本記事について
私は野菜を育てるのが大好きです✨
そこで、私が育てている野菜苗をディープラーニングを使用して植物の画像分類してみました。
以下の写真は左からかぼちゃ、ピーマン、トマト苗になります。



本記事はGoogle Clabratory上でVGG16モデルをベースに転移学習を用い、カボチャ、ピーマン、トマトの画像分類する方法を記載します。
なお、「このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています」
開発環境
モデル開発環境
- Google Colabratory
アプリ開発環境(ローカル開発環境)
- OS :
Windows 11 23H2 - Python Version :
3.10.11 - tensorflow :
2.15.1
集めた野菜苗画像
野菜苗画像については、すべて正方形の画像に画像加工しています(例 : 256x256, 224x224, 128x128)
- かぼちゃ画像 : かぼちゃ : 152枚(うちインターネットから75枚取得)
- ピーマン : 167枚(うちインターネットから82枚)
- トマト画像: 202枚(うちインターネットから91枚取得)
本記事では、256x256の画像を用いました。
なお、以下の記事にインターネットからの画像収集方法、および画像加工方法を記載したので、よろしければ参考にしてください。
Google Colabを使用するため、Google Driveにマウントする
from google.colab import drive
# Google Colabを使用する場合のドライブマウント
drive.mount('/content/drive')
処理の内容
以下の処理は、大まかに分けて3つのステップに分かれています。
- 画像データのロード
- 最初に、使用する画像データをロードします。これには、トレーニングデータとテストデータが含まれます。データは通常、フォルダに分類されており、各フォルダは異なるクラス(カテゴリ)を表しています
- VGG16を用いた学習
- 次に、事前学習済みのVGG16モデルを用いて学習を行います。VGG16は、画像分類タスクで広く使用される深層学習モデルです
- このステップでは、VGG16モデルにトレーニングデータを供給し、モデルのパラメータを調整して特定のタスクに最適化されたモデルを生成します。学習にはエポック数やバッチサイズなどのハイパーパラメータを設定します
- 学習させたモデルを用いた予測
- 最後に、学習させたモデルを使用して新しいデータの予測を行います。このステップでは、テストデータをモデルに供給し、その出力結果を評価します。予測結果は、混同行列や分類レポートを使用してモデルの性能を評価します
必要なライブラリのインポート
まず、必要なライブラリをインポートします。ここでは、標準ライブラリおよび外部ライブラリを使用します。
import os
import random
from datetime import datetime
from pathlib import Path
import zipfile
import cv2
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.model_selection import train_test_split
import keras
from keras.applications.vgg16 import VGG16
from keras.applications import MobileNetV2
from keras.callbacks import EarlyStopping, ModelCheckpoint, ReduceLROnPlateau
from keras.layers import Dense, Dropout, Flatten, Input, GlobalAveragePooling2D
from keras.models import Sequential
from keras.optimizers import SGD
from keras.preprocessing.image import ImageDataGenerator
from keras.utils import to_categorical
画像データの読み込み
次に、指定されたフォルダから画像を読み込み、Numpy配列として返す関数を定義します。この関数では、OpenCVを使用して画像を読み込みます。
def load_images_from_folder(folder_path: Path) -> np.ndarray:
"""
指定されたフォルダから画像を読み込み、Numpy配列として返す
Parameters:
folder_path (Path): 画像フォルダへのパス
Returns:
np.ndarray: 画像データ配列
"""
file_list = [filename for filename in os.listdir(str(folder_path)) if not filename.startswith('.')]
result_list: list = []
for file_name in file_list:
file_path: Path = folder_path / file_name
original_image: np.ndarray = cv2.imread(str(file_path))
if original_image is None:
print(f"画像の読み込みに失敗しました: {file_name}")
continue
result_list.append(original_image)
return np.array(result_list)
zipファイルの解凍
次に、ZIPファイルを解凍する関数を定義します。この関数では、Pythonの標準ライブラリであるzipfileを使用します。
def unzip_file(zip_file_path: Path, folder_to_extract_zip_file: Path):
"""
zipを解凍する
Args:
zip_file_path (Path): 解凍するzipファイルパス
folder_to_extract_zip_file (Path): zipファイルを展開するフォルダー
"""
try:
with zipfile.ZipFile(zip_file_path, 'r') as zip_ref:
zip_ref.extractall(folder_to_extract_zip_file)
print(f"Files extracted to {folder_to_extract_zip_file}")
except zipfile.BadZipFile:
print(f"Error: {zip_file_path} is not a valid zip file.")
except Exception as e:
print(f"An error occurred: {e}")
画像データの正規化
画像データを正規化する関数を定義します。この関数では、画像データのピクセル値を0から1の範囲にスケーリングします。
def normalize_image_data(images) -> np.ndarray:
"""
画像データを正規化し、NumPy配列として返す
画像データは最小値が0、最大値が255なので、255で割り、0から1の範囲に変換する
Args:
images (list[np.ndarray]): 画像データのリスト
Returns:
np.ndarray: 正規化された画像データの配列
"""
processed_images = []
for img in images:
img = img / 255.0
processed_images.append(img)
return np.array(processed_images)
転移学習モデルの構築
次に、MobileNetV2をベースにした転移学習モデルを構築する関数を定義します。この関数では、事前訓練されたMobileNetV2の重みを使用し、カスタムの全結合層とドロップアウト層を追加します。
def build_model_light(input_shape: tuple) -> Sequential:
"""
MobileNetV2ベースの転移学習モデルを構築する
この関数は、MobileNetV2モデルをベースにした転移学習モデルを構築し、最終的な分類層を追加します。
MobileNetV2の事前訓練済みの重みを使用し、カスタムの全結合層とドロップアウト層を追加して、特定のタスクに適応させます。
Args:
input_shape (tuple): モデルに入力される画像の形状 (height, width, channels)
Returns:
keras.Sequential: 構築されたKerasのSequentialモデル
"""
# MobileNetV2のベースモデルを取得し、トップ層を除外
mobilenet_v2 = MobileNetV2(weights='imagenet', include_top=False, input_shape=input_shape)
# カスタムモデルの構築
model = Sequential([
mobilenet_v2,
GlobalAveragePooling2D(),
Dense(128, activation='relu'), # 全結合層
Dropout(0.5), # ドロップアウト層
Dense(3, activation='softmax') # 出力層 (クラス数は3)
])
# ベースモデルの層を凍結
for layer in mobilenet_v2.layers:
layer.trainable = False
# モデルのコンパイル
model.compile(optimizer=SGD(learning_rate=0.001, momentum=0.9),
loss='categorical_crossentropy',
metrics=['accuracy'])
print(f"build_model model : {type(model)}")
return model
関数の説明
- 引数
- input_shape (tuple): モデルに入力される画像の形状 例: (height, width, channels)
- 戻り値
- keras.Sequential: 構築されたKerasのSequentialモデル
- モデルの構築手順
- MobileNetV2のベースモデルの取得
- MobileNetV2を使用し、事前訓練された重みをロード
- include_top=Falseとすることで、最上位の分類層を除外
- カスタムモデルの追加層
- GlobalAveragePooling2D: グローバル平均プーリング層を追加
- Dense(128, activation='relu'): ユニット数128の全結合層を追加
- Dropout(0.5): ドロップアウト層を追加し、過学習を防止
- Dense(3, activation='softmax'): 出力層を追加し、3クラスの分類を行う
- ベースモデルの層の凍結
- MobileNetV2の層を凍結し、事前訓練された重みが更新されないようにする
- モデルのコンパイル
- オプティマイザにSGDを使用し、学習率とモメンタムを設定
- 損失関数にcategorical_crossentropyを指定し、分類タスクに対応
- 評価指標としてaccuracyを指定
- MobileNetV2のベースモデルの取得
乱数シードの設定
機械学習や深層学習モデルのトレーニングにおいて、再現性を確保するためには乱数シードの設定が重要です。
そのため、乱数シードを設定する関数を定義します。この関数は、Pythonのrandomモジュール、NumPy、TensorFlowの乱数シードを設定します。
def set_random_seed(seed: int):
"""
指定されたシード値を使用して、乱数生成の再現性を設定する
Args:
seed (int): 乱数生成のシード値
"""
random.seed(seed)
np.random.seed(seed)
tf.random.set_seed(seed)
データの準備
画像データをロードし、トレーニングセットとテストセットに分割する関数を定義します。この関数では、画像データの正規化も行います。
def prepare_data(base_image_folder_path: Path, seed: int):
"""
画像データをロードし、トレーニングセットとテストセットに分割する
Args:
base_image_folder_path (Path): 画像データが保存されているフォルダのパス
seed (int): データ分割のランダムシード値
Returns:
X_train (np.ndarray): トレーニング用画像データのNumPy配列
X_test (np.ndarray): テスト用画像データのNumPy配列
y_train (np.ndarray): トレーニング用ラベルデータのワンホットエンコーディング配列
y_test (np.ndarray): テスト用ラベルデータのワンホットエンコーディング配列
"""
folder_path_pumpkin = base_image_folder_path / "pumpkin"
folder_path_green_papper = base_image_folder_path / "green_papper"
folder_path_tomato = base_image_folder_path / "tomato"
pumpkin_images = load_images_from_folder(folder_path_pumpkin)
green_papper_images = load_images_from_folder(folder_path_green_papper)
tomato_images = load_images_from_folder(folder_path_tomato)
print(f"pumpkin_images = {len(pumpkin_images)}")
print(f"green_papper_images = {len(green_papper_images)}")
print(f"tomato_images = {len(tomato_images)}")
# 画像データを正規化する
X_pumpkin = normalize_image_data(pumpkin_images)
X_green_papper = normalize_image_data(green_papper_images)
X_tomato = normalize_image_data(tomato_images)
# すべての画像データを含むNumPy配列。形状は(総画像数, 画像高さ, 画像幅, チャネル数)
X = np.concatenate([X_pumpkin, X_green_papper, X_tomato], axis=0)
print(f"X shape : {X.shape}")
# すべての画像に対応するラベルのリスト
y = np.array([0]*len(pumpkin_images) + [1]*len(green_papper_images) + [2]*len(tomato_images))
print(f"y shape : {y.shape}")
# データをトレーニングセットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y , test_size=0.2, random_state=seed)
# データセットの一部をプロットして可視化
num_images_to_display = 30
fig, axes = plt.subplots(5, 6, figsize=(10, 10))
axes = axes.ravel()
class_names = ["Pumpkin", "Green Papper", "Tomato"] # クラス名のリスト
for i in range(num_images_to_display):
image = X_train[i][..., ::-1] # BGR ⇒ RGB
axes[i].imshow(image)
axes[i].set_title(class_names[y_train[i]])
axes[i].axis('off')
plt.show()
# ワンホットエンコーディング
y_train = tf.keras.utils.to_categorical(y_train, num_classes=3)
y_test = tf.keras.utils.to_categorical(y_test, num_classes=3)
return X_train, X_test, y_train, y_test
関数の説明
- 機能
- 画像データをロードし、正規化を行い、トレーニングセットとテストセットに分割する
- 一部のデータを可視化して確認する
- ラベルデータをワンホットエンコーディング形式に変換する
複数のシード値でのモデルトレーニング
複数のシード値を使用してモデルをトレーニングし、その結果を保存するコードを示します。
# シード値を設定
seeds = [42, 52, 62]
# ハイパーパラメーターを設定
epochs = 50
# トレーニング履歴を保存するリスト
histories = []
# ベース画像フォルダパスと画像サイズを設定
base_image_folder_path = Path('path_to_images')
image_file_size = 128 # 画像のサイズを設定(例: 128x128)
for seed in seeds:
set_random_seed(seed)
X_train, X_test, y_train, y_test = prepare_data(base_image_folder_path, seed)
input_shape = (image_file_size, image_file_size, 3)
model = build_model_light(input_shape)
# モデルのトレーニングを実施する
history = model.fit(X_train, y_train, epochs=epochs, validation_split=0.2, batch_size=32)
histories.append(history)
トレーニング結果のサマリ表示関数
このコードは、複数のシード値に対して行ったトレーニングの結果を要約し、表示する関数を定義しています。この関数は、トレーニングと検証の損失および精度を各シード値ごとに表示し、最終的にはそれらの平均値も計算して表示します。
def summarize_final_results(seeds: list[int], histories: list[tf.keras.callbacks.History]) -> None:
"""
各シード値でのトレーニングの最終結果を表示する
Args:
seeds (list[int]): seed配列
histories (list[keras.callbacks.History]): トレーニング履歴リスト
"""
# 最終エポックの結果を格納するリスト
final_train_losses = []
final_val_losses = []
final_train_accuracies = []
final_val_accuracies = []
for history in histories:
final_train_losses.append(history.history['loss'][-1])
final_val_losses.append(history.history['val_loss'][-1])
final_train_accuracies.append(history.history['accuracy'][-1])
final_val_accuracies.append(history.history['val_accuracy'][-1])
# 結果の表示
print(f"{'Seed':^7} {'Train Loss':^12} {'Validation Loss':^18} {'Train Accuracy':^18} {'Validation Accuracy':^20}")
print("="*75)
for seed, train_loss, val_loss, train_acc, val_acc in zip(seeds, final_train_losses, final_val_losses, final_train_accuracies, final_val_accuracies):
print(f"{seed:^7} {train_loss:^12.4f} {val_loss:^18.4f} {train_acc:^18.4f} {val_acc:^20.4f}")
# 平均値の計算
avg_train_loss = np.mean(final_train_losses)
avg_val_loss = np.mean(final_val_losses)
avg_train_acc = np.mean(final_train_accuracies)
avg_val_acc = np.mean(final_val_accuracies)
print("="*75)
print(f"{'Average':^7} {avg_train_loss:^12.4f} {avg_val_loss:^18.4f} {avg_train_acc:^18.4f} {avg_val_acc:^20.4f}")
summarize_final_results(seeds, histories)
関数説明
各履歴から最終結果を抽出
for history in histories:
final_train_losses.append(history.history['loss'][-1])
final_val_losses.append(history.history['val_loss'][-1])
final_train_accuracies.append(history.history['accuracy'][-1])
final_val_accuracies.append(history.history['val_accuracy'][-1])
histories リストをループし、各履歴からトレーニングと検証の最終エポックの損失と精度を抽出してリストに追加します。
トレーニング履歴のプロットとバンド表示関数
異なるシード値でトレーニングしたモデルの履歴を可視化し、その範囲を帯として表示することで、モデルの安定性や性能のばらつきを視覚的に確認することができます。
def plot_histories_with_bands(seeds: list[int], histories: list[tf.keras.callbacks.History], epochs: int) -> None:
"""
複数のトレーニング履歴を同じグラフにプロットし、最大・最小範囲を帯として表示する
Args:
seeds (list[int]): seed配列
histories (list[keras.callbacks.History]): トレーニング履歴リスト
epochs (int): エポック数
"""
# NumPy配列に変換
train_losses: np.ndarray = np.array([history.history['loss'] for history in histories])
val_losses: np.ndarray = np.array([history.history['val_loss'] for history in histories])
train_accuracies: np.ndarray = np.array([history.history['accuracy'] for history in histories])
val_accuracies: np.ndarray = np.array([history.history['val_accuracy'] for history in histories])
# 各列(エポック)ごとの最大値・最小値を計算
max_train_loss: np.ndarray = train_losses.max(axis=0)
min_train_loss: np.ndarray = train_losses.min(axis=0)
max_val_loss: np.ndarray = val_losses.max(axis=0)
min_val_loss: np.ndarray = val_losses.min(axis=0)
max_train_acc: np.ndarray = train_accuracies.max(axis=0)
min_train_acc: np.ndarray = train_accuracies.min(axis=0)
max_val_acc: np.ndarray = val_accuracies.max(axis=0)
min_val_acc: np.ndarray = val_accuracies.min(axis=0)
# 各列(エポック)ごとの平均値を計算
avg_train_loss: np.ndarray = train_losses.mean(axis=0)
avg_val_loss: np.ndarray = val_losses.mean(axis=0)
avg_train_acc: np.ndarray = train_accuracies.mean(axis=0)
avg_val_acc: np.ndarray = val_accuracies.mean(axis=0)
plt.figure(figsize=(13, 6))
# Lossの可視化
plt.subplot(1, 2, 1)
# trainのlossを表示
for seed, history in zip(seeds, histories):
plt.plot(history.history["loss"], label=f"train (seed={seed})", alpha=0.3)
# validのlossを表示
for seed, history in zip(seeds, histories):
plt.plot(history.history["val_loss"], label=f"valid (seed={seed})", linestyle='--', alpha=0.3)
plt.fill_between(range(epochs), min_train_loss, max_train_loss, color='blue', alpha=0.1, label="train range")
plt.fill_between(range(epochs), min_val_loss, max_val_loss, color='orange', alpha=0.1, label="valid range")
plt.plot(avg_train_loss, color='blue', label="avg train")
plt.plot(avg_val_loss, color='orange', linestyle='--', label="avg valid")
# lossのy軸の範囲を設定
max_loss_value = max(max_train_loss.max(), max_val_loss.max())
plt.xlim(0, epochs)
plt.ylim(0, max_loss_value)
plt.title("Train and Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.grid()
# Accuracyの可視化
plt.subplot(1, 2, 2)
# trainのaccuracyを表示
for seed, history in zip(seeds, histories):
plt.plot(history.history["accuracy"], label=f"train (seed={seed})", alpha=0.3)
# validのaccracyを表示
for seed, history in zip(seeds, histories):
plt.plot(history.history["val_accuracy"], label=f"valid (seed={seed})", linestyle='--', alpha=0.3)
plt.fill_between(range(epochs), min_train_acc, max_train_acc, color='blue', alpha=0.1, label="train range")
plt.fill_between(range(epochs), min_val_acc, max_val_acc, color='orange', alpha=0.1, label="valid range")
plt.plot(avg_train_acc, color='blue', label="avg train")
plt.plot(avg_val_acc, color='orange', linestyle='--', label="avg valid")
plt.xlim(0, epochs)
plt.ylim(0, 1)
plt.title("Train and Validation Accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
plt.grid()
plt.show()
plot_histories_with_bands(seeds, histories, epochs)
関数の説明
- 機能
- 各シード値でのトレーニング履歴をプロットし、最大・最小範囲を帯として表示する
- 平均的なトレーニング損失および精度をプロットする
モデルの保存とファイルサイズの確認
以下のコードは、Kerasモデルを保存し、その保存ファイルのサイズを確認する方法を示しています。具体的な手順として、現在の日時を用いたファイル名の生成、モデルの保存、ファイルサイズの確認を行っています。
# モデルを保存する
now = datetime.now()
timestamp = now.strftime("%Y%m%d_%H%M%S")
model_file_path: Path = Path(f'/content/drive/My Drive/my_model_{timestamp}.h5')
model.save(model_file_path)
file_size = model_file_path.stat().st_size
print(f"モデルファイルのサイズ: {(file_size / (1024 * 1024)):.2f} MB")
モデルのパフォーマンス結果
シード値ごとの最終エポックの結果分析
Seed Train Loss Validation Loss Train Accuracy Validation Accuracy
===========================================================================
42 0.0517 0.1387 0.9940 0.9167
52 0.0461 0.2013 1.0000 0.9405
62 0.0528 0.2415 0.9880 0.9048
===========================================================================
Average 0.0502 0.1938 0.9940 0.9206
-
各列の意味
- Seed: トレーニングに使用したシード値。異なるシード値を使うことで、トレーニング結果の再現性や変動性を確認できます
- Train Loss: トレーニングデータに対する最終エポックの損失。低いほどモデルがトレーニングデータに対してうまく適合していることを示します
- Validation Loss: 検証データに対する最終エポックの損失。低いほどモデルが検証データに対してうまく適合していることを示します
- Train Accuracy: トレーニングデータに対する最終エポックの精度。1.0に近いほど高い精度を示します
- Validation Accuracy: 検証データに対する最終エポックの精度。1.0に近いほど高い精度を示します
-
平均的に見て、モデルはトレーニングデータに対して非常にうまく適合しており、検証データに対しても良好な精度を示しています
-
分析結果考察
この結果から、モデルはトレーニングデータに対して非常に高い精度を持ち、検証データに対しても高い精度を維持しています。ただし、検証損失がやや高めであるため、多少の過学習の可能性も考慮する必要があります
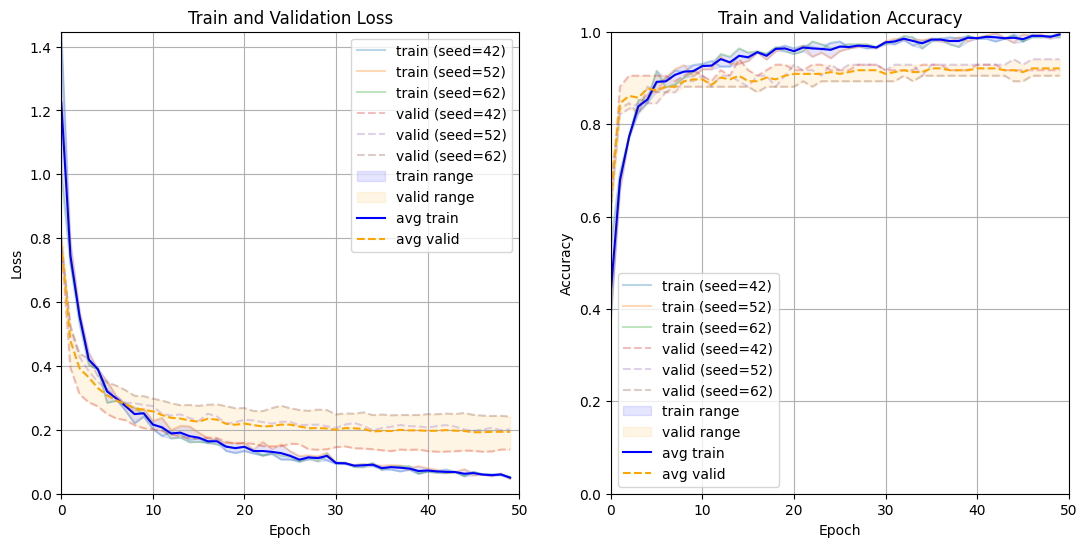
トレーニングと検証の損失および精度の可視化結果について
以下の図は、異なるシード値で行ったトレーニングの損失と精度の推移を示しています。
左側のプロットはトレーニングと検証の損失、
右側のプロットはトレーニングと検証の精度を表しています。
可視化結果考察
モデルは非常に高い精度でトレーニングされ、検証データに対しても良好なパフォーマンスを示しています。トレーニングと検証の損失および精度の推移が一貫しており、異なるシード値による変動も少ないため、モデルの安定性が確認できます。
ただし、トレーニング精度が非常に高く、検証精度が若干低いことから、過学習の兆候が少し見られます。
モデル予測結果の表示関数について
以下に示すコードは、訓練済みのKerasモデルを使用して入力画像のクラス予測を行い、その予測結果を表示する関数 predict_result_display を定義しています。この関数は、入力画像の配列を処理し、それぞれの画像に対する予測クラスと実際のクラスを表示します。
def predict_result_display(model: keras.src.engine.sequential.Sequential, images: np.ndarray, y_test: np.ndarray, class_names: list[str]):
"""
モデルを使用して入力画像のクラス予測を行い、予測結果を表示する
Args:
model (keras.src.engine.sequential.Sequential): 予測に使用する訓練済みのKerasモデル
images (np.ndarray): 予測するBGR形式の画像配列。形状は(num_images, height, width, channels)とすること
y_test (np.ndarray): テスト用ラベルデータのワンホットエンコーディング配列
class_names (list[str]): モデルが予測するクラスの名前のリスト
Notes:
- 入力画像はBGR形式で提供されるため、表示のためにRGB形式に変換すること
"""
plt.figure(figsize=(12, 12)) # matplotlibの初期設定 (画像のサイズ(縦(12inch), 横(12inch)))
for i in range(min(len(images), 30)):
plt.subplot(5, 6, i + 1) # 図の分割 (plt.figureで定義したものをさらに5行5列で分割する)(通し番号(初期値はi+1=1))
img_float32 = np.float32(images[i])
plt.imshow(cv2.cvtColor(img_float32, cv2.COLOR_BGR2RGB)) # matplotlibはRGB形式にする必要がある。cv2はBGR形式で読み込む
# predict image
temp_img_array = img_float32.reshape(1, image_file_size, image_file_size, 3) # 次元を増やす(128, 128, 3(RGB)) ⇒ (1, 128, 128, 3(RGB)) バッチサイズ : 32枚まとめて学習
# 2枚の場合は(2, 128, 128, 3)の場合となる
img_pred: float = model.predict(temp_img_array) # 4次元に変換した画像データを1個入れてあげると予測値が出力される
# 予測クラス名を取得
predicted_class = class_names[np.argmax(img_pred)] # np.max: 大きい値を取り出す, np.argmax: 大きい値のインデックス番号を取り出す
# 正解クラス名を取得
true_class = class_names[np.argmax(y_test[i])]
# 予測クラス名と正解クラス名を各サブプロットに表示する
# 0.5: テキストのx座標。軸の中央に配置されます。
# -0.2: テキストのy座標。画像の下に配置されます。
# f"Pred: {predicted_class}\nTrue: {true_class}": 表示するテキスト。予測クラス名と正解クラス名が含まれます。
# ha='center': テキストを中央揃えに設定します。
# transform=plt.gca().transAxes: 軸の座標系に基づいてテキストを配置します。
# fontsize=9: テキストのフォントサイズを9ポイントに設定します。
plt.text(x = 0.5, y = -0.2, s = f"Pred: {predicted_class}\nTrue: {true_class}", ha='center', transform=plt.gca().transAxes, fontsize=9) # 予測クラス名と正解クラス名をタイトルに表示
plt.axis('off') # 縦軸・横軸を表示しない設定
plt.subplots_adjust(hspace=0.5) # 行間のスペースを設定
plt.tight_layout() # レイアウトを調整
plt.show() # グラフを表示
# 画像の予測結果を表示する
predict_result_display(model, X_test, y_test, class_names)
予測結果
おおよそ正しく苗の種類を予測することができました。

混同行列と分類レポートを表示する関数
以下のコードは、モデルの予測結果に基づいて混同行列と分類レポートを表示する関数を定義しています。この関数は、モデルの性能を詳細に評価するために役立ちます。
import seaborn as sns
def display_confusion_matrix_and_classification_report(model: Sequential, X_test: np.ndarray, y_test: np.ndarray, class_names: list[str]) -> None:
"""
モデルの予測結果に基づいて混同行列と分類レポートを表示する
Args:
model (Sequential): 予測に使用する訓練済みのKerasモデル
X_test (np.ndarray): テスト用の入力データ
y_test (np.ndarray): テスト用ラベルデータのワンホットエンコーディング配列
class_names (list[str]): モデルが予測するクラスの名前のリスト
"""
# 予測結果の取得
y_pred = model.predict(X_test)
y_pred_classes = np.argmax(y_pred, axis=1)
y_true = np.argmax(y_test, axis=1)
# 混同行列の計算
conf_matrix = confusion_matrix(y_true, y_pred_classes)
# 混同行列のプロット
plt.figure(figsize=(8, 6))
sns.heatmap(conf_matrix, annot=True, fmt="d", cmap="Blues")
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.title('Confusion Matrix')
plt.show()
# 分類レポートの表示
class_report = classification_report(y_true, y_pred_classes, target_names=class_names)
print(class_report)
display_confusion_matrix_and_classification_report(model, X_test, y_test, class_names)
分類レポート結果 (混同行列)
以下の混同行列は、モデルの予測結果に基づく実際のクラスと予測されたクラスの関係を視覚化したものです。各セルには、特定の実際のクラスに対して予測されたクラスの数が示されています。
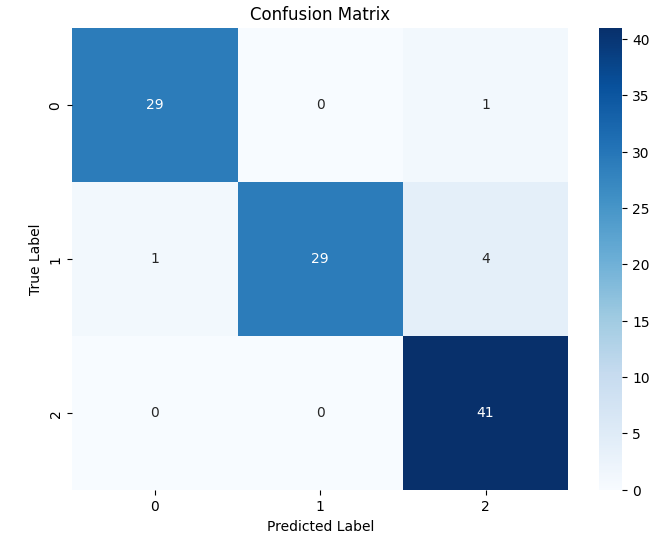
混同行列の解釈
- True Label(縦軸): 実際のクラス
- Predicted Label(横軸): 予測されたクラス
- 各セルの値: 特定の実際のクラスと予測されたクラスの数
各クラスについての詳細な解釈は以下の通りです:
-
Class 0 (Pumpkin)
- 正しく予測された数(True Positives, TP): 29
- 他のクラスとして誤って予測された数(False Negatives, FN): 1 (1つの Pumpkin が Tomato と誤って予測された)
- 他のクラスから誤って予測された数(False Positives, FP): 0
ここでの精度(Precision)は、予測された Pumpkin のうち実際に Pumpkin であった割合です - 再現率(Recall)は、実際の Pumpkin のうち正しく予測された割合です
-
Class 1 (Green Pepper)
- 正しく予測された数(TP): 29
- 他のクラスとして誤って予測された数(FN): 5 (1つの Green Pepper が Pumpkin、4つが Tomato と誤って予測された)
- 他のクラスから誤って予測された数(FP): 0
- ここでの精度(Precision)は、予測された Green Pepper のうち実際に Green Pepper であった割合です
- 再現率(Recall)は、実際の Green Pepper のうち正しく予測された割合です
-
Class 2 (Tomato)
- 正しく予測された数(TP): 41
- 他のクラスとして誤って予測された数(FN): 0
- 他のクラスから誤って予測された数(FP): 1 (1つの Pumpkin が Tomato と誤って予測された)
- ここでの精度(Precision)は、予測された Tomato のうち実際に Tomato であった割合です
- 再現率(Recall)は、実際の Tomato のうち正しく予測された割合です
混同行列考察結果
全体として、モデルは非常に高い精度で各クラスを予測しています。特に Pumpkin と Tomato クラスの予測性能が優れており、Green Pepper クラスも良好な性能を示しています。ただし、Green Pepper クラスの再現率を改善する余地があります。これにより、全体のモデル性能をさらに向上させることができます。
分類レポート結果
以下の分類レポートは、各クラスごとに精度、再現率、F1スコア、およびサポート数が示されています。
precision recall f1-score support
pumpkin 0.97 0.97 0.97 30
green papper 1.00 0.85 0.92 34
tomato 0.89 1.00 0.94 41
accuracy 0.94 105
macro avg 0.95 0.94 0.94 105
weighted avg 0.95 0.94 0.94 105
各指標の意味
- precision(適合率):予測した正例のうち、実際に正例であった割合を示します。高い精度は、誤って予測された正例(偽陽性)が少ないことを意味します
- recall(再現率):実際の正例のうち、正しく予測された割合を示します。高い再現率は、誤って予測された負例(偽陰性)が少ないことを意味します
- f1-score: 精度と再現率の調和平均です。精度と再現率のバランスを考慮した指標であり、高い値はモデルが全体的に良好であることを示します
- support(サポート): 各クラスの実際のデータポイント数を示します。モデル評価の際の基準となる実データの数です
分析結果考察
この分類レポートから、モデルの予測性能は全体的に非常に高いことがわかりました
- pumpkin : クラスの予測性能は非常に高く、精度、再現率、F1スコアのすべてが良い結果だった
- green papper : クラスは適合率が完璧ですが、再現率が若干低いため、改善の余地があった
- tomato : クラスは再現率が完璧ですが、適合率が若干低くかった
全体の正確性は0.94であり、ほとんどのデータポイントが正しく分類された
混同行列と分類レポートと改善点とChatGPTからの提案について
混同行列と分類レポートを詳細に分析することで、モデルの強みと弱点を把握し、さらなる改良点を見つけることができます。
- データ拡張: 特に Green Pepper クラスのデータ拡張を行うことで、再現率を改善する可能性があります
- モデルチューニング: ハイパーパラメータの調整や正則化の追加により、特定クラスの予測性能を向上させることができます
- さらなる評価: 交差検証を用いてモデルの安定性と汎化性能を評価することも検討すべきです
結果総括
今回の実験結果から、いくつかの重要なポイントが明らかになりました。
-
モデルの精度
- 全体のValidation Accuracyが0.9206と非常に高い精度を示しています。これは、モデルが検証データに対しても高い適合性を持っていることを示しており、モデルの信頼性が高いことを意味します
-
シード値ごとのパフォーマンス
Seed Train Loss Validation Loss Train Accuracy Validation Accuracy =========================================================================== 42 0.0517 0.1387 0.9940 0.9167 52 0.0461 0.2013 1.0000 0.9405 62 0.0528 0.2415 0.9880 0.9048 =========================================================================== Average 0.0502 0.1938 0.9940 0.9206- どのシード値でも安定して高い精度を示しており、特にシード52のトレーニング精度が1.0000に達していることが注目されます
-
過学習の可能性
- トレーニングデータに対する精度(Train Accuracy)が非常に高く、一部のシード値では1.0000に達している一方で、検証損失(Validation Loss)がやや高めとなっています。これは、多少の過学習が発生している可能性があることを示唆しています
-
画像データの課題
- 現在の課題として、画像数が少ないです。データ量の不足はモデルの汎化性能に影響を与えるため、データ拡張や新たな画像データの収集が推奨されます
本記事のモデルを用いたアプリ作成
本記事で作成したモデルを用いた植物苗画像分類アプリを作成しました。以下から参照可能です。
https://seeding-classification.onrender.com/
ただし、Renderが無料プランであるため、非常に動作が遅く、さらには画面ロードに失敗する場合がありますので、ご了承ください。<(_ _)>
実行イメージを以下に載せます。


コードについてはGitHubを参照ください。
https://github.com/a143321/seeding-classification
エラー対処例(パッケージのバージョン管理のエラーの対象方法)
ローカルで動作するようになったアプリをRenderにデプロイする際、パッケージのバージョンエラーが多発しました。
パッケージのバージョンエラーは、同じエラーがインターネット上で見つからない場合も多く解決が難しいエラーと思います。
以下にチューターの方に回答をいただいてから、問題解決までの調査方法・対処方法を記載します。
requirements.txtの生成と使用方法
まず、requirements.txtの生成と使用方法について説明させてください。
現在のバージョンは以下で保存できます。
pip freeze > requirements.txt
requirements.txtを用いて同じパッケージを素早くインストールできます。
pip install -r requirements.txt
現在のインストールされているパッケージを削除する場合は以下で可能です。
pip freeze > requirements_uninstall.txt
pip uninstall -r requirements_uninstall.txt -y
実際に発生したパッケージのバージョンエラー
モデルのロード処理で発生したエラー内容です。全く対処方法がわからなかったため、チューターの方に質問させていただきました。
Traceback (most recent call last):
File "main.py", line 24, in <module>
model = load_model('./my_model_20240705_074144.h5', compile=False)
File "/opt/render/project/src/.venv/lib/python3.7/site-packages/tensorflow/python/keras/saving/save.py", line 182, in load_model
return hdf5_format.load_model_from_hdf5(filepath, custom_objects, compile)
File "/opt/render/project/src/.venv/lib/python3.7/site-packages/tensorflow/python/keras/saving/hdf5_format.py", line 178, in load_model_from_hdf5
custom_objects=custom_objects)
File "/opt/render/project/src/.venv/lib/python3.7/site-packages/tensorflow/python/keras/saving/model_config.py", line 55, in model_from_config
return deserialize(config, custom_objects=custom_objects)
File "/opt/render/project/src/.venv/lib/python3.7/site-packages/tensorflow/python/keras/layers/serialization.py", line 175, in deserialize
printable_module_name='layer')
File "/opt/render/project/src/.venv/lib/python3.7/site-packages/tensorflow/python/keras/utils/generic_utils.py", line 358, in deserialize_keras_object
list(custom_objects.items())))
File "/opt/render/project/src/.venv/lib/python3.7/site-packages/tensorflow/python/keras/engine/sequential.py", line 487, in from_config
custom_objects=custom_objects)
File "/opt/render/project/src/.venv/lib/python3.7/site-packages/tensorflow/python/keras/layers/serialization.py", line 175, in deserialize
printable_module_name='layer')
File "/opt/render/project/src/.venv/lib/python3.7/site-packages/tensorflow/python/keras/utils/generic_utils.py", line 360, in deserialize_keras_object
return cls.from_config(cls_config)
File "/opt/render/project/src/.venv/lib/python3.7/site-packages/tensorflow/python/keras/engine/base_layer.py", line 697, in from_config
return cls(**config)
File "/opt/render/project/src/.venv/lib/python3.7/site-packages/tensorflow/python/keras/layers/pooling.py", line 848, in __init__
super(GlobalPooling2D, self).__init__(**kwargs)
File "/opt/render/project/src/.venv/lib/python3.7/site-packages/tensorflow/python/training/tracking/base.py", line 457, in _method_wrapper
result = method(self, *args, **kwargs)
File "/opt/render/project/src/.venv/lib/python3.7/site-packages/tensorflow/python/keras/engine/base_layer.py", line 318, in __init__
generic_utils.validate_kwargs(kwargs, allowed_kwargs)
File "/opt/render/project/src/.venv/lib/python3.7/site-packages/tensorflow/python/keras/utils/generic_utils.py", line 778, in validate_kwargs
raise TypeError(error_message, kwarg)
TypeError: ('Keyword argument not understood:', 'keepdims')
チューターの方の回答
当日中に以下の回答をいただきました✨
エラーログTypeError: ('Keyword argument not understood:', 'keepdims')とsuper(GlobalPooling2D, self).__init__(**kwargs)から想定原因を見つけ出し、そこから公式ドキュメントを用いてtensorflowのバージョンの違いによるGlobalAveragePooling2Dの仕様の違いがあることを正確に把握されていました。
以下にチューターの方に回答をいただいてから、問題解決までの調査方法・対処方法を記載します。
チューターの方が見出した想定原因
mobilenetv2の次のGlobalAveragePooling2Dクラスのインスタンス化(initメソッド)の箇所でkeepdims引数が定義されていないために起こったエラーと思われる
チューターの方の確認内容
tensorflow v.2.3.0のドキュメントを確認したところ、確かにkeepdimsについて言及されていませんでした。
https://www.tensorflow.org/versions/r2.3/api_docs/python/tf/keras/layers/GlobalAveragePooling2D
一方でtensorflow v.2.16.1ではkeepdimsについて言及されていました
https://www.tensorflow.org/api_docs/python/tf/keras/layers/GlobalAveragePooling2D
チューターの方のエラー解決のためのアドバイス内容
従いまして、requirments.txtで指定したtensorflowのバージョンを変更してみてください。おそらくv.2.16に変更すると他の箇所でエラーが起こる可能性が高いです。
なので少しづつバージョンを2.3から上げながら確認してみてください。
アドバイスを受けた後のエラー調査・対処方法
tensorflow versionの2.16.1を使用するとエラーになる可能性が高いので、
tensorflowのリリース履歴から少し前のtensorflow versionの2.15.1を使用することにしました。
tensorflow versionのバージョン選定理由は、今回Google Colabで作成したモデルは主に新しいパッケージバージョンで作成しており、古いversionでは動作しない可能性が高いと思ったためです。
なお、Google Colab上のパッケージバージョンは以下で確認可能です。
Google Colabでは、Python Versionは3.10.12、tensorflowは2.15.0を使用していました。
## Google Colab上でのpip listでパッケージバージョンを確認
!python --version
!pip list
!pip freeze > requirements.txt
Python 3.10.12
Package Version
-------------------------------- ---------------------
~~
tensorflow 2.15.0
~~
ここで、さらにtensorflow 2.15.1ダウンロードページからtensorflow 2.15.1に対応したPython Versionを選定します。
Google ColabのPython Versionが3.10.12を使用していることに着目して、Pyton 3.11ではなく、Python 3.10を使用することにしました。
tensorflow-2.15.1-cp310-cp310-win_amd64.whl
そのため、Python Installerは3.10のバージョンをインストールする必要があります。以下から3.10の最新のインストーラーをダウンロードしました。
https://www.python.org/downloads/
Python 3.10の仮想環境を作成する場合は、以下のようにバージョン指定で実現可能です。
py -3.10 -m venv .venv
あとは、エラーログを見ながら、パッケージのバージョンを1つずつ微修正しながら、エラーを解決していきました。
お礼と今後について
ディープラーニングを用いた植物苗の画像分類のアプリを短期間で作成できたのはチューターの方々の適切なコーチングのおかげです。本当にありがとうございます✨
AIの学習は私にとって本当に難しかったですが、なんとか進めることができました。
今後のチャレンジとして、以下の項目に取り組みたいと思います。
-
ImageDataGeneratorを用いた画像のデータ拡張
画像のデータ拡張を行い、モデルの汎化性能を向上させることを目指します。これにより、モデルがより多様 なデータに対しても正確に予測できるようになります -
Kaggleで他のエンジニアのディープラーニングコードを学ぶ
Kaggle上で他のエンジニアが記載したディープラーニングのコードを参照し、最新の技術やトレンドを学びたいと思います -
Dockerの勉強
誰が環境を作成しても同じ環境を作成できるように、Dockerを学びたいです -
YOLOを用いた物体検出
YOLO(You Only Look Once)を用いて物体検出を行う技術を習得したいと思います
補足記事
本記事記載で役立った情報を追記します。
Google Colab有料プランについて
今回Google Colabの有料プランを用いて学習実施しました。
以下に有料プランの情報について記載します。
以下のコマンドでランタイムを切断できます。
from google.colab import runtime
runtime.unassign()
TensorflowとPytorchの違いについて
学習するライブラリが大きく分けて2つあるため、注意が必要です。
https://inside-alpha-media.com/pytorch-vs-tensorflow%ef%bc%9a%e6%b7%b1%e5%b1%a4%e5%ad%a6%e7%bf%92%e7%95%8c%e3%81%ae%e9%a0%82%e4%b8%8a%e6%b1%ba%e6%88%a6%ef%bc%81/
TensorFlow 2.16がリリースされたことにより、Tensorflowのコードの書き方は注意必要
2024年3月8日、Keras 3をデフォルトの高水準APIとしたTensorFlow 2.16がリリースされました。
このタイミングで、TensorFlowにはtf.kerasが同梱されなくなりました。