はじめに
株式会社estieでオフィス募集データのパイプラインを構築するチームのソフトウェアエンジニア兼Product Ownerをしております、平田です!
今回は Calendar for estie Advent Calendar 2021 | Advent Calendar 2021 - Qiita 12日目の記事としてVision and Languageの汎用モデルとして有名なCLIPの概要の説明をしたのち、estieが扱っているような不動産画像に対してCLIPを適用してみたいと思います。
CLIPとは?
CLIPはLearning Transferable Visual Models From Natural Language Supervision(以下、アルゴリズムの説明に使った画像はこちらから引用しています)というOpenAIから発表された論文で紹介された手法で、特定のタスクに特化していない汎用的な画像とテキストの表現を学習し、さまざまなタスクに適応できることを示しました。簡単にCLIPの論文について紹介していきます。(論文の詳細に興味のない方は読み飛ばしてください)
背景
多くのState-of-the-artを達成している画像認識モデルはラベルの付けられた教師ありデータセットを用いて学習され、そのデータセット✖️タスクにおいて突出した結果を出しています。しかしそれらのモデルを他のデータセットやタスクに用いるには、そのタスクに適した教師データつきのデータセットを新たに用意する必要があり、汎用性にかけていました。
手法
CLIPは汎用性のあるモデルを構築するためにウェブから得た大量の画像とキャプションのペアを教師データとしてpre-trainingを行います。
画像とテキストをそれぞれImage EncoderとText Encoderに入力し、(batch size, hidden tensor size)のテンソルを出力します。
画像特徴とテキスト特徴は内積(実際には特徴はそれぞれNormalizeされているのでcos similarity)を計算し、ペアである画像とテキストについて内積が大きくなり、ペアではない特徴同士の内積は小さくなるようにCrossEntropyLossを用いて学習します。
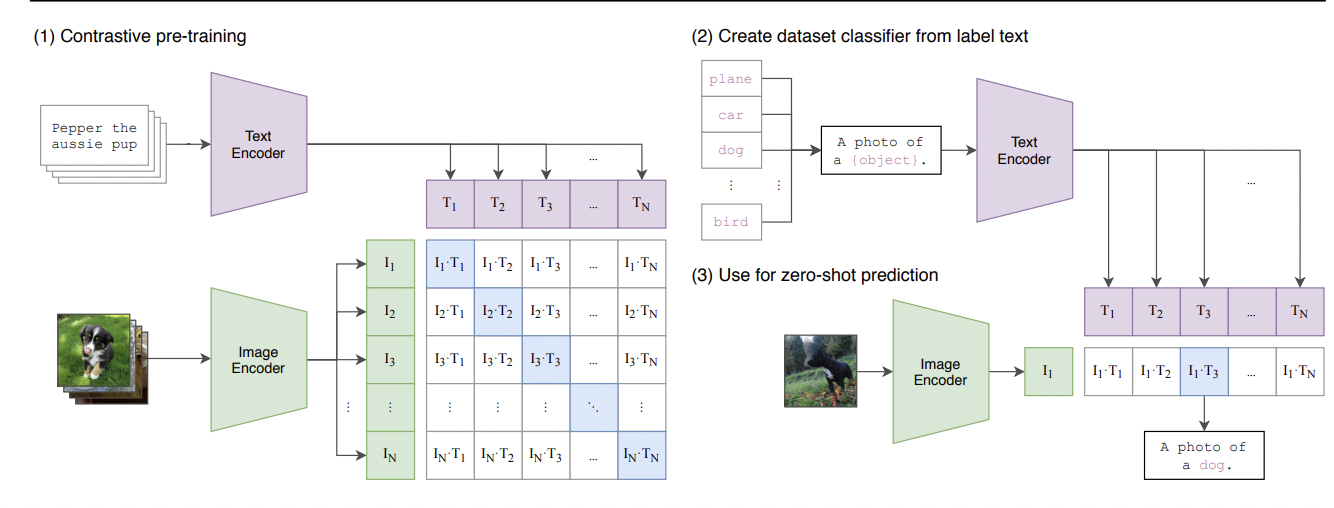
pre-trainされたモデルを特定のタスクに用いる場合にはCLIPの画像特徴とテキスト特徴を用いる判別器を学習させるか、上の図表にあるように"A photo of a {object}"といった特定の形式のテキスト入力に整形してzero-shot predictionを行います。
実験
30を超える画像系のデータセットで実験した結果、CLIPを用いた予測はzero-shot predictionであっても教師あり学習で学習させたモデルと同程度の結果を出すことを示しました。
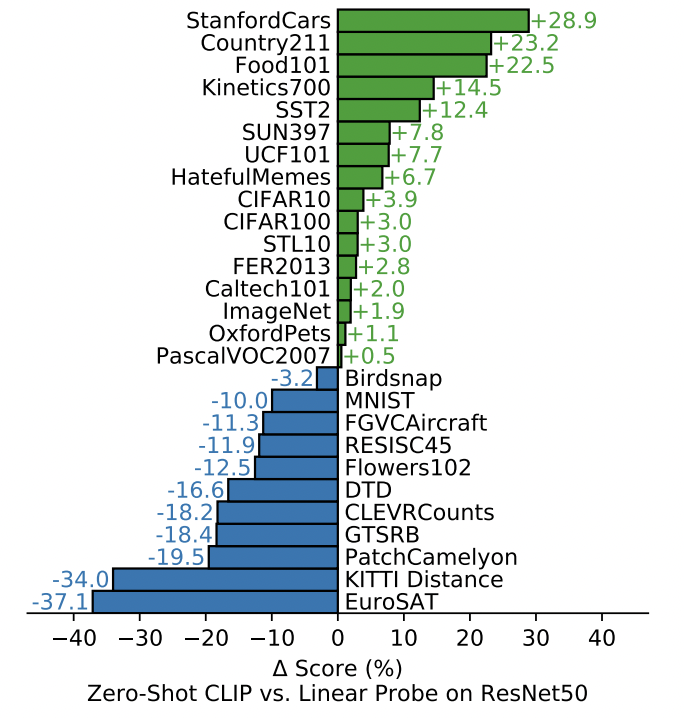
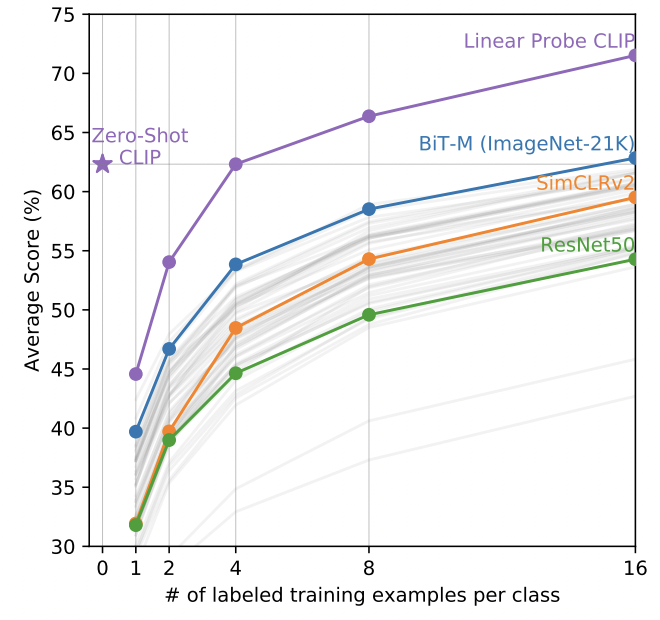
不動産画像に使ってみる
さて、とてつもない結果を示しているCLIPを実際に使ってみましょう。CLIPの実装や学習済みモデルは公式のGithubかHugging Face Transformersで公開されています。
今回は後者を使っていきます。まずTransformersのドキュメントにあるようにモデルを準備します。
from PIL import Image
import requests
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
簡単ですね。
estieではestie proという不動産事業者向けのオフィス情報プラットフォームを提供しています。estie proでは個別のオフィスビルの画像も扱っているのですが、不動産データは整備されていない部分も多く、用途の異なるビルの画像が含まれていたり、内観と外観の画像が混ざってしまっていたりします。今回はCLIPを用いてこうした画像のzero-shotでの分類を行なっていきます。
建物用途の判別
office_image_url = "http://path/to/office image"
shopping_mall_image_url = "http://path/to/shopping mall image"
house_image_url = "http://path/to/house image"
selection = ["a photo of an office building", "a photo of a shopping mall", "a photo of a house"]
for url in (office_image_url, shopping_mall_image_url, house_image_url):
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
inputs = processor(text=selection, images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
probs = logits_per_image.softmax(dim=1)
print(selection[probs.argmax()])

>>> probs
tensor([[0.9950, 0.0038, 0.0012]])
>>> selection[probs.argmax()]
a photo of an office building

>>> probs
tensor([[0.1162, 0.8814, 0.0025]])
>>> selection[probs.argmax()]
a photo of a shopping mall

>>> probs
tensor([[0.2214, 0.0015, 0.7771]])
>>> selection[probs.argmax()]
a photo of a house
うまく判別できていそうですね。
建物の内装・外装の判別
上記と同様に建物の内観(inside)か外観(appearance)か判別していきます。
inside_url = "http://path/to/inside image"
appearance_url = "http://path/to/appearance image"
selection = ["a photo of the inside", "a photo of the appearance"]
for url in (inside_url, appearance_url):
image = Image.open(requests.get(url, stream=True).raw).convert('RGB')
inputs = processor(text=selection, images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
probs = logits_per_image.softmax(dim=1)
print(selection[probs.argmax()])

>>> selection[probs.argmax()]
a photo of the inside
>>> selection[probs.argmax()]
a photo of the appearance
こちらも上手く判別できていそうです。
更に知りたい方は
まずはぜひ、元の論文を読んでみてください。
また、同じような課題を解決しようとしているViLBERTやViLTを読まれたりすると理解が深まるかもしれません。実装詳細については少し複雑ですがソースコードが公開されているので見てみて下さい。
終わりに
estieは不動産業界をアップデートするために目立たない部分で多くの技術的な難しさに立ち向かっています。事業が拡大する中、解決しなければいけない問題も多く、データ・機械学習エンジニアを求めています。
興味持っていただいた方はぜひお話しましょう!
https://jobs.estie.jp/
参考
Learning Transferable Visual Models From Natural Language Supervision
https://huggingface.co/transformers/model_doc/clip.html