やりたいこと
アクセスログをもとに機械学習(ディープラーニング)で不正アクセスを予測する仕組み作る。
1.Splunkを使い、access.logをCSVに変換
2.CSVファイルをもとにJupyterLab上で教師データを作る ⇦今回の内容
3.ディープラーニングを用いて、予測精度を確かめる

前回
Splunkとkerasを用いた不正アクセス予測検知の仕組み(前処理編)
環境
・JupyterLab 2.1.4 @ AWS Cloud9
・Python 3
・Splunk Enterprise 8.1 @ AWS EC2
教師データ(答え合わせ用)作成
初期設定を行う。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from distutils.util import strtobool
from sklearn.model_selection import train_test_split
from sklearn.ensemble import IsolationForest
# DataFrameで全ての行・列を表示する設定
pd.options.display.max_columns = None
Splunkで作成したCSVファイルを読み込む。
dataset_access_log = pd.read_csv('access-log_200MB.csv')
データを確認する。
dataset_access_log.head()
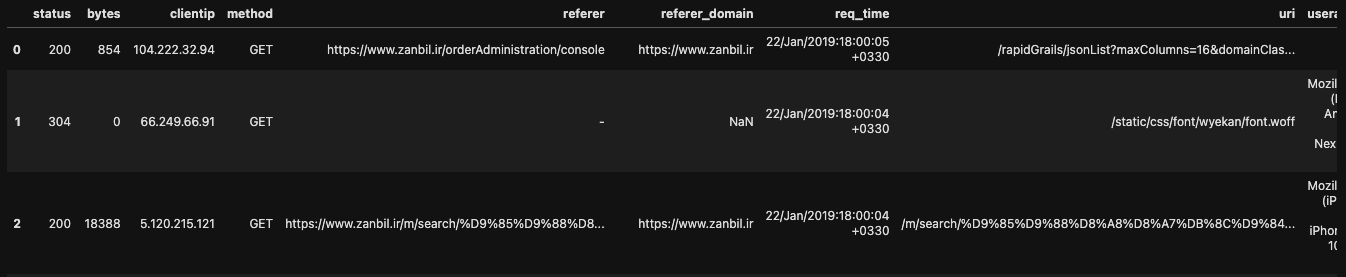
dataset_access_log.shape
dataset_access_log.info()

dataset_access_log.columns

dataset_access_log.isnull().sum()

データのない行を削除する。
dataset_access_log_2 = dataset_access_log.drop(['referer_domain','referer'],axis=1).dropna()
dataset_access_log_2.isnull().sum()

カラムの中から不正アクセスとして認識させる特徴量をピックアップする。
今回は暫定で以下のパラメータから抽出したが、精度についてはご愛嬌部分多目。
dataset_access_log_2['uri_find_%'] = dataset_access_log_2['uri'].str.find('%') + 1 #1
dataset_access_log_2['uri_find_:'] = dataset_access_log_2['uri'].str.find(':') + 1 #2
dataset_access_log_2['uri_count_:'] = dataset_access_log_2['uri'].str.count('\:') #3
dataset_access_log_2['uri_count_('] = dataset_access_log_2['uri'].str.count('\(') #4
dataset_access_log_2['uri_count_;'] = dataset_access_log_2['uri'].str.count(';') #5
dataset_access_log_2['uri_count_%'] = dataset_access_log_2['uri'].str.count('%') #6
dataset_access_log_2['uri_count_/'] = dataset_access_log_2['uri'].str.count('/') #7
dataset_access_log_2['uri_count_'] = dataset_access_log_2['uri'].str.count('\'') #8
dataset_access_log_2['uri_count_<'] = dataset_access_log_2['uri'].str.count('<') #9
dataset_access_log_2['uri_count_?'] = dataset_access_log_2['uri'].str.count('\?') #10
dataset_access_log_2['uri_count_.'] = dataset_access_log_2['uri'].str.count('.') #11
dataset_access_log_2['uri_count_#'] = dataset_access_log_2['uri'].str.count('#') #12
dataset_access_log_2['uri_count_%3d'] = dataset_access_log_2['uri'].str.count('%3d') #13
dataset_access_log_2['uri_count_%2f'] = dataset_access_log_2['uri'].str.count('%2f') #14
dataset_access_log_2['uri_count_%5c'] = dataset_access_log_2['uri'].str.count('%5c') #15
dataset_access_log_2['uri_count_%25'] = dataset_access_log_2['uri'].str.count('%25') #16
dataset_access_log_2['uri_count_%20'] = dataset_access_log_2['uri'].str.count('%20') #17
dataset_access_log_2['uri_azAZ09'] = dataset_access_log_2['uri'].str.replace('[a-zA-Z0-9_]','').str.len() #19
dataset_access_log_2['uri_count_/%'] = dataset_access_log_2['uri'].str.count('/%') #23
dataset_access_log_2['uri_count_//'] = dataset_access_log_2['uri'].str.count('//') #24
dataset_access_log_2['uri_count_./.'] = dataset_access_log_2['uri'].str.count('./.') #25
dataset_access_log_2['uri_count_..'] = dataset_access_log_2['uri'].str.count('..') #26
dataset_access_log_2['uri_count_=/'] = dataset_access_log_2['uri'].str.count('=/') #27
dataset_access_log_2['uri_count_./'] = dataset_access_log_2['uri'].str.count('./') #28
dataset_access_log_2['uri_count_/?'] = dataset_access_log_2['uri'].str.count('/?') #29
dataset_access_log_2['method_POST'] = dataset_access_log_2['method'].str.contains('POST') #18
dataset_access_log_2['method_POST_num'] = dataset_access_log_2['method_POST'].where(dataset_access_log_2['method_POST'] == 1,0) #18
dataset_access_log_2['uri_len'] = dataset_access_log_2['uri'].str.len()
dataset_access_log_2.head()
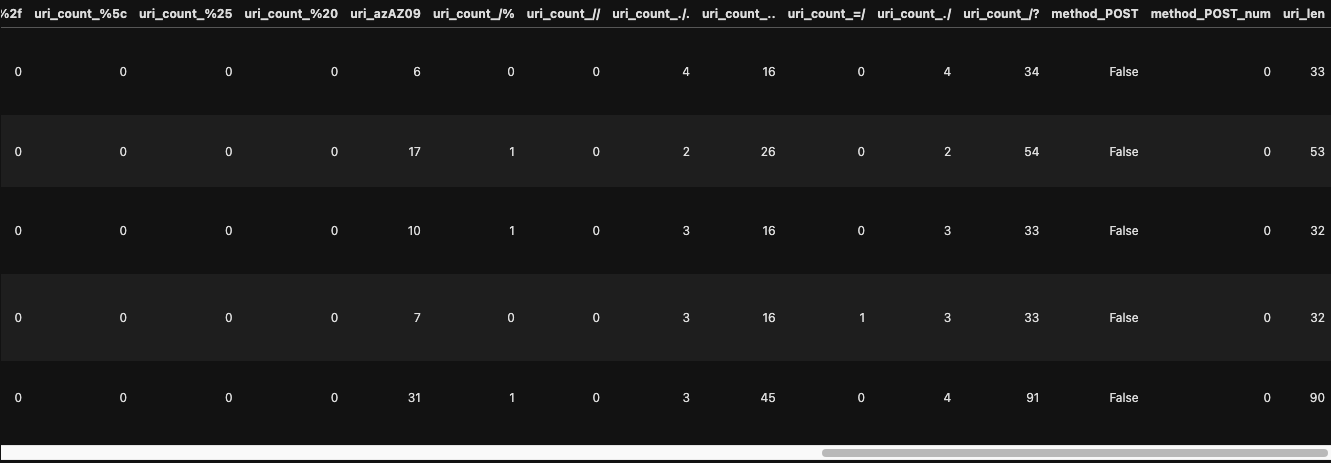
必要なカラムだけピックアップ
dataset_access_log_3 = dataset_access_log_2.drop(dataset_access_log_2.columns[1:8],axis=1)
dataset_access_log_3.head()

"method_POST"が邪魔なので削除
dataset_access_log_4 = dataset_access_log_3.drop(dataset_access_log_3.columns[len(dataset_access_log_3.columns) - 3 ],axis=1)
dataset_access_log_4.head()

再びデータの確認
dataset_access_log_4.info()

"method_POST_num"の型がObjectなのでintに変換
dataset_access_log_5 = dataset_access_log_4.astype({'method_POST_num': 'int64'})
dataset_access_log_5.info()

IsolationForestを用いて異常値を抽出して教師データにする。
clf = IsolationForest(random_state=0).fit_predict(X)
clf

配列(clf)をデータフレームに追加。
負の値があるとKerasでエラーになるので0と1に変換しておく。
dataset_access_log_5['clf'] = clf
dataset_access_log_5.loc[dataset_access_log_5['clf'] < 0, 'clf'] = 0
dataset_access_log_5.head()

csvファイルに出力。
※10文字以下のuriを見てみると、不正アクセスチックなものがほぼないので除外。
dataset = dataset_access_log_5[dataset_access_log_5['uri_len'] >10]
dataset.to_csv('dataset.csv')
以上。
[【次回】:Splunkとkerasを用いた不正アクセス予測検知の仕組み(ディープラーニング構築編)] (https://qiita.com/Uryy/items/104a4e01d386a72dd184)