◾️はじめに
初投稿です!普段は統計解析などのソリューションのセールスをしています。最近は生成AIの話が多くなりキャッチアップ、勉強のために先日オンラインセミナー(以下URL)を開催しました。セミナー当時から期間が空いてしまったので、復習を込めて当記事を書いている次第です。初投稿&非エンジニアなので間違い、アドバイスがあれば、コメント欄で指摘していただければと思います。
当記事ではwatsonx.aiの概要、LangChain(IBM)のおさらいと情報源の確認、そしてセミナー時はLancChainで実装したMemory部分(会話履歴)について、LangGraphで簡単なものを実装してみたいとおもます。
前半は各サービスのおさらいなので、実装例だけ見たい方は こちら から読み始めてください。
◾️前提
- 初学者向けの記事です。
- Pythonについて少し知っていると○
- LangChain、LangGraphについて少し知っていると○
- IBMid、IBM Cloud アカウントを作成済みだと◎
- Macユーザーだと◎(ターミナルでの操作部分だけ)
◾️watsonx.aiとは
IBMの企業向けAI開発スタジオで、様々な基盤モデルの選択、テスト、調整、デプロイまでを一貫して行え、従来の機械学習モデルの利用ができるほか、それをAPIで連携することで業務アプリへの組み込みを支援するプラットフォームです。
利用できる基盤モデル
- IBMが開発したGraniteシリーズ
- オープンソースのサードパーティ基盤モデル
※独自に開発したカスタム基盤モデルもデプロイして使用可能
などなど。以下URLに使えるモデルの一覧について記載があります。
リージョンによって、使える基盤モデルは異なるので注意してください。
※リージョン別の利用可能な基盤モデルについては以下をご覧ください。
https://dataplatform.cloud.ibm.com/docs/content/wsj/getting-started/regional-datactr.html?context=wx&audience=wdp#data-centers
各モデルの「ライセンス」や「対応している言語」などを詳細データの他、モデルのベンチマークも簡単に閲覧可能なので、自分の目的に合ったモデルが選択しやすくなっています。
主な機能
・Prompt Lab
上記の基盤モデルに対して、効果的なプロンプトを実験的できるGUIツール。各モデルに対して、プロンプトエンジニアリングを試せるほか、タスクにあったプロンプトのサンプルを参考にできる他、「これ良いな!」と思ったプロンプトを保存・共有できるため、実際の業務に沿った使用感を試すことができます。
・Tuning Studio
基盤モデルに対して、自社のドメインデータを使ってファイチューニングができるツール
・Agent Lab
基盤モデルに対して、GUIで簡単なエージェント構築・実験ができるツール。外部ツールとの連携ができるほか、LLMが使用するToolsもカスタムできる(予定?)なので今後のリリースが楽しみな機能です。
2025年6月現在ベータ版なのでこちらもいずれ試してみたいと思います。
デプロイ
以上のツールで実験・調整をして、デプロイまで可能となっております。Prompt Labで作ったプロンプトテンプレートを使えるなど便利です。
API
またAPIでの業務アプリへの組み込みも可能でこちらは以下から詳細が確認できます。
・Python SDK
・Node.js SDK
◾️LangChain
LLMの拡張機能を効率的に実装するためのOSSライブラリ。RAGを組むための様々な機能や、プロンプトの管理も楽に行える。LLMを提供する各ベンダーごとのAPIとLangChainを統合するためのパッケージが提供されている。
watsonx.aiであればlangchain-ibmがそれにあたります。
以下から見ると、どんなクラスがあるのが一覧で見れます。
実装は以下から見れます。
◾️LangGraph
LangChainのコンポーネントを使って状態遷移(State Transition)ベースのワークフローを構築できるライブラリ。例えば、RAG(検索拡張生成)やチャットボットのような複雑なLLMの処理フローをノード(処理単位)で整理し、フロー全体をグラフとして設計・制御できる。状態ごとの処理・分岐条件を明示的に記述できるため、信頼性の高い業務向けアプリケーション構築に向いている。
watsonx.ai + LangChain + LangGraph の構成をとることで、IBM watsonのLLMを活用した堅牢で拡張性のある生成AIアプリケーションを効率的に実装可能です。
私の様な初心者には少しハードルが高いので、当記事では以下を参考にさせていただきました。LangGraph自体の概要、使い方などの説明はこちらを参照いただけると幸いです。
◾️実際にwatsonx.aiを使ってみる
当記事では、Pythonを使ってwatsonx.aiのAPIを呼び出してみたいと思います。
筆者の環境(以下の想定で進めます。)
OS :Mac
IDE :VSCode
python :3.11
ライブラリ
- ibm-watsonx-ai>=1.3.13
- gradio>=5.29.0
- langchain-core>=0.3.58
- langchain-ibm>=0.3.10
- langgraph>=0.4.1
- python-dotenv>=1.1.0
IBMCloud、watsonx(SaaS)側の準備
1.IBMid、IBMCloudのアカウントを作成後、以下から無料評価版を試すことができます。
2.アカウントに登録したらプロジェクトの作成、watsonx.ai Runtimeとの関連付けを行いましょう。以下の記事が参考になります。
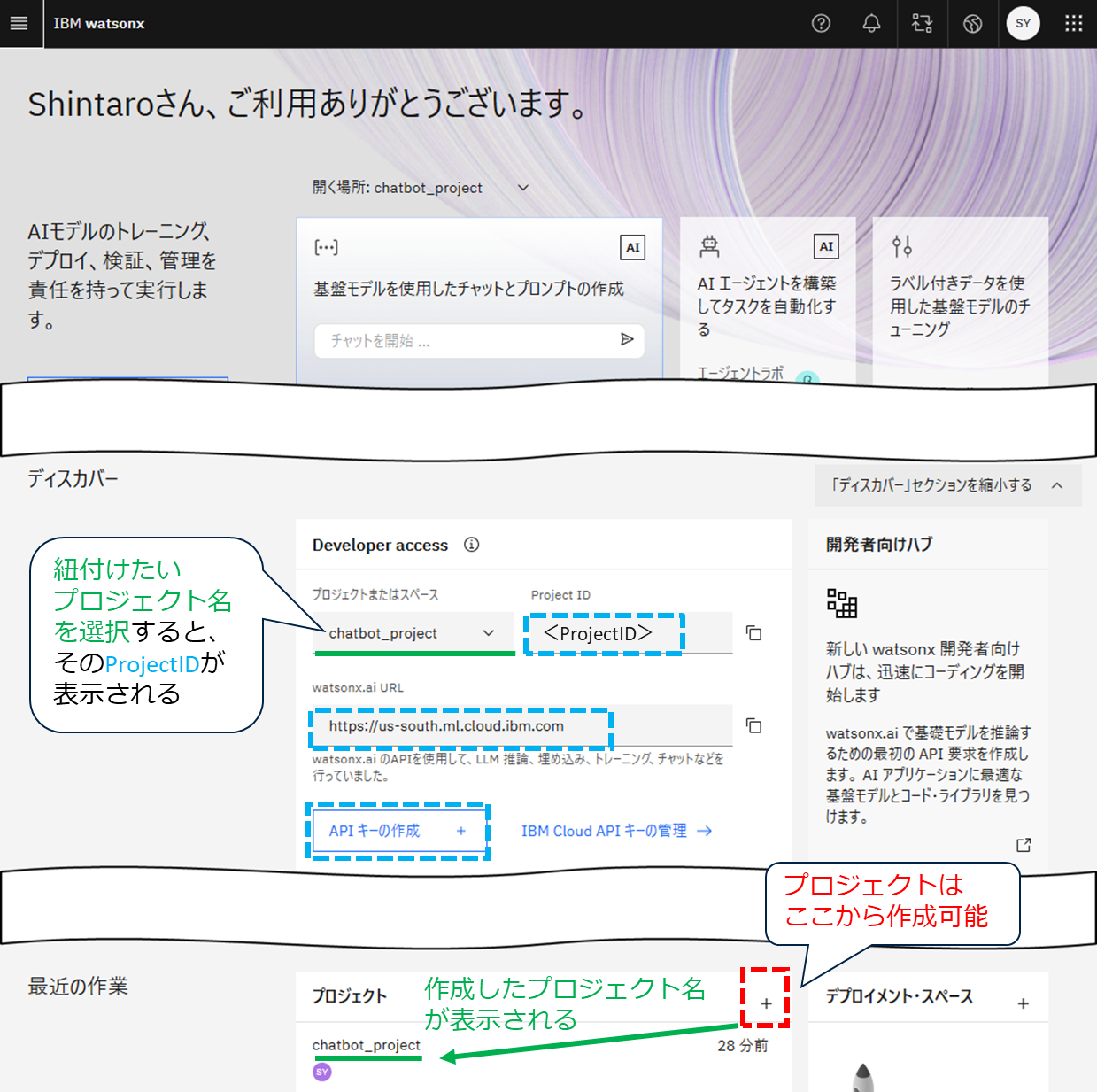
3.当記事ではAPI経由でpython上で使うので、watsonx.aiのホーム画面にあるDeveloperAccessから プロジェクトID エンドポイントのURL APIキー を取得しましょう。以下画像を参考にしてください。
ローカル環境の準備
Pythonのバージョン管理、パッケージ管理はuvを使ってみたいと思います。
UVの概要やインストール方法などは公式ページをご参照ください。
uvのインストールが終わったら、ターミナルで以下を実行していきましょう。
# プロジェクトフォルダ作成&移動 watsonx-demo の部分はお好きな名前でOKです。
mkdir watsonx-demo
cd watsonx-demo
# Pythonバージョンの確認・インストール&プロジェクト初期化
uv python list # 使えるバージョンを確認
# uv python install 3.11 # Ver3.11がなければ実行。
uv init watsonx-demo -p 3.11 # 初期化。-pでpythonのバージョン指定
uv python pin 3.11 # pythonのバージョンを固定
# 今回使うライブラリを追加
uv add "ibm-watsonx-ai" "gradio" "langchain-core" "langchain-ibm" "langgraph" "python-dotenv"
# 依存関係のロックとインストール
uv lock # 依存を解決。uv.lockファイルが作られる。
uv sync # 環境の作成or更新。仮想環境がなければ自動で.venvが作成される。
touch .env # API Keyなどを入れる.envファイルを作る
touch app.py # これから記述していくPythonプログラムファイルの作成
# ※オプション
source .venv/bin/activate # 仮想環境を手動でアクティブにする場合
deactivate # …作業を終えたら、仮想環境から抜けましょう。
上で作った.envファイルに3.で取得した情報を入力していきましょう。変数の名前は後ほど使うので以下で記載する様にしましょう。
WATSONX_APIKEY=**************
WATSONX_URL=https://*******.ibm.com
WATSONX_PROJECT_ID=************
これで準備完了。
gitを使う場合は、.gitignoreに、「.env」を入れてKeyの情報流出をしない様にしましょう。
◾️[本題]LangGraphでチャットボットを作ってみよう
さて、やっと本題です。先ほど作ったapp.pyにチャットボットを作っていきましょう。当記事ではセミナーで扱ったチャットをLangGraphで作り直してみたいと思います。せっかくなのでセミナー時のチャットボットを少し変えてチャットを作ってみます。
今回はテキストマイニングツール「IBM SPSS Modeler」について答えてくれるチャットボットを作ってみたいと思います。「IBM SPSS Modeler」については以下詳細をご覧ください。
LangGraphで実装すると、今回作る様な簡単なものでは以下のようなグラフ構造になっています。
(当記事で実装するチャットボットは以下のNodeが一つなのでもっと簡単…)

先ほど作ったapp.pyにPythonを書いていきます。
早速作っていきましょう。
1.各ライブラリのインポート
watsonx.aiのAPI、LangGraphとLangChain、そしてUI部分はGradioを使います。
import os
import uuid
from dotenv import load_dotenv
from ibm_watsonx_ai.foundation_models.schema import TextChatParameters
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph.message import MessagesState
from langchain_core.messages import HumanMessage, AIMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.output_parsers import StrOutputParser
from langchain_ibm import ChatWatsonx
import gradio as gr
2.APIKey、LLMのパラメーターをセッティング
IBMのLangChainのChatwatsonxを使うとお手軽にセットできます。
環境変数に WATSONX_APIKEY や WATSONX_URL が設定されていると、ChatWatsonxがそれらを自動で読み込んでくれます。
使えるLLMはこちらで確認できるのでmodel_id部分はお好きなものに変更してください。今回はIBMのGraniteを使いたいと思います。
出力トークンの調整などのパラメーターは ibm-watsonx-ai のChatParametersを使用すると簡単かつ細かく設定できます。以下詳細。
# 環境変数の設定
load_dotenv() # APIKeyとエンドポイントはこれでlangchain-ibmが自動で読んでくれます。
project_id = os.getenv("WATSONX_PROJECT_ID") # ProjectIDだけ手動で読み込みましょう。
# watsonx.aiのAPIでパラメーターを設定。
parameters = TextChatParameters(
max_tokens=200, # 応答の最大トークン数
temperature=0.3, # 応答のランダム性(0.0〜1.0)
frequency_penalty=0.3, # 同じ語句の繰り返し抑制(0.0〜2.0)
time_limit=600000 # タイムアウト(ミリ秒)
)
# IBMのLangChainのChatクラスで簡単にモデルの設定。
model = ChatWatsonx(
model_id="ibm/granite-3-3-8b-instruct",
project_id=project_id,
params=parameters,
)
3.グラフ内でやり取りされるメッセージの状態(State)を定義
MessagesStateクラスを使うことで、今回実装する程度のチャットであれば簡易的にStateが実装で決ます。このStateにチャットボットの現在の状態が保持されます。
class GraphState(MessagesState):
pass
4.プロンプトの設定、LLMの呼出などの関数を定義
3. のStateを受け取り会話履歴をLLMになげ、AIのメッセージだけを返すような関数になってます。この関数がLangGraphのノードになります。
具体的には、
- LangChainのMessagePlaceholderを用いてAIと人間の会話の履歴を保持できるようなホルダーを作成。
- システムプロンプトと上記Placeholderで、ChatPromptTemplateを用いてプロンプトをテンプレ化します。
- このテンプレプロンプトを 2. で定義した
modelに投げ、StrOutputParserを使ってmodelの出力から、回答となる文字列だけを取り出せるようにしています。
def call_llm(state: GraphState) -> dict:
prompt = ChatPromptTemplate([
("system",
"あなたはIBM SPSS Modelerの専門家です。IBM SPSS Modelerはデータマイニングと予測分析のためのビジュアルインターフェースを提供し、CRISP-DMモデルに沿ったワークフローでデータの取り込み、前処理、特徴量エンジニアリング、モデル構築、評価、デプロイを行います。これら全てのフェーズに関する質問に日本語で簡潔に回答してください。英語の技術用語には必ず日本語訳を添えてください。必要に応じてノード名やオプションの使い方を具体的に示してください。"),
MessagesPlaceholder("messages"),
])
chain = prompt | model | StrOutputParser()
answer = chain.invoke({"messages": state["messages"]})
return {"messages": [AIMessage(content=answer)]}
5.Graphを構築 ノードとエッジを定義
“llm”という名前で 4. の関数を実行するノードを作成。開始地点のSTARTと終了地点のENDとつなげます。(あんまりLangGraphにする意味がないですが…)
そしてここが当記事の肝なのですが、メモリ上に会話履歴を保存するためのcheckpointerを設定し、グラフをコンパイルします。セミナーで作ったようにLangChainで実装するとConversationBufferMemoryを使って、いちいち会話履歴をロードしたり入れたりしなければならないでですが、LangGraphではInMemorySaverクラスでこのように簡単に実装できるのです!
memory=MemorySaver() # Memoryの初期化
builder = StateGraph(GraphState)
builder.add_node("llm", call_llm)
builder.add_edge(START, "llm")
builder.add_edge("llm", END)
# メモリ上に会話履歴を保存するための checkpointer を設定。
graph = builder.compile(checkpointer=memory)
6.Gradio インターフェース用の関数 を定義
会話のスレッドを指定するthread id(SESSION_ID)を作成。これでInMemorySaverが同一の会話の流れを認識。
実質的にGradioのUI上で実行される関数が以下になります。人間の入力をGradioのUIから受け取り、 5. で作ったGraphに送信。Graphから得られた回答を返します。
今回はデモのため、セッションIDをグローバル変数で管理するシンプルな実装にしています。実際のWebアプリケーションでは、ユーザーごとにセッションを管理する、より堅牢な仕組み(例: Flaskのsessionオブジェクトなど)を使用することが推奨されます。
SESSION_ID = str(uuid.uuid4())
def gen_response(message: str):
global SESSION_ID
result = graph.invoke(
{"messages": [HumanMessage(content=message)]},
config={"configurable": {"thread_id": SESSION_ID}}
)
return result["messages"][-1].content
7.GradioのUIセット
今回作るチャットはSPSS Modelerについて答えてくれるQ&Aチャットボットなので、それに沿ってタイトルや説明文等を作っていきます。
GradioにはChatInterface等もあるが、こちらはデフォルトで会話履歴を保存する機能があります。今回のLangGraphのMemoryを使った会話履歴保持の検証と意図が変わる部分があるので今回はInterfaceクラスを使いたいと思います。
demo = gr.Interface(
fn=gen_response,
inputs=gr.Textbox(lines=2, label="質問を入力してください"),
outputs=gr.Textbox(label="回答", lines=6),
title="SPSS Modeler Q&Aチャットボット",
description="IBM SPSS Modeler に関する質問をどうぞ。日本語で回答します。",
allow_flagging="never" # フラグは使わないので消しておきます。
)
if __name__ == "__main__":
try:
demo.launch() # Gradio サーバー起動
except KeyboardInterrupt: # Ctrl+C 等でポートを解放して終了
print("Stopping Gradio…")
demo.close()
except Exception as e: # エラー用
print(f"Error: {e}")
demo.close()
※ここをクリックでapp.pyのコード全文表示
import os
import uuid
from dotenv import load_dotenv
from ibm_watsonx_ai.foundation_models.schema import TextChatParameters
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph.message import MessagesState
from langchain_core.messages import HumanMessage, AIMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.output_parsers import StrOutputParser
from langchain_ibm import ChatWatsonx
import gradio as gr
load_dotenv()
project_id = os.getenv("WATSONX_PROJECT_ID")
parameters = TextChatParameters(
max_tokens=200,
temperature=0.3,
frequency_penalty=0.3,
time_limit=600000
)
model = ChatWatsonx(
model_id="ibm/granite-3-3-8b-instruct",
project_id=project_id,
params=parameters,
)
class GraphState(MessagesState):
pass
def call_llm(state: GraphState) -> dict:
prompt = ChatPromptTemplate.from_messages([
("system", "あなたはIBM SPSS Modelerの専門家です。簡潔に日本語で回答してください。"),
MessagesPlaceholder("messages"),
])
chain = prompt | model | StrOutputParser()
answer = chain.invoke({"messages": state["messages"]})
return {"messages": [AIMessage(content=answer)]}
memory=MemorySaver()
builder = StateGraph(GraphState)
builder.add_node("llm", call_llm)
builder.add_edge(START, "llm")
builder.add_edge("llm", END)
graph = builder.compile(checkpointer=memory)
SESSION_ID = str(uuid.uuid4())
def gen_response(message: str):
global SESSION_ID
result = graph.invoke(
{"messages": [HumanMessage(content=message)]},
config={"configurable": {"thread_id": SESSION_ID}}
)
return result["messages"][-1].content
demo = gr.Interface(
fn=gen_response,
inputs=gr.Textbox(lines=2, label="質問を入力してください"),
outputs=gr.Textbox(label="回答", lines=6),
title="SPSS Modeler Q&Aチャットボット",
description="IBM SPSS Modeler に関する質問をどうぞ。日本語で回答します。",
allow_flagging="never"
)
if __name__ == "__main__":
try:
demo.launch()
except KeyboardInterrupt:
print("Stopping Gradio…")
demo.close()
except Exception as e:
print(f"Error: {e}")
demo.close()
これでapp.pyは完成です。
早速実行してみましょう。
◾️作ったチャットボットを試してみる
ターミナルからwatsonx demoフォルダに移動。以下を実行していきましょう。
uv run app.py
すると以下のようにコンソールに出力されるのでURL(http://~)をコピー。Chromeなどのブラウザを開いてURLを貼り付けアクセスしてみましょう。
/<ルートフォルダ>/watsonx demo/.venv/lib/python3.11/site-packages/gradio/interface.py:415: UserWarning: The `allow_flagging` parameter in `Interface` is deprecated.Use `flagging_mode` instead.
warnings.warn(
* Running on local URL: http://127.0.0.1:****
* To create a public link, set `share=True` in `launch()`.
うまくいくと以下の様な画面になると思います。早速質問をしてみましょう。
「SPSSModelerの具体的な使い方を教えてください。」と聞いてみると、何やらそれっぽい答えを返してくれていますね!

それでは問題の会話保持ができているかの検証をしてみましょう。クリアを押すとユーザー入力、AIの回答が消えます。クリアを押して次の入力をしてみましょう。
通常のGradioのInterfaceクラスでは1質問に対して1回答なので前回の会話の内容は継承しません。
前回回答に出てきた「2.データ探索」について質問をしてみましょう。LLMの素の能力で回答ができては検証にならないので、前回回答については一切触れず「2.について」とだけ聞いてみましょう。
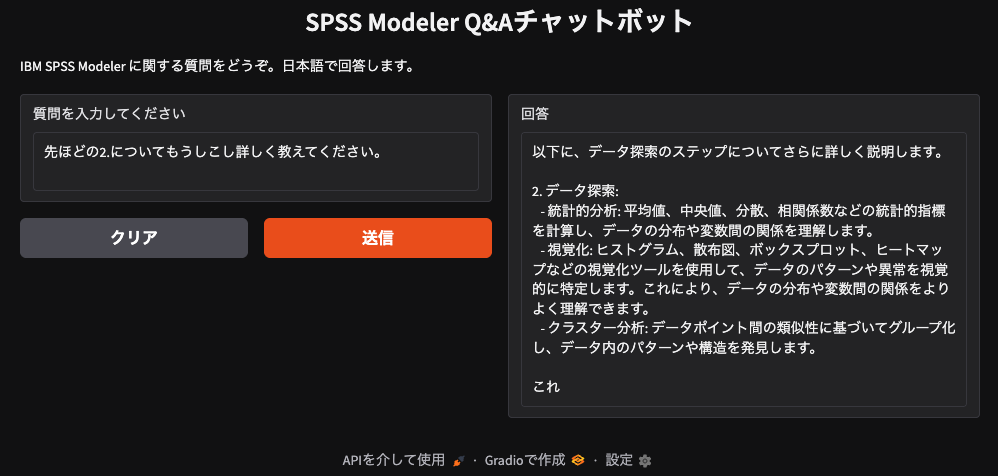
データ探索について深掘りして答えてくれました!前回の会話を覚えていることが確認できたのではないでしょうか。会話を一人しきり終えた後は、ブラウザを閉じましょう。その後ターミナルでCtrl+C を一度押し、Stopping Gradio… と表示されたら正常に終了しています。
さて、ここで一つ気になるのが回答が途中で途切れてしまっていることです。これはwatsonx.aiのAPI「TextChatParameters」で設定したmax_tokenの上限に達したからです。これもうまく作動している証拠です。
記事が長くなってきたので今回はここまでにしたいと思います。
◾️反省点、次やりたいこと。
当記事の実装では、すべての会話履歴を保存し、それをそのままプロンプトとしてLLMに渡しています。簡易的なチャットボットであればこの方法でも問題ありませんが、会話のターン数が増えたり、RAG(Retrieval-Augmented Generation)構成で外部情報を追加するようなケースでは、プロンプトのトークン数が非常に大きくなってしまいます。
しかし、LLMにはそれぞれ「コンテキストウィンドウ」(一度に処理できる最大トークン数)の上限があるため、プロンプト内に収める情報の取捨選択や圧縮が必要になります。
さらに、コンテキストウィンドウの上限いっぱいまで使えば良いというわけでもありません。例えば、
-
Levy(2024)の研究では、「入力トークン数が多すぎるとモデルの性能が低下する」可能性が指摘されています。
-
また、Liu(2023)の研究では、「長い文脈の中では、特に中間部分の情報がモデルにとって忘れられやすい」という傾向が示されています。
こうした背景から、プロンプトのトークン数を制御する技術が注目されており、たとえばZhao(2024)のサーベイ論文では、様々なプロンプト圧縮手法(ハード/ソフトの両方)が整理・分類されています。
とはいえ、私のような初心者がいきなり高度な圧縮アルゴリズムを実装するのは難しいので、 「会話履歴の要約」 が現実的なところかな、と考えています。
ということで、次回の記事は引き続きメモリ管理②として、会話履歴の要約を試してみたいと思います。
…あと色々検証するにあたって、割と会話履歴を追うのがめんどくさかったので次の記事でLangSmithについても触れてみたいと思います。
◾️まとめ
さて当記事ではwatsonx.aiとLangChain、LangGraphの紹介と、それらを使って実際にチャットボットを作成。その中の会話履歴の管理を通して、LangGraphにおけるメモリ管理をどう実装するのかを簡単に触れてみました。
ただ今回のチャットボットは実用性皆無ですし、LangGraphを使っている意味があまりないです(笑)。またSPSSModelerのQ&Aとして作りましたが、LLMは正確で最新の情報は持っていないのでハルシネーションがよく起きると思います。
そこで、せっかくLangGraphで実装したので、今後の記事としてはwatsonx.dataでRAGを組み込んで豊富なドキュメントを読み込ませてみたり、話題のMCPを使ってWeb検索を実装して、最新情報を獲得してみたり、マルチエージェントとか作ってみたり、できればなーと考えています。
◾️参考