この記事はPostgreSQLアドベントカレンダーの21日目の記事です。
昨日は @kasa_zip さんの PostgreSQLのバックトレースレポート機能 というPostgreSQLの新機能についての記事でした。
サーバログにバックトレースを残せる機能がPG13で追加されるかもということです。たしかにレアケースを踏んでSEGVになったときは再現が難しいのでこういう機能があると良さそうですね。(まだ、試作段階で用途は少なそうということらしいですが。)
はじめに
突然ですが、autovacuumってちゃんとチューニングしていますか?
正直自分はあまり意識したことがなかったですが、最近、お仕事の中で設定値について考える機会が多かったので、せっかくなので整理してみようと思い、アドベントカレンダーのテーマとして選びました。
裏付けのための検証をもとに [まとめ] (https://qiita.com/U_ikki/private/e9cfc374c473f07436cc#%E3%81%BE%E3%81%A8%E3%82%81) を最後に書いていますので、お忙しいかたはそちらだけでもどうぞ。
この記事に書いていること
- autovacuumのチューニングってどのパラメータって何があるか
- autovacuumのチューニングが必要なケースとその対策案ってどういうのがあるか
- 上記の裏取りとして、不要領域の回収が間に合わないパターンでのチューニングの結果(3パターン実施)
autovacuumとは
簡単に言うと、PostgreSQLが自動でDBのメンテナンスを行うための機能で、必要に応じてVACUUM処理で不要領域を回収し、ANALYZE処理を行い統計情報を最新化を行うことができます。
本記事ではautovacuumによるVACUUM処理についてのみ調査、検証しており、ANALYZE処理については言及していません。
autovacuumの詳細についてはPostgreSQLのマニュアルをご参照ください。
autovacuumの挙動
autovacuumはランチャープロセスとワーカープロセスの2種類で構成されています。それぞれを簡単に説明すると・・・
- autovacuum launcherプロセス
- 稼働統計情報と呼ばれるテーブルの状態(タプル数、不要領域となったタプル数)をチェックして、閾値を超えたテーブルに対してワーカープロセスを起動する。
- autovacuum workerプロセス
- 対象のテーブルに対して、VACUUMやANALYZEを実行する。
ちなみにautovacuum workerプロセスが起動されるための閾値は以下のパラメータで定義されています。
| パラメータ名 | デフォルト値 | 概要 |
|---|---|---|
| autovacuum_vacuum_threshold | 50 | VACUUMを起動するために必要な最低限の不要領域のレコード数 |
| autovacuum_vacuum_scale_factor | 0.2 | VACUUMを起動するために必要な最低限の不要領域のレコードの割合 |
閾値の算出方法はマニュアルの24.1.6. The Autovacuum Daemonに以下のように書かれています。
vacuum threshold = vacuum base threshold + vacuum scale factor * number of tuples
例えば、1000万レコードを持つテーブルの場合は、デフォルトでの閾値は50+1000万*0.2=200万50レコードとなります。
つまり、UPDATEやDELETEで200万50レコードが発生したテーブルがautovacummのVACUUM処理の対象となります。
動作制御
続いて、autovacuumが動作したときの制御に関するパラメータについて簡単に紹介します。
| パラメータ名 | デフォルト値 | 概要 |
|---|---|---|
| autovacuum_max_workers | 3 | 同時に実行することができるautovacuum worker のプロセス数(デフォルトでは最大3並列でVACUUM処理が可能) |
| autovacuum_vacuum_cost_delay | 20ms | autovacuumによるVACUUM処理のsleep時間(値が大きいほどゆっくりVACUUMする) |
| autovacuum_vacuum_cost_limit | 200 | autovacuumが次のsleepまでに処理する処理量(値が大きいほどsleepまでにたくさんのレコードをVACUUMする) |
(2021/9/14追記)
PostgreSQL 12以降はデフォルト値が変わり autovacuum_vacuum_cost_delay = 2ms となっている。
動作制御に関連するパラメータ
autovacuumの動作制御に使用されているautovacuum_vacuum_cost_delayのコストとはなんなのか?気になりますよね。
autovacuumのコストは以下のGUCパラメータで定義されており、これが徐々に加算され200になったタイミングでdelay時間分sleepするという挙動になります。
特に注意しないといけないのが、このコストはグローバルな値であるということです。複数のautovacuum workerプロセスがいた場合、全員でコストを分け合って処理していることになります。つまり、プロセス数を増やすと一つのプロセスあたりのlimit_costが減ってしまう点に気をつけてください。
| パラメータ名 | デフォルト値 | 概要 |
|---|---|---|
| vacuum_cost_page_hit | 1 | VACUUM対象のレコード(ページ)をバッファから読み出す場合に加算されるコスト |
| vacuum_cost_page_miss | 10 | VACUUM対象がフラッシュ済みでディスク(またはOSキャッシュ)から読み出す場合に加算されるコスト |
| vacuum_cost_page_dirty | 20 | クリーンにしたページをVACUUMで変更し、そのダーティなページをディスクに書き出すときに加算されるコスト |
独り言:上の2つはわかるけど、最後のやつって具体的にどんなページなのかわからない。(誰か教えてほしいです。)
余談
ここでパラメータから毎秒あたりのVACUUM処理量について算出してみます。
autovacuum_vacuum_cost_delayはデフォルトで「20ms」となっています。つまり、MAXで1秒間に50ループ分のVACUUM処理が動ける計算になります。ループって言っちゃうとわかりづらいので、コスト換算で表現すると「10000コスト/sec」となります。
で、さらにこれをページに換算してみると・・・
- 全てのVACUUM対象がバッファ上(vacuum_cost_page_hit)にある場合
- 10000ページ/sec → 80MB/sec
- 全てのVACUUM対象がフラッシュ済み(vacuum_cost_page_miss)の場合
- 1000ページ/sec → 8MB/sec
- 全てのVACUUM対象を書き出す(vacuum_cost_page_hit)場合
- 500ページ/sec → 4MB/sec
※ただし、上記は値は実際にVACUUM処理が行われる時間は含んでいないので、実際の単位時間あたりの処理量は下がると考えられます。
本題:どうやってチューニングしていけば良いか?
- チューニングのゴール
- autovacuumの負荷がシステムに影響を与えない
- autovacuumを十分に行い、不要領域を増加させない
だと定義します。
また、ゴールの前者については後者の裏返しな面でもあるので、ここでは「autovacuumを十分に行い、不要領域を増加させない」ためにどうするかを考えていきます。
なお、基本的にチューニング対象とするのは、上記であげた「autovacuumの閾値」と「動作制御」としてます。コスト値を定義する部分は触らないほうが無難かと思います。(どうチューニングするのが正解かもわからないし)
考えられる「autovacuumが十分にできず不要領域が増加する」ためのチューニング
チューニングを行うために、そもそもどういうケースに問題が起きるのか、その問題を解決するためにはどうチューニングしたら良いかという観点で考えてみます。
- autovacuumが十分にできていないパターン
- ケース1:閾値に到達せず、VACUUM処理されない
- ケース2:閾値に到達するが、不要領域の発生量がVACUUMの処理量を上回っている
- ケース2-1:特定のテーブルで不要領域の発生量が多く、常時VACUUM処理が実行されているが不要領域の回収が間に合っていない
- ケース2-2:VACUUM対象のテーブルが多く、autovacuum workerプロセスが上限に達して、VACUUM処理が実施されない
- ケース3:ロングトランザクションがいて、VACUUMが実行できない
ケース1:閾値に到達せず、VACUUM処理されない
この問題は主にテーブルのレコード数が膨大であり、レコード数に対して更新量が少ない場合に発生する可能性があります。
この事象を解決するには、前述のautovacuumによるVACUUM処理の閾値を下げる必要があります。具体的にはscale factorの値を「0」にしてthresholdの値で制御する方法が考えられます。
vacuum threshold = vacuum base threshold + vacuum scale factor * number of tuples
ケース2:閾値に到達するが、不要領域の発生量がVACUUMの処理量を上回っている
処理が間に合わないケースについてはさらに細分化して考えることができます。
ケース2-1:テーブルでの更新が多く、常時VACUUM処理が実行されているが不要領域が増えている
単純に不要領域の発生量 > VACUUMによる回収量というケースです。
この事象を解決するには、
autovacuum_vacuum_cost_delay, autovacuum_vacuum_cost_limitをチューニングする必要があります。
リソースに余裕があれば、autovacuum_vacuum_cost_delayを小さくし、autovacuum_vacuum_cost_limitの値を増やすことで解決できる可能性があります。
注意:本事象はautovacuum_max_workersを増やしても解決できないので気をつけてください。
手元の環境での結果ですが、本件について検証したので良ければ後述の結果をご確認ください。
ケース2-2:VACUUM対象のテーブルが多く、autovacuum workerプロセスが上限に達して、VACUUM処理が実施されない
このケースでは、プロセス数が少ないことが最初に解決すべき問題なので、まずはautovacuum_max_workersを増やしてください。
ケース3:ロングトランザクションがいて、VACUUMが実行できない
ロングトランザクションを止めて、VACUUMしてください。
特にチューニング要素はなく、言うことは特に無いので本書では割愛します。
実機検証:case2-1はmax_workersを増やしても解消しないのか?
-
検証環境
- VirtualBox CentOS 7
- PostgreSQL 11.6
-
実施概要
- pgbenchで負荷を掛け、不要領域を大量に発生させる(敢えてautovacuumが間に合わないような負荷を掛けています)
- 以下のパターンでn_dead_tupの量の傾向を比較する
| 測定パターン | autovacuum_max_workers | autovacuum_vacuum_cost_limit | autovacuum_vacuum_cost_delay |
|---|---|---|---|
| pattern01 | 1 | 200 | 20ms |
| pattern02 | 3 | 200 | 20ms |
| pattern03 | 1 | 2000 | 20ms |
結果
不要領域の回収が間に合わない場合、autovacuum_max_workersを増やしただけでは解決しません!
ベースラインが青線の状態なのですが、worker数を増やした結果がオレンジの線です。
見てわかるとおり、プロセス数を増やしても不要領域(縦軸)はグイグイ伸びちゃっています。なんなら若干悪化しちゃっている状態になっています。チューニングしたつもりがまさかの悪化するパターンですね。
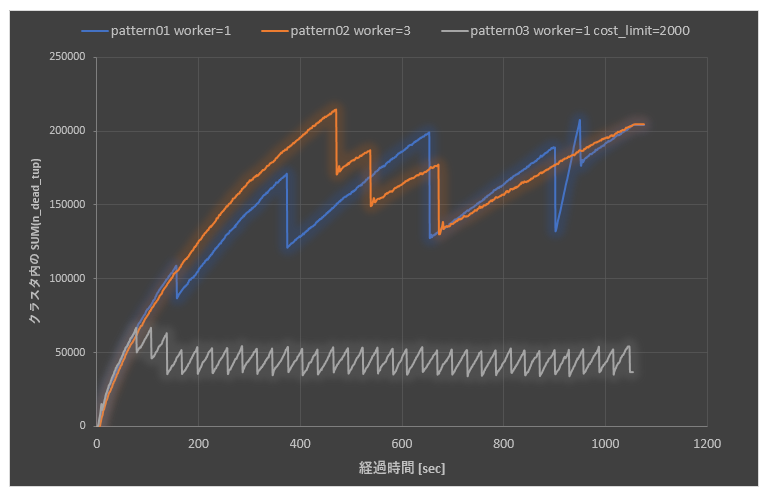
ここでお気づきの方がいるかもしれませんが、pattern01(青)とpattern02(オレンジ)で最初に不要領域が減るタイミングズレているところに注目してみてください。パラメータの説明でcost_limitはworker数で均等に分けられることについてお話しました。つまり、pattern01だと1プロセスで200cost分をone cycleで処理していましたが、pattern02だと3プロセスなので、およそ68costがone cycleになっています。(つまり、処理速度が1/3ぐらいになっているということです。)
ちなみに今回はautovacuum_vacuum_cost_limitを変えてVACUUMの処理量を上げていますが、処理量が増えるということは当然リソースへの負荷が上がるので、注意してください。
以降では、チューニングの結果として、リソースの負荷に変化があったかについても確認してみます。
CPU usage
左側:pattern01 (worker=1 limit=200)
右側:pattern03 (worker=1 limit=2000)
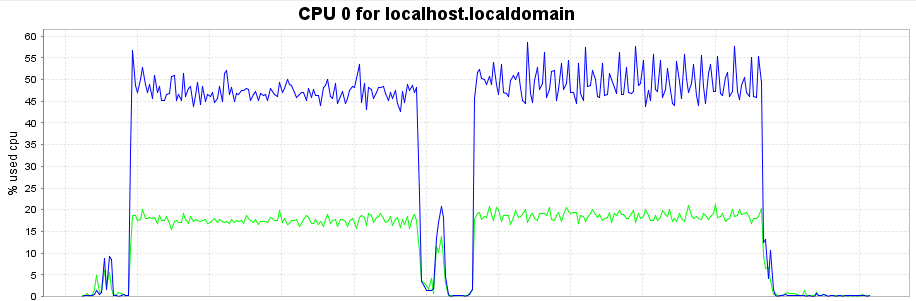
青:user 緑:system
僅か数%の範囲ですが、チューニングによる影響が見えますが。
ただ、特筆して言うような違いでもないのでスルー。
ディスクIO
左側:pattern01 (worker=1 limit=200)
右側:pattern03 (worker=1 limit=2000)
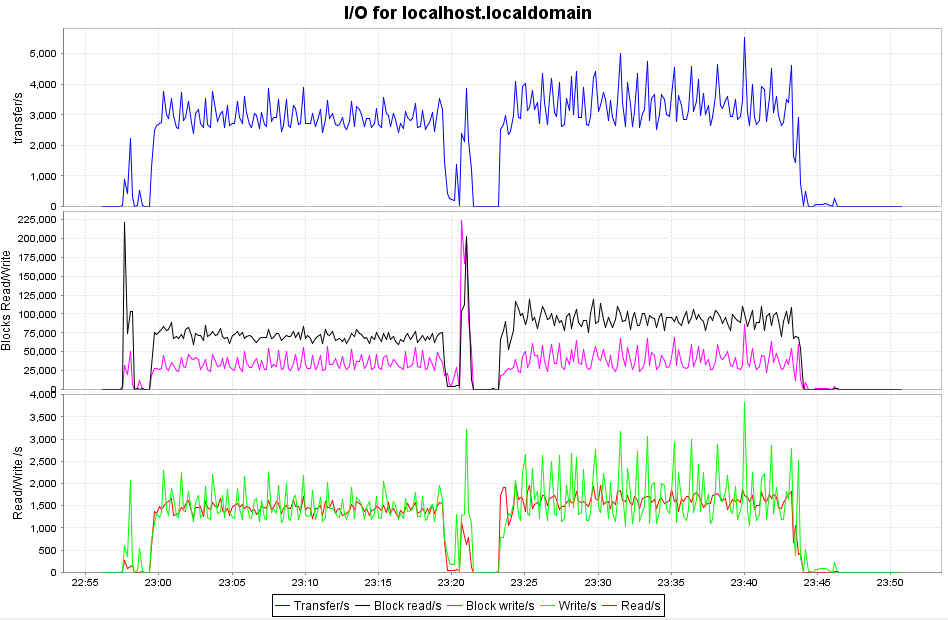
こちらはチューニングによる影響がしっかりと見えています。
VACUUMはそもそもIOが発生する処理なので、その処理量を上げたら、当然IO負荷が上がっています。特にReadは今回の結果だと、25%ぐらい上がっているようですね。Writeも10%くらいは増えてそう。
まとめ
- 不要領域の回収が間に合っていない場合、autovacuum workerプロセスの最大数だけ増やしても効果はない。むしろ逆効果になることもある。
- autovacuum_vacuum_cost_limitのデフォルトはかなり小さい値なので、常時更新が多く発生するようなシステムでは回収に問題がないかチェックすること。
- チューニングしてVACUUMの処理量を増やすとリソースに影響(特にディスクIO)が出てしまう。(今回の結果ではIOが10%ぐらい増)
さいごに
さらっとチューニングの考え方だけ書いて終わるつもりが無駄に長くなってしまいました。(誰かの役に立てば良いな。)
あと、最近周回防止VACUUM周りをやたら見る機会があるので、今度記事にまとめてみようと思います。
時間が足りずダッシュで書いているので、嘘を書いている箇所があったらごめんなさい。気づいたことがあれば、指摘してもらえると助かります。
さて、明日は@nuko_yokohamaさんの記事です。ラーメンネタ楽しみですね。