はじめに
この記事は Fujitsu Advent Calendar 2021 25日目の記事です。(記事は個人の見解であり、組織を代表するものではありません。)
さて、今年もこれまでと同じく不揮発メモリの記事を書きます。今回は以下の内容です。
- 不揮発メモリ周りの規格・新仕様(CXL, RDMA)
- メモリ不足時の不揮発メモリの活用
- Filesystem-DAXの動向
不揮発メモリ周りの規格・新仕様
今年は規格回りでいくつか新仕様が策定されています。まずは、それらについてざっくりと解説していきましょう。
CXLの不揮発メモリ対応
これまではNVDIMM、すなわちDRAMと同じようにCPU中のメモリコントローラからDDR4で直接つながるデバイスであった不揮発メモリですが、ここへきて新たな接続方法が追加されようとしています。それがCompute Express Link(CXL)です。
コンピュータの筐体内のインターコネクトとしてはPCI Expressがほぼ業界標準となっていて広く普及していますが、その規格を拡張した1次世代インターコネクトとして新たにCXLが策定されてきました。
そして、このCXLの仕様のv2.0が昨年末に公開されましたが、そのCXLに不揮発メモリが接続されることが今年になって明らかになってきています。
これについてはStorage Developer Conference 2021(以後SDC 21)でのIntelのAndy Ruddof氏の発表 や、Linux Plumbers ConferenceのBen Widawsky氏の発表でその概略が公開されています。
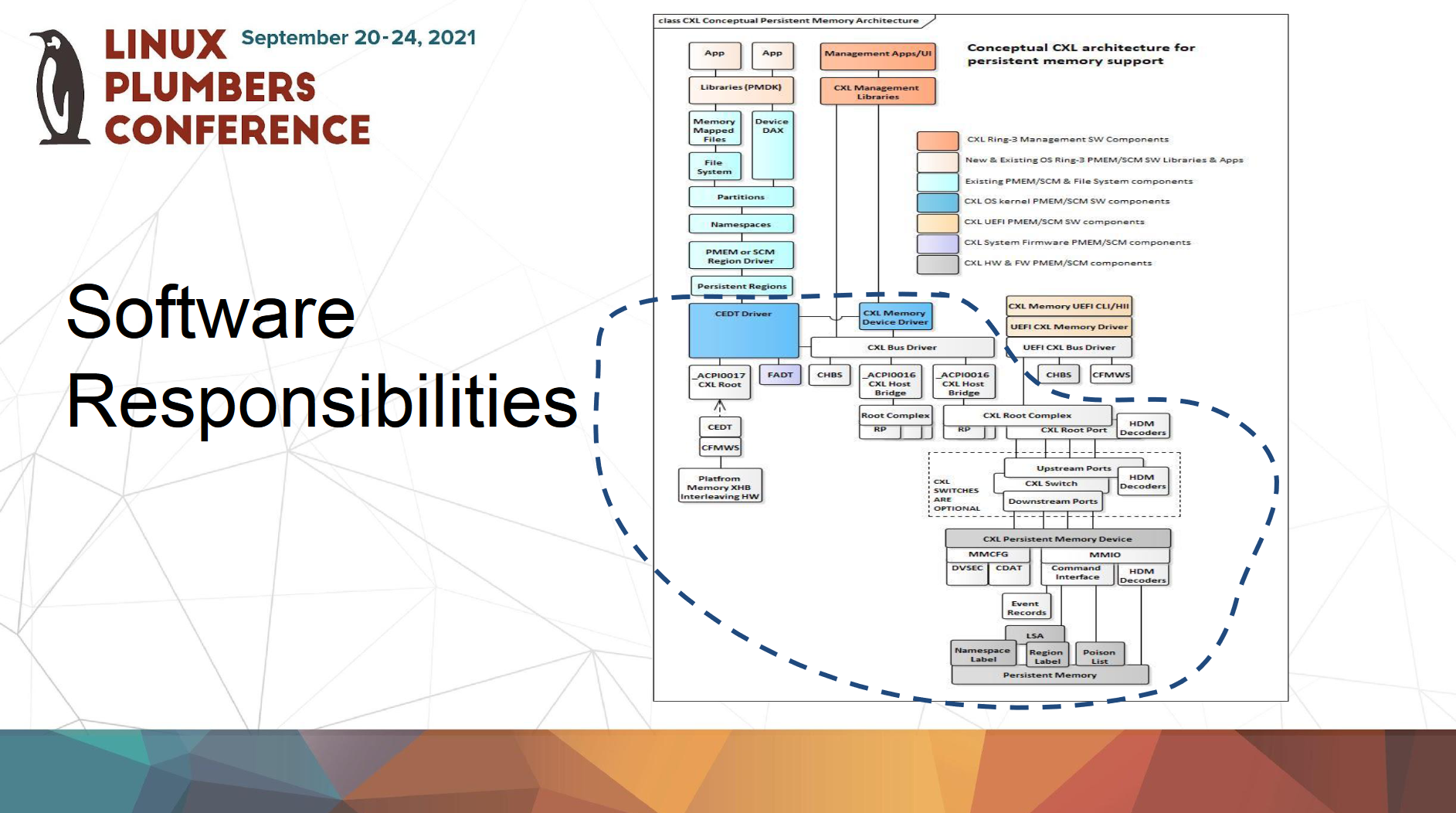
CXLになって変更される点
今回はこれらの資料から引用します。以下の図のようにCXLには3つの利用モデルがあります。1つ目は従来のI/Oデバイス向け(2022/2/2訂正)内部にキャッシュを持ちデバイス内部のメモリを他に見せないタイプのデバイス(左)。例えばRNICやFPGAで当該構成にした場合がそれに該当するようです。2つめは、GPGPUのように内部にキャッシュを持ち、かつデバイス内部のメモリを公開するようなアクセラレータのようなデバイスです(中)。そして3つ目に、揮発または不揮発メモリ向け(右)のインタフェースが用意されているのが分かります。

これまでNVDIMMのデバイスの認識やドライバの初期化のために、ACPIにNFITや_DSMといったインタフェースが定義されていました。しかし、CXLに接続される不揮発メモリでは、これらのインタフェースは使われないことが示されています2。

代わりにPCIeのようにメモリマップされたコンフィグレーション空間(MMCFG)やMMIOの仕組みがあり、そこで不揮発メモリデバイスの認識や設定が行われるようです。従来のNVDIMMとはデバイスの認識方法や設定方法がCXLになって大きく変わるため、CXLに接続される不揮発メモリ向けのドライバは新たに作る必要があり、かなりの工数がかかりそうです。すでにある程度のCXL向けのドライバはすでにupstream kernelにマージされているようで/driver/cxlのディレクトリ配下にある程度のソースがありますが、現在それがどれくらいの進捗なのかは筆者もまだ把握できていません。
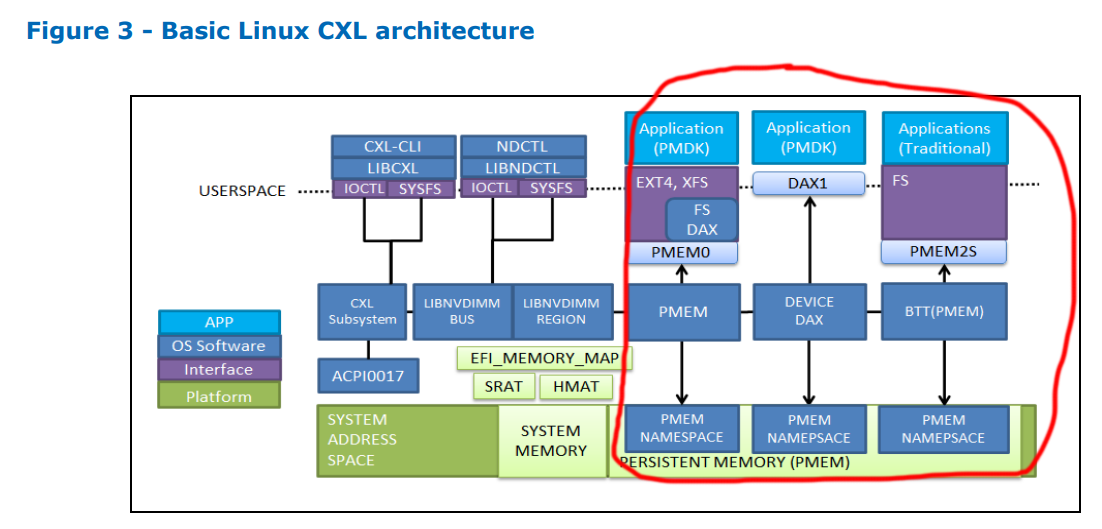
CXLになっても変わらない点
一方で、上記の図に示されているように、従来のNVDIMMと同じようにregionやnamespaceの設定は残るようです。
また、メモリ間のインターリーブはCXLでも従来のNVDIMMと同様に設定できるようです。

さらに、「CXL* Type 3 Memory Device Software Guide」 の図3には、CXLというインターコネクトの先に接続されながらも、CPUから不揮発メモリへの直接アクセスする機能もサポートされるため、Filesystem-DAXやDevice DAXが使えることが示されています。このため、これまで不揮発メモリ向けのアプリを作っていたミドルウェアやアプリには影響はなさそうですね。
CXLの影響
CXLという次世代の業界標準として期待されているインターコネクトに対して、不揮発メモリの規格が決まったことは大きな意味を持ちます。これまでは一部例外を除いて事実上IntelのData Center Persistent Memory Module一択でしたが、CXLのおかげでIntel以外のハードウェアベンダーがこの領域に参入できる可能性を示しているからです。実際サムソンはHPC向けにCXL対応の不揮発メモリを発表しています。今後、様々なメーカーが参入することで価格が安くなり、将来的には現在のNVMe SSDのように普及が進むかもしれません。
また、個人的には、HPCのような用途のほかにもArm向けの不揮発メモリが出たら、IoT/Edgeコンピューティングの世界で活躍するのではないかとかなり期待しています。
RDMAの新仕様
もう一つの新仕様はRDMAについてです。
これまで不揮発メモリDIMMに対するアクセス方法として、Filesystem-DAXやDevice-DAXのインタフェースによって、CPUから不揮発メモリへ直接アクセスする手段が提供されてきました。しかし、現代的なシステムでは、冗長化や負荷分散など様々な理由で複数または多数のシステムで全体を構成するのが当たり前であり、単一のシステムで処理か完結するということはあり得ません。このため、ネットワークなどを使って他のリモートシステムへデータを転送したりする必要があります。
しかし、せっかくローカルシステムのアクセスを高速にしても、リモートのシステムに対しては従来のTCP/IPを使った一般的なネットワークを使うとどうしてもそこがボトルネックになることが容易に推察されます。packetを解釈してドライバの領域からアプリの領域にデータをコピーしたりするなど、途中に様々な処理が介在するので、その分がどうしても遅くなってしまうのです。
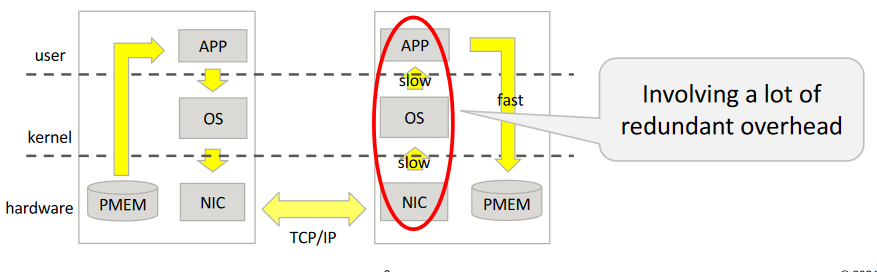
そこで、Remote Direct Memory Access(以後RDMA)でのリモートシステムへのデータ転送が有力候補となるわけです。RDMAとはローカルシステムのメモリから、異なるリモートシステム上のメモリに対してデータ転送を行う技術です。RDMAに対応したRNIC(またはHCA)カードは(リモートシステムの)CPUの介在なしに直接データをリモートシステム上のメモリに転送できるため、冗長な処理を省くことで大幅にデータ転送速度を向上させることができるからです。これは不揮発メモリにとっては大きなアドバンテージになるでしょう。
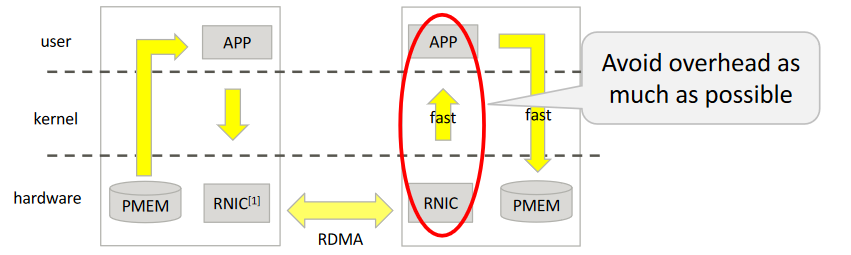
しかし、このRDMAも不揮発メモリにとっては重大な問題がありました。以下の図のようにwrite操作においては、リモート側のRNICはデータを受け取った時点、言い換えるとデータの書き込みを完了する前にローカル側にAckを返すことができるため、データの書き込みが確かに完了したかどうかその時点ではわからないということになってしまいます。これは、データベースのようにトランザクション処理を行うような用途では致命的といってよいでしょう。
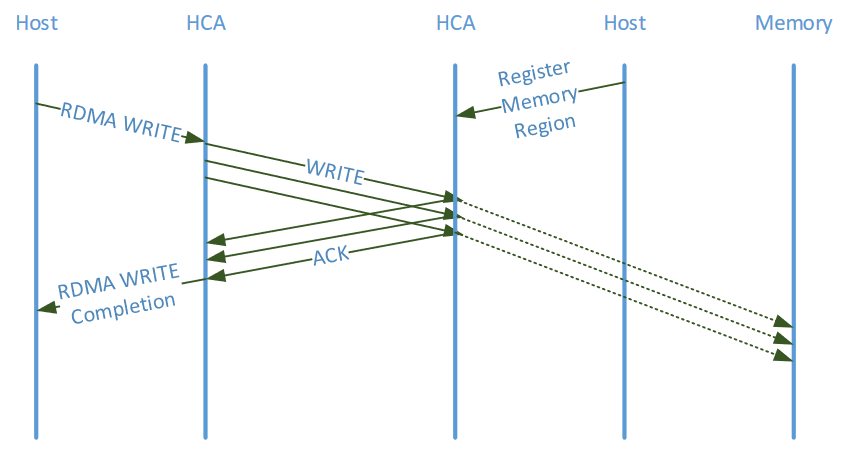
現状ではデータの永続性を保証するためには、例えばwriteが終わった後にその領域をreadするなどいくつかの方法がありますが、それらはどうしても操作としては重くなりがちです。
そこで、RDMAの仕様のうちInfiniband3については2021年8月にv1.5のが策定され、その中では不揮発メモリ向けの操作が2つ追加されました。この新仕様については、前述のSDC 21において、IntelのChet Douglas氏からその概略について話がなされており、その時の資料や動画も公開されています。
また、私のチームののYangさんもOpen Source Summit Japanにてその新仕様の内容やSoftRoCEでの実現方法などを発表PDFしています。
(なお、IETFにおいてもほぼ同様な操作が提案されています。ただ、こちらは2020年9月に提案した後、その後の様子が分かりません。このため、これ以降はこのInfinibandの新仕様ベースでお話しします。)
Infinbandでは追加された操作は以下の2つです。これらについて上記資料を参照しつつご紹介しましょう。
- flush
- atomic write
flush
次の図のように、flushはそれまで発行されたwriteの操作についてその書き込みの完了を待つ操作です。正確にはメモリコントローラ(図中ではMemory Subsystem)からの応答を待つ操作となります。なお、メモリコントローラからさらに先の不揮発メモリデバイスまでの間についても本来ならデータの永続性を保証すべきですが、これについてはおそらく従来からあるADR4によって保たれることになるでしょう。
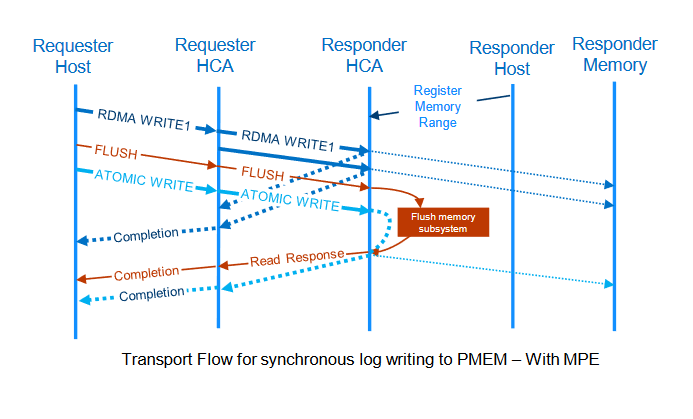
atomic write
atomic writeは上記の図のように、先行するflushの完了を待ってから8バイトの値をアトミックに書く操作になります。ローカル側がatomic writeの要求を出すときにはflushの完了を待つ必要がありません。リモート側のRNICがその順序を保証してくれるからです。データベースなどの処理で巨大なデータを書き込んだ後、トランザクション処理を行い時などに非常に便利な機能と言えます。
仕様が策定されてから実際にこの操作に対応したハードウェアが出るまでは、まだしばらく時間がかかるだろうと予想しています。が、私のチームでは上記のYangさんの発表のとおり、一足先にSoftRoCEでエミュレーションする方法を検討中です。上記の発表のPDFでも触れていますので、ぜひご参照ください。(数か月後には動画がLinux FoundationからYoutubeに公開されると思います。)
メモリ不足時に不揮発メモリにデータを移動
memory demotion/promotion
メモリ不足時にその内容を一時的にSSDやHDDに退避させるswap outの機能は皆さんにとってなじみの深い機能でしょう。このメモリ上のデータの退避先にSSDやHDDではなく、不揮発メモリを使うという機能がkernel5.15にて追加されました。Publickeyでも「不揮発性メモリへのスワップアウト」として紹介されていますから、ご存じの方も多いでしょう。この機能について補足しておきましょう。
まずこの機能、実はswap outという機能とは厳密には異なります。swap outではSSDやHDDにデータを退避してしまった場合は、swap inによってDRAMに戻すまではCPUからはデータにアクセスすることはできなくなってしまいます。仮に従来のNVDIMMでもStorage Modeでnamespaceを作成してswapデバイスとして設定しても、kernelはこの不揮発メモリの領域をSSDやHDDと同じく「CPUからアクセスできないストレージ」として認識してしまっているので、CPUから直接アクセスすることはできません。
一方、この機能ではswap in/swap outではなくmemory migraitonの機能5を使ってデータの内容を移動させます。これはユーザープロセスの仮想アドレスを変更せず、それに紐づいている物理アドレス上のデータをkernelのメモリ管理機構がこっそり移動させるというテクニックです(下図)。
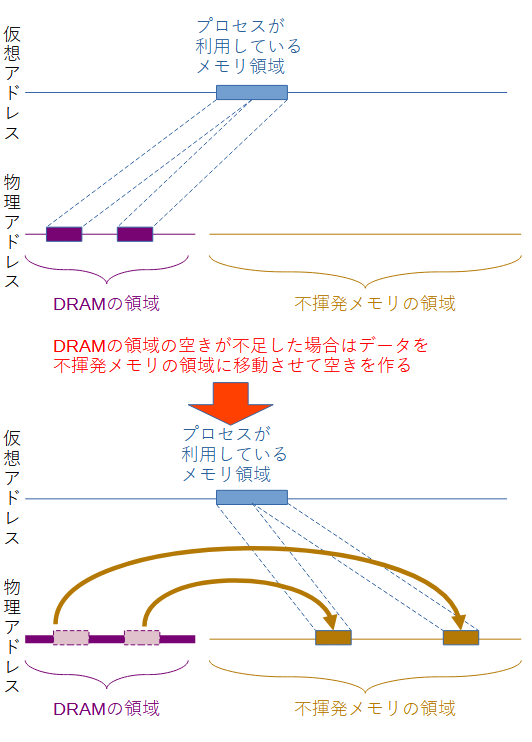
物理アドレスは移動しますが、プロセスから見た仮想アドレスは変わらないので、不揮発メモリの領域にデータが移動した後でもプロセスはそのデータにそれまでと同じようにアクセスし続けることができます。この点がswap out/swap inと比べて大きく異なる点です。このため、カーネルソース中ではswap out/swap inではなく、__demote(降格)/promote(昇進)__という表現がされています。
demoteはアクセス速度の速いメモリ(DRAM)から遅いメモリ(通常は不揮発メモリ)へ移動、promoteはその逆です。不揮発メモリの大容量性に着目した美味い機能だと思います。
promoteの難しさ
ところでこの機能、demoteはkernel 5.15で確かにマージされているのですが、promoteについては実はまだ開発中です。 この原因は投稿されているpromotionの実現パッチのdescriptionを読むとその一端が推測できます。
demoteだけなら空いていると思われる領域にデータを追い出すだけですが、promoteではメモリがひっ迫しやすいノードにデータを戻すことになります。というのは、メモリ管理機構はできるだけプロセスが利用しているCPUからできるだけアクセス速度の速い領域のメモリを使おうとするからです。そういう領域にメモリを戻すわけですから、空きメモリがたまたまあればよいですが、空きが無ければだれかが使っているページを代わりにdemoteやswap outなどしなければなりません。そのため新たに色々な考慮が必要となってきています。
現在投稿されているパッチでは、従来の基準よりもメモリ使用量が少ない時点でもkswapdを動作させてメモリを押し出したり、またpromoteしたメモリがすぐにdemoteしてping pongが無駄に発生したりすることを抑えたり、Transparent Huge Pageの機能のためにkswapdが誤って動作しなくなることを防ぐために定期的に動作させるようにロジックを変更する…などがなされており、色々苦労していることがうかがえます。
このあたりのロジックが固まってpromoteが実現するまでにはもう少し時間がかかるかもしれません。
demote機能を使うためには
ちょっと余談になりますが、このdemoteの機能は一昨年紹介した不揮発メモリをkernelがDRAMのようにとして使う機能を使っています。一昨年の記事では以下のようにsysfsで設定する方法を紹介しました。
To make this work, management software must remove the device from
being controlled by the "Device DAX" infrastructure:
echo -n dax0.0 > /sys/bus/dax/drivers/device_dax/remove_id
echo -n dax0.0 > /sys/bus/dax/drivers/device_dax/unbind
and then bind it to this new driver:
echo -n dax0.0 > /sys/bus/dax/drivers/kmem/new_id
echo -n dax0.0 > /sys/bus/dax/drivers/kmem/bind
この機能を使うには、現在以下のようにdaxctlコマンドを使うと楽に実行できます。
まず、この機能を使えるようにsysfsの構成を変える必要があります。このため、以下のコマンドを打ってシステムを再起動します。(または関係するカーネルモジュールをいったん切り離してudevadm triggerでリロードしても良いそうですが筆者は試したことがありません)。
daxctl migrate−device−model
このコマンドは設定ファイルを作るだけなので、一度実行するとずっと有効になります。
その後、以下のコマンドを実行することで、指定したDevice DAXの領域がkernelのメモリとして利用されるようになります。
この指定した不揮発メモリの領域は、"CPUが搭載されていないアクセス速度が他のノードと比べて遅いNUMAノード"として登録されます。
daxctl reconfigure-device --mode=system-ram --no-online --human dax6.0
{
"chardev":"dax6.0",
"size":"248.06 GiB (266.35 GB)",
"target_node":11,
"mode":"system-ram",
"movable":false
}
reconfigured 1 device
移動先の選択
厳密にはdemoteの機能は正確には”不揮発メモリ”を判別して移動先に選ぶというわけではありません。上記の機能で登録されるような、「CPUが搭載されていないアクセス速度が他と比べて遅いNUMAノード」を優先的にdemote先として優先的に選択するようになっています。つまり"DRAMでも当該のCPUからの距離が非常に遠いためアクセス速度が遅いノード"とか、"CPUがついていないMemoryだけのNUMAノード"であってもdemote先として選ばれる可能性があります。ただ、そういうNUMAノードは結果的に上記で設定された不揮発メモリの領域が選ばれやすいというだけです。
今後のCPUとメモリの間のアクセス速度がどうなっても対応できるように配慮したため、このような作りになっているのかもしれません。
Filesystem DAXのExperimental Statusはどうなった?
最後に、Filesystem DAXの開発状況について説明しましょう。結論から言うと、残念ながら今なおExperimental Statusのままです。
昨年の記事では、Filesystem-DAXがExperimentalとなっている当時の課題として以下をあげてました。
- DMA/RDMA v.s. Filesystem DAX
- inodeごとのdax 利用のon/off
- FilesystemのCopy On Write機能との両立
このうち、1については結局、ハード側がOn Demand Pagingの機能を持つことが事実上の解決策となっていて、これがExperimentalの原因とはみなされなくなっています。(kernel側で解決する方法は実装が相当複雑になるそうで、コミュニティに受け入れられる可能性は低いようです。)
2.については、昨年提案したパッチがupstreamに取り入れられて、問題が完全になくなりました。drop_cachesをする必要もなくなったので、kernelのドキュメントからその記述を削除しています。
3.については、これを解決するためのRuanさんの開発したパッチ群があともう少しで入りそう…というところまで来ています。また、昨年の段階ではLVMなどのデバイスマッパーが使われた時にどうするのかといった問題が残っていましたが、それも今年は解決済みです。これについてはLinux Plumbers Conferenceでその内容を私とRuanさんとで発表[ PDF | 動画 ]している6ので、そちらをご覧ください。
しかし、残念ながら今年の2月に新たに4つ目の問題が指摘されました。その影響もうけて上記の3についても実装の変更が必要となり、これが3についても時間がかかる原因となったのです。この4つ目の問題とはunbindとのrace conditionが報告されたものです。
unbind機能とのrace condition
unbindとは、Windowsでいう所の「ハードウェアを安全に取り外してメディアを取り出す」の操作に相当する機能だと考えればよいでしょう。
ただ問題は、Windowsのように__利用中のタスクがいる場合は取り外しを待つ__という動作ではなく、Linuxのunbindは__強制的に取り外し処理が進む__という仕組みなっていることです。「Windowsのように対象のデバイスを利用中なら取り外しを一旦停止したりcancelするような仕組みはないの」とは誰もが思う疑問かもしれませんが、Linuxではそのような機能にはなっていません。実際、コミュニティで私から問い合わせたところ、NVDIMMのメンテナーであるIntelのDan Williamsから、Linuxではそのような仕組み自体が用意されていないという返事が返ってきました。
では一方で、「不揮発メモリDIMMならHotplugできるような仕組みが構造上存在しないので、unbindのような操作は不要じゃないか?」と考える人がいるかもしれません。しかし、このインタフェースはnamespaceの設定変更にすでに使われていて、例えば「Filesystem-DAXからDevice DAXにnamespaceを切り替える」といった操作を行うと動作してしまいます。(先ほど説明した「不揮発メモリをkernelがDRAMのように扱う機能」の設定をもう一度見ていただくとわかるように、この場合でもsysfsのunbindという設定ファイルに値を書き込むことによって、領域をいったん論理的に切り離すことを行っています。)
このため、もしFilesystem-DAXを利用中にユーザが強制的にネームスペースを切り替えてしまうと、unbindがFilesystem-DAXの利用中に動いてしまうというわけです。このため、surprising hot-remove、すなわち不揮発メモリを利用中であっても強制的なデバイスの切り離しを行う機能の追加が必要が出てきました。
この機能は現在先ほど3.のFilesystemのCopy On Write機能との両立の開発の中で作っている機能を流用して作成することが内定しています。というのは、我々が3.で作っているパッチの中でも最後のパッチは__「不揮発メモリ上のあるページが故障した場合、そのページ(ブロック)利用しているプロセスをkillできるように、追跡できるようにするための機能」だからです。
unbindの場合、”あるページが故障した”のではなく、"unbind対象のページが全て故障した"__と解釈してプロセスをkillする必要があります。このため、この問題については3.の解決後に取り組むことになる予定です。
まとめ
不揮発メモリについて、Linuxと周辺の規格・使用などについて今年の動向をまとめました。いかがだったでしょうか?
昨年の想定よりも私のチームも苦労していますが、来年も頑張りますのでよろしくお願いします。
-
CXLについては私もまだまだこれから勉強という段階なのですが、CXLのサイトの冒頭で次のように説明されています。"Compute Express Link™ (CXL™) is an industry-supported Cache-Coherent Interconnect for Processors, Memory Expansion and Accelerators."とされています。デバイスとCPU間でメモリアクセスの際に、Cache-Coherencyを保つための仕組みが入った…という点が大きいようです。 ↩
-
ところで、このページにあるように、CXLに挿入される不揮発メモリはもはやNVDIMMと呼べなさそうですね。 ↩
-
infinibandについて知りたいという方は、nminoruさんによる解説が非常におすすめです。http://www.nminoru.jp/~nminoru/network/infiniband/ ↩
-
プラットフォーム側がメモリコントローラから不揮発メモリデバイスの間のデータの永続性に責任をもつという仕組みです。 ↩
-
この機能、もともとはMemory Hotplugのために作られた機能です。運用中にメモリを抜くためには動作中のプロセスが利用しているメモリを退避させなければならないため、他のメモリの領域に移動させるという機能が必要だったのです。このあたりの解説は以前日経の記事で解説しています。このmemory migrationの機能は、HPC向けのメモリの最適化や、フラグメントの解消、透過的なHugepageの作成機能など、様々な応用をされています。 ↩
-
この発表、メンテナーの方々には好評だったようで、NVDIMMのメンテナーであるDan Williamsからは"Great Presentation!"というコメントをいただきました。また、XFSのメンテナーのDarick Wangは「ちょっと今後のファイルシステムについて議論しない?」とQ/Aの時間に突然のパネルディスカッションを始めてしまいました。動画のように私もRuanさんも突然の展開についていけずワタワタしてますが、それも今年の良い思い出です。 ↩