1. 概要
突然ですが私は体験型のアクティビティーが大好きです。サーフィン体験をしたり、屋久杉を見に行ったり、スノードームを作ったり、香水を調製してみたり、、、。
そんな私が食べログの情報から機械学習でラーメンレコメンドをする記事をみて、これのアクティビティー版をやったら面白いのでは!!と考えました笑
アクティビティーを探すとき、人は3ステップの思考フローを辿るのではないかと思います。
- 「ストレスが溜まっているからスカッとしたい」など休みへの想いを考える
- 「スカッとするためにはバンジージャンプだな」等、過ごし方を考える
- アクティビティーを探して予約する
この思考フローの中で、1→2への移行にはその人各々のクリエイティブさ(?)が求められていると感じます。もちろん「バンジーしてみたい」などのやることありきで予定を立てることも少なくないですが、「スッキリしたい」などの休日への想いから、「そのためには△△っていうアクティビティーがいいよね」という過ごし方を考え出すことは想像力と創造力を必要とする作業だと思います。
事実、私がこういう体験してきたよーという話を友人にすると、「よくそんなの見つけたね」って言われることも少なくありません笑
そこで、機械学習を用いて休日への想いをアクティビティーという形にすることを目指していきたいと思います!
口コミ情報を学習し、「スッキリしたい」という想いを入力したら「それなら〇〇っていうアクティビティーがオススメだよ」と教えてくれるモデルを構築していきたいです!!
今回はそのための学習データ集めです。
体験型アクティビティーを調べたり、予約したりするサイトとしてはアソビュー!が有名なのではないかと思います。調べた限りアソビュー!を用いてのスクレイピングを行なっている記事は見当たらなかったので挑戦してみようと思います!
拙いコードですがご容赦ください🙇♂️
(追記)
完成したアプリはこちら
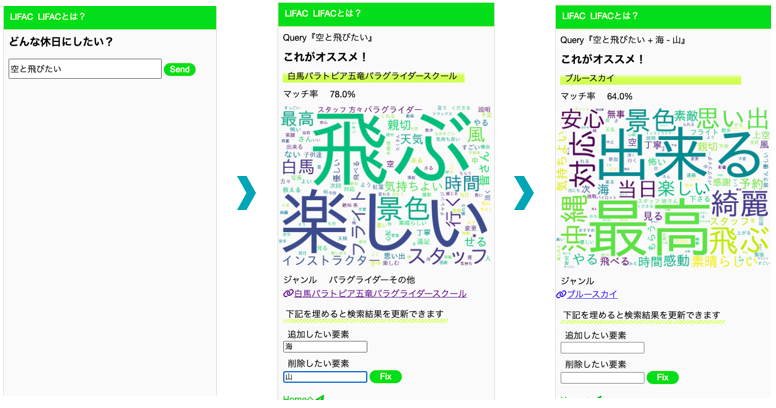
例えば「空を飛びたい」とき(検索後に海要素を足して、山要素を引くこともできます!!)
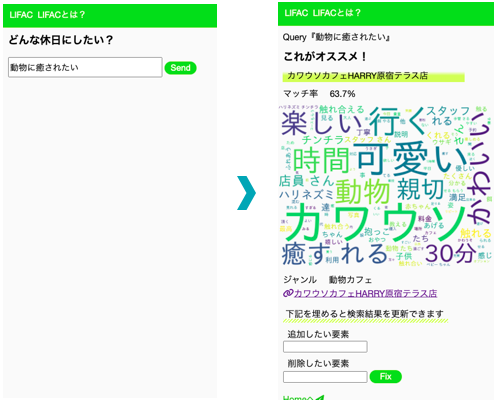
例えば「動物に癒されたい」とき
第1回:本記事
第2回:第2回 【Python】まだ見ぬアクティビティーを求めてアソビュー !分析
第3回: 第3回 【Python】まだ見ぬアクティビティーを求めてアソビュー !口コミ スクレイピング
第4回: 第4回 【Python】まだ見ぬアクティビティーを求めてアソビュー !機械学習(Doc2Vec)
第5回:第5回 【Python】まだ見ぬアクティビティーを求めてアソビュー !Doc2Vecモデルチューニング
2. アソビュー!のHPを散歩する
まずはアソビュー!の中でアクティビティー情報がどのように掲載されているかを確認します。
例えば我らが埼玉の誇るムーミンバレーパークならこんな感じです。

黄色い丸で囲んだ部分に施設名やレビュー、施設所在地やジャンル(この場合は遊園地・テーマパーク)が書かれていることがわかります。ジャンルにはパラグライダーやアスレチック、お香作りなどなど実に様々なものが含まれています。後ほどこれらの情報のスクレイピングを試みます。
このページのURLは
https://www.asoview.com/base/156897/
であり、
他には茶道教室であれば、https://www.asoview.com/base/155331/
パラグライダーであれば、https://www.asoview.com/base/960/
となっています。
各施設毎に
https://www.asoview.com/base/<<施設固有の番号>>/
となっていることがわかるので、<<施設固有の番号>>を変えていきながらスクレイピングしたいと思います。
ここで、この<<施設固有の番号>>がどのようなルールでつけられているのか調べるのに苦戦してしまいました😅
6もあるかと思えば155331もあり、1桁から6桁までかなり幅があります。なにかのルールに基づいて数字がつけられているのかとホームページ内を徘徊してみましたが、結局ルールは見つけられませんでした、、、
かといって1~999999まで数字を変えながらアクセスしたら大変なことになってしまうので、困ったなあと思っていたら、、、見つけました!こちらに施設一覧がまとまっているではないですか!!

このページから各施設固有の番号を抽出していこうと思います!!
3. 施設の一覧を抽出する
まずは先ほどのサイトから<<施設固有の番号>>(以後アクテビティーNo.と呼びます)を取得してみます。
サイト上で右クリック>検証とすると、

そのサイトがHTMLでどのように書かれているのかを見ることができます。さらに、こちらから要素ごとにサイトの構造を確認できます。


まずはこのaタブから全アクテビティーNo.を取得します。
必要なもののインポート
import requests
from bs4 import BeautifulSoup
import re
requestsを用いることでHTMLを取得でき、そのHTMLをBeautifulSoupで解析します。
url= "https://www.asoview.com/base/"
n_list = [] #アクティビティーNo.をこのリストの中にいれていく
res = requests.get(url) #HTMLの取得
soup = BeautifulSoup(res.text, "html.parser") #BeautifulSoupに渡す
links = soup.find_all("a", class_="page-base__base-link") #classが"page-base__base-link"である全aタブ
n_list = [int(re.sub("\D*", "", link.get('href'))) for link in links]
link.get('href')でaタブ中のhrefを取得し、正規表現で数字のみ抜き出しました。
print(n_list)で中身を確認すると、
[163, 178, 191, 232, 260, 261, 263, 264, 281, 314, .....]
とアクテビティーNo.がしっかり取得できました。len(n_list)からアクテビティーの掲載数は8786であることが分かります。このn_listを使って各アクテビティーの基本情報を取得していきます。
4. 各アクティビティーの基本情報
アクテビティーNo.155331の茶道教室のページを見てみると、

施設名、評価/評価数、所在地>詳細な所在地、アクテビティーのジャンル、施設についての説明文が掲載されているので、それぞれのアクテビティー毎にこれらの情報を取得し、1つのファイルにまとめていきます。
足りないものをインポートして、
import time
import pandas as pd
取得した情報を追加していくためのからのDataFrameを作ります。
#DataFrameを作る
columns = ["name", "area", "small_area", "genre_type", "rating_star", "rating_asorepo", "introduction_title", "introduction_text", "No.", "url", "review_link"]
df = pd.DataFrame(index=[], columns=columns)
https://www.asoview.com/base/<アクテビティーNo.>/のリンクや口コミページへのリンクも一緒に取得しておきます。
アクティビティーNo.を取得した時と同様に、例えば、施設の名前であれば、h1タグのclassが"base-name"となっていることが分かります。

したがって、soup.find("h1", class_="base-name").textとすることで施設名を入手できます。
このようにして、他の値も入手していきます。
for n in n_list: #各アクテビティーNo.毎
try:
url = f"https://www.asoview.com/base/{n}/"
res = requests.get(url)
soup = BeautifulSoup(res.content, "html.parser")
time.sleep(1)
res.raise_for_status()
print(f'No.{n}はURLが存在する')
base_name = soup.find("h1", class_="base-name").text #店の名前
base_data = soup.find("div", id="base-summary-contents")
base_data_area = base_data.find("span", class_="base-data__area").text #場所
base_data_small_area = base_data.find("span", class_="base-data__small-area").text #詳細な場所
#ジャンルは複数あることもある
base_data_genre_type = base_data.find_all("li", class_="base-data__genre-type") #ジャンル
base_data_genre_type_list = list(i.text for i in base_data_genre_type)
review_link = base_data.find("a").get("href") #レビューリンク
#レーティング
base_data_rating = base_data.find("i", class_="base-data__rating")
base_data_rating_star = float(base_data_rating.contents[3].text) #星の数
base_data_rating_asorepo = int(int(base_data_rating.contents[5].text.replace(",", ""))) #レビュー数
introduction_text_title = soup.find("b", class_="introduction__text-title").text #イントロのタイトル
introduction_text = soup.find("p", class_="introduction__text").text #イントロダクション
#追加用のdf
df_new = pd.DataFrame([[base_name, base_data_area, base_data_small_area, base_data_genre_type_list, base_data_rating_star, base_data_rating_asorepo, introduction_text_title, introduction_text, n, url, review_link]],
columns=columns)
#dfに追加
df = pd.concat([df, df_new], axis=0)
count+=1
#100個ごとに保存する
if count%100 == 0:
df.to_csv(f'base_data_{count}.csv')
print("実行時間:", time.time() - start)
print("進捗率:", str((count/len(n_list))*100), "%")
time.sleep(10)
except requests.exceptions.HTTPError as e: #例外処理
print("HTTPError:", e)
continue
except requests.exceptions.ConnectionError as e:
print("ConnectionError:", e)
continue
except:
print("エラー")
continue
アクテビティーNo.を取得したときと同じ要領でサイトの要素を確認し、1つずつ取得していきました。
df.head()で取得したdfを見てみると、
| name | area | small_area | genre_type | rating_star | rating_asorepo | introduction_title | introduction_text | No. | url | review_link | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ガイドラインアウトドアクラブ | 北海道 | 富良野・美瑛・トマム | ['ラフティング'] | 5.0 | 7 | 3歳からOKのラフティング!川を全身で遊ぼう!自然を満喫しよう☆ | 南富良野にある水の綺麗な「シーソラプチ川」と「空知川源流部」にてラフティングを開催。全ツアー... | 163 | 省略 | /base/163/asorepo/list/ |
| 1 | 洞爺ガイドセンター | 北海道 | 洞爺・登別・苫小牧 | ['レイクカヌー', 'エコツアー・自然体験', 'スノーシュー・スノートレッキング'] | 0.0 | 1 | 美しい洞爺湖を満喫。「旬なプラン」をご提供します! | 北海道・洞爺湖で、自然体験アクティビティを開催している洞爺ガイドセンター。美しい自然をご案内... | 178 | 省略 | /base/178/asorepo/list/ |
| 2 | 函館どさんこファーム | 北海道 | 函館・大沼・松前 | ['乗馬 その他'] | 0.0 | 3 | どさんこと触れあう函館の旅!函館空港・函館駅から車で20分! | 函館どさんこファームは函館空港・函館駅から20分と、アクセス抜群・好立地の乗馬クラブです。... | 191 | 省略 | /base/191/asorepo/list/ |
| 3 | リバートリップ北海道 | 北海道 | 洞爺・登別・苫小牧 | ['ラフティング'] | 0.0 | 2 | 女子会プランも大好評!北海道最高峰の激流・鵡川で本格ラフティング! | リバートリップは、北海道最高峰と言われている鵡川で、本格的な激流ラフティングをご提供していま... | 232 | 省略 | /base/232/asorepo/list/ |
| 4 | 知床サイクリングサポート | 北海道 | 網走・北見・知床 | ['マウンテンバイク(MTB)・ダウンヒル'] | 0.0 | 2 | ベテランガイドがご案内!知床を肌で感じるネイチャーサイクリングツアー! | 知床サイクリングサポートは、世界自然遺産に選ばれた北海道・知床半島を中心に、マウンテンバイク... | 260 | 省略 | /base/260/asorepo/list/ |
といい感じにデータを取得できました!
最後にこれを保存します。
df.to_csv('base_data.csv')
5. まとめ
アソビュー!のホームページから各アクティビティーの基本情報を取得することができました。
次回は取得した情報を使って、アソビューにどんな施設が掲載されているのかを調べていこうと思います。
次回
第1回:本記事
第2回:第2回 【Python】まだ見ぬアクティビティーを求めてアソビュー !分析
第3回: 第3回 【Python】まだ見ぬアクティビティーを求めてアソビュー !口コミ スクレイピング
第4回: 第4回 【Python】まだ見ぬアクティビティーを求めてアソビュー !機械学習(Doc2Vec)
第5回:第5回 【Python】まだ見ぬアクティビティーを求めてアソビュー !Doc2Vecモデルチューニング