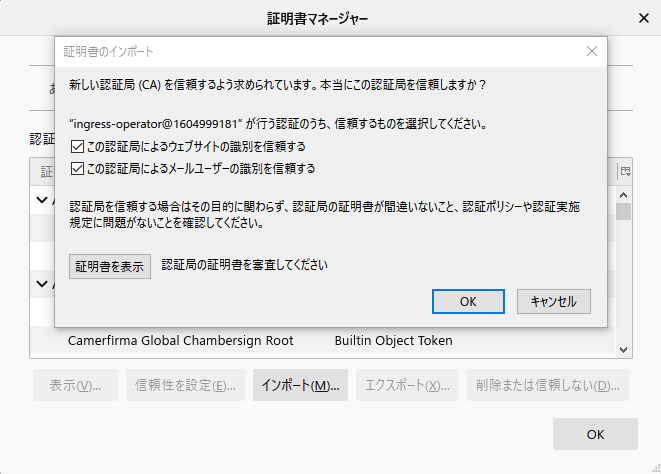
この認証局によるウェブサイトの識別を信頼するをチェックします。
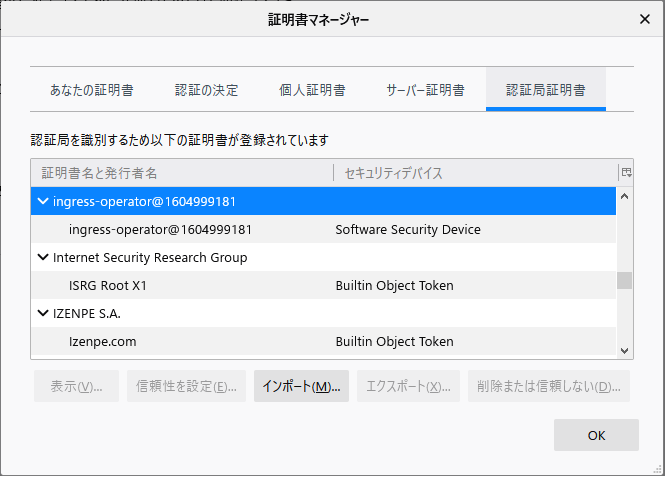
ingress-operator@xxxxxxxが証明書名と発行者名に表示されていればOKです。
これで Webブラウザでアクセス時の警告が表示されなくなります。
警告が表示されなくなるのは、router-ca.crtを導入した端末だけである事に注意して下さい。
7.8.6.bootstrapサーバーの除去
クラスターのセットアップが完了したらBoostrapサーバーは削除して問題ありません。
またロードバランサーのHaproxyの設定からも忘れずに取り除いて下さい。
<省略>
# server app4 127.0.0.1:5004 check
# internal domains is ocp45.example.localdomain
backend kube_api
mode tcp
balance roundrobin
option ssl-hello-chk
# server bs bs.ocp45.example.localdomain:6443 check # Entryから Boostratp Serverを除去
server m1 m1.ocp45.example.localdomain:6443 check
server m2 m2.ocp45.example.localdomain:6443 check
server m3 m3.ocp45.example.localdomain:6443 check
backend machine_config
mode tcp
balance roundrobin
# server bs bs.ocp45.example.localdomain:22623 check # Entryから Boostratp Serverを除去
server m1 m1.ocp45.example.localdomain:22623 check
server m2 m2.ocp45.example.localdomain:22623 check
server m3 m3.ocp45.example.localdomain:22623 check
<省略>
8.クラスターインストール完了後の作業
これまでのステップでとりあえずOpenShiftのクラスターとしては稼働するようになりました。コンテナもデプロイする事ができます。
ですが、現実の使える環境をを考えると、もう少しセットアップを続ける必要があります。
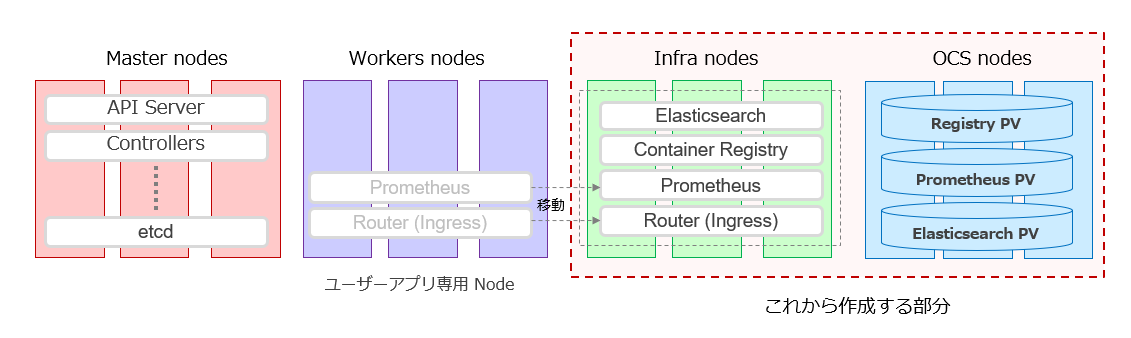
この章では、PV(Persistent Volume)用のストレージを準備し、運用のコンポーネントを載せるためのOpenShift用語でInfraノードと呼ばれるWorkerノードを作成します。
その後、Container Registry、Elasticsearch(Cluster Logging)を構成します。
これらの各種運用コンポーネントは、Infraノードに配置します。
また、Prometheusや、Router(Ingress)と言ったコンポーネントは、OpenShiftクラスターインストール時に既に作成されていますが、これらも運用コンポーネントですので、Infraノードに移動させます。
8.1. PV用のストレージの作成
PV用のストレージに何を使うかは環境次第ですが、この手順では、OCSを作成する事にします。以下の手順を参考にOCS(OpenShift Container Storage)を作成します。
OCS(OpenShift Container Storage)をインターナルモードで作成する
8.2.Infraノードの作成
OpenShiftの運用コンポーネントを配置するためのInfraノードを作成します。
Infraノードは、あくまでOpenShiftの世界での用語です。技術的にはWorkerノードと同じものです。
Workerノードを新規に3本作成します。IPアドレスなどは、セクション「1.1.7.ノードのサイジング」に書いてある通りです。
手順になれていれば、Workerノードの作成時に同時にInfraノードを作成しても良いのですが、作業に慣れていない時に、一度に大量のWorkerノードを作成すると作業ミスした時のリカバリーが大変なので敢えて後から追加で構成する手順にしました。
まずは、通常のWorkerノードと同様に以下の手順を実行します。
1.Infraノード用のIPアドレスを決定
2.DHCPサーバーに、MACアドレスに結びつけてInfraノードに固定IPを配れるように設定
3.DNSサーバーにInfraノードとして使用するWorkerノードのホスト名を DNSに登録 (逆引きも設定)
4.CoreOSのインストール。Workerノードの Inginiton fileを使って Workerノードとして構成
5.Woker NodeのCSRをapprove
ここでは、i1.ocp45.example.localdomain、i2.ocp45.example.localdomain、i3.ocp45.example.localdomainという3本のInfraノードを作成します。ここで作成するInfraノードのスペックは1.1.7.1.OpenShift 関連ノードのサイジングで設計した通りに、以下の通りです。
| サーバー | vCPU(HT-on) | Memory | Disk | OS | ホスト名 | IP Address | note |
|---|---|---|---|---|---|---|---|
| Infraノード | 4VCPU | 16GByte | 120G | CoreOS | i1.ocp45.example.localdomain | 172.16.0.41 | |
| 4VCPU | 16GByte | 120G | CoreOS | i2.ocp45.example.localdomain | 172.16.0.42 | ||
| 4VCPU | 16GByte | 120G | CoreOS | i3.ocp45.example.localdomain | 172.16.0.43 |
InfraノードのCoreOSのインストールに取りかかる前に、ネットワークの設定が取れているか確認しておく事をおすすめします。
dig +short i1.ocp45.example.localdomain # ノードが無いと ping は返ってこないが、dig で名前解決はできる
dig +short i2.ocp45.example.localdomain # ノードが無いと ping は返ってこないが、dig で名前解決はできる
dig +short i3.ocp45.example.localdomain # ノードが無いと ping は返ってこないが、dig で名前解決はできる
dig +norec -x 172.16.0.41 +short # Infraノード 1 のIPの逆引き
dig +norec -x 172.16.0.42 +short # Infraノード 2 のIPの逆引き
dig +norec -x 172.16.0.43 +short # Infraノード 3 のIPの逆引き
8.2.1.Infraノードとしてのラベルを貼る
Workerノードが完成したら、Infraノードとしてのラベルを振ります。
# oc label node i1.ocp45.example.localdomain node-role.kubernetes.io/infra=
# oc label node i2.ocp45.example.localdomain node-role.kubernetes.io/infra=
# oc label node i3.ocp45.example.localdomain node-role.kubernetes.io/infra=
検索するとWorkerノードとしてのRoleを外す手順が出てくる場合がありますが、worker Role のラベルは外さなくても大丈夫です。
(workerラベルを外す場合は、Maching Config Poolという追加リソースを作成する必要がでてきます。)
infraラベルが貼られている事を確認します。
[root@bastion openshift]# oc get nodes
NAME STATUS ROLES AGE VERSION
i1.ocp45.example.localdomain Ready infra,worker 15h v1.18.3+47c0e71
i2.ocp45.example.localdomain Ready infra,worker 15h v1.18.3+47c0e71
i3.ocp45.example.localdomain Ready infra,worker 15h v1.18.3+47c0e71
m1.ocp45.example.localdomain Ready master 15h v1.18.3+47c0e71
m2.ocp45.example.localdomain Ready master 15h v1.18.3+47c0e71
m3.ocp45.example.localdomain Ready master 15h v1.18.3+47c0e71
s1.ocp45.example.localdomain Ready infra,worker 66m v1.18.3+47c0e71
s2.ocp45.example.localdomain Ready infra,worker 66m v1.18.3+47c0e71
s3.ocp45.example.localdomain Ready infra,worker 66m v1.18.3+47c0e71
w1.ocp45.example.localdomain Ready worker 15h v1.18.3+47c0e71
w2.ocp45.example.localdomain Ready worker 15h v1.18.3+47c0e71
w3.ocp45.example.localdomain Ready worker 15h v1.18.3+47c0e71
[root@bastion openshift]#
8.2.2 Load Balancer の設定にInfraノードを追加する。
Infraノードに各種コンポーネントを移動させるので、この環境でのLoad BalancerであるHA Proxyに、Infraノードを登録します。
Load Balancerである HA Proxyサーバーに移動して、/etc/haproxy/haproxy.cfgを編集します。
<省略>
backend machine_config
mode tcp
balance roundrobin
server bs bs.ocp45.example.localdomain:22623 check
server m1 m1.ocp45.example.localdomain:22623 check
server m2 m2.ocp45.example.localdomain:22623 check
server m3 m3.ocp45.example.localdomain:22623 check
backend worker_http
mode tcp
balance source
server i1 i1.ocp45.example.localdomain:80 check # 追加
server i2 i2.ocp45.example.localdomain:80 check # 追加
server i3 i3.ocp45.example.localdomain:80 check # 追加
server w1 w1.ocp45.example.localdomain:80 check
server w2 w2.ocp45.example.localdomain:80 check
server w3 w3.ocp45.example.localdomain:80 check
backend worker_https
mode tcp
balance source
server i1 i1.ocp45.example.localdomain:443 check # 追加
server i2 i2.ocp45.example.localdomain:443 check # 追加
server i3 i3.ocp45.example.localdomain:443 check # 追加
server w1 w1.ocp45.example.localdomain:443 check
server w2 w2.ocp45.example.localdomain:443 check
server w3 w3.ocp45.example.localdomain:443 check
設定を変更したら、有効化します。
systemctl restart haproxy
8.2.3 Infraノードに taint を付ける
以下のコマンドで、Infraノードにtaintを付けます。
taintは、KubernetesのPodのスケジューリングを意図通りに行うために使われるテクニックの一つです。(参考:TaintとToleration)
taintを付ける前に、OpenShift ConsoleのHome→OverviewでAlertが上がってないか確認し作業前の状態に問題が無いか確認して下さい。
taintを付ける事でコンテナの移動が発生する事があり、一時的な警告などが表示される事があります。元から出ていた警告・エラーなのか、taintの追加により発生した警告・エラーなのか判別するために事前に状態を確認しておきます。
taintは、Key=Value:Effectの形式で表されますが、ここではInfraノードに
infra=reserved:NoSchedule
infra=reserved:NoExecute
の2つのtaintを付けます。
oc adm taint node i1.ocp45.example.localdomain infra=reserved:NoSchedule infra=reserved:NoExecute
oc adm taint node i2.ocp45.example.localdomain infra=reserved:NoSchedule infra=reserved:NoExecute
oc adm taint node i3.ocp45.example.localdomain infra=reserved:NoSchedule infra=reserved:NoExecute
taintは以下のコマンドで確認できます。
oc describe node <node名>
<省略>
CreationTimestamp: Sat, 10 Oct 2020 01:00:40 +0900
Taints: infra=reserved:NoExecute
infra=reserved:NoSchedule
Unschedulable: false
<省略>
taintを付ける事で、これまでInfraノード上に配置されていた、tolerationの無い一部のコンテナがInfraノード外に追い出されます。
OpenShift ConsoleのHome->Overviewで状態が落ち着くまでAlertを確認して下さい。
特に問題が無さそうであればInfraノードのセットアップは完了です。
8.3.Cluster Logging のセットアップ
この手順はPVを作成できるようになっている事が前提です。
OpenShiftでは、ロギングにEKF(ElastictSearch/Fluented/Kibana)スタックを使用しています。OpenShiftではこれをひとまとめにCluster Loggingと読んでいます。
以下の手順を参考にCluster Loggingをインストールします。独立した手順として成り立たせるために、Infraノードの作成についても書いてますが、その部分は、セクション「8.2.infraノードの作成」 と同じなのでスキップして大丈夫です。
OpenShift 上に Cluster Logging (EFK) をインストールする
8.4.Container Registry の作成
OpenShift 上にOpenShift標準のContainer Registryを作成します。
この手順は、OCSがインターナルモード(OpenShiftのクラスター内のノードとして稼働)で作成されている事が前提です。
(OCSで無いストレージを使用している場合は、Storage Class名が、使用するストレージが提供しているStorage Class名になります)
8.4.1.Registry 用 Storage Class と PVC の実行
既存のOCSのFileSystem用のStorageClassの定義ocs-storagecluster-cephfsを元に、新しいStroageClassを作成します。
oc get sc ocs-storagecluster-cephfs -o yaml > my-sc-fs.yaml
上記で出力したStorage Classの定義を元に編集して、Storage Class名my-registry-fs-scを作成します。
デフォルトで用意されているStorage Classは、Reclaim Policyが、Deleteです。
一応、Cotainer Registryに保管されるデータは、その企業の資産とも言えるので、Reclaim PolicyをRetainに書き替えた新しいStorage Classを作ります。
allowVolumeExpansion: true
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: my-registry-fs-sc # my-registry-fs-sc という名前を付けます。
parameters:
clusterID: openshift-storage
csi.storage.k8s.io/controller-expand-secret-name: rook-csi-cephfs-provisioner
csi.storage.k8s.io/controller-expand-secret-namespace: openshift-storage
csi.storage.k8s.io/node-stage-secret-name: rook-csi-cephfs-node
csi.storage.k8s.io/node-stage-secret-namespace: openshift-storage
csi.storage.k8s.io/provisioner-secret-name: rook-csi-cephfs-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: openshift-storage
fsName: ocs-storagecluster-cephfilesystem
provisioner: openshift-storage.cephfs.csi.ceph.com
reclaimPolicy: Retain # ここを Delete から Retainに
volumeBindingMode: Immediate
作成したmy-sc-fs.yamlを適用します。
oc apply -f my-sc-fs.yaml
新しいSC(Storage Class)ができた事を確認します
# oc get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
localblock kubernetes.io/no-provisioner Delete WaitForFirstConsumer false 2d12h
my-registry-fs-sc openshift-storage.noobaa.io/obc Retain Immediate false 2m16s
ocs-storagecluster-ceph-rbd openshift-storage.rbd.csi.ceph.com Delete Immediate true 2d12h
ocs-storagecluster-ceph-rgw openshift-storage.ceph.rook.io/bucket Delete Immediate false 2d12h
ocs-storagecluster-cephfs openshift-storage.cephfs.csi.ceph.com Delete Immediate true 2d12h
openshift-storage.noobaa.io openshift-storage.noobaa.io/obc Delete Immediate false 2d12h
Storage Class名、my-registry-fs-scが作成されています。
次に作成したStorage Classを使ってPVをClaimするために、以下のような、PVC(Persistent Volume Claim)定義ファイルmy-pvc-fs.yaml を作ります。PVC名は、image-registry-storageで、サイズは100Giにしています。
apiVersion: "v1"
kind: "PersistentVolumeClaim"
metadata:
name: "image-registry-storage"
spec:
accessModes:
- "ReadWriteMany"
resources:
requests:
storage: "100Gi"
storageClassName: "my-registry-fs-sc" # 先ほど作成した Storage Class
以下のコマンドで、作成したmy-pvc-fs.yamlを適用しPVCを作成します。
# oc project openshift-image-registry # まず Registry の Project に移動します。
# oc apply -f my-pvc-fs.yaml
PVCが出来た事を確認します。
# oc get pvc -n openshift-image-registry
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
image-registry-storage Bound pvc-4a3e0b7e-8b30-4753-98aa-95d92d244e26 100Gi RWX my-registry-fs-sc 4s
StatusがBoundになっていればOKです。
8.4.2.Registryの構成
configs.imageregistry.operator.openshift.ioのmanagedStateをMangedに変更します。
oc patch configs.imageregistry.operator.openshift.io cluster --type merge --patch '{"spec":{"managementState":"Managed"}}'
念のためopenshift-image-registryネームスペースのPodが問題なく稼働している事を確認します。
[root@bastion openshift]# oc get pod -n openshift-image-registry
NAME READY STATUS RESTARTS AGE
cluster-image-registry-operator-56d78bc5fb-fckwp 2/2 Running 0 19h
image-registry-58876b649-v48xk 1/1 Running 0 5m51s
node-ca-c5v7p 1/1 Running 0 5h15m
node-ca-cxn2g 1/1 Running 0 19h
node-ca-db25w 1/1 Running 0 19h
node-ca-f2nk8 1/1 Running 0 19h
node-ca-gvng5 1/1 Running 0 19h
node-ca-gzh4m 1/1 Running 0 5h15m
node-ca-j7nxd 1/1 Running 0 19h
node-ca-k652z 1/1 Running 0 19h
node-ca-ls9rp 1/1 Running 0 19h
node-ca-s5v4f 1/1 Running 0 5h15m
node-ca-tg2hz 1/1 Running 0 19h
node-ca-vnq7j 1/1 Running 0 19h
[root@bastion openshift]#
先ほど作成したPVCが、 configs.imageregistry.operator.openshift.ioから参照されるように設定します。
oc edit configs.imageregistry.operator.openshift.io
<省略>
spec:
httpSecret: 4c0857824322cf083be5198d5ca486eeed9afb18c2870fcdef3a78efe21168e545a192ab6b1030c86870ef45072fcbcef0a359c0d435ad04f6cfa2475a0f027e
logging: 2
managementState: Managed
proxy: {}
replicas: 1
requests:
read:
maxWaitInQueue: 0s
write:
maxWaitInQueue: 0s
rolloutStrategy: RollingUpdate
storage: # {} を削除
pvc: # 追加
claim: image-registry-storage # 追加 (前段で作成したPVC名。空欄にした場合でも、この名前が自動でセットされる)
status:
conditions:
- lastTransitionTime: "2020-10-09T15:57:45Z"
reason: AsExpected
status: "False"
<省略>
image-registry Operatorのステータスを確認します。
# oc get clusteroperator image-registry
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE
image-registry 4.5.13 True False True 6m17s
AVAILABLEがTrueになるまで待ちます。数分かかるはずです。
8.4.3.Container Registry のInfraノードへの移動
以下のコマンドで、Container RegsitryをInfraノードに移動させます。
oc patch configs.imageregistry.operator.openshift.io/cluster --type=merge -p '{"spec":{"nodeSelector": {"node-role.kubernetes.io/infra": ""},"tolerations": [{"effect":"NoSchedule","key": "infra","value": "reserved"},{"effect":"NoExecute","key": "infra","value": "reserved"}]}}'
ワンライナーでちょっと読みにくいですが、nodeSelectorでInfraノードを指定し、Infraノードのtaintに弾かれないようにtolerationsを付けています。
確認してみます。
[root@bastion openshift]# oc get pod -n openshift-image-registry
NAME READY STATUS RESTARTS AGE
cluster-image-registry-operator-56d78bc5fb-6kflj 2/2 Running 0 15h
image-pruner-1604016000-2hhx7 0/1 Completed 0 6h34m
image-registry-58579b74c5-pbwr4 1/1 Running 0 2m24s
node-ca-58d7m 1/1 Running 0 14h
node-ca-5h2x9 1/1 Running 0 5h32m
node-ca-5ngxk 1/1 Running 0 14h
node-ca-8cvd6 1/1 Running 0 14h
node-ca-92xtj 1/1 Running 0 14h
node-ca-cxn5g 1/1 Running 0 15h
node-ca-drgkr 1/1 Running 0 15h
node-ca-jdlrd 1/1 Running 0 5h32m
node-ca-jtsls 1/1 Running 0 5h32m
node-ca-n9gl5 1/1 Running 0 14h
node-ca-qbwqc 1/1 Running 0 14h
node-ca-zvtq8 1/1 Running 0 15h
[root@bastion ~]#
どのコンポーネントが何かというのは、見た目で判断するしかないのですが、各ノード毎に置かれているコンポーネント以外の配置について確認してみます。
[root@bastion openshift]# oc describe pods cluster-image-registry-operator-56d78bc5fb-6kflj -n openshift-image-registry | grep Node:
Node: m2.ocp45.example.localdomain/172.16.0.22
[root@bastion openshift]# oc describe pods image-registry-58579b74c5-pbwr4 -n openshift-image-registry | grep Node:
Node: i2.ocp45.example.localdomain/172.16.0.42
[root@bastion openshift]# oc describe pods image-pruner-1604016000-2hhx7 -n openshift-image-registry | grep Node:
Node: s3.ocp45.example.localdomain/172.16.0.53
cluster-image-registry-operator-xxxxは、Masterノード上に配置されていますが、Controllerだと思われるので、これで良い事にします。
image-pruner-xxxxが、Workerノード上で実行された形跡がありますが、これは一時的なPodなので後で問題なさそうですが、後で追求してみます。
この例だとimage-registry-58876b649-v48xkが、Infraノード上にあれば問題なさそうなので、これで良い事にします。
Image Registry の
8.5. RouterのInfraノードへの移動
この手順は、Infraノードが作成されている事が前提になります。
8.5.1.nodeSelectorとtolerationの設定
Infraノードに、Podをスケジュールするには、nodeSelectorで、Infraノードを選択させます。
またInfraノードにユーザーアプリケーションがスケジュールされないように、最終的にInfraノードにtaintを付けます。そのtaintを無視できるようにtolerationもInfraノードにスケジュールするコンポーネントに付ける必要があります。
まとめると、Infraノードにスケジュールする、コンポーネントには、以下の記述をspecに追加します。
spec:
nodePlacement:
nodeSelector:
matchLabels:
node-role.kubernetes.io/infra: ""
tolerations:
- effect: NoSchedule
key: infra
value: reserved
- effect: NoExecute
key: infra
value: reserved
Routerに上記のnodeSelectorとtolerationを追加するために以下のコマンドを実行します。
oc patch ingresscontroller/default -n openshift-ingress-operator --type=merge -p '{"spec":{"nodePlacement": {"nodeSelector": {"matchLabels": {"node-role.kubernetes.io/infra": ""}},"tolerations": [{"effect":"NoSchedule","key": "infra","value": "reserved"},{"effect":"NoExecute","key": "infra","value": "reserved"}]}}}'
さらにデフォルトでは、Routerは、2つしか Replica を持たないので、Infraノードの数に合わせるため3つにします。
oc patch ingresscontroller/default -n openshift-ingress-operator --type=merge -p '{"spec":{"replicas": 3}}'
8.5.2.スケジュールの確認
oc describe node | grep ingress で、ingress関連のコンポーネントの名前を見つけます。
root@bastion openshift]# oc describe node | grep ingress
openshift-ingress router-default-cbbf5f64-fxpzf 100m (2%) 0 (0%) 256Mi (0%) 0 (0%) 4m25s
openshift-ingress router-default-cbbf5f64-m4mhp 100m (2%) 0 (0%) 256Mi (0%) 0 (0%) 4m45s
openshift-ingress router-default-cbbf5f64-g4tvj 100m (2%) 0 (0%) 256Mi (0%) 0 (0%) 4m59s
openshift-ingress-operator ingress-operator-56f5778d85-ddncf 20m (0%) 0 (0%) 40Mi (0%) 0 (0%) 15h
[root@bastion openshift]#
一つ一つ配置を確認してみます。
[root@bastion openshift]# oc describe pod ingress-operator-56f5778d85-ddncf -n openshift-ingress-operator | grep Node:
Node: m2.ocp45.example.localdomain/172.16.0.22
[root@bastion openshift]# oc describe pod router-default-cbbf5f64-fxpzf -n openshift-ingress | grep Node:
Node: i1.ocp45.example.localdomain/172.16.0.41
[root@bastion openshift]# oc describe pod router-default-cbbf5f64-m4mhp -n openshift-ingress | grep Node:
Node: i2.ocp45.example.localdomain/172.16.0.42
[root@bastion openshift]# oc describe pod router-default-cbbf5f64-g4tvj -n openshift-ingress | grep Node:
Node: i3.ocp45.example.localdomain/172.16.0.43
[root@bastion openshift]#
ingress-operator-xxxxは、Masterノードで、その他はinfraノードなので問題なさそうです。
以上で、Routerの設定は完了です。
Routerの設定は以下のKBを参考にしました。
参考:Configuring Infrastructure Nodes with Taint in OpenShift 4
このKBは、他のコンポーネントのinfraノードへのスケジュール方法も書いてますが、気づいた範囲ではPrometheus部分で、Thanosの設定が抜けているようです。
8.6. Prometheus の構成
Prometheus関連のコンポーネントは、OpenShiftではCluster Monitoringと呼ばれています。
OpenShiftのインストールと一緒にPrometheusは既にインストールされて稼働しています。
ここではPrometheusのメインコンポーネントを、Infraノードに移動させデータ保管用にPVを作成します。
この作業はPrometheus設定用のConfigMapを作成する事で実現できます。
8.6.1. Prometheus 用のPVの作成とInfraノードへの移動
以下のcluster-monitoring-configmap.yamlを作成します。
Promethuesの各コンポーネントに、nodeSelectorを使ってInfraノードに配置するよう指定する事と、Infraノードに付いているtaintを無視するようにtolerationを付けたConfigMapリソースを作成しています。
ここではログ保管用に40GiのPVCをしていいます。事前にPVCをする事でPVが作成される環境である事を想定しています。
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
data:
config.yaml: |+
alertmanagerMain:
nodeSelector: # nodeSelectorでinfraを選ぶ
node-role.kubernetes.io/infra: ""
tolerations: # toleration を付ける
- key: infra
value: reserved
effect: NoSchedule
- key: infra
value: reserved
effect: NoExecute
prometheusK8s:
volumeClaimTemplate: # volumeCliaimTemplate
spec: # 追加
storageClassName: ocs-storagecluster-cephfs # Ceph FileSystem の Storage Class
volumeMode: Filesystem # FileSystem
resources: # 追加
requests: # 追加
storage: 40Gi # Size はとりあえず 40Gi
nodeSelector: # nodeSelectorでinfraを選ぶ
node-role.kubernetes.io/infra: ""
tolerations: # toleration を付ける
- key: infra
value: reserved
effect: NoSchedule
- key: infra
value: reserved
effect: NoExecute
prometheusOperator:
nodeSelector: # nodeSelectorでinfraを選ぶ
node-role.kubernetes.io/infra: ""
tolerations: # toleration を付ける
- key: infra
value: reserved
effect: NoSchedule
- key: infra
value: reserved
effect: NoExecute
grafana:
nodeSelector: # nodeSelectorでinfraを選ぶ
node-role.kubernetes.io/infra: ""
tolerations: # toleration を付ける
- key: infra
value: reserved
effect: NoSchedule
- key: infra
value: reserved
effect: NoExecute
k8sPrometheusAdapter:
nodeSelector: # nodeSelectorでinfraを選ぶ
node-role.kubernetes.io/infra: ""
tolerations: # toleration を付ける
- key: infra
value: reserved
effect: NoSchedule
- key: infra
value: reserved
effect: NoExecute
kubeStateMetrics:
nodeSelector: # nodeSelectorでinfraを選ぶ
node-role.kubernetes.io/infra: ""
tolerations: # toleration を付ける
- key: infra
value: reserved
effect: NoSchedule
- key: infra
value: reserved
effect: NoExecute
telemeterClient:
nodeSelector: # nodeSelectorでinfraを選ぶ
node-role.kubernetes.io/infra: ""
tolerations: # toleration を付ける
- key: infra
value: reserved
effect: NoSchedule
- key: infra
value: reserved
effect: NoExecute
openshiftStateMetrics:
nodeSelector: # nodeSelectorでinfraを選ぶ
node-role.kubernetes.io/infra: ""
tolerations: # toleration を付ける
- key: infra
value: reserved
effect: NoSchedule
- key: infra
value: reserved
effect: NoExecute
thanosQuerier:
nodeSelector: # nodeSelectorでinfraを選ぶ
node-role.kubernetes.io/infra: ""
tolerations: # toleration を付ける
- key: infra
value: reserved
effect: NoSchedule
- key: infra
value: reserved
effect: NoExecute
作成したファイルを適用します。
oc create -f cluster-monitoring-configmap.yaml
PVCができているか確認します。
# oc get pvc -n openshift-monitoring
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
prometheus-k8s-db-prometheus-k8s-0 Bound pvc-78175f98-d22e-4023-96ac-6bf2a92b973b 40Gi RWO ocs-storagecluster-cephfs 36s
prometheus-k8s-db-prometheus-k8s-1 Bound pvc-22975d1f-47ed-40a5-b1d6-5131c22dab36 40Gi RWO ocs-storagecluster-cephfs 35s
2つPVCが出来ていてStatusがBoundになっていればOKです。
各コンポーネントの配置を確認してみます。
[root@bastion ~]# oc get pods -n openshift-monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 5/5 Running 0 20h
alertmanager-main-1 5/5 Running 0 20h
alertmanager-main-2 5/5 Running 0 20h
cluster-monitoring-operator-79d58c4598-hqrc7 2/2 Running 2 39h
grafana-859c496b85-84rnh 2/2 Running 0 20h
kube-state-metrics-ff7bbdd5c-bwjwt 3/3 Running 0 20h
node-exporter-2ptbn 2/2 Running 0 39h <== これは Node毎にある。
node-exporter-65ckx 2/2 Running 0 39h
node-exporter-94kpv 2/2 Running 0 25h
node-exporter-9gfrm 2/2 Running 0 39h
node-exporter-bmfmb 2/2 Running 0 39h
node-exporter-g5pt6 2/2 Running 0 25h
node-exporter-l7qsx 2/2 Running 0 39h
node-exporter-mmw2f 2/2 Running 0 39h
node-exporter-rvq5j 2/2 Running 0 25h
node-exporter-rvs6h 2/2 Running 0 39h
node-exporter-z7pbv 2/2 Running 0 39h
node-exporter-zzhv6 2/2 Running 0 39h
openshift-state-metrics-674b677b97-5m9bk 3/3 Running 0 20h
prometheus-adapter-ccfbd8b84-wbvbk 1/1 Running 0 16h
prometheus-adapter-ccfbd8b84-xx8mc 1/1 Running 0 16h
prometheus-k8s-0 7/7 Running 0 5h18m
prometheus-k8s-1 7/7 Running 0 5h19m
prometheus-operator-7bf95c767d-9b9wp 2/2 Running 0 20h
telemeter-client-76966457-8k5g6 3/3 Running 0 20h
thanos-querier-867c77f45d-d8gg2 4/4 Running 0 4m56s
thanos-querier-867c77f45d-k4h84 4/4 Running 0 5m15s
ノード毎に必要なexporter以外の配置を確認してみます。
[root@bastion ~]# oc describe pods alertmanager-main-0 -n openshift-monitoring | grep Node:
Node: i1.ocp45.example.localdomain/172.16.0.41
[root@bastion ~]# oc describe pods alertmanager-main-1 -n openshift-monitoring | grep Node:
Node: i2.ocp45.example.localdomain/172.16.0.42
[root@bastion ~]# oc describe pods alertmanager-main-2 -n openshift-monitoring | grep Node:
Node: i3.ocp45.example.localdomain/172.16.0.43
[root@bastion ~]# oc describe pods cluster-monitoring-operator-79d58c4598-hqrc7 -n openshift-monitoring | grep Node:
Node: m2.ocp45.example.localdomain/172.16.0.22
[root@bastion ~]# oc describe pods grafana-859c496b85-84rnh -n openshift-monitoring | grep Node:
Node: i2.ocp45.example.localdomain/172.16.0.42
[root@bastion ~]# oc describe pods kube-state-metrics-ff7bbdd5c-bwjwt -n openshift-monitoring | grep Node:
Node: i1.ocp45.example.localdomain/172.16.0.41
[root@bastion ~]# oc describe pods kube-state-metrics-ff7bbdd5c-bwjwt -n openshift-monitoring | grep Node:
Node: i1.ocp45.example.localdomain/172.16.0.41
[root@bastion ~]# oc describe pods openshift-state-metrics-674b677b97-5m9bk -n openshift-monitoring | grep Node:
Node: i2.ocp45.example.localdomain/172.16.0.42
[root@bastion ~]# oc describe pods prometheus-adapter-ccfbd8b84-wbvbk -n openshift-monitoring | grep Node:
Node: i2.ocp45.example.localdomain/172.16.0.42
[root@bastion ~]# oc describe pods prometheus-adapter-ccfbd8b84-xx8mc -n openshift-monitoring | grep Node:
Node: i3.ocp45.example.localdomain/172.16.0.43
[root@bastion ~]# oc describe pods prometheus-k8s-0 -n openshift-monitoring | grep Node:
Node: i3.ocp45.example.localdomain/172.16.0.43
[root@bastion ~]# oc describe pods prometheus-k8s-1 -n openshift-monitoring | grep Node:
Node: i2.ocp45.example.localdomain/172.16.0.42
[root@bastion ~]# oc describe pods prometheus-operator-7bf95c767d-9b9wp -n openshift-monitoring | grep Node:
Node: i2.ocp45.example.localdomain/172.16.0.42
[root@bastion ~]# oc describe pods telemeter-client-76966457-8k5g6 -n openshift-monitoring | grep Node:
Node: i1.ocp45.example.localdomain/172.16.0.41
[root@bastion openshift]# oc describe pods thanos-querier-867c77f45d-d8gg2 -n openshift-monitoring | grep Node:
Node: i2.ocp45.example.localdomain/172.16.0.42
[root@bastion openshift]# oc describe pods thanos-querier-867c77f45d-k4h84 -n openshift-monitoring | grep Node:
Node: i1.ocp45.example.localdomain/172.16.0.41
[root@bastion openshift]#
概ね必要なコンポーネントは、Infraノードに配置されているようです。
cluster-monitoring-operator-xxx がMasterノードに配置されていましたが、これは指定方法がマニュアルになかったのと、このままで良さそうなので設計通りなのかもしれません。
概ねInfraノードに配置されているという事で、良い事にします。
参考: 1.1. About cluster monitoring
8.7. Workerノード の Load Balancer からの削除
HTTP/HTTPS トラフィックは、この環境でのLoad BalancerであるHA Proxyから、Infraノード上のRouterで一旦受けた後、Podに割り振られます。
WorkerノードでLoad Balancer(HA Proxy)から直接トラフィックを受け取る必要がないので、HA Proxyの設定からWorkerノードを取り外します。
また、好みの問題ですが、xxxxx_workerhttp(s) だった部分 をxxxxx_infrahttp(s)に置き換えています。
<省略>
frontend infrahttp # 名前の変更
default_backend infra_http # 名前の変更
mode tcp
bind *:80
frontend infrahttps # 名前の変更
default_backend infra_https # 名前の変更
mode tcp
bind *:443
<省略>
backend infra_http # 名前の変更
mode tcp
balance source
server i1 i1.ocp45.example.localdomain:80 check
server i2 i2.ocp45.example.localdomain:80 check
server i3 i3.ocp45.example.localdomain:80 check
backend infra_https # 名前の変更
mode tcp
balance source
server i1 i1.ocp45.example.localdomain:443 check
server i2 i2.ocp45.example.localdomain:443 check
server i3 i3.ocp45.example.localdomain:443 check
設定を変更したら、有効化します。
haproxy -f /etc/haproxy/haproxy.cfg -c # 構成の確認
systemctl restart haproxy # 再起動
現在、OpenShift Consoleの入り口となるRouter(OpenShiftのIngress)は、Infraノードに配置されているはずなので、アクセスできるかどうか確認してみてください。(OpneShiftのConsoleのPodは、、Masterノードに配置されています。)
9.(番外編) OpenShift クラスタ-インストール時のDebug
OpenShiftクラスターのインストールは、手順が多いのでミスをしないで進めることはなかなか大変です。
ここでは、クラスターのインストール時に使えそうなデバック手法について、幾つか解説します。
9.1. ignition ファイルの期限切れ
はじめのインストールは時間がかかります。そうこうしているうちにセクション[「4.2.3.ignition ファイルの作成 (manifestファイルのignitionファイルへの変換)」] (#423ignition-ファイルの作成-manifestファイルのignitionファイルへの変換)で作成した ignition ファイルが期限切れしている事があります。これらのファイルの期限は24時間ですので、もし24時間経過していたらこのファイルを再作成する必要があります。
9.2. ネットワークの設定確認
経験上、エラーの殆どはネットワーク設定に起因します。
UPIインストールは、OpenShiftのIPIインストールよりも、周辺サーバーの構築が作業の殆どのウェイトを占めるためミスを誘発する要素を大量に含んでいます。
沼に吸い込まれる前に、まずはネットワークの確認を(面倒でも)確認して足下を固めましょう。
1.ロードバランサーは正しく構成されているか
2.ドメイン名は正しく解決されるか
3.ポートは正しく開いているか(firewalldが邪魔していないか)
4.SELinuxが動作を邪魔していないか
5.必要なファイルは、boostrap/master/workerノードから正しくアクセスできているか
これらの確認方法に決まった手順があるわけではないので、これまでの知識を総動員して動きを確認してみましょう。
また、セクション「6.ネットワーク環境の疎通確認」に記載されているネットワークの疎通確認は、是非とももう一度試して見て下さい。いろいろいじっているうちに構成を変更してしまい、上手く動いてない可能性もあります。
9.3. oc get nodes コマンドを打ってみる
以下は、host名の逆引きができない状態でインストールを行い、インストールが失敗した時に oc get nodes を実行してみた時の結果です。
[root@bastion openshift]# oc get nodes
NAME STATUS ROLES AGE VERSION
localhost Ready master,worker 32m v1.18.3+47c0e71
[root@bastion openshift]#
通常は、node のホスト名が入る場所に localhost と入ってます。ここから「もしかして名前の逆引きができる必要があるのでは?」と推理を働かせる事ができます。(その推理が当たっているかどうかは定かではありませんが)
oc describe node localhost で、この node の IPが何なのか情報が取れます。
[root@bastion openshift]# oc describe node localhost
Name: localhost
Roles: master,worker
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=localhost
kubernetes.io/os=linux
node-role.kubernetes.io/master=
node-role.kubernetes.io/worker=
node.openshift.io/os_id=rhcos
Annotations: machineconfiguration.openshift.io/currentConfig: rendered-master-42e06c66fbcaf5796b9413e85dc2d752
machineconfiguration.openshift.io/desiredConfig: rendered-master-42e06c66fbcaf5796b9413e85dc2d752
machineconfiguration.openshift.io/reason:
machineconfiguration.openshift.io/state: Done
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Fri, 02 Oct 2020 17:12:17 +0900
Taints: <none>
Unschedulable: false
Lease:
HolderIdentity: localhost
AcquireTime: <unset>
RenewTime: Fri, 02 Oct 2020 17:47:27 +0900
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
MemoryPressure False Fri, 02 Oct 2020 17:47:24 +0900 Fri, 02 Oct 2020 17:12:17 +0900 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Fri, 02 Oct 2020 17:47:24 +0900 Fri, 02 Oct 2020 17:12:17 +0900 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Fri, 02 Oct 2020 17:47:24 +0900 Fri, 02 Oct 2020 17:12:17 +0900 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Fri, 02 Oct 2020 17:47:24 +0900 Fri, 02 Oct 2020 17:14:18 +0900 KubeletReady kubelet is posting ready status
Addresses:
InternalIP: 172.16.0.21
Hostname: localhost
Capacity:
<略>
InternalIP: 172.16.0.21 とあり、これはこの環境では、MasterノードのIPとして提供したものなので、この謎のlocalhostは、Masterノードであるようです。
このことから「Masterノードが上がってきているという事は、BootStrapノードは正しくセットアップされた。という可能性が高いな」と想像する事ができます。(これもまたその推理が正しいか保証はありませんが)
こういった情報が、実際、どんな役に立つかは状況次第ですが、こう言った情報を集めてどの辺りが悪そうか当たりをつけていきましょう。
9.4. インストール中の CoreOS 内のログの観察
インストール中の Boostrap Node や Masterノードにログインしてインストールの経過を見る事ができます。
もしインストールが上手く行かなかった場合 BootStrapノード にログインして状況を確認すると何か原因のヒントがつかめるかもしれません。
CoreOS は core というユーザーと、インストール時に作成した公開鍵、秘密鍵の秘密鍵を使って ssh ログインする事ができます。
BootStrap ノードのログイン画面がでたらすかさず以下のコマンドで、踏み台サーバー(通常 SSHキーをそこに保存して、ここからインストールコマンドを実行していると思います) から SSH ログインします。(ログイン画面からはログインできません)
[root@bastion .ssh]# ssh core@bs -i <作成した秘密鍵>
※bs=この環境での BootStrapノードです。ここでは bs で bootstrap のノードIPに名前解決されるように /etc/hosts に登録済みです。この解説を読んでいる時点で、あなたは既に魔物に囚われているはずです。そうそう抜け出せないので/etc/hosts には、各ノードのホスト名を登録して起きましょう。これからの長い修行(デバッグ)が楽になります。
※ノードを作り直した場合は、bastion サーバー上の ./ssh/known_hosts から、bootstrap サーバーの登録を削除する必要があります。
CoreOS内では、journalctl コマンドでログが確認できます。例えば、bootkube サービスのログを見るには以下のようにします。
journalctl -b -f -u release-image.service -u bootkube.service
CoreOS 内のサービス・ログの読み方の注意
以下は、bootstrapノードでjournalctl -b -f -u release-image.service -u bootkube.service コマンドで、bootkube サービスのログを確認した時の抜粋です。
途中に大量に fail という文字がでて[#171] failed to create some manifests: というような文字も見えます。
Sep 28 13:38:24 localhost bootkube.sh[2632]: Failed to create "openshift-install-manifests.yaml" configmaps.v1./openshift-install-manifests -n openshift-config: namespaces "openshift-config" not found
Sep 28 13:38:24 localhost bootkube.sh[2632]: Failed to create "secret-initial-kube-controller-manager-service-account-private-key.yaml" secrets.v1./initial-service-account-private-key -n openshift-config: namespaces "openshift-config" not found
Sep 28 13:38:24 localhost bootkube.sh[2632]: [#170] failed to create some manifests:
Sep 28 13:38:24 localhost bootkube.sh[2632]: "99_openshift-machineconfig_99-master-ssh.yaml": unable to get REST mapping for "99_openshift-machineconfig_99-master-ssh.yaml": no matches for kind "MachineConfig" in version "machineconfiguration.openshift.io/v1"
Sep 28 13:38:24 localhost bootkube.sh[2632]: "99_openshift-machineconfig_99-worker-ssh.yaml": unable to get REST mapping for "99_openshift-machineconfig_99-worker-ssh.yaml": no matches for kind "MachineConfig" in version "machineconfiguration.openshift.io/v1"
Sep 28 13:38:24 localhost bootkube.sh[2632]: "configmap-admin-kubeconfig-client-ca.yaml": failed to create configmaps.v1./admin-kubeconfig-client-ca -n openshift-config: namespaces "openshift-config" not found
Sep 28 13:38:24 localhost bootkube.sh[2632]: "configmap-csr-controller-ca.yaml": failed to create configmaps.v1./csr-controller-ca -n openshift-config-managed: namespaces "openshift-config-managed" not found
Sep 28 13:38:24 localhost bootkube.sh[2632]: "configmap-initial-etcd-serving-ca.yaml": failed to create configmaps.v1./initial-etcd-ca -n openshift-config: namespaces "openshift-config" not found
Sep 28 13:38:24 localhost bootkube.sh[2632]: "configmap-kubelet-bootstrap-kubeconfig-ca.yaml": failed to create configmaps.v1./kubelet-bootstrap-kubeconfig -n openshift-config-managed: namespaces "openshift-config-managed" not found
Sep 28 13:38:24 localhost bootkube.sh[2632]: "configmap-sa-token-signing-certs.yaml": failed to create configmaps.v1./sa-token-signing-certs -n openshift-config-managed: namespaces "openshift-config-managed" not found
Sep 28 13:38:24 localhost bootkube.sh[2632]: "etcd-ca-bundle-configmap.yaml": failed to create configmaps.v1./etcd-ca-bundle -n openshift-config: namespaces "openshift-config" not found
Sep 28 13:38:24 localhost bootkube.sh[2632]: "etcd-client-secret.yaml": failed to create secrets.v1./etcd-client -n openshift-config: namespaces "openshift-config" not found
Sep 28 13:38:24 localhost bootkube.sh[2632]: "etcd-metric-client-secret.yaml": failed to create secrets.v1./etcd-metric-client -n openshift-config: namespaces "openshift-config" not found
Sep 28 13:38:24 localhost bootkube.sh[2632]: "etcd-metric-serving-ca-configmap.yaml": failed to create configmaps.v1./etcd-metric-serving-ca -n openshift-config: namespaces "openshift-config" not found
Sep 28 13:38:24 localhost bootkube.sh[2632]: "etcd-metric-signer-secret.yaml": failed to create secrets.v1./etcd-metric-signer -n openshift-config: namespaces "openshift-config" not found
Sep 28 13:38:24 localhost bootkube.sh[2632]: "etcd-serving-ca-configmap.yaml": failed to create configmaps.v1./etcd-serving-ca -n openshift-config: namespaces "openshift-config" not found
Sep 28 13:38:24 localhost bootkube.sh[2632]: "etcd-signer-secret.yaml": failed to create secrets.v1./etcd-signer -n openshift-config: namespaces "openshift-config" not found
Sep 28 13:38:24 localhost bootkube.sh[2632]: "kube-apiserver-serving-ca-configmap.yaml": failed to create configmaps.v1./initial-kube-apiserver-server-ca -n openshift-config: namespaces "openshift-config" not found
Sep 28 13:38:24 localhost bootkube.sh[2632]: "openshift-config-secret-pull-secret.yaml": failed to create secrets.v1./pull-secret -n openshift-config: namespaces "openshift-config" not found
Sep 28 13:38:24 localhost bootkube.sh[2632]: "openshift-install-manifests.yaml": failed to create configmaps.v1./openshift-install-manifests -n openshift-config: namespaces "openshift-config" not found
Sep 28 13:38:24 localhost bootkube.sh[2632]: "secret-initial-kube-controller-manager-service-account-private-key.yaml": failed to create secrets.v1./initial-service-account-private-key -n openshift-config: namespaces "openshift-config" not found
Sep 28 13:38:24 localhost bootkube.sh[2632]: Created "configmap-admin-kubeconfig-client-ca.yaml" configmaps.v1./admin-kubeconfig-client-ca -n openshift-config
Sep 28 13:38:24 localhost bootkube.sh[2632]: Created "configmap-csr-controller-ca.yaml" configmaps.v1./csr-controller-ca -n openshift-config-managed
Sep 28 13:38:25 localhost bootkube.sh[2632]: Created "configmap-initial-etcd-serving-ca.yaml" configmaps.v1./initial-etcd-ca -n openshift-config
Sep 28 13:38:25 localhost bootkube.sh[2632]: Created "configmap-kubelet-bootstrap-kubeconfig-ca.yaml" configmaps.v1./kubelet-bootstrap-kubeconfig -n openshift-config-managed
Sep 28 13:38:25 localhost bootkube.sh[2632]: Created "configmap-sa-token-signing-certs.yaml" configmaps.v1./sa-token-signing-certs -n openshift-config-managed
Sep 28 13:38:25 localhost bootkube.sh[2632]: Created "etcd-ca-bundle-configmap.yaml" configmaps.v1./etcd-ca-bundle -n openshift-config
Sep 28 13:38:25 localhost bootkube.sh[2632]: Created "etcd-client-secret.yaml" secrets.v1./etcd-client -n openshift-config
Sep 28 13:38:26 localhost bootkube.sh[2632]: Created "etcd-metric-client-secret.yaml" secrets.v1./etcd-metric-client -n openshift-config
Sep 28 13:38:26 localhost bootkube.sh[2632]: Created "etcd-metric-serving-ca-configmap.yaml" configmaps.v1./etcd-metric-serving-ca -n openshift-config
Sep 28 13:38:26 localhost bootkube.sh[2632]: Created "etcd-metric-signer-secret.yaml" secrets.v1./etcd-metric-signer -n openshift-config
Sep 28 13:38:26 localhost bootkube.sh[2632]: Created "etcd-serving-ca-configmap.yaml" configmaps.v1./etcd-serving-ca -n openshift-config
Sep 28 13:38:26 localhost bootkube.sh[2632]: Created "etcd-signer-secret.yaml" secrets.v1./etcd-signer -n openshift-config
Sep 28 13:38:27 localhost bootkube.sh[2632]: Created "kube-apiserver-serving-ca-configmap.yaml" configmaps.v1./initial-kube-apiserver-server-ca -n openshift-config
Sep 28 13:38:27 localhost bootkube.sh[2632]: Created "openshift-config-secret-pull-secret.yaml" secrets.v1./pull-secret -n openshift-config
Sep 28 13:38:27 localhost bootkube.sh[2632]: Created "openshift-install-manifests.yaml" configmaps.v1./openshift-install-manifests -n openshift-config
Sep 28 13:38:27 localhost bootkube.sh[2632]: Created "secret-initial-kube-controller-manager-service-account-private-key.yaml" secrets.v1./initial-service-account-private-key -n openshift-config
Sep 28 13:38:27 localhost bootkube.sh[2632]: [#171] failed to create some manifests:
Sep 28 13:38:27 localhost bootkube.sh[2632]: "99_openshift-machineconfig_99-master-ssh.yaml": unable to get REST mapping for "99_openshift-machineconfig_99-master-ssh.yaml": no matches for kind "MachineConfig" in version "machineconfiguration.openshift.io/v1"
Sep 28 13:38:27 localhost bootkube.sh[2632]: "99_openshift-machineconfig_99-worker-ssh.yaml": unable to get REST mapping for "99_openshift-machineconfig_99-worker-ssh.yaml": no matches for kind "MachineConfig" in version "machineconfiguration.openshift.io/v1"
Sep 28 13:38:27 localhost bootkube.sh[2632]: Created "99_openshift-machineconfig_99-master-ssh.yaml" machineconfigs.v1.machineconfiguration.openshift.io/99-master-ssh -n
Sep 28 13:38:28 localhost bootkube.sh[2632]: Created "99_openshift-machineconfig_99-worker-ssh.yaml" machineconfigs.v1.machineconfiguration.openshift.io/99-worker-ssh -n
ここで
Sep 28 13:38:24 localhost bootkube.sh[2632]: "configmap-admin-kubeconfig-client-ca.yaml": failed to create configmaps.v1./admin-kubeconfig-client-ca -n openshift-config: namespaces "openshift-config" not found`
という一行に注目してみると、failed to create になっていますが、数行下の同じタイムスタンプで、以下の様に Created とでています。
Sep 28 13:38:24 localhost bootkube.sh[2632]: Created "configmap-admin-kubeconfig-client-ca.yaml" configmaps.v1./admin-kubeconfig-client-ca -n openshift-config
fail は、問題が無い場合でもログ内に大量に記録されているので、その後に何らかの成功ログが無いか注意して判別する必要があります。
エラーでは無いエラーを追いかけると、間違った方向に連れてかれてしまうので、読むのは大変ですが3K(気合いと根性と感性) を使って頑張りましょう。
9.5. HAProxy の動作の観察
ロードバランサー(HAProxy)には、インストール中、踏み台サーバー、BootStrap、Masterからのアクセスが集まってきます。
Sep 29 16:02:59 localhost haproxy[69855]: Connect from 172.16.0.23:55618 to 172.16.0.110:22623 (machineconfig/TCP)
Sep 29 16:03:03 localhost haproxy[69855]: Connect from 172.16.0.21:36944 to 172.16.0.110:22623 (machineconfig/TCP)
Sep 29 16:03:03 localhost haproxy[69855]: Connect from 172.16.0.22:45350 to 172.16.0.110:22623 (machineconfig/TCP)
Sep 29 16:03:04 localhost haproxy[69855]: Connect from 172.16.0.23:55620 to 172.16.0.110:22623 (machineconfig/TCP)
Sep 29 16:03:08 localhost haproxy[69855]: Connect from 172.16.0.21:36946 to 172.16.0.110:22623 (machineconfig/TCP)
Sep 29 16:03:08 localhost haproxy[69855]: Connect from 172.16.0.22:45352 to 172.16.0.110:22623 (machineconfig/TCP)
Sep 29 16:03:08 localhost haproxy[69855]: Server machine_config/bs is UP, reason: Layer4 check passed, check duration: 0ms. 1 active and 0 backup servers online. 0 sessions requeued, 0 total in queue.
Sep 29 16:03:09 localhost haproxy[69855]: Connect from 172.16.0.23:55622 to 172.16.0.110:22623 (machineconfig/TCP)
Sep 29 16:03:12 localhost haproxy[69855]: Connect from 192.168.124.201:58070 to 192.168.124.110:6443 (kubeapi/TCP)
Sep 29 16:03:13 localhost haproxy[69855]: Connect from 172.16.0.21:36948 to 172.16.0.110:22623 (machineconfig/TCP)
Sep 29 16:03:13 localhost haproxy[69855]: Connect from 172.16.0.22:45354 to 172.16.0.110:22623 (machineconfig/TCP)
Message from syslogd@localhost at Sep 29 03:03:15 ...
haproxy[69855]: backend kube_api has no server available!
Sep 29 16:03:15 localhost haproxy[69855]: Server kube_api/bs is DOWN, reason: Layer4 connection problem, info: "Connection refused", check duration: 0ms. 0 active and 0 backup servers left. 0 sessions active, 0 requeued, 0 remaining in queue.
Sep 29 16:03:15 localhost haproxy[69855]: backend kube_api has no server available!
Sep 29 16:03:17 localhost haproxy[69855]: Connect from 192.168.124.201:58072 to 192.168.124.110:6443 (kubeapi/TCP)
Sep 29 16:03:19 localhost haproxy[69855]: Connect from 192.168.124.201:58074 to 192.168.124.110:6443 (kubeapi/TCP)
172.16.0.21~23 は、Master1~Master3 のIPアドレスで、何らかの活動中である事が見て取れます。
上記のログを見ると、途中で
haproxy[69855]: backend kube_api has no server available!
Sep 29 16:03:15 localhost haproxy[69855]: Server kube_api/bs is DOWN, reason: Layer4 connection problem, info: "Connection refused"
のようなログが上がっています。
kube_api は今回の例で、ロードバランサー(HA Proxy) に定義した 6443 ポートへのアクセスを Booststrap/Master1~Master3に割り振るための定義ですが、kube_api/bs is DOWN (bsはこの環境での boostrapサーバーの名前)なので、bs との通信が途絶した事が見て取れます。
インストール中のノードは、度々再起動がされるため、この手のログは良くでます。通信途絶自体は問題ありませんが、このまま起動してこないと bs (boostrap) で問題が起きている可能性があります。
10. 変更履歴
2020/11/1 : 初版
2021/08/30 : 9.1を追加