はじめに
この記事では、メインフレームでは異常時の処理でどのようなことをやっているのか、また、Linuxの異常処理との違いなどについて話してみようと思います。
この記事を書くに至った直接的なきっかけは、とある人からリクエストがあったからです。が、日ごろからメインフレームの異常処理の考え方については、PCサーバーやクラウドによるシステムがメジャーになった現代であっても、参考になることは多いと感じていてはいました。
筆者は今でこそLinux Kernel周りの仕事をしていますが、20年ぐらい前のころはメインフレームのOS開発部隊に配属されていて、メインフレームのとあるコプロセッサのドライバを書いたりしていました。この際、その異常処理における考え方を体験する機会が多々あり、当時のその経験が20年後の現在でも大いに役にたっていると感じていたからです。
そもそもメインフレームは、これまで長年にわたって社会の根幹を静かに支えてきたシステムです。例えば、銀行の勘定系、すなわち皆さんの口座の元帳を預かっているシステムでは今なおメインフレームが多数1を占めています。毎日正常に動き続けて当たり前、トラブルになると社会問題になるようなシステムとして使われてきたのがメインフレームなのです。そのメインフレームが異常時においてどのようなことを行うのかというのは、最新のシステムであっても何かしらヒントになるものがあるかもしれません。
読者には、温故知新という言葉とともに、この記事を参考にしていただけると幸いです。
お断り(用語について)
この記事を書くにあたって非常に悩んだ・苦労したのが用語についてです。メインフレームの用語はUnix/Linux系の用語とは異なることが多く、また正確に同じ機能を有するとは限らないからです。
例えば、IBMのメインフレームの資料では以下のように書かれていたりします。
ESTAE 出口ルーチンは、ESTAE マクロ命令を出すことによって設定されます。
ESTAEというのは後述しますが、ここでいうマクロというのは、Unix/Linuxにおけるシステムコール2やライブラリ関数を呼び出すような処理のことを指します。このマクロという呼び名は、メインフレームのシステム制御プログラムがアセンブラベースで記述されていて、当該の関数を呼び出す際の一連の流れを__マクロ__として登録していて、呼び出すときにはそのマクロを使うことから来ています。
同じように、「出口ルーチン」も読者にとっては「ハンドラ」という呼び方のほうがしっくりくるかもしれません。 このように、何かの機能を呼び出すというだけでも、メインフレームのOSでは呼び方が異なることがよくあります。
私にとってもUnix/Linuxなどの用語の方がなじみが深いため、多少そちらに合わせた書き方をしています。しかし、メインフレームとして正確な記述ではない点はご了承ください。
また、私自身メインフレームから離れて20年近い時間が立っているので、間違っている個所もあると思います。そういう所はご指摘いただけると幸いです。
メインフレームの異常処理の考え方
さて、まずはメインフレームの異常処理の基本的な考え方について説明します。これについては、以下の文章が最もよく表しているでしょう。この文章は昔のIBMのメインフレームOSである MVS3の解説書「MVSの機能と構造」から抜粋したものです。(強調筆者)
MVSではシステムの利用可能度(availability)を最大にすることを主目的にし、ハードウェアやソフトウェアに障害が起きても、ユーザーへの影響を最小限にすることを目標としている。障害の発生に当たっては仕事や資源の回復処理をまず行おうとするが、これが成功しない場合には、障害部分をシステムから切り離してでも、システム全体としてとにかく稼働を継続し、ユーザーが使用できる状態を保つようにする。
注意してほしい点は、ここでいう所のシステム全体とはクラスタリングをしたクラスタシステムなどによるシステム全体の話をしているの__ではない__点です。この文章は実は__「1ハードウェア+1OS」__構成での話をしています。つまりMVSはそれが動作する1システム単体でこのような__障害を最小化する__動作を目標としているのです。Linuxであれば、kernelがやむなくpanicするようなケースでも、メインフレームでは障害を局所化してそこだけ切り離し、可能な限りシステムの動作を継続するようにしています。
もちろん1システムでできることには限界があるので、メインフレームでも当然クラスタリングによる冗長化を行うことができますが、たとえ1システム内であっても上記のような動作を目指すところがメインフレームの特徴といえるでしょう。
可能な限り1台の稼働継続を大事にするというのは、メインフレームが発展した時代が、コンピュータ一台当たりの単価がまだまだ高かったために生まれた発想といえるかもしれません。
異常処理ハンドラの登録(ESTAE)
上記の目標を達成するために、メインフレームのOSではクリティカルなエラーの時の処理のハンドラを、上述の__ESTAEマクロ__で、__ESTAE出口ルーチン__と呼ばれる異常処理用のハンドラを登録することができました4。通常のエラー処理であれば、呼び出したサブルーチンの復帰コードでエラーが伝えられるのに対して、ある種の異常な状態である場合には、このESTAEという機能を使って登録した異常処理のハンドラが呼ばれるのです。
このハンドラの意味は、Unix/LinuxでのC言語のプログラムであればシグナルハンドラ、Go言語ならdefer()で登録するハンドラを考えるとわかりやすいかもしれません。ただ、メインフレームOSの場合、システムコールの内部でもこのESTAEの機能を使うことができます。
この異常処理用のハンドラは以下のようなときに呼ばれます。
- プログラムのエラー。NULL pointerアクセスなどの場合です。
- ハードウェアエラー。(CPUなどが故障した場合、下の図のようにECCなどによるリカバリができなかった場合は別の正常なプロセッサからこのハンドラが呼び出されます。)
- OSのページング処理において、ページインの時にI/Oエラー
- オペレーターがジョブプログラムなどを(強制)終了させる場合
- etc.
このように、ソフトウェアのバグの場合だけでなく、ハードの異常時にも呼ばれるのが特徴です。
ハードウェアのエラーの場合、どのようにこのハンドラが呼ばれるのかについては、次の図が示すように以下のような順序で行われます。
- 異常を検出したCPUが(マシンチェック)機械チェック割り込みを発生させます。
- Machine Check Handler(MCH)はECCなどでリカバリできるかどうかを判定し、回復可能であれば中断した処理から再開します。
- 回復不可能と判断した場合、他のプロセッサがあればそちらに異常を通知します。
- 異常が通知されたプロセッサは、リカバリ処理回復マネージャー(Recovery Termination Manager = RTM)を走らせます。
- (この図の中には記述がありませんが)RTMは、登録されているESTAEハンドラを呼び出します。
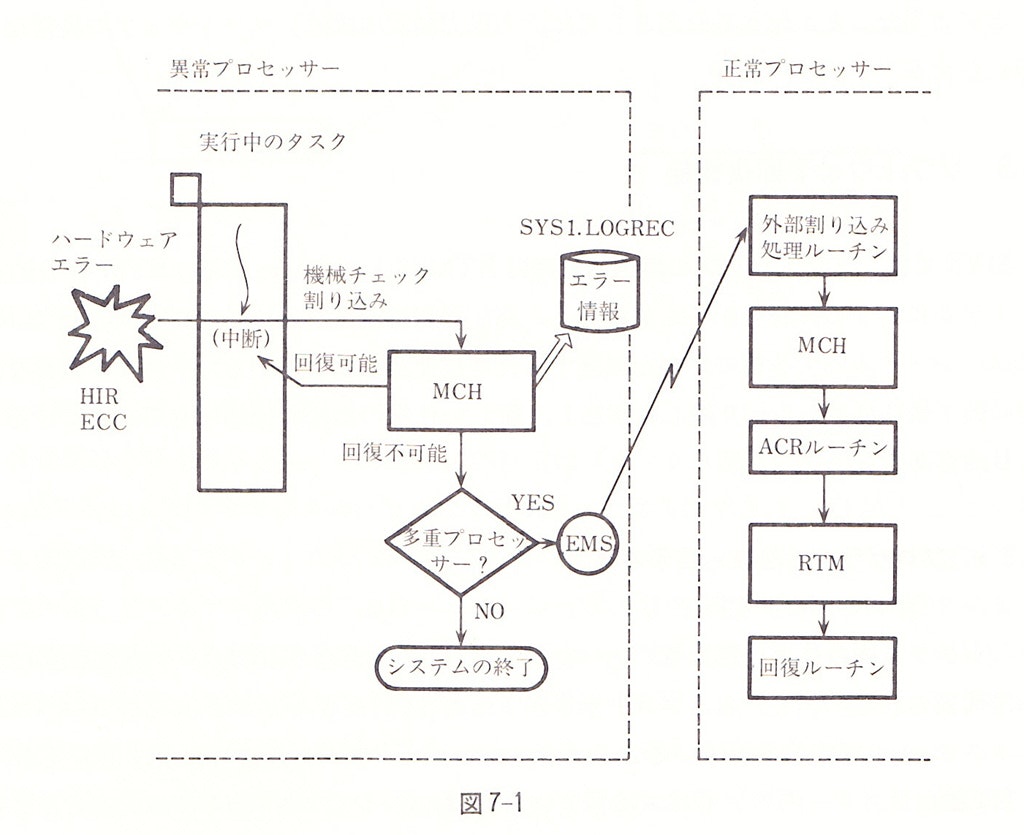
(図は「MVSの機能と構造」より抜粋)
ESTAEの特徴として、以下のようなものが挙げられます。
- ESTAEハンドラは複数登録して、ネストすることが可能です。例えば、ESTAEハンドラAを登録したモジュールが別のモジュールを呼び出し、そのモジュールがESTAEハンドラBを登録してから異常が発生した場合、ESTAE ハンドラBが呼び出されます。Unix/Linuxのsignalハンドラがネストできないことを考えると非常に便利です。
- 1.のような関係において、呼び出し先のサブルーチンの異常処理ハンドラがリカバリしきれなかった場合、呼び出し元の異常処理ハンドラが呼び出されます。(これをパーコレーションと呼んでいます)。子供の不始末の責任を親がとる(?)という形になります。
この様子を簡単な図にすると、以下のような形になります。
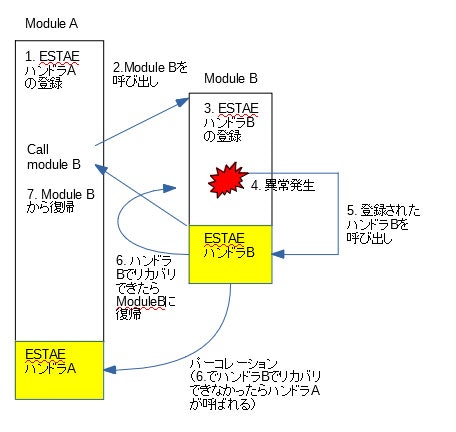
異常処理ハンドラの登録(FRR)
メインフレームにはESTAEのほかに__FRR__と呼ばれる機能もあります。
FRRもESTAEのように異常処理ハンドラを登録できるのですが、ESTAEと異なる点はシステム専用でMWやアプリが利用できない5代わりに__システムのロックを保持したまま__ハンドラが呼ばれる点です。ロックを保持した状態で異常処理を継続できるので、異常処理中にロックを再確保する必要がなくデッドロックを気にしなくて済むのが長所です。
Unix/Linuxのasync signal safeという仕様に苦しんだ人は、この価値が分かるかもしれません。「signal ハンドラの中で呼んでもよい関数」を限定するよりは、ロックを保持している時の専用のハンドラを持つ方が、リカバリ処理が楽にできるでしょう。
FRRのハンドラが登録されているとESTAEのハンドラよりも先にこのハンドラが呼び出されます。システムのロックを返却しなければならないときなど、どうしても返却しなければならない資源があるときに使える便利な機能です。
異常処理ハンドラで何を行うか?
異常処理出口ルーチンでは、とあるコプロセッサのドライバを書いた時の自分の経験では、以下のようなことをしていました。
- 異常が起きた時のデバッグ情報の記録
- 当該機能を使っているコンポーネントへの異常発生通知
- 可能であればコンポーネント内のポインタの修復
- 使っていた資源の返却(ロックや、確保していたメモリなど)
- 修復が不可能であった場合、再度当該機能が呼び出さたときにエラーを返すように設定
一つ一つ、順番に見ていきましょう。
1. 異常が起きた時のデバッグ情報の記録
異常が起きた時の状態について、あとから原因調査ができるようにするために、関係した個所の部分ダンプやログ、実行トレースの採取を行います。1年に一回発生する頻度のような難しいタイミング障害であっても、エンドユーザーから見ればこの前起きたばかりのトラブルです。そういう時のために、デバッグのための情報を保存しておいて、それをもとに確実に原因を突き止めなければなりません。異常が発生したコンポーネントについて、その時の内部の状態がどのような状態であったのか、関連する構造体などのデータを採取しておくことが肝要です。
部分ダンプと書きましたが、私が書いたドライバではそのドライバが使っているメモリ領域など、関連する箇所だけをダンプに採取していました。また、この部分ダンプを採取した後は、可能であればリカバリしてシステムが動作しつづける形になります。Linux kernelではこのような部分ダンプに該当するような機能はあまり記憶にありません。
(あえて言うなら、一番近いのはLinuxのkdumpですが、kdumpは部分ダンプではなくシステム全体のメモリダンプを採取するのが本来の目的であり、また再起動することが前提となっています。)
2. 当該機能を使っているコンポーネントへの異常発生通知
異常が起きたコンポーネントの機能を使っているプログラムには、異常が起きたことを通知する必要があります。
メインフレームは前述のとおり、可能な限りシステムが動作を継続するように設計されているので、これを行っておかないと__「システムは正常に稼働している」のに「業務に必要なコンポだけが死んでいた」__という最悪な死に方をしてしまいます。もしそうなってしまうと必要なリカバリ処理が動作しないため、業務システム全体に影響する大きなトラブルの原因となってしまうのです。
このため、当該コンポの処理完了を待って寝ているタスクすべてに対して、異常が起きたことを示す復帰コードを設定して、そのタスクをたたき起こす…ということをする必要があります。
Linux Kernelではメモリエラーが発生した場合には、その領域を使っているのがプロセスであればプロセスをkillするというのが最も近い動作になります。ただ、PCIeのエラーの場合などではそこまではできておらず、ログに記録を残すぐらいのことしかできていません。(ただし、これはLinuxではI/Oがkernel内でpage cacheからドライバ層まで多段階に抽象化されて、どのI/Oがどのプロセスに紐づいているのか判別できないためではないかと思います。メインフレームのI/O層はpage cacheのようなキャッシング層を持たないなど、比較的シンプルです。)
3. 可能であればコンポーネント内のポインタの修復
ここはあまり詳しくは書けませんが、私が書いたドライバではコンポーネント内部のリンクリストなどのポインタを、可能な限り修復していた記憶があります。
Linuxのドライバで同じようなことをしているものはちょっと記憶にありません。基本的にこのようなことが発生した場合はpanicさせるのがLinux kernelの基本的なスタンスです。
4. 使っていた資源の返却
使っていた資源は異常時であっても返却しなければなりません。例えば、使っていたメモリは返却しないとメモリリークとなって後々システムのメモリが足りなくなっていく可能性があります。さらに、システム全体のロックを持ったままの状態になっていると、後々システムがそのロックを取りに行こうとしてデッドロックしてしまいます。
このように異常処理ルーチンにおいて保持していた資源を返却することは重要です。可能な限りシステムの動作を存続させようとするためには、適切に資源を返却しなければなりません。
5. 修復が不可能であった場合、再度当該機能が呼び出さたときにエラーを返すように設定
当該のコンポーネントが異常な状態のまま使われないようにするために、システムから切り離します。コンポーネントが呼び出されたらエラーの復帰コードが返るようにしておきます。
メインフレームの文化
文化を語るうえで、少し昔話をしたいと思います。メインフレームのとある機能のソースコードの机上レビューで先輩から指摘された言葉は、私にとって一生忘れられないものとなりました。というのは、この言葉はメインフレームの文化の一端を示しているように思えるからです。
先輩:「アセンブラに変換したソースを見たら、この命令と次の命令の間で(ハード故障により)マシンチェックが起きたらどうなる?」
私:「????」
先輩:「 (FRRハンドラがまだ登録されていないから)ロックを返却できなくてシステムがストールするだろ? バグだから直そうね!」
先輩からごく当たり前のように言われたセリフは、メインフレームのシステム開発者たちが、異常処理に対してどのような態度で仕事をしていたのかを示していると思います。
ハード故障というのはソフトのどこが動いている時に発生するかは予想ができません。よって、私がレビューをうけたコード一か所だけが上記のような考慮をしたところで意味がありません。上から下までほぼすべてのソースコードが、このようなハード異常への考慮をしておかなければ指摘として意味がない言葉なのです。
メインフレームの信頼性の本当の凄さは、このようなハード故障時の異常処理ですらシステムを止めないという態度で実装してきており、それをずっと継続してきたことによるものだと思います。
また、このように異常処理をとことんまで突き詰めてまで実装しているので、全体のソースコードのうちの異常処理のコードの割合は非常に多かったと記憶しています。n=1の個人的な実感で恐縮ですが、メインフレームの正常系の処理と異常系の処理は直感的に比率にすると3:7ぐらいの割合で実装されていたという感触です。それぐらい、異常処理に力を入れて実装されていたように思います。(同じ比率を求めるなら、Linux kernelは5:5ぐらいでしょうか?興味のある方は計算してみてください。)
批判的な見解
ここまでメインフレームの異常時の処理について解説しましたが、最後に批判的な見解についても説明しましょう。
ここまでの解説を読んで違和感を感じた人もいるでしょうし、私もメインフレーム部門在籍当時から、懐疑的あるいは批判的な意見を聞いたことが何度もあります。メインフレームを妄信するのは健全な態度とは言えません。逆に、メインフレームを全面的に否定するのもエンジニアリングとして正しい姿ではないとも思います。
メインフレームとクラウドを含む現代的なアーキテクチャについて、メリットデメリットを冷静に分析して適切な技術を取捨選択できるようになるためには、メインフレームへの懐疑的な姿勢を知っておくのも重要でしょう。
「そもそもハード故障時の異常処理がうまくいくのか?」
手元にデータが無いので定性的な話になってしまいますが、CPU故障などが発生したときにリカバリ処理がうまく動作するかというと、メインフレームと言えどもやはり思うようにリカバリできなかったというケースも結構あるそうです。ハード故障というのは結局のところ、何が起きるかわからない__パルプンテ__であることも多く、これだけ頑張っているメインフレームといえどもうまくリカバリ処理を行うのは難しいようです。このため、ここまでリカバリ処理を頑張ることに意味があるのか?という考え方もあります。
個人的にはたとえ理想的に動作しなくとも、「ソフトとしてはここまでリカバリするように設計していました」と胸を張って言えるのは凄いことのように思わなくもないですが、技術的に意味があるかどうか意見が分かれるところでしょう。
(2020/5/3 20:00追記)
Facebookでコメントをいただきました。許可をいただけたので、こちらにも追記します。
「そもそもハード故障時の異常処理がうまくいくのか?」という話ですが、汎用機の仕事をしてた当時、
・「ハード故障を回避」するというより、「運用時のトラブル発生状況を「説明可能」にするための情報を残すという考え方をしなさい。」
・「プロの世界は、『説明責任を果たす』ことが必須だから。」
・「ベストエフォートでは許されないとまず認識しなさい。」
・「だからタスクのリンクについても3重化して、過去の状態遷移・その遷移を引き起こした要因を含めて残すのだ。」
・「そのためには、ハード故障を回避して、情報を残す必要があるのだ。」
と教わりました。参考まで。
「自分を異常だとするシステムでリカバリするのはそもそも信頼に値するのか? 」
そもそも異常の報告が信頼に値するのか?という意見があります。当時の隣の部署の上司から『「俺は気が狂った」と称する人の話を信頼するより、別の正常な人にリカバーさせるのが正しいだろ?だから、異常を起こしたシステムが自らESTAEやFRRでリカバリするのはおかしい。他のノードから回復処理を行うべきだ』という意見を伺ったことがあります。これは実際間違った意見ではありませんし、実際そのように設計されたメインフレーム後継を目指したシステムもあるそうです。
もちろん他のシステムによるリカバリは別な問題が浮上してきます。クラスタリングや分散システムによるリカバリの難しさについては、これを読んでいる読者のほうが詳しいかと思うのでここではあまり述べませんが、絶対的な解というのは無さそうです。結局のところ、「異常時のリカバリ処理をどこまでどのようにして行うか?」は技術的・金額的なコストと効果を見比べて、適切なものを採用していくことしか道はないのかもしれません。
まとめ
メインフレームの異常処理についてその考え方や内容について記述しました。また、それに対してLinuxではどのようなことを行っているのかについても、書ける範囲で補足しました。読者の参考になれば幸いです。
参考文献
「MVSの機能と構造」近代科学社(インプレス)ISBN-13: 978-4844372899
-
これもメインフレームではシステムコールではなく、SVC(Super Visor Call)ルーチンと呼ばれていたりします。 ↩
-
今のIBMのメインフレームOSはz/OSですが、基本的な考え方はMVSでもz/OSでも通じるはずです。 ↩
-
レビューしていただいた方によると、ESTAEのほかにESPIEというのものあるそうです。(ESTAEの方が機能範囲が広い)。ただ、残念ながら筆者はESPIEを使ったことがありません。 ↩
-
ただし、z/OSのマニュアルでは、"Any program function can use SETFRR..."と書かれているので、z/OSではシステムプログラムに限らず呼び出せるようになっているかもしれません。 ↩