1. 概要
この記事は第2回の続きです。
第1回および第2回で、アクティビティー予約サイトであるアソビュー!から掲載されている施設の基本情報を取得しました。
そこで、本来の目的である口コミ情報を学習し、オススメのアクティビティーを提示するモデルを構築するために口コミ集めの作業に入っていきます!
完成したアプリはこちら↓
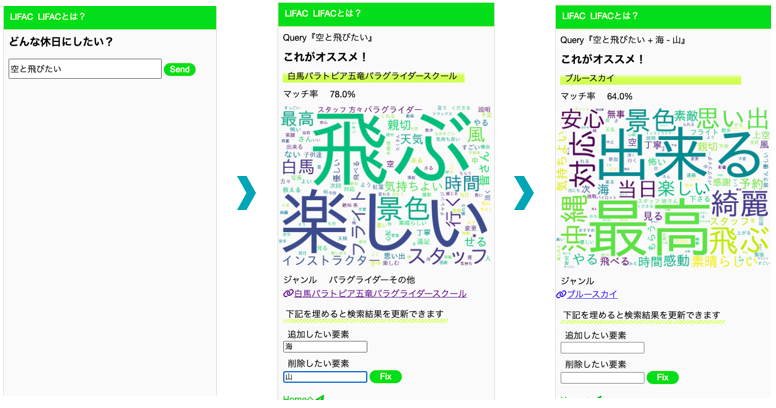
例えば「空を飛びたい」とき(検索後に海要素を足して、山要素を引くこともできます!!)
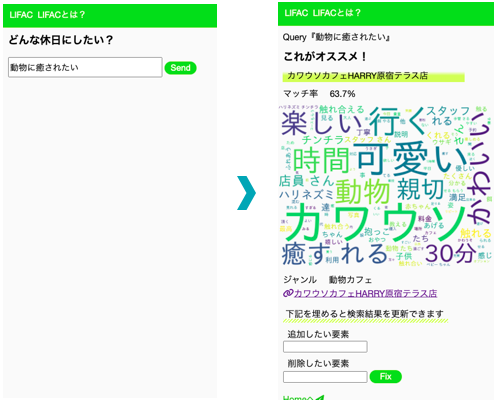
例えば「動物に癒されたい」とき
第1回:【Python】まだ見ぬアクティビティーを求めてアソビュー !スクレイピング
第2回:第2回 【Python】まだ見ぬアクティビティーを求めてアソビュー !分析
第3回:本記事
第4回: 第4回 【Python】まだ見ぬアクティビティーを求めてアソビュー !機械学習(Doc2Vec)
第5回:第5回 【Python】まだ見ぬアクティビティーを求めてアソビュー !Doc2Vecモデルチューニング
2. 口コミページの作りを確認
まずは口コミがどのように掲載されているかについて、以前からずっと気になっているインドアスカイダイビング施設FlyStation Japanを例に確認してみます。
口コミはhttps://www.asoview.com/base/151512/asorepo/list/に掲載されており、https://www.asoview.com/base/<<アクティビティーNo.>>/asorepo/list/とすることで他の施設の口コミも見られそうです。
1ページに20件口コミが掲載されており、FlyStation Japanの場合は2022/09/30時点で240件の口コミが付いているので口コミページが12ページ存在します。

試しに3ページ目に飛んでみると、https://www.asoview.com/base/151512/asorepo/list/?page=2となり、口コミのトップページ(https://www.asoview.com/base/151512/asorepo/list/)に?page=<<数字>>を付け加えることでページを移動できます。
3. 口コミを取得してみる
先ほどまでの内容を踏まえて、FlyStation Japanの口コミを取得してみます。
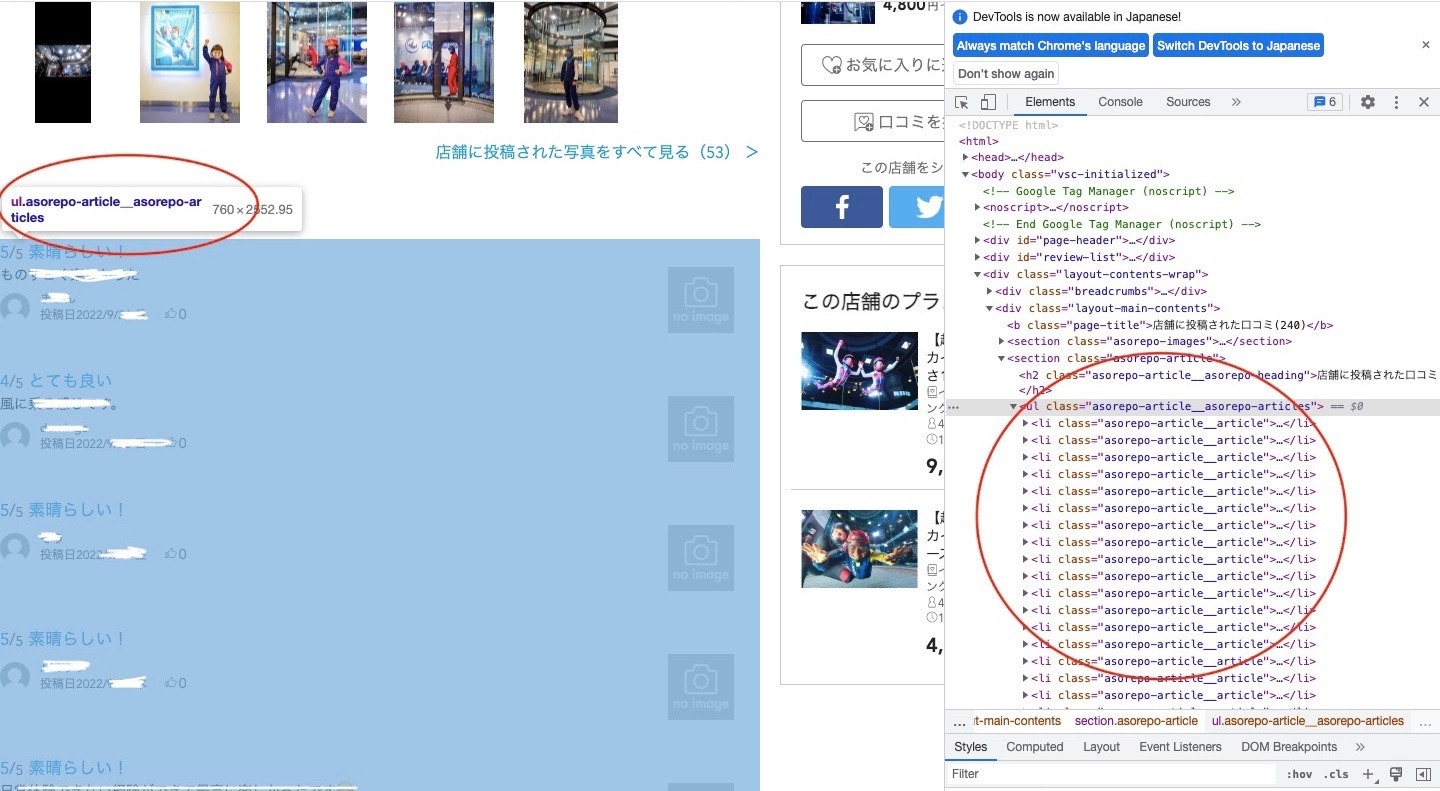
それぞれの口コミはclass名が"asorepo-article__asorepo-articles"のulタグの中に入っており、<li class="asorepo-article__article">が口コミ1つ分です。
そこで、
import requests
from bs4 import BeautifulSoup
import time
from datetime import datetime
import pandas as pd
import re
import math
必要なライブラリをインストールしたら、
url = 'https://www.asoview.com/base/151512/asorepo/list/'
res = requests.get(url)
soup = BeautifulSoup(res.text, "html.parser")
#口コミのブロック
review_block = soup.find("ul", class_="asorepo-article__asorepo-articles")
#各口コミのリスト
review_block_list = review_block.find_all("li", class_="asorepo-article__article")
として<li class="asorepo-article__article">全てをリストとして取得します。
口コミの
投稿日は<time class="asorepo-article__post-date">
評価は<em class="asorepo-article__review-total-score-value">
コメントは<i class="asorepo-article__user-comment">
に入っているのでreview_block_listから1つずつ取り出していきます。
for r in review_block_list:
#日付を取得
r_date = r.find("time", class_="asorepo-article__post-date")
r_date = re.sub(' \D','', r_date.text)
r_date = datetime.strptime(r_date, '%Y/%m/%d')
print(r_date)
#評価を取得
r_star = r.find("em", class_="asorepo-article__review-total-score-value")
if r_star.text != "未設定": #評価があるとき
r_star = int(r_star.text)
else: #評価がないとき
r_star = None
print(r_star)
#コメントを取得
r_comment = r.find("i", class_="asorepo-article__user-comment")
r_comment = r_comment.text
print(r_comment)
print('---------')
2022-09-26 00:00:00
5
ものすごく楽しかった
---------
2022-09-25 00:00:00
4
風に乗る感じです。
---------
2022-09-23 00:00:00
5
(以下略)
とこんな感じで口コミを取得できました!
ここで1つ問題が起こりました。この手法では次のように長いコメントの全文を取得できません。

未知の体験でとても良かったです。
1分だけ?短いな、と思いましたが、全身の筋肉を使うので逆に1分以上は無理だと思います。
ふわふわ浮くようなイメージをしていたのですが、強風に負けないよ...
となってしまいます。そこで長いコメントに対してはそのコメントの詳細ページまで行って取得するようにします。
#コメントが長い場合は詳細ページまで確認しにいく
if "..." in r_comment:
r_url = r.find("a", class_="asorepo-article__article-detail")
r_url = r_url.get('href')
r_url = "https://www.asoview.com" + r_url
r_res = requests.get(r_url)
r_soup = BeautifulSoup(r_res.text, "html.parser")
r_comment = r_soup.find("pre", class_="asorepo-detail__text").text
長いコメントには末尾に"..."が付くので、それを頼りにコメントが省略されているかどうかを判別しました。
こうすることで口コミの日時と評価、およびコメントを取得できるようになりました!!
4. 口コミが掲載されているページのURL
上で確認した通り、1ページに20件の口コミが掲載されているので、それ以上を取得する場合は新たに訪問するべきページのリンクを知っておく必要があります。
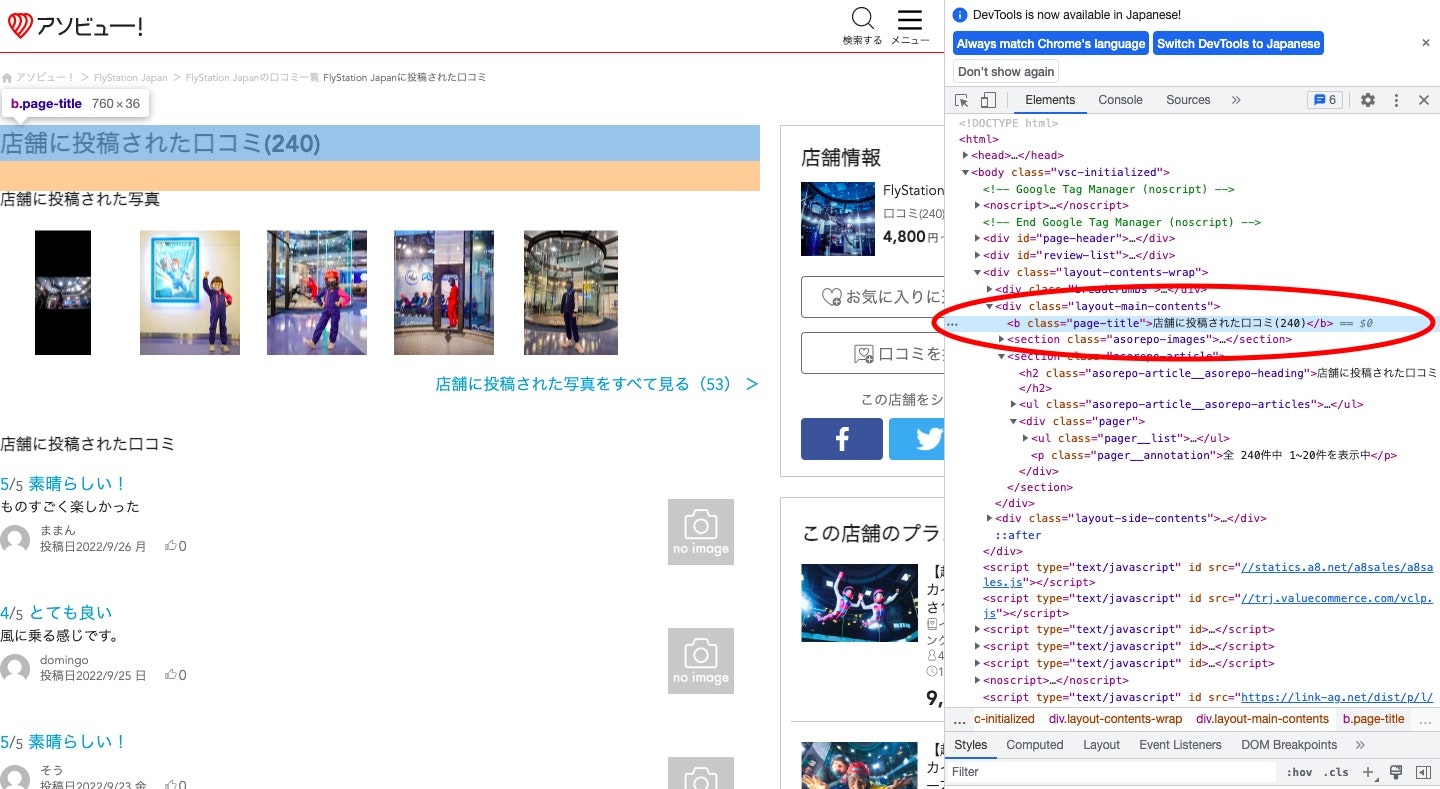
口コミの総数はここに記述されているので、口コミ総数/20(小数点以下切り上げ)でページ数を取得し、全口コミの全リンクを取得します。
#baseとなるURLとそのレスポンス
url_base = "https://www.asoview.com/base/151512/asorepo/list/"
res_base = requests.get(url_base)
soup_base = BeautifulSoup(res_base.text, "html.parser")
#URLの数
#口コミが存在するページ数を取得する
num_review = soup_base.find("b", class_="page-title").text
num_review = re.sub("(\D)*","", num_review)
num_review = int(num_review)
page_num = math.ceil(num_review/20)
#口コミのある全URLをリストに格納する
url_list = []
url_list.append(url_base)
for i in range(1, page_num):
url = url_base + "?page=" + str(i)
url_list.append(url)
print(url_list)
['https://www.asoview.com/base/151512/asorepo/list/', 'https://www.asoview.com/base/151512/asorepo/list/?page=1', 'https://www.asoview.com/base/151512/asorepo/list/?page=2', 'https://www.asoview.com/base/151512/asorepo/list/?page=3', 'https://www.asoview.com/base/151512/asorepo/list/?page=4', 'https://www.asoview.com/base/151512/asorepo/list/?page=5', 'https://www.asoview.com/base/151512/asorepo/list/?page=6', 'https://www.asoview.com/base/151512/asorepo/list/?page=7', 'https://www.asoview.com/base/151512/asorepo/list/?page=8', 'https://www.asoview.com/base/151512/asorepo/list/?page=9', 'https://www.asoview.com/base/151512/asorepo/list/?page=10', 'https://www.asoview.com/base/151512/asorepo/list/?page=11']
5. 口コミをアクティビティー毎に取得していく
ここまできたらあとは第1回に取得した基本情報のうち、アクティビティーNo.を用いて口コミを取得していきます!
まずは取得したいアクティビティーNo.のリスト
#第1回の取得ファイル
df_base_data = pd.read_csv('base_data.csv')
#アクティビティーNo.のリスト
#10件以上レビューがあるものを使う
n_list = n_list = df_base_data[df_base_data['rating_asorepo']>=10]['No.']
print(n_list)
6 263
7 264
8 281
12 337
13 340
...
8591 158104
8601 158220
8606 158341
8625 158646
8630 158757
Name: No., Length: 2865, dtype: int64
取得したデータを入れていく空のDataFrame
#dfをつくる
#アクティビティーNo./日付/評価/コメント
df_review_all = pd.DataFrame(index=[], columns=["No.", "date", "star", "comment"])
各アクティビティーの口コミを100件まで取得する関数
#各アクティビティーの全口コミを取得する関数
def get_reviews(n_list, df_review_all): #引数はアクティビティーNo.のリストとDataFrame
start=time.time()
count=0 #取得したアクティビティ数を数える
for n in n_list: #各アクティビティー毎
r_count = 0 #口コミ数を数える
print(f"No.{n}の口コミを集める")
#そのアクティビティーの口コミをまとめるdf
df_review = pd.DataFrame(index=[], columns=["No.", "date", "star", "comment"])
#baseとなるURLとそのレスポンス
url_base = f"https://www.asoview.com/base/{n}/asorepo/list/"
res_base = requests.get(url_base)
soup_base = BeautifulSoup(res_base.text, "html.parser")
time.sleep(1)
#URLの数
#口コミが存在するページ数を取得する
num_review = soup_base.find("b", class_="page-title").text
num_review = re.sub("(\D)*","", num_review)
num_review = int(num_review)
page_num = math.ceil(num_review/20)
#口コミのある全URLをリストに格納する
url_list = []
url_list.append(url_base)
for i in range(1, page_num):
url = url_base + "?page=" + str(i)
url_list.append(url)
try:
#URLの各リスト毎に口コミを取得する
for url in url_list:
res = requests.get(url)
soup = BeautifulSoup(res.text, "html.parser")
time.sleep(1)
#口コミのブロック
review_block = soup.find("ul", class_="asorepo-article__asorepo-articles")
#各口コミのリスト
review_block_list = review_block.find_all("li", class_="asorepo-article__article")
for r in review_block_list:
#日付を取得
r_date = r.find("time", class_="asorepo-article__post-date")
r_date = re.sub(' \D','', r_date.text)
r_date = datetime.strptime(r_date, '%Y/%m/%d')
#評価を取得
r_star = r.find("em", class_="asorepo-article__review-total-score-value")
if r_star.text != "未設定":
r_star = int(r_star.text)
else:
r_star = None
#コメントを取得
r_comment = r.find("i", class_="asorepo-article__user-comment")
r_comment = r_comment.text
# print('コメント', r_comment)
#空欄でないレビュー数
if r_comment != '':
r_count += 1
# print('レビュー数', str(r_count))
#コメントが長い場合は詳細ページまで確認しにいく
if "..." in r_comment:
r_url = r.find("a", class_="asorepo-article__article-detail")
r_url = r_url.get('href')
r_url = "https://www.asoview.com" + r_url
r_res = requests.get(r_url)
r_soup = BeautifulSoup(r_res.text, "html.parser")
time.sleep(1)
r_comment = r_soup.find("pre", class_="asorepo-detail__text").text
#1行ずつdf_reviewに追加する
df_new = pd.DataFrame([[n, r_date, r_star, r_comment]], columns=["No.", "date", "star", "comment"])
#df_reviewと結合
df_review = pd.concat([df_review, df_new], axis=0)
#アクティビティー毎のレビュー数の取得上限は100とする
if r_count >= 100:
print('レビューが100件に達しました')
break
except requests.exceptions.HTTPError as e: #例外処理
print("HTTPError:", e)
continue
except requests.exceptions.ConnectionError as e:
print("ConnectionError:", e)
continue
except:
print("エラー")
continue
df_review_all = pd.concat([df_review_all, df_review], axis=0)
count+=1
print(f"進捗率:{(count/len(n_list))*100}%")
print("経過時間:", time.time()-start, "秒")
print("=============================================")
#1時間経ったら止める
if time.time()-start > 3600:
print('1時間に達しました')
break
return df_review_all
これで口コミを取得できます!!
df_review_all = get_reviews(n_list, df_review_all)
#csvとして保存
df_review_all.to_csv('df_review_all.csv')
df_review_all.head()
No. date star comment
0 263 2022-09-19 5 最高のカヌー体験でした!ありがとうございました!
0 263 2022-09-16 5 ガイドの方が親切。\nツアー内容も充実していて、素敵な思い出になりました。
0 263 2022-08-28 5
0 263 2022-08-18 5
...
6. まとめ
今回は各アクティビティー毎の口コミを取得することができました。次回はこの口コミを学習して、オススメのアクティビティーをレコメンドしてくれるモデルを構築していきます💪
次回
第1回:【Python】まだ見ぬアクティビティーを求めてアソビュー !スクレイピング
第2回:第2回 【Python】まだ見ぬアクティビティーを求めてアソビュー !分析
第3回:本記事
第4回: 第4回 【Python】まだ見ぬアクティビティーを求めてアソビュー !機械学習(Doc2Vec)
第5回:第5回 【Python】まだ見ぬアクティビティーを求めてアソビュー !Doc2Vecモデルチューニング