1. 概要
この記事は第3回の続きです。
第3回ではアクティビティー予約サイト「アソビュー!」から各アクティビティー施設の口コミをスクレイピングしました。
休日への想いをアクティビティーという形にするという目的を達成するため、今回は口コミデータを使って、アクティビティーをレコメンドしてくれるモデルを構築していきたいと思います。
完成したものはこちら↓
例えば「空を飛びたい」とき(検索後に海要素を足して、山要素を引くこともできます!!)
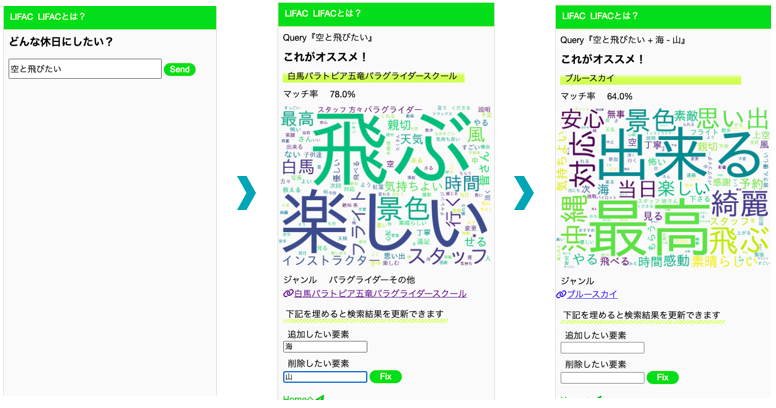
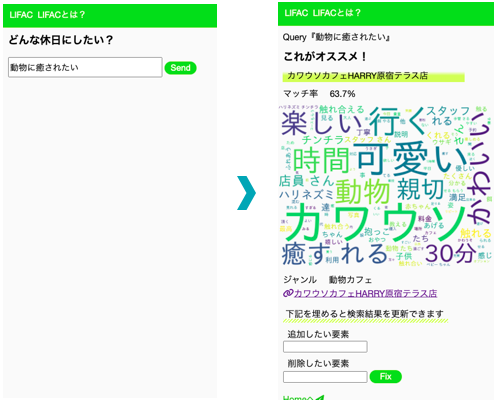
例えば「動物に癒されたい」とき
第1回:【Python】まだ見ぬアクティビティーを求めてアソビュー !スクレイピング
第2回:第2回 【Python】まだ見ぬアクティビティーを求めてアソビュー !分析
第3回: 第3回 【Python】まだ見ぬアクティビティーを求めてアソビュー !口コミ スクレイピング
第4回:本記事
第5回:第5回 【Python】まだ見ぬアクティビティーを求めてアソビュー !Doc2Vecモデルチューニング
2. 学習手法
今回はDoc2Vecという手法を用いて、モデルを作っていきます。
Doc2Vecやその親戚(?)のWord2Vecについて大変わかりやすく説明されている動画があるので、詳しくはそちらを参照いただければと思います。
Doc2Vecとは文章をベクトル表現する技術です。それぞれの文章に対して固定長のベクトルを与えることで、文章ごとの類似度を計算することができます!
今回はこのDoc2Vecを用いて、「こんな休日を過ごしたい!」という想いとの類似度の高いアクティビティーを探せるようにしていきます!!
3. モデル構築の前準備
今回のモデル構築では形態素解析にMecabを用います。
形態素解析(morphological analysis)とは、検索エンジンなどにも用いられている自然言語処理(NLP)の手法の一つです。
ある文章・フレーズを「意味を持つ最小限の単位」に分解して、文章やフレーズの内容を判断するために用いられます。
出典: https://aiacademy.jp/media/?p=3009
そのため、まずはMecabをインストールする必要があります。インストール方法については下記リンクが参考になります。
4. モデル構築
下準備
まずは必要なものをインポートします。
import numpy as np
import pandas as pd
import MeCab
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
今回はGensimというオープンソースライブラリを用いてモデル構築を行なっていきます。コードは引き続きこちらを参考にさせていただきました。
まずはテキストの分かち書きを試してみます。
わかち書き(わかちがき)とは、文章において語の区切りに空白を挟んで記述することである。
出典:https://ja.wikipedia.org/wiki/%E3%82%8F%E3%81%8B%E3%81%A1%E6%9B%B8%E3%81%8D
#タグはMeCab.Tagger(neologd辞書)を使用
tagger = MeCab.Tagger('-Owakati -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')
nodes = tagger.parseToNode('国境の長いトンネルを抜けると雪国であった。')
while nodes:
print(nodes.surface)
print(nodes.feature)
nodes = nodes.next
BOS/EOS,*,*,*,*,*,*,*,*
国境
名詞,一般,*,*,*,*,国境,コッキョウ,コッキョー
の
助詞,格助詞,一般,*,*,*,の,ノ,ノ
長い
形容詞,自立,*,*,形容詞・アウオ段,基本形,長い,ナガイ,ナガイ
トンネル
名詞,一般,*,*,*,*,トンネル,トンネル,トンネル
を
助詞,格助詞,一般,*,*,*,を,ヲ,ヲ
抜ける
動詞,自立,*,*,一段,基本形,抜ける,ヌケル,ヌケル
と
助詞,接続助詞,*,*,*,*,と,ト,ト
雪国
名詞,一般,*,*,*,*,雪国,ユキグニ,ユキグニ
で
助動詞,*,*,*,特殊・ダ,連用形,だ,デ,デ
あっ
助動詞,*,*,*,五段・ラ行アル,連用タ接続,ある,アッ,アッ
た
助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
。
記号,句点,*,*,*,*,。,。,。
国境の長いトンネルを抜けると雪国であった。という文章をしっかり単語ごとに分解することができました!口コミでも同じことをしたいので分かち書きする関数を作ります。
def tokenize_ja(text):
node = tagger.parseToNode(text)
while node:
if node.feature.split(',')[0] in ["名詞","形容詞","形容動詞","動詞"]:#分かち書きで取得する品詞を指定
yield node.surface.lower() #単語を出力
node = node.next
分かち書きした口コミを1つのリストにする関数も作ります。
def tokenize(content):
token = [token for token in tokenize_ja(content)]
return token
データの整理
学習させるデータの方も用意していきます。第1回で取得したアクティビティー施設の基本情報、および第3回で取得した各アクティビティー施設の口コミを使っていきます。
df_base_data = pd.read_csv('base_data.csv', index_col=0)
df_review_all = pd.read_csv('df_review_all.csv', index_col=0)
df_review_all.head()
No. date star comment
0 163 2022-08-29 5.0 とっても楽しかったです。\n川の水は冷たかったけれど、その分澄んでいて、景色も綺麗で感動しま...
1 163 2022-08-06 5.0 仲の良いご夫婦、ずっと笑顔でのガイド有難うございました。\n地元話とか、もっとお聞かせ頂きた...
2 163 2022-08-04 5.0 大自然の中ゆったりと流れる川を眺めながらボートにやられるのはとても気持ちよく、なだらかなコー...
3 163 2020-10-12 5.0 昨日は大変お世話になり\nありがとうございました😊\n\n参加した皆、ラフティング初体験で\...
4 163 2020-10-10 4.0 楽しかったでーす^_^\n来年は、水量の多い時期に行きたいです😄
df_review_allの口コミを各アクティビティーごとに1つの文字列にまとめます。
#各アクティビティーのコメントを1つにつなげたdf
df_c_join = pd.DataFrame(index=[], columns=["No.", "comment"])
df_review_all['comment'] = df_review_all['comment'].astype(str)
for n in df_review_all['No.'].unique(): #各アクティビティーNo.毎
c = '' #コメントを格納するリスト
df_no = df_review_all[df_review_all['No.']== n]
for i in df_no['comment']:
c += i
df_c_list_new = pd.DataFrame([[n, c]], columns=["No.", "comment"])
df_c_join = pd.concat([df_c_join, df_c_list_new], axis=0)
df_c_join.reset_index(inplace=True, drop=True)
df_c_join.head()
No. comment
0 163 とっても楽しかったです。\n川の水は冷たかったけれど、その分澄んでいて、景色も綺麗で感動しま...
1 178 ガイドさん曰く、天気予報はいい意味で大ハズレの無風!暑すぎず寒すぎず、楽しくカヌー体験出来ま...
2 191 雪で覆われた静かな林の中を馬に乗って分け入るのは最高の気分です。アップダウンがあるので馬との...
3 232 陽気なスタッフのサポートにより、楽しい時間を過ごすことが出来ました。\n初めての人でも、安心...
4 260 暑い晴天の日に、知床峠からのダウンヒルを楽しみました。町中に入るまで殆どペダルを漕ぐことなく...
df_base_dataとdf_c_joinを横方向に結合して1つのDataFrameとします。
df_base_review = pd.merge(df_base_data, df_c_join, left_on='No.', right_on='No.')
#コメントをstr型で統一
df_base_review['comment'] = df_base_review['comment'].astype(str)
df_base_review['introduction_title'] = df_base_review['introduction_title'].astype(str)
df_base_review['introduction_text'] = df_base_review['introduction_text'].astype(str)
#introduction_title, introduction_text, comment列のいらない文字を消す
for i in range(len(df_base_review)):
a,b,c = df_base_review['introduction_title'].iloc[i], df_base_review['introduction_text'].iloc[i], df_base_review['comment'].iloc[i]
a,b,c = a.replace('\n', ''), b.replace('\n', ''), c.replace('\n', '')
a,b,c = a.replace('\r', ''), b.replace('\r', ''), c.replace('\r', '')
df_base_review['introduction_title'].iloc[i], df_base_review['introduction_text'].iloc[i], df_base_review['comment'].iloc[i] = a,b,c
df_base_review.head()
name area small_area genre_type rating_star rating_asorepo introduction_title introduction_text No. url review_link comment
0 ガイドラインアウトドアクラブ 北海道 富良野・美瑛・トマム ['ラフティング'] 5.0 7 3歳からOKのラフティング!川を全身で遊ぼう!自然を満喫しよう☆ 南富良野にある水の綺麗な「シーソラプチ川」と「空知川源流部」にてラフティングを開催。全ツアー... 163 https://www.asoview.com/base/163/ /base/163/asorepo/list/ とっても楽しかったです。川の水は...
1 洞爺ガイドセンター 北海道 洞爺・登別・苫小牧 ['レイクカヌー', 'エコツアー・自然体験', 'スノーシュー・スノートレッキング'] 0.0 1 美しい洞爺湖を満喫。「旬なプラン」をご提供します! 北海道・洞爺湖で、自然体験アクティビティを開催している洞爺ガイドセンター。美しい自然をご案内... 178 https://www.asoview.com/base/178/ /base/178/asorepo/list/ ガイドさん曰く、天気予報はいい意味で...
2 函館どさんこファーム 北海道 函館・大沼・松前 ['乗馬 その他'] 0.0 3 どさんこと触れあう函館の旅!函館空港・函館駅から車で20分! 函館どさんこファームは函館空港・函館駅から20分と、アクセス抜群・好立地の乗馬クラブです。最... 191 https://www.asoview.com/base/191/ /base/191/asorepo/list/ 雪で覆われた静かな林の中を馬に乗って分け入るのは最高の気分...
3 リバートリップ北海道 北海道 洞爺・登別・苫小牧 ['ラフティング'] 0.0 2 女子会プランも大好評!北海道最高峰の激流・鵡川で本格ラフティング! リバートリップは、北海道最高峰と言われている鵡川で、本格的な激流ラフティングをご提供していま... 232 https://www.asoview.com/base/232/ /base/232/asorepo/list/ 陽気なスタッフのサポートにより、楽しい時間を過ごすことが出来ま...
このうち学習に必要なものだけを含むDataFrameを新たに作ります。
# 学習用のdf
df_train = df_base_review[['name', 'introduction_title', 'introduction_text', 'comment']]
学習を進めていく!!
TaggedDocumentを使って、アクティビティーの施設名をタグとし、先ほど分かち書きしたものと対応付けます。
taggeddocument = []
for i in range(len(df_train)):
#tagはアクティビティーの施設名(name列)/単語はwakati列
taggeddocument.append(TaggedDocument(tags=[df_train['name'].iloc[i]], words=df_train['wakati'].iloc[i]))
パラメーターはとりあえず何も考えずに学習させてみます。
model = Doc2Vec()
model.build_vocab(taggeddocument)
model.train(taggeddocument, total_examples=model.corpus_count, epochs=model.epochs)
1分ほどで学習が終わりました。モデルのできを確認してみます。
#スカイダイビングと似ている単語
model.wv.most_similar(['スカイダイビング'])
[('ハンググライダー', 0.6422897577285767),
('パラグライダー', 0.6232543587684631),
('フライボード', 0.570016086101532),
('モーターパラグライダー', 0.5616021752357483),
('ウインドサーフィン', 0.5531895160675049),
('タンデム', 0.520599901676178),
('ウェイクボード', 0.5099303722381592),
('スキューバ', 0.5097637176513672),
('パラセーリング', 0.5093426704406738),
('タンデムフライト', 0.5047745108604431)]
#茶道と似ている単語
model.wv.most_similar(['茶道'])
[('日本の伝統', 0.7715215682983398),
('染物', 0.7561860084533691),
('伝統文化', 0.75600266456604),
('伝統工芸', 0.7505102753639221),
('日本文化', 0.7441943883895874),
('伝統', 0.7313286662101746),
('フラワーアレンジメント', 0.7102695107460022),
('益子焼', 0.698409378528595),
('工芸', 0.6917717456817627),
('漢方薬', 0.6898465752601624)]
なにもチューニングしなくても割といい感じに学習できていそうです!単語だけでなくアクティビティーの施設名でも確認してみます。
#FlyStation Japanと似ている施設
model.dv.most_similar(['FlyStation Japan'])
[('松島熱気球・パラグライダー体験', 0.7538259029388428),
('秩父Geo Gravity Park(ジオグラビティーパーク)', 0.7106642127037048),
('東京タワーバンジーVR', 0.7083470225334167),
('阿蘇ネイチャーランド', 0.7024345397949219),
('エンジェル・ジップ スカイスポーツ\u3000つくば', 0.6908627152442932),
('富士見パノラマ パラグライダースクール', 0.6905115246772766),
('KPS那須高原パラグライダースクール', 0.6875401139259338),
('ハルカスバンジーVR', 0.6849852800369263),
('フライフィールド逗子', 0.6840368509292603),
('Niseko Paragliding(ニセコパラグライディング)', 0.6786245107650757)]
屋内スカイダイビングの施設であるFlyStation Japanと類似施設には、直感的にも近そうなパラグライダーやバンジージャンプができる施設が多く表示されました!!
#ムーミンバレーパークと似ている施設
model.dv.most_similar(['ムーミンバレーパーク'])
[('東映太秦映画村', 0.7494460344314575),
('サンリオピューロランド', 0.7350760102272034),
('六甲ミーツ・アート芸術散歩2022', 0.7135170698165894),
('星の王子さまミュージアム 箱根サン=テグジュペリ', 0.7100465893745422),
('大阪南港ATCホール', 0.7047433853149414),
('野外民族博物館 リトルワールド', 0.7018035054206848),
('美らヤシパークオキナワ・東南植物楽園', 0.7013224363327026),
('彫刻の森美術館', 0.7012519240379333),
('よこはま動物園ズーラシア', 0.6958396434783936),
('サントピアワールド', 0.6952996850013733)]
埼玉の誇る一大テーマパークであるムーミンバレーパークの類似施設は映画村やサンリオピューロランドみたいです。
これについても大変いい感じだと思います。
最後にモデルを保存しておきます。
#モデルを保存
model.save('asoview.model')
5. まとめ
今回はこれまでのデータからDoc2Vecのモデル構築を行いました!
まあまあいい感じのモデルができたのではないかと思います。次回はモデルのチューニングとレコメンド機能の実装に挑戦します!!
次回
参考文献
完成したものはこちら↓
第1回:【Python】まだ見ぬアクティビティーを求めてアソビュー !スクレイピング
第2回:第2回 【Python】まだ見ぬアクティビティーを求めてアソビュー !分析
第3回: 第3回 【Python】まだ見ぬアクティビティーを求めてアソビュー !口コミ スクレイピング
第4回:本記事
第5回:第5回 【Python】まだ見ぬアクティビティーを求めてアソビュー !Doc2Vecモデルチューニング