この記事はFujitsu Advent Calendar 2020 24日目の記事です。(記事は個人の見解であり、組織を代表するものではありません。)
はじめに
毎年恒例になったAdevent CalendarでのLinuxの不揮発メモリ対応の動向について、今年も記述しようと思います。
正直言うと、今年は不揮発メモリとは別のネタを書くことも考えました。不揮発メモリのLinuxの動向については、今年はすでにOpen Source Summit Japan 2020 (以後OSSJ)でも話してしまっていて、スライドも公開したので、その内容が今年の全てです。なので、改めてAdvent Calendarで話す必要があるのかどうかいささか迷いました。
また、5月に公開した「メインフレームの異常処理」の記事が結構評判がよかった一方で、Linuxの異常処理について知らない人が多そうだったので、それについて書いてもよかったかな?ともチョット思いました。ただ、ちょっとまだ調査時間が必要そうだったので、それについても今回は諦めています。
まあ、OSSJは曲がりなりにも国際カンファレンスであるので英語で資料を記載して話しているのと、昨年の情報処理学会Comsysで話しをした内容から被る部分もあるので、日本語で2020年度のupdate分についてまとめるのも悪くないかな? と考えました。そういうわけで今年もNVDIMMで書きます。
この記事では昨年Comsysで話した内容はスキップしますので、まだご覧になっていない方はこちらをご覧ください。
不揮発メモリ(NVDIMM)とLinuxの対応動向について(for comsys 2019 ver.)
新しいライブラリ
PMDKに新しいライブラリが追加されています。まずは、それらについて簡単に紹介しましょう。
libpmem2
低レイヤライブラリにはlibpmemがあったのですが、libpmem2というのが追加されています。正確には、これは2020年よりも前から追加されていたようです。
特徴として新しくGRANULARITYの概念が導入されていて、以下の3つが定義されています。3つ目が少し興味深いところです。
- PMEM_GRANULARITY_PAGE: HDDやSSD向け
- PMEM_GRANULARITY_CACHE_LINE: 現在のNVDIMM向け。これまでのように、cpu cacheのflushを行わないといけないプラットフォーム向け
- PMEM_GRANULARITY_BYTE:これもNVDIMM向けですが、電源断の時にプラットフォームがcpuのcacheもflushしてくれる環境向け
今3つ目の定義が示すようなプラットフォームが実際にあるのかどうかは筆者は知りません。バッテリーを余分に積んでいることができるような環境であれば、利用できるかもしれませんし、あるいは将来そういう予定があるのかもしれません。
cpu cacheの扱いがNVDIMMの難しさの一つなので、それを気にしなくてよい環境ができればうれしいですね!
また、このライブラリはNVDIMMの異常ブロックや突然電源断が起きたかどうかの状態を取得するインタフェースもあるようです。内部ではNVDIMMのnamespaceの管理コマンドであるndctlのライブラリを使って実現しているようです。
旧libpmemとはインタフェースが一新されているようで、互換性はなさそうです。
librpma
これまでPMDKにはRDMA用のライブラリとしてlibrpmemがありましたが、長らくexperimental statusのままでした。しかし、それとは別に新たにlibrpmaのライブラリが登場しました。なぜ新たに作られたのでしょうか?
これについては、Intelの発表資料から引用するのが分かりやすいでしょう。私からは詳しくは述べませんが、librpmemはいくつかユーザのニーズと合わないところがあったようです。
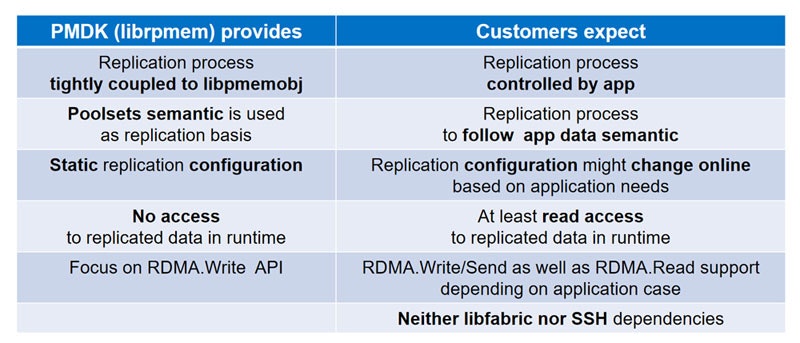
実際筆者も、Pmemのメーリングリストに「librpmemってなぜExperimentalなのか?」と質問を投げたところ、「誰も使っている人がいないからね。君が使うなら今すぐExperimentalは外すよ」という回答が返ってきた経験があります。
このため、新たにユーザのニーズに合わせてライブラリを作ったようです。
現在はv0.9となっており、ライブラリの本体については2021年1Qにはv1.0が出る予定のようです。
Filesystem DAXの残りの課題
Filesystem DAXは、残念ながら今年もExperimental Statusのままでした。ただ、残る課題は徐々に解決されてきたり、あるいは回避方法が見つかってきていて、少しずつですが前進してきています。
大きく分けて、以下の3つの問題が残っていますが、以下にそれぞれについて説明しましょう。
- DMA/RDMA v.s. Filesystem DAX
- inodeごとのdax 利用のon/off
- FilesystemのCopy On Write機能との両立
1) DMA/RDMA v.s. Filesystem DAX
以前から述べているように、Filesytem DAXは、sync()/fsync()/msync()を呼ばなくても、CPUのキャッシュのフラッシュだけすればデータの永続化ができることを志向しています。しかし、ユーザのデータはそれでよくてもファイルのメタデータはそうはいきません。Filesystem自身が更新するタイミングがこれまではsync()などを呼び出すときに更新できていたのが、そのタイミングが無くなってしまうからです。
この問題についてはユーザ空間からのアクセスについてはmmap()のMAP_SYNCオプションによる解決、カーネルレイヤのDMA/RDMAについては、データ転送が完了するまでtruncate()の処理を待たせるなどして解決してきました。
しかし、infinibandやvideo(V4L2)のように、ユーザ空間に直接DMA/RDMAでデータを転送するような機能の場合はそうはいきません。ドライバ・カーネル層のプログラムは長期間CPUを保持し続けるのはご法度なので、いつかは処理を手放してくれるということが期待できます。なので、待つという選択肢があり得るのですが、ユーザー空間ののプログラムはそれが保証できません。わかりやすい例だとビデオの録画が挙げられますが、ユーザが録画をいつ止めるかはユーザ次第であり、カーネル側では予想することができません。データ転送がいつ終わるかがわからないので、待つことができないというわけです。

この問題については、解決方法についていくつか提案があったようですが、コミュニティで合意できた実装はまだありません。ただ、__On Demand Paging__という機能をハードが対応していれば__回避__できるそうです。
この機能は、I/Oのためにユーザ空間にmapしている領域に対して、普段は物理ページをユーザ空間にマップせずプロセスが当該アクセスしたときにだけマップするというしくみです。この機能により、物理ページを張り付ける時にメタデータの更新を行うことができるため、truncate()などで失ったりしたブロックの情報などを調停するチャンスができる...ということのようです。
mellanox の inifiniband の比較的あたらしいカードにはこの機能があるそうで、将来的には他のハードにも同様な機能が搭載されていくかもしれません。
また、このワークアラウンドが登場したことにより、Filesystem-DAXの課題の中ではこの問題の優先度がかなり下がってきているような印象です。
2) inodeごとのdax 利用のon/off
inodeごと、すなわちFileやディレクトリごとにDAXのon/offの指定ができる機能を作るべきという方向が決まっていました。これは、以下のようなユースケースが想定されていました。
- mountしたファイルシステム全体でDAX on/offを決めるのではなく、もう少し細かい単位で設定したい。
- アプリケーションによってon/offができるようにしたい。
- NVDIMMと言えどもDRAMよりは遅いので、DAXをoffにした方が速くなるようになるケースでは、チューニングに使えるので便利。
- Filesystem-DAXがバグっていた時の回避方法として使いたい。
が、この話を聞いた時、かなり開発の難度が高そうに聞こえたため、私は解決には数年かかってしまうのではないかと予想していました。例えば、私がぱっと思いつくだけでも以下のような課題が考えられます。
a) ページキャッシュの扱い
DAXがoffになっているファイルをonにした場合、そのファイルのメモリ上のキャッシュ(Page cache)はどうするのか? 少なくともpage cacheとして使っているRAMの領域からNVDIMMの領域にmemory migrationのようなことをしなければなりません。RAM同士の移動ならmemory migrationの機能が既にありますが、NVDIMMとの移動にもこれを拡張する必要が出てきます。
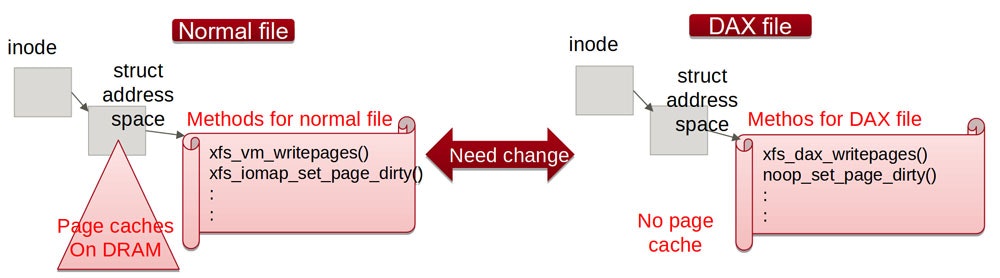
b) 通常ファイル用のメソッドとDAX用のメソッドの切り替え
通常ファイルとDAXファイルではファイルシステムの中でも扱いが異なるため、当然使うメソッドも異なります。page cacheを扱うためのaddress_space_operationsは、以下のようにDAX用に別途用意されていたりします。
const struct address_space_operations xfs_address_space_operations = { <--- 通常ファイル用
.readpage = xfs_vm_readpage,
.readahead = xfs_vm_readahead,
.writepage = xfs_vm_writepage,
.writepages = xfs_vm_writepages,
.set_page_dirty = iomap_set_page_dirty,
.releasepage = iomap_releasepage,
.invalidatepage = iomap_invalidatepage,
.bmap = xfs_vm_bmap,
.direct_IO = noop_direct_IO,
.migratepage = iomap_migrate_page,
.is_partially_uptodate = iomap_is_partially_uptodate,
.error_remove_page = generic_error_remove_page,
.swap_activate = xfs_iomap_swapfile_activate,
};
const struct address_space_operations xfs_dax_aops = { <---- DAX用
.writepages = xfs_dax_writepages,
.direct_IO = noop_direct_IO,
.set_page_dirty = noop_set_page_dirty,
.invalidatepage = noop_invalidatepage,
.swap_activate = xfs_iomap_swapfile_activate,
};
DAXのon/offを切り替えると、このようなメソッドを切り替える必要がありますが、切り替えた時にはまだ当該のメソッドが実行中かもしれません。どのように排他処理を行って、どういうタイミングで切り替えればよいのか? という非常に難しい課題があります。
しかしこの問題については、割と穏当な解決方法を選択をすることで解決がなされました。
「inode cacheがメモリ上に無い時にon/offを切り替える」
inode cacheがメモリ上に乗っていない状態の時であれば、だれもその当該のファイルの利用者がいない状態ですから切り替えは容易です。これは言い換えると、「誰かが使っていれば切り替えを行うことができない」ということも言えますが、DAXの設定を変えたい時というのはそのファイルを利用しているアプリの挙動も変えたいということがほとんどでしょうから、あまり問題にならないでしょう。
だれかが対象のファイルをopenするなどして使っている時はinode cacheはメモリ上に残ってしまうので、その時点では切り替えは行われず処理が遅延されます。利用者がいなくなってinode cacheがディスクにsyncしていったん削除され、改めてinodeがディスクから再読み込みされた後、その時のDAXのflagを見てようやく切り替わるという動きになります。
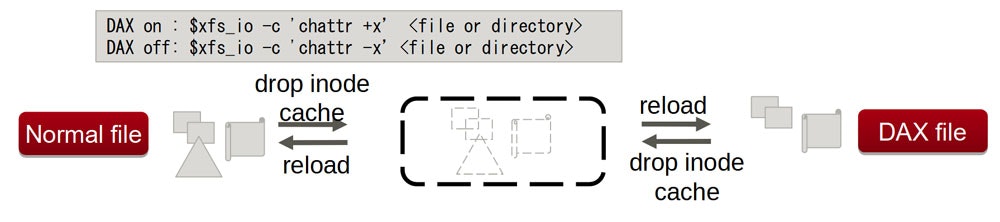
これによって、DAX on/offの設定ができるようになり、図の通りXFSではxfs_io -c 'chattr +x'のようなコマンドを打つことで変更ができるようになりました。なお、この機能を使う時はmount 時のオプションは以下のようにdax=inodeの指定をしておく必要があります。
# mount ... -o dax=inode
ただ、個人的にはこの機能にはまだ若干問題があると思っています。というのは、現在のkernelのドキュメントDocumentation/filesystem/dax.txtには、キャッシュを消すための操作として以下のように書かれているからです。
b) evict the data set from kernel caches so it will be re-instantiated when
the application is restarted. This can be achieved by:
i. drop-caches
ii. a filesystem unmount and mount cycle
iii. a system reboot
1つ目のdrop cacheの操作というのは、procfsのインタフェースで以下の操作によってシステム全体のcacheを追い出す1操作です。
# echo 3 > /proc/sys/vm/drop_caches
page cacheであれ、inodeを含むslabキャッシュであれ、システム全体のキャッシュを落とそうとする操作ですから、システム全体への影響は避けられません。mountのやり直しやrebootはどちらかというと、kernel側で何らかの問題が発生した時のような非常時の操作という印象がありますが、drop_cacheの操作はそういう雰囲気でもなく、中途半端な操作になっていますね。せっかくファイル、ディレクトリ単位で切り替えるようにしたのに、システム全体に影響が及んでしまうというのはできれば避けたい操作です。特に、最近だとコンテナーホストで動いているサーバも多いと思いますが、この操作で隣の関係ないコンテナにも影響が出てしまうのはかなり問題となるでしょう。
なぜこのようになっているのかコミュニティに問い合わせたところ、現在はrace conditionによってどうしてもcacheが残ってしまうタイミングがあるため、やむなくこの記述がされたそうです。筆者は「ファイル単位でdrop_cacheするような機能が作れないか?」という提案もしましたが、それはDOS攻撃の温床となるということで却下されました。
そこで、DAX on/off切り替え時にはI_DONTCACHEとDCACHE_DONTCACHEをうまく設定・評価することで、cacheが残らないようにするためのパッチを提案しています。このパッチがはいれば、drop_cacheしなければならない状況というのは無くなってくるかもしれません。
3) FilesystemのCopy On Write機能との両立
Linuxでkernelに取り込まれているCoWのファイルシステムといえばbtrfsですが、XFSでもreflink/dedupという機能2があります。
この機能のdedupが働くと、あるファイルシステム中のあるブロックが、File Aのoffset 100と、File Bのoffset 200の両方で共有されている形となります。ブロックのデータが同じであれば重複するので削除することができるのです。
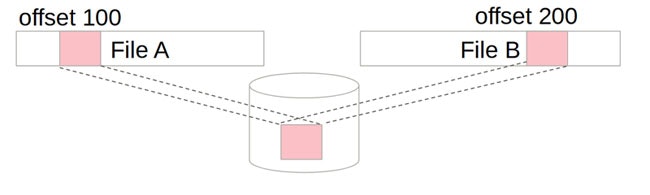
Experimental Statusを外すには、これらの機能とFilesystem-DAXの両立することが条件となっていました。しかし、現在はFilesystem DAXとは排他の関係にあり、XFSのmkfs時にreflinkを有効にしていると、mount時にDAXを指定してもエラーになってしまいます。何が問題なのでしょうか?
これについては、大きく二つの問題があります。
- そもそもFilesystem-DAXとその周辺のソースコードがCoWについて考慮していない。
- メモリ管理機構側がFilesystemのCoWの機能を考慮しないといけなくなったが、構造上それが難しい。
特に2の問題は、(前述のメタデータの更新問題もそうでしたが)Filesystem-DAXがメモリの特徴とストレージの特徴を併せ持つゆえに出てきた問題であると言えるでしょう。
この問題については筆者のチームのメンバが解決をするためのパッチを投稿しているので、それについて説明しましょう。
1. そもそもFilesystem-DAXとその周辺のソースコードがCoWについて考慮していない
前述のとおり、今までCoWやFilesystem DAXの配慮のなかった箇所に、ソースを追加する必要があります。以下の3つのレイヤーで対応が必要となっていますが、それぞれについて実直に実装する必要があります。
a. iomapにCoWのためのインタフェース追加
iomapとはbuffer_headに代わるブロックレイヤ層のインタフェースで、最大でも1page単位でのI/O発行が条件だったbuffer_headに対し、複数のpageにまたがるI/Oを一回で行えるのが特徴です。Filesystem DAXの下位レイヤではこのインタフェースを使っているのですが、CoWのための仕組みは持っていませんでした。まずはここにCoWのためのインタフェースを追加する必要がありました。今回はsrcmapというコピー元の情報のインタフェースを追加しています。
b. Filesystem DAXにもCoWのためのロジックを追加
Filesystem DAXのコードのwrite()の処理と、そしてmmap()でのpage faultの際に、CoWのためのロジックを追加する必要があります。srcmapの情報をもらってデータをコピーして更新するということを素直に実装しています。また、Filesystem DAX用にdedupの処理を追加する必要がありますが、これもDAX専用のルートを作りこんでいます。
c. 各CoWファイルシステムが、Filesystem DAXの時に上記のインタフェースを利用するように変更
XFS, btrfsがFilesystem-DAXの時に、上記のインタフェースを使うように修正する必要があります。
2. メモリ管理機構側がFilesystemのCoWの機能を考慮しないといけなくなったが、構造上それが難しい。
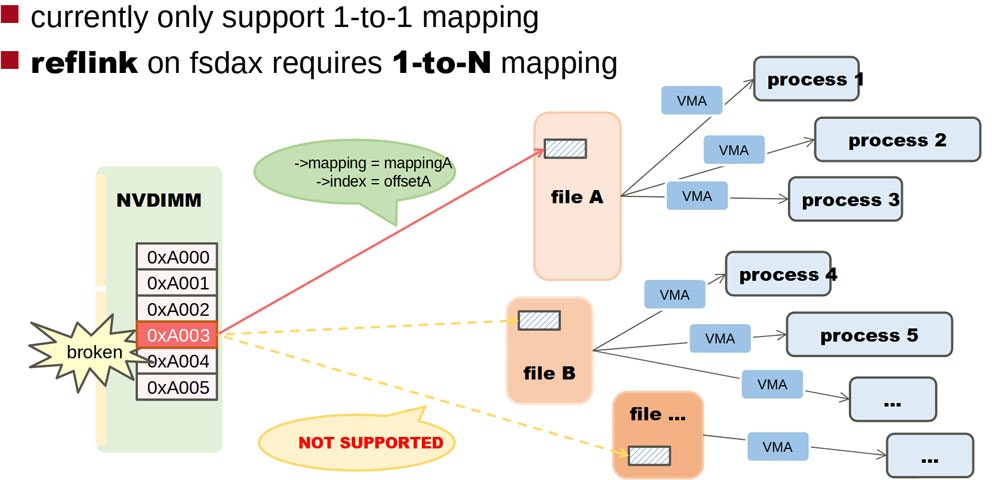
メモリ故障により、そのメモリを使っているプロセスをkillしなければならないときに、これまではメモリ管理機構の仕組みからその領域を使っているプロセスを求めてプロセスを探すということをしていました。これまでのpage cacheなどのケースでは、そういう場合には1つのファイルを見つけて、それを使っているプロセスをkillすることで実現していました。使っているメモリのstruct pageのmappingやindexの情報から、関係しているファイルを1つ見つけてそれを追跡すればよかったのです。しかし、Filesystem DAXとCoWファイルシステムの機能が合体したことによって、struct pageから複数のファイルを探さなくてはいけなくなりました。これは非常に難しい問題です。なぜなら、struct pageには複数のファイルを登録するようなスペースがないからです。
少しわき道にそれますが、struct pageはLinuxのメモリ管理機構の中でも重要な構造体で、各物理ページの状態を記録するため、物理メモリ1ページに1つ割りあてられる仕組みになっています。x86では4K pageに対して40byte程度のstruct pageが割り当てられます。つまり、物理メモリのだいたい1%がstruct pageになってしまうのです。1TBのメモリを搭載していたら、10Gbyteぐらいがこのstruct pageだけで占有されてしまうのです。このため、伝統的にstruct pageのサイズは大きくならないように細心の注意が払われており、その構造体の定義はunionを使って年々カオスになっています。そんなカオスなところにさらにファイルの情報を複数記録する方法が必要となるということですから、どうやってサイズを変えずに実現するか、頭を悩ませる必要が出てきたのです。
さすがに難題であったため、実現方法を3度やり直しています。では、それらを順番に見ていきましょう。
案1. page structにtree構造のデータを登録する。
各ページについて、複数のファイルがdedup機能によって使われるようになったとき、tree構造で登録しておくアイデアです。この案は素直で誰もが思いつく設計です(私も最初はこれを考えていました)。が、メモリの消費量もoverheadも大きいということで、コミュニティでの議論の結果、没になりました。

案2. XFSのrmapbtをつかってそのpage(block)を使っているファイルを探す。
Filesystem-DAXでは、rmapbtという利用しているblockから使われているファイルを検索するためのツリー構造を持っているそうです。この案ではそれを検索してowner listとしてリストに登録しておき、メモリ故障発生時にそのリストを追うという方法です。案1よりはメモリ使用量やオーバーヘッドなどを小さくできました。
が、まだリストを作ること自体に余計なメモリを使うので、これも没になりました。
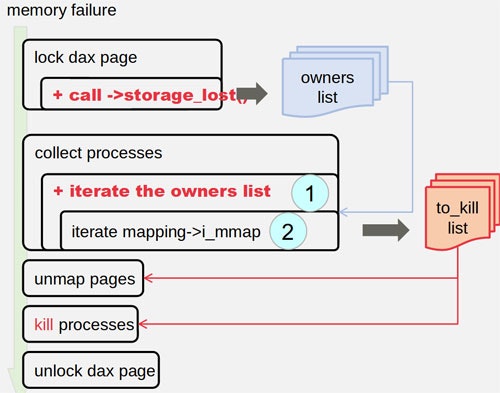
案3. リストを作らず、メモリ故障時にrmapbt treeを検索して、利用しているファイルを見つけていく。
あらかじめowner listを作るのではなく、メモリ故障時に頑張ってrmapbtをたどってownerを検索するアイデアです。また、メモリ故障時の処理が行うcall backルーチンを登録するようにしておいて、各ownerごとにこのこのcall backルーチンを実行するというスタイルになりました。このcall backはDevice DAXの時にも使える共通インタフェースとなりました。現在はこの案で実装しており、大まかな方向はこれでコミュニティで合意されています。
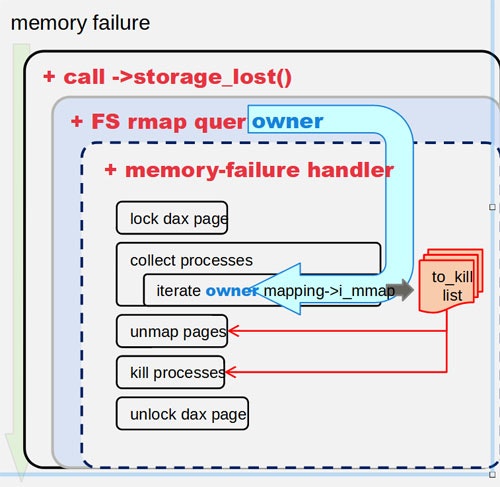
いくつかまだ残課題3がありますが、この実装がupstreamに取り込まれれば、いよいよFilesystem-DAXの最後の問題も解決できそうです。
おわりに
2020年のNVDIMMのLinuxの動きについて日本語でまとめましたが、いかがだったでしょうか? 皆様のお役に立てれば幸いです。それではよいお年を!
-
指定する値を1にするとpage cacheを追い出す操作に、2にするとinode cacheを含むslab cacheを追い出す操作になります。3はその両方です。 ↩
-
ちなみに、XFSのreflink/dedupは、btrfsと異なりmetadataについてはCoWせず、ユーザデータのみをCoWするのだそうです。 ↩
-
発表資料を作成ている時点ではLVMを使っているとrmapbtを追えないなどの問題があったようです。それは解決したようなのですが、まだ私の理解が追い付いていません。)。また、XFSのrealtime Deviceのような機能はrmapbtを持たないため、この方法では解決できないという問題があります。 ↩