※ 一部修正したコードをコメント欄に記載しましたので、そちらもご参照ください。
はじめまして、XBRLJapanの開発委員会のメンバーKです。
XBRL便利ですよね。と言って、まだ強く同意いただける人はまだ少ないのでしょうか?「XBRLから企業の財務データを取得できる」ことは知っていても「どうすれば」できるのか、まだ知らない人も多いのではないでしょうか。Arelleという専用のソフトウェアも公開されていますが、Pythonの一般的なライブラリでXBRLを扱えるとすると、XBRLの敷居が少し下がるのではないでしょうか?
今回の記事では、XBRLがPythonのBeautifulSoupで扱え、そこからPandasのデータフレームを構築できることを示し、多くのユーザーにとってXBRLが親しみやすいものであることを理解していただくことを目標にしています。
0. 忙しい人のために
最低限XBRLからデータを取得するのに必要なコードは以下です。
from bs4 import BeautifulSoup
import pandas as pd
# XBRLのパスから、有価証券報告書内のテキスト情報をデータフレームで返す関数本体。
def get_nonnumeric(arg_path):
# fsファイルの読み込み。bs4でパース
with open(arg_path, encoding='utf-8') as f:
soup = BeautifulSoup(f.read(), 'lxml')
# nonNumericタグのみ抽出
tags_nonnumeric = soup.find_all('ix:nonnumeric')
# nonnumericの各要素を格納するカラのリストを作成
list_nonnumeric = []
# nonnumericの内容を辞書型に
for tag in tags_nonnumeric:
dict_tag = {}
dict_tag['nonnumeric_tag'] = tag.get('name')
dict_tag['nonnumeric_text'] = tag.text
list_nonnumeric.append(dict_tag)
# 辞書を格納したリストをDFに
df_nonnumeric = pd.DataFrame(list_nonnumeric)
return df_nonnumeric
# XBRLのパスから、有価証券報告書内の数値情報をデータフレームで返す関数本体。
def get_nonfraction(arg_path):
# fsファイルの読み込み。bs4でパース
with open(arg_path, encoding='utf-8') as f:
soup = BeautifulSoup(f.read(), 'lxml')
# nonFractionタグのみ抽出
tags_nonfraction = soup.find_all('ix:nonfraction')
# nonfractionの各要素を格納するカラの辞書を作成
list_nonfraction = []
# nonfractionの内容を辞書型に
for tag in tags_nonfraction:
dict_fs = {}
dict_fs['account_item'] = tag.get('name')
dict_fs['contextRef'] = tag.get('contextref')
dict_fs['format'] = tag.get('format')
dict_fs['decimals'] = tag.get('decimals')
dict_fs['scale'] = tag.get('scale')
dict_fs['unitRef'] = tag.get('unitRef')
# マイナス表記の場合の処理+円単位への変更
if tag.get('sign') == '-' and tag.get('xsi:nil') != 'true':
amount = int(tag.text.replace(',', '')) * -1 * 10 ** int(tag.get('scale'))
elif tag.get('xsi:nil') != 'true':
amount = int(tag.text.replace(',', '')) * 10 ** int(tag.get('scale'))
else:
amount = ''
dict_fs['amount'] = amount
# 辞書をリストへ格納
list_nonfraction.append(dict_fs)
# 辞書を格納したリストをDFに
df_nonfraction = pd.DataFrame(list_nonfraction)
return df_nonfraction
1. はじめに
XBRLについて知りたい人は、以下のLinkを参考にしてください。
XBRLを知ろう(1/10)
EDINET APIを利用して、企業情報(XBRLデータ)を自動で集めてみよう(4/10)
XBRLの構成要素の解説
2. この記事の対象
以下を対象にこの記事を記載します。
- XBRLの1種類であるインラインXBRLを対象に
- PythonのBeautiful Soupで
- 財務諸表の
経理の状況に含まれる各科目数値を - Pandasのデータフレームにする。
さらに、
- 日本語の標準科目ラベル
- 独自科目ラベル
を、取得しに行きます。
なお財務諸表は、会計基準に日本基準を採用した有価証券届出書・有価証券報告書・半期報告書・四半期報告書を対象にします。
3. 前提
- 有価証券報告書のXBRLが入手できるEDINETでは、
docID単位で有価証券報告書が管理されています。 - 今回の記事ではEDINET APIの解説は省略し、
docID単位の有価証券報告書がすでに手元にある前提で解説します。 - XBRLの入手先にはTDNetもありますが、今回はEDINETを対象に説明します。
4. EDINETにおける本文ファイルの命名規則
EDINETで提供されるXBRLの各ファイルには命名規則が存在します。
報告書インスタンス作成ガイドライン
https://www.fsa.go.jp/search/20191101/2b-1_InstanceGuide.pdf


上記命名規則から、有価証券報告書の第一部 【企業情報】、第5 【経理の状況】は0105からはじまるhtmファイルであることが分かります。
※ 財務諸表の種類によって経理の状況の場所は異なります。(例えば、四半期報告書の場合は0104です。)
5. BeautifulSoupによるパース結果
5.1 経理の状況に含まれる財務数値を取得するサンプルコード
def get_nonfraction(arg_path):
# fsファイルの読み込み。bs4でパース
with open(arg_path, encoding='utf-8') as f:
soup = BeautifulSoup(f.read(), 'lxml')
# nonFractionタグのみ抽出
tags_nonfraction = soup.find_all('ix:nonfraction')
# nonfractionの各要素を格納するカラの辞書を作成
list_nonfraction = []
# nonfractionの内容を辞書型に
for tag in tags_nonfraction:
dict_fs = {}
dict_fs['account_item'] = tag.get('name')
dict_fs['contextRef'] = tag.get('contextref')
dict_fs['format'] = tag.get('format')
dict_fs['decimals'] = tag.get('decimals')
dict_fs['scale'] = tag.get('scale')
dict_fs['unitRef'] = tag.get('unitRef')
# マイナス表記の場合の処理+円単位への変更
if tag.get('sign') == '-' and tag.get('xsi:nil') != 'true':
amount = int(tag.text.replace(',', '')) * -1 * 10 ** int(tag.get('scale'))
elif tag.get('xsi:nil') != 'true':
amount = int(tag.text.replace(',', '')) * 10 ** int(tag.get('scale'))
else:
amount = ''
dict_fs['amount'] = amount
# 辞書をリストへ格納
list_nonfraction.append(dict_fs)
# 辞書を格納したリストをDFに
df_nonfraction = pd.DataFrame(list_nonfraction)
return df_nonfraction
以下のように、勘定科目名account_itemと前期/当期の別contextRefや金額amountなどが取得できます。
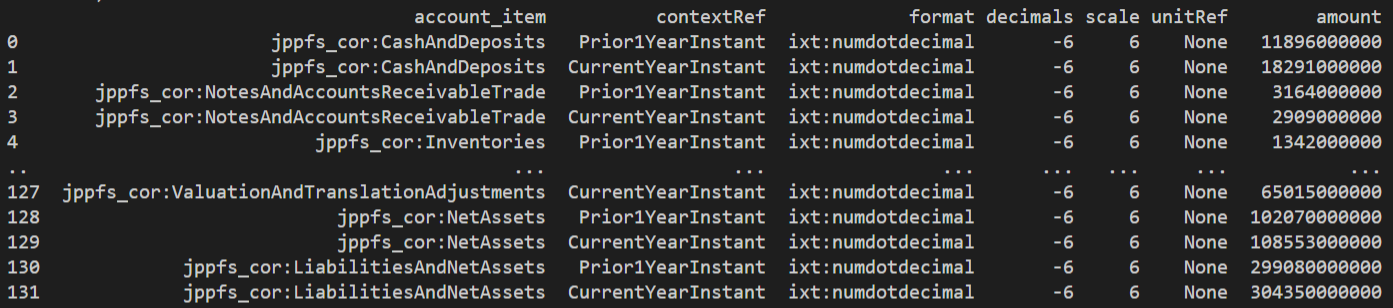
6. キー情報の取得
上記のままでは、財務諸表に対するキー情報(docID, EDINETコード, 決算期等)が含まれていないため、これを取得します。
キー情報の取得方法には、以下の2つ考えられます。
- ファイル名からキー情報を取得する方法
-
DEIからキー情報を取得する方法
DEIとは、Document Entity Informationの略で、提出書類の基本情報(Document Information)及び開示書類等提出者の基本情報(Entity Information)が含まれています。
6.1 ファイル名からキー情報を取得するコード
import re
import pandas as pd
import os
def get_keys(arg_filename):
# カラの辞書を作成
dict_key = {}
# docIDを取得
dict_key['docID'] = re.findall('S\w{7}', arg_filename)[0]
# エラーを回避するために、ファイル名部分だけ抽出
filename = os.path.basename(arg_filename)
# 府令コードは`jp`以降の3文字
dict_key['ordinance'] = filename[filename.find('jp') + 2 : filename.find('jp') + 5]
# 判定基準:数字6桁 & 直後が`-`
dict_key['formCode'] = re.findall('\d{6}-', filename)[0][0:6]
# 判定基準:英数字3桁 & 直前が`-` & 直後が`-`
dict_key['reporting_id'] = re.findall('-\w{3}-', filename)[0][1:4]
# 判定基準:数字3桁 & 直前が`-` & 直後が`_` の1個目
dict_key['sequence_n1'] = re.findall('-\d{3}_', filename)[0][1:4]
# 判定基準:英数字1桁 & 数字5桁 & 直前が`_` & 直後が`-`
dict_key['edinetCode'] = re.findall('_\w{1}\d{5}-', filename)[0][1:7]
# 判定基準:数字3桁 & 直前が`-` & 直後が`_` の2個目
dict_key['sequence_n2'] = re.findall('-\d{3}_', filename)[1][1:4]
# 判定基準:YYYY-MM-DD の1個目
dict_key['periodend'] = re.findall('\d{4}-\d{2}-\d{2}', filename)[0]
# 判定基準:数字2桁 & 直前が`_` & 直後が`_`
dict_key['report_his'] = re.findall('_\d{2}_', filename)[0][1:3]
# 判定基準:YYYY-MM-DD の2個目
dict_key['submitdate'] = re.findall('\d{4}-\d{2}-\d{2}', filename)[1]
# 横持のDFに変換
df_key = pd.DataFrame(pd.Series(dict_key)).T
return df_key
6.2 DEIからキー情報を取得するコード
from bs4 import BeautifulSoup
import pandas as pd
import os
from mylib import get_filename_keys
def get_dei(arg_path):
# headerファイルの読み込み
with open(arg_path, encoding='utf-8') as f:
header_xbrl = f.read()
# bs4でパース
soup = BeautifulSoup(header_xbrl, 'lxml')
# header内の情報を取得
ix_header = soup.find_all('ix:header')
# header内のhidden内の情報取得
ix_hidden = ix_header[0].find_all('ix:hidden')
# hidden内のnonnumeric, nonfractionタグを取得
ix_hidden_nonnumeric = ix_hidden[0].find_all('ix:nonnumeric')
ix_hidden_nonfraction = ix_hidden[0].find_all('ix:nonfraction')
# DEI情報を格納するカラの辞書オブジェクト作成
dict_dei = {}
# nonnumericタグの情報(定性情報)を辞書に格納
# タグ内のnameを辞書のキーに、表示されるテキストを値に格納
for dei in ix_hidden_nonnumeric:
dict_dei[dei.get('name')] = dei.text
# nonfractionタグの情報(定量情報)を辞書に格納
# タグ内のnameを辞書のキーに、表示されるテキストを値に格納
for dei in ix_hidden_nonfraction:
dict_dei[dei.get('name')] = dei.text
# 横持ちのデータフレームに変換
df_dei = pd.DataFrame(pd.Series(dict_dei)).T
return df_dei
7. 財務諸表区分の取得
上記のコードのままでは、連結貸借対照表や連結損益計算書の区別がなく使い勝手がよくありません。
インラインXBRLを見ると、連結貸借対照表はjpcrp_cor:ConsolidatedBalanceSheetTextBlockという要素名でnonNumericによって囲われていることがわかります。

要素名と財務諸表区分の対応関係は、以下です。
| 要素名 | 財務諸表区分 |
|---|---|
| jpcrp_cor:ConsolidatedBalanceSheetTextBlock | 連結貸借対照表 |
| jpcrp_cor:ConsolidatedStatementOfIncomeTextBlock | 連結貸借対照表 |
| jpcrp_cor:ConsolidatedStatementOfComprehensiveIncomeTextBlock | 連結包括利益計算書 |
| jpcrp_cor:ConsolidatedStatementOfChangesInEquityTextBlock | 連結株主資本等変動計算書 |
| jpcrp_cor:ConsolidatedStatementOfCashFlowsTextBlock | 連結キャッシュ・フロー計算書 |
| jpcrp_cor:BalanceSheetTextBlock | 貸借対照表 |
| jpcrp_cor:StatementOfIncomeTextBlock | 損益計算書 |
| jpcrp_cor:StatementOfChangesInEquityTextBlock | 株主資本等変動計算書 |
| jpcrp_cor:StatementOfCashFlowsTextBlock | キャッシュ・フロー計算書 |
これらのことから、上記要素名ごとにnonNumericタグを取得すれば財務諸表区分ごとにデータを取得することができます。
そこで、1つのXBRLファイルに対して上記要素名をfor文で検索し、ヒットした場合にデータフレームを返す処理に変更します。
処理の流れとしては以下のようになります。
- XBRLファイルをBeautiful Soupで読み込む
- 財務諸表区分ごとの
nonNumericタグを検索・抽出 - 抽出されたタグの要素ごとにデータフレームにする
7.1 財務諸表区分ごとに財務数値を取得するサンプルコード
# 財務諸表の要素タグからDFを返す関数。
# 5.のサンプルコードからXBRLファイルの読み込みを省略し、引数をタグに変更。
def get_df(arg_tags):
# 各fsの各要素を格納した辞書を入れるカラのリスト作成
list_fs = []
# 各fsの各要素を辞書に格納
for each_item in arg_tags:
dict_fs = {}
dict_fs['account_item'] = each_item.get('name')
dict_fs['contextRef'] = each_item.get('contextref')
dict_fs['format'] = each_item.get('format')
dict_fs['decimals'] = each_item.get('decimals')
dict_fs['scale'] = each_item.get('scale')
dict_fs['unitRef'] = each_item.get('unitRef')
# マイナス表記の場合の処理+円単位への変更
if each_item.get('sign') == '-' and each_item.get('xsi:nil') != 'true':
amount = int(each_item.text.replace(',', '')) * -1 * 10 ** int(each_item.get('scale'))
elif each_item.get('xsi:nil') != 'true':
amount = int(each_item.text.replace(',', '')) * 10 ** int(each_item.get('scale'))
else:
amount = ''
dict_fs['amount'] = amount
# 辞書をリストへ格納
list_fs.append(dict_fs)
# 辞書を格納したリストをDFに
df_eachfs = pd.DataFrame(list_fs)
return df_eachfs
# XBRLのパスから、DFを返す関数本体。
def get_fs(arg_path):
# fsファイルの読み込み。bs4でパース
with open(arg_path, encoding='utf-8') as f:
soup = BeautifulSoup(f.read(), 'lxml')
# nonNumericタグのみ抽出
tags_nonnumeric = soup.find_all('ix:nonnumeric')
# nonnumericの各要素を格納するカラの辞書を作成
dict_tag = {}
# nonnumericの内容を辞書型に
for tag in tags_nonnumeric:
dict_tag[tag.get('name')] = tag
# 取得対象となりうる財務諸表の`name`一覧定義
list_target_fs = [
# 有価証券報告書
'jpcrp_cor:ConsolidatedBalanceSheetTextBlock',
'jpcrp_cor:ConsolidatedStatementOfIncomeTextBlock',
'jpcrp_cor:ConsolidatedStatementOfComprehensiveIncomeTextBlock',
'jpcrp_cor:ConsolidatedStatementOfChangesInEquityTextBlock',
'jpcrp_cor:ConsolidatedStatementOfCashFlowsTextBlock',
'jpcrp_cor:BalanceSheetTextBlock',
'jpcrp_cor:StatementOfIncomeTextBlock',
#'jpcrp_cor:DetailedScheduleOfManufacturingCostTextBlock',#製造原価報告書を取得する場合はコメントアウトを外してください。
'jpcrp_cor:StatementOfChangesInEquityTextBlock',
'jpcrp_cor:StatementOfCashFlowsTextBlock',
# 半期報告書
'jpcrp_cor:SemiAnnualConsolidatedBalanceSheetTextBlock',
'jpcrp_cor:SemiAnnualConsolidatedStatementOfIncomeTextBlock',
'jpcrp_cor:SemiAnnualConsolidatedStatementOfComprehensiveIncomeTextBlock',
'jpcrp_cor:SemiAnnualConsolidatedStatementOfChangesInEquityTextBlock',
'jpcrp_cor:SemiAnnualConsolidatedStatementOfCashFlowsTextBlock',
'jpcrp_cor:SemiAnnualBalanceSheetTextBlock',
'jpcrp_cor:SemiAnnualStatementOfIncomeTextBlock',
#'jpcrp_cor:SemiAnnualDetailedScheduleOfManufacturingCostTextBlock',#製造原価報告書を取得する場合はコメントアウトを外してください。
'jpcrp_cor:SemiAnnualStatementOfChangesInEquityTextBlock',
'jpcrp_cor:SemiAnnualStatementOfCashFlowsTextBlock',
# 四半期報告書
'jpcrp_cor:QuarterlyConsolidatedBalanceSheetTextBlock',
'jpcrp_cor:QuarterlyConsolidatedStatementOfIncomeTextBlock',
'jpcrp_cor:QuarterlyConsolidatedStatementOfComprehensiveIncomeTextBlock',
'jpcrp_cor:QuarterlyConsolidatedStatementOfChangesInEquityTextBlock',
'jpcrp_cor:QuarterlyConsolidatedStatementOfCashFlowsTextBlock',
'jpcrp_cor:QuarterlyBalanceSheetTextBlock',
'jpcrp_cor:QuarterlyStatementOfIncomeTextBlock',
'jpcrp_cor:QuarterlyStatementOfChangesInEquityTextBlock',
'jpcrp_cor:QuarterlyStatementOfCashFlowsTextBlock',
'jpcrp_cor:YearToQuarterEndConsolidatedStatementOfIncomeTextBlock',
'jpcrp_cor:YearToQuarterEndConsolidatedStatementOfComprehensiveIncomeTextBlock',
'jpcrp_cor:YearToQuarterEndConsolidatedStatementOfCashFlowsTextBlock',
'jpcrp_cor:YearToQuarterEndStatementOfIncomeTextBlock',
'jpcrp_cor:YearToQuarterEndStatementOfComprehensiveIncomeTextBlock',
'jpcrp_cor:YearToQuarterEndStatementOfCashFlowsTextBlock'
]
# 各財務諸表を入れるカラのDFを作成
list_fs = []
# 可能性のある財務諸表区分ごとにループ処理でDF作成
# dict_tagのキーの中には、財務諸表本表に関係のない注記情報に関するキーもあるため、必要な本表に絞ってループ処理
for each_target_fs in list_target_fs:
# ターゲットとなるFS区分のタグを取得
tag_each_fs = dict_tag.get(each_target_fs)
# 辞書型の値をgetして、値がなければnoneが返る。noneはfalse扱いのため、これを条件に分岐。
if tag_each_fs:
# 財務諸表要素は'ix:nonFraction'に入っているため、このタグを取得
tag_nonfraction = tag_each_fs.find_all('ix:nonfraction')
# 財務諸表の各要素をDFに。財務諸表区分とタグを引数にして関数に渡す。
df_each_fs = get_df(tag_nonfraction)
df_each_fs['fs_class'] = each_target_fs
list_fs.append(df_each_fs)
# タグの中にtarget_FSが含まれない場合(例えば注記だけのixbrlを読み込んだ場合)の分岐
if list_fs:
# 各財務諸表の結合
df_fs = pd.concat(list_fs)
# 並べ替え
df_fs = df_fs[['fs_class', 'account_item', 'contextRef', 'format', 'decimals', 'scale', 'unitRef', 'amount']]
else:
df_fs = pd.DataFrame(index=[])
return df_fs
結果

8. 日本語科目ラベルの取得
上記のコードのままでは、各勘定科目名が英語表記で可読性が低いため、日本語のラベルを付します。
有価証券報告書では、各企業で統一して使用される標準的な科目ラベル(標準ラベル)と企業が独自に設定する科目ラベル(独自ラベル)があります。
標準ラベルは金融庁が公開し、独自ラベルは各企業が提出した有価証券報告書データのdocID内に**_lab.xmlとして保存されています。
8.1 独自ラベルを取得するサンプルコード
def get_label_local(arg_docid):
# 引数のdocidからパスを生成
path_local_label = glob.glob(path_base + arg_docid + '/XBRL/PublicDoc/*_lab.xml')
# 標準ラベルのみ使用し、独自ラベルを持たない場合があるため、if分岐
if path_local_label:
# labファイルの読み込み
with open(path_local_label[0], encoding='utf-8') as f:
soup = BeautifulSoup(f.read(), 'lxml')
# link:labelタグのみ抽出
link_label = soup.find_all('link:label')
# ラベル情報用dictを格納するカラのリストを作成
list_label = []
# ラベル情報をループ処理で取得
for each_label in link_label:
dict_label = {}
dict_label['id'] = each_label.get('id')
dict_label['xlink_label'] = each_label.get('xlink:label')
dict_label['xlink_role'] = each_label.get('xlink:role')
dict_label['xlink_type'] = each_label.get('xlink:type')
dict_label['xml_lang'] = each_label.get('xml:lang')
dict_label['label'] = each_label.text
list_label.append(dict_label)
# ラベル情報取得結果をDFに
df_label_local = pd.DataFrame(list_label)
else:
df_label_local = pd.DataFrame(index=[])
return df_label_local
8.2 財務諸表と独自ラベルを引数に日本語ラベルを付して返すサンプルコード
以下のサンプルコードでは、金融庁が公表している勘定科目リストをtsv形式にしたファイルを読み込むことを想定しています。
tsvファイルは以下にあります(taxonomy_label.tsv)が、使用は自己責任でお願いします。使用する場合は、保存先をpath_taxonomy_labelsとして定義してください。
https://github.com/sat128/xbrl_bs4
実際の勘定科目リストについては、金融庁のサイトを参照してください。
金融庁 勘定科目リスト
https://www.fsa.go.jp/search/20201110.html
def get_labeled_df(arg_fs, arg_label_local):
# 標準ラベルの読み込み
df_label_global = pd.read_table(path_taxonomy_labels, sep='\t', encoding='utf-8')
# 標準ラベルの処理
# 標準ラベルデータのうち、必要行に絞る
df_label_global = df_label_global[df_label_global['xlink_role'] == 'http://www.xbrl.org/2003/role/label']
# 必要列のみに絞る
df_label_global = df_label_global[['xlink_label', 'label']]
# 'label_'はじまりを削除で統一
df_label_global['xlink_label'] = df_label_global['xlink_label'].str.replace('label_', '')
# 同一ラベルで異なる表示名が存在する場合、独自の表示名を優先
df_label_global['temp'] = 0
# 標準ラベルのみ使用し、独自ラベルを持たない場合があるため、if分岐
if len(arg_label_local) > 0:
# 独自ラベルの処理
# 独自ラベルデータのうち、必要列に絞る
df_label_local = arg_label_local[['xlink_label', 'label']].copy()
# ラベルの末尾に'_label.*'があり、FSと結合できないため、これを削除
df_label_local['xlink_label'] = df_label_local['xlink_label'].str.replace('_label.*$', '').copy()
# ラベルの最初に'jpcrp'で始まるラベルがあり、削除で統一。
# 削除で統一した結果、各社で定義していた汎用的な科目名(「貸借対照表計上額」など)が重複するようになる。後続処理で重複削除。
df_label_local['xlink_label'] = df_label_local['xlink_label'].str.replace('jpcrp\d{6}-..._E\d{5}-\d{3}_', '')
# ラベルの最初に'label_'で始まるラベルがあり、削除で統一
# 削除で統一した結果、各社で定義していた汎用的な科目名(「貸借対照表計上額」など)が重複するようになる。後続処理で重複削除。
df_label_local['xlink_label'] = df_label_local['xlink_label'].str.replace('label_', '')
# 同一要素名で異なる表示名が存在する場合、独ラベルを優先
df_label_local['temp'] = 1
# label_globalとlabel_localを縦結合
df_label_merged = pd.concat([df_label_global, df_label_local])
else:
df_label_merged = df_label_global
# 同一要素名で異なる表示名が存在する場合、独自ラベルを優先
grp_df_label_merged = df_label_merged.groupby('xlink_label')
df_label_merged = df_label_merged.loc[grp_df_label_merged['temp'].idxmax(),:]
df_label_merged = df_label_merged.drop('temp', axis=1)
# localラベルで重複してしまう行があるため、ここで重複行を削除
df_label_merged = df_label_merged.drop_duplicates()
# 結合用ラベル列作成
arg_fs['temp_label'] = arg_fs['account_item'].str.replace('jpcrp\d{6}-..._E\d{5}-\d{3}:', '')
arg_fs['temp_label'] = arg_fs['temp_label'].str.replace('jppfs_cor:', '')
# ラベルの結合
df_labeled_fs = pd.merge(arg_fs, df_label_merged, left_on='temp_label', right_on='xlink_label', how='left').drop_duplicates()
return df_labeled_fs
9. まとめ
上記までのコードをまとめると以下になります。
import os
import re
import glob
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
# パスの指定
path_base = '****' # baseとなるディレクトリの指定。個々のdocidが付されたフォルダが格納された階層を指定することを想定しています。
if path_base[-1] != '/':
path_base = path_base + '/'
path_taxonomy_labels = '****/taxonomy_label.tsv' # Gitに乗せたtsvファイルをローカルに保存して当該パスを指定してください。
def get_keys(arg_filename):
# カラの辞書を作成
dict_key = {}
# docIDを取得
dict_key['docID'] = re.findall('S\w{7}', arg_filename)[0]
# 必要なファイル名部分だけに絞る
filename = os.path.basename(arg_filename)
# 府令コードは`jp`以降の3文字
dict_key['ordinance'] = filename[filename.find('jp') + 2 : filename.find('jp') + 5]
# 判定基準:数字6桁 & 直後が`-`
dict_key['formCode'] = re.findall('\d{6}-', filename)[0][0:6]
# 判定基準:英数字3桁 & 直前が`-` & 直後が`-`
dict_key['reporting_id'] = re.findall('-\w{3}-', filename)[0][1:4]
# 判定基準:数字3桁 & 直前が`-` & 直後が`_` の1個目
dict_key['sequence_n1'] = re.findall('-\d{3}_', filename)[0][1:4]
# 判定基準:英数字1桁 & 数字5桁 & 直前が`_` & 直後が`-`
dict_key['edinetCode'] = re.findall('_\w{1}\d{5}-', filename)[0][1:7]
# 判定基準:数字3桁 & 直前が`-` & 直後が`_` の2個目
dict_key['sequence_n2'] = re.findall('-\d{3}_', filename)[1][1:4]
# 判定基準:YYYY-MM-DD の1個目
dict_key['periodend'] = re.findall('\d{4}-\d{2}-\d{2}', filename)[0]
# 判定基準:数字2桁 & 直前が`_` & 直後が`_`
dict_key['report_his'] = re.findall('_\d{2}_', filename)[0][1:3]
# 判定基準:YYYY-MM-DD の2個目
dict_key['submitdate'] = re.findall('\d{4}-\d{2}-\d{2}', filename)[1]
# 横持のDFに変換
df_key = pd.DataFrame(pd.Series(dict_key)).T
return df_key
def get_dei(arg_docid):
path_header = glob.glob(path_base + arg_docid + '/XBRL/PublicDoc/0000000_**.htm')
# headerファイルの読み込み
with open(path_header[0], encoding='utf-8') as f:
soup = BeautifulSoup(f.read(), 'lxml')
# header内の情報を取得
ix_header = soup.find_all('ix:header')
# header内のhidden内の情報取得
ix_hidden = ix_header[0].find_all('ix:hidden')
# hidden内のnonnumeric, nonfractionタグを取得
ix_hidden_nonnumeric = ix_hidden[0].find_all('ix:nonnumeric')
ix_hidden_nonfraction = ix_hidden[0].find_all('ix:nonfraction')
# DEI情報を格納するカラの辞書オブジェクト作成
dict_dei = {}
# nonnumericタグの情報(定性情報)を辞書に格納
# タグ内のnameを辞書のキーに、表示されるテキストを値に格納
for dei in ix_hidden_nonnumeric:
dict_dei[dei.get('name')] = dei.text
# nonfractionタグの情報(定量情報)を辞書に格納
# タグ内のnameを辞書のキーに、表示されるテキストを値に格納
for dei in ix_hidden_nonfraction:
dict_dei[dei.get('name')] = dei.text
# 横持ちのデータフレームに変換
df_dei = pd.DataFrame(pd.Series(dict_dei)).T
# DEIに含まれる情報のうち、EDINETコードと会社名に絞る
df_dei = df_dei[['jpdei_cor:EDINETCodeDEI', 'jpdei_cor:FilerNameInJapaneseDEI', 'jpdei_cor:AccountingStandardsDEI', 'jpdei_cor:DocumentTypeDEI']]
df_dei = df_dei.rename(columns={'jpdei_cor:EDINETCodeDEI': 'edinetCode', 'jpdei_cor:FilerNameInJapaneseDEI': 'companyName', 'jpdei_cor:AccountingStandardsDEI': 'GAAP', 'jpdei_cor:DocumentTypeDEI': 'DocType'})
return df_dei
# 財務諸表の要素タグからDFを返す関数。
# 5.のサンプルコードからXBRLファイルの読み込みを省略し、引数をタグに変更。
def get_df(arg_tags):
# 各fsの各要素を格納した辞書を入れるカラのリスト作成
list_fs = []
# 各fsの各要素を辞書に格納
for each_item in arg_tags:
dict_fs = {}
dict_fs['account_item'] = each_item.get('name')
dict_fs['contextRef'] = each_item.get('contextref')
dict_fs['format'] = each_item.get('format')
dict_fs['decimals'] = each_item.get('decimals')
dict_fs['scale'] = each_item.get('scale')
dict_fs['unitRef'] = each_item.get('unitRef')
# マイナス表記の場合の処理+円単位への変更
if each_item.get('sign') == '-' and each_item.get('xsi:nil') != 'true':
amount = int(each_item.text.replace(',', '')) * -1 * 10 ** int(each_item.get('scale'))
elif each_item.get('xsi:nil') != 'true':
amount = int(each_item.text.replace(',', '')) * 10 ** int(each_item.get('scale'))
else:
amount = ''
dict_fs['amount'] = amount
# 辞書をリストへ格納
list_fs.append(dict_fs)
# 辞書を格納したリストをDFに
df_eachfs = pd.DataFrame(list_fs)
return df_eachfs
# XBRLのパスから、DFを返す関数本体。
def get_fs(arg_path):
# fsファイルの読み込み。bs4でパース
with open(arg_path, encoding='utf-8') as f:
soup = BeautifulSoup(f.read(), 'lxml')
# nonNumericタグのみ抽出
tags_nonnumeric = soup.find_all('ix:nonnumeric')
# nonnumericの各要素を格納するカラの辞書を作成
dict_tag = {}
# nonnumericの内容を辞書型に
for tag in tags_nonnumeric:
dict_tag[tag.get('name')] = tag
# 取得対象となりうる財務諸表の`name`一覧定義
list_target_fs = [
# 有価証券報告書
'jpcrp_cor:ConsolidatedBalanceSheetTextBlock',
'jpcrp_cor:ConsolidatedStatementOfIncomeTextBlock',
'jpcrp_cor:ConsolidatedStatementOfComprehensiveIncomeTextBlock',
'jpcrp_cor:ConsolidatedStatementOfChangesInEquityTextBlock',
'jpcrp_cor:ConsolidatedStatementOfCashFlowsTextBlock',
'jpcrp_cor:BalanceSheetTextBlock',
'jpcrp_cor:StatementOfIncomeTextBlock',
#'jpcrp_cor:DetailedScheduleOfManufacturingCostTextBlock',#製造原価報告書を取得する場合はコメントアウトを外してください。
'jpcrp_cor:StatementOfChangesInEquityTextBlock',
'jpcrp_cor:StatementOfCashFlowsTextBlock',
# 半期報告書
'jpcrp_cor:SemiAnnualConsolidatedBalanceSheetTextBlock',
'jpcrp_cor:SemiAnnualConsolidatedStatementOfIncomeTextBlock',
'jpcrp_cor:SemiAnnualConsolidatedStatementOfComprehensiveIncomeTextBlock',
'jpcrp_cor:SemiAnnualConsolidatedStatementOfChangesInEquityTextBlock',
'jpcrp_cor:SemiAnnualConsolidatedStatementOfCashFlowsTextBlock',
'jpcrp_cor:SemiAnnualBalanceSheetTextBlock',
'jpcrp_cor:SemiAnnualStatementOfIncomeTextBlock',
'jpcrp_cor:SemiAnnualStatementOfChangesInEquityTextBlock',
'jpcrp_cor:SemiAnnualStatementOfCashFlowsTextBlock',
# 四半期報告書
'jpcrp_cor:QuarterlyConsolidatedBalanceSheetTextBlock',
'jpcrp_cor:QuarterlyConsolidatedStatementOfIncomeTextBlock',
'jpcrp_cor:QuarterlyConsolidatedStatementOfComprehensiveIncomeTextBlock',
'jpcrp_cor:QuarterlyConsolidatedStatementOfChangesInEquityTextBlock',
'jpcrp_cor:QuarterlyConsolidatedStatementOfCashFlowsTextBlock',
'jpcrp_cor:QuarterlyBalanceSheetTextBlock',
'jpcrp_cor:QuarterlyStatementOfIncomeTextBlock',
'jpcrp_cor:QuarterlyStatementOfChangesInEquityTextBlock',
'jpcrp_cor:QuarterlyStatementOfCashFlowsTextBlock',
'jpcrp_cor:YearToQuarterEndConsolidatedStatementOfIncomeTextBlock',
'jpcrp_cor:YearToQuarterEndConsolidatedStatementOfComprehensiveIncomeTextBlock',
'jpcrp_cor:YearToQuarterEndConsolidatedStatementOfCashFlowsTextBlock',
'jpcrp_cor:YearToQuarterEndStatementOfIncomeTextBlock',
'jpcrp_cor:YearToQuarterEndStatementOfComprehensiveIncomeTextBlock',
'jpcrp_cor:YearToQuarterEndStatementOfCashFlowsTextBlock'
]
# 各財務諸表を入れるカラのDFを作成
list_fs = []
# 可能性のある財務諸表区分ごとにループ処理でDF作成
# dict_tagのキーの中には、財務諸表本表に関係のない注記情報に関するキーもあるため、必要な本表に絞ってループ処理
for each_target_fs in list_target_fs:
# ターゲットとなるFS区分のタグを取得
tag_each_fs = dict_tag.get(each_target_fs)
# 辞書型の値をgetして、値がなければnoneが返る。noneはfalse扱いのため、これを条件に分岐。
if tag_each_fs:
# 財務諸表要素は'ix:nonFraction'に入っているため、このタグを取得
tag_nonfraction = tag_each_fs.find_all('ix:nonfraction')
# 財務諸表の各要素をDFに。財務諸表区分とタグを引数にして関数に渡す。
df_each_fs = get_df(tag_nonfraction)
df_each_fs['fs_class'] = each_target_fs
list_fs.append(df_each_fs)
# タグの中にtarget_FSが含まれない場合(例えば注記だけのixbrlを読み込んだ場合)の分岐
if list_fs:
# 各財務諸表の結合
df_fs = pd.concat(list_fs)
# 並べ替え
df_fs = df_fs[['fs_class', 'account_item', 'contextRef', 'format', 'decimals', 'scale', 'unitRef', 'amount']]
else:
df_fs = pd.DataFrame(index=[])
return df_fs
def get_label_local(arg_docid):
# 引数のdocidからパスを生成
path_local_label = glob.glob(path_base + arg_docid + '/XBRL/PublicDoc/*_lab.xml')
# 標準ラベルのみ使用し、独自ラベルを持たない場合があるため、if分岐
if path_local_label:
# labファイルの読み込み
with open(path_local_label[0], encoding='utf-8') as f:
soup = BeautifulSoup(f.read(), 'lxml')
# link:labelタグのみ抽出
link_label = soup.find_all('link:label')
# ラベル情報用dictを格納するカラのリストを作成
list_label = []
# ラベル情報をループ処理で取得
for each_label in link_label:
dict_label = {}
dict_label['id'] = each_label.get('id')
dict_label['xlink_label'] = each_label.get('xlink:label')
dict_label['xlink_role'] = each_label.get('xlink:role')
dict_label['xlink_type'] = each_label.get('xlink:type')
dict_label['xml_lang'] = each_label.get('xml:lang')
dict_label['label'] = each_label.text
list_label.append(dict_label)
# ラベル情報取得結果をDFに
df_label_local = pd.DataFrame(list_label)
else:
df_label_local = pd.DataFrame(index=[])
return df_label_local
def get_labeled_df(arg_fs, arg_label_local):
# 標準ラベルの読み込み
df_label_global = pd.read_table(path_taxonomy_labels, sep='\t', encoding='utf-8')
# 標準ラベルの処理
# 標準ラベルデータのうち、必要行に絞る
df_label_global = df_label_global[df_label_global['xlink_role'] == 'http://www.xbrl.org/2003/role/label']
# 必要列のみに絞る
df_label_global = df_label_global[['xlink_label', 'label']]
# 'label_'はじまりを削除で統一
df_label_global['xlink_label'] = df_label_global['xlink_label'].str.replace('label_', '')
# 同一ラベルで異なる表示名が存在する場合、独自の表示名を優先
df_label_global['temp'] = 0
# 標準ラベルのみ使用し、独自ラベルを持たない場合があるため、if分岐
if len(arg_label_local) > 0:
# 独自ラベルの処理
# 独自ラベルデータのうち、必要列に絞る
df_label_local = arg_label_local[['xlink_label', 'label']].copy()
# ラベルの末尾に'_label.*'があり、FSと結合できないため、これを削除
df_label_local['xlink_label'] = df_label_local['xlink_label'].str.replace('_label.*$', '').copy()
# ラベルの最初に'jpcrp'で始まるラベルがあり、削除で統一。
# 削除で統一した結果、各社で定義していた汎用的な科目名(「貸借対照表計上額」など)が重複するようになる。後続処理で重複削除。
df_label_local['xlink_label'] = df_label_local['xlink_label'].str.replace('jpcrp\d{6}-..._E\d{5}-\d{3}_', '')
# ラベルの最初に'label_'で始まるラベルがあり、削除で統一
# 削除で統一した結果、各社で定義していた汎用的な科目名(「貸借対照表計上額」など)が重複するようになる。後続処理で重複削除。
df_label_local['xlink_label'] = df_label_local['xlink_label'].str.replace('label_', '')
# 同一要素名で異なる表示名が存在する場合、独ラベルを優先
df_label_local['temp'] = 1
# label_globalとlabel_localを縦結合
df_label_merged = pd.concat([df_label_global, df_label_local])
else:
df_label_merged = df_label_global
# 同一要素名で異なる表示名が存在する場合、独自ラベルを優先
grp_df_label_merged = df_label_merged.groupby('xlink_label')
df_label_merged = df_label_merged.loc[grp_df_label_merged['temp'].idxmax(),:]
df_label_merged = df_label_merged.drop('temp', axis=1)
# localラベルで重複してしまう行があるため、ここで重複行を削除
df_label_merged = df_label_merged.drop_duplicates()
# 結合用ラベル列作成
arg_fs['temp_label'] = arg_fs['account_item'].str.replace('jpcrp\d{6}-..._E\d{5}-\d{3}:', '')
arg_fs['temp_label'] = arg_fs['temp_label'].str.replace('jppfs_cor:', '')
# ラベルの結合
df_labeled_fs = pd.merge(arg_fs, df_label_merged, left_on='temp_label', right_on='xlink_label', how='left').drop_duplicates()
return df_labeled_fs
def make_tidy(arg_df):
# 連結財務諸表フラグの作成
arg_df['consoli_flg'] = np.where(arg_df['contextRef'].str.contains('NonConsolidated'), 0, 1)
# 財務諸表区分コードの作成
arg_df['fs'] = np.where(arg_df['fs_class'].str.contains('BalanceSheet'), 'bs', \
np.where(arg_df['fs_class'].str.contains('StatementOfIncome'), 'pl', \
np.where(arg_df['fs_class'].str.contains('StatementOfCashFlows'), 'cf', \
np.where(arg_df['fs_class'].str.contains('StatementOfChangesInEquity'), 'ss', \
np.where(arg_df['fs_class'].str.contains('StatementOfComprehensiveIncome'), 'ci', '')))))
# 並び替え
df_tidy = arg_df[[
'docID',
'ordinance',
'formCode',
'reporting_id',
'sequence_n1',
'DocType',
'edinetCode',
'companyName',
'sequence_n2',
'periodend',
'report_his',
'submitdate',
'consoli_flg',
'fs',
'label',
'contextRef',
'amount'
]]
return df_tidy
def get_df_fs(arg_docid):
# DEI情報の取得
df_dei = get_dei(arg_docid)
# DEIの情報から、財務諸表の含まれるxbrlファイルの特定
if df_dei['GAAP'].unique() == 'Japan GAAP' and df_dei['DocType'].unique() == '第二号の四様式':
# docidから経理の状況が含まれるXBRLファイルのリストを取得
list_xbrl_fs = glob.glob(path_base + arg_docid + '/XBRL/PublicDoc/0205**.htm')
elif df_dei['GAAP'].unique() == 'Japan GAAP' and df_dei['DocType'].unique() == '第四号の三様式':
# docidから経理の状況が含まれるXBRLファイルのリストを取得
list_xbrl_fs = glob.glob(path_base + arg_docid + '/XBRL/PublicDoc/0104**.htm')
elif df_dei['GAAP'].unique() == 'Japan GAAP':
# docidから経理の状況が含まれるXBRLファイルのリストを取得
list_xbrl_fs = glob.glob(path_base + arg_docid + '/XBRL/PublicDoc/0105**.htm')
else:
list_xbrl_fs = []
# DFの取得開始
if list_xbrl_fs:
# ファイル名からキー情報の取得
df_filename_keys = get_keys(list_xbrl_fs[0])
# 結合用のキー列追加
df_filename_keys['temp_key'] = 1
# 経理の状況が含まれるリストから、各ファイルに対応するDFを作成し、リストに格納
list_df_fs = [get_fs(each_xbrl_fs) for each_xbrl_fs in list_xbrl_fs]
# 各ファイルごとのDFを縦結合する。
df_fs = pd.concat(list_df_fs)
# docidから独自ラベルを取得する。
df_label_local = get_label_local(arg_docid)
# 日本語ラベル付きDFを取得する。
df_labeled_fs = get_labeled_df(df_fs, df_label_local)
# 結合用のキー列追加
df_labeled_fs['temp_key'] = 1
# ファイル名から作成したキー情報と結合
df_output = pd.merge(df_filename_keys, df_labeled_fs, on='temp_key', how='left').drop(columns='temp_key')
df_output = pd.merge(df_dei, df_output, on='edinetCode', how='left')
df_output = make_tidy(df_output)
else:
df_output = pd.DataFrame(index=[])
return df_output
上記サンプルコード中のget_df_fsがメインの関数となります。
以下のように、docid単位でフォルダが存在する場合(zipファイルを解凍した状態)、当該階層をpath_baseに定義し、ループを回せば複数docidの財務諸表のデータフレームを作成できます。
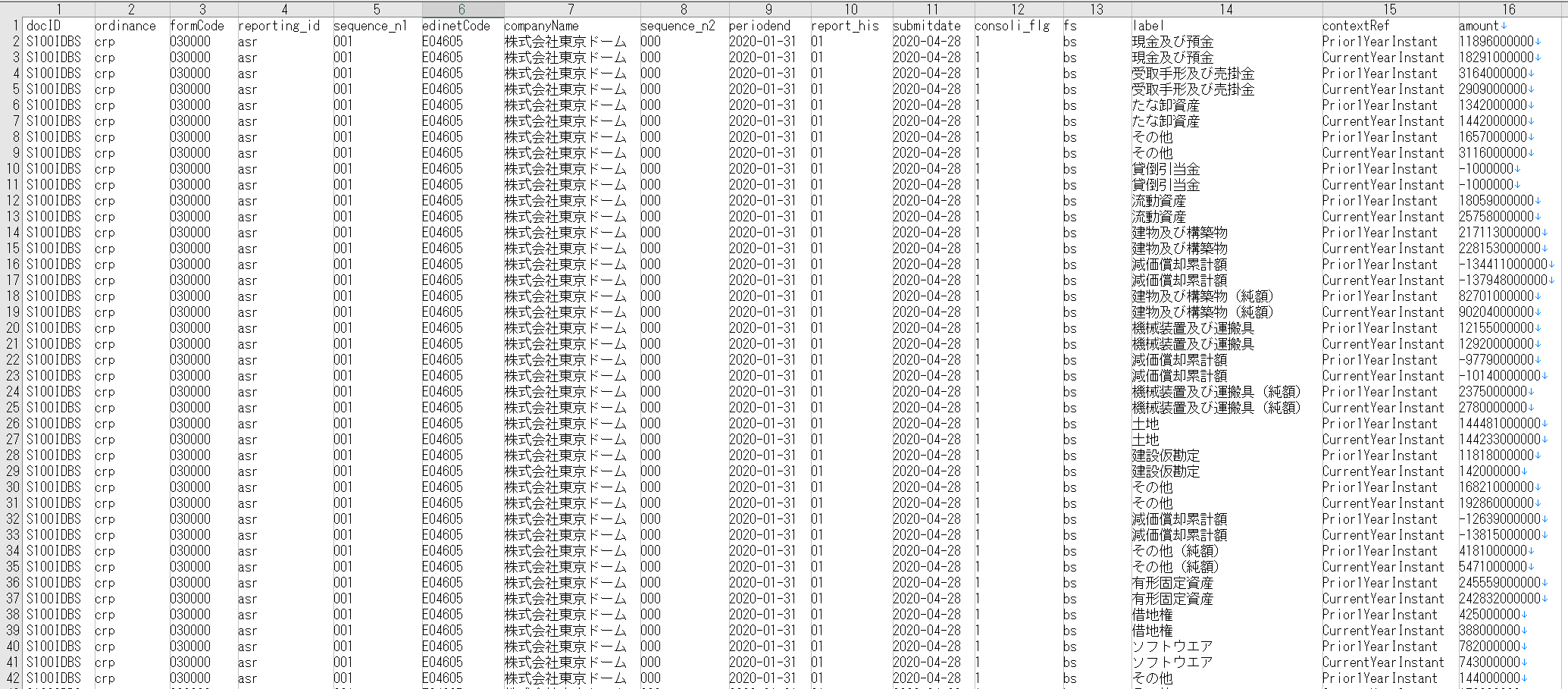
できあがりイメージ
10. 問合せ先
本記事に関する問い合わせは、以下のメールアドレスまでお願いします。
e-mail:xbrl-tech-qa@xbrl.or.jp
(もちろん、qiita上でのコメントも歓迎します)
本メールアドレスは、qiitaの記事を執筆しているXBRLJapanの開発委員会の問合せ窓口になります。
そのため、組織に関する一般的な問合せなどは内容によって回答できかねますが、XBRLに関する技術的な質問、意見、要望、助言等はお気軽にご連絡ください。
なお、委員会メンバが有志で対応しているため、回答に時間がかかることもありますが、ご了承ください。