概要
読んで字の如くです。と言うか、このプログラムを作った後に元ネタのソースコードの存在を知ったのでハッキリ言って泣きそうです。(元ネタのサイト)
正確な理論は**参考文献(論文)がある**のでそちらを当たってください。以下はそれを読んだ前提で書きます。
※2016/01/12追記:別の糸口から厳密解を高速に求めることに成功しました。このページの最後の方(目次で言えば「おまけ」)をご覧ください。
ソルバに投げるデータ(lpファイル)を作成する
本来なら何回かこの作業が必要なのですが、論文が難解過ぎてよく分からなかったので1回で済ませます。
この際、ソルバは結果の上界を返します。つまり、「まあこれが正解っぽいけど100%全部使うとは保証しない」感じです。具体的には、**「始点と終点を別途定める」「始点と終点を除いた各頂点において、入力されるフロー量=出力されるフロー量」「始点と終点から出る辺はどちらも1本づつ」「使用する辺の数を最大化する」**感じでlpファイルを組み立てていきます。具体的にはこんな感じ。
[word_list.txt]
しまむらうづき
きたひなこ
こばやかわさえ
えびはらなほ
ほんだみお
ほししょうこ
きむらなつき
きしべあやか
かわしまみずき
こひなたみほ
[単語(の先頭・末尾に現れる文字)の対応表]
{"え"=>0, "お"=>1, "か"=>2, "き"=>3, "こ"=>4, "し"=>5, "ほ"=>6}
[先頭・末尾の文字のペアの個数]
{[5, 3]=>1, [3, 4]=>1, [4, 0]=>1, [0, 6]=>1, [6, 1]=>1, [6, 4]=>1, [3, 3]=>1, [3, 2]=>1, [2, 3]=>1, [4, 6]=>1}
……例えば[6, 1]=>1は、「ほ」から始まって「お」で終わる単語を表している
[query.lp]
maximize
# 最大化したい値
# ここでx_5_3は、「し」から始まって「き」で終わる単語がグラフ中に現れる回数を表している
+ x_5_3 + x_3_4 + x_4_0 + x_0_6 + x_6_1 + x_6_4 + x_3_3 + x_3_2 + x_2_3 + x_4_6
subject to
# 各辺におけるフロー量の制約条件
# 例えば「 + x_2_3 + x_2_t - x_3_2 - x_s_2 = 0」は、「か」から始まる単語の和と「か」で終わる単語の和が同じだということ
+ x_0_6 + x_0_t - x_4_0 - x_s_0 = 0
+ x_1_t - x_6_1 - x_s_1 = 0
+ x_2_3 + x_2_t - x_3_2 - x_s_2 = 0
+ x_3_4 + x_3_3 + x_3_2 + x_3_t - x_5_3 - x_3_3 - x_2_3 - x_s_3 = 0
+ x_4_0 + x_4_6 + x_4_t - x_3_4 - x_6_4 - x_s_4 = 0
+ x_5_3 + x_5_t - x_s_5 = 0
+ x_6_1 + x_6_4 + x_6_t - x_0_6 - x_4_6 - x_s_6 = 0
+ x_7_t - x_s_7 = 0
+ x_8_t - x_s_8 = 0
# 始点および終点における制約条件
+ x_s_0 + x_s_2 + x_s_3 + x_s_4 + x_s_5 + x_s_6 = 1
+ x_0_t + x_1_t + x_2_t + x_3_t + x_4_t + x_6_t = 1
bounds
# 使用される変数の上限
x_5_3 <= 1 x_3_4 <= 1 x_4_0 <= 1 x_0_6 <= 1 x_6_1 <= 1 x_6_4 <= 1 x_3_3 <= 1 x_3_2 <= 1 x_2_3 <= 1 x_4_6 <= 1
binary
# 始点と終点は1本しかないので0-1変数
x_s_0 x_s_2 x_s_3 x_s_4 x_s_5 x_s_6
x_0_t x_1_t x_2_t x_3_t x_4_t x_6_t
また、この際の状況を図示するとこうなります。幸い、「同じ文字で始まって同じ文字で終わる人」がダブってないので漢字表記にしてみます。
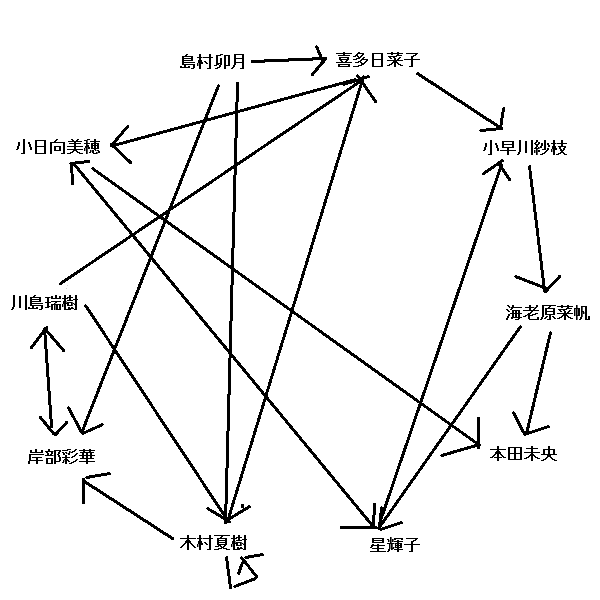
ソルバーに解かせる
後は、この問題をSCIPなどの適当なMIPソルバーに投げつけ、結果を受け取ります。すると、「各単語(正確には、ある文字から始まってある文字で終わる単語)が各何回使われるか」が分かりますので、そこから閉路を除去→一本道となる道を探索→閉路と合わせておしまいとなります。
ただ、この辺の理論が論文を読んでも地味に分からなかったので、とりあえずDFSで探索しました。上記問題の場合の最適解は次のようになります。
長さ:10
開始->しまむらうづき->きしべあやか->かわしまみずき->きむらなつき->きたひなこ->こばやかわさえ->えびはらなほ->ほししょうこ->こひなたみほ->ほんだみお->終了
画像化するとこんな感じですね。もちろん全単語を使えないことも多々ありますが。
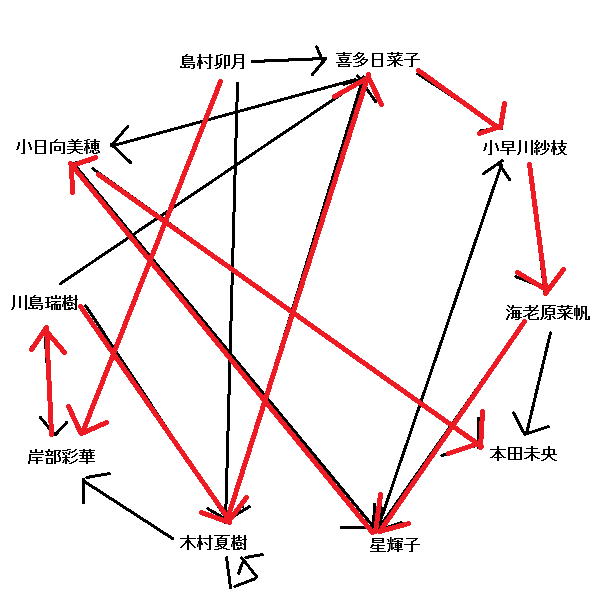
まとめ
このようにして、最長しりとり問題を解くことができました。ただし、このコードだとちょっとデータ量が多くなると最適解が出るまで時間が掛かりますので、なるべくなら元ネタのサイトで処理することをおすすめします。お粗末さまでした。
ちなみにしぶりんがいないのは「し」で終わる名前のアイドルが思いつかなかったため
ソースコードを置いておきます
require 'unf'
def norm_str(str)
# 英字なら小文字にする
str2 = str.downcase
# ひらがなとカタカナなら濁点・半濁点を除き、小文字を大文字にする
str2 = str2.to_nfd.split('').reject{|char| char =~ /^゙゚/}.join
str2 = str2.tr("ぁぃぅぇぉゃゅょっゎ", "あいうえおやゆよつわ")
str2 = str2.tr("ァィゥェォャュョッヮ", "アイウエオヤユヨツワ")
# 促音を除外する
str2 = str2.gsub('ー', '')
# その他ならそのまま返す
return str2
end
def conv(best_root, word_list, char_hash)
output = ''
return '' if best_root == nil
(best_root.size - 1).times{|i|
if char_hash.rassoc(best_root[i])[0] == '開始' then
output += '開始->'
next
end
candi = []
word_list.each{|word|
if norm_str(word) =~ /^#{char_hash.rassoc(best_root[i])[0]}.*#{char_hash.rassoc(best_root[i + 1])[0]}$/ then
candi.push(word)
end
}
if candi.size == 1 then
output += candi[0] + '->'
elsif candi.size != 0 then
output += '('
candi.size.times{|j|
output += '|' if j != 0
output += candi[j]
}
output += ')' + '->'
end
}
output += '終了'
return output
end
def dfs(word_list, char_hash, char_hash_size, start_pos, pair_hash3, root, best_root)
# return best_root if best_root.size != 0
# puts start_pos.to_s + ":" + root.to_s + " " + root.size.to_s
root.push(start_pos)
# 終端ノードである際の処理
if start_pos == char_hash_size + 1 then
# puts "Root:" + root.to_s + " " + root.size.to_s
if best_root.size < root.size then
best_root = Marshal.load(Marshal.dump(root))
puts best_root.to_s + " " + (best_root.size - 1 - 2).to_s
puts conv(best_root, word_list, char_hash)
end
else
# 終端ノードに行ける場合はとりあえず行ってみる
if pair_hash3.has_key?([start_pos, char_hash_size + 1]) && pair_hash3[[start_pos, char_hash_size + 1]] > 0 then
# puts "Last:" + pair_hash3.to_s
pair_hash3[[start_pos, char_hash_size + 1]] -= 1
best_root = dfs(word_list, char_hash, char_hash_size, char_hash_size + 1, pair_hash3, root, best_root)
pair_hash3[[start_pos, char_hash_size + 1]] += 1
end
# start_posから始まるノードを片っ端から辿る
char_hash_size.times{|next_pos|
if pair_hash3.has_key?([start_pos, next_pos]) && pair_hash3[[start_pos, next_pos]] > 0 then
# puts "Normal:" + pair_hash3.to_s
pair_hash3[[start_pos, next_pos]] -= 1
best_root = dfs(word_list, char_hash, char_hash_size, next_pos, pair_hash3, root, best_root)
pair_hash3[[start_pos, next_pos]] += 1
end
}
end
root.pop
return best_root
end
# 単語リストを読み込む
Encoding.default_external = 'UTF-8'
word_list = File.read('word_list.txt').split("\n")
# 単語の先頭文字および末尾文字の種類を数える
char_hash = {}
word_list.each{|word|
char_hash[norm_str(word)[0]] = 1
char_hash[norm_str(word)[-1]] = 1
}
char_array = char_hash.to_a.sort
char_array.size.times{|i| char_array[i][1] = i}
char_hash = Hash[*char_array.flatten]
char_hash_size = char_hash.size
char_hash['開始'] = char_hash_size
char_hash['終了'] = char_hash_size + 1
# 単語の先頭文字および末尾文字のペアを数える
pair_hash = Hash.new(0)
word_list.each{|word|
pair_hash[[char_hash[norm_str(word)[0]], char_hash[norm_str(word)[-1]]]] += 1
}
p char_hash;puts ''
p pair_hash;puts ''
# lpファイルを組み立てる
# 最大化する値
# lp_file = "# 最大化するのはフロー量の総和\n"
lp_file = "maximize\n"
pair_hash.each{|pair|
lp_file += ' + x_' + pair[0][0].to_s + '_' + pair[0][1].to_s
}
lp_file += "\n"
# 制約条件
lp_file += "\nsubject to\n"
# lp_file += "\n# 各頂点に対して、入力フローの和=出力フローの和\n"
char_hash.each_value{|i|
pair_hash.each{|pair|
if pair[0][0] == i then
lp_file += ' + x_' + i.to_s + '_' + pair[0][1].to_s
end
}
lp_file += ' + x_' + i.to_s + '_t'
pair_hash.each{|pair|
if pair[0][1] == i then
lp_file += ' - x_' + pair[0][0].to_s + '_' + i.to_s
end
}
lp_file += ' - x_s_' + i.to_s
lp_file += " = 0\n"
}
# lp_file += "\n# 始点と終点における制約条件\n"
lp_file += "\n"
char_hash.each_value{|i|
pair_hash.each{|pair|
if pair[0][0] == i then
lp_file += ' + x_s_' + i.to_s
break
end
}
}
lp_file += " = 1\n"
char_hash.each_value{|i|
pair_hash.each{|pair|
if pair[0][1] == i then
lp_file += ' + x_' + i.to_s + '_t'
break
end
}
}
lp_file += " = 1\n"
# 変数一覧
# lp_file += "\n# 変数一覧(各頂点)\n"
lp_file += "\nbounds\n"
pair_hash.each{|pair|
lp_file += ' x_' + pair[0][0].to_s + '_' + pair[0][1].to_s + ' <= ' + pair[1].to_s
}
lp_file += "\n"
# lp_file += "\n# 変数一覧(始点・終点)\n"
lp_file += "\nbinary\n"
char_hash.each_value{|i|
pair_hash.each{|pair|
if pair[0][0] == i then
lp_file += ' x_s_' + i.to_s
break
end
}
}
lp_file += "\n"
char_hash.each_value{|i|
pair_hash.each{|pair|
if pair[0][1] == i then
lp_file += ' x_' + i.to_s + '_t'
break
end
}
}
lp_file += "\n"
# lpファイルを出力する
io = File.open('query.lp', 'w:SHIFT_JIS')
io.puts lp_file
io.close
# SCIPで計算を実行する
io = File.open('query.txt', 'w:SHIFT_JIS')
io.print "read query.lp\noptimize\nwrite solution query.sol\nquit\n"
io.close
system('scip-3.1.1.1.win.x86.msvc.opt.spx.ld.exe < query.txt > log.txt')
File.delete('query.txt')
File.delete('log.txt')
File.delete('query.lp')
# 結果を受け取り、読み込む
# (char_hash_sizeがstart、char_hash_size+1がterminalの位置を示す)
pair_hash2 = {}
sum = 0
File.read('query.sol').split("\n").each{|line|
next if line[0] != "x"
line = line.gsub(/ {1,}/, "\t").sub('s', char_hash_size.to_s).sub('t', (char_hash_size + 1).to_s).split("\t")
pair_hash2[line[0].sub('x_', '').split('_').map(&:to_i)] = line[1].to_i
sum += line[1].to_i
}
File.delete('query.sol')
# p pair_hash2; puts ''
puts '上界:' + (sum - 2).to_s
# 幅優先探索で最長経路を求める
root = []; best_root = []; start_pos = char_hash_size
pair_hash3 = Marshal.load(Marshal.dump(pair_hash2))
best_root = dfs(word_list, char_hash, char_hash_size, start_pos, pair_hash3, root, best_root)
puts '長さ:' + (best_root.size - 1 - 2).to_s
# p best_root
# p char_hash
puts conv(best_root, word_list, char_hash)
おまけ
Tsutomu-KKE@githubさんの提案法を使っても解いてみました。こちらの方がより直感的で、しかも上のコードよりは速く解けます(C++の予約語84個で一瞬、ポケモン718種で17秒ほどプログラムの改良でポケモンも一瞬になりました)。皆もRubyとSCIPをダウンロードして試してみるんだ!
# 最長しりとり問題の定式化II
# http://qiita.com/Tsutomu-KKE@github/items/ba2dedb5795cae36f8a1
require 'unf'
# 文字列を正規化したものを返す
def normStr(str)
# 英字なら小文字にする
str2 = str.downcase
# ひらがなとカタカナなら濁点・半濁点を除き、小文字を大文字にする
str2 = str2.tr('がぎぐげござじずぜぞだぢづでどばびぶべぼぱぴぷぺぽぁぃぅぇぉゃゅょっガギグゲゴザジズゼゾダヂヅデドバビブベボパピプペポァィゥェォャュョッ', 'かきくけこさしすせそたちつてとはひふへほはひふへほあいうえおやゆよつカキクケコサシスセソタチツテトハヒフヘホハヒフヘホアイウエオヤユヨツ')
# 促音を除外する
str2 = str2.gsub('ー', '')
# その他ならそのまま返す
return str2
end
# 文字列Aの末尾が文字列Bの先頭と等しいかを判定する
def isMatch(str1, str2)
# norm_str1 = normStr(str1)
# norm_str2 = normStr(str2)
# return norm_str1[-1] == norm_str2[0]
return str1[-1] == str2[0]
end
def makeLP(word_list)
word_list_size = word_list.size
# 線が引けるペアの一覧を作成する
puts '線が引けるペアの一覧を作成...'
word_list_ = Array.new(word_list_size)
word_list_size.times{|i|
word_list_[i] = normStr(word_list[i])
}
pair = {}
word_list_size.times{|i|
word_list_size.times{|j|
pair[[i,j]] = 1 if isMatch(word_list_[i], word_list_[j])
}
}
#p pair
# 最大化する値=線の数
puts '最大化する値=線の数...'
lp_file = "maximize\n"
pair.each_key{|key|
lp_file << " + x_#{key[0]}_#{key[1]}"
}
lp_file << "\n"
lp_file << "\nsubject to\n"
# 制約条件1:線が引ける本数(出力編)
puts '制約条件1...'
word_list_size.times{|i|
flg = false
word_list_size.times{|j|
unless pair[[i, j]].nil? then
lp_file << " + x_#{i}_#{j}"
flg = true
end
}
lp_file << " <= 1\n" if flg
}
lp_file << "\n"
# 制約条件2:線が引ける本数(入力編)
puts '制約条件2...'
word_list_size.times{|i|
flg = false
word_list_size.times{|j|
unless pair[[j, i]].nil? then
lp_file << " + x_#{j}_#{i}"
flg = true
end }
lp_file << " <= 1\n" if flg
}
lp_file << "\n"
# 制約条件3:先頭の単語における制約
puts '制約条件3...'
word_list_size.times{|i|
word_list_size.times{|j|
lp_file << " + x_#{i}_#{j}" unless pair[[i, j]].nil?
}
word_list_size.times{|j|
lp_file << " - x_#{j}_#{i}" unless pair[[j, i]].nil?
}
lp_file << " - y_#{i} <= 0\n"
}
lp_file << "\n"
# 制約条件4:先頭の単語は1つだけ
puts '制約条件4...'
word_list_size.times{|i|
lp_file << " + y_#{i}"
}
lp_file << " = 1\n"
# 変数宣言
puts '変数宣言...'
lp_file << "\nbinary\n"
pair.each_key{|key|
lp_file << " x_#{key[0]}_#{key[1]}"
}
return lp_file
end
# 単語リストを読み込む
puts '単語リストを読み込み...'
Encoding.default_external = 'UTF-8'
word_list = File.read('word_list.txt').split("\n")
# lpファイルを組み立てる
lp_file = makeLP(word_list)
# lpファイルを出力する
puts 'lpファイルを出力...'
io = File.open('query.lp', 'w:SHIFT_JIS')
io.puts lp_file
io.close
# SCIPで計算を実行する
puts '計算中...'
io = File.open('query.txt', 'w:SHIFT_JIS')
io.print "read query.lp\noptimize\nwrite solution query.sol\nquit\n"
io.close
system('scip-3.1.1.1.win.x86.msvc.opt.spx.ld.exe < query.txt > log.txt')
# 結果を受け取り、読み込む
# (char_hash_sizeがstart、char_hash_size+1がterminalの位置を示す)
puts '結果を読み込み...'
hash = {}
y = 0
File.read('query.sol').split("\n").each{|line|
line = line.gsub(/ {1,}/, ' ').split(' ')
case (line[0])[0]
when 'x'
temp = line[0].split('_')
hash[temp[1].to_i] = temp[2].to_i
when 'y'
y = line[0].split('_')[1].to_i
end
}
# 適切な形で出力する
# puts "\n長さ:" + (hash.size + 1).to_s
# 先頭→末尾の流れ(メインルート)
puts 'メインルート:'
main_root = []
loop do
print word_list[y]
main_root.push(word_list[y])
break unless hash.has_key?(y)
print '->'
y = hash.delete(y)
end
puts ''
# 余ったループ群(サブルート)
puts 'サブルート:'
sub_root = []
while hash.size > 0
sub_root_ = []
y = hash.keys[0]
loop do
print word_list[y]
if hash.has_key?(y) then
sub_root_.push(word_list[y])
else
break
end
print '->'
y = hash.delete(y)
end
puts ''
sub_root.push(sub_root_)
end
# 見栄えのために、メインルートにサブルートを加える
puts '結合結果:'
sub_root.each{|sub_root_|
flg = false
sub_root_.size.times{|x|
main_root.each_with_index{|word, index|
next unless isMatch(normStr(word), normStr(sub_root_[0]))
main_root = main_root[0..index] + sub_root_ + main_root[index + 1..main_root.size - 1]
flg = true
break
}
break if flg
sub_root_.rotate!
}
}
main_root.each_with_index{|word, index|
print '->' if index != 0
print word
}
puts "\n長さ:" + main_root.size.to_s
# 余分なファイルを削除する
File.delete('query.txt')
File.delete('log.txt')
File.delete('query.lp')
File.delete('query.sol')
おまけ2
アイマス用IME辞書を元に、モバマス勢のしりとりを作成しました。ご確認ください。
○アイドル一覧(ファイル上では改行区切り)
しまむらうづき, なかのゆか, みずもとゆかり, ふくやままい, しいなのりこ, いまいかな, もちだありさ, みむらかなこ,
おくやまさおり, まなかみさと, こひなたみほ, おがたちえり, いがらしきょうこ, やなせみゆき, まえかわみく,
あかにしえりか, まつばらさや, あいはらゆきの, みやもとふれでりか, こばやかわさえ, さいおんじことか, ふたばあんず,
やおふぇいふぇい, ももいあずき, すずみやせいか, つきみやみやび, ひょうどうれな, どうみょうじかりん, やなぎきよら,
はらだみよ, しぶやりん, くろかわちあき, まつもとさりな, きりのあや, たかはしれいこ, あいかわちなつ, かわしまみずき,
かみやなお, かみじょうはるな, あらきひな, とうごうあい, ただりいな, みずきせいら, ささきちえ, へれん, まつながりょう,
こむろちなみ, たかみねのあ, たかがきかえで, かんざきらんこ, いじゅういんめぐみ, ひいらぎしの, ほうじょうかれん,
けいと, せなしおり, あやせほのか, さじょうゆきみ, しのはられい, ふるさわよりこ, ほんだみお, たかもりあいこ,
なみきめいこ, りゅうざきかおる, きむらなつき, まつやまくみこ, さいとうようこ, さわだまりな, やぐちみう, あかぎみりあ,
あいのなぎさ, まなべいつき, おおつきゆい, ひめかわゆき, あいばゆみ, ののむらそら, はまかわあゆな, わかばやしともか,
じょうがさきみか, じょうがさきりか, せんざきえま, ひのあかね, もろぼしきらり, とときあいり, なたーりあ, そうまなつみ,
まきはらしほ, むかいたくみ, なんじょうひかる, さくらいももか, みふねみゆ, きたみゆず, いむらせつな, もちづきひじり,
いぶさんたくろーす, えがみつばき, はっとりとうこ, うえだすずほ, いちはらにな, いけぶくろあきは, たかふじかこ,
くさかべわかば, さかきばらさとみ, わくいるみ, よしおかさき, すぎさかうみ, きたひなこ, ながとみはすみ, きばまなみ,
えびはらなほ, こしみずさちこ, うめきおとは, しらさかこうめ, あんざいみやこ, きしべあやか, きたがわまひろ,
あさのふうか, おおにしゆりこ, うじいえむつみ, にしかわほなみ, めありーこくらん, こまついぶき, あべなな, くどうしのぶ,
くりはらねね, なるみやゆめ, みよしさな, きゃしーぐらはむ, ふじいとも, よこやまちか, ふじわらはじめ, なんばえみ,
こがこはる, せきひろみ, おいかわしずく, しおみしゅうこ, はまぐちあやめ, わきやまたまみ, にったみなみ, こせきれいな,
くらりす, おかざきやすは, みずのみどり, えとうみさき, むらかみともえ, さくままゆ, はやみかなで, むらまつさくら,
おおいしいずみ, つちやあこ, おおたゆう, ほししょうこ, まつおちづる, しゅとうあおい, たちばなありす, かたぎりさなえ,
にわひとみ, もりくぼのの, ほりゆうこ, むなかたあつみ, あなすたしあ, しらぎくほたる, にしじまかい, ふじもとりな,
はやさかみれい, やまとあき, さぎさわふみか, おおはらみちる, ゆうきはる, ゆさこずえ, やがみまきの, さえじまきよみ,
らいら, まとばりさ, ありうらかんな, おおぬまくるみ, ざいぜんときこ, にのみやあすか, あさりななみ, いちのせしき,
さとうしん, おとくらゆうき, よりたよしの, きりゅうつかさ
○メインルート
せんざきえま->まつばらさや->やおふぇいふぇい->いけぶくろあきは->はやさかみれい->いぶさんたくろーす->すずみやせいか->
かわしまみずき->きりゅうつかさ->さぎさわふみか->かみじょうはるな->なんばえみ->みむらかなこ->こまついぶき->
きしべあやか->かんざきらんこ->こしみずさちこ->こむろちなみ->みよしさな->なかのゆか->かたぎりさなえ->えびはらなほ->
ほんだみお->おいかわしずく->くどうしのぶ->ふじいとも->もちだありさ->さわだまりな->なたーりあ->あかぎみりあ->
あなすたしあ->あいかわちなつ->つきみやみやび->ひめかわゆき->きりのあや->やぐちみう->うめきおとは->はらだみよ->
よしおかさき->きたみゆず->すぎさかうみ->みふねみゆ->ゆさこずえ->えとうみさき->きたひなこ->こひなたみほ->ほりゆうこ->
こせきれいな->ながとみはすみ->みやもとふれでりか->かみやなお->おおたゆう->うえだすずほ->ほししょうこ->
こばやかわさえ->えがみつばき->きむらなつき->きゃしーぐらはむ->むなかたあつみ->みずもとゆかり->りゅうざきかおる
○サブルート
らいら->らいら
○結合結果(61個)
せんざきえま->まつばらさや->やおふぇいふぇい->いけぶくろあきは->はやさかみれい->いぶさんたくろーす->すずみやせいか->
かわしまみずき->きりゅうつかさ->さぎさわふみか->かみじょうはるな->なんばえみ->みむらかなこ->こまついぶき->
きしべあやか->かんざきらんこ->こしみずさちこ->こむろちなみ->みよしさな->なかのゆか->かたぎりさなえ->えびはらなほ->
ほんだみお->おいかわしずく->くどうしのぶ->ふじいとも->もちだありさ->さわだまりな->なたーりあ->あかぎみりあ->
あなすたしあ->あいかわちなつ->つきみやみやび->ひめかわゆき->きりのあや->やぐちみう->うめきおとは->はらだみよ->
よしおかさき->きたみゆず->すぎさかうみ->みふねみゆ->ゆさこずえ->えとうみさき->きたひなこ->こひなたみほ->ほりゆうこ->
こせきれいな->ながとみはすみ->みやもとふれでりか->かみやなお->おおたゆう->うえだすずほ->ほししょうこ->
こばやかわさえ->えがみつばき->きむらなつき->きゃしーぐらはむ->むなかたあつみ->みずもとゆかり->りゅうざきかおる
○結合結果(漢字に戻した)
仙崎恵磨->松原早耶->楊菲菲->池袋晶葉->早坂美玲->イヴ・サンタクロース->涼宮星花->川島瑞樹->桐生つかさ->鷺沢文香->
上条春菜->難波笑美->三村かな子->小松伊吹->岸部彩華->神崎蘭子->輿水幸子->小室千奈美->三好紗南->中野有香->片桐早苗->
海老原菜帆->本田未央->及川雫->工藤忍->藤居朋->持田亜里沙->沢田麻理菜->ナターリア->赤城みりあ->アナスタシア->
相川千夏->月宮雅->姫川友紀->桐野アヤ->矢口美羽->梅木音葉->原田美世->吉岡沙紀->喜多見柚->杉坂海->三船美優->
遊佐こずえ->衛藤美紗希->喜多日菜子->小日向美穂->堀裕子->小関麗奈->長富蓮実->宮本フレデリカ->神谷奈緒->太田優->
上田鈴帆->星輝子->小早川紗枝->江上椿->木村夏樹->キャシー・グラハム->棟方愛海->水本ゆかり->龍崎薫